基于偏好融合的群組推薦研究
2019-05-30 23:31:00汪祥舜鄭孝遙朱德義章玥孫麗萍
南京信息工程大學學報 2019年5期
關鍵詞:數據挖掘
汪祥舜 鄭孝遙 朱德義 章玥 孫麗萍


摘要 傳統的推薦系統主要針對單個用戶,但隨著社會和電子商務的快速發展,人們越來越多地以多個用戶的形式一起參與活動,而群組推薦旨在為多個用戶組成的群組提供服務,已成為當前研究的熱點之一.針對目前群組推薦準確率低,群組成員之間偏好沖突難以融合的問題,本文提出了一種新的共識模型策略,融合了群組領袖影響因子和項目熱度影響因子,基于K近鄰為目標群組尋找鄰居群組,借鑒鄰居群組的偏好,設計了基于偏好融合的群組推薦算法.在MovieLens數據集上的實驗結果表明,本文所提的融合策略較傳統的偏好融合策略有著更優越的表現,推薦準確率(nDCG)的總體平均性能約提高13%,推薦列表多樣性指標的總體平均性能約提高10%.
關鍵詞 群組推薦;推薦系統;偏好融合;協同過濾;數據挖掘;偏好預測
中圖分類號 TP311
文獻標志碼 A
0 引言
隨著社會和經濟的飛速發展,尤其是近年互聯網的廣泛應用,人類進入了大數據時代.面對紛繁復雜的商品信息,僅依靠搜索引擎很難準確獲得滿足自身需求和個性化的信息資源,用戶往往難以發現最需要或最適合的項目,越來越多的在線服務不可避免地受到“信息過載”問題的困擾,這使得用戶難以發現他們所需要的信息,推薦系統為解決這一問題應運而生.
傳統的推薦系統,如上下文感知推薦系統、移動推薦系統、實時推薦系統等,都是向單個用戶提供個性化推薦,但是隨著社會的發展和人們聯系的緊密,人們經常以多個用戶所組成的群組形式參與某項活動,例如人們會組團出去度假、進餐、看電影等,因此進行群組推薦的研究有著十分重要的意義.群組推薦已經成為近些年來推薦系統領域一個研究熱點.
群組推薦系統得到了國內外研究人員和開發工作者的廣泛重視.文獻[1-2]結合模型融合和推薦融合的優點,提出了一種改進的偏好融合方法,提高了組推薦的整體推薦性能.Yuan等[3]提出了一個稱為COM的共識模型,考慮用戶在群組中的行為變化,依賴于主題的影響和內容信息,有效地提高了組推薦的準確率.Tang等[4]提出了一種基于用戶交互行為的偏好融合策略,但該策略未考慮群組內已消費項目的影響因素.Sabrine等[5]用基于用戶的協同過濾算法為群組成員生成推薦列表,用Borda規則來生成群組推薦,但是該方法的融合策略過于簡單,導致推薦準確率相對較低.
群組推薦系統與很多領域(如數據挖掘、機器學習等)都有著緊密的聯系.Chen等[6]將遺算法應用于組推薦中,用來預測群組成員之間存在的相互作用,提高了群組成員的滿意度.文獻[7-10]將數據挖掘的很多方法與組推薦相結合,提升了群組推薦系統在多方面的作用效益.機器學習和深度學習的很多理論和方法也被廣泛應用到組推薦系統[11-14]中,Wang等[15]提出了一種用于組推薦的雙向張量分解模型,采用貝葉斯個性化排序技術來學習所提出的BTF-GR模型的參數.群組內的成員之間包含豐富的行為作用信息,挖掘用戶之間的相互作用規律可大幅度提高推薦質量,文獻[16-17]通過用戶之間的信任關系和社交信息來提高組推薦的準確率.盡管國內外研究在群組推薦領域做出了很多有益的探索,但是現有方法的偏好融合策略都相對較簡單,群組成員之間的分歧度較高,推薦準確率仍有待提高.因此本文針對群組偏好建模問題,提出一種新的共識模型策略,融合群組領袖影響因子和項目熱度影響因子,并基于K近鄰設計了一種新的基于偏好融合的群組推薦算法,實驗表明,本文提出的改進算法效能較傳統的策略推薦性能有著更優越的表現.
