一種結(jié)合隨機(jī)游走和粗糙決策的文本分類方法
2019-06-06 05:46:34柴玉梅王黎明
小型微型計算機(jī)系統(tǒng) 2019年6期
韓 飛,柴玉梅 ,王黎明 ,劉 箴
1(鄭州大學(xué) 信息工程學(xué)院, 鄭州 450001)2(寧波大學(xué) 信息科學(xué)與工程學(xué)院,浙江 寧波 315211)
1 引 言
伴隨著互聯(lián)網(wǎng)發(fā)展的熱潮以及人工智能領(lǐng)域技術(shù)的不斷革新,賦予機(jī)器情感已成為研究中的重要課題.情感分類作為其中的重要手段,在社會媒體處理領(lǐng)域有了良好的發(fā)展,如輿情監(jiān)控、商務(wù)決策等[1].由于各大主流媒體平臺的開放性,人們通常會在評論區(qū)表達(dá)其主觀情緒特征,因此針對用戶行為偏好的分析具有很高的研究價值[2,3].
由于用戶在瀏覽網(wǎng)頁時其行為的隨機(jī)性與模糊性,有學(xué)者通過用戶對網(wǎng)頁的點(diǎn)擊行為進(jìn)行分析并建立模型,從而實(shí)現(xiàn)針對用戶行為的網(wǎng)頁排序,并取得了良好的效果.本文把隨機(jī)游走模型在網(wǎng)頁排序中的方法應(yīng)用在詞網(wǎng)絡(luò)圖的構(gòu)建中,結(jié)合粗糙集模型,把詞網(wǎng)絡(luò)圖構(gòu)建后的情感詞極性分析結(jié)果進(jìn)行離散化處理,并對屬性值進(jìn)行加權(quán),擴(kuò)充了隨機(jī)游走模型的使用范圍,通過最終的粗糙決策置信度對加權(quán)后的屬性文本進(jìn)行類別劃分.
模糊性詞匯的判別一直是文本分類中的重要課題,本文通過對數(shù)據(jù)集的標(biāo)詞、分詞等處理,對詞匯進(jìn)行特征選擇,得到候選特征,提出基于擴(kuò)展隨機(jī)游走模型的情感詞極性判別算法,得到模糊性詞匯的情感極性,進(jìn)一步得到候選屬性集.結(jié)合詞匯情感極性,建立文本情感決策表.運(yùn)用粗糙集的知識,對候選屬性進(jìn)行離散化處理,提出基于粗糙集的文本情感類別判定模型,從而得到最終文本情感分類.本文流程框架圖如圖1所示.
2 相關(guān)工作
文本情感分類是指通過分析文本中的立場、觀點(diǎn)、態(tài)度等主觀信息,挖掘文本中的情感傾向,從而對其傾向類別進(jìn)行判定,目前已經(jīng)提出了一系列的情感分類方法[4-8].

圖1 文本類別判定流程框架圖Fig.1 Flow chart of text categorization decision
由于社交媒體的開放性不斷增加,評論和博客可能被分為不同的極性組,如正、負(fù)和中性,以便從輸入數(shù)據(jù)集中提取信息. Tripathy等人[4]利用有監(jiān)督機(jī)器學(xué)習(xí)方法對這些評論進(jìn)行分類,使用樸素貝葉斯(Naive Bayes,NB),最大熵(Maximum Entropy,ME),隨機(jī)梯度下降(Stochastic Gradient Descent,SGD)和支持向量機(jī)(Support Vector Machine,SVM)方法,依據(jù)精度,召回率,F(xiàn)度量和準(zhǔn)確率等評價標(biāo)準(zhǔn),對不同方法的準(zhǔn)確性進(jìn)行了嚴(yán)格的考察.Turney等人[5]以情感詞為中心,采用點(diǎn)互式信息檢索(Pointwise Mutual Information,PMI)和潛在語義分析(Latent Semantic Analysis,LSA)兩種方法用于評估詞關(guān)聯(lián)度,并取得了較高的準(zhǔn)確率.在對情感類別劃分的基礎(chǔ)上,有些學(xué)者利用算法框架對情感分類結(jié)果進(jìn)行優(yōu)化.Silva等人[6]提出了一種半監(jiān)督學(xué)習(xí)框架,從無標(biāo)簽數(shù)據(jù)構(gòu)建的相似性矩陣中捕獲無監(jiān)督信息,并與分類器相結(jié)合,通過自訓(xùn)練算法來產(chǎn)生更好的情感分類結(jié)果.實(shí)驗(yàn)數(shù)據(jù)集從Twitter中選取,結(jié)果表明,提出的框架可以提高情感分類的準(zhǔn)確性.由于文本維度通常很龐雜,對特征的降維也是情感分類中必不可少的工作.吳鈺潔等人[7]通過建立一種概率圖模型,并用其對詞語中的情感概率值進(jìn)行計算,再通過信息熵公式歸一化其情感特征值,最后進(jìn)行情感分類,實(shí)驗(yàn)也表明其方法的有效性.在文本評論中,用戶偏好使得情感判定類別產(chǎn)生傾斜,Tian等人[8]提出了一種基于句子的實(shí)例轉(zhuǎn)移方法,通過使用輔助數(shù)據(jù)集(源數(shù)據(jù)集)來處理不平衡的正負(fù)文本產(chǎn)品評論數(shù)量.該方法結(jié)合了規(guī)則和監(jiān)督學(xué)習(xí)混合方法來識別每個產(chǎn)品評論的主題句,并將主題句的特征集添加到情感分類的特征空間.
