Spark框架中RDD緩存替換策略優化
2019-06-06 05:46:36陳天宇張龍信李肯立周立前
小型微型計算機系統 2019年6期
陳天宇,張龍信,李肯立,周立前
1(湖南工業大學 計算機學院,湖南 株洲 412007)2(湖南大學 信息科學與工程學院,長沙 410082)
1 引 言
隨著大數據與云計算的興起,基于集群的大規模數據處理已成為各大IT公司的解決方案[1].許多高科技企業使用的大數據分析技術具有迭代特性,包括使用圖計算來進行PageRank或社交網絡分析,使用機器學習進行聚類或回歸分析等.這些應用共同的特點是其數據需要多次迭代處理直到滿足收斂條件或者結束條件,于此同時,大量的數據需要在迭代中重用[2].
目前比較有影響力的大數據處理框架有Hadoop、Spark、Storm等[3],它們均源于Google早期提出的MapReduce思想.Hadoop在進行迭代計算時速度比較慢,當待處理的數據規模越來越大時,Hadoop通過分布式文件系統讀寫的性能瓶頸愈發明顯,而Spark正是在這種背景下應運而生.Spark針對迭代計算中需要被多次使用的工作數據集進行優化,引入了內存集群計算的概念,將數據集緩存在內存中,以減少訪問延遲.用戶可以調整Spark的存儲策略,Spark是基于彈性分布數據集(RDD)的內存計算,數據集可從記錄的信息來源重構.RDD被表示為一個對象,并且可以在文件中創建[4].
由于Spark的存儲策略可由用戶選擇定制,Spark整個計算過程有不同的存儲策略可供選擇[5].用戶可以根據經驗選擇緩存到內存或是物理硬盤中,由此產生的計算時間不盡相同.當緩存的是無用數據時,該數據會占用內存空間,系統性能將降低.如果緩存了錯誤的數據還會導致內存溢出等后果,甚至可能將隨后重用的中間結果忽略,造成計算時間延長.通常情況下,計算機內存空間是有限的,無法保證每個計算節點有充裕的內存空間緩存數據.
目前的存儲替換策略中,先入先出(FIFO)策略主要關注創建時間,最近最少使用(LRU)策略更側重于命中歷史訪問次數,然而這些經典的算法沒有考慮分片的計算成本問題[6].現有的研究大多數基于此類算法改進,其中部分改進算法諸如GreedyDual[7]、GD-Wheel[8]均考慮了訪問歷史和計算成本,但在一個作業中待處理任務的執行邏輯在Spark中是已知的,對訪問RDD歷史次數進行優化的緩存策略效果不明顯.類似的研究還有不考慮RDD的訪問歷史次數的LCS[9]算法,以及考慮計算成本次數加權的WR[10]算法.本文針對內存占用率與RDD替換時的權重,考慮了分片的歷史訪問次數和計算成本等因素對權值的影響,并提出緩存權重替換算法(CWS).
本文第一部分介紹了Spark的應用背景;第二部分闡述了Spark的相關概念;第三部分介紹相關的預備知識;第四部分詳細介紹本文提出的算法;第五部分通過實驗驗證了本文提出的算法的性能;最后對本文工作進行了總結.
2 Spark相關概念
2.1 彈性分布式數據集
彈性分布式數據集的提出,是對不適合非循環數據流模型應用的一種改進.非循環數據流模型是從物理存儲中加載記錄,將操作記錄傳入有向無環圖(DAG)后寫回物理存儲介質中[11].計算機集群系統通過調用這個數據流圖來完成調度工作和故障恢復.當作業在多個并行操作時需要重用工作數據集(例如迭代算法、交互式數據挖掘[12]),系統會將數據輸出到物理存儲介質,計算機集群每次重用時都需要重新加載,從而導致開銷較大.
RDD是Spark框架的核心抽象,作為Spark的用戶,可以把RDD看成獨立數據分片的集合.RDD具有以下特征:
1) RDD能夠記錄其血統(Lineage)信息,RDD能夠記錄其本身是怎樣通過其他數據集來產生或者轉換的.在某個RDD分片丟失時,能夠根據Lineage信息恢復該分片,而不必重新計算所有分片.
2) RDD中的數據分片存儲在集群中的節點上,可并行操作每個分片中的數據.RDD的每個分片上都有函數,通過函數調用可操作RDD的分片轉換.