1 相關工作
1.1 群組推薦系統的形式化定義
到目前為止,群組推薦系統仍沒有統一的定義形式.文獻[18-19]詳細闡述了群組推薦的語義和效率,并提出了一種使用共識分數的方法來定義群組推薦系統,該定義主要由共識函數和分歧度組成,具體的形式化定義如下:
1)群組預測評級.群組G對項目i的預測評級RG(G,i)是對每個群組成員的預測評級的融合結果.使用的融合策略不一樣,得到的群組的預測評級也不一樣,如均值策略的群組預測分數的計算公式為
2)群組分歧度.群組G對項目i的分歧,表示為dis(G,i),反映了群組成員之間預測評級的分歧程度.文獻[1-2]考慮了以下兩種主要的計算分歧度的方法:
1.2 群組推薦偏好融合策略
群組推薦系統有多種不同的偏好融合策略,文獻[20]對常見的融合策略做了詳細闡述.到目前為止,在群組推薦系統的研究中,常用的策略有最小痛苦策略、均值策略和最開心策略.具體定義如下:
1)最小痛苦策略(Least Misery Strategy,LM):以群組成員最低的個人評級作為該群組的評級.設RGi,j表示群組Gi對項目j的評分,RUl,j為群組中成員ul對項目j的評分,則可用下述式(5)表示:
2)均值策略(Average Strategy,AVG):以群組成員的評級的平均值作為該群組的評級.若用avg表示求平均值運算,則可用下述式(6)表示:
3)最開心策略(Most Pleasure Strategy,MP):以群組成員最高的個人評級作為該群組的評級.若用max表示求最大值運算,則可用下述式(7)表示:
2 問題定義和模型構建
2.1 相關定義
為了更好的描述本文對群組推薦系統所做的研究,將本文所做的研究工作定義如下:
定義1 群組領袖:一個群組由多個用戶組成,群組內的成員各有差異,消費的項目及其數量各不相同,對推薦的決策產生的影響也有所不同.因此,本文根據群組成員的作用大小為其分配不同的權重,將群組內對推薦決策起到關鍵作用的用戶定義為該組的群組領袖.群組領袖可以是一個,也可以是多個,群組領袖的排名按照影響大小逐步遞減的次序依次確定.群組領袖往往是該群組內活躍度最大、消費項目數量最多的用戶.
定義2 群組領袖影響因子:為了精確衡量群組內成員作用程度的大小,本文定義群組領袖影響因子為αi.設用戶ui消費的項目總數記為Ni,項目種類數為Ci,群組G消費的項目總數和種類數分別為NG和CG,則αi定義如下:
定義3 熱度項目:推薦系統更傾向于向用戶推薦消費次數多的項目,項目被消費的次數越多,在一定程度上表明其受歡迎的程度越高.本文定義消費數量排名靠前的k個項目為熱度項目.
定義4 項目熱度影響因子:為了量化項目熱度的高低,本文定義項目熱度影響因子為βj,設m為消費該項目的用戶個數,M為群組G內的用戶總數,則βj定義如下:
定義5 鄰居群組:群組之間也具有相似性,例如學生群組、球迷群組、旅游群組等,群組之間彼此都有著緊密的聯系或相同的興趣愛好等.相似的群組在很大程度上會有著相同的偏好,可以根據相似群組的偏好為目標群組提供推薦參考,本文將這樣相似的群組定義為鄰居群組.鄰居群組的尋找,可首先計算該群組與目標群組之間的相似度,根據群組之間相似度的大小為其合理歸類到相應的目標群組.一個目標群組可找到多個鄰居群組,這些鄰居群組可構成一個鄰居群組集合.
2.2 共識模型
為進一步提高群組推薦的準確率,本文融合了群組領袖影響因子和項目熱度影響因子,為目標群組尋找近鄰組,并借鑒鄰居群組的偏好.本文用F(Gi,Ij)表示群組Gi對項目j的預測評分,αi表示群組領袖影響因子,βj表示項目熱度影響因子,I表示群組的項目集,j表示需要預測的項目,RCF(ui,Ij)表示單個用戶之間協同過濾產生的預測評級,RNG(Gi,Ij)表示基于群組間的K近鄰推薦產生的預測評級,則本文的共識模型定義如下:
3 算法設計與分析
本文的算法在訓練集上對共識模型進行訓練,在測試集上驗證推薦結果,本文算法的主要思想流程如圖1所示.