隨機(jī)游走模型是針對用戶瀏覽網(wǎng)頁的行為建立的抽象概念模型.Rao等人[9]提出一種基于單詞極性構(gòu)圖的問題求解框架,每個節(jié)點(diǎn)表示要確定其極性的單詞,并且可以有兩個標(biāo)簽:正或負(fù).Kok等人[10]提出了一種基于隨機(jī)游走模型的方法來學(xué)習(xí)雙語平行語料庫.文中采用隨機(jī)游走來計算達(dá)到釋義排序所需的平均步數(shù),而更好的“更接近”感興趣的詞組.隨機(jī)游走模型也可用于多標(biāo)簽分類學(xué)習(xí)中,鄭偉等人[11]提出了一種基于隨機(jī)游走模型的多標(biāo)簽分類算法,將多標(biāo)簽數(shù)據(jù)映射成為多標(biāo)簽隨機(jī)游走圖,有效解決多標(biāo)簽分類問題.
粗糙集理論是一種比較新的處理模糊性和不確定性的軟計算工具,被認(rèn)為是前沿領(lǐng)域.基于粗糙集的離散化具有一定的特點(diǎn),必須滿足決策系統(tǒng)離散化的一致性要求.張嬌鵬等[12]提出一種面向數(shù)據(jù)取值更新的批處理機(jī)制,根據(jù)粗糙集和信息熵的概念,提出了一種面向數(shù)據(jù)取值動態(tài)變化數(shù)據(jù)集的特征選擇方法,可一次處理一組變化數(shù)據(jù),拓展了粗糙集在特征選擇方向的應(yīng)用,實(shí)驗(yàn)證明了算法的有效性.Sun等人[13]提出了一種基于決策屬性的連續(xù)屬性離散化方法,該方法考慮了決策屬性的重要度,連續(xù)屬性依照重要度依次離散化,實(shí)驗(yàn)結(jié)果表明該方法有效減少斷點(diǎn)并提高識別精準(zhǔn)度.孫夢等人[14]提出了一種基于粗糙集的優(yōu)勢關(guān)系排序問題,利用向量相似度和并列對象準(zhǔn)則對排序向量進(jìn)行賦權(quán),得到最終排序結(jié)果.實(shí)驗(yàn)表明其方法的合理性.Chen等人[15]提出了一種區(qū)間數(shù)離散化算法,基于多屬性決策建立區(qū)間決策樣本,確定區(qū)間對象間的相似矩陣,并利用最小離散區(qū)間得到最終離散化結(jié)果,實(shí)驗(yàn)證明了算法的有效性.
3 相關(guān)概念
3.1 基于圖論的隨機(jī)游走模型
隨機(jī)游走模型可以預(yù)測不同節(jié)點(diǎn)之間的潛在關(guān)系,也可應(yīng)用于文本分類中[16].通過構(gòu)建圖框架,進(jìn)而找出相鄰節(jié)點(diǎn)間的關(guān)系,每個節(jié)點(diǎn)可以用一個單詞進(jìn)行表示,如果有多關(guān)系節(jié)點(diǎn),那么就調(diào)整節(jié)點(diǎn)間的邊緣強(qiáng)度[17].
使用隨機(jī)游走模型來識別單詞的極性,可以假定使用一個詞網(wǎng)絡(luò),其中一些詞被標(biāo)記為正或負(fù).在這個網(wǎng)絡(luò)中,如果有關(guān)聯(lián),兩個詞是相連的.不同來源的信息來決定兩個詞是否相關(guān).例如,一個詞的同義詞都是語義相關(guān)的,連接語義相關(guān)詞背后的隱藏信息是單詞往往有相似的極性.現(xiàn)在假定一個隨機(jī)游走者沿著網(wǎng)絡(luò)從一個未標(biāo)記的詞w開始,隨機(jī)游走一直持續(xù)到游走者走到標(biāo)記的詞為止.如果詞w是正的,那么隨機(jī)游走擊中一個正詞的概率就更高;如果w是負(fù)的,那么隨機(jī)游走擊中負(fù)詞的概率就更高.因此,如果詞w極性為正,那么從w開始到正節(jié)點(diǎn)的隨機(jī)游走的平均時間應(yīng)該比從w開始到負(fù)節(jié)點(diǎn)的隨機(jī)游走的平均時間小得多.如果w沒有明確的極性,可以說它是中性的.
假設(shè)在詞關(guān)聯(lián)圖G中,從一個具有未知詞極性的節(jié)點(diǎn)i開始,在第一步后移動到節(jié)點(diǎn)j的概率為Pij.如果我們重復(fù)隨機(jī)游走N次,則可以將正/負(fù)詞的游走結(jié)束次數(shù)的百分比作為其正/負(fù)極性的指標(biāo).從w開始的隨機(jī)游走到達(dá)正/負(fù)節(jié)點(diǎn)的平均時間也是其極性的指標(biāo).
W是詞典中詞匯的集合,構(gòu)建一個圖G,其節(jié)點(diǎn)V都是W中的詞匯,邊E是對應(yīng)詞匯間的相關(guān)性.通過歸一化節(jié)點(diǎn)i之外的邊的權(quán)重,定義從節(jié)點(diǎn)i到節(jié)點(diǎn)j的轉(zhuǎn)移概率P[18]:
(1)
式中,k代表與i相鄰的所有節(jié)點(diǎn),P代表在第t步的節(jié)點(diǎn)i到第t+1步的節(jié)點(diǎn)j的轉(zhuǎn)移概率.注意到,權(quán)重Wij的矩陣是對稱的,而轉(zhuǎn)移概率矩陣P由于節(jié)點(diǎn)出度歸一化,不一定是對稱的.
