基于分層模糊支持向量機的油液磨粒自動識別*
2019-05-30 08:59:20
潤滑與密封 2019年5期
(重慶大學煤礦災害動力學與控制國家重點實驗室 重慶 400030)
視情維修理念的提出為機械設備的運行維護提供了一個新的突破口,解決了長期定期維修下的種種弊端,在故障潛在階段即可采取相應的維修維護措施,避免其進一步擴大引起設備的功能故障。油液分析技術是視情維修理念指導下典型的設備故障診斷與監測方法之一,它以油液性能檢測及油液中的磨損顆粒分析為核心,通過磨粒的形貌特征來識別磨粒類型,繼而判斷設備當前的磨損程度及失效原因,減少甚至消除設備以磨損失效為主的突發性故障。磨粒分析是油液監測的重要內容,該項工作提出之際均為人工分析,耗時長、誤差大,嚴重限制了油液分析技術在工程領域的廣泛應用。近年來,不少學者在磨粒的智能分析領域開展了大量研究,灰色系統[1]、神經網絡[2-4]、支持向量機[5-7]、決策樹[8]、證據推理規則[9]等都被用于磨粒識別領域且取得了一定的成果,磨粒分析工作逐步實現自動化,分析效率得到了明顯的提高。
受磨粒樣本數量、高維特征參數的影響,以小樣本為研究對象的模式識別方法在磨粒分析工作中表現出更強的適用性,支持向量機在解決小樣本、非線性、高維特征問題上的特有優勢,更是在磨粒自動識別領域顯示出了十足的發展前景。傳統支持向量機、最小二乘支持向量機作為目前應用最廣泛的識別模型,其在測試樣本集上雖然表現出較高的識別精度,但在實際應用過程中,模型的泛化能力依舊不足。受運行工況影響,設備在用油液攜帶有各種形態的磨損顆粒,某些磨粒呈現多種磨損機制作用下的復合特征,當這些磨粒作為訓練樣本時,其本身包含了對類別的隸屬信息,而傳統支持向量機(Support Vector Machines,SVM)、最小二乘支持向量機(Least Squares Support Vector Machines,LSSVM)模型均未考慮訓練樣本對分類結果的貢獻程度這一因素,而將所有樣本同等對待,使得支持向量機的理論優越性在磨粒自動識別工作中難以完全凸顯,模型的泛化能力受到影響。
除此之外,支持向量機現有的構造多類別分類器的方法,包括一對多法(one-against-rest,o-a-r)、一對一法(one-against-one,o-a-o)、有向無環圖法(Directed Acyclic Graph,DAG)、二叉樹法(Decision Tree,DT)[10]等,在完成磨粒多類別分類時也出現了不少問題。例如,o-a-r法的每個二分類器都有龐大的訓練樣本集,模型的分類效率難以提高;o-a-o法與DAG法需要構造的二分類器數量多,模型的累積誤差嚴重;DT法的分類效果很大程度上取決于二叉樹的結構選型,分類誤差始終處于不可控狀態。因此,有必要考慮更適合磨粒識別的多類別分類模型,讓模型在分類器數量、訓練效率及分類精度之間取得最佳折中,充分發揮支持向量機的性能。
