一種基于評論分析雙層圖的推薦方法
2019-06-06 05:46:34陳晉音陳一賢吳洋洋
小型微型計算機系統 2019年6期
陳晉音,陳一賢,林 翔,吳洋洋
(浙江工業大學 信息學院,杭州 310000)
1 引 言
隨著大數據技術的廣泛應用,如何有效利用大數據來提高人們的生活品質已經引起了越來越多的關注.然而,過大的數據量往往會超出處理者的處理能力,即信息超載問題.推薦方法是解決信息超載問題的一個很好的解決方案,它通過收集用戶的個性,習慣和偏好來生成相應的推薦信息.而傳統的推薦方法如協同過濾、非負矩陣分解等方法具有無法充分挖掘用戶或項目特征,受數據稀疏性影響大,當數據量增加時計算復雜度高等問題.
為了解決這些問題,許多學者提出了很多有效的方法.其中一個提高推薦準確度的方法是從評論數據中尋找更多的特征,而不是只使用用戶對項目的評分信息.Wang等人[1]使用改進的情感字典來計算每個評論的情感分數,將加權調整后的平均值和修改后的平均值結合,以此計算每個項目的分數.這種方法本質上是用情感得分代替用戶直接評分,忽略了評論中含有眾多的項目特征.考慮到傳統的基于矩陣分解的方法很難對用戶解釋矩陣分解得到的結果,Zhai等人[2]將語言主題模型與矩陣分解相結合,以發現用戶和項目的隱藏特征.Wang等人[3]使用基于特征的加權非負矩陣分解算法來查找每個特征的最具代表性的句子,以此來總結每個特征.
近年來基于圖結構的推薦系統受到越來越多的重視.在該模型中,用戶和項目被認為是二分圖中的節點,而它們間的交互信息被認為是連邊.在這種表示下,推薦問題被轉換為鏈路預測問題.最近,在用戶-項目二分網絡上已經出現了許多有效的推薦算法,例如物質擴散(MD)算法和熱傳導(HC)算法.MD算法[4]實質上是鄰居用戶在對象之間的資源重新分配方法.HC算法[5]像一個從項目到相鄰用戶并再次返回項目的熱傳導過程,它具有高度的多樣性,但是精度較低.
本文提出了一種基于評論分析雙層圖的個性化推薦算法.該算法使用雙層雙向網絡模型進行個性化推薦.本文的主要貢獻如下:
1)提出了一種無監督的評論挖掘方法,相比傳統的頻繁項Apriori算法,該方法借助部分特征列表和word2vec對頻繁名詞項進行刪減,具有更高的準確率和可擴展性.
2)提出了一種雙層雙向加權二分圖模型,該模型配合聚類算法增加了算法處理大數據的能力并降低了數據稀疏性對算法的影響,從而獲得更準確的推薦結果.
本文的其余部分的結構如下.第二節介紹了當下在評論挖掘、二分網絡投影方面的相關工作.第三節描述了基于評論分析雙層圖的個性化推薦方法.第四節使用Yelp數據集和Amazon數據集進行實驗,將本文的算法與其他推薦算法進行比較.第五節總結本文的工作.
2 相關工作
2.1 用戶評論挖掘
