基于R語言的齊普夫信息挖掘
2019-06-20 10:31:23張含陽
電子技術(shù)與軟件工程 2019年5期
張含陽

摘要??? 本課題以機(jī)器人產(chǎn)業(yè)領(lǐng)域的數(shù)字媒體為采樣資料,以R語言編程方法為研究工具,詳細(xì)探索齊普夫定律對(duì)于信息挖掘的理論指導(dǎo)意義,進(jìn)一步分析出國內(nèi)數(shù)字媒體對(duì)于機(jī)器人產(chǎn)業(yè)發(fā)展趨勢的關(guān)注點(diǎn)。該方法論同樣適用于其他產(chǎn)業(yè)領(lǐng)域。
【關(guān)鍵詞】齊普夫定律 數(shù)理語言學(xué) R語言編程 采樣 信息挖掘 機(jī)器人產(chǎn)業(yè) 概率
對(duì)于機(jī)器人產(chǎn)業(yè)來說,通過對(duì)于信息資源的數(shù)據(jù)挖掘工作,我們可以理論化地預(yù)測短期內(nèi)的行業(yè)關(guān)注點(diǎn),對(duì)于信息資源的采集和編寫具有指導(dǎo)性意義,以便更好地為雜志定位,為新媒體的數(shù)字信息采集、規(guī)劃提供理論性指導(dǎo),同時(shí)對(duì)產(chǎn)業(yè)發(fā)展重點(diǎn)也有很強(qiáng)的指導(dǎo)意義。
1 文本采樣
為了集中討論齊普夫信息挖掘?qū)τ谛畔①Y源的現(xiàn)實(shí)性意義,本文選定了10篇知名數(shù)字媒體,上發(fā)布的有關(guān)機(jī)器人產(chǎn)業(yè)的文章,且文章內(nèi)容具有較高的代表性。采樣文本充分滿足產(chǎn)業(yè)領(lǐng)域人士的政策性需求、學(xué)術(shù)性需求與實(shí)用性需求。由于齊普夫定律具有廣適性,本文研究方法同樣適用于除機(jī)器人產(chǎn)業(yè)外的其他專業(yè)領(lǐng)域的問題。
樣本源如下:
(1)和訊網(wǎng)(各地政府力推機(jī)器人計(jì)劃,智能制造前景廣闊)
(2)網(wǎng)易新聞(想象空間大,機(jī)器人板塊集體飆升)
(3)新浪新聞中心(學(xué)習(xí)搞不好的孩子不能搞機(jī)器人?)
(4)中國機(jī)器人網(wǎng)(美國科學(xué)家稱未來自主材料能讓機(jī)器人改變顏色和形狀)
(5)新浪科技(智能機(jī)器人首次用于三叉神經(jīng)痛臨床)
(6)財(cái)富中文網(wǎng)(放一百個(gè)心,機(jī)器人不會(huì)反攻人類)
(7)南方企業(yè)新聞網(wǎng)(沈陽獲批籌建國家機(jī)器人質(zhì)量監(jiān)督檢驗(yàn)中心)
(8)百度百家(暖男大白背后:靠譜智能機(jī)器人3元素)
(9)鳳凰財(cái)經(jīng)(巨輪股份機(jī)器人產(chǎn)品市場逐步打開)
(10)雷鋒網(wǎng)(機(jī)器人取代嬰兒做研究:姿勢很重要!)。
經(jīng)統(tǒng)計(jì),采樣文本全文共19886字,基本涵蓋了機(jī)器人產(chǎn)業(yè)中的各個(gè)領(lǐng)域,符合采樣應(yīng)滿足的隨機(jī)性,能夠說明結(jié)果的準(zhǔn)確性。