把首次達(dá)到目標(biāo)節(jié)點(diǎn)所用的時間h(i|k)定義為隨機(jī)游走者第一次進(jìn)入狀態(tài)節(jié)點(diǎn)k所用的步數(shù)平均數(shù)[19],初始i≠k.G=(V,E)是具有V個頂點(diǎn),E條邊的圖,頂點(diǎn)集S是V的子集,S∈V,在圖G中第i點(diǎn)開始游走,i不屬于S.因此,第一次到達(dá)目標(biāo)節(jié)點(diǎn)所用時間h(i|S)可以形式化描述為:

(2)
其中,Pij是i到j(luò)點(diǎn)的轉(zhuǎn)移概率,h(j|S)表示節(jié)點(diǎn)j第一次到達(dá)目標(biāo)節(jié)點(diǎn)S所用的時間.
3.2 粗糙集基礎(chǔ)理論
粗糙集是一種有效的數(shù)學(xué)工具,用于處理數(shù)據(jù)的不完整和不確定的信息,是由波蘭科學(xué)家Pawlak[20]在1982年提出.使用粗糙集時,數(shù)據(jù)必須是離散的,但實(shí)際上決策表的大多數(shù)屬性是連續(xù)的,這一特性也大大限制了粗糙集的使用范圍,因此,連續(xù)的屬性應(yīng)該被替換為有限的語義變量,這就是連續(xù)屬性的離散化處理.在離散化過程中,為使屬性可以滿足粗糙集理論對屬性約簡和規(guī)則歸納的需求,需要依賴不同的離散化方法,如區(qū)域知識離散化、等距離散化、等頻離散化等.
定義1.(信息集合系統(tǒng))一個信息集合系統(tǒng)可以用一個四元組表示:IS=
1)U為研究對象的非空有限集合,即論域.
2)A為屬性的非空有限集合,即屬性集.
3)V=∑a∈AVa為屬性A的值域,其中Va為屬性a∈A的值域.
4)f:U×A→V為信息函數(shù),表示對每一個x∈U,a∈A,f(x,a)∈Va.
如果A中的屬性表示為分類的結(jié)果,則信息系統(tǒng)IS被定義為DT=(U,C∪D,V,F(xiàn)),其中A=C∪D,C∩D=φ,C為條件屬性集,D為決策屬性集,該信息系統(tǒng)也被稱為決策表.
定義2.(不可分辨關(guān)系)給予決策表DT=(U,C∪D,V,F(xiàn)),對于任意屬性集B?C∪D,則B的不可分辨關(guān)系IND(B)定義為[21]:
IND(B)={(x,y)∈U×U:?a∈B(f(x,a)=f(y,a))}
(3)
不可分辨關(guān)系IND(B)把論域U劃分為相互不連接的子集,即等價類.IND(B)的所有等價類的集合記為U/IND(B),簡記為U/B.U/B也可稱之為IND(B)對論域U的劃分,對任意X?U,X/B={E∩X:E∈U/B∧E∩X≠?}稱為IND(B)對X的劃分.對任意x∈U,使得[x]B表示為IND(B)中包含x的等價類.
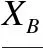

(4)
定義4.(正域)給予決策表DT=(U,C∪D,V,F(xiàn)),對于任意屬性集B?C∪D,稱POSB(D)為D的B正域.其所有對象為論域U的子集,使得U/D能準(zhǔn)確劃分來自屬性B的集合,其中[22]:
(5)

(6)
定義5.(約簡)給予決策表DT=(U,C∪D,V,F(xiàn)),B?C∪D,a∈B,若IND(B)=IND(B-{a}),則a為B中冗余的,否則稱a為B中必要的.若任一a∈B都為B中必要的,且IND(C∪D)=IND(V),則稱B為V的一個約簡[23].
定義6.(相對決策約簡) 給予決策表D=(U,C,D),B?C,a∈B,若B為D中獨(dú)立的,且POSB(D)=POSC(D),則稱B為C的一個D相對決策約簡.
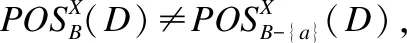

由于Pawlak的粗糙集模型更適合于處理含有離散屬性的數(shù)據(jù),所以在粗糙集中,連續(xù)屬性的離散化應(yīng)當(dāng)作為數(shù)據(jù)的預(yù)處理步驟.因此,連續(xù)屬性離散化是粗糙集中的一個重要工作.目前的離散化方法主要分為兩種,一種是在有監(jiān)督和無監(jiān)督框架內(nèi)的算法,一種是基于單變量和多變量的算法.
有監(jiān)督算法通過考慮分類信息進(jìn)行離散屬性,如NB算法.在NB算法中,通過構(gòu)造切割點(diǎn)對所有屬性進(jìn)行排序.例如,連續(xù)屬性v的屬性值為r0,…,rn,決策類d(r0),…,d(rn),則v中的屬性切割點(diǎn)Ca=(ri+ri+1)/2,其中d(ri)≠d(ri+1),0≤i≤n-1.無監(jiān)督算法則不考慮分類信息,其效果沒有有監(jiān)督算法好,如EF(Entropy-Feature)算法[24].
單變量算法在一個決策表中一次只考慮一個獨(dú)立的條件屬性,多變量算法則是同時考慮幾個條件屬性,通常情況下,多變量算法是考慮所有屬性在內(nèi)的.目前多數(shù)離散化算法都是單變量的,沒有考慮決策表中多依賴關(guān)系,因此會有丟失正確分類信息的風(fēng)險.傳統(tǒng)的連續(xù)屬性離散化方法一般分為4步:
Step1.對連續(xù)屬性值按照某種規(guī)則進(jìn)行排序.
Step2.初步確定連續(xù)屬性的切割點(diǎn)劃分.
Step3.按照某種給定的標(biāo)準(zhǔn)繼續(xù)劃分切割點(diǎn) 或合并切割點(diǎn).
