
面向CSTR的事件觸發(fā)GDHP控制算法
2019-07-22 01:39:34吳凌段棠少白竣仁
山東工業(