關于命名實體識別的生成式對抗網絡的研究
2019-06-06 05:46:34馮建周馬祥聰劉亞坤宋沙沙
小型微型計算機系統 2019年6期
關鍵詞:模型
馮建周,馬祥聰,劉亞坤,宋沙沙
(燕山大學 信息科學與工程學院,河北 秦皇島 066004) (燕山大學 河北省軟件工程重點實驗室,河北 秦皇島 066004)
1 引 言
互聯網的快速發展使網絡信息呈爆發式增長,同時網絡信息的形式也變得越來越多樣化,這給用戶有效利用網絡信息資源帶來了很大的不便.面對網絡信息爆發式增長帶來的挑戰,信息抽取技術逐漸發展起來.信息抽取是指從大規模的無結構文本中提取出用戶真正感興趣的信息,并以結構化或半結構化的形式存儲或輸出[1].
信息抽取技術起源于20世紀70年代早期對自然語言處理(Natural Language Processing,NLP)的研究,而后從20世紀80年代中期開始蓬勃發展起來,這得益于消息理解會議(Message Understanding Conference,MUC)1的推動.繼MUC之后,自動內容抽取(Automatic Content Extraction,ACE)2評測會議也對信息抽取技術的發展起著關鍵性的作用.
根據ACE的劃分,信息抽取主要包括4個方面的研究:命名實體識別、指代消解、實體關系抽取和事件抽取.其中,命名實體識別(Named Entity Recognition,NER)是這些任務中最關鍵的部分.這是因為命名實體識別是NLP領域中一些復雜任務(如機器翻譯、問答系統、信息檢索等)的基礎.同時命名實體識別又是實體關系抽取的基礎.例如,在機器翻譯中,3Stanford Open Information Extraction.https://nlp.stanford.edu/software/openie.html.
4http://blog.heuritech.com/2016/01/20/attention-mechanism/
只有將目標句子中的實體準確地識別出來并知道實體之間的語義關系才能夠準確的翻譯目標句子.在問答系統中,系統只有從用戶的提問中準確地識別出實體類型以及實體之間的關系才能更好地為用戶解答.
命名實體識別任務最初是在MUC-6上被提出的,它的主要任務是識別出自然語言文本中的各種短語并加以歸類.它有兩個關鍵的任務:一是要識別出文本中是否有命名實體,二是要判斷出命名實體具體所指的目標類型.命名實體的領域相關性很強;數量巨大,收錄非常困難,沒有通用化的字典可供查詢;表達形式多樣,可能采用縮寫等其他變化的方式,影響判別準確率等等,這些都給命名實體識別任務增加了難度.
2 相關工作
命名實體識別是NLP領域中一些復雜任務的基礎,因此一直以來都是NLP領域中的研究熱點.現有的命名實體識別研究方法有基于規則的方法,基于傳統機器學習的方法(又叫統計的方法),以及近年來流行的基于深度學習的方法.
基于規則的方法[2]由于手工構造規則,系統能夠達到較好的性能,但構造規則時太依賴于專業領域知識,費時費力且系統的可移植性較差.
基于機器學習的方法中,命名實體識別被看作是序列標注問題,傳統的機器學習方法有許多適用于序列標注問題的模型.Borthwick等人[3]利用最大熵馬爾科夫模型和額外知識集提高了NER的準確性.Lafferty等人[4]提出條件隨機場用于模式識別任務.Zhou等人[5]提出使用四種不同特征來提高隱馬爾可夫模型在NER任務上的性能.McCallum A[6]提出使用更豐富,更高階的馬爾科夫模型的特征感應法和維特比法用于NER任務.除了基于有監督的機器學習方法,機器學習的半監督和無監督的學習方法也可以用于NER任務.在NER方面,主要的半監督學習方法是“bootstrapping”方法[7,8].李麗雙[9]利用半監督SVM模型與CRF模型進行組合的方法,實現了將多分類器組合與字典匹配運用到命名實體識別中,提高了試驗效果.此外,還有一些無監督的開放信息抽取系統,如華盛頓大學的TxtRunner[10]、 ReVerb[11]等系統,斯坦福大學的Stanford OpenIE3等是開放信息抽取中的典型工作.