Step4.如果Step 3得到判定標(biāo)準(zhǔn)的終止條件,則終止整個連續(xù)屬性離散化過程,否則繼續(xù)Step 3執(zhí)行.
4 基于隨機(jī)游走模型的情感詞極性計算
對于隨機(jī)游走模型在情感詞極性判別上的應(yīng)用,最重要的是需要構(gòu)建詞的圖框架,將數(shù)據(jù)映射成隨機(jī)游走圖,在圖框架中加入詞間的相關(guān)關(guān)系,進(jìn)而得到對未知詞極性的判別.其中,在進(jìn)行詞性判別前,需要對文本進(jìn)行特征選擇,以得到候選特征詞.在此基礎(chǔ)上,本文提出了基于擴(kuò)展隨機(jī)游走模型的情感詞極性判別算法,通過同義詞詞典構(gòu)建詞關(guān)聯(lián)圖,加入未知極性詞,計算隨機(jī)游走轉(zhuǎn)移概率,進(jìn)而預(yù)測未知單詞極性.
4.1 特征選擇
在文本分類中,特征詞及其類別傾向于服從CHI分布(Chi-squared Distribution),高CHI值意味著較高的特征分類能力,CHI值計算公式如下[25]:
(7)
其中N代表訓(xùn)練集大小;A代表屬于c類并且包含單詞t的文本數(shù)量;B代表不屬于c類并且不包含單詞t的文本數(shù)量;C代表屬于c類但不包含單、詞t的文本數(shù)量;D代表不屬于c類并且不包含單詞t的文本數(shù)量.
盡管CHI在文本分類中有著較好的表現(xiàn),但仍有一些缺陷存在.首先,高頻詞的出現(xiàn)會導(dǎo)致高CHI值,但是它并不一定有較高的區(qū)分能力.其次,有些單詞在較少的文本中頻繁出現(xiàn),有著很好的區(qū)分能力,但CHI值偏低,導(dǎo)致被低估.通過對原始CHI記錄日志的處理,能有效降低高CHI值.改進(jìn)的CHI計算公式如下[26]:
(8)
其中,A+B代表包含單詞t的文本數(shù),N代表文本總數(shù).如果t在所有類別中都出現(xiàn)并且頻率很高,則其CHI值接近于0,因此可以篩選出來不具備特征屬性的高頻詞.
4.2 詞匯情感極性判別
基于隨機(jī)游走模型的描述以及對游走狀態(tài)的預(yù)測,本文提出基于擴(kuò)展隨機(jī)游走模型的情感詞極性判別算法.首先構(gòu)建一個詞匯關(guān)聯(lián)圖,并在圖中定義隨機(jī)游走.令S+和S-分別表示已經(jīng)標(biāo)記為正或負(fù)的目標(biāo)詞的兩組頂點(diǎn).
對于任何給定的詞w,如前所述迭代地計算兩組Tn的h(w|S+)和h(w|S-). 然后將兩次Tn之間的比例用作給定字的正/負(fù)值的標(biāo)準(zhǔn).該方法可以很容易地從雙向分類(即正或負(fù))擴(kuò)展到三向分類(正,負(fù)或中性).通過設(shè)置正和負(fù)Tn比例的閾值λ,并且只有當(dāng)兩組Tn有明顯差異時才將單詞分為正或負(fù),否則將其分類為中性.圖的構(gòu)建采用哈工大社會計算與信息檢索研究中心提供的同義詞詞林(擴(kuò)展版),分別以Pos(w)、Neg(w)和Neu(w)來表示正、負(fù)和中性詞,算法如下:
算法 1.基于擴(kuò)展隨機(jī)游走模型的情感詞極性判別算法(EDEW)
輸入:詞關(guān)聯(lián)圖G(V,E);
輸出:詞情感極性Sentiment(w).
1 給定原始詞節(jié)點(diǎn)w,w∈V;
2while(Pos(w)←φorNeg(w)←φ)
3 從w出發(fā),隨機(jī)k個rw;
4ifrw→Pos(w)then
5E[h(w|S+)]←h*(w|S+);
6endif;
7elseifrw→Neg(w)then
8E[h(w|S-)]←h*(w|S-);
9endelse;
10endwhile;
11 設(shè)置擴(kuò)展參數(shù)λ(0<λ<1);
12ifh*(w|S+)≤λh*(w|S-)then
13Sentiment(w)←Pos(w);
14endif;
15elseifh*(w|S-)≤λh*(w|S+)then
16Sentiment(w)←Neg(w);
17endelse;
18else
19Sentiment(w)←Neu(w);
20endelse
在算法1中,結(jié)合詞關(guān)聯(lián)圖,得到最終詞匯情感極性.在1中,V表示詞關(guān)聯(lián)圖中節(jié)點(diǎn),w表示原始詞節(jié)點(diǎn);在3中,k表示隨機(jī)游走次數(shù),rw表示隨機(jī)游走的散列個數(shù);在45中表示如果其中一個游走散列到達(dá)目標(biāo)節(jié)點(diǎn)Pos(w),則游走結(jié)束,得到h(w|S+)的目標(biāo)期望值h*(w|S+).
在二分類情況下,每個詞匯極性必須為正或負(fù),如果h*(w|S+)大于h*(w|S-),則該原始詞匯極性判定為負(fù),否則判定為正.這可以通過在算法1中設(shè)置擴(kuò)展參數(shù)λ=1來實(shí)現(xiàn).