3) Spark在任務調度時,盡可能將計算任務分配到數據塊所存儲位置,即數據本地化.
RDD自身是只讀數據集,僅能通過對其它的RDD執行轉換操作(例如map,join和groupBy)創建.傳統的分布式共享內存尋找丟失的分片需要checkpoint和rollback操作,開銷較大,而RDD的內存共享方式既能保證低開銷,又能保證容錯性.RDD通過轉換操作轉換成不同的RDD后,可通過lineage來計算出相應的RDD分片.RDD所有分片都分布在集群系統的各節點上,默認情況下的RDD在需要用到時都會被重新計算.
2.2 Spark中的作業調度與緩存機制
在Spark中,RDD被表示為對象,RDD的操作僅包含轉換操作和行為操作.RDD在轉換操作執行完后才可能執行行為操作,此時DAGScheduler為每個執行中的任務生成一個DAG(有向無環圖),隨后將任務上傳至集群.圖1是Spark中的作業調度模型,本文對于選擇算法部分的優化基于DAG將選擇RDD分片的緩存至內存.
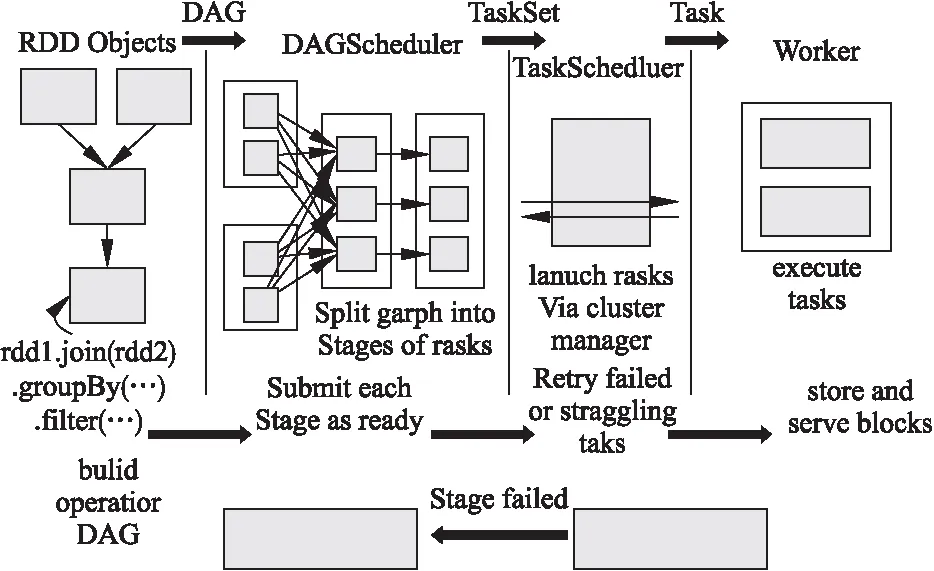
圖1 Spark中的任務調度Fig.1 Task scheduling in the Spark
圖2展示了RDD在集群中的緩存,RDD2是由RDD1經過Transformation操作轉換得到的,RDD2在接下來的運行過程中有可能被再次使用,所以Spark主動緩存RDD2.假設RDD2中包含3個分片21、P22和P23,集群中有3個節點,緩存時P21、P22和P23分別存儲在節點1、節點2以及節點3的內存中.
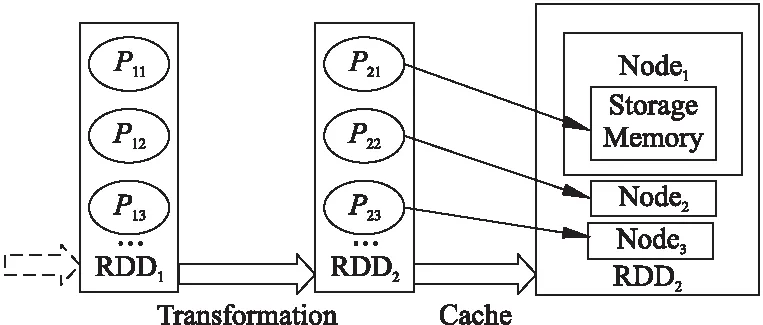
圖2 集群中的RDD緩存Fig.2 RDD cache in a cluster
在Spark默認的緩存機制中,當RDD在內存中完成計算后,可通過CacheManager來獲取結果.RDD分片由CacheManager來緩存,而CacheManager中的操作取決于BlockManager提供的API.用戶通過BlockManager來決定分片將從內存或者磁盤中獲取,而MemoryStore則確定分片是否緩存至內存中.當分片占滿內存之后,默認情況下系統將用LRU算法來選擇要被替換的分片[13].傳統的LRU算法忽略了RDD分片的大小和計算成本,無法確定所選擇的分片是否將被重用.本文的工作正是針對RDD分片的選擇和替換策略進行優化.
