生態背景下基于人工智能深度學習的竹類害蟲識別方法研究
2019-07-17 09:29:26李禹辰李非非李見輝
世界竹藤通訊 2019年3期
李禹辰 李非非 李見輝 余 飛 徐 杰
(1 電子科技大學 成都 611731;2 成都市森林病蟲防治檢疫站 成都 610032)
竹子(Bambusaceae),禾本科竹亞科植物,全世界約有70屬,1 000種以上,廣泛分布于熱帶、亞熱帶至暖溫帶地區。我國是世界上主要的產竹國,在長江流域、珠江流域等南方地區均有大面積栽植。竹子是一種經濟價值較高的植物,是在生態、經濟、社會、文化等方面效益結合最為緊密的優秀林種之一。
1 研究背景
2018年2月,習近平總書記來四川視察時指出“要因地制宜發展竹產業,讓竹林成為四川美麗鄉村的一道風景線”。四川省獨特的自然立地條件,形成了以叢生竹為主,叢生竹、散生竹、混生竹兼有的竹資源富集區。目前,四川省有竹子18屬160余種,分別占全國竹子屬、種數的46%和32%;有竹林面積116余萬hm2,居全國首位,產業發展潛力巨大。根據《四川省竹產業發展規劃(2017—2022年)》要求,四川省將構建“一群三帶+其他區”的竹產業發展格局,即“川南竹產業集群”“青衣江竹產業帶”“龍門山竹產業帶”“渠江竹產業帶”及“其他發展區”。力爭到2022年,基本形成以川南竹產業集群和青衣江、渠江、龍門山3大竹產業帶為支撐的現代竹業發展格局,建成竹業重點縣40個,竹林面積穩定在120萬hm2,現代竹林基地突破67萬hm2,竹產品就地初加工轉化率和品牌覆蓋率均超過70%,竹旅游康養達到5 300萬人次;全省竹業綜合產值達到500億元,竹農人均竹業年收入達到1 500元。
在當前四川省竹產業大發展的有利背景下,逐步將以計算機、互聯網、人工智能等高新技術為代表的科技支撐手段應用于竹產業發展的各個方面,實行精細化管理及提升生產效益是竹產業發展勢在必行的趨勢。作為竹產業發展的基礎,在造林完成后,特別是撫育管護階段對竹類相關害蟲進行精準識別并進行有效防治,對高效益發展竹產業具有極其重要的現實意義。
2 智能識別技術發展現狀
目前對于竹類害蟲的識別大多依賴于人工判斷識別,然而這類方法對從業人員專業知識和人力依賴性較強,當前我國森防體系和森林管護體系現實條件下,在生產一線具備相關專業知識的人員稀缺,無法準確判斷蟲害發生種類并及時采取有效防治措施,往往因時機延誤造成損失,難以滿足現代化林業高質量發展的需求。進入21世紀,隨著計算機視覺技術和人工智能技術在理論研究和行業應用方面的高速發展,為高效、準確、便捷、智能的竹類害蟲的識別提供了新的手段,為人工診斷提供了有效補充,對促進竹業健康發展、加速傳統竹業向智慧竹業轉型有著重要的現實意義和社會影響[1]。