近年來,隨著深度學習算法的普及,很多學者開始將深度學習算法應用在NER領域,而且已經取得了卓越的效果.Athavale V[12]提出的BiLSTM模型采用了雙向長短時記憶(Bi-Long-Short-Term Memory,BiLSTM)網絡,通過BiLSTM網絡將上下文結合起來,進行NER的訓練,取得了良好的效果.Huang Z[13]和Lample G[14]采用BiLSTM與CRF(Conditional random field algorithm)結合的方法,進行命名實體識別的實驗,不但能充分利用上下文的信息,又能考慮到句子的語義規則信息,從而取得了比單純BiLSTM更好的效果.Chiu等人[15]使用BiLSTM+CNN模型來獲取更多的特征,在輸入層,將詞向量和詞特征進行結合,然后利用CNN進行特征抽取,最后,通過BiLSTM進行訓練,從而提高了效果.Rei等人[16]在RNN-CRF模型結構基礎上,重點改進了詞向量與字符向量的拼接,采用CRF作為輸出層,并以預測的標簽作為條件,使用注意力機制(Attention)4將原始的字符向量和詞向量拼接改進成權重求和,使用兩層傳統神經網絡隱層來學習Attention的權值,這樣就使得模型可以動態地利用詞向量和字符向量信息.深度學習的方法在NER領域雖然取得了很好的效果,但是仍然存在很大的改進空間,比如超參數的選擇仍然依賴經驗,優化過程過早收斂等情況.
2014年,Ian Goodfellow[17]提出了生成式對抗網絡,即GAN(Generative Adversarial Networks)模型.最初,GAN模型是用于生成圖像這樣的連續數據的,并不能直接用來生成離散數據.而當離散數據做微小改變時,在映射空間中也許根本就沒有對應意義的序列,所以當GAN處理NLP這種離散數據的任務時,容易出現梯度消失的問題.此外,GAN無法判斷目前生成的某一部分序列的質量,因為它只能給生成的完整序列打分.
但是,這些問題近兩年已經有所突破.于瀾濤等人[18]提出的SeqGAN(Sequence Generative Adversarial Nets)模型,通過執行強化學習中的策略梯度解決了原始GAN在序列標注問題中無法為生成器提供梯度的問題.SeqGAN中的獎勵信號仍來自判別器對完整序列的判斷,只不過它使用蒙特卡洛搜索返回中間狀態的動作步驟來實現為部分序列打分.Arjovsky M[19]提出了WGAN模型來解決NLP領域的梯度消失問題.該論文給出了GAN訓練效果不穩定的原因,并利用wassertein距離進行了解決,同時解決了GAN的模式崩潰的問題.Mirza M[20]提出的CGAN模型針對NLP領域以往的GAN不能生成特定屬性的問題,進行了相關改進,它將特定屬性融入到生成器和判別器當中,從而解決了GAN不能生成特定屬性的缺點.Gulrajani I[21]在WGAN的基礎之上提出了WGAN-GP,通過采用lipschitz連續性限制的方法,解決了訓練梯度消失或者梯度爆炸的問題,同時,提高了收斂速度.
相關研究工作表明,GAN可以在NLP任務上有杰出表現.但在NER方面,GAN還沒有相應的研究.因此,本文將CGAN和WGAN-GP兩者的優點結合,提出一個適合于命名實體識別任務的條件Wasserstein生成式對抗網絡(Conditional Wasserstein Generative Adversarial Nets,CWGAN).
3 基于CWGAN的命名實體識別
命名實體識別任務一般被看做序列標注問題.因此,本文將未標注的句子作為條件,構建CWGAN模型,完成命名實體識別任務.在對抗學習中本文將命名實體識別任務描述如下:給定一個未標注的由一系列單詞組成的句子X={x1,x2,…,xn},并以此作為CWGAN模型的條件,生成器模型通過條件生成句子的標注序列,判別器模型給生成的標注序列打分,并為生成器模型提供反饋指導生成器模型訓練,最終訓練好的生成器模型能夠生成質量較高的命名實體標簽Y={y1,y2,…,yn},其中xi代表單詞,yi代表其對應的生成標簽.
3.1 用于命名實體識別的CWGAN模型的設計思路
本小節介紹用于命名實體識別的CWGAN模型的設計思路.如圖1所示,模型分為兩部分:生成器模型(G)和判別器模型(D).