3 預備知識
3.1 問題定義
Spark在任務執行過程中需要用到某個RDD時,并非立即對該RDD進行計算,任務調度器會根據該RDD的lineage關系構建一個DAG圖.生成DAG后,Spark會將任務劃分為不同的stage,執行后得到目標的RDD.在本文中用表示分片,Pij表示第i個RDD的第j個分片.
當剩余的緩存不足以存放新的RDD時,Spark默認的緩存策略會替換最近最少使用的RDD.在一個作業中RDDn所包含的分片Pnm被推出緩存后,若在后續的作業中被重用,該分片會被再次計算,采用默認的算法會產生很多不必要的開銷,我們需要解決默認情況下僅考慮最近最少使用的逐出帶來的計算效率差異.
在計算RDD的過程中,任務的stage通過DAG來劃分,本文提出的替換策略在執行過程中將stage中滿足替換條件的分片進行替換.
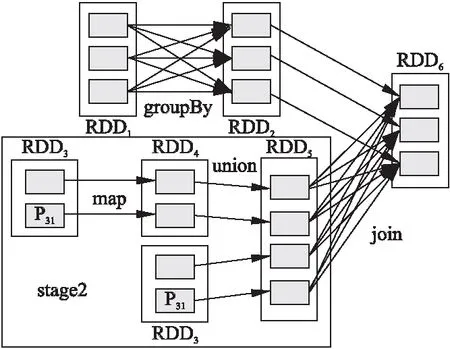
圖3 一個計算過程的DAG圖Fig.3 DAG graph of a computational process
圖3展示了Spark中一個作業執行階段的DAG圖,假設該作業的所有分片都在同一個節點之中,實驗通過六臺虛擬機所組成的節點計算數據.這個任務序列的執行階段Stage如公式(1)和公式(2)所示.
Stage11{RDD3→RDD4→RDD5}
(1)
Stage21{RDD3→RDD5}
(2)
RDD是由分片組成的,假定一個作業中所有的RDD分片大小都相同,用Pnm表示第n個RDD的第m個分片,那么:
RDDn=Pn1+…+Pnm+…+Pnp
(3)
假設每個分片的執行時間為TPnm,則Stage2中的執行總時間為:
TP=TP32+2TP31+TP41+TP42
(4)
我們可以看到P31被重復計算了,而這僅僅是一個作業中的小部分,整個作業中可能存在大量重復的高開銷計算.
3.2 計算模型
Spark在數據處理的過程中,為每個作業生成一個DAG.在作業的計算過程中,有些變量會反復出現,若將這些變量緩存在內存中可以顯著提升處理速度.Spark默認內置的LRU是通過LinkedHashMap實現的,本文所實現的工作在此基礎上重構了內存管理策略.
默認的LRU算法選擇最近使用的RDD分片,不考慮分片的計算成本和大小.當兩個RDD分片的大小和重復出現的次數相同時,應該緩存計算成本更高的分片;而當兩個分片的計算成本和重復出現的次數都相同時,則需要考慮緩存空間較小的分片.
4 緩存權重替換策略(CWS)
4.1 RDD計算過程
通常情況下,當計算緩存資源不夠用時,需要對緩存中的RDD分片進行替換,我們用MemoryC表示集群內存總資源,計算節點中實際空閑內存記為MemoryA,默認條件下,假設此時的任務中有q個RDD在等待,則等待計算的RDD所需占用的內存資源必須小于MemoryA.即:
(5)
Spark中的行為操作都是在轉換操作之后才執行的,所以可從DAG圖中統計分片重復使用的次數,在作業執行的過程中,本文把緩存中已有的RDD記為MemoryS.