目前,智能識別技術已經廣泛應用于多個行業,且取得了長足進步。在昆蟲識別領域,基于傳統圖像處理技術的識別已開展了一些研究并獲得了一定成效。Christian等[2]使用了幾何形態學來分析熊峰翅的變異性;潘鵬亮等[3]使用數字形態學區分了桃紅頸天牛雌雄成蟲間的差異;趙汗青等[4]通過利用數學形態特征提取的方法提取到半翅目等昆蟲的整體圖片的葉狀性、似圓度等特征,但由于上述方法只能提取昆蟲的部分形態學特征而無法完全提取一張圖像的所有特征,因而大多適用于昆蟲的粗分類。劉景東[5-6]通過從卷蛾亞科研究人員手中獲得的標準圖構建了53種根據前翅的翅脈模板圖來識別卷蛾不同的種類,但這種方法的缺點是模板匹配的計算量大,識別過程耗時較長,且魯棒性(魯棒性是Robustness的音譯,指系統在其參數發生變化時性能保持穩定的能力)不強。Weeks等[7-8]利用主成分分析法對寄生蜂的翅脈特征進行分析,完成了對寄生蜂的識別,然而此類方法對蟲類圖像的質量要求較高,圖像中光照、角度、背景等環境因子對識別精確度有較大影響。經過行業應用實際效果比較,以上幾種基于傳統圖像處理的昆蟲類識別方法大多存在計算較復雜,識別過程耗時較長,且魯棒性較差的缺點,在行業應用中普及較為困難。由于竹類害蟲存在種類繁多,實際環境中背景較為復雜等具體情況,上述幾種傳統方法的識別效果不佳,整體實用性不強,無法大規模應用于林業生產實際。
目前,較之傳統圖像處理技術,人工智能深度學習在圖像分類和目標識別領域已經取得了巨大進步,在生物類的識別領域也開展了較廣泛的研究與應用。Lim等[9]使用AlexNet(一種神經網絡結構模型,以下的LeNet、GoogLeNet均同)對ImageNet(一個計算機視覺識別大型數據集,是目前深度學習圖像領域應用得非常多的數據集,關于圖像分類、定位、檢測等研究工作大多基于此數據集開展)上的27種昆蟲進行實驗并取得了不錯的效果;程尚坤[10]在儲糧害蟲的檢測中使用了深度學習并使得甲蟲類的識別率達到95%;Cheng等[11]在生態背景下利用深度學習神經網絡對10種害蟲進行識別并取得了較高的識別率;Motta等[12]在進行野外成年蚊子分類識別的研究中分別采用了LeNet、AlexNet和GoogLeNet模型來進行訓練,其中GoogLeNet取得了最佳的83.9%的識別率,遠高于AlexNet的74.7%識別率。
可見,基于深度學習的圖像識別方法,通過數據集的訓練能夠使計算機學習到更多的圖像特征,識別魯棒性更強,對于生態背景的適應性也更好,并且訓練好后的模型識別效率也更高,對于硬件的計算性能要求大大降低,實用性得到極大的提高。因此,本研究提出一種基于深度學習的竹類害蟲識別方法,以期實現生態背景下幾種主要竹類害蟲的自動識別,為大規模、高質量的竹產業發展中的害蟲智能識別與防治提供一種先進科學方法與技術支撐。
3 研究數據
研究所用數據由2個部分組成:一部分采集自四川省邛崍市某竹林基地,使用移動手持設備在正常光照下采集,包括3種竹類害蟲(竹象蟲、竹蝗、竹織葉野螟),此為本文算法的主要識別目標;另一部分采集自互聯網昆蟲圖庫(www.insectimage.org),包括3種其他昆蟲(螞蟻、蜜蜂、蜻蜓),主要用于增加數據種類,作為訓練與識別的干擾種類,提高識別算法的魯棒性和實用性。
