
圖書館海量網絡學術數據的關聯檢索技術研究
2019-06-19 02:33:41張文晶
現代電子技術 2019年11期
張文晶


摘 ?要: 為解決傳統PIT圖書館學術數據檢索方法存在索引定位數組數量有限、檢索承載額度較低等弊端,設計新型圖書館海量網絡學術數據的關聯檢索技術模型。通過定義數據包類型的方式,判斷網絡學術數據的衍生結構、設置準確的數據命名機制,完成圖書館海量網絡學術數據的結構分析。在此基礎上,利用關聯數據節點的空間編碼,確定嚴格的檢索分級法則、完善數據的關聯檢索流程,實現新型技術模型的搭建,完成圖書館海量網絡學術數據的關聯檢索技術研究。對比模型應用結果可知,與傳統PIT檢索方法相比,應用新型關聯檢索技術模型后,索引定位數組數量提升至5.0×1011 TB以上,檢索承載額度也達到預期水平。
關鍵詞: 網絡數據; 關聯檢索; 數據包定義; 衍生結構; 命名機制; 空間編碼; 分級法則; 技術模型
中圖分類號: TN911?34; TP391 ? ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2019)11?0181?06
Abstract: The traditional PIT library′s academic data retrieval method has some disadvantages, such as the limited number of index positioning arrays and low retrieval load quota. Therefore, a new association retrieval technology model of library′s massive network academic data is designed. By defining the data packet type, the derivative structure of network academic data is judged, and the accurate data naming mechanism is set up to complete the structure analysis of library′s massive network academic data. On this basis, the spatial coding of the associated data nodes is used to determine the strict retrieval grading rules, improve the process of data association retrieval, realize the construction of new technical model, and complete the association retrieval technology research of library′s massive network academic data. The model application results show that, in comparison with the traditional PIT retrieval method, the number of index positioning arrays obtained by the proposed method can reach up to more than 5.0×1011 TB, and the retrieval load quota can reach the expected level.
Keywords: network data; association retrieval; data packet definition; derivative structure; naming mechanism; spatial coding; hierarchical rule; technical model
0 ?引 ?言
關聯檢索是一項常見的引擎式檢索手段,可以通過輸入的主要關鍵詞得到準確的檢索結果,且在結果頁面中會顯示一到多個不固定數量的關聯搜索詞,單擊這些搜索詞,會得到大量的關聯參考結果。這種關聯檢索手段既能在一定程度上避免關鍵詞的重復輸入,也能在海量網絡空間中規劃出關鍵詞的大致存在范圍,對于使用者來說,信息的檢索速率得到大幅提升,大大節省了有效信息的傳輸消耗時間[1?2]。在現代社會環境中,大多數圖書館都利用Bloom filter技術搭建網絡學術信息的檢索數據庫,并通過MBF的二叉樹結構,將這些學術信息傳輸至各級定位數組,再在PIT傳輸結構的促進下,將這些數組按照關鍵詞的關聯差異性進行按需分配,完成PIT圖書館學術數據檢索方法的搭建。但隨著科學技術手段的進步,這種傳統的數據檢索技術開始出現定位數組數量有限、檢索承載額度達不到預期水平等問題。為避免上述情況的出現,通過數據衍生結構判斷、數據節點空間編碼等手段,建立一種新型圖書館海量網絡學術數據的關聯檢索技術模型,并通過對比實驗數據的方式,證明該新型技術模型的應用可行性。
1 ?圖書館海量網絡學術數據結構分析
圖書館海量網絡學術數據結構分析是新型檢測技術模型的搭建基礎。在數據包類型定義、數據衍生結構判斷等關鍵環節的支持下,具體搭建方法按如下步驟進行。
1.1 ?數據包類型定義