4.2 RDD的選擇
默認情況下系統使用LRU算法淘汰最長時間未被使用的分片,如果該分片需要被再次使用,此分片重新計算的成本可能會非常高.LRU無法確定分片是否有保存的意義,本文提出的CWS算法能選擇高權值的分片并保留在緩存中,該算法的偽代碼如算法1所示.
算法1.選擇算法
Selection algorithm
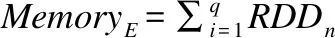
actual free cacheMemoryA
maximum cacheMemoryC
selected blocksMemoryS
Output:evicted RDDs
1 get a DAG from the driver of the spark
2 allocate memory according to DAG
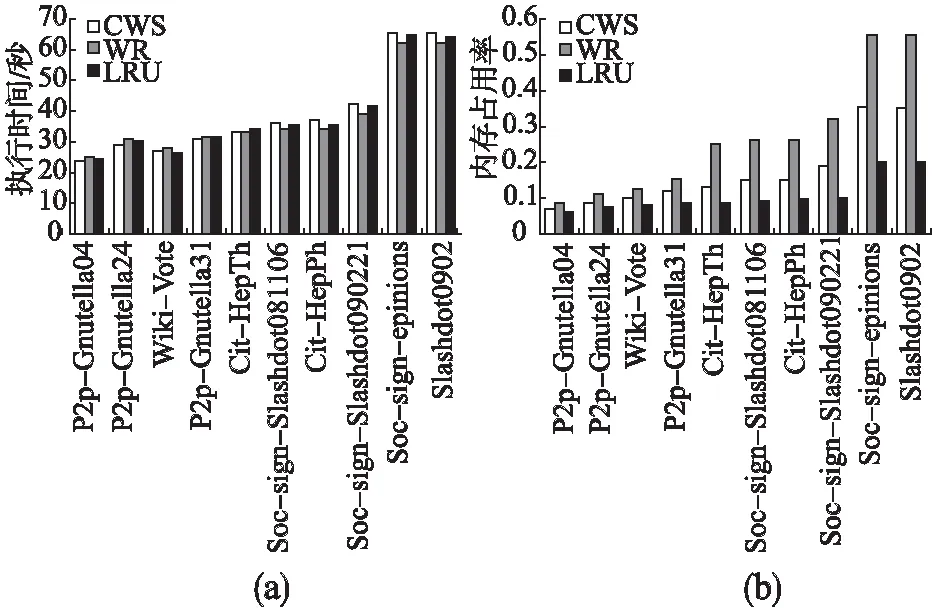
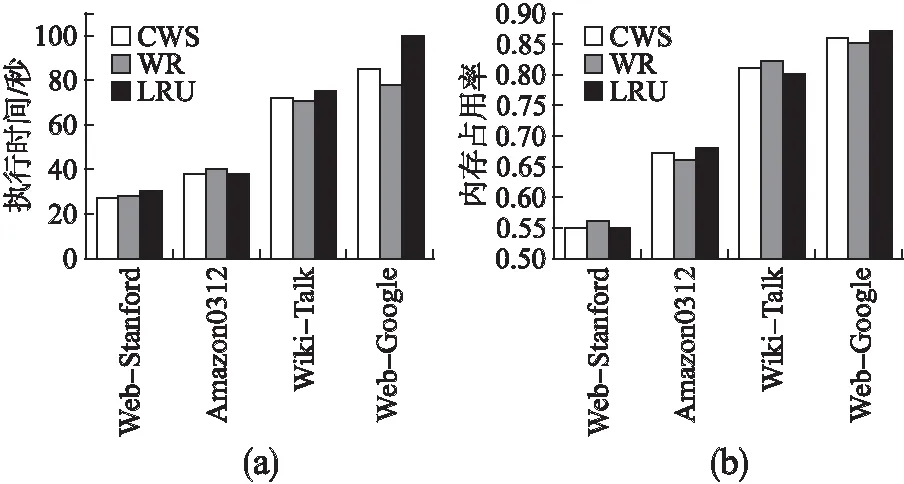
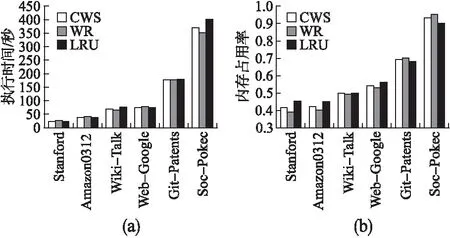
3if(MemoryE 4fori=1toq 5if(MemoryE 6MemoryA 7elseif(MemoryE>MemoryA) 8 call replacement algorithm 9endif 10endfor 11endif 在選擇算法中,MemoryE表示等待執行隊列中的RDD,RDD的數量記為q個,剩余的緩存總量表示為MemoryC.算法首先在設定好緩存的替換策略后,遍歷內存查找是否已有待選擇的RDD,若已有則停止循環.第5-9步判斷實際空閑內存的大小,當實際空閑內存大于待分配的內存大小時,將RDD放入緩存中,否則跳轉至替換策略.該選擇算法的時間復雜度為O(n). Spark中的各節點處理能力基本相同,那么分片完成作業花費的時間更多,則意味著其計算成本更高.通常情況下,我們可以使用分片大小近似作為其計算成本.在替換分片的過程中,當發現某個分片占用的存儲空間較大(計算成本更高)而使用次數又較少時,本文提出的算法將用存儲空間較小且使用次數相同的分片替換該分片,或者使用存儲空間大小相近且使用次數更多的分片來替換該分片.在公式(6)中,當分片的使用次數Fnm不變時,分片的計算成本Spnm的增加將導致該分片的權值變小;當Spnm不變時,該分片的權值隨著Fnm增加而變大.本文用Fnm表示RDDn的第m個分片的使用次數,分片大小記為Spnm,分片的權值Vpnm則可表示為: Vpnm=Fnm/Spnm (6) 若RDDn有m個分片,那么RDDn的權值VRn為: (7) 當內存中的分片緩存接近飽和時,替換算法將根據Vpnm和VRn替換權值較小的分片.替換算法的偽代碼如算法2所示. 算法2.