由于計算轉(zhuǎn)移概率P時,需要?dú)w一化節(jié)點(diǎn)之外邊的權(quán)重W(0 (9) 其中,Pij表示從節(jié)點(diǎn)i到節(jié)點(diǎn)j歸一化后的游走權(quán)重值,Wkmin表示K次游走權(quán)重調(diào)整中的最小值,Wkmax表示K次游走權(quán)重調(diào)整中的最大值. 在文本情感分類中,候選屬性集決定待分類的文本維度,通過特征選擇及情感詞極性判定,得到較低維度的文本,使得屬性集更具有代表性.候選屬性集的獲取步驟如下: Step1.對訓(xùn)練文本進(jìn)行分詞. Step2.根據(jù)式(8),計算詞匯CHI值,篩選詞征,得到候選特征集. Step3.通過EWPDA算法,得到候選特征集的情感極性權(quán)重,結(jié)合詞匯特征,進(jìn)而構(gòu)成候選屬性集. 通過上述3個步驟,得到候選屬性集,由于在計算情感極性前,進(jìn)行了文本的特征選擇,所以得到的文本維度有了一定程度的約簡,降低了詞匯圖計算的時間復(fù)雜度. 文本決策表[27]也叫作文本判定表,它可以把復(fù)雜的邏輯關(guān)系和多種條件組合的情況表達(dá)的比較明確,由于它邏輯結(jié)構(gòu)的嚴(yán)格性,可用于對文本屬性類別進(jìn)行判定.在文本情感分類中,常常將單個詞匯作為分類特征用以構(gòu)造文本表示向量,而情感詞匯對分類的貢獻(xiàn)要高于普通詞匯.因此,我們用來建立一種帶有特征情感詞匯極性的文本表示模型. 表1 文本情感決策表Table 1 Decision table for text sentiment 形式化該模型,一個文本Doci被表示為在一組屬性(F1,P1),(F2,P2),…,(Fn,Pn)下的取值所構(gòu)成的向量(wi1,…,wij,…,win),其中屬性(Fj,Pj)由特征Fj和其詞匯情感極性權(quán)重Pj組成,wij表示文本Doci在特征Fj下的權(quán)重,在表1中,“D”列表示文本的情感傾向類別,取“正”或者“反”. 為了克服傳統(tǒng)離散化方法排序規(guī)則的復(fù)雜度問題,本文對傳統(tǒng)的離散化方法做出了改進(jìn),通過隨機(jī)游走模型中對游走邊的權(quán)重劃分,得到每個詞的游走權(quán)重,對于每個游走權(quán)重,結(jié)合候選特征詞,從而得候選屬性集C.第j個候選屬性表示為(Fj,Pj),結(jié)合不可分辨關(guān)系的定義,進(jìn)而得到等價類的劃分U/IND(B).為解決傳統(tǒng)離散化方法中切割點(diǎn)選取過多導(dǎo)致的數(shù)據(jù)冗余問題,本文提出基于情感詞極性權(quán)重序的屬性離散化算法,算法可以有效減少切割點(diǎn)數(shù)量,得到最優(yōu)的離散化決策表. 對于決策表DT=(U,C∪D,V,F(xiàn)),其屬性B?C,hi∈B,則IND(h)在論域U中劃分的等價類表示為U/{hi}. 算法 2.等價類計算 輸入:DT=(U,C∪D,V,F(xiàn)),B?C, U={x1,…,xn}; 輸出:B對應(yīng)對象集U的劃分U/B. 1 對對象集U進(jìn)行排序; 2t←1,k←1,B1←{x1}; 3fori←2 tondo ifxi和xk對于B中的每個屬性具有相同值; Bt←Bt∪{xi}; endif; else t←t+1; B←{xi}; k←i; endelse; endfor; 4U/B←Bt 算法3.基于情感詞極性權(quán)重序的屬性離散化算法(ADPWS) 輸入:決策表DT=(U,C∪D,V,F(xiàn)), U={x1,…,xn},C={h1,…,hm}, B?C; 輸出:決策表DT*=(U*,C*∪D*,V*,F(xiàn)*). 1T={X1,…,X|T|},Xi?U,1≤i≤|T|,h是需要離散化的屬性,j←1;t←|T|;count←0; 2whilej 3low←Max({f(x,a):x∈Xj}); 4high←Min({f(x,a):x∈Xj+1}); 6 通過算法2計算Xj/(C-{h}),Xj+1/(C-{h})和(Xj∪Xj+1)/(C-{h}); 8count←count+1; 9Ycoount←Xj∪Xj+1; 10 在T中用Ycount取代Xj和Xj+1,j←j+2; 11ifj=tthen 12count←count+1,Ycount←Xj; 13 在T中用Ycount取代Xj; 14endif; 15else 16 獲取屬性切割點(diǎn)c=(low+high)/2, 17P←P∪{c}; 18count←count+1,Ycount←Xj; 19 在T中用Ycount取代Xj,把T分為兩個子集 20T1={Y1,…,Ycount}和T2={Xj+1,…,Xt}; 21ifcount>1orj+1 22 通過算法2計算U/{hi}={X1,…,Xq},并得到離散化屬性hi; 23endif; 24endelse; 25endwhile; 26 返回離散化決策表DT* 在算法3中,結(jié)合等價類計算算法,最終得到離散化決策表DT*.在1中,T={X1,…,X|T|}為屬性h當(dāng)前區(qū)間集合;在3和4中,通過相鄰區(qū)間的最大值和最小值,進(jìn)而得到切割點(diǎn)的劃分c=(low+high)/2;通過5可以計算6中的正域,即基于(C-{h})的分類劃分.在7中判斷基于(C-{h})劃分下Xj,Xj+1的正域之和是否與Xj∪Xj+1相等. 