數據對于神經網絡的訓練至關重要。一般來說,數據量越大,訓練出來的模型精度越高,泛化能力越強。因此利用已有的數據,通過翻轉等數據處理,可以制造出更多的圖片,進而提高網絡的精度和泛化能力。本研究通過旋轉、高斯濾波、椒鹽噪聲、變亮+椒鹽噪聲、變暗+高斯濾波幾種數據處理方式,進行蟲類圖像數據的增強和擴充,如圖1所示。

圖1 經數據增強擴充后的竹象蟲成蟲圖片
通過數據增強方法擴充并篩選,形成共計5 663張蟲類圖片的數據集,且均為生態背景下的蟲類圖片。蟲類圖像數據集共分7類(表1),分別為竹織葉野螟、竹蝗、竹象蟲幼蟲、竹象蟲成蟲、螞蟻、蜜蜂、蜻蜓,其中由于竹象蟲成蟲與幼蟲形體區別較大,故分類進行識別。
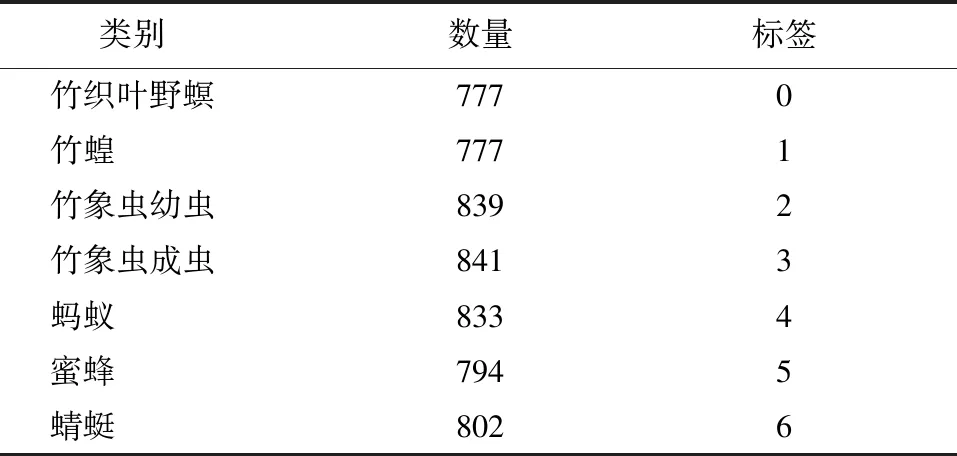
表1 蟲類數據集各類圖片數量
本研究中采用的圖像分辨率大小均為256×256,并對數據集的每一種昆蟲圖像進行標簽,記作n,代表圖像所屬的類別:0代表竹織葉野螟;1代表竹蝗;2代表竹象蟲幼蟲;3代表竹象蟲成蟲;4代表螞蟻;5代表蜜蜂;6代表蜻蜓,如圖2所示。

圖2 數據集標記示例
4 研究方法
本研究基于GoogLeNet網絡的竹類蟲害識別方法。GoogLeNet網絡相比于AlexNet等早期網絡擁有更寬、更深的網絡結構。同時,所需要的參數也大大減少。GoogLeNet特有的Inception模塊構成的網中網結構能夠使其獲得更多的圖片特征。Inception模塊的設計特點是用稠密結構來替代網絡中的局部稀疏結構,這種特點使得Inception可以在具備稀疏性來減少參數的同時利用密集矩陣進行運算,這使得網絡利用資源的效率大大提高。本文的識別模型結構圖如圖3所示,GoogLeNet在分類層之前使用了連續的9層Inception模塊來提取特征。在分類部分,采取了平均池化層,使得整個網絡結構參數減少了,抑制了過擬合現象的出現,從而降低了訓練的難度。
實驗所使用的計算機CPU為英特爾酷睿i7-7700,顯卡為英偉達GeForce GTX 1080Ti,操作系統為Ubuntu16.04。實驗均采用相同的參數,所用參數學習率為0.005,動量參數設置為0.9,權值衰減系數為0.000 5,Gamma矯正參數為0.1,采用小批量訓練且以24張圖片為一組,共進行100輪訓練,每輪訓練進行1萬次迭代。所有實驗均在Caffe(卷積神經網絡框架)下進行。Caffe是一個開源的深度學習框架,實驗所有的測試結果均可在Caffe上復現。

圖3 基于GoogLeNet的竹類害蟲識別模型結構
在深度學習中,數據集通常被分為獨立的3個部分:訓練集、驗證集和測試集。其中訓練集用來估計模型,驗證集用來確定網絡結構或者控制模型復雜程度的參數,而測試集則檢驗最終選擇最優模型的識別性能。