替換算法 Replacement algorithm Input:selected blocksMemoryS the valueVRnof candidate RDDs the size of partitionsSpnm execution sequencePnm Output:evicted RDDs 1fori=1toq 2if(Pnm==Pni) 3 break; 4elsequickly sortMemorySforVRn 5 expel RDD; 6endif 7endfor 在替換算法中,首先判斷待替換分片是否存在于內存中,若不存在則對內存中待替換的緩存序列按權值進行快速排序,得到新的序列,最后按照新的序列逐出RDD.該算法的時間復雜度為O(n). 為避免因實驗環境差異帶來的實驗結果對比的不便,本文盡量使用與目前主流研究算法一致的實驗環境.在服務器上部署含有6個節點的集群,每個節點配備8核2.2GHz Intel Xeon E5-2620 CPU、物理硬盤空間80G、內存根據實驗條件可調整為2G、4G、8G等多種情況.集群使用的操作系統為CentOS 7,Scala版本為2.11.8,而Java開發工具包版本為1.7,Hadoop的版本為2.2.0,Spark版本為2.0.0.實驗過程中的計算時間通過對三次運行結果取平均值,內存占用率則通過Ganglia[14]監控獲取. 測試數據集使用斯坦福大學提供的公開網絡分析項目獲取的17個真實的圖形數據集.這些數據集的Nodes和Edges對執行時間和內存的使用情況影響較大.實驗采取PageRank算法對這些數據集進行排序,數據集如表1所示. 表1 斯坦福大型網絡數據集 NameNodesEdges Descriptionp2p-Gnutella041087639994Gnutella peer to peer network from August 4,2002p2p-Gnutella242651865369Gnutella peer to peer network from August 24,2002wiki-Vote7115103689Wikipedia who-votes-on-whom networkp2p-Gnutella3162586147892Gnutella peer to peer network from August 31,2002Cit-HepTh27770352807Arxiv High Energy Physics paper citation networksoc-sign-Slashdot08110677357516757Slashdot Zoo signed social network from November 6,2008Cit-HepPh34546421578Arxiv High Energy Physics paper citation networksoc-sign-Slashdot09022182144549202Slashdot Zoo signed social network from February 21,2009Soc-sign-epinions131828841372Epinions