基于高光譜技術的香腸亞硝酸鹽快速檢測方法
2019-07-03 02:07:34劉崢殷勇
食品與機械 2019年5期
劉 崢 殷 勇
(河南科技大學食品與生物工程學院,河南 洛陽 471023)
在香腸的制作過程中,為了呈現良好的色澤和防止腐蝕,會加入一定量的亞硝酸鹽。隨著香腸存放時間的延長,原先添加的亞硝酸鹽會分解消耗掉一部分,而香腸中的肉品本身也會產生一部分亞硝酸鹽,導致香腸在儲藏過程中亞硝酸鹽含量不斷變化,存在不確定性。由于亞硝酸鹽的毒性強,攝入過多時會讓血液中的血紅蛋白轉化成高鐵血紅蛋白,失去輸送氧氣的能力,使組織產生缺氧,引起紫紺現象甚至死亡[1]。
現階段,檢測食品中亞硝酸鹽的主要方法有高效液相色譜法[2]、國際格里斯(Griess)試劑比色法[3]、熒光光度法[4-5]、毛細管電泳法[6]、離子色譜法[7]等。雖然這些方法較為普遍,但是存在操作復雜,對環境敏感,適用范圍窄等問題。而高光譜技術具有可視性、快速性等優點,在水果[8-9]、小麥[10]、玉米[11]、茶葉[12]等農副產品品質檢測中得以廣泛地運用。文獻檢索發現,利用高光譜技術針對肉制品中亞硝酸鹽檢測的研究報道比較少。陳曉東等[13]利用高光譜技術研究了香腸中亞硝酸鹽的預測方法,指出了高光譜技術檢測香腸中亞硝酸鹽的可行性。但是,該文是基于主成分分析提取的特征所構建的預測模型還不能較好地滿足實用要求,模型最高預測精度僅為0.918。本試驗擬從回歸模型輸入信息的選擇方面作為切入點嘗試提升高光譜技術檢測香腸在儲藏過程中亞硝酸鹽含量的準確性。
1 材料與方法
1.1 試驗材料
香腸樣品:雙匯潤口香甜王玉米風味香腸,購于超市。樣品保質期為120 d,儲藏方式與購買時超市的存放方式相同,即自然條件(溫室環境)下儲藏。由于購買日期是生產日期的第29天,所以試驗選取儲藏30,50,70,90,110,130,150 d的香腸樣品進行亞硝酸鹽含量檢測。每個樣品分別選取40個樣本,每個樣本含量為(24.0±0.5) g,包含21個香腸切片。其中,任選30個樣本構造訓練集,共210個樣本;剩余的10個樣本構造測試集,共70個樣本。在模型構建中,隨機生成3組訓練集及其對應的測試集來分別構建模型和校驗模型,以說明研究結果的可靠性。