大多數評論挖掘工作的重心在特征提取與情感分析兩部分.做特征提取的先驅是 Hu等人[6],Hu等人使用Apriori算法提取評論中的頻繁項,然后修建頻繁項集來獲得產品特征并尋找距離特征最近的形容詞作為情感詞.之后大多數的特征提取工作都具有提取頻繁項的步驟,這種方法的基本假設是產品特征的出現頻率相較其他詞或短語將更高.還有一種尋找特征與情感詞的方法是使用依存關系分析,Khan 等人[7]羅列一些句法關系作為語言模板,提取評論句子中與模板相匹配的短語,以此作為特征或情感詞,Devasia等人[8]使用斯坦福依存關系分析工具提取句子中各個詞之間的語法關系,針對不同的語法關系來提取不同詞性的單詞.這兩種方法因為沒有判別尋找到的名詞或名詞短語是否是真正的特征項,所以實際效果一般.Sharma等人[9]創建特征列表來尋找電影評論,雖然能比較準確的找出評論中存在的特征,但因為列表并不能全部枚舉,所以仍然會有特征沒有被提取出來.
現有的情感分析方法主要可以分為基于詞典與基于機器學習兩種方法.基于機器學習的方法包括使用樸素貝葉斯,支持向量機,遞歸深度模型和最大熵等,它可以被用于特定領域的情感分析中.基于詞典的方法是指通過查詢字典獲取各個單詞的情感得分,以此來判斷句子傾向.Hu等人[6]選擇多個已知情感方向的形容詞生成種子列表,然后使用wordnet預測情感詞列表中所有單詞的情感方向.還有一些工作[9]借助SentiWordNet,得到每個單詞的情感得分,以此來判斷句子的情感傾向.由于借助情感詞典可以快速的得到單詞的情感得分,所以基于詞典的情感分析算法在多個領域都有良好的表現.但是因為單詞的情感得分受上下文關系影響,所以獨立考慮每個單詞的得分有其局限性.
2.2 基于二分圖結構的推薦系統
近年來,許多系統將用戶與項目間的關系建模為雙向網絡.Chang等人[10]應用監督學習的方法來預測維基百科二分網絡中的隱藏連邊.Zhang等人[11]將社區結構添加到用戶-項目關系中,并將原始算法與雙向網絡中檢測到的社區相結合,從而使建議更加個性化.Xia等人[12]提出了一種計算兩個不同節點之間的鏈接概率的方法.并且還提出了一些基于核函數的方法來用于雙向網絡鏈路預測.
物質擴散算法[4]的實質是一種鄰居對象之間的資源重新分配算法.基于物質擴散算法,Chen等人[13]在物質擴散模型中考慮項目間的相似性以提高準確率.Zeng等人[14]提出相似優先擴散機制,即加強或削弱與目標用戶相似的用戶的權重.Wang 等人[15]將相似性函數與二分網絡相結合,基于相似性網絡使得資源重分配過程更加個性化.
當下已經有很多研究工作已經證明基于聚類的推薦系統對于計算大規模數據集有效率高、擴展性強等特點[16].本文使用評論挖掘提取產品的多維特征,使用密度聚類提高處理大規模數據的能力以應對數據稀疏性對模型的影響,還提出了一種基于評分數據的不對稱加權方法并將之用于雙層雙向網絡模型,最后在雙層圖網絡中使用物質擴散算法以實現個性化推薦.
2.3 物質擴散算法
對于不加權的二分網絡,任意節點中的資源將平均分配給它的鄰居節點.圖1顯示了這種分配的具體過程.如圖1(a)所示,三個項目節點最初被賦予的權重分別為x,y和z.資源分配過程首先從項目到用戶然后重新分配回項目.在每一步之后資源的分配情況如圖1(b)和圖 1(c)所示.經過這兩個步驟之后,位于這三個項目節點中的最終資源分布用x′,y′ 和z′表示,其計算方法如公式(1)所示:
(1)
本文可以注意到公式(1)中的3×3矩陣有一個明顯的特點,即每一列中元素的總和為1,由于每個項目節點連接到不同的用戶節點,所以此矩陣是不對稱的.