signed social networkSlashdot090282168948464Slashdot social network from November 2008Amazon03022621111234877Amazon product co-purchasing network from March 2,2003Web-Stanford2819032312497Web graph of Stanford.eduAmazon03124007273200440Amazon product co-purchasing network from March 12,2003Wiki-Talk23943855021410Wikipedia talk (communication) networkweb-Google8757135105039Web graph from Googlecit-Patents377476816518948Citation network among US patentssoc-Pokec163280330622564Pokec online social network 由于Spark是基于內存計算的框架,所以集群系統中各節點的內存空間越充足其計算優勢越明顯.當緩存重復的RDD分片時,充足的內存能保證最大限度地縮短執行時間.在本文實驗中,根據目前國內外研究均使用的PageRank算法來測試性能,使用開源項目Ganglia監控內存使用率[15].每個數據集在Spark集群環境下運行PageRank算法三次,取其時間的平均值.本文使用表1中的數據集來測試充足內存條件下的執行時間和內存占用率,分別測試了默認情況的下LRU、權重替換WR和CWS的策略. 圖4(a)是每個數據集在內存空間寬裕的條件下對應的執行時間.當每個數據集在充裕的內存中被處理時,WR的替換算法優勢并不明顯,而WR的選擇算法由于執行選擇算法時會頻繁統計分片的使用次數,數據集較小時,其處理時間可能會稍微增加.但是,隨著數據集的Nodes和Edges數量的增加,WR算法的計算時間會減少.CWS算法在計算過程中減少了統計分片的使用次數,降低內存占用率的同時允許計算時間適當地增加.計算較小的數據集時,由于減少了頻繁的統計分片使用次數,從而縮短了計算時間.計算較大的數據集時,算法側重于降低內存的占用率,執行時間不是算法重點考慮的指標.CWS算法在處理表1所示的圖形數據集時,總的執行時間比WR算法平均降低了2.4%.在圖4(b)中,當每個節點使用8G內存時,WR算法的內存占用率明顯高于其它算法,CWS盡管在計算時間上沒有明顯的優勢,但其內存的占用率較低. Spark在內存接近飽和時使用LRU算法來重新分配內存,在有限的內存情況下替換算法起著重要作用.我們將LRU、WR和CWS算法分別在單個節點內存大小分別為2G和4G條件下進行比較.我們使用表1的數據集運算PageRank算法測試,使用Ganglia監控內存使用率.