為研究訓練集與測試集比例對模型識別準確率的影響,采用4種不同訓練集與測試集比例進行測試,分別為:1)9∶1(數據集的90%作為訓練集,10%作為測試集);2)8∶2(數據集的80%作為訓練集,20%作為測試集);3)7∶3(數據集的70%作為訓練集,30%作為測試集);4)6∶4(數據集的60%作為訓練集,40%作為測試集)。
5 結果與分析
5.1 Loss曲線分析
Loss曲線是用來衡量網絡訓練情況的一種方法,Loss曲線收斂即代表模型能夠被訓練。圖4為訓練過程中的Loss曲線圖,其中縱坐標表示Loss值,橫坐標為訓練輪數。由圖4可以得出結論:模型在對竹類害蟲圖片數據集進行訓練過程中,Loss值一直呈下降態勢,并能夠很快趨近于0,這表明模型訓練過程中沒有出現過擬合現象。可見,本文模型在對竹類害蟲圖片數據集訓練過程中展現了優越的性能。

圖4 Loss曲線圖
5.2 F1值分析
F1值,又稱平衡F分數,是用來衡量分類模型精確度的一種重要指標,同時兼顧了分類模型的查全率(Recall)和查準率(Precision)。查全率是針對原來樣本而言的,它表示樣本中的真樣例有多少被預測正確。查準率是針對測結果而言的,它表示預測為真的樣例中有多少是真正的真樣例。
對竹類害蟲的識別結果分為4種情況:一是正確肯定(TP),預測為真,實際為真;二是正確否定(TN),預測為假,實際為假;三是錯誤肯定(FP),預測為真,實際為假;四是錯誤否定(FN):預測為假,實際為真。
因此,查全率定義公式如(1)所示,查準率定義公式如(2)所示。
(1)
(2)
本文中查全率表示某一類竹子害蟲被識別出來的比例,比率越大則表示漏掉的樣例越少;查準率表示在所有識別為某種害蟲類別的樣例中,實際屬于該類別的樣例的比例,比率越大表示模型識別得越準確。本文模型在4種不同比例的訓練集與測試集下,各類竹類害蟲識別結果的查全率和查準率如表2所示。
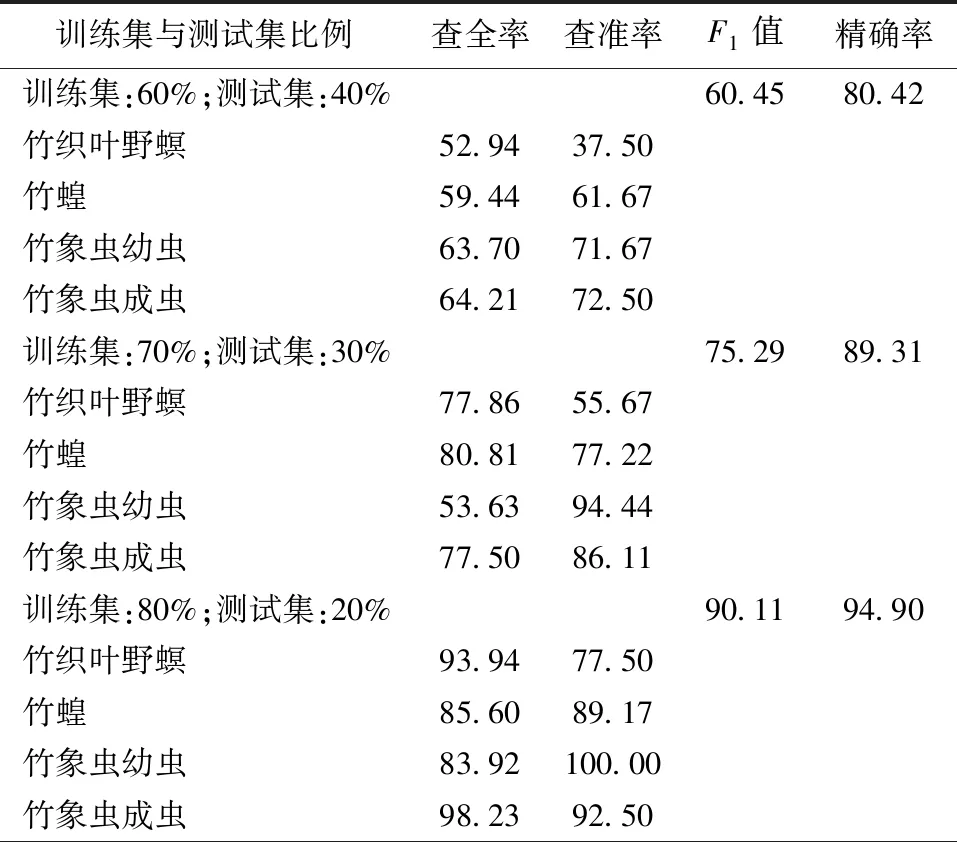
表2 不同訓練集與測試集比例的查全率、查準率、
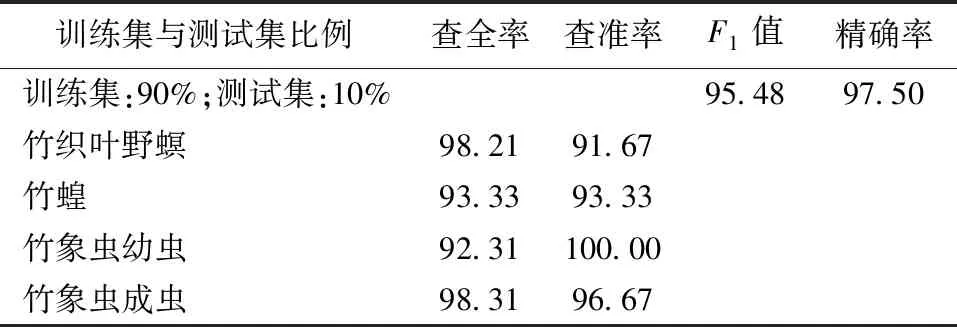
表2(續)
F1值作為對查全率和查準率的綜合評估指標,可以看作是模型查全率和查準率的一種加權平均,是表示這兩者對模型的影響的最優平衡點。F1值定義公式如(3)所示。
(3)
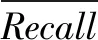
由表2可得,竹類害蟲識別模型在4種不同訓練集與測試集比例情況下的平均查全率分別為60.07%、72.45%、90.42%、95.54%,平均查準率分別為60.84%、78.36%、89.79%、95.42%,因此根據公式(3)可得本文模型的F1值分別為60.45%、75.29%、90.11、95.48%。
由此可知,當訓練集與測試集比例為9∶1時識別模型的平均查全率和平均查準率都較高,且F1值達到了95.48%。較高的平均查全率和查準率代表本文識別模型能從多種蟲類中較準確識別竹類害蟲,較高的F1值表示識別模型具有較好的綜合性能和較高的實用性。
