基于PLS和組合預測方法的冬小麥收獲指數高光譜估測*
2019-07-03 05:51:54徐新剛杜曉初楊貴軍趙曉慶魏鵬飛王玉龍范玲玲
中國農業信息 2019年2期
關鍵詞:模型
陳 幗 ,徐新剛 ,杜曉初 ,楊貴軍 ,趙曉慶 ,魏鵬飛 ,王玉龍 ,范玲玲
(1. 湖北大學資源與環境學院,武漢430062;2. 農業部農業遙感機理與定量遙感重點實驗室/北京農業信息技術研究中心,北京100097;3. 國家農業信息化工程技術研究中心,北京100097)
0 引言
收獲指數(Harvest Index,HI)指收獲時作物籽粒產量和地上部生物量的比值,又名經濟系數,是選擇作物品種和品種改良研究中的重要參考因子[1]。收獲指數通常可以通過田間取樣獲得,但需要耗費較大的人力、物力,并具有一定滯后性。遙感技術擁有動態、快速和準確獲取地表作物參數信息的優勢,隨著遙感監測技術的快速發展,通過遙感手段獲取收獲指數將成為未來收獲指數評價的發展趨勢[2]。
當前,基于遙感技術的作物收獲指數遙感估算已開展了初步研究。杜鑫等[3]利用遙感技術監測作物收獲指數的可行性分析研究,基于HI的形成過程總結歸納出3類利用遙感技術實現HI估測的方法,為如何利用遙感方式估算收獲指數提供了借鑒思路。Moriondo等[4]基于時間序列NDVI(歸一化植被指數)遙感信息,利用小麥開花前后NDVI均值比作為指示特征,開展小麥的收獲指數遙感提取研究,但是該方法需要首先確定提取區域內最大收獲指數和其可能會有的變動幅度,不同的取值一定程度會影響收獲指數估算結果。基于Moriondo等的研究,任建強等[5]做了方法改進,利用MODIS衛星遙感影像獲取冬小麥生長期內時間序列NDVI數據,以小麥開花前的NDVI累計值與花后NDVI累計值的比值作為指示HI的遙感指數,很好地估測了區域冬小麥的收獲指數,反演結果與實測結果的R2達到了0.49。上述方法,盡管很好地實現區域尺度作物HI的遙感估測,但需要作物生長季內逐日或者短周期間隔的時間序列衛星遙感影像,數據處理工作量巨大。
另一方面,由于作物收獲指數反映了作物光合產物在籽粒和營養器官上的分配比例,它與作物不同生育期植株體內光合產物的形成、運轉過程息息相關,并受到諸多因素的影響,因此,作物不同生育期的生長對作物最終收獲指數的形成都具有或多或少的影響,如何來刻畫不同生育期對作物HI的影響貢獻,組合預測方法提供了一種可能途徑。文章通過獲取的冬小麥多生育期多時相地面冠層高光譜數據,開展小區田塊尺度的作物收獲指數高光譜估測研究,通過引入最優組合預測方法,將基于不同生育期光譜信息建立的不同冬小麥收獲指數光譜估測模型進行組合,通過優化算法賦予最優權重,從而構建組合估測模型實現冬小麥收獲指數的高光譜估測,相關的研究并不多見。該文提出的作物收獲指數遙感光譜估測方法,嘗試利用權重最優組合算法,以達到充分利用作物多個生育期有用信息進而改善收獲指數估算精度的目的,以期為基于多時相光譜信息的HI遙感估算提供新的方法參考。