生成器模型(G)定義了在給定句子的情況下生成該句子對應的命名實體標簽序列的策略.本文的生成器模型使用的是一個BiLSTM網絡.將句子序列X輸入到生成器中(句子序列是未標注的),將未標注的句子作為條件信息,用于生成標注,通過BiLSTM網絡得到每個單詞的上下文信息表示,通過全連接層以及softmax層得到每個單詞在各個命名實體標簽上的概率.判別器模型(D)使用的是一個BiLSTM網絡.將句子序列X及其對應標注標簽序列L(專家預先標注的標簽)連接作為正實例輸入到D,同時,將句子序列X與G生成的標簽序列連接起來作為負實例輸入到BiLSTM網絡,以專家標注的標簽為參照,為生成的標簽序列的打分,將每個詞的生成標簽得分進行求和,返回句子中每個詞的標簽的總得分,最后句子的得分是句子中每個詞的得分的均值.由于得分均值是通過每個詞和標注組合的得分加和而來,所以在反向傳導過程中,D能針對G每一步的輸出進行反饋.D給G的反饋是針對于句子中每個詞的,這樣做相對于直接對整個標簽序列和句子序列進行判別,返回的信息更多,更有助于G的優化.
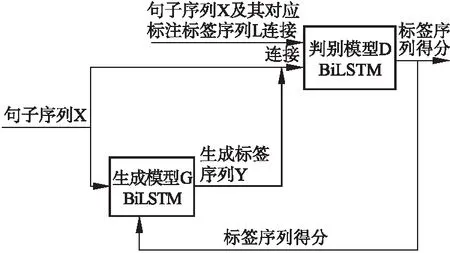
圖1 CWGAN整體框架Fig.1 Whole frame diagram CWGAN
3.2 輸入表示
NLP任務中通常要把文本轉換成分布式表示,本文采用詞向量的方式來表示文本中的單詞,使用詞向量的目的是將句子中的每個單詞映射成K維實值向量.例如,給定一個句子X={x1,x2,…,xn},通過映射詞向量矩陣E∈R|V|×dw將每個單詞xi表示為dw維實值向量,V是詞表的大小(詞向量訓練語料中的詞的數目).
3.3 生成器模型

如圖2所示,得到單詞的上下文表示后,通過一個全連接層并將結果傳送給softmax層得到每個單詞在各類標簽上的條件概率,計算方法如下:
(1)
公式(1)表示在參數θ下,單詞xi的標簽歸為y的概率,其中,nm是標簽種類個數,o是全連接層后的輸出,其計算方法如下:
(2)
其中,W′代表全連接層的權重矩陣,hi代表單詞xi的上下文信息,b′為偏置向量.
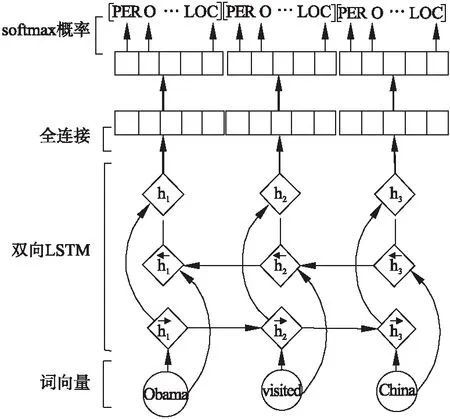
圖2 生成器的BiLSTM處理過程Fig.2 Bidirectional LSTM processing of generator
3.4 判別器模型
本文提出的CWGAN模型中的判別器模型也是BiLSTM網絡.使用BiLSTM,可以為每個單詞的標簽單獨打分.由于句子的長度是不固定的,通過填充將句子轉換為具有固定長度T的序列,該長度是生成器模型的輸出設置的最大長度.