1.2 高光譜系統
實驗采用的高光譜系統是由計算機、光譜儀(IST 50-3810型,德國Inno-spec公司,光譜范圍為371.05~1 023.82 nm,涵蓋可見光和部分近紅外光譜)、4個500 W 的光纖鹵素燈(RK90000420108型,德國Esylux公司)和傳送裝置等組成。其示意圖與性能參數與劉燕德等[14]使用的裝置相同。
1.3 樣本高光譜數據采集和校正
在采集樣品高光譜數據時,將香腸樣品切片平鋪在規格為10 cm×1 cm的培養皿中,再將盛有樣品的培養皿放置在傳送帶上,帶速2 mm/s,用SICap-STVR V1.0.x 控制驅動,獲得高光譜信息采集結果。每個測試樣本的高光譜反射值采用ENVI 4.8軟件提取,最終可以采集到1 288個波段的高光譜反射值。在采集樣本的高光譜圖像時,須進行黑白校正。具體校正方法為:白板校正是使用白色特氟龍(Teflon)標準矯正板進行掃描得到全白的標定圖像,黑板校正則是關閉光源及相機鏡頭得到全黑的標定圖像。
其他數據處理方法均在Matlab 2014a平臺上實現。
1.4 光譜預處理
采集高光譜信息時,會受到高光譜儀器的電路噪聲干擾,而且樣品表面不平整也會影響到原始光譜數據的采集。所以,為了減少這些外界因素對光譜信息的干擾,在建立模型之前需對原始光譜數據進行預處理。采用Savitzky-Golary卷積平滑法(SG平滑)對原始光譜數據進行預處理[15-16]。Savitzky-Golary卷積平滑法是通過多項式來對移動窗口內的數據進行多項式最小二乘擬合,其實質是一種加權平均法,更強調中心點的中心作用[17]。
1.5 香腸中亞硝酸鹽含量測定
采用GB 5009.33—2016的檢測方法。對所選擇的每個儲存時間的樣品進行3次平行樣本測試,取平均值作為檢測結果。
1.6 特征波長的提取
因高光譜信息共有1 288個波段的光譜數據,數據繁多,會提高建模時的復雜度,所以在高光譜分析中通常會進行特征波長的提取[18-19]。在特征波長提取方法上,常用偏最小二乘回歸系數大小作為選擇特征波長的依據[20-21]。因此,采用偏最小二乘回歸系數提取特征波長。
1.7 香腸中亞硝酸鹽的定量分析方法
