
云網一體使能網絡即服務
2019-06-10 13:50:26朱海東
中興通訊技術 2019年2期
朱海東
摘要:隨著云業務的深入部署,除接入和連接性服務外,云網運營商還須需要將網絡端到端帶寬和時延等服務質量保障能力作為網絡服務提供給最終客戶。云網運營商基于云網一體網絡架構,通過部署性能測量和故障發現、基于性能的路由、流量統計和狀態預測,以及多域編排等系統,滿足客戶對不同需求層級能力的要求,使能網絡即服務(NaaS)能力,實現網絡與云化業務的有機結合。
關鍵詞:云網;多云;NaaS;服務等級
Abstract: In addition to access and connectivity services, cloud operators also provide multi-factor quality of service (QoS) assurance capabilities (such as end-to-end bandwidth and delay) as the network service to end customers. The cloud network service provider enables network as a service (NaaS) by building performance measure and fault detection, performance aware routing, traffic statistics and state prediction, and multi-domain orchestration systems to match the hierarchy of service needs upon the cloud network architecture.
Key words: cloud network; multi-cloud; NaaS; service-level agreement
一直以來,網絡規劃人員采用自頂向下的設計方法構建并不斷擴展數據通信網絡,在過去的20年里成功地完成了業務和網絡IP化過程。近年來,隨著云計算的成熟應用以及信息技術(IT)行業與信息通信(IC)行業的交融,這種以需求為基礎創建的網絡通常無法如預期那樣運行,也無法隨網絡規模的不斷增長而擴展,無法滿足客戶的需求[1]。未來網絡的規劃設計應以數據和數據中心(DC)為核心,圍繞云化業務的需求進行,這已經成為IT和IC行業的共識。云與網有機結合將構成云網一體的新型信息系統架構。
1 云網的概念
云網(CloudNet)將云計算架構與網絡能力相結合。云網一體架構充分利用軟件定義網絡(SDN)和網絡功能虛擬化(NFV)等技術提供的動態可編程能力,實現服務設施按需靈活部署。在該架構下,業務通過跨Internet連接的若干數據中心協同提供,在提升資源利用率和業務可靠性的同時實現業務部署和管理的敏捷性[2]。
1.1 云網一體參與方