判別器的BiLSTM的輸入有兩種,一種是句子序列x1,…,xT和對應的標注標簽序列l1,…,lT的連接[X;L],另一種句子序列x1,…,xT和生成器生成的標簽序列y1,…,yT的連接[X;Y](兩個句子序列相同,標簽不同).其中X,L,Y分別為句子序列矩陣X1:T和生成標簽矩陣Y1:T以及標注標簽矩陣序列L1:T,它們分別建立為:
X1:T=x1;x2;…;xT
Y1:T=y1;y2;…;yT
L1:T=l1;l2;…;lT
其中,xt,yt,lt是k維詞向量表示,分號是連接運算符,且在[X;L]和[X;Y]中為行連接,在X1:T、Y1:T以及L1:T中為列連接,即,若標簽序列維度為n1,則連接后的[X;L]和[X;Y]的維度為T×(dw+n1).
(3)
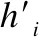

圖3 判別器的BiLSTM處理過程Fig.3 Bidirectional LSTM processing of discriminator
3.5 優化目標函數
本文提出的CWGAN模型使用WGAN-GP模型的梯度更新方式,即通過拉近真實樣本分布和生成樣本分布之間的Wasserstein距離(又叫Earth-Mover,EM距離)來優化目標函數.Wasserstein距離的公式定義如下所示:
(4)
其中,Pr代表真實樣本的分布,Pg代表生成器生成樣本的分布,∏(Pr,Pg)代表真實樣本分布Pr和生成樣本分布Pg組合起來的所有可能的聯合分布的集合.從每一個可能的聯合分布γ中采樣得到一個真實樣本x和一個生成樣本y,即(x,y)~γ,算出這對樣本的距離‖x-y‖,然后就可以計算該聯合分布γ下樣本對距離的期望E(x,y)~γ[‖x-y‖].在所有可能的聯合分布中能夠對這個期望值取到的下界(公式(5)等號右邊),即定義為Wasserstein距離.通過拉近真實樣本和生成樣本的Wasserstein距離來拉近兩個樣本的分布,其好處是在兩個樣本分布無重疊或重疊部分可忽略的情況下,Wasserstein距離仍然可以提供有意義的梯度.
在對抗訓練的過程中,判別器的作用是為生成器生成的數據(分布)打分,生成器則根據判別器給出的分數做出微小的調整,然后再將新生成的數據交給判別器打分.所以當輸入判別器的樣本稍微改變,判別器不能給出與上次樣本差距太大的分數,即需要限制判別器打分的變動幅度.對于判別器的這種限制可以通過施加Lipschitz限制實現,如下:
‖f(x1)-f(x2)‖≤K|x1-x2|
(5)
其中K是一個大于等于0的常數,x1和x2是樣本空間內的元素.本文的CWGAN模型利用梯度懲罰來實現Lipschitz限制,即額外設置一個損失項:
[‖xD(x)‖p-K]2
(6)
為了使損失項的期望能夠進行采樣,只在生成樣本集區域、真實樣本集中區域以及夾在它們中間的區域進行采樣.加上以上損失項后判別器損失函數定義如下:
L(D)=-Ex~Pr[D(x)]+Ex~Pg[D(x)]+

(7)

(8)
判別器期望拉大兩個分布之間的Wasserstein距離,生成器希望拉近兩個分布之間的Wasserstein距離.
生成器的損失函數定義如下:
L(G)=Ex~Pg[D(x)]+cost
(9)
其中,cost代表真實樣本與生成樣本的交叉熵,計算公式如下:
cost=-[D((l′)log(D(y′))+(1-D(l′))log(1-D(y′))]
(10)
其中,l′代表句子序列和對應的標注標簽序列的連接[X;L],y′代表句子序列和生成器生成的標簽序列的連接[X;Y].
本模型采用Adam優化算法來優化判別器和生成器的損失函數.為了防止生成器訓練時發生梯度爆炸,使用裁剪(clip)的方法限制每次更新后梯度的范圍,一旦生成器的梯度超過了設定閾值就對其進行“裁剪”,使其保持在設定閾值范圍內.
4 實驗結果及分析
為了證明本文提出的CWGAN模型的優越性,本節設置了幾組對比實驗,通過比較CWGAN模型和BiLSTM模型在不同數據集上實現NER任務時的性能,以及不同設置下CWGAN模型在NER任務中的性能來說明CWGAN模型的效果.另外需要說明的是,本文的CWGAN算法只與基礎的BiLSTM模型進行了比較,因為上節提到的BiLSTM+CRF模型、CNN+BiLSTM模型,以及CNN+Attention+BiLSTM模型都是在BiLSTM基礎模型上增加新的模塊從而改善了性能,本文算法同樣可以在輸入端和輸出端增加相應的模塊來改善性能,這里就不再一一進行比較.