在算法3中,若用m,n分別表示C和U的基數(shù),在最壞情況下,1的算法時間復(fù)雜度為O(m×nlog2n),則整個算法的時間復(fù)雜度為O(m2×nlog2n). 粗糙集理論包含了對信息系統(tǒng)的約簡,通過去除冗余信息,完成對規(guī)則的提取,實(shí)現(xiàn)在沒有任何先驗(yàn)知識基礎(chǔ)上的系統(tǒng)分類.在連續(xù)屬性離散化的過程中,也包含了對決策表的約簡,通過選擇切割點(diǎn)并且合并相鄰間隔區(qū)間,得到?jīng)Q策表中條件屬性的約簡.通過離散化后的決策表可以獲得知識系統(tǒng)中的隱含數(shù)據(jù),即決策規(guī)則,以此增加對新對象匹配的可能性.一般地,在文本數(shù)據(jù)處理過程中,不可避免的會出現(xiàn)“維數(shù)災(zāi)難”問題,在文本向量空間中,維數(shù)災(zāi)難問題就轉(zhuǎn)化為了高維特征空間的線性劃分問題,其維數(shù)的增加就會導(dǎo)致數(shù)據(jù)稀疏,從而引出屬性值匹配困難,這也是本節(jié)需要解決的問題. 本節(jié)提出了基于粗糙決策置信度的文本情感類別判定算法,通過分類文本中的條件屬性及其游走權(quán)重值,找出文本在訓(xùn)練集中的等價類,并計算其決策類的置信度,然后計算在屬性特征及相對應(yīng)文本位置下的權(quán)重,構(gòu)造在決策類下的隸屬度函數(shù),得到最終的文本情感類別判定.通過計算在待分類文本中每個屬性的隸屬度,從而避免了多屬性值的匹配困難問題和其所引發(fā)的數(shù)據(jù)稀疏問題. 定義7.(粗糙決策隸屬度)給予決策表DT=(U,C,D),其中B?C,j∈B,x∈U,其中屬性均為符號值屬性,j*為屬性j下的一個條件屬性,Cd為一個決策類,Cd={x∈U|C(x)=d},則 (10) (11) 其中,稱μcd為文本在決策類d下的粗糙決策置信度.情感極性權(quán)重Pj已經(jīng)歸一化,wij≠0,μcd(U)越接近于1,則表明其隸屬于決策類Cd的可信程度越高. 算法4.基于粗糙決策置信度的文本類別判定算法(TCRDC) 輸入:決策表DT*=(U*,C*,D*),待分類文本 U*=(U1,U2…,Un); 輸出:文本類別集合CPOS,CNEG. 1CPOS,CNEG←?,i=1; 2foreachU∈U*do 3ifi≠nthen 4 通過公式(14)計算μcd(Ui)的值; 5i=i+1; 6C(U)=μcPOS(Ui); 7CPOS=CPOS∪argmax{μcPOS(Ui)}; 8endif; 9elseifC(U)=μcNEG(Ui); 10CNEG=CNEG∪argmax{μcNEG(Ui)}; 12endfor 在待分類文本U中,CPOS和CNEG分別表示正反兩種情感類別,由μcd(U)得到的正反兩類文本分別為: (12) 其中: CPOS={x∈U|C(x)=POS} (13) 通過計算文檔的置信度,從而得到其隸屬于正反兩類文本的最大值,就是對于正反兩類文本的最大置信度的分類. 實(shí)驗(yàn)數(shù)據(jù)采用第6屆中文傾向性分析評測語料及第3屆自然語言處理與中文計算會議評測語料,記作COAE2014及NLPCC2014,在COAE2014中提取其中對食品飲料的評論文本400篇,其中正面文本200篇,負(fù)面文本200篇;在NLPCC2014中提取其中對音樂及電影的評論400篇,其中正面文本200篇,負(fù)面文本200篇,總計共800篇文本語料.由于評論中人群主要涉及對于食品飲料使用及電影觀看后的評價,都是作為普通消費(fèi)者人群,因此具有一定的代表性.使用其中600篇語料作為訓(xùn)練數(shù)據(jù)集,剩余200篇作為測試數(shù)據(jù)集.通過分詞工具對所有文本進(jìn)行分詞及詞性標(biāo)注,并采用人工方式對文本情感類別進(jìn)行標(biāo)注,情感文本數(shù)據(jù)集如表2所示. 表2 情感文本數(shù)據(jù)集Table 2 Emotional text dataset 通過第3.1節(jié)介紹的方法后獲取候選文本屬性集,由于選取較少特征詞會損失一定的實(shí)驗(yàn)精度,選取過多特征詞雖不會對結(jié)果造成直接影響,但會造成數(shù)據(jù)冗余,提高算法的時間復(fù)雜度.王素格等[28]提出一種面向非平衡文本情感分類的TSF特征選擇方法,通過在COAE2014選取的圖書評論數(shù)據(jù)集,顯式組合正相關(guān)和負(fù)相關(guān)特征,去考量特征的平衡性用以表達(dá)文本信息.本文綜合文本數(shù)量及文本平衡性,為使特征詞的選擇能更好代表實(shí)驗(yàn)結(jié)果,因此在600篇訓(xùn)練數(shù)據(jù)集里,選取候選特征詞700個,里面包括了積極詞匯特征數(shù)350個,消極詞匯特征數(shù)350個,部分詞匯特征如表3所示. 表3 情感詞匯示例Table 3 Examples of emotional words 自旋模型(Spin)、標(biāo)簽傳播方法(Label Propagation Algorithm,LP)都是針對情感詞的詞匯極性判別方法,Spin模型通過計算文本的近似概率函數(shù)去優(yōu)化被選參數(shù),只需少量種子詞就可高精度定義語義傾向,但該方法需要手動標(biāo)注種子詞,在數(shù)據(jù)規(guī)模較大的情況下時間復(fù)雜度過高;LP方法是一種基于圖的半監(jiān)督學(xué)習(xí)方法,其基本思路是用已標(biāo)記節(jié)點(diǎn)的文本標(biāo)簽去預(yù)測未標(biāo)記節(jié)點(diǎn)的文本標(biāo)簽,但該方法缺少對文本標(biāo)簽信息的驗(yàn)證;而本文提出的RW方法可以通過隨機(jī)游走選取種子詞,并且對種子詞進(jìn)行十折交叉驗(yàn)證,來驗(yàn)證其準(zhǔn)確率.