3.1 劃分群組
為了確定兩個用戶之間的關聯程度,可以通過計算兩個用戶之間相似度的方法度量兩個用戶之間的親密程度.設u和v表示任意兩個用戶,u和v分別為由用戶u和用戶v評分信息所組成的評分向量,用scos(u,v)表示兩個用戶之間的余弦相似度,則計算式為
為合理劃分群組,本文首先通過計算任意2個用戶之間的余弦相似度,將相似度高的用戶構造成一個群組,并且總是優先選擇有相同或相似偏好的用戶加入該群組,以減少群組成員之間的分歧度.
3.2 基于偏好融合的K近鄰組推薦
基于偏好融合的K近鄰(K Nearest Nighborhood,KNN)組推薦,其基本思想是根據鄰居群組的偏好為目標群組提供推薦,如圖2所示.設Group-m為需要推薦的目標群組,Group-n和Group-s是和目標群組相似的2個群組,可借鑒近鄰組的偏好,為目標群組生成Top-k推薦列表.
基于偏好融合的K近鄰組推薦,首先計算任意2個群組之間的相似度,然后挑選合適的鄰居,最后完成推薦過程.挑選合理的鄰居集合規模是基于K近鄰推薦最重要的一步.
3.2.1 領域的選擇
領域數量和選擇領域的規則會對推薦結果產生重要的影響,傳統基于K近鄰的推薦可用如圖3左圖所示.在選定目標群組以后,首先選定K個鄰居,然后根據歐式距離或者計算2個群組之間的相似度來挑選鄰居,然而由于K的值是人為事先選定,如果挑選的不合理,加入了關聯程度較差的群組,這樣反而會大大降低推薦的精度.例如圖3左圖所示,若事先選定6個鄰居,從圖中可以看出,群組G8和目標群組G1的距離較遠,并不適合挑選出來作為目標群組G1的鄰居,如果把G8挑選出來當做鄰居反而降低了推薦的準確度,此時的推薦質量不如挑選G2、G3、G5、G7、G9這5個鄰居更合適.
與選擇固定數量的鄰居數目的做法不同,本文首先設定一個閾值過濾,保留相似度權重數大于設定閾值的近鄰,在算法執行時,過濾掉相似度低的群組,如下方右圖所示,閾值的過濾效果相當于在目標群組G1的周邊畫了一個圓,可以合理舍棄掉周邊相似度低的離散的點,這樣便可以去掉G8這個偏離中心的點.
閾值的合理選取會影響預測的精度,如果閾值設置過高,會降低可供選擇的近鄰的數量,這會降低很多群組的覆蓋率;相反,如果閾值設置太低,鄰居數量會很多,如果鄰居群組中有很多關聯度低的群組,也會對推薦結果產生消極的影響.當所需要的鄰居數量較少的時候,2種方法產生的結果幾乎一致,但當可供挑的鄰居數量較多時,第二種方案對推薦結果更能起到更好的作用.
3.2.2 算法實現
基于偏好融合的K近鄰組推薦算法,首先需要確定相似的鄰居群組集,本文首先采用Pearson相關系數來計算2個群組之間的相似度,用sPearson(G,G′)表示群組G和群組G′之間的Pearson相似度,計算式如下:
在確定好近鄰組的集合以后,對于N個最相似的鄰居群組,設RG,i值表示群組G后對項目i的預測評分,則目標群組G對項目i的預測評分可用下式表示:
具體的算法描述如下所示.