本文作者將模糊支持向量機應用到油液磨粒的自動識別工作中,通過引入隸屬度函數來使訓練樣本集包含對類別的隸屬信息,同時基于現有的多分類算法構造一種更適用于磨粒識別的參數自適應分層多分類模型,以期進一步提高油液磨粒分析技術的工程實用性,促進故障診斷在工業生產中的廣泛應用。
1 油液磨粒自動識別的核心內容
1.1 待識別磨粒類型的確定
機械設備在用油液中的游離金屬磨粒包括正常磨損磨粒與異常磨損磨粒,異常磨粒按磨損機制可以劃分為切削磨粒、嚴重滑動磨損磨粒、滾滑復合磨損磨粒、疲勞片狀磨粒、疲勞塊狀磨粒及球狀磨粒。正常磨粒產生于設備運行全壽命周期的各個階段,單個粒子不攜帶有任何設備異常磨損的信息。而異常磨粒與磨損工況密切相關,油液中一旦出現這些類型的磨粒,無論數量分布多少,都預示著機器內部可能已經出現了相應形式的磨損。這是異常磨損信息最早期的表現形式,磨粒類型的判定對磨損部位的判斷和磨損嚴重程度的確定都有很強的指導作用。因此,本文作者選擇6類異常磨損磨粒為待識別對象,設計分層多類別模糊支持向量機模型完成磨粒的自動識別工作。
1.2 磨粒自動識別流程
利用鐵譜技術或濾膜譜片技術提取油液中的磨損顆粒,基于顯微鏡獲取磨粒圖譜,作為磨粒自動識別工作開展的前提。完成圖像的獲取后,即可開展磨粒的自動識別工作,其實現流程如圖1所示。
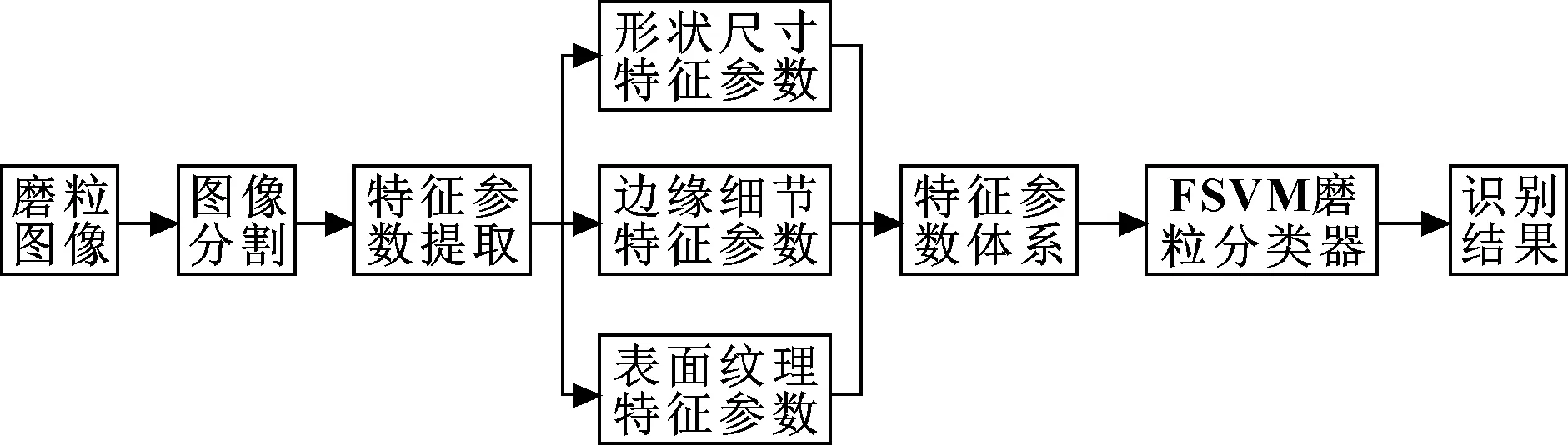
圖1 磨損顆粒自動識別流程
1.3 磨粒圖像分割
為了實現磨粒與背景的準確分割,最大化保留原始圖像的信息,文中直接對彩色圖像進行分割,在Lab顏色空間中利用K-均值聚類算法實現目標磨粒的提取,具體分割流程參照文獻[11]。圖2所示為一嚴重滑動磨粒的分割實例。

圖2 嚴重滑動磨粒圖像分割實例
1.4 磨粒特征參數提取
特征參數作為磨粒的量化表征,必須能夠代表磨粒的典型形貌特征,以保證在特征量化的過程中不會丟失磨粒形貌的關鍵信息,最大化還原磨粒的區分度。根據六類待識別磨粒的形貌特征,文中選擇形狀尺寸特征參數、邊緣細節特征參數、表面紋理特征參數構成了磨粒的18維特征參數體系。
(1)形狀尺寸特征參數
對磨粒的輪廓曲線進行Fourier變化即可提取具有平移旋轉不變性的形狀特征參數。文中主要基于磨粒的輪廓曲線提取了其相應的傅里葉描述子[12],計算得到圓形度F1、細長度F2、散射度F3、凹凸度F4等形狀特征參數。為了盡可能降低磨粒輪廓跟蹤過程存在的誤差,文中又基于磨粒的二值圖像提取了區域形狀描述子作為修正,包括矩形度AP及體態比AR,形成6維形狀尺寸特征參數。區域描述子的定義如下:
AP=A/P
(1)
AR=a/b
(2)
式中:A、P分別為基于區域統計的磨粒面積與周長;a、b分別為磨粒區域最小外接矩形的長軸與短軸。
(2)邊緣細節特征參數
邊緣細節特征參數是反應磨粒輪廓隨機程度和復雜程度的典型參數,文中采用FAENA法[13]提取磨粒的邊界分形維數D作為其邊緣細節表征。
(3)表面紋理特征參數
表面紋理參數主要基于灰度共生矩陣[14]提取。將原圖像的灰度級壓縮至16級,提取對比度CON、相關性COR、能量ENG、熵ENT、一致度HOM等二次統計量在0°、45°、90°、135°方向上的均值m與方差v作為磨粒的紋理表征。考慮到圖像灰度級壓縮過程可能造成的信息損失,提取磨粒表面灰度值的方差GM作為補充,形成11維表面紋理參數。參數GM的定義如下:
GM=
1pixels∑p∈s[gray(xp,yp)-1pixels∑p∈sgray(xp,yp)]2
(3)
式中:s為磨粒區域;gray(x,y)為磨粒區域(x,y)點的灰度值;pixel為磨粒區域s的像素點個數。
表1所示為待識別6類磨粒的18維特征參數提取結果示例。

表1 磨粒特征參數提取結果示例
1.5 二分類模糊支持向量機模型的建立
模糊支持向量機[15](Fuzzy Support Vector Machines,FSVM)是傳統支持向量機的一種變形算法,通過隸屬度函數實現樣本集的模糊處理,使訓練樣本集包含有對類別隸屬程度的信息,以此來提高分類器的推廣能力。
對于二類別分類問題,選擇n個類別已知磨粒的特征參數體系構成訓練樣本集,首先定義適當的隸屬度函數完成樣本的模糊化,將訓練集轉化為模糊訓練集:
train={(xl,yl,tl),l=1,.....,n}
其中:l表示第l個樣本;xl為磨粒樣本的特征參數向量;xl∈Rn;yl為樣本xl的所屬類別;yl∈{-1,1};tl為樣本xl屬于某類的隸屬度,滿足δ≤tl≤1,其中δ為任意一個極小的正數。
對于非線性可分的訓練數據集,(w,b)在特征空間中確定唯一的最優超平面,滿足w·x+b=0,使得兩類樣本之間有最大的分類間隔。模糊支持向量機在最優超平面的求解問題上,采取將其轉化為目標函數的最優解問題這一思路進行求解:
min12‖w‖2+C∑nl=1tlξl
s.t.{yl(wlxl+b)≥1-ξl,l=1,2,......,n
ξl≥0,l=1,2,......,n
(4)
式中:ξl為松弛變量,是對樣本xl錯分程度的度量參數;C為懲罰因子,代表優化過程對分類誤差的關注程度。
式(4)為典型的二次規劃問題,引入Lagrange乘子α,將該約束最優化問題轉換為相應的對偶問題:
maxα∑nl=1αl-12∑nl=1∑nq=1αlαqylyq(xl·xq)
s.t.{∑nl=1αlyl=0,l=1,2,......,n
0≤αl≤Ctl,l=1,2,......,n
(5)
假設優化問題的最優解α*=(α*1,......,α*n)T,則最優分類函數表示為
f(x)=w*·x+b*
(6)
式中:w*表示最優權值向量;b*表示最優偏置,計算公式分別為
{w*=∑α*lylxl
b*=mean(yq-∑nl=1α*lyl(xl·xq))
l=1,......,n
q=1,......,n且q∈{q|0<α*q≤Ctq}
(7)
根據式(6)與式(7)獲取樣本x的最優分類函數值后,樣本x的類別決策規則為
F(x)={ 1,f(x)>0
-1,f(x)<0
(8)