1.7.1 多元回歸 多元回歸是對相關隨機變量進行預測,確定這些變量之間數量關系的可能形式,并用數學模型來表示。多元回歸模型的精確度由決定系數(determination coefficients,R2)、均方根誤差(root mean squared error,RMSE)2個指標決定,R2越接近于1,精度越高,模型越穩定,RMSE越小,模型的預測能力越高。
1.7.2 主成分回歸 主成分回歸(PCR) 是目前處理高維復雜數據時非常有效的方法之一。它可以對復雜的高維數據進行降維,在不丟失主要數據信息的情況下選擇維數較少的新變量來代替原來較多的變量,以排除眾多信息共存中相互重疊的現象以及夾雜的噪聲等干擾,還可以解決高維數據的多重共線性問題,從而使預測結果更加準確合理。本研究采用R2和RMSE進行評價,R2越接近于1,精度越高,模型越穩定,RMSE越小,模型的預測能力越高。
1.7.3 偏最小二乘回歸 偏最小二乘回歸(PLSR)是一種多元統計數據分析方法,可以同時實現回歸建模、簡化數據結構和分析2組變量間的相關性。PLSR模型預測精度取決于R2、RMSE兩個指標,R2越接近于1,精度越高,模型越穩定,RMSE越小,模型的預測能力越高。
2 結果與分析
2.1 香腸中亞硝酸鹽的含量
由表1可知,香腸在儲藏過程中亞硝酸鹽含量是變化的、不確定的。因此,對香腸儲藏過程中亞硝酸鹽的檢測、監控是必要的。
2.2 光譜預處理
為了減少外界因素對于光譜信息的干擾,需對原始光譜數據進行SG平滑處理。從圖1、2中可以看出,經過SG平滑法處理過的光譜曲線相較于原始光譜曲線更平滑,受到的噪音影響很小,有利于后期模型的建立。
表1 亞硝酸鹽理化試驗結果
Table 1 Physicochemical test results of nitrite content
圖1 原始光譜圖
圖2 經SG平滑處理后的光譜圖
2.3 特征波長的篩選
可見—近紅外高光譜中波長范圍是371.05~1 023.82 nm,但試驗操作過程中由于首尾波段受環境及儀器噪聲影響較為嚴重,因此在光譜信息分析的過程中應只考慮400~1 000 nm波段下的信息。對全波長數據經偏最小二乘回歸分析后,得到的回歸曲線如圖3所示。