1 研究區與研究方法
1.1 研究區域
實驗區位于北京郊區的順義區和通州區,該區域屬于暖溫帶半濕潤大陸性季風氣候。年平均溫度11.3℃,年平均降水量在620 mm左右。氣候宜人,地形平緩,適宜耕種。為展開研究,在順義區和通州區種植基地中隨機挑選出27個采樣點,采樣選取大田塊、生長具有代表性冬小麥地塊進行實驗獲取數據。
1.2 冬小麥冠層光譜測定
實驗于2009—2010年冬小麥生長季開展,分別選取冬小麥起身期、拔節期、孕穗期、開花期和灌漿期,對冬小麥冠層進行光譜測定。測定日期分別為:2010年4月1日、4月17日、4月29日、5月17日和6月2日。測量光譜儀選用ASD Field Spec FR2500,光譜范圍350~2 500 nm,采樣間隔為1 nm。盡量選擇在天氣晴朗時測定,測定時間為北京時間10: 00~14: 00。測定時,探頭始終垂直向下且保持與地面約為1 m的距離,探頭視場角為25°。在每個采樣點測量10次,取平均值為光譜測定的結果。在每個采樣點測定前、后立即進行標準白板矯正。在進行植被指數計算時,為排除干擾波段,僅僅選用敏感度較高的400~1 100 nm作為有效分析數據。
1.3 收獲指數測定
選取研究區內共27個實測樣區。其中,通州區、順義區樣區數分別為15個和12個。樣區位置的選擇充分考慮了冬小麥生長狀況和區域分布的代表性,且樣區面積均不小于100 m×100 m。采用五點取樣法進行取樣,拷種稱量后,剪掉根部,只保留地上生物量部分進行晾曬,之后稱量5采樣點冬小麥干重記錄為M。隨后進行脫粒處理,稱取籽粒的重量記錄為M′,這樣每個采樣點的實測收獲指數HI即為兩者重量的比值。該實驗測得的結果HI,即為試驗區域內冬小麥收獲指數的實際測量值。該值將被用于構建單個生育期的預測模型以及驗證組合預測模型所計算結果的精度。計算公式為:

式(1)中,HI為收獲指數,M′為小麥籽粒重量,M為小麥干重。
1.4 植被指數選擇
到目前為止,植被指數的種類已經達到了100多種,并在各個領域得到了廣泛應用。由于關于收獲指數的研究成果有限,能夠明顯反映收獲指數大小的植被指數還在探索中,但是收獲指數的大小與作物光合作用關系密切[6],在選擇植被指數構建模型時,可以將對光合作用有關的因素列入考慮范圍,如葉面積大小、溫度、施氮水平、葉綠素含量等。