在云網一體框架下,客戶的業務由云業務服務商(CSP)和網絡業務服務商(NSP)共同完成。CSP利用架設在數據中心之上的設備和資源,通過互聯網或其他網絡以隨時獲取、按需使用、隨時擴展、協作共享等方式,為用戶提供數據存儲、互聯網應用開發環境、互聯網應用部署和運營管理等服務。CSP通過云化數據中心提供服務,主要類型有軟件即服務(SaaS)、平臺即服務(PaaS)和基礎設施即服務(IaaS)等。典型的CSP有阿里云、騰訊云、亞馬遜AWS、微軟Azure等。
除了公有云,互聯網公司和政府、大型企業的私有云也是云的重要組成部分,如Facebook通過全球分布的數據中心為各區域客戶提供服務,各級政府通過政務云提供便捷的公眾服務。當私有云與公有云配合提供服務時,即成為混合云。
NSP則為客戶提供網絡接入服務、本地互連和跨地域骨干遠程連接等服務,這些網絡服務是綜合電信運營商的基礎電信業務之一。目前電信行業內一些運營商同時提供云服務和網絡連接服務,轉型為云網綜合運營商,如中國三大運營商:中國電信(天翼云)、中國聯通(沃云)和中國移動(移動云),它們都運營有各自的公用云和專有云業務;其他國家如西班牙電信(Telefónica)、德電(Deutsche Telekom)等傳統電信運營商也紛紛進入公有云市場。
1.2 云網一體的研究范圍
參照電氣和電子工程師協會(IEEE)CloudNet委員會關注和研究的技術方向,云網一體架構分為以下幾個技術領域[2]。
(1)云網總體架構。
云網總體架構包括分布式數據中心架構、云數據中心大規模路由組織方式、數據中心內/外部互訪方式以及聯合云和混合云組網等方面。業務的扁平化使得越來越多的數據中心網絡引入Internet全球路由,實現跨地域的信息服務,這需要使用基于邊界網關協議(BGP)路由屬性和策略對流量流向進行優化控制。隨著個人和政企業務上云的演進,聯合云、混合云等多云方式部署也成為影響云網架構的重要推動力量。調研表明:81%的企業會采用多云策略,平均每個企業會使用5朵公用云和(或)私用云[3]。大型互聯網公司如Twitter也轉向了混合云方案,將其冷存儲和Hadoop業務遷移到了Google云上。在多云環境下,端到端業務需要在多個網絡域和管理域間完成交互協同。
(2)云網資源管理。
云網資源管理根據業務需要動態按需提供計算資源、存儲資源和網絡帶寬、服務等級等能力,涵蓋的范圍不僅包含數據中心基礎設施和數據中心內部網絡(DCN),還要包含數據中心互聯網絡(DCI),特別是通過多個NSP網絡資源及CSP自用的骨干專網共同實現跨數據中心互聯[4]。云網資源管理需要獲取物理網絡和虛擬拓撲的全局視圖和資源使用狀態,提供最優的資源調度和使用策略,提供彈性、可擴展的動態資源管理方案。
(3)云網虛擬化技術。
云網虛擬化引入SDN轉控分離架構和NFV虛擬網元,一方面可以實現業務部署的簡化和自動化,提供敏捷服務,加速新業務上線速度;另一方面在多層、多域、多廠家組網的復雜網絡中提供端到端的管理和控制能力。分域化和層次化部署的SDN控制面還能夠提供精細的控制粒度,提高系統資源利用率和運維效率。
(4)云網業務和云網安全。
云網業務和云網安全包括SaaS、PaaS、IaaS、大數據和數據分析、內容分發、多業務邊緣計算等業務場景及其相關的安全要求。