第1主成分涵蓋的信息較為全面和常見,波動較小,不能較好地體現樣本間的差異;第2主成分有一定的波動,可部分體現樣本間的差異,所以選取第2主成分回歸系數的最大值和最小值所對應的波長作為2個特征波長;第3主成分波動明顯,可較好地體現樣本間的差異,所以選取第3主成分所有波峰和波谷的回歸系數所對應的波長作為特征波長。這樣,第2主成分有2個特征波長,第3主成分有27個特征波長,共計29個特征波長。
2.4 特征波長下的定量分析
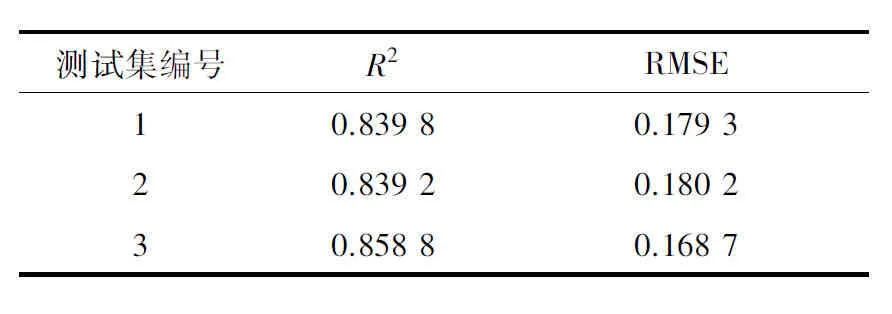
2.4.1 特征波長下多元回歸建模 直接將29個特征波長作為模型的輸入變量,進行回歸分析。圖4給出了第1組數據集的預測結果。由圖4可以看出,預測值與真實值相差較大,預測結果精確度不高。表2給出了3組測試集模型預測結果的R2與RMSE,從表2中可以看出,3組預測集R2最高為0.858 8,對應的RMSE為0.168 7,預測結果不理想。考慮到各個特征波長之間會存在一定的相關性,影響建模的精度,故嘗試建立特征波長下主成分回歸和偏最小二乘回歸的預測模型。
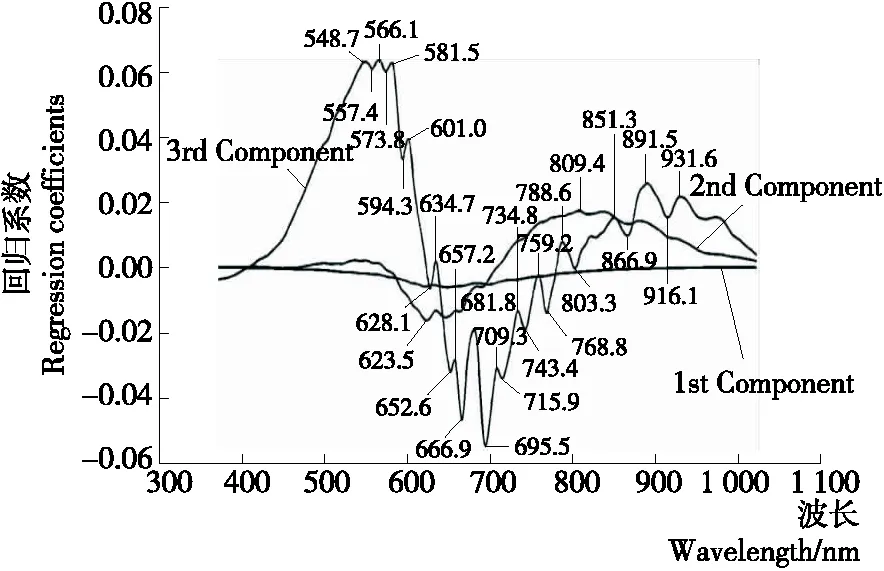
圖3 權重系數圖
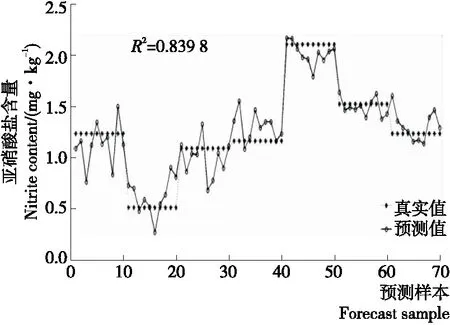
圖4 特征波長下多元回歸結果
2.4.2 主成分回歸模型的定量分析 對29個特征波長變量進行PCA分析,得到按貢獻率從大到小排序的29個主成分。經比較,在提取前26個主成分時預測結果準確性相對較高,如圖5所示(以第1組測試集為例,下同)。表3為3組測試集模型預測結果的R2與RMSE,從表3中可以看出, 3組測試集的預測結果的R2最高為0.896 1,對應的RMSE為0.148 8,模型精度仍不理想。
表3特征波長下的主成分回歸與偏最小二程回歸結果
Table3Principalcomponentregressionandpartialleastsquaresregressionresultsatcharacteristicwavelengths
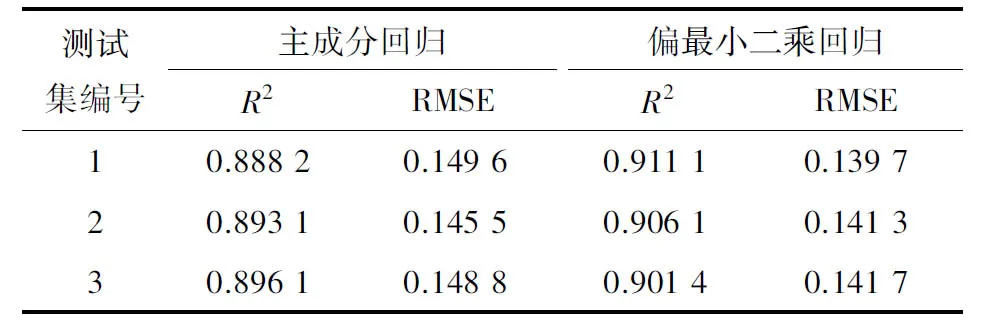