在挑選出的植被指數中,NDVI(歸一化差值植被指數)、DVI(差值植被指數)、RVI(比值植被指數)、EVI(增強植被指數)、OSAVI(優化土壤調整植被指數)等均屬于常用的植被指數,而后學者們為了估測水稻大葉面積指數,在NDVI的計算公式上進行了改良,提出了GBNDVI(綠藍波段歸一化植被指數)、GRNDVI(紅綠波段歸一化植被指數)、RBNDVI(紅藍波段歸一化植被指數)、BNDVI(藍波段歸一化植被指數),這些改良的植被指數也被挑選為反演參數。常用于監測葉綠素含量的植被指數有:NPCI(歸一化色素葉綠素植被指數)、TCARI(轉化葉綠素吸收反射指數)、MCARI 2#(改進葉綠素吸收比率指數II)、GVI(綠度植被指數)等;植被含氮量估測常用的植被指數有:NDRE(歸一化紅邊指數)、MTCI(MERIS陸地葉綠素指數)、SIPI(結構不敏感色素指數)、PPR(植被色素比率)等;除此之外,該研究還引入了一些新型的植被指數作為對比參考,如DPI(雙峰值指數)、REP-li(線性內插法紅邊位置指數)、PSRI(三波段比值指數)、MSR(改進比值植被指數)等。
綜合以上,共計44種植被指數被列為反演參數。計算時,分別選擇620~760 nm、492~577 nm、400~450 nm、700~1 100 nm的波段范圍內平均反射率作為紅光(R)、綠光(G)、藍光(B)和近紅外(NIR)波段的反射率值。其詳細的計算公式和引用文獻如表1所示。
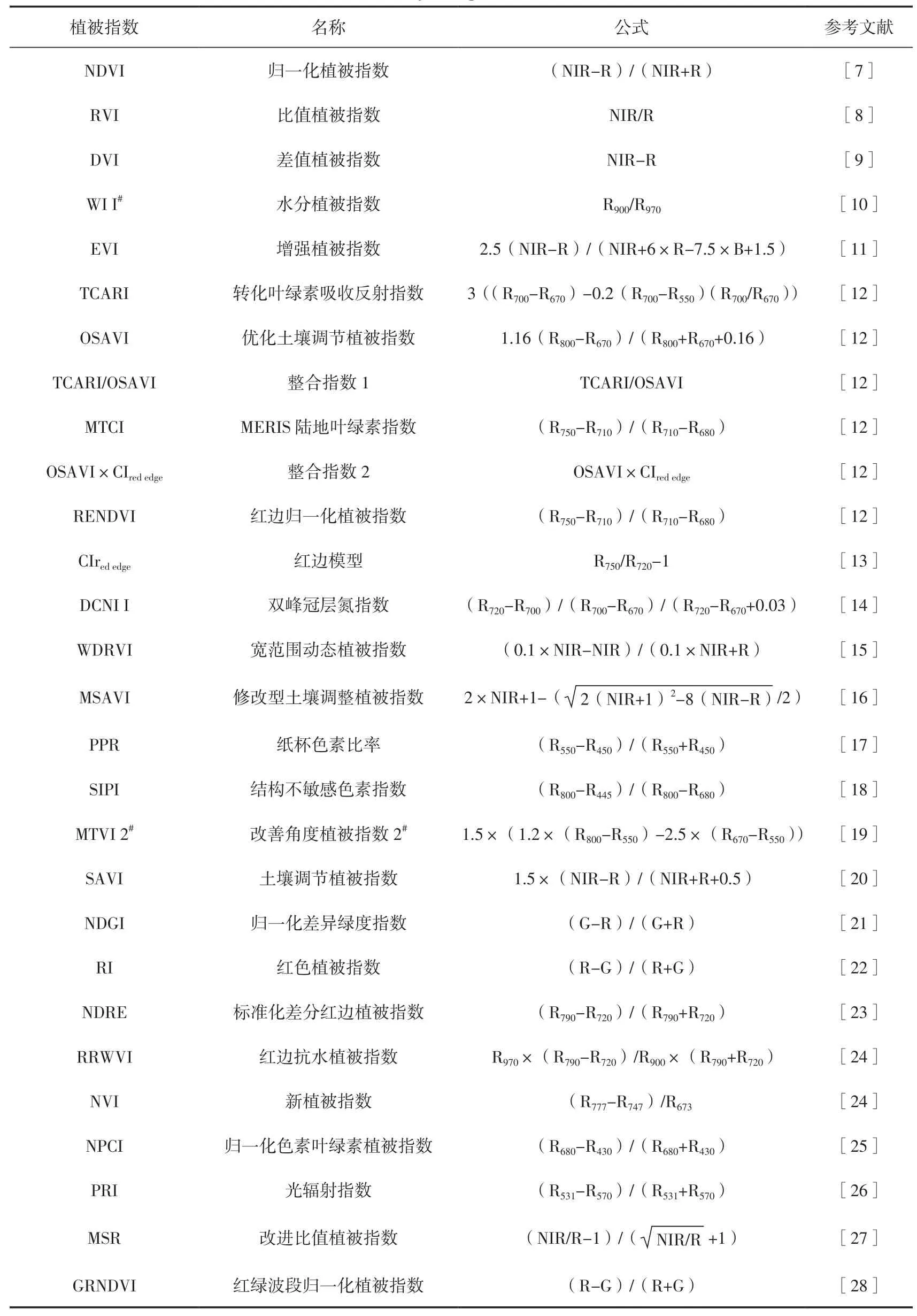
表1 采用的植被指數Table 1 Summary of vegetation indices studied

續表
1.5 統計分析
將測定出的冬小麥5個生育期的冠層光譜數據,代入表1所列公式進行計算。按照不同生育期,排列出27個取樣點對應的44個植被指數值,并將每個生育期的44種植被指數與冬小麥實測收獲指數HI之間建模,進行相關性計算。選擇決定性系數(R2)和均方根誤差(RMSE)作為指標,將所計算的結果進行排序,挑選R2較大同時RMSE盡量較小的5個植被指數作為篩選結果。
1.6 偏最小二乘建模
偏最小二乘法(Partial Least-Square,PLS)是一種多元統計分析法,具有計算簡單、建模預測精度高、解釋性強等優點。PLS通常用于解決對于多個因變量和多個自變量的回歸建模等問題,當解釋變量的個數遠超過樣本個數或者解釋變量內部存在多重共線性時,PLS能運用成分提取的方法,解釋變量與因變量的相關性[34]。研究中篩選出的植被指數即為解釋變量,實測收獲是因變量,將二者利用PLS結合后,得到每個生育期的單個預測方程。與其他線性模型一樣,PLS的最終結果也是一個線性模型,其方程為:
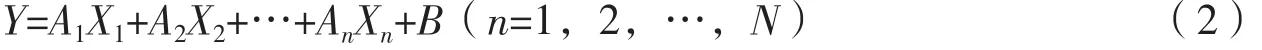
式(2)中,Y是因變量,即實測收獲指數;X1~Xn是用于構建模型的植被指數;A1~An是對應植被指數的系數;B是殘差參數。使用PLS得到A1~An和B的值,即可得到單個生育期的預測方程。
1.7 組合預測法