關(guān)于采樣文本的切分,最理想的處理是把句子切分成最小、最有意義的語言成份——語素。但是語素和作為最小自由活動(dòng)的語言片段的詞之間,常產(chǎn)生很多難以辨認(rèn)的文義現(xiàn)象。再則,中文文獻(xiàn)的體裁不同、風(fēng)格各異。
鑒于以上兩個(gè)因素,本課題做兩點(diǎn)解釋。
(1)由于計(jì)算機(jī)無法詳細(xì)進(jìn)行語義分析,本課題所做的切分嘗試,并非嚴(yán)格按照漢語的語素切分規(guī)則進(jìn)行切分,而是采用計(jì)算機(jī)初篩加人工細(xì)篩相結(jié)合的方式。
(2)按最長切分原則,本課題盡量保持詞意的獨(dú)立性,如“機(jī)器人”不再切分為“機(jī)器”+人”。
2 R語言的應(yīng)用
2.1 何為R語言
R語言是主要用于統(tǒng)計(jì)分析的語言和操作環(huán)境。R編程語言由新西蘭奧克蘭大學(xué)的RossIhaka和RobertGentleman創(chuàng)造,被廣泛應(yīng)用在統(tǒng)計(jì)和科學(xué)領(lǐng)域,在云計(jì)算領(lǐng)域處于領(lǐng)先地位。EEESpectrum推出的最流行的編程語言排行榜中,R語言在數(shù)據(jù)語言中位列第三。2.2利用R語言對(duì)采樣文本的詞語進(jìn)行概率統(tǒng)計(jì)本課題采用R語言對(duì)采樣文本進(jìn)行漢語詞語切分,同時(shí)對(duì)詞語的出現(xiàn)頻率進(jìn)行統(tǒng)計(jì)。本課題采用直接拆分法,分別對(duì)采樣文本的所有兩字詞、三字詞進(jìn)行拆分,并逐個(gè)比較,比如“機(jī)器人產(chǎn)業(yè)”的所有二字組合為“機(jī)器、“器人”“人產(chǎn)”“產(chǎn)業(yè)”,所有三字組合為“機(jī)器人”、“器人產(chǎn)”、“人產(chǎn)業(yè)”。由于語義混亂的詞使用頻率很低,因此也就間接對(duì)所有語素進(jìn)行了過濾,如遇特殊情況,我們可人工對(duì)排序結(jié)果進(jìn)行篩選。
我們先對(duì)雙字詞進(jìn)行頻率排序,其中采樣文本置于F盤下data文檔中。
源代碼如下所示:
p=scan("F:/data.txt","character',sep="\n");#計(jì)算每一行的長度
p.len=nchar(p);
data=p;
#利用標(biāo)點(diǎn)將文章分成句子
sentences-strsplit(data,"、|,|?|。|、”);sentences=-unlist(sentences);
sentences-sentences[sentences!=""];
#計(jì)算句子的長度
length=nchar(sentences);
#將每一一個(gè)句子拆分為雙字詞
divide-function(x,x.len)substring(x,1:(x..len-l),2:x.len);
phrase-mapply(divide,sentences,length,SIM
PLIFY=TRUE,USE.NAMES-=FALSE);
words=unlist(phrase);
#統(tǒng)計(jì)頻數(shù)
words.freq=table(words);
#降序排列
words.freq=sort(words.