2.4.3 偏最小二乘回歸模型的定量分析 對于PLSR模型的構建,經比較,同樣在提取前26個主成分時預測結果相對較高,如圖6所示。表3給出了3組測試集模型預測結果的決定系數與均方根誤差,從表3中可以看出,3組測試集的預測結果的決定系數R2最高為0.911 1,對應的均方根誤差RMSE為0.139 7。模型精度有所提高,但還是不太理想。
綜合基于特征波長的檢測結果來看,在特征波長下建立PCR和PLSR預測模型的結果雖然比直接回歸建模分析的結果較優,但仍不很理想,且模型的變量僅降到26個,比29個特征波長并無明顯的減少,建模的復雜度仍較高。陳曉東等[13]在用主成分分析方法提取特征波長的基礎上構建了預測模型,但預測精度只有0.918,且數據處理過程繁雜。這可能是選擇特征波長表達的信息不夠全面,不能充分體現原始數據的信息,從而導致了預測模型的精度不高。而岳學軍等[22]采用全波長數據信息作為模型輸入向量較好地實現了對柑橘葉片葉綠素含量的檢測。受此啟發,本試驗嘗試了在全波長下建立PCR和PLSR預測模型的效果。
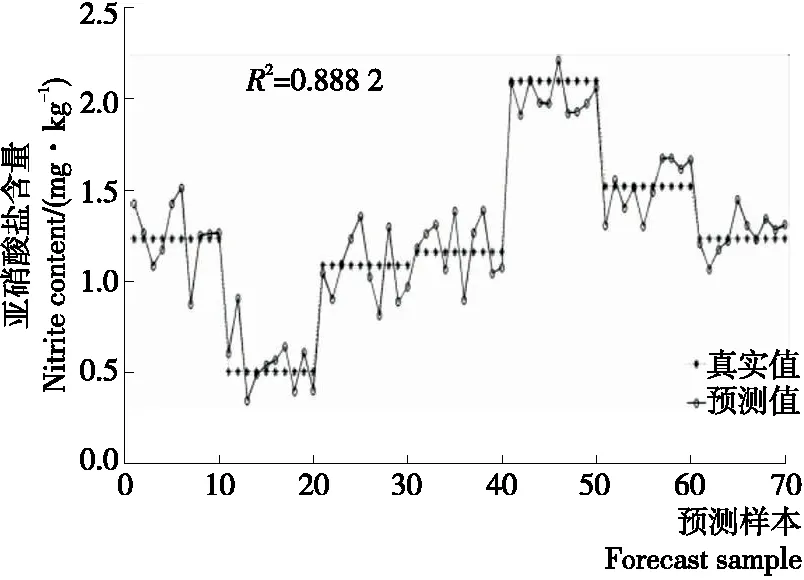
圖5 特征波長下主成分回歸結果
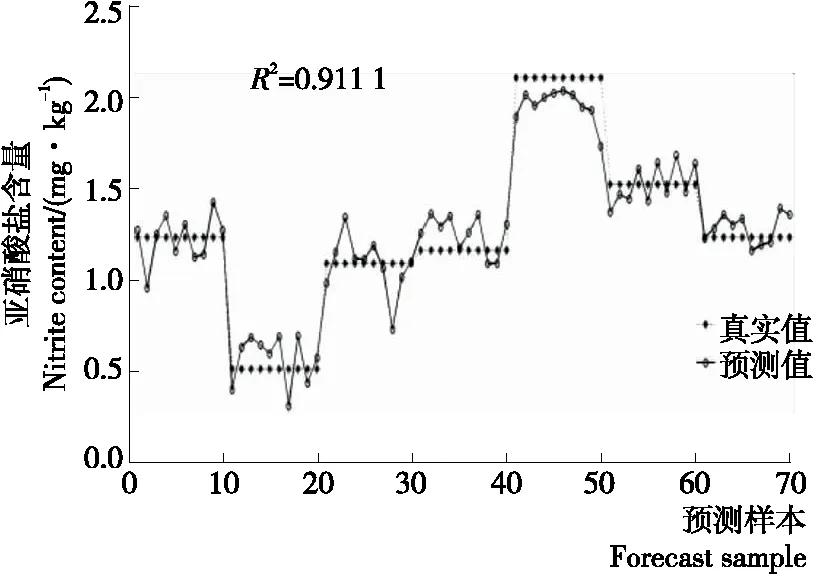
圖6 特征波長下偏最小二乘回歸的結果
2.5 全波長下的定量分析
為了克服特征波長不能充分表征原始光譜信息這一問題,本試驗對1 288個全波長數據進行PCA分析;同時選取前29個主成分作為回歸模型的輸入向量,這樣可以與特征波長下的定量分析結果形成對比。
2.5.1 主成分回歸的定量分析 在全波長下建立PCR預測模型,基于前29個主成分構建的模型得到的預測結果如圖7所示。從圖7中可以看出,預測值與真實值較為接近,預測結果精確度提高。表4為3組測試集模型預測結果的R2與RMSE,從表4中可以看出,3組測試集模型預測結果的R2最高為0.952 2,對應的RMSE為0.097 4。模型精度較高,預測結果較為理想。
2.5.2 偏最小二乘回歸的定量分析 在全波長下建立PLSR預測模型,其主成分變量仍為前29個,得到的預測結果如圖8所示。圖8表明,預測值與真實值非常接近,預測結果精度很高。表4為3組測試集模型預測結果的R2與RMSE,從表4中可以看出,3組測試集模型預測結果的R2最高為0.982 9,對應的RMSE為0.059 2。模型精度很高,預測結果非常理想。