基于上述原理構建模糊支持向量機二分類模型,以磨粒的特征參數提取結果為輸入向量,即可獲取磨粒分類的最優決策函數值,實現類別的自動判斷。隸屬度函數的確定是構建模糊支持向量機分類器的關鍵環節,合理地選擇隸屬度函數可以最大程度地提取樣本包含的信息,讓模糊支持向量機的特有性能獲得充分表現。反之,隸屬度函數如果不符合樣本的實際情況,往往會混淆不同數據點對分類結果的實際貢獻程度,在分類過程中引入新的誤差。文獻[16-18]提出了幾類隸屬度函數的確定方法。就目前而言,模糊隸屬度函數的形式并未有統一標準,隸屬度函數的優劣應結合樣本數據點的測試情況來具體判斷。
2 分層多類別FSVM模型的構造
2.1 分層多類別FSVM分類器的設計
考慮6類磨粒的形貌特殊性,球狀磨粒和切削磨粒與其他4類磨粒在形狀特征上有明顯的差異性,因此在構造球狀磨粒和切削磨粒分類器時可以不考慮表面紋理特征參數,而僅以形狀尺寸特征參數及邊緣細節特征參數為主,構成分類器的輸入向量。對于嚴重滑動磨粒、滾滑復合磨粒、疲勞片狀磨粒及疲勞塊狀磨粒,這4類磨粒的形狀特征參數與球狀磨粒、切削磨粒之間有明顯的區分點,但彼此之間的分布較為接近,主要在表面紋理特征參數上表現出一定的差異性,想要實現這4類磨粒的準確分割,需要以18維特征參數作為輸入向量,完成各個二分類器的訓練。
為了最大程度地簡化分類器結構、縮短訓練時間、提高分類速度與精度,文中結合DT法和o-a-r法,提出了一種更適合磨粒自動識別的分層多類別FSVM分類器的構造方法,將這種構造方法下的模型記為DT/oar-FSVM模型。記球狀磨粒為類別1,切削磨粒為類別2,嚴重滑動磨粒為類別3,滾滑復合磨粒為類別4,疲勞層狀磨粒為類別5,疲勞剝塊磨粒為類別6,該模型的分解策略和組合策略描述如下:
分解策略:首先將類別1作為正類樣本,其余所有類別作為負類樣本,選擇形狀尺寸特征參數和邊緣細節特征參數組成7維輸入向量,訓練球狀磨粒分類器FSVM1;其次將類別2作為正類樣本,除類別1以外的4類磨粒為負類樣本,同樣以形狀尺寸特征參數和邊緣細節特征參數為輸入向量,訓練切削磨粒分類器FSVM2;對于其他4類磨粒,則結合表面紋理參數形成18維輸入向量,以待識別磨粒為正類樣本,其余三類為負類樣本,依次訓練分類器FSVM3、FSVM4、FSVM5、FSVM6。這種分解策略下共需要訓練6個二分類器,但訓練樣本的數量相較于o-a-r法明顯減少,訓練速度快,同時,該方法避免了二叉樹結構的選型問題,使得累積誤差可控。
組合策略:基于訓練好的6個二分類器,結合DT法和o-a-r法完成三層多類別FSVM分類器的構造。選擇FSVM1作為分類器的根節點,其組合模型如圖3所示。
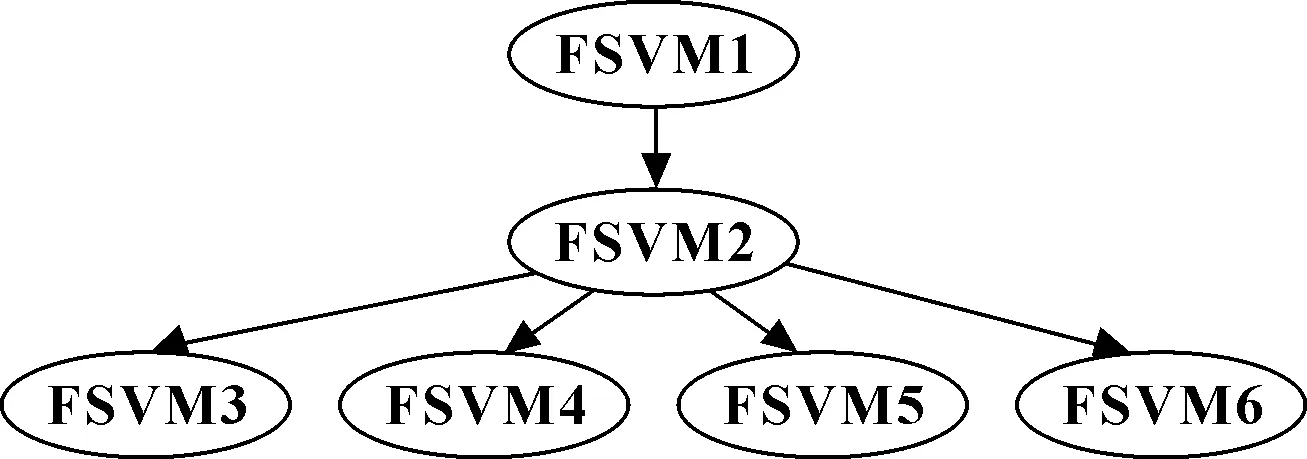
圖3 DT/oar-FSVM模型的組合策略
2.2 測試樣本的識別過程
假設m個待識別磨粒的特征參數集構成18維輸入向量Xi,其中i為磨粒的編號,i=1,......m。在識別過程中,首先選擇Xi的前7維特征參數構成新的輸入向量xi,進入分類器FSVM1,利用決策函數f1(x)確定屬于類別1的樣本,不屬于類別1的樣本繼續進入FSVM2,判斷其是否屬于類別2。對于不屬于類別1和類別2的樣本,再基于18維特征參數集重新構成輸入向量xj,同時進入FSVM3、FSVM4、FSVM5、FSVM6四個分類器,將決策函數f(x)取最大值時的二分類器作為識別結果。圖4所示為基于DT/oar-FSVM模型的磨粒識別過程。