4.1 數據集及評估標準
本節實驗使用的數據集是CoNLL-2002中的西班牙文數據集和CoNLL-2003中的英文數據集.
CoNLL-2002中NER任務數據集包含了西班牙文數據集和荷蘭文數據集.西班牙文數據集是由西班牙的EFE通訊社提供的新聞組成.該數據集標記有四種不同的命名實體類型,分別為:人名(PERSON),地名(LOCATION),組織機構名(ORGANIZATION)以及其他命名實體(MISC),即不屬于以上三種實體中的任何一種.該數據集包含了標準的訓練集,驗證集和測試集.如表1所示.
5https://en.wikipedia.org/wiki/Word2vec
6https://nlp.stanford.edu/projects/glove/
表1 CoNLL-2002 NER任務西班牙文數據集規模表
Table 1 CoNLL-2002 NER Task Spanish dataset scale table

人名地名組織機構名其他單詞數量訓練集82246804123825385273037驗證集208113213066109954837測試集13691409250489653049
CoNLL-2003 NER任務數據集由路透社RCV1語料庫的新聞專線組成.它標有四種不同類別的命名實體類型:人名(PERSON),地名(LOCATION),組織機構名(ORGANIZATION)以及其他命名實體(MISC).該數據集包括標準的訓練集,驗證集和測試集.如表2所示.
表2 CoNLL-2003 NER任務英文數據集規模表
Table 2 CoNLL-2003 NER Task English dataset scale table

人名地名組織機構名其他單詞數量訓練集111358297100274593204568驗證集315020942092126851597測試集27771925249691846667
采用NLP任務中常用的評測指標F-1測度值對實驗結果進行評價分析,F-1測度值是對準確率和召回率的一種平均加權,它能夠體現整體測試效果.它的計算方法為:
(11)
其中,P代表準確率,P=正確識別的命名實體個數/識別的命名實體總數×100%,R代表召回率,R=正確識別的命名實體個數/數據集中命名實體總數×100%.
4.2 實驗設置
1)預訓練的詞向量.與隨機初始化的詞向量相比,使用預訓練的詞向量可以取得更好的效果.
本實驗使用了兩種預訓練的詞向量:Word2vec5和GloVe6.GloVe與Word2vec都是基于詞共現結構以無監督的方式學習單詞的向量表示.不同的是,GloVe是對“詞-詞”矩陣進行分解從而得到詞表示的方法,屬于基于矩陣的分布表示,它相比Word2vec充分考慮了詞的共現情況.
由于兩者都具有比較優秀的準確性,并且這兩種詞向量是當前使用比較廣泛的兩種詞向量,所以,此次實驗采用了這兩種方法生成的向量作為實驗的輸入.本實驗中使用300維的實值向量表示單詞的詞向量,word2vec和GloVe訓練詞向量時使用的參數如表3所示.
表3 詞向量訓練參數表
Table 3 Word vector training parameters table

詞向量工具詞向量維度窗口大小學習率采樣閾值Word2vec30030.011e-4GloVe30030.01—
2)參數設置.本文在訓練時使用三折交叉驗證法調整模型.用網格搜索法來確定最優參數,并指定參數空間子集為:窗口大小w∈{1,2,3…7},過濾器數量n∈{64,128,256,512},生成器梯度裁剪閾值∈{8,9,10,11,12},隨機梯度下降學習率λ∈{0.1,0.01,0.001,0.0001},使用 Adam優化器更新參數.本文實驗使用的參數如表4所示.
表4 實驗參數表
Table 4 Table of experimental parameters

詞嵌入維度隱藏層神經元個數窗口大小批大小丟棄率學習率梯度閾值dw=300n=256w=3B=16p=0.5λ=0.000110
4.3 實驗對比及分析
本文提出的CWGAN模型與BiLSTM模型[12]的性能進行了對比.表5是BiLSTM與CWGAN的基于西班牙文數據集的對比實驗的結果.表6是BiLSTM、CWGAN的基于英文數據集的對比實驗結果.CWGAN代表生成器和判別器都使用BiLSTM.由于西班牙用于預訓練的數據不充足,導致實驗效果不是很好,但是,實驗的對比效果并沒有因此受到影響.