算法1 基于偏好融合的K近鄰群組推薦算法
輸入:需要預測的群組編號id和項目編號id
輸出:該群組對該項目的預測評分
1.divide Groups
2.calculate GroupJaccardSim
3.while(Current Nearest Neighbor Groups!=required Neighbor Groups) do
4.for each k in GroupNum∥k表示計數器
5. if (k!=G&&GroupJaccardSim>max) then
∥G為群組id,max用來臨時保存GroupJaccardSim所得的最大值
6. for each j< Current NearestNeighborGroups
7.if(k==flaG[j]) then
∥flaG[]表示已存在的與群組G相似度最大的群組id的數組
8.Break;
9. end if
10. if(j==Current Nearest Neighbor Groups)
11. max←GroupJaccardSim;
12. flaG[i2]←k
13.end if
14. end for
15.end if
16. end for
17. utill find required K Neighbor Groups
18.end while
19.caculate GroupPearsonSim
20.return G on Item i Predicted Rating Based on KNN Groups
4 實驗結果與分析
4.1 數據集和實驗設置
本文實驗采用的是MoviesLens 100K數據集,MovieLens數據集是由明尼蘇達大學的GroupLens研究項目收集,該數據集包括943名用戶對1 682部電影的100 000點評分,評分范圍是1~5分,評分越大表示用戶越喜歡該電影,其中每位用戶至少點評了20部電影.該數據集被廣泛應用于推薦系統相關的實驗或科研項目中.為了有效對推薦結果和算法進行衡量,本文將MoviesLens數據集隨機選擇80%作為訓練集,剩余20%作為測試集,算法在訓練集中進行測試,然后將推薦結果與測試集中的數據進行驗證,對比分析論證實驗結果.
4.2 評價指標
1)歸一化折損累計增益
歸一化折損累計增益指標(normalized Discounted Cumulative Gain,nDCG)是基于排序的評價方法,是衡量組推薦準確率的一種重要指標.本文使用nDCG來作為推薦準確率的評價標準.由于群組推薦列表是由群組內成員若干偏好得到,要反應該群組成員對推薦結果的滿意程度,可對比驗證測試集中的數據,度量預測的排序與實際排序的準確程度.
設p1,p2,…,pk為算法產生的有序推薦結果列表,u表示某一個用戶,rupi表示用戶u對項目pi的真實評分,i為列表中的位置.DCG(Discounted Cumulative Gain)的計算公式為
其中,GuIDC,k 表示用戶u的最大DCG值,可根據用戶真實評分高低,將k個項目按照最理想情況進行排序計算出IDCG的值.nDCG等于真實DCG值與IDCG的商,nDCG的數值越大,表明推薦準確率越高.本文的nDCG是群組成員的平均nDCG值.
2)多樣性
推薦項目的多樣性是衡量組推薦系統的推薦性能高低的一個重要評價指標,本文用Divers衡量推薦項目的多樣性.首先采用Jaccard相關系數來計算兩個項目之間的相似度,然后按照公式(17)計算推薦列表項目的多樣性.
計算兩個項目之間的Jaccard相似度用下式表示:
推薦列表多樣性Divers可用下式計算:
其中sJac(Ii,Ij)表示項目i和項目j之間的Jaccard相關系數,k表示推薦列表的項目的個數.Divers的數值越大,表明推薦結果的多樣性越高.
3)均方根誤差
均方根誤差被廣泛應用于推薦系統的實驗評估指標,可衡量預測結果的精確度,本文所用的群組推薦的均方根誤差公式RMSE如下:
設RG,i表示群組G對項目i的預測評分,G,i表示群組G對項目i的真實評分,T表示群組G中的參與預測的項目個數,IRMSE的值越小表明推薦的準確度越高.
4.3 敏感性分析
4.3.1 參數權重對推薦性能的影響
為達到最佳的推薦效果,選取最佳的參數,通過實驗對參數a和b進行靈敏度分析.
從圖4中可以看出,當a=0.6,b=0.4時,RMSE取得最小值,此時推薦準確度最好,這也從側面說明在推薦過程中起決定性因素的是群組內的用戶偏好.
4.3.2 近鄰組個數對推薦精度的影響
本文在MoiveLens數據集上,改變近鄰組的個數,采用本文所提的共識模型,完成對預測精度的測試實驗,實驗結果如圖5所示.