每個數據集進行三次運算后取平均值,發現每個節點的內存使用情況大致相同.因為Spark使用負載均衡策略來管理資源,所以我們用其中一個節點的內存使用情況對比.圖5(a)展示了單個節點在2G內存條件下完成較小數據集的處理的執行時間,圖6(a)展示了單個節點在4G內存條件下完成較大數據集的執行時間. 圖4 單節點使用8G內存時數據集運行不同算法后的執行時間和內存占用率Fig.4 Task execution time and memory usage comparison under different algorithms with RAM=8 GB in each node 圖5 單節點使用2G內存時數據集運行不同算法后的執行時間和內存占用率Fig.5 Task execution time and memory usage comparison under different algorithms with RAM=2 GB in each node 從圖5(a)和圖6(a)的對比,我們可以看出,在內存有限的情況下,計算量較大的數據集會導致緩存空間不夠,LRU算法僅根據分片最近是否使用來決定是否替換,當被替換的分片計算成本較高時,此時可能需要花費更多時間;WR算法會頻繁計算分片的使用次數,當數據集較小時,也會消耗掉部分時間.從圖5(b)不難看出,2G內存條件下各算法的內存占用率基本一致,與LRU相比,WR算法的平均計算時間有較大改善,CWS算法在計算時間節省方面沒有較大提高.在圖6(b)中,每個節點使用4G內存時,CWS算法相比WR算法降低了0.8%的內存占用率,而WR算法的內存占用率會隨著數據集的增大高于其它算法. 圖6 單節點使用4G內存時數據集運行不同算法后的執行時間和內存占用率Fig.6 Task execution time and memory usage comparison under different algorithms with RAM=4 GB in each node 通過對Spark的RDD進行深入研究,我們從選擇RDD和替換RDD兩個方面對Spark的緩存機制進行算法調優.Spark是基于內存的計算,但Spark默認的機制沒有充分利用內存的性能.WR算法雖然考慮了多個因素,但由于頻繁的選擇操作,在處理較小數據集時,產生了較多的時間開銷.本文在此基礎上,對算法進行優化.實驗結果表明CWS算法在內存空間充裕的條件下處理較小數據的平均執行時間相比WR算法縮短了2.4%,內存占用率降低36%;在內存空間有限的條件下,每個計算節點使用2G內存時,內存占用率與WR算法基本持平.使用4G內存時,與WR算法相比,CWS算法降低了0.8%的內存占用率.4.3 權值替換
5 實驗部分
5.1 實驗環境
5.2 內存充足條件下的算法對比
Table 1 Stanford large network dataset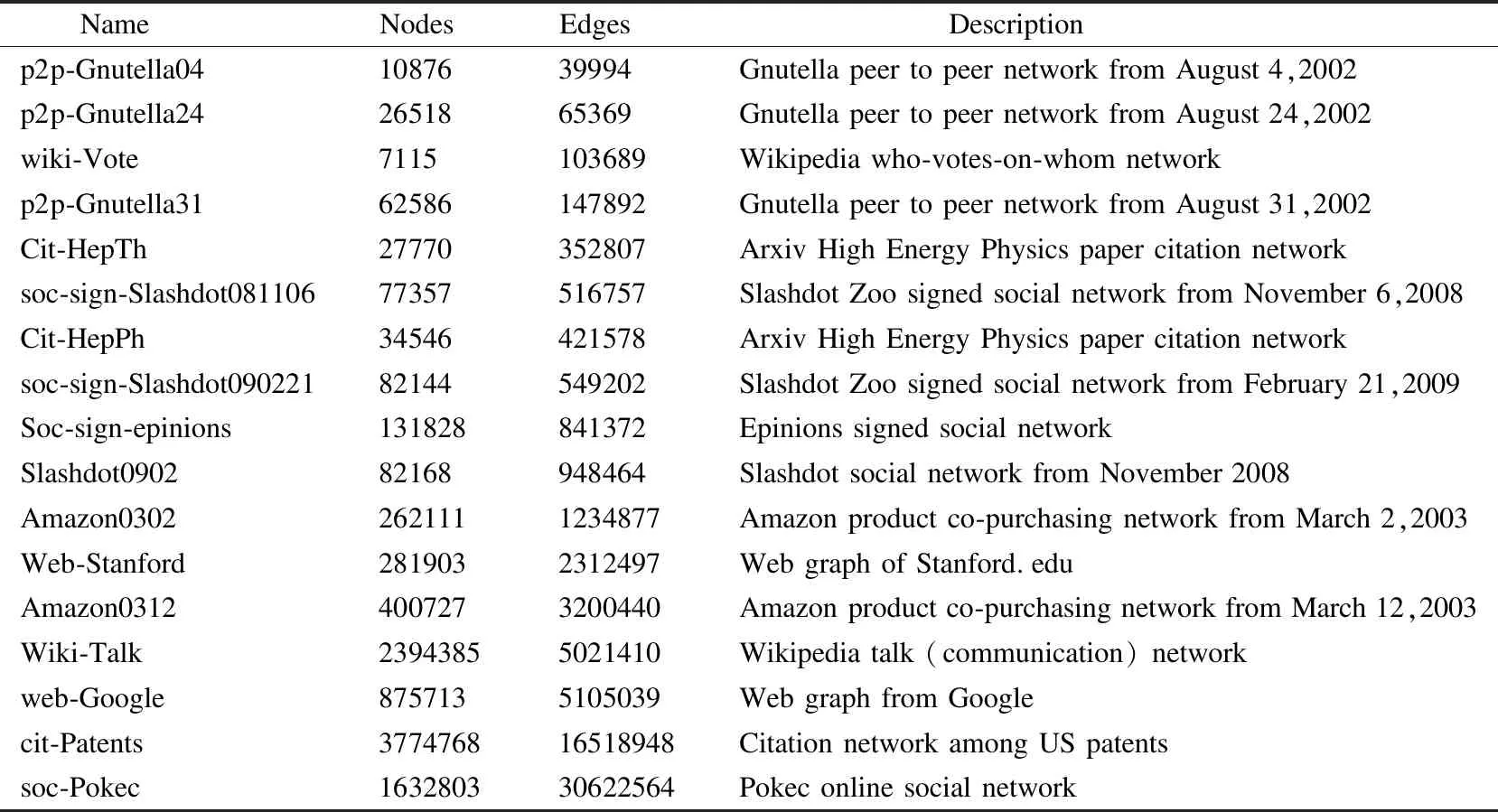
5.3 有限內存條件下的算法對比
6 總 結