圖1 二分網絡中資源分配過程Fig.1 Illustration of the resource-allocation process in bipartite network
對于一個二分圖網絡G(U,B,L),其中L為連邊集合,U={U1,U2,…,Um}和B={B1,B2,…,Bn}分別表示用戶和項目集合.設f(bi)表示物品節點bi的初始資源,lip是大小為n×m的分配矩陣,由連邊權重定義,k(bi)為分配矩陣lip的第i列元素的和.則經過第一步資源流動后,用戶節點up的資源大小為:
(2)
(3)
接下來資源從U流向B,最終物品節點bi的資源為:
(4)
或者寫做:
(5)
式中:
(6)
3 基于評論分析雙層圖結構的推薦
本文提出了一種基于評論分析雙層圖結構的推薦方法(RM-DGR),其主要步驟包括:
1)基于評論的文本分析結果和用戶-商品(user-item)簽到關系,構建用戶和商品的特征并分別進行密度聚類.
2)構建用戶簇和商品簇的雙層雙向二分圖網絡,在雙層圖上使用物質擴散算法實現個性化推薦.
該算法的框架圖2所示.首先對評論進行詞匯級情感分析,獲得各項目的特征向量,再根據簽到關系進行特征映射,獲得各用戶的特征向量,以此對項目和用戶分別進行密度聚類.之后使用用戶簇和項目簇構建二部圖網絡,在資源重新分配后,選中目標用戶簇和得分最高的K個項目簇再次構建二部圖網絡,完成個性化推薦.
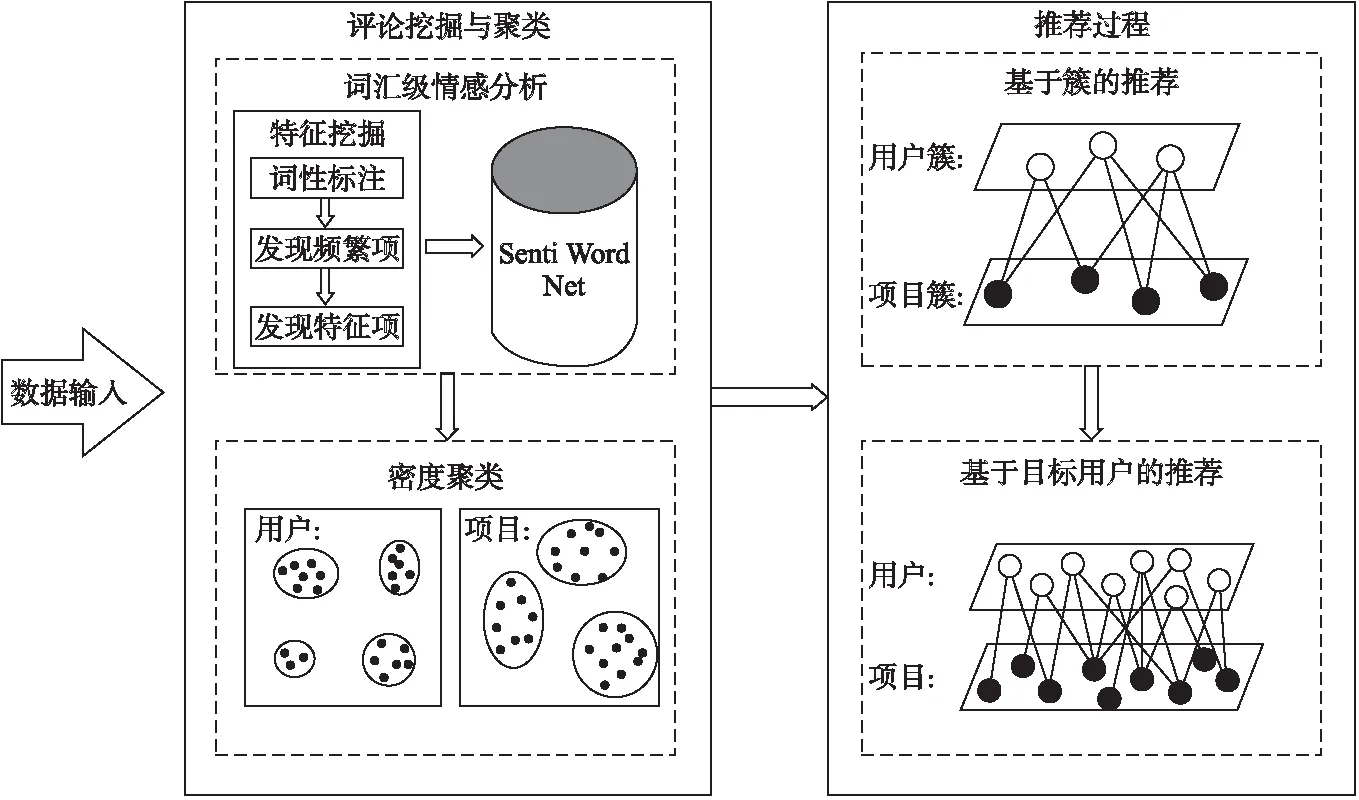
圖2 RM-DGR框架Fig.2 Framework of the RM-DGR
3.1 詞匯級情感分析
本節的目標是通過對評論進行情感分析構建項目的特征向量.注意到句子中的特征有隱式特征與顯式特征之分,但是在評論中隱式特征出現次數極少[9],是故在此本文只考慮顯式特征.本文中情感分析的流程可以分為以下五個主要步驟:提取頻繁項、創建特征列表、將頻繁項與列表中的特征相匹配、判斷評論中句子的情感方向、針對每個特征總結所有評論.
3.1.1 特征提取
首先我們對評論文件進行詞性標注并刪除停用詞,停用詞通常是冠詞、介詞、連詞,它們經常出現在文本中但卻沒有實際含義.這些停用詞會對特征提取造成干擾.由于產品的特征絕大多數是名詞或名詞短語并且出現得較為頻繁,因此本文提取評論中的頻繁名詞項作為候選特征.但是并不是所有頻繁名詞項都是真正的特征.為了刪除這種非特征的頻繁名詞項,本文創建包含少量特征的特征列表并與word2vec配合使用.例如對于餐廳,本文可以如表1所示的列表.
創建的特征列表并不必包括太多的真實特征,只包含少量即可,接下來使用word2vec[17]對特征列表進行擴充.首先使用word2vec將單詞轉化為向量,選擇余弦相似度來度量每一個名詞頻繁項與特征列表中單詞的相似度,然后挑選出相似度大于閾值的名詞頻繁項作為特征.需注意的是,因為word2vec產生的詞向量是基于文本的上下文關系,是故最終挑選出的特征未必都是名詞.
表1 特征列表
Table 1 List of features

聚類用特征特征食物food,vegetable,fruits,fried,eat,meat服務service,delivery,order,waiter環境environment,atmosphere,air,music,space
算法1.項目特征提取


過程(FC,S,θ,δ):
foreachsiinS
foreach wordinPOS tagging
ifword is noun
extract the noun word
endif
Count the number of times each noun word occurred
Extract noun words whose occurrence number greater thanθ
foreach frequent noun wordn
fi.extend(n)
break
endif
endfor
endfor
3.1.2 情感分析
情感分析的目的是根據評論句子中情感詞的情感傾向,判斷句子的傾向從而將評論句子進行分類.情感詞是指能夠體現評論者情感傾向的單詞.情感分析的方法有多種,本文中選用的方法是SentiWordNet,它在很多研究工作中被使用并且表現良好.
SentiWordNet是一個龐大的字典資源.它包含一個很大的文本文件,存有字典中每一個單詞的用法與得分.借助SentiWordNet,對于每個單詞的每種用法,本文都會得到與之相應的積極得分(PosScore)與消極得分(NegScore),將積極得分與消極得分相減,可以得到這種用法的得分.
Score=PosScore-NegScore
(7)
最終得分的取值在[-1,1]之間,大于0時該用法具有積極傾向,反之則具有消極傾向.
另外因為句子中表示情感傾向的詞大多是形容詞、副詞、動詞、名詞,所以本文提取句子中除了特征外的形容詞、副詞、動詞、名詞作為情感詞.在根據情感詞計算句子的情感得分前,還必須考慮否定詞的存在,例如以下句子:
“The food in the restaurant is not terrible”
在這個句子中not 和 terrible的得分均為負值,若是直接將句子中的所有情感詞得分相加作為句子的得分,那么結果將不再準確.所以在計算情感得分時必須考慮否定詞的存在.
本文中情感分析的步驟如下:
Step 1.尋找評論中含有特征的句子.
Step 2.對每個句子提取句子中除了特征外的形容詞、副詞、動詞、名詞作為情感詞.
Step 3.如果句子中含有否定詞,則標記否定詞之后距離否定詞最近的情感詞標記優先級為形容詞、副詞、動詞、名詞.若之后沒有情感詞,則向前尋找情感詞.
Step 4.使用SentiWordNet 得到每一個情感詞的得分,對于被標記的情感詞,它的最終得分為SentiWordNet得分的相反數.
Step 5.將句子中所有情感詞的得分和作為句子的得分.
3.1.3 評論總結
在總結所有評論前,需要構建每條評論的特征向量,假設有共有n個用于聚類用特征,則構建評論R的特征向量MR的算法如下:
算法2.構建評論特征向量


過程(S,F):
InitializeMRto zero vector;
foreachsiinS
Calculate the score of the sentencefs
Extract the characteristics of the sentencef
foreachfiinF
iffinfi
endif
endfor
endfor
returnMR
基于評論對不同特征的情感傾向,可以得到一個評論-特征矩陣,如表2所示.
表2 評論-特征矩陣
Table 2 Review-feature matrix

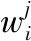
(8)
其中R為評價項目j的所有評論,m為其個數.
3.2 針對個性化推薦的雙層圖結構模型
3.2.1 距離度量
在構建雙層圖結構之前,我們首先要對用戶和項目分別進行聚類.考慮到簇的個數與形狀的不確定性,我們采用Rodriguez 等人[18]提出的密度聚類算法,該算法能夠自動確定聚類中心并在多個領域表現良好.

(9)
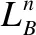
用戶間的相似性由他們間不同的條目數量決定:
dist(U1,U2)=num(s1-s2)
(10)
式中:
(11)
(12)
(13)

3.2.2 推薦過程
推薦過程分為兩部分:基于簇的個性化推薦和基于目標用戶的個性化推薦.首先本文根據聚類結果建立用戶簇與項目簇之間的第一層二分網絡,節點間的權重由用戶簇與項目簇之間的訪問記錄數定義.設P表示用戶簇節點,I表示項目簇節點.在這種情況下,對于公式(3)中的lip與ljp,計算方法為:
lIP=lPI=∑i∈I∑p∈Paip
(14)
式中:
(15)
之后通過公式(2)~公式(6)和公式(14)~公式(15),我們可以得到基于簇的個性化推薦結果.
本文通過構建第二層二分網絡來完成針對目標用戶的個性化推薦.第二層二分網絡使用目標用戶所在的用戶簇和上一層簇推薦中的資源最高的K個項目簇來構建.在第二個二分網絡中,每一個節點表示一個用戶或項目.考慮到用戶對項目的評分范圍為1~5,本文取3作為閾值來判斷用戶的情感取向從而得到兩個二分網絡,其一由積極連邊構成,另一個則由消極連邊構成.
在第二層二分網絡中,用戶p和項目i間權重定義為:
(16)
對于表示消極傾向的二分網絡,lip<0.通過這個二分網絡的個性化推薦可以表示用戶對每個項目的不喜歡程度.最后,將兩種二分網絡中各項目節點資源之差作為最終結果,從而得到最終推薦列表.
3.2.3 復雜度分析
對于密度聚類算法[18],計算n維數據的局部密度ρ,距離δ和劃分各數據點的時間復雜度均為O(n),所以聚類過程的時間復雜度為O(n).在雙層圖推薦過程中,因為第二層圖結構中節點數量遠大于第一層圖的節點數量,所以僅考慮第二層圖的時間復雜度.設目標用戶簇中的用戶數量為N′,項目簇中的項目數量為M′,則雙層圖推薦的時間復雜度是O(N′*M′).因為N′和M′遠小于用戶數N和項目數M,所以雙層圖結構有效地降低了MD算法的時間復雜度O(N*M).由于雙層圖推薦依舊需要存儲全部信息,所以它的存儲復雜度與MD算法相同,但是在第一層推薦后,我們可以刪除我們大量不需要的簽到信息,提前釋放大量存儲空間.
4 實驗結果與分析
4.1 數據集
實驗數據集是在第七屆Yelp數據競賽中使用的公共數據集.在本論文中,選擇簽到數量最多的三個州來測試本文的算法:拉斯維加斯,鳳凰城,斯科茨代爾,其中每個用戶至少含有5條訪問記錄.
除Yelp數據集外,我們還在Amazon數據集[19]上測試我們的算法.在實驗中我們所選數據集為Amazon零食數據集,其中每個用戶至少含有10條訪問記錄.
過濾后各數據集的數據分布如表3所示.
實驗中本文依據訪問時間8:2將數據集劃分為訓練集和測試集.實驗環境為PC i7-4710MQ和8 GBs RAM.
表3 各數據集的數據分布
Table 3 Data volume of the selected datasets
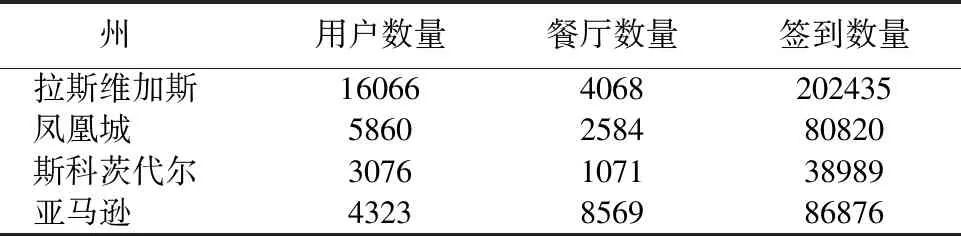
州 用戶數量餐廳數量簽到數量拉斯維加斯160664068202435鳳凰城5860258480820斯科茨代爾3076107138989亞馬遜4323856986876
4.2 評價指標與方法
本文使用準確率、召回率、F值分析推薦結果.
(17)
(18)
(19)

在實驗中使用的對比算法為IBCF 算法,UBCF 算法,NMF 算法和PMF 算法.除此之外,本文還將原算法與選擇性刪減后的原算法進行比較,以驗證聚類和評論挖掘對算法的影響.接下來本文簡單介紹這些對照算法.
DGR-Ⅰ:該算法直接使用所有的用戶與項目構建二分網絡.即通過單層網絡直接完成個性化推薦.
DGR-Ⅱ:該算法項目間相似度距離的度量方法與用戶相似,都是使用項目的標簽信息進行度量.
4.3 結果與分析
實驗中Word2vec訓練數據為部分維基百科數據集,其中單詞數量為15857306個,詞匯數量是98331個.在實驗中本文選擇頻繁項閾值θ為評論個數的1%,相似度閾值δ為0.6,使用的特征列表如表4與表5所示.
表4 Yelp數據集使用的特征列表
Table 4 List of features used in Yelp datasets

聚類用特征特征食物food,vegetable,fruits,cook,eat,bite,meat,entrees服務service,delivery,order,waiter,waitress,parking環境environment,atmosphere,air,spot,music,fountains
表5 Amazon數據集使用的特征列表
Table 5 List of features used in Amazon dataset

聚類用特征特征Snacktaste,flavor,product,food,fried,spicy,snack,meatPriceprice,cost,worthHealthhealth,weight,calorie,nutrient,caffeine,vitamin
最終挑選出的頻繁項與特征信息如表6所示.我們可以看出使用頻繁項集挖掘算法和word2vec刪除了大量名詞項并且將原本只包含少量特征的特征列表大幅擴展.
表7展示了RM-DGR與DGR-Ⅰ算法的運行時間,表明了雙層圖結構有效提高了MD算法的效率.
圖3-圖6展示了對于不同推薦長度k,各項指標的變化曲線.從圖中可以看出RM-DGR的總體表現明顯優于其他算法,尤其在拉斯維加斯區域內,各項指標優勢較為明顯.這表明評論挖掘與密度聚類的加入非常有效提高了算法在處理大規模數據時的準確率.對于Amazon數據集,由于該數據集中用戶極少對同一家商戶有訪問記錄,所以所有算法在該數據集上的表現效果均有所下降,但是通過對比我們仍能發現相較于其他算法,RM-DGR仍有明顯優勢.是故我們認為在推薦算法中加入評論挖掘、聚類機制確實有助于提高推薦效果.在鳳凰城區域中,我們可以看到RM-DGR算法的準確率與F值兩項指標對于其他算法有一定優勢,但在召回率一項上略低于對照算法DGR-I算法.這可能是因為在鳳凰城區域數據中,項目個數較少的用戶所簽到的餐廳可能比較特殊,它們歸屬于較小的餐廳簇.如此一來,這些餐廳在簇推薦過程中被刪去,因為這些用戶的簽到餐廳個數少,所以這對召回率的影響較大,是故會出現準確率高于對照算法,而召回率卻略低的情況.
表6 各數據集的名詞項、頻繁項與特征個數
Table 6 Number of frequent items and feature

州 名詞數量頻繁項數量特征數量拉斯維加斯83260375159鳳凰城47147394163斯科茨代爾36584349147Amazon40731369167

圖3 拉斯維加斯區域的實驗結果Fig.3 Evaluation results comparing with other algorithms in Las Vegas

圖4 鳳凰城區域的實驗結果Fig.4 Evaluation results comparing with other algorithms in Phoenix

圖5 斯科茨代爾區域的實驗結果Fig.5 Evaluation results comparing with other algorithms in Scottsdale

圖6 亞馬遜零食數據集的實驗結果Fig.6 Evaluation results of controlled experiment in Amazon
表7 雙層圖結構對MD算法的影響(s)
Table 7 Effect of double-layer graph on MD algorithm(s)

州RM-DGRDGR-Ⅰ拉斯維加斯63.688.7鳳凰城13.625.4斯科茨代爾4.713.7Amazon43.466.2
相比對照算法僅使用評分一項特征,本文使用評論挖掘分析多種特征可以更好地對項目進行建模.在圖推薦前加入密度聚類,一方面使得圖中節點數大量減少,另一方面經過簇推薦也過濾了大量明顯不相干的項目,是故本文在各數據上可以取得更好的推薦效果.
5 總 結
本文提出了一種基于評論分析雙層圖的推薦方法.我們的目的是克服傳統的個性化推薦算法的缺點:這些算法具有較高的時間復雜度,僅僅使用評分信息,不能有效地解決數據稀疏性等問題.我們的算法步驟如下:首先,通過詞匯級情感分析和基于簽到關系的映射,得到用戶和項目的特征信息,然后分別對用戶和項目進行聚類.接下來,根據聚類結果,采用基于雙圖結構推薦算法,對用戶進行個性化推薦.在未來,我們的目標是尋找將文本信息嵌入圖結構的更合適的方法并在模型中考慮社交關系,以此得到更合理的個性化推薦結果.并且,我們也想建立一個更完整的動態推薦系統.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