從實驗結果可以看出:預測的準確度受近鄰組數量的影響,RMSE隨著近鄰組的數量的增加總體呈下降的趨勢,當近鄰組達到一定的數量的時候,RMSE的值開始上下波動、維持動態平衡.實驗結果表明預測的精度隨著近鄰組的個數的增加總體呈上升的趨勢;當近鄰組的個數比較少的時候,預測的準確度不是很高;當近鄰組達到一定數量的時候,我們會發現預測的精確度總體趨勢幾乎保持不變.我們更換不同的群組,多次進行重復實驗,發現當近鄰組的個數在9左右的時候,群組推薦的預測準確度受近鄰組的個數敏感較小,預測的準確度可穩定在一定的范圍內.實驗發現并不是近鄰組越多,預測的準確度就越高,而是到達一定數量的時候,預測的準確度基本維持不變.
4.4 實驗結果
在本節中我們改變群組規模來驗證本文所提共識模型的推薦準確率和推薦列表多樣性.
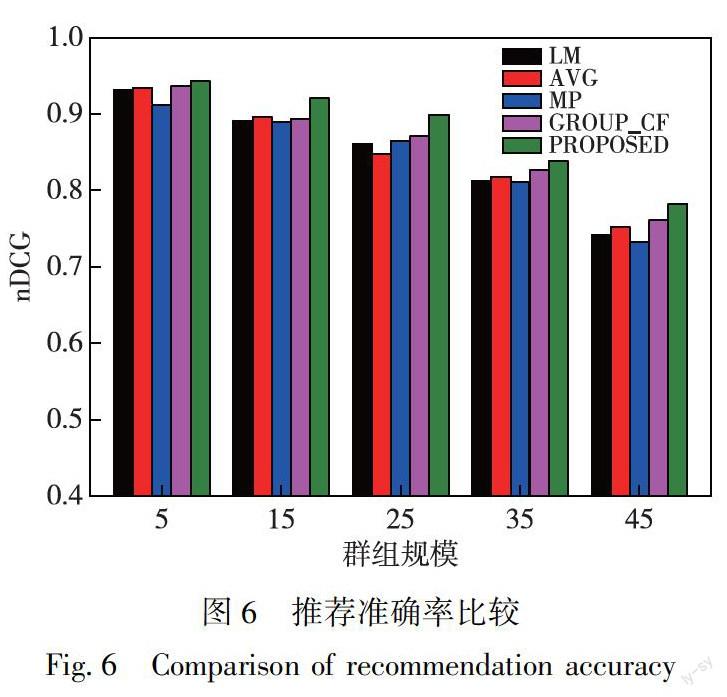
1)推薦準確率
實驗結果如下圖所示,其中橫軸表示群組規模,群組規模為5表示該群組成員的個數為5,依次類推;縱軸表示nDCG.GROUP-CF表示群組間協同過濾算法策略;PROPOSED表示本文所提的共識模型策略.從圖6中可以看出,在相同的群組規模下,本文所提的模型策略在推薦準確率上有所提高;當群組規模為15和25時,本文所提共識模型有更著較為優良的表現;實驗也表明在其他的分組規模下,本文所提的融合模型策略也明顯優于另外常見的4種策略,在推薦準確率上總體的平均性能約提高13%.
2)推薦項目的多樣性
實驗結果如圖7所示,其中縱軸Divers表示群組推薦項目的多樣性.實驗結果表明,當群組成員的個數較少的時候,推薦列表的多樣性相對較低;隨著群組成員個數的增加,群組推薦列表的多樣性有一定的增加.同時實驗結果也驗證了本文所提的共識模型的多樣性優于前4種融合策略,本文所提的共識模型在多樣性指標上總體平均性能上約提高10%.
5 總結和展望
現有的大多數推薦系統主要是針對單個用戶進行推薦,隨著人們聯系的緊密和社會的發展,群組推薦已成為研究熱點.如何為群組提供精準的推薦仍然是一個開放性的問題,也是一個挑戰.群組推薦系統研究的難點在于是找出一個合理的偏好融合策略,盡可能的降低群組成員的之間的分歧度,使推薦結果能夠滿足群組內大多數成員的偏好.本文提出了一種新的共識模型,提出了群組領袖影響因子和項目熱度影響因子等概念,融合群組內和群組間的多種因素,提高了群組推薦的準確率;并設計了基于偏好融合的K近鄰群組推薦算法,為目標群組尋找鄰居群組,并借鑒鄰居群組的偏好,在MoviesLens數據集上也驗證了本文所提的共識模型的優越性,相較幾種常見的偏好融合策略,本文所提的共識模型策略在推薦準確率nDCG上總體的平均性能約提高13%,在多樣性上總體的平均性能約提高10%.接下來的工作擬打算從群組成員之間的信任關系和社交關系等展開進一步的研究.