圖4 基于DT/oar-FSVM模型的磨粒識別過程
2.3 DT/oar-FSVM識別模型的參數優化
在FSVM模型的訓練過程中,參數的選擇是影響分類器性能的重要因素,文中基于粒子群優化算法(Particle Swarm Optimization,PSO)完成DT/oar-FSVM模型的參數優化工作,該算法在SVM、LSSVM模型中已經表現出較優的性能[19-20]。參考文獻[6],以磨粒識別率為適應度函數,選擇能對慣性因子實現動態調整的改進PSO算法優化模型參數,以迭代中止時識別率最高的解變量為優化結果,獲取分類模型的最佳參數,實現參數自適應的PSO-DT/oar-FSVM模型。
3 工程實例分析及對比研究
3.1 樣本獲取與試驗設計
以某臺正常施工的旋挖鉆機為監測對象,設備運行5 000 h左右時分別在其液壓回路和潤滑點取樣,利用濾膜譜片技術完成油液中磨損顆粒的提取,獲取試驗樣本。圖5所示為油樣中典型磨粒的圖像。

圖5 旋挖鉆機油液中的典型磨粒
選取6類磨粒各50個,共300個磨損顆粒構成樣本集data,data={data1,data2,data3,data4,data5,data6}。磨粒識別工作的各個環節均在MatLab平臺上完成。通過交叉驗證來測試PSO-DT/oar-FSVM模型的性能,并通過對比試驗分析PSO-DT/oar-FSVM模型在磨粒識別中的實用性,具體試驗步驟如下:
(1)完成磨粒圖像的分割及特征參數的提取工作,獲取18維特征參數體系,形成分類器的輸入樣本集。
(2)在各類磨粒中分別隨機選擇40個作為訓練樣本,10個作為測試樣本,組合成訓練樣本集與測試樣本集,訓練PSO-DT/oar-FSVM識別模型,模糊隸屬度函數參考文獻[16]。PSO算法的基本參數選擇如下:粒子總數為40,最大循環迭代次數N為100,學習因子均為2,慣性因子的最大值和最小值分別為0.9和0.4。
(3)為了評估PSO-DT/oar-FSVM模型對測試數據集的泛化能力,分析訓練樣本及測試樣本的選擇情況對模型性能的影響,對模型的性能進行交叉驗證評估,對比測試樣本集的識別率。交叉驗證試驗流程如下:
①將各類磨粒的50個樣本隨機均分成5份,分別形成5個相斥的子集。記為datai={datai1,datai2,datai3,datai4,datai5},i=1,2,3,4,5,6。
②輪流在data1、data2、data3、data4、data5、data6中選擇1份作為測試樣本集,其他的4份作為訓練樣本集,組合成240個數據點的訓練樣本集與60個數據點的測試樣本集,得到5個分類模型。測試樣本集的組成如下所示:
testdata1= {data11,data21,data31,data41,data51,data61}
testdata2= {data12,data22,data32,data42,data52,data62}