在云網一體架構下,為了保證端到端的業務體驗,運營商還將提供給客戶端到端帶寬和時延等網絡服務質量保障能力,從而實現網絡即服務(NaaS)。
2 網絡架構和業務需求
2.1 云網一體骨干網架構
對云網業務服務商而言,網絡整體架構在很大程度上決定了業務組織方式和SDN/NFV等新技術的部署難度,從而影響資源優化利用所能達到的程度。從網絡角度看,云網架構可以分為數據中心內外2個部分。數據中心內部DCN的目標架構主要有Fat Tree、Spine-Leaf等。數據中心之外的骨干網部分,得益于IP網與生俱來的互通性和可達性,目前NSP和CSP根據各自商業目標在其資源管控范圍分別建設和發展各自的骨干網絡系統。
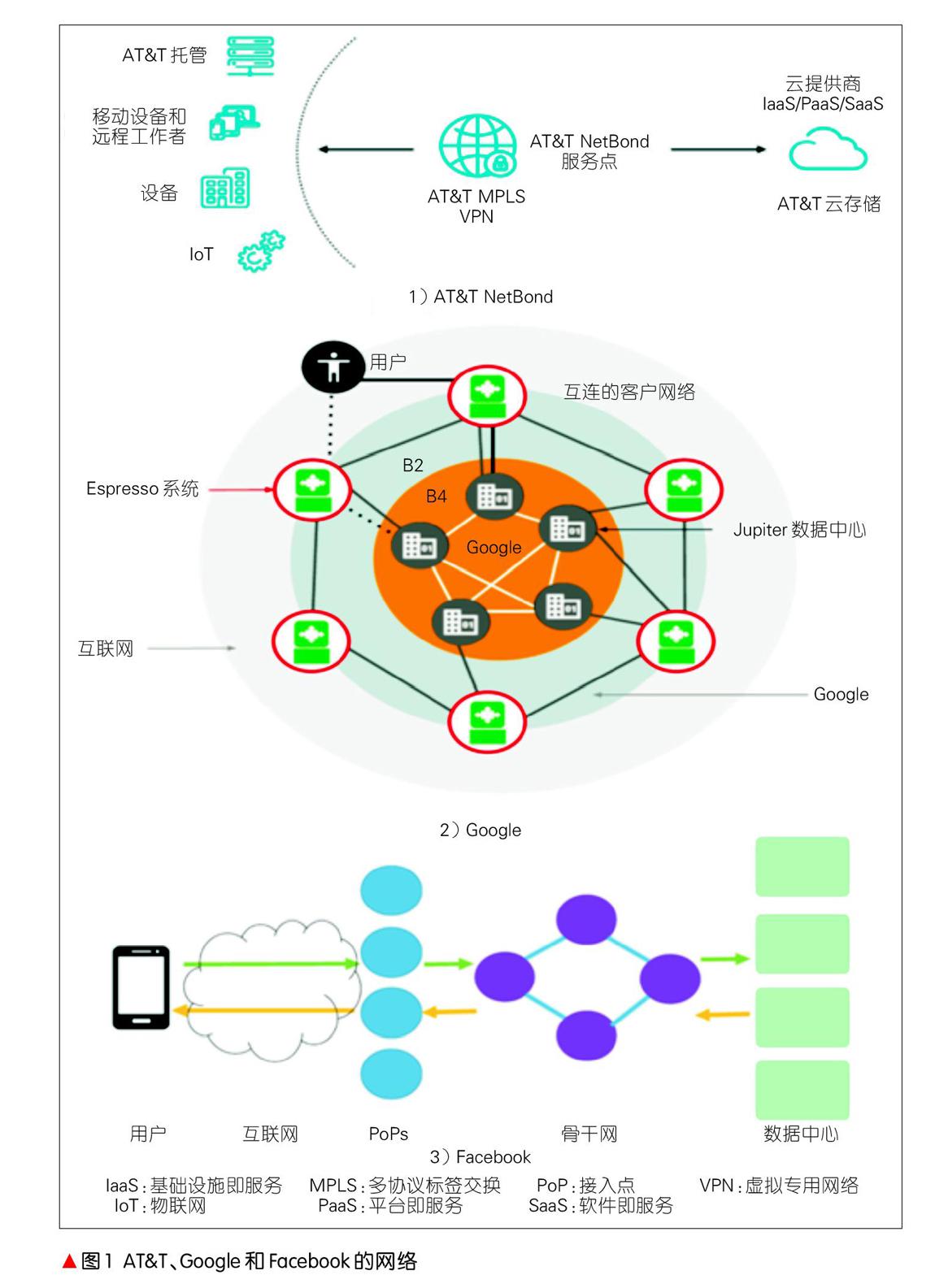
如圖1所示,AT&T針對企業入云提供了NetBond產品[5],在網絡中部署NetBond服務節點并與CSP背靠背接入,實現了AT&T企業多協議標簽交換(MPLS)虛擬專用網絡(VPN)和多云接入服務的整合,支持用戶接入私有云和公用云,還實現了帶寬的按需擴展和連接的高安全保障。既是云服務商,又是內容服務商的Google擁有名為B4和B2的2張骨干網,前者由33個全球節點構成專用的大容量DCI網絡[6],后者在全球70多個區域完成Google數據中心與外部鄰接運營商互通,是終端用戶訪問Google的各種服務的必經通道[7]。Facebook的網絡由邊緣接入點(PoP)、全球骨干和若干數據中心構成。用戶通過Internet接入各地PoP點,再經由骨干網訪問數據中心,Facebook的骨干網同時承載外部用戶流量和內部數據中心(DC)間流量[8]。
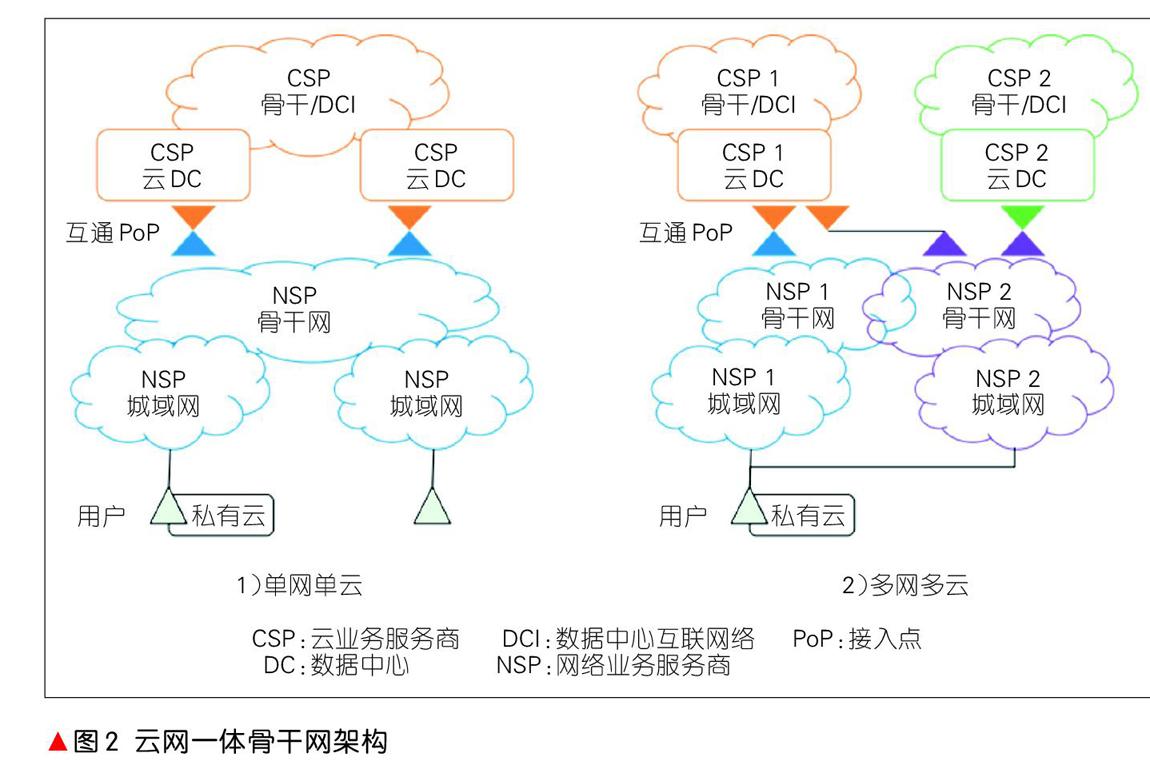
從業務的視角看,上述3種骨干網架構沒有把從最終用戶到云中的、業務的全部端到端路徑視為一個整體,實質上是在各自網絡域內部進行的分段局部優化。根據NSP和CSP網絡架構現狀,用戶端到端業務路徑包含基礎網絡運營商NSP的接入/城域網、NSP-CSP網間互通PoP、運營商骨干網和CSP骨干/DCI專網,以及數據中心內網DCN等。其中,互通PoP是新引入的網絡節點,它不僅要完成傳統BGP域間路由互通,還要滿足業務互通對服務質量、安全隔離等要求,是實現業務端到端一致性的關鍵節點。當用戶基于使用安全性和經濟性等因素選擇多網多云方案時,該方案還需要具備多個NSP和多個CSP間的多域資源組合優化和編排能力。圖2分別展示了云網一體架構的單網單云和多網多云2種架構。
2.2 網絡能力需求層級
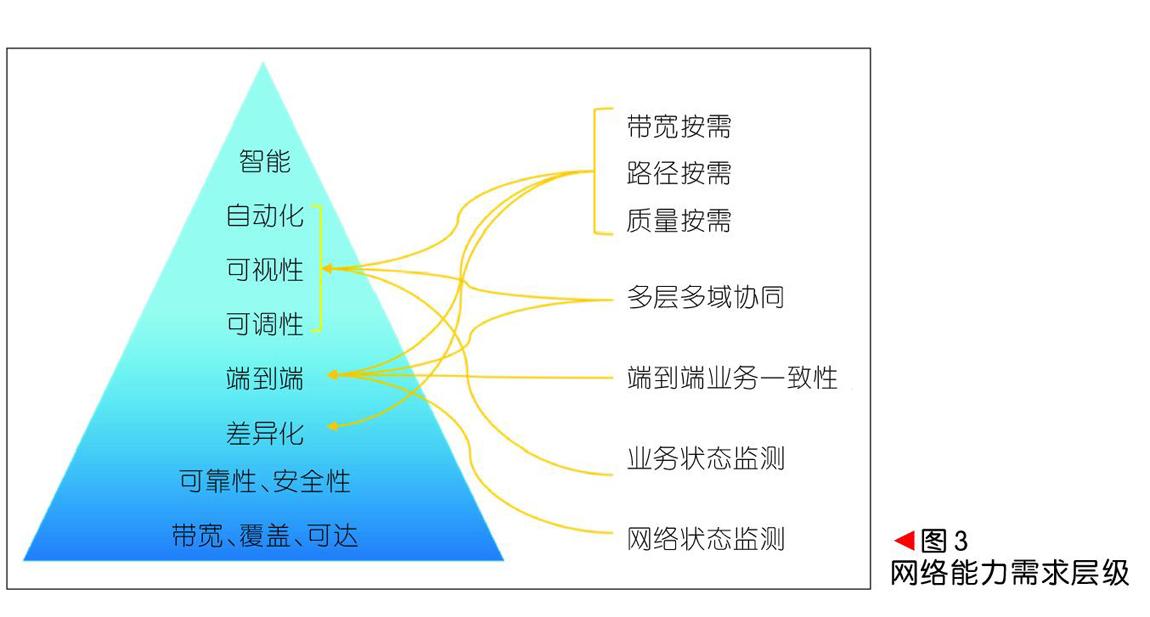
業務運營對網絡能力的需求存在若干層級,如圖3所示。
(1)最底層是網絡物理帶寬、物理覆蓋范圍和站點間可達性,這些屬性是提供網絡服務的基礎。其中,物理帶寬能力包含接入帶寬和傳輸帶寬能力。
(2)按照開放式系統互聯(OSI)7層模型,可靠性和安全性可分為物理層到網絡層(L1—L3)、傳輸層到應用層(L4—L7)2部分。前者主要由網絡能力保證,后者則由業務應用軟件來實現。