本文把訓(xùn)練數(shù)據(jù)集分為10份,每份含有特征詞匯80個,通過7次十折交叉驗(yàn)證比較RW與Spin模型,LP方法的準(zhǔn)確率,如圖2所示. 圖2 十折交叉驗(yàn)證準(zhǔn)確率對比Fig.2 Accuracy rate of ten fold cross-validation 由圖2可以得出,不考慮參數(shù)影響,隨機(jī)游走算法通過十折交叉驗(yàn)證準(zhǔn)確率要優(yōu)于Spin模型和LP方法.在7次十折交叉驗(yàn)證中,由于分組數(shù)據(jù)的不同,其準(zhǔn)確率也會隨之波動,但每種算法波動趨勢趨于一致,RW算法與其余兩組數(shù)據(jù)對比中,在數(shù)據(jù)的耐受性方面表現(xiàn)較好. 在實(shí)驗(yàn)中,稱原始詞匯節(jié)點(diǎn)為種子詞,本文設(shè)計了針對不同方法的5組10種子詞實(shí)驗(yàn),通過求取不同種子詞的加權(quán)平均值,將RW算法與Spin模型、LP方法、SO-PMI方法的情感詞匯極性判別的準(zhǔn)確率進(jìn)行對比.其中,SO-PMI方法是將PMI引入計算詞語的情感傾向中,從而達(dá)到捕獲情感詞的目的,在本文中SO-PMI的計算公式為: (14) 其中,w是具有未知極性的單詞,hitsw,pos是在搜索查詢給定單詞時返回的命中次數(shù)和提取的所有正種子詞.hitspos是搜索所有正種子詞時的命中數(shù),類似地定義了hitsw,neg和hitsneg.對比實(shí)驗(yàn)結(jié)果如圖3所示. 圖3 不同方法中10種子詞結(jié)果對比 Fig.3 Comparison of ten seeds vocabulary in different methods 在選取種子詞進(jìn)行驗(yàn)證的過程中,考慮到隨著SO-PMI方法中數(shù)據(jù)量的增加,其準(zhǔn)確率會有所上升,在選取SO-PMI方法中的數(shù)據(jù)時的數(shù)據(jù)量為1×107,屬于比較平均的數(shù)據(jù)量,而更高的數(shù)據(jù)量對結(jié)果對比影響較小.LP方法效果較差,隨機(jī)游走方法稍優(yōu)于Spin方法.總體來看,在對比這幾種經(jīng)典構(gòu)圖算法中,隨機(jī)游走算法為結(jié)果較優(yōu)的算法. 雖然隨機(jī)游走在上述結(jié)果表現(xiàn)較好,但是未考慮參數(shù)對算法準(zhǔn)確率的影響,由于隨機(jī)游走模型中樣本K值和最大游走Step對最終情感極性判別的準(zhǔn)確率影響較大,并且最后特征的權(quán)重與步數(shù)有很大的相關(guān)關(guān)系,所以下面要討論K值及最大游走Step對隨機(jī)游走的準(zhǔn)確率的影響,如圖4所示.由于不同類別特征在訓(xùn)練時對λ的敏感度不同,實(shí)驗(yàn)通過不斷調(diào)整擴(kuò)展參數(shù)λ,在0.1-1.0之間進(jìn)行測試,在訓(xùn)練數(shù)據(jù)集中,選取λ=0.8能得到較為清晰的結(jié)果. 圖4 參數(shù)對準(zhǔn)確率的影響Fig.4 Influence of the parameters on the accuracy 從實(shí)驗(yàn)結(jié)果可以看出,不斷增加的Step與準(zhǔn)確率有一種先增后減的趨勢,而不斷增加的K值與準(zhǔn)確率成正比.在試驗(yàn)中設(shè)置初始Step為5,這是因?yàn)槿绻鸖tep小于5,則準(zhǔn)確率波動太大,使得結(jié)果缺少可信度.由于Step越少,則從種子詞節(jié)點(diǎn)搜尋到正確情感詞匯極性的概率越大,所以Step的增加,會導(dǎo)致尋找到正確情感詞極性的概率變小,而當(dāng)Step取15左右時,能得到較好的結(jié)果;而對于K值來說,由于最大散列數(shù)的增加,越大的K值使得能搜尋到正確結(jié)果的概率越大,實(shí)驗(yàn)結(jié)果也更加說明了Step及K值對準(zhǔn)確率的影響. 通過計算情感詞極性傾向強(qiáng)度值,結(jié)合公式(9)計算隨機(jī)游走權(quán)重百分比,對每個特征在文本中的權(quán)重予以賦值[29],賦權(quán)之后的文本決策表如表4所示. 表4 情感詞極性處理數(shù)據(jù)表示Table 4 Expression of emotion word processing data 表4中共有訓(xùn)練文本600篇,包含特征選擇及權(quán)重處理后得到的700個特征,包括“好產(chǎn)品、努力、問題、呵護(hù)、關(guān)懷、激進(jìn)、圓滑、諷刺、強(qiáng)化、……”得到的特征文本矩陣為600×700,每個特征詞的情感極性權(quán)重均為歸一化后的結(jié)果,每個特征詞在文本所占比重也為歸一化后的結(jié)果.其值越接近1,則特征在文本中所占的比重越大. 表5 離散化后的決策表Table 5 Decision table after discretization 如表5所示,當(dāng)特征在文本下權(quán)重值為0,使得離散化后的特征權(quán)重仍然為0.