5.3 精確度分析
模型的精確度(Accuracy)是分類正確的樣本數占樣本總數的比例,反映了模型對整個樣本數據的判定能力(即能將真的判定為真的,假的判定為假的)。計算公式如(4)所示。
(4)
由公式(4)可得模型的精確度(如表2所示),通過對比在4種不同訓練集和測試集比例下模型的精確度可以得出結論:模型的精確度隨訓練集比重的增大而增大。在本實驗中,當訓練集和測試集的比例為9∶1時精確度最高,達到了97.5%。因此,本文的識別模型具備較高的精確度,能較準確地識別出各類竹類害蟲。圖5為竹類害蟲識別成功的示例。可見,本文的識別模型能夠滿足生態背景下竹類害蟲識別的要求,具有較強的實用性。

圖5 竹類害蟲識別示例
6 結論與展望
本研究基于人工智能深度學習的竹類害蟲識別方法,相比于傳統的圖像處理方法,其深度學習模型能提取更多的圖像特征,能對生態背景下的竹類害蟲識別有更好的精確度和適應性。本文首先構建了具有5 663張圖片的蟲類數據集(包含3種竹類害蟲和3種其他昆蟲類),并利用GoogLeNet特有的Inception模塊構成的網中網結構能夠使其獲得更多的圖片特征,進行了4組不同訓練集與測試集比例的模型識別實驗。實驗結果顯示,模型在對竹類害蟲圖片數據集進行訓練過程中,Loss值一直呈下降態勢,并能夠很快趨近于0,這表明模型訓練過程中沒有出現過擬合現象,展現了優越的性能。此外,模型的精確度隨訓練集比重的增大而增大,當訓練集和測試集的比例為9∶1時識別表現最好,F1值達到了95.48%,精確度為97.5%,表明模型能較準確的識別出實驗中的各類竹類害蟲,體現了識別模型具有較好的綜合性能和較高的實用性。
因本文著重于方法的探索,在數據集中只包含了3種竹類害蟲,在后續的研究中將加入數量更多、更豐富的竹類害蟲圖像數據,研究建立準確率更高的識別模型,實現更多種類竹類害蟲的自動識別并擴展至其他樹種蟲害。此外,目前所用于訓練的單張圖片僅包含一種目標害蟲,后續將考慮加入多目標檢測方法,實現單張圖片中多種害蟲的準確識別,以達到更好的實用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南教育·中學教師(2020年11期)2021-01-07 08:26:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
山東煤炭科技(2020年1期)2020-03-06 06:43:28
新教育時代·教師版(2017年30期)2017-09-12 08:17:15
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
浙江農業科學(2011年3期)2011-01-31 11:01:30
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