預測結果可以表明,全波長下建立的預測模型結果精確度較高,且偏最小二乘回歸的結果高于主成分回歸的,決定系數可以高達0.978 8以上。因此,在全波長下建立偏最小二乘回歸的預測模型可以滿足檢測要求。綜上研究認為,在全波長下建立的主成分回歸和偏最小二乘回歸預測模型,將變量也降低到了29個,遠低于1 288個波長,省去了特征波長的選擇計算,不僅簡化了數據處理步驟,而且還能得到較為理想的預測結果。另外,也可以認為,全波長下的前29個主成分可以較充分地表征原始光譜數據的信息。
表4全波長下的主成分回歸與偏最小二乘回歸結果
Table4Principalcomponentregressionandpartialleastsquaresregressionresultsatfullwavelength
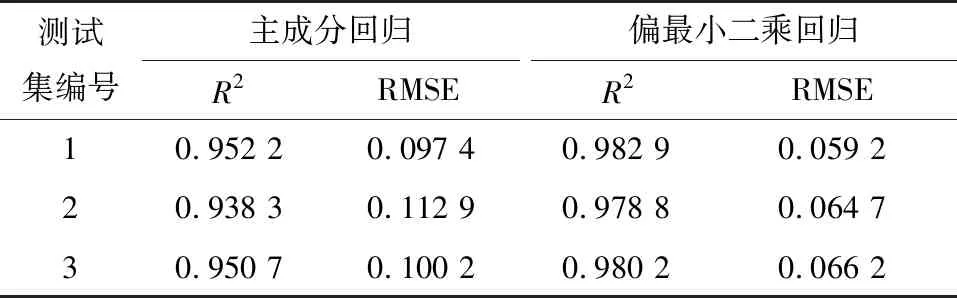
測試集編號主成分回歸R2RMSE偏最小二乘回歸R2RMSE10.952 20.097 40.982 90.059 220.938 30.112 90.978 80.064 730.950 70.100 20.980 20.066 2
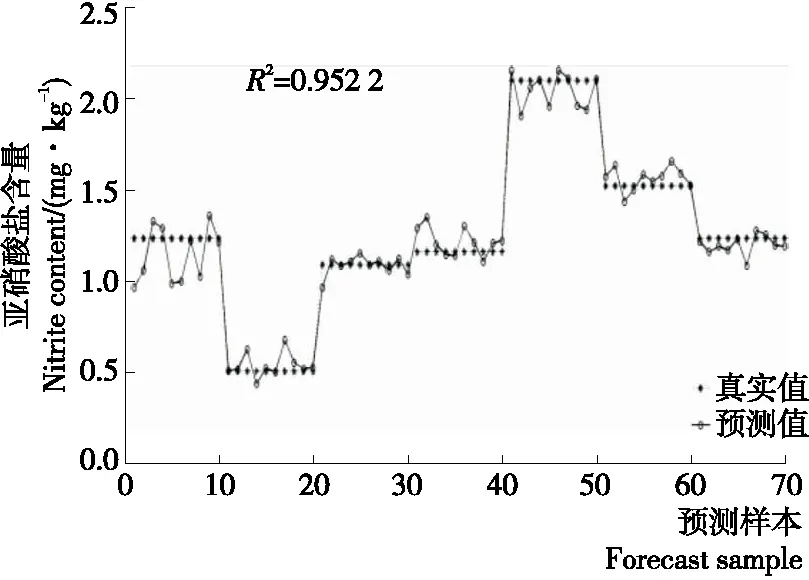
圖7 全波長下主成分回歸的結果
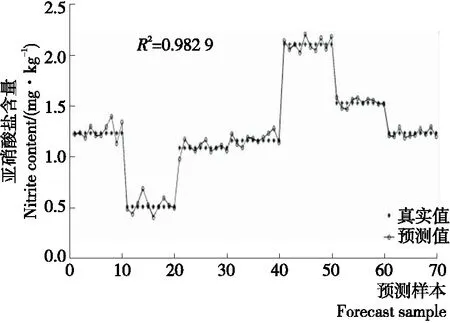
圖8 全波長下偏最小二乘回歸的結果
3 結論
采用高光譜技術檢測香腸儲藏中亞硝酸鹽含量時,在提取特征波長的基礎上進行回歸模型構建,得到的模型精度不高,效果不理想,預測精度最高只達到了0.911 1,且數據處理過程復雜。直接在全波長之下建立的預測模型既可以提高預測結果的精度,又可以降低從預處理到建模計算過程中的復雜性。所以全波長信息作為香腸儲藏過程中亞硝酸鹽含量高光譜檢測模型信息的輸入是合適的。另外,考慮到提取特征波長在高光譜研究中的優勢,在今后的研究中,應該對特征波長的提取方法進行更多的嘗試,以提高檢測模型的預測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