可以看出,算法3能夠保證文本決策表離散化后的分類能力仍能保持不變. 為了對比本方法的效果,將通過三個指標(biāo)進(jìn)行比對,一是切割點(diǎn)的數(shù)量(CU);二是離散化時間(TI);三是屬性壓縮比率(RI),與本方法對比的三種經(jīng)典方法是NB、ME、EF.具體結(jié)果如表6所示. 表6 離散化數(shù)據(jù)指標(biāo)對比Table 6 Data index comparison after discretization 為了在試驗(yàn)中排除由于硬件問題導(dǎo)致的數(shù)據(jù)不穩(wěn)定,統(tǒng)一機(jī)器參數(shù)信息(OS:Windows 7;CPU:Inter(R) Pentium(R) CPU of 2.10 GHz;Memory:4GB)并對每個算法的計算時間都進(jìn)行了5次驗(yàn)證,最終結(jié)果取平均值.可以看出,ADPWS算法在切割點(diǎn)數(shù)量和數(shù)據(jù)屬性的壓縮比率上都優(yōu)于其他方法,但在時間花費(fèi)上沒有EF算法效果好.由此可以得出,ADPWS方法在切割點(diǎn)選取和屬性壓縮方面效果較好,但在運(yùn)行時間上還有進(jìn)一步的改進(jìn)空間. 使用ADPWS算法對決策表DT進(jìn)行離散化后,得到離散化決策表DT*,離散化后的屬性為文本最終屬性,下一步通過粗糙決策置信度對測試集文本進(jìn)行表示,同時使用多種評價指標(biāo)對分類結(jié)果進(jìn)行對比,查準(zhǔn)率(P)、查全率(R)、F1值.同時,使用多種分類算法與粗糙決策置信度方法進(jìn)行對比,SVM、K近鄰(k-Nearest Neighbor,KNN)、NB、文獻(xiàn)[30]的粗糙隸屬度分類方法(P-B).其中,F(xiàn)1值是 (15) 公式中α取1時的結(jié)果,F(xiàn)1值是取P值和R值的加權(quán)調(diào)和平均,F(xiàn)1值越大,則說明實(shí)驗(yàn)的方法越有效.實(shí)驗(yàn)還通過分析正類文本和負(fù)類文本的P值、R值、F1值,來得到更全面的測試評價指標(biāo),實(shí)驗(yàn)結(jié)果如圖5所示. 圖5 不同分類方法結(jié)果對比Fig.5 Comparison of the classification results of different methods 由圖5可以看出,在多評價指標(biāo)下,本文所提出的方法均取得了較好的效果,在負(fù)類查準(zhǔn)率、正類F1值指標(biāo)下均優(yōu)于其它幾種方法,幾種評價指標(biāo)下相比較于P-B方法、KNN方法的正確率有所提升,正確率提升約1.85%,表明數(shù)據(jù)離散化后的屬性分類能力與原屬性相比并沒有丟失. 文本情感分類問題,一直是研究的熱點(diǎn),如何提高分類效率,減少分類過程中的數(shù)據(jù)維度,同時又不損失精度,這是本文所需要解決的主要問題.隨機(jī)游走模型多用于排序問題,本文推廣了隨機(jī)游走模型,將文本空間轉(zhuǎn)化為詞匯圖,提出了基于擴(kuò)展隨機(jī)游走模型的情感詞極性判別算法,有效判別情感詞極性,最終得到候選屬性集;通過對候選屬性集的處理,結(jié)合特征權(quán)重,構(gòu)建情感詞匯決策表,提出基于情感詞極性權(quán)重序的屬性離散化算法,得到離散化決策表;為把離散化后的屬性特征進(jìn)行表示,提出粗糙決策置信度模型,對文本進(jìn)行最終決策分類.實(shí)驗(yàn)對算法進(jìn)行了分析,均取得了較優(yōu)的效果,但有些步驟仍有改進(jìn)的空間,比如離散化算法中的時間復(fù)雜度問題,通過進(jìn)一步的優(yōu)化應(yīng)能得到理想的效果.由于每個步驟都有可能對實(shí)驗(yàn)的最終分類結(jié)果造成精度的損失,如何提取整合方法中的優(yōu)點(diǎn)以提高整體精度,這也是今后工作的一個要點(diǎn).4.3 獲取候選屬性及建立文本情感決策表

5 基于粗糙集的連續(xù)屬性離散化
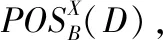

6 基于粗糙決策置信度的文本情感類別判定



11 end else;
CNEG={x∈U|C(x)=NEG}7 實(shí)驗(yàn)結(jié)果與分析
7.1 實(shí)驗(yàn)數(shù)據(jù)

7.2 文本情感詞極性判別

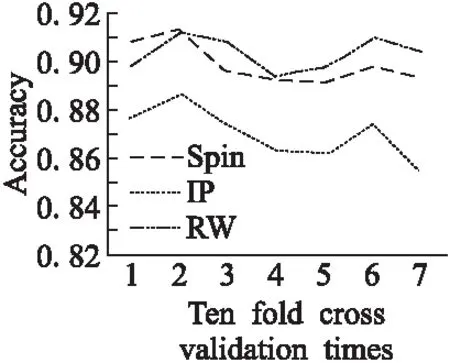


7.3 文本情感決策表離散化




7.4 文本情感類別判定

8 總 結(jié)
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56中華胰腺病雜志(2021年1期)2021-02-26 11:28:36山東醫(yī)藥(2020年34期)2020-12-09 01:22:24制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08中華胰腺病雜志(2019年4期)2019-08-29 08:52:20中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32電子制作(2018年18期)2018-11-14 01:48:06中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