testdata3= {data13,data23,data33,data43,data53,data63}
testdata4= {data14,data24,data34,data44,data54,data64}
testdata5= {data15,data25,data35,data45,data55,data65}
③重復驗證模型5次。獲取當前樣本集下PSO-DT/oar-FSVM模型對訓練樣本及測試樣本的識別率。
(4)為了測試多類別分類器的構造方法對分類結果的影響,在同等條件下分別基于o-a-r法、DT法構造多類別分類器,二叉樹結構選擇為分類器性能最佳時的最優結構,依次建立PSO-oar-FSVM模型與PSO-DT-FSVM模型,基于步驟(3)中的樣本集完成訓練樣本和測試樣本的分類測試。
(5)為了測試PSO-DT/oar-FSVM模型是否優于其它類型的支持向量機分類模型,同時測試隸屬度函數的選擇是否正確,在相同的多類別構造方法和參數優化算法下對步驟(3)中的樣本集利用SVM和LSSVM模型進行分類測試,分別建立PSO-DT/oar-LSSVM模型與PSO-DT/oar-SVM模型,對比樣本的識別結果。
3.2 PSO-DT/oar-FSVM模型的測試結果
基于磨粒的特征參數集訓練分類器模型。在訓練過程中,利用PSO算法優化模型的懲罰因子C值,C的取值范圍選擇為[10,1000]。分類結果表明:在當前樣本集下,PSO-DT/oar-FSVM模型對訓練樣本的識別率為90.42%,對測試樣本的識別率為90%。表2所示為模型的主要參數及對樣本集的識別率。

表2 PSO-DT/oar-FSVM模型的參數優化結果及識別率
3.3 模型的交叉驗證
模型的交叉驗證結果如圖6所示。結果表明,在不同的訓練樣本集下,PSO-DT/oar-FSVM模型對測試樣本集的識別率均不低于85%,模型的性能較為穩健。

圖6 PSO-DT/oar-FSVM模型的交叉驗證
3.4 對比分析3.4.1 不同多類別分類方法下的識別率對比
從模型的復雜程度、分類效率以及分類精度等方面對不同構造形式下的多類別分類器的性能進行對比分析,圖7為分類器的識別率對比圖。結果表明:PSO-oar-FSVM模型識別率最低、誤差最大,該模型需要構建6個二分類器,每個二分類器的訓練樣本數量均為240個,模型訓練速度慢;PSO-DT-FSVM模型與PSO-DT/oar-FSVM模型相對穩定,DT法只需要構造5個二分類器,且訓練樣本數量逐層減少,依次為240個、200個、160個、120個、80個,分類效率顯著提高,但該分類器在測試樣本上表現不佳,推廣性能有待提高;而文中提出的DT/oar分層構造多類別FSVM模型的方法,測試樣本的識別率明顯提高,最高達90%,說明這種方法最大化平衡了模型的學習精度和學習能力,使模型的泛化性能達到最佳。就磨粒自動識別而言,PSO-DT/oar-FSVM模型表現出一定的優越性。

圖7 不同多類別分類方法下模型的識別率對比圖