(3)網絡差異化業務保證能力是多業務綜合承載的要求,即在一張物理網絡上按照不同業務的服務質量等級分配相應資源,不同業務對網絡服務關鍵指標不同,比如企業跨DC大量數據復制業務關注在一定時間內總數據吞吐量,而對網絡時延和丟包相對不很敏感。基于WEB的交互式應用,除了帶寬和丟包率之外,影響傳輸控制協議(TCP)效率的時延因素成為業務保障的重要指標。目前,云網業務的主要技術指標有帶寬、時延和可靠性等[9],云網運營商在保證各等級業務服務達標的過程中,不僅為價值用戶提供了更多產品選擇,也使得網絡資源得以充分利用。
(4)網絡的端到端能力是指從用戶終端到應用服務器的全路徑業務保障能力,特別是業務路徑可能經過一個或多個運營商的多個管理域,在相鄰的管理域之間需要保證用戶體驗的一致性。通過引入SDN編排系統,消除各個網絡域采用的不同技術的形式差異,完成不同管理域間在資源定義、業務定義和服務等級協議(SLA)定義的映射和轉換,同時實現資源的優化配置。
(5)自動化、可視性和可調性是云網敏捷能力的體現,也是實現NaaS的靈活按需能力的基礎。在SDN技術架構下,云網運營者將網絡控制和轉發分離,通過集中的控制面獲取全局的資源和資源利用信息,并在路由層面實現對業務端到端全局路徑組合優化。借助SDN網絡規劃和業務部署工具,云網運營者還可以實現業務部署的簡化和自動化過程。只有具備了自動化、可視性和可調性的網絡,才能作為一種服務發布給客戶。
(6)智能化是更加高階的自動化,其目標在于實現基于意圖的網絡(IBNS),從而為云網資源的設計、實施、運營提供覆蓋全生命周期的自動化能力,將業務需求和網絡資源配置實時同步。
3 關鍵技術和系統
3.1 性能測量和故障發現
云網業務的分布式天性使得最終用戶的體驗效果除了依賴應用軟件外,還依賴于包括數據中心里的服務器、數據中心內外部網絡以及運行在服務器上的虛擬化軟件等組件的運行情況。從網絡角度來看,云網運營商需要管理和保障數據中心內、數據中心間和用戶到數據中心這3個網絡域的業務帶寬、時延和可靠性。研究表明當業務中斷或體驗下降時,用戶很自然地將問題歸結為終端問題和網絡問題,而實際上50%的“網絡”問題并不是由網絡引發的[10],因此,云網運營商需要有效的性能測量系統。
Ping探測是一種檢測網絡L3連通性和丟包率的通用手段。NSP用IP Ping探測網絡邊界間的連通性,CSP則使用TCP Ping和HTTP Ping檢驗業務層的連通性。顯然后者更能符合用戶端到端體驗,但會存在2點問題:(1)針對網絡中每用戶每應用的測量不僅占用終端和服務器計算資源,同時其產生的海量測量數據需要存儲和管理,例如Microsoft Ping mesh系統每天可以產生2 000億個探針和24 T字節的數據[10],Facebook為了降低對資源的需求采用隨機選擇部分業務進行測量[11];(2)將CSP應用層的測量結果應用到NSP網絡層資源管理的映射關系是十分復雜的,特別是中間網絡的路徑上匯集了不同等級的海量應用,針對特定應用的網絡問題根因分析缺少自動化手段。網絡吞吐量和時延的性能測量分為帶內和帶外,帶內的方式就是在報文頭中設置或添加探針字段,在測量點統計性能指標,網絡中間節點無感知。帶外的方式則通過在網絡中增加獨立的探針數據流。由于數據網絡的逐跳轉發天性,這種方式無法保證探針流與業務流全程同路徑。
基于業務的網絡性能測量是支撐云網運維的重要手段,國際互聯網工程任務組(IETF)正在研究、發展的In-band操作管理維護(OAM)采用帶內機制,在數據包頭增加OAM字段來實現對網絡故障檢測、路徑測量、流量等的監測,有望成為各種隧道封裝統一的測量機制。
3.2 基于性能的路由
基于路由的L3尋址是實現網絡可達的基礎手段。現有的內部網關協議(IGP)和BGP協議在路由計算中對網絡性能,特別是鏈路利用率、擁塞丟包性能、路徑時延等實時動態性能變化并不敏感。云網業務通常跨越多個網絡域,在域間運行的BGP協議為距離-矢量協議,其自身甚至對帶寬也不敏感,所以依靠目前的IGP和BGP協議,無法針對業務的服務質量需求和網絡性能的變化自動調整業務路由。為此,基于IP/MPLS和SDN/Openflow的流量工程隧道被引入到網絡中完成流量流向的調整。隧道封裝方式可以有很多種:虛擬局域網(VLAN)、虛擬可擴展局域網(VXLAN)、通用路由封裝(GRE)、MPLS、分段路由(SR)等,云網運營商可以根據自身網絡設備的支持情況和技術布局選擇具體方式。
鑒于網絡中業務種類的多樣性和不同業務對網絡資源需求的關聯性,優化對象只能是網絡中的高價值流量,或對整網帶寬占用顯著的、數量少流量高的“大象”流[12]。針對這些高價值流量,應用上節討論的性能測量結果,采用SDN集中控制方式調整流量路徑,從而優先保障這些業務的質量。在同一個網絡管理域中,可以為高價值流量建立端到端流量工程優化路徑,當存在對丟包、時延等不敏感的背景流量時,網絡帶寬資源利用率可以接近100%。從網絡資源全局優化角度,業務等級數量越多不一定會使得優化效果更好。過多的業務等級使得資源分配算法更加復雜,流向調整引起的網絡收斂速度也可能受到影響,甚至導致出現網絡震蕩。目前在實踐中,部署2~4個業務等級即可取得較好的調優效果。
3.3 流量統計和狀態預測
基于性能的路由落地須要準確地統計當前在網業務流量并預測調整后的網絡狀態。使用簡單網絡管理協議(SNMP)可以以秒級粒度收集網絡設備接口流量,業務級流量記錄則需要使用Netflow/IPFIX、sFlow等基于采樣的工具,云網的控制面需要將這些信息與網絡拓撲結合,生成網絡資源矩陣和流量矩陣。網絡中某個路徑性能與該路徑上的負荷有關,而負荷是實時變化的。當負荷的變化主要是由控制面基于策略主動發起的,在一段時間內具有可預測性,使用流量工程TE技術進行網絡資源優化才可行。這個時間段就是TE調整的窗口,在這個窗口期內,要根據網絡性能完成TE策略的計算或下發生效。Facebook[11]和Google[12]分別在邊緣PoP和DCI場景實現了頻度在30 s的調優方案。面對云網系統海量的業務流,Telemetry技術提供效率更高的信息上報通道,可以提供更加精細的流量狀態信息,進一步提高調優算法的效果。
3.4 多域編排
對一個由多域異構網絡承載的業務,其網絡轉發面端到端路徑可由多種制式的隧道拼接而成,控制面則歸屬于多個NSP和CSP的管理域范圍。如圖4所示,這需要引入多域編排(MDO)系統,完成多種技術和多個運營商間的資源管理、業務管理和域間SLA協同[13]。單域編排器從SDN控制器獲取資源信息后進行本域的資源編排和業務編排,并與鄰接域的單域編排器互通。多域編排器則通過應用程序編程接口(API)與本管理域中各下級單域編排器實現通信,完成多個子域間的協同編排,并實現對端到端業務的SLA保障。
4 結束語
在業務上云和多云時代,云網一體是ICT融合的必由之路。云網運營商發掘和擴展網絡能力,將基礎網絡接入能力、連接保障能力、按需SLA能力與云化業務需求相結合,提供滿足用戶對高品質靈活服務的需要的新型網絡服務,提升網絡資源的商用價值,實現供需雙贏。
參考文獻
[1] OPPENHEIMER P. 自頂向下網絡設計(第3版)[M]. 北京:人民郵電出版社, 2011
[2] IEEE- Cloudnet about CloudNet[EB/OL].[2019-01-10].http://cloudnet2018.ieee-cloudnet.org/about.html
[3] 2018 State of the Cloud Report [EB/OL].[2019-01-10]. https://www.rightscale.com/lp/state-of-the-cloud
[4] NGUYEN C L, PING W, DUSIT N. Resource Management in Cloud Networking Using Economic Analysis and Pricing Models: A Survey [J]. IEEE Communications Surveys and Tutorials, 2017,19(2): 954-1001.DOI: 10.1109/COMST.2017.2647981
[5] AT&T NetBond Product Brief [EB/OL].[2019-01-10]. https://www.business.att.com/products/netbond.html
[6] CHIYAO H, SUBHASREE M, MOHAMMAD A. B4 and After: Managing Hierarchy, Partitioning, and Asymmetry for Availability and Scale in Googles Software-Defined WAN[C]//SIGCOMM 2018. Budapest, Hungary: ACM, 2018. DOI: 10.1145/3230543.3230545
[7] KOK Y, MURTAZA M, JEREMY R. Taking the Edge off with Espresso: Scale, Reliability and Programmability for Global Internet Peering [C]// SIGCOMM '17 Proceedings of the Conference of the ACM Special Interest Group on Data Communication. Los Angeles, USA: 2017. DOI: 10.1145/3098822.3098854
[8] SUNG E Y, TIE X, WONG H Y S, et al. Robotron: Top-down Network Management at Facebook Scale[EB/OL].[2019-01-10]. https://research.fb.com/publications/robotron-top-down-network-management-at-facebook-scale/
[9] CHRISTOPH A, AJAY B, EMILLIE D. Capacity Planning for the Google Backbone Network [EB/OL].[2019-01-10]. https://ai.google/research/pubs/pub45385
[10] CHUANXIONG G, LIHUA Y, DONG X. Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis[EB/OL].(2015-08-23)[2019-01-10]. https://www.microsoft.com/en-us/research/publication/pingmesh-large-scale-system-data-center-network-latency-measurement-analysis/
[11] BRANDON S, HYOJEONG K, TIMOTHY C. Engineering Egress with Edge Fabric: Steering Oceans of Content to the World [C]//SIGCOMM 2017. USA: ACM, 2017. DOI: 10.1145/3098822.3098853
[12] ALOK K, SUSHANT J, UDAY N. BwE: Flexible, Hierarchical Bandwidth Allocation for WAN Distributed Computing[EB/OL].[2019-01-10]. https://ai.google/research/pubs/pub43838
[13] RICCARDO G, DAVID P, PAOLO M, et al. Multi-Domain Orchestration and Management of Software Defined Infrastructures: a Bottom-Up Approach[C]//2016 European Conference on Networks and Communications. IEEE Communications Society. USA:IEEE, 2016