組合預測法是采用兩種或者兩種以上不同的預測方法,對同一對象進行預測,對各單獨的預測結果適當加權綜合后作為其最終結果[35]。這種方法能聚集各個預測方法的有用信息,使得組合模型的精度優于其中任意一個單一模型的模擬精度,從而達到提高預測收獲指數精度的目的。研究采用組合預測法確定每個生育期對于最終收獲指數值的貢獻程度,即計算出每個生育期對應的權重。確定權重的算法很多,該文采用最優加權算法,評價最優的標準為使組合預測偏差值之和最小。公式為:
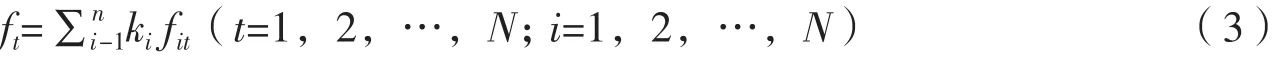
式(3)中,ft代表第i種預測方法在t時刻的預測值,為第i種預測方法的權系數,且滿足
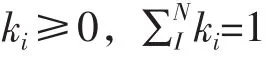
根據最小二乘法,當殘差平方和達到最小,變權系數達到最佳。設et為t時刻組合預測的偏差,則計算最佳變權系數的方程組為:

式(4)中,k1~kN是需要求解的系數,代表單個生育期的預測方程在組合預測中的權重。最后,用實測的數據和組合方程預測出的收獲指數值進行驗證。
2 研究結果
2.1 相關性分析
將5個生育期內的植被指數和實測植被指數進行相關性分析,計算出R2和RMSE,并進行排序,選取每個時期中R2盡可能大和RMSE盡可能小的5個最優植被指數,結果如表2所示。每一項植被指數與收獲指數的R2都非常低,均沒有超過0.3,拔節期內所有植被指數與實測收獲指數的相關性幾乎趨近于0,且RMSE也出現了非常巨大的值。可以看出,單個生育期的單個植被指數與實測收獲指數的相關性太低,因此篩選5個最優植被指數與收獲指數構建模型。

表2 不同生育期最優植被指數Table 2 Optimal vegetation indices in different stages
2.2 單生育期與收獲指數的PLS建模
利用5個生育期中的最優植被指數與PLS結合,建立冬小麥收獲指數的估算模型,可以得到經過建模后,單生育期的預測模型。將模型中得到的預測值與實測的收獲指數進行相關性分析,按照生育期進行順序排列,結果如表3所示。相對于單個植被指數擬合,單生育期的多個植被指數擬合的結果在相關性方面有了明顯提高,能明顯看出單個生育期預測方程對于最終結果的影響大小。但是,只有灌漿期擬合結果的R2超過了0.4,其余4個時期與實測值的相關性都不明顯;5個RMSE相較于單個生育期擬合而言,結果有了明顯優化,且結果相對穩定,沒有太大起伏。說明在經過PLS建模之后,單個生育期的擬合已達到最優狀態,但是精度并不足以支持預測方程成立,需要進一步提高。

表3 植被指數與PLS結合預測收獲指數的結果Table 3 Performance of the combination of vegetation indices and PLS for predicting harvest index