3.4.2 不同支持向量機模型的識別率對比
在相同的多類別分類方法下,FSVM模型相較于同等參數優化條件下的LSSVM模型和SVM模型也表現出一定的優勢,表3為模型交叉驗證時隨機生成的樣本集在不同形式支持向量機上的識別率平均值。從測試結果可以看出,在樣本集模糊化處理后,無論是對訓練樣本的分類精度,還是對未知樣本的識別能力,PSO-DT/oar-FSVM模型都表現出較優的性能,說明FSVM模型在磨粒自動識別工作中有較強的適用性,隸屬度函數的引入對磨粒的識別率提高起到正相關作用。
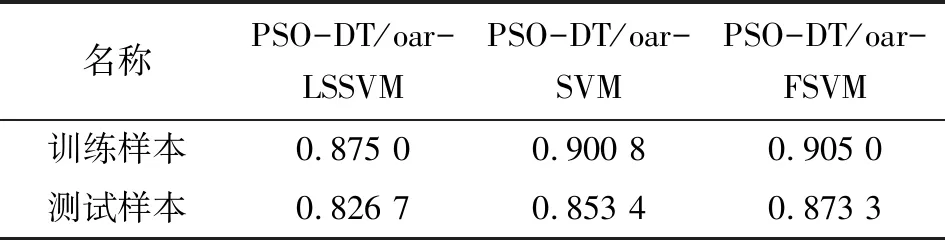
表3 三類SVM模型的識別率對比
3.5 討論
文中提出的PSO-DT/oar-FSVM模型雖然在磨粒識別中表現出了較好的分類效果,但其準確率也不是100%,表4明確地給出了識別率最高時60個測試樣本的具體誤分情況。可以看出,滾滑復合磨粒的識別率最低,疲勞片狀和剝塊磨粒也出現誤分的現象。分析磨粒誤分的原因,滾滑復合磨粒的形成受多種磨損機制共同影響,疲勞磨損和黏著磨損下都有可能出現滾滑復合磨粒,使得該類磨粒的形貌呈現多樣性,容易將其識別為單一磨損機制下的嚴重滑動磨粒或疲勞磨粒。對于疲勞片狀磨粒和疲勞剝塊磨粒而言,厚度信息是區分和識別這兩類磨粒的重要信息,而灰度圖像往往難以明確地反映出這類特征信息,同時,圖像分割的后處理環節也使片狀磨粒喪失了表面孔洞等信息,從而影響了這兩類磨粒的識別率。
磨粒自動識別的準確程度受磨粒獲取、圖像分割、特征參數提取等各個環節影響,由于每個環節都存在或多或少的誤差,誤差累積后最終都會體現在模型的識別性能上。為了進一步提高磨粒自動識別工作的準確程度,可以從磨粒識別工作的各個環節入手,優化磨粒識別體系,將累積誤差降到最低。
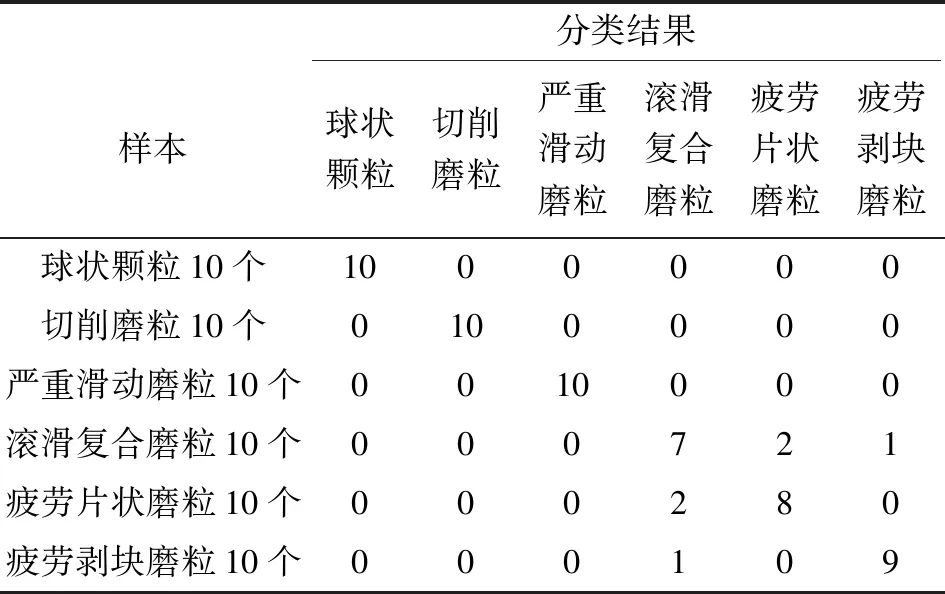
表4 PSO-DT/oar-FSVM模型下各測試樣本的分類結果
4 結論
(1)通過將模糊集理論引入支持向量機,充分考慮了樣本對類別歸屬的模糊性,最大化地利用了訓練樣本集的信息,對于磨粒識別而言,在樣本來源非常廣泛時也可以獲得較高的識別精度。
(2)在各個二分類器的訓練過程中,輸入向量可以根據待識別正類樣本的形貌特征視情選擇。選擇最能反映該類磨粒的典型特征參數作為訓練該類磨粒分類器的輸入向量,這樣可以在最大化分類精度的條件下通過降低輸入參數的維數來提高分類器的訓練速度,減少多余參數的干擾。
(3)在磨粒的自動識別工作中,結合二叉樹和一對多法構造的分層多類別分類器表現出了單一組合法難以比及的效果,這種構造方法最大程度地簡化了分類器的結構,降低了累計誤差,顯著提高了分類效率和泛化能力。
(4)采用PSO-DT/oar-FSVM模型對旋挖鉆機齒輪油和液壓油中的磨粒進行識別,模型對測試樣本的識別準確率最高可達90%,優于同等條件下的其他支持向量機模型。該模型有較大的工程實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