freq,decreasing=TRUE);
#顯示結(jié)果
data.frame(Word=names(words.freq[1:200]),F(xiàn)req-=as.integer(words.freq[1:200]);
通過以上代碼,我們就可清晰地得到該采樣文本的雙字詞頻率排序表。通過修改拆分代碼,即“divide-function(x,x.len)substring(x,1:(x.len-1),3:x.len);”,我們可以對(duì)三字詞進(jìn)行頻率排序。
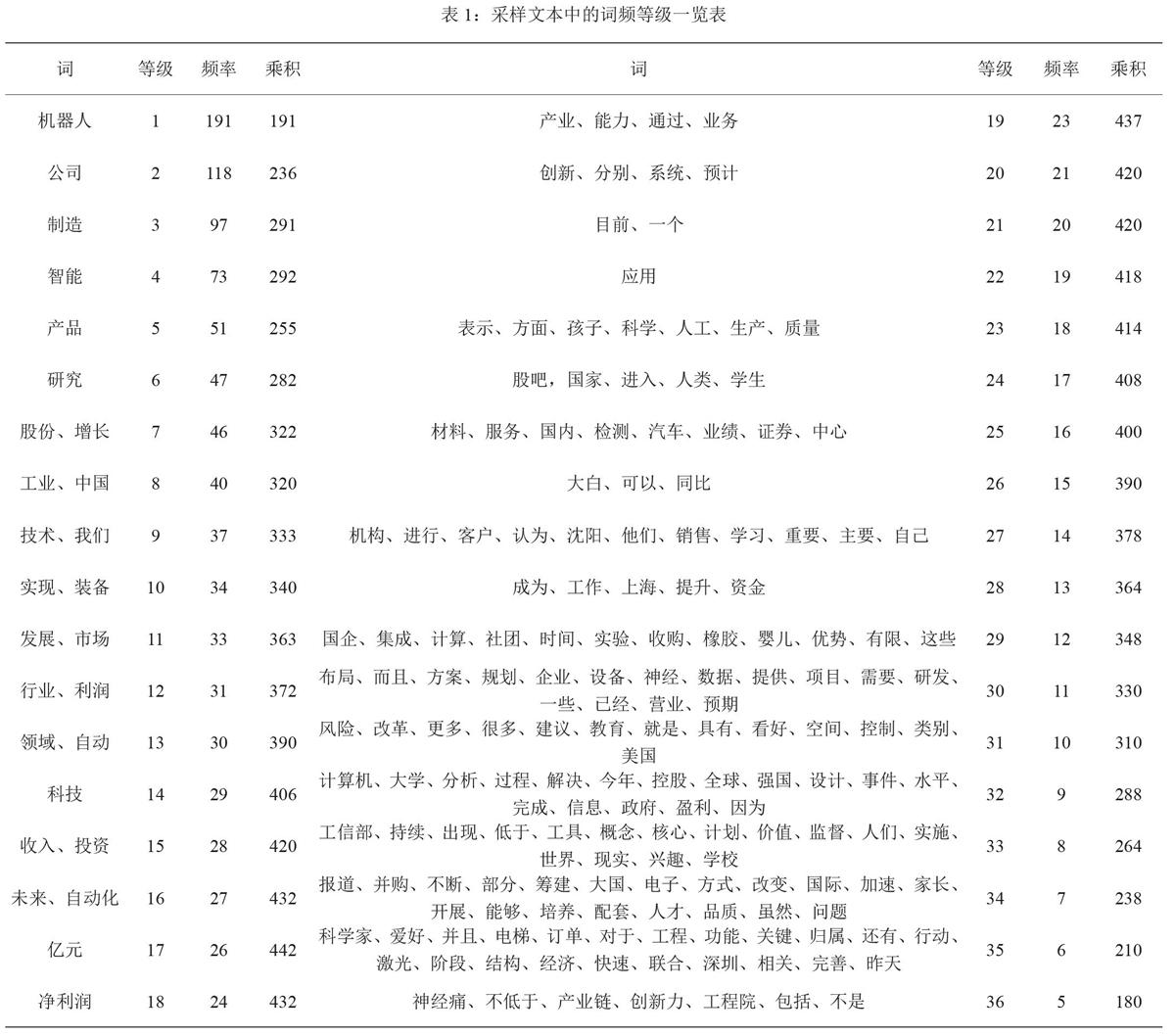
通過以上代碼,我們可清晰地得到該采樣文本的三字詞頻率排序表。整理之后,我們便得到了整個(gè)采樣文本的詞頻統(tǒng)計(jì)表,詳細(xì)列表見附表1。由于低頻詞過多,且對(duì)該課題的研究價(jià)值不大,因此列表中并未詳盡列出全部詞頻等級(jí)的詞匯。
3 利用齊普夫定律進(jìn)行信息挖掘
3.1 齊普夫定律的意義
上世紀(jì)30年代,美國哈佛大學(xué)語言學(xué)教授齊普夫(G·K·Zipf)經(jīng)過對(duì)文獻(xiàn)集中單詞的出現(xiàn)頻率進(jìn)行統(tǒng)計(jì)后發(fā)現(xiàn),雖然各個(gè)作者使用了不同的寫作風(fēng)格,但是文集中單詞的頻次與它的等級(jí)之間均呈現(xiàn)某種限定關(guān)系。齊普夫用文字描述為“最小努力原則”。齊普夫法則是眾所周知的數(shù)理語言學(xué)中的重要法則,這個(gè)法則發(fā)現(xiàn)了在按頻率遞減順序排列的頻率詞表中,單詞的頻率與它的序號(hào)之間存在某種冪律關(guān)系。
齊普夫型分布在社會(huì)現(xiàn)象中處處存在,如詞語分布、收入分布、地理特征分布、生物種屬分布等等。本課題利用齊普夫定律分析信息的深層內(nèi)涵,正是基于它對(duì)社會(huì)科學(xué)很多實(shí)踐活動(dòng)有理論指導(dǎo)作用。文獻(xiàn)計(jì)量學(xué)家海通曾說過,齊普夫定律是解決社會(huì)科學(xué)分布現(xiàn)象最好的定律。
3.2 齊普夫第一定律
如果把一篇較長的文章中每個(gè)詞的出現(xiàn)頻率按遞減順序排列,并編上等級(jí)序號(hào),即頻次最高的詞等級(jí)為1,頻次次之的等級(jí)為2,......,頻次最小的詞等級(jí)為N。若用f表示頻次(frequency),r表示等級(jí)(rank),C和α是參數(shù)。公式如下:
f=Cr-α
