基于Python的科技情報智能化識別檢索系統的研究與設計
2019-06-20 01:22:08賀洪煜
科技視界 2019年11期
賀洪煜
【摘 要】科技情報不僅能提供科研人員開展科技研發工作的基本資源,更為科研工作者的研究方向與研究內容提供了決策支持。因此,如何為科技工作者提供多渠道、及時準確的科技情報成為科研院校及企業科技部門亟需面對的問題。本文提出了一個利用Python編程語言定時對動態網頁中與本行業相關的科技情報進行數據抓取方法,將獲取的有用信息保存到本地數據庫中,再使用B/S架構的信息系統為科研人員提供查詢及訂閱功能。該系統具備較高的實時性及準確性,并已經在企業科技部門中進行使用。
【關鍵字】大數據;科技情報;Python;網絡爬蟲
中圖分類號: G351.1 文獻標識碼: A 文章編號: 2095-2457(2019)11-0072-003
DOI:10.19694/j.cnki.issn2095-2457.2019.11.033
【Abstract】Scientific and technological information can not only provide the basic resources for researcher workers, but also provide decision support for the research direction and content of scientific research workers. Therefore, how to provide multi-channel, timely and accurate scientific and technological information for science and technology researcher workers has become an urgent problem for research institutes and enterprises. This paper proposes a method for data capture of scientific and technological information related to the industry in dynamic web pages using Python programming language. This system saves the useful information to a local database, and then the system of B/S architecture provides scientific research workers searching and subscription features. The system is highly time-sensitive and accurate and has been used in the corporate technology sector.
【Key words】Big data; Scientific and technological information; Python; Web crawler
近年來,各個領域的企業都積極地開展對大數據的挖掘和利用。隨著物聯網、智能設備與互聯網+的概念不斷普及,每天在互聯網上產生的數據已經超過2.5萬億字節,致使這些巨量的數據無法在短時間內被捕捉和處理,提煉成為我們日常有用的數據。大數據與信息技術的應用融合,將科技情報研究工作轉變為一種基于海量數據的知識發現和知識分析過程,科技情報研究已經向"數據密集型科學"這一新的研究范式演進[1]。企業的科技研發部門肩負著企業科技創新與成果轉化的重擔,科研人員每年必須積極參與國家及地方各部委發布的科研課題從而獲得科研經費的支撐。在海量數據的環境下,真正需要的有價值的知識被淹沒,準確的科技情報收集工作不但占用了科研人員寶貴的時間,不能很好地為企業的科研工作提供保障。
作為國家知識庫的概念,中國知網(CNKI)擁有世界上最大的中文知識信息資源數據庫,每天提供數千種信息檢索服務,且其平臺KBase服務于包括歐美、日本在內的發達國家,并取得了成功。在全球5,000個機構用戶中,其卓越的性能和穩定性深受用戶歡迎。此外,在調查了美國的蘭德公司(RAND)、加拿大科技情報研究所(CISTI)、日本科學技術政策研究所(NISTEP)等幾家國際著名情報機構的情報分析方法后發現,國外典型科技情報機構的情報分析與應用呈現出工具化、系統化與平臺化的特征。
綜上分析,企業情報部門及科研人員需要獲得粒度更細更精準的科技情報服務,亟需設計開發一套符合企業實際情況、開發靈活、簡單易用、具備科技情報收集與分析功能的軟件平臺系統。Python語言是一種功能強大的具有解釋性、交互性和面向對象的第四代計算機編程語言,它開發代碼的效率非常高,具有強大和豐富實用的第三方標準庫,使得編程變得簡潔快速并支持廣泛的應用程序開發,從簡單的文字處理到基于Web的開發及游戲設計的應用[2]。使用基于Python的網絡爬蟲應用,不僅可以實時監控提供科技情報的網站發布的所有信息,并且還能進行關鍵字等的過濾,無需人工干預,就能向指定的用戶提供有效信息的推送。
1 系統的主要功能及目標
根據前期對企業科研部門調研,本文所研究的基于Python的科技情報智能化識別檢索系統需要實現以下功能:定時從系統預設的網絡渠道獲取最新發布的科研情報;建立可視化科技情報智能化識別檢索系統,用戶還可自行訂閱相關類型或關鍵字的情報。系統建設完成后,能推廣至集團及下屬子集團各科研單位進行使用。
2 系統的功能設計
2.1 系統的設計
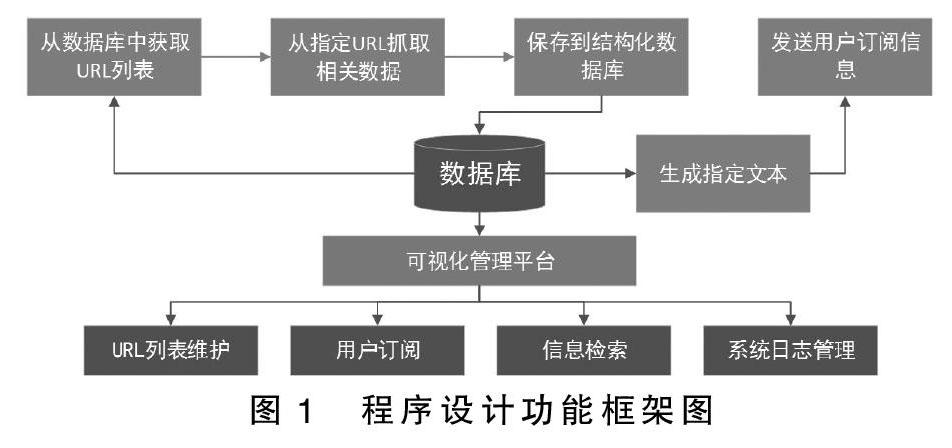
本系統程序設計分為兩大模塊:(1)通過Python網絡爬蟲程序抓取可自定義類型及關鍵字的科技情報,將非結構化數據按指定格式保存到數據庫中;(2)建立基于B/S架構的可視化管理平臺,可實現包括用戶管理、信息檢索、內容訂閱、數據維護、日志管理等功能。程序設計功能框架如圖1所示。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
少兒科學周刊·兒童版(2017年9期)2018-03-15 15:00:11
家庭影院技術(2017年9期)2017-09-26 03:41:45
兒童故事畫報·發現號趣味百科(2017年4期)2017-06-30 12:41:53
商用汽車(2016年11期)2016-12-19 01:20:16
兒童故事畫報·發現號趣味百科(2016年6期)2016-08-19 06:35:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