2.3 組合預測建模
利用組合預測的方法,計算出了最優變權系數,將系數得到組合預測的方程為:
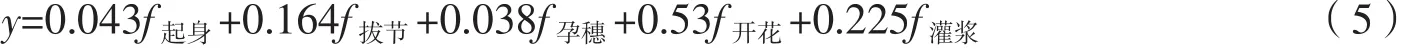
式(5)中每個單生育期預測方程前的系數,代表單個生育期對最終結果的貢獻程度,即在組合預測方程中,單生育期預測方程的權重系數。這些系數根據前文中式(4)所列出的方程計算而出。
將各生育期的預測結果帶入組合預測方程中,得到最終的預測結果。建立實測地面冬小麥收獲指數與組合預測結果的關系為:

式(6)中,x為組合預測得到的參數,y為預測出的收獲指數,詳細結果由圖1所示。由圖可以看出,相較于單個生育期的預測結果而言,RMSE的變化不大,比單個預測模型中的最小值只降低了0.003,但是R2有了顯著提升,較單個預測模型的最大值提升了0.13。根據前文所述,組合預測法具有提取單個預測模型中有效信息的功能,單個預測模型的有效信息越多,代表單個模型的貢獻度越大,在組合預測中被賦予的權重就越大,反之則越小。由式(5)可以看出,開花期和灌漿期的單個預測模型在組合中權重最大,這與冬小麥栽培種植的特征基本吻合。由于前3個生育期的時間較短,作物光合產物的累積量不及后兩個生育期的累積量充足,而收獲指數的確定與光合作用累計的生物量密切相關,所以時間間隔最長的開花期相較于其他生育期對于收獲指數的影響力最大,因此相關性最高,權重最大。因此,運用組合預測的算法,可以成功篩選出單個預測模型中的有效信息,利用最優加權組合預測模型的精度比起單個模型預測的精度提升明顯。表明組合預測的方法能夠為利用遙感數據信息估算收獲指數提供有效的方法途徑。
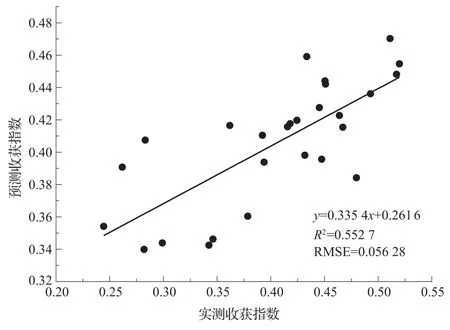
圖1 組合預測值與冬小麥收獲指數關系Fig.1 Relationship between combination predicted value and winter wheat harvest index
3 結論
單一生育期的植被指數與實測收獲指數相關性較低,在挑選出每個生育期中相關性最合適的5個植被指數后與PLS建模,相關性有所提高但依然很低,值最高的R2來自灌漿期為0.42,對應的RMSE為各生育期預測值中最低為0.06,說明PLS的確具有能提升預測精度的能力,可是在該研究中,PLS與單一生育期建模并不能達到理想的預測標準。在利用組合預測法構建方程以后,預測值與實測值的相關性有了明顯提高。研究結果表明,在多種不同的方法進行預測時,使用組合預測法可以有效起到提取有用信息的作用,從而可以提高對冬小麥收獲指數的估算精度。利用組合預測法得到的預測結果與實測結果的R2能達到0.55,對應的RMSE為0.06。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