根據(jù)齊普夫的研究,凡是高頻率使用的詞,其價(jià)值就較小。同時(shí),低頻詞不常出現(xiàn),其詞義本身在這個(gè)場合中價(jià)值比較少,因此傳遞它們所需要的“力”就不大。因此,最常見且最具有功能的詞是居于中間乘積的中頻詞。經(jīng)驗(yàn)表明,中頻詞往往包含大量有研究價(jià)值的關(guān)鍵詞。那么,本課題的關(guān)鍵就在于如何確定該采樣文本的中頻詞。
齊普夫定律規(guī)定,若采用對(duì)數(shù)軸描繪,中頻詞的等級(jí)直線斜率近似-1。對(duì)于上式兩邊取對(duì)數(shù)后得到?? 公式?? ,可化簡為y=b-kx,即采用對(duì)數(shù)軸描述的齊普夫第一定律是以-k為斜率的直線。也就是說,當(dāng)?? 公式?? 時(shí),該函數(shù)對(duì)應(yīng)的語素為中頻詞。
3.3 齊普夫第一定律在本課題中的應(yīng)用
當(dāng)時(shí),,即中頻詞的頻率與等級(jí)的成績近似為一固定常數(shù)。將表1中的數(shù)據(jù)生成曲線圖(以等級(jí)為x軸,以乘積為y軸),如圖1所示。
我們對(duì)該曲線進(jìn)行多項(xiàng)式趨勢線擬合,多項(xiàng)式的階數(shù)為2階,得到黑色曲線,如圖2所示。
通過觀察擬合曲線,我們可以看到,等級(jí)18可近似視為該凸曲線的拐點(diǎn),那么該點(diǎn)的二階導(dǎo)數(shù)約為0,即?? 公式?? 。由于拐點(diǎn)附近的函數(shù)變化率最小,因此等級(jí)18附近的點(diǎn)更接近某一固定值。我們?nèi)?5-22這個(gè)區(qū)間,令這個(gè)區(qū)間內(nèi)的詞為中頻詞。那么,這些詞代表著它們所需的“力”最大、最具有研究意義。
經(jīng)過篩選,我們將本課題采樣文本中的中頻詞總結(jié)如表2所示。
4 中國機(jī)器人產(chǎn)業(yè)新媒體內(nèi)容的發(fā)展趨勢
綜合分析本課題使用的齊普夫信息挖掘技術(shù),再析回到原文,我們可以得出中國機(jī)器人產(chǎn)業(yè)相關(guān)媒體近期關(guān)注的焦點(diǎn)主要在三個(gè)方面。
(1)對(duì)于機(jī)器人產(chǎn)業(yè)的經(jīng)濟(jì)類的報(bào)道主要關(guān)注于機(jī)器人公司的綜合實(shí)力,包括營業(yè)收入、凈利潤、業(yè)務(wù)發(fā)展?fàn)顟B(tài)。同時(shí),各種投融資機(jī)構(gòu)、基金、股票市場對(duì)于機(jī)器人產(chǎn)業(yè)的行情預(yù)測也是各類媒體關(guān)注的焦點(diǎn);