表5 基于CoNLL-2002的CWGAN模型效果表
Table 5 CWGAN Model base CoNLL-2002 effect table
從表5中可以看出,在對于基于CoNLL-2002的實驗上,無論是在驗證集Test_a上還是測試集Test_b上,CWGAN模型的F1值都比BiLSTM模型的F1值有所提高.在驗證集Test_a上,CWGAN模型比BiLSTM模型提高0.49%;在測試集Test_b上,CWGAN模型比BiLSTM模型提高1.20%.這說明CWGAN模型將生成對抗式網絡用于命名實體識別任務是成功的,判別器能夠指導生成器學習.
表6 基于CoNLL-2003的CWGAN模型效果表
Table 6 CWGAN Model effect base CoNLL-2003 table

模型Test_a_F1Test_b_F1收斂所需的迭代次數BiLSTM92.73%88.01%60CWGAN(BiLSTM-BiLSTM)93.02%88.32%40
從表6中可以看出,對于基于CoNLL-2003數據集的實驗上,無論是在驗證集Test_a上還是測試集Test_b上,CWGAN模型的F1值比BiLSTM模型的F1值有所提高.在驗證集Test_a上,CWGAN模型比BiLSTM模型提高0.29%;在測試集Test_b上,CWGAN模型比BiLSTM模型提高0.21%.這說明CWGAN模型將生成對抗式網絡用于命名實體識別任務是成功的,判別器能夠指導生成器學習.
從收斂迭代次數方面比較,CWGAN模型的效果也優于BiLSTM模型,CWGAN模型在迭代40次上下時達到收斂,而BiLSTM模型則需要迭代60次上下.
4.4 預訓練詞向量和dropout的影響
為了驗證預訓練的詞向量以及dropout對于命名實體識別模型的影響,本小節做了以下對比實驗.“dropout”是指在訓練的時候,按一定的概率p來對權重層的參數進行隨機采樣.
表7 基于CoNLL-2003數據集的不同設置下的CWGAN
模型效果對比表
Table 7 CWGAN model effect comparison table under different
Settings base CoNLL-2003 database

模型Test_a_F1Test_b_F1CWGAN84.17%80.45%CWGAN+dropout85.81%81.38%CWGAN+pretrain(word2vec)91.85%86.99%CWGAN+pretrain(GloVe)73.60%69.44%CWGAN+pretrain(word2vec)+dropout93.02%88.32%CWGAN+pretrain(GloVe)+dropout74.62%70.67%
表7顯示了使用預訓練的詞向量和使用隨機初始化的詞向量的結果對比,表中“dropout”代表訓練時設置丟棄率,“pretrain(word2vec)”代表使用word2vec工具預訓練的詞向量,“pretrain(GloVe)”代表使用GloVe工具預訓練的詞向量,CWGAN和CWGAN+dropout代表使用隨機初始化的詞向量.結果顯示,使用預訓練的word2vec詞向量比使用隨機初始化的詞向量F1值提高了6.99%到7.16%,說明與隨機初始化的詞向量相比,使用預訓練的word2vec詞向量可以獲得更好的效果.而使用GloVe詞向量F1值反而比隨機初始化的詞向量效果更差了,因此建議預訓練詞向量時使用word2vec詞向量.表7中可以看出,在訓練時使用“dropout”比不使用F1值提高了1.17%到1.02%,說明在訓練時使用“dropout”可以提高模型的性能,這是因為“dropout”在訓練階段可以阻止神經元的共適應.
5 結 論
本文提出了一個生成式對抗網絡模型(CWGAN)用于命名實體識別任務.該網絡模型借鑒CGAN以文本描述為條件的圖像概率分布的思想,來完成命名實體識別以句子序列為條件獲得標注序列概率分布的任務.另外,該模型采用WGAN-GP中的梯度懲罰來保證梯度在后向傳播的過程中保持平穩.實驗證明,本文提出的CWGAN模型在命名實體識別任務中是有效的,在對抗學習的過程中判別器可以指導生成器進一步提高自己的性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