參考文獻References
[1] 張玉潔,杜雨露,孟祥武.組推薦系統及其應用研究[J].計算機學報,2016,39(4):745-764
ZHANG Yujie,DU Yulu,MENG Xiangwu.Research on group recommender systems and their applications[J].Chinese Journal of Computers,2016,39(4):745-764
[2] 胡川,孟祥武,張玉潔,等.一種改進的偏好融合組推薦方法[J].軟件學報,2018,29(10):3164-3183
HU Chuan,MENG Xiangwu,ZHANG Yujie,et al.Enhanced group recommendation method based on preference aggregation[J].Journal of Software,2018,29(10):3164-3183
[3] Yuan Q,Cong G,Lin C Y.COM:a generative model for group recommendation[C]∥ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2014:163-172
[4] Tang F,Liu K,Feng L,et al.Research on the integration strategy of group recommendation based on user's interactive behaviors[C]∥2016 IEEE International Conference on Cloud Computing and Big Data Analysis,2016:367-372
[5] Abdrabbah S B,Ayadi M,Ayachi R,et al.Aggregating top-K lists in group recommendation using Borda rule[M]∥Advances in Artificial Intelligence:From Theory to Practice.Cham:Springer International Publishing,2017:325-334
[6] Chen Y L,Cheng L C,Chuang C N.A group recommendation system with consideration of interactions among group members[J].Expert Systems with Applications,2008,34(3):2082-2090
[7] Guo Z W,Tang C W,Tang H,et al.A novel group recommendation mechanism from the perspective of preference distribution[J].IEEE Access,2018,6:5865-5878
[8] Seo Y D,Kim Y G,Lee E,et al.An enhanced aggregation method considering deviations for a group recommendation[J].Expert Systems with Applications,2018,93:299-312
[9] Feng S S,Cao J,Wang J,et al.Group recommendations based on comprehensive latent relationship discovery[C]∥2016 IEEE International Conference on Web Services,2016:9-16
[10] Boratto L,Carta S,Fenu G,et al.Influence of rating prediction on group recommendation's accuracy[J].IEEE Intelligent Systems,2016,31(6):22-27
[11] Guo Z W,Zeng W R,Wang H,et al.An enhanced group recommender system by exploiting preference relation[J].IEEE Access,2019,7:24852-24864
[12] Yin H,Wang Q,Zheng K,et al.Social influence-based group representation learning for group recommendation[C]∥2019 IEEE 35th International Conference on Data Engineering,2019:566-577
[13] Du Y L,Meng X W,Zhang Y J.CVTM:a content-venue-aware topic model for group event recommendation[J].IEEE Transactions on Knowledge and Data Engineering,2019.DOI:10.1109/TKDE.2019.2904066
[14] Zhang W,Wang J,Feng W.Combining latent factor model with location features for event-based group recommendation[C]∥ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2013:910-918
[15] Wang J K,Jiang Y C,Sun J S,et al.Group recommendation based on a bidirectional tensor factorization model[J].World Wide Web,2018,21(4):961-984
[16] Guo C,Tian X M.Flickr group recommendation using content interest and social information[C]∥Proceedings 2014 IEEE International Conference on Security,Pattern Analysis,and Cybernetics,2014:405-410
[17] Santos E B,Manzato M G,Goularte R.A conceptual architecture with trust consensus to enhance group recommendations[C]∥2014 IEEE/ACIS 13th International Conference on Computer and Information Science,2014:137-142
[18] Amer-Yahia S,Roy S B,Chawlat A,et al.Group recommendation:semantics and efficiency[J].Proceedings of the VLDB Endowment,2009,2(1):754-765
[19] Roy S B,Amer-Yahia S,Chawla A,et al.Space efficiency in group recommendation[J].The VLDB Journal,2010,19(6):877-900
[20] Masthoff J.Group modeling:selecting a sequence of television items to suit a group of viewers[J].User Modeling and User-Adapted Interaction,2004,14(1):37-85
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