(2)對(duì)于機(jī)器人產(chǎn)業(yè)的方針政策的報(bào)道主要集中在提高中國機(jī)器人企業(yè)的創(chuàng)新能力的制度建設(shè)、產(chǎn)業(yè)各環(huán)節(jié)的新政策、新方針;
(3)對(duì)于機(jī)器人產(chǎn)業(yè)的技術(shù)類的報(bào)道主要關(guān)注于機(jī)器人領(lǐng)域的自動(dòng)化或自動(dòng)控制相關(guān)技術(shù)、機(jī)器人的系統(tǒng)集成,以及機(jī)器人產(chǎn)品的應(yīng)用工程。
5 結(jié)語
社會(huì)學(xué)科研究正在走向定量化的發(fā)展方向,整個(gè)科學(xué)研究群體的特征呈現(xiàn)專業(yè)化和綜合化之勢,單純憑直覺和經(jīng)驗(yàn)的信息挖掘?qū)⒈恢鸩教蕴R普夫信息挖掘技術(shù)就成為了解釋各個(gè)領(lǐng)域內(nèi)在規(guī)律的最有效的定律。而利用R語言強(qiáng)大的統(tǒng)計(jì)分析能力支持齊普夫定律的運(yùn)用,則使得信息資源的詞頻與齊普夫分布的擬合實(shí)現(xiàn)更快速、更標(biāo)準(zhǔn)的概率化統(tǒng)計(jì),對(duì)各個(gè)媒體的信息資源挖掘?qū)a(chǎn)生深遠(yuǎn)意義,對(duì)指導(dǎo)產(chǎn)業(yè)發(fā)展的關(guān)注重點(diǎn)提供了一種更精準(zhǔn)的方法論。
參考文獻(xiàn)
[1]徐文霞.齊普夫定律與中文詞頻分布機(jī)理[J].情報(bào)科學(xué),1986(01):29.
[2]劉光牛,南雋,劉瀅.中國傳媒全媒體發(fā)展研究報(bào)告[J].科技傳播,2010,2-81.
[3]楊霞,吳東偉.R語言在大數(shù)據(jù)處理中的應(yīng)用[J].信息技術(shù),2013(10):19.

- 電子技術(shù)與軟件工程的其它文章
- 無線傳感器網(wǎng)絡(luò)節(jié)點(diǎn)多目標(biāo)安全優(yōu)化部署
- 發(fā)電機(jī)變壓器通過荷蘭KAMA實(shí)驗(yàn)室短路試驗(yàn)
- 基于信息安全的計(jì)算機(jī)網(wǎng)絡(luò)應(yīng)用
- 運(yùn)用層析分析法建立醫(yī)院治療模式的評(píng)估模型
- Oracle數(shù)據(jù)庫應(yīng)用系統(tǒng)性能優(yōu)化技術(shù)及其集群技術(shù)的實(shí)施
- 空間目標(biāo)監(jiān)視仿真系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)