在圖書館海量學術網絡中,數據包定義過程由信息請求端發起。信息請求端發送的原始數據包具備明顯的Interest名稱標識,且在整個數據類型定義過程中,圖書館網絡的輸入結構會對學術信息內容進行基礎判斷。當圖書館學術網絡處理中心收到檢索數據庫發出的連接請求后,在FIB整合裝置的促進下,這些連接請求中的數據信息會脫離原結構,進入信息請求端的數據定義組織中,并在其中按照一定的物理排列順序生成全新的Interest數據包[3?4]。當Interest數據包中包含大量的圖書館關聯數據時,各項與學術網絡相關的數據內容、數據名稱等信息會在信息請求端的促進下形成全新的分級Data包,然后再將所有圖書館學術數據按照關聯檢索要求整合成一條完整的信息鏈,再通過傳輸路徑將完成數據包類型定義的信息鏈返回至內容請求端。具體圖書館學術數據包類型定義原理如圖1所示。
圖1 ?圖書館學術數據包類型定義原理詳解圖
1.2 ?網絡學術數據衍生結構判斷
圖書館學術數據的衍生結構包含Counting Bloom filter,Dynamic Bloom filter,Spectral Bloom filter,Compressed Bloom filter四種類型。其中,Counting Bloom filter圖書館學術數據的衍生結構可以與所有相鄰關聯檢索節點進行比特數組共享,且隸屬于該結構的圖書館學術數據不能進行單獨刪除操作,必須始終以集合的形式存在。Dynamic Bloom filter圖書館學術數據衍生結構的比特數組位數始終固定,且隨著學術網絡中數據總量的不斷增加,隸屬于同一集合的圖書館學術數據必須保持相同的衍生趨勢[5]。Spectral Bloom filter圖書館學術數據衍生結構具備較為固定的比特數組檢測頻率,在與相鄰關聯檢索節點進行信息共享時,這些數組也只能維持二進制的編程形式。Compressed Bloom filter圖書館學術數據衍生結構具備較大的比特數組共享空間,可滿足數據包類型定義過程中的彈性壓縮要求,使各關聯檢索節點間的物理距離得到適當縮短。綜上可知,比特數據的存在形式是判斷圖書館網絡學術數據衍生結構的主要依據。表1為四種衍生結構的詳細判斷依據。
表1 ?圖書館網絡學術數據衍生結構判斷方法總結表
1.3 ?數據命名機制設置
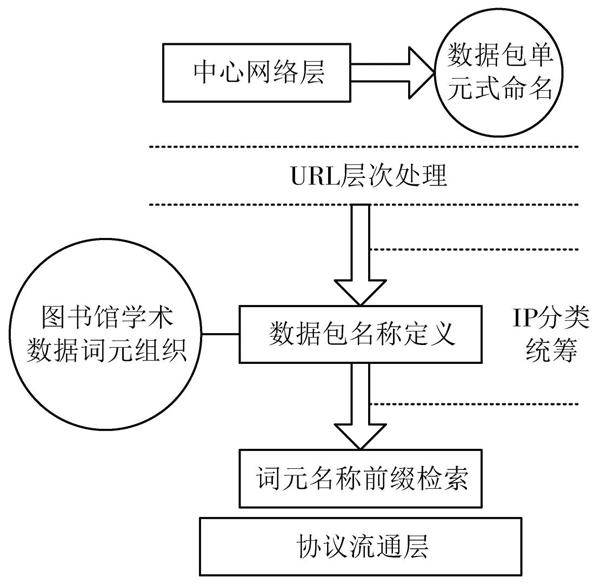
新型關聯檢索技術模型的數據命名機制主要存在于中心網絡層中,且可以在信息傳輸的過程中對已完成類型定義的數據包進行單元式命名。這種新型的數據命名機制采用URL層次處理方式定義數據包名稱,并在豐富的詞元組織支持下,界定每個詞元的字符串長度。圖書館學術數據在海量傳輸網絡環境中始終保持分層連接的狀態,而數據命名機制主要作用于中心網絡層及協議流通層[6?7]。當中心網絡層傳出大量的圖書館學術數據時,由于受到關聯檢索網絡不透明特點的影響,這些數據中的節點詞元不能得到清晰顯示。為解決上述問題,數據命名機制首先利用詞元自身的名稱前綴完成圖書館學術數據的聚合處理,再通過IP分類統籌的形式,將這些數據傳輸至協議流通層進行長久儲存。圖2為新型關聯檢索技術模型數據命名機制的運轉原理。整合上述操作原理,完成圖書館海量網絡學術數據的結構分析。
2 ?基于數據結構分析的關聯檢索技術模型搭建
在圖書館海量網絡學術數據結構分析的基礎上,通過節點的空間編碼、分級法則確定等關鍵環節的運行,實現新型關聯檢索技術模型的順利搭建。
圖2 ?數據命名機制運轉原理詳解圖
2.1 ?關聯圖書館海量學術數據節點的空間編碼
關聯圖書館海量學術數據節點的空間編碼以GeoSOT體系作為程序編寫的主要原則,且所有待編碼的圖書館學術數據都具備固定的節點數值和空間屬性參數。在編碼形式恒定的條件下,不同的空間屬性參數是區分每個圖書館學術數據的唯一法則,參數值越大代表與該參數對應圖書館學術數據的比特數組位數所占存儲空間越大,反之則越小[8?9]。在不發生數據命名紊亂情況的前提下,關聯圖書館海量學術數據空間編碼節點的排列結構如圖3所示。
圖3 ?圖書館學術數據空間編碼節點排列結構圖、

圖書館學術數據命名機制直接影響空間節點的類型及相關分層秩序。因此,在不發生數據命名紊亂情況的前提下,空間節點的類型、相關分層秩序兩項始終保持不變。設某固定圖書館學術數據的節點數值為[l],該節點的空間屬性參數為[k],則與該數據相關的空間編碼標準可表示為:
式中:[x]代表標準情況下,與該項圖書館學術數據相關的編碼因子;[log d]代表編碼執行系數;[g]代表空間編碼標準的關聯項。
2.2 ?檢索分級法則的確定
新型技術模型的檢索分級法則具備元數據區分、網絡映射屬性判斷、編碼節點創建等主要功能。當關聯圖書館海量學術數據節點完成空間編碼后,所有數據信息中的元成分都會發生定向改變,且空間屬性參數不再是判斷圖書館學術數據類型的唯一標準[10?11]。比特數組位數較大的圖書館學術數據會在檢索分級法則的促進下,將元數據成分遷移成更加緊湊的結構類型,并以此擴充在單位空間內索引定位數組的數量,解決檢索承載額度較低的問題。網絡映射屬性判斷是關聯檢索技術模型的核心處理功能,隨著檢索分級法則的逐漸完善,圖書館網絡中映射脈絡得到有效劃分,學術數據的流通速率得到一定程度的促進。編碼節點創建是檢索分級法則中的核心環節,且隨著網絡中圖書館學術數據總量的增加,該功能會促進關聯檢索識別程序的快速運行。圖4為檢索分級法則的確定原理。
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
文苑(2019年20期)2019-11-16 08:52:12
當代陜西(2019年15期)2019-09-02 01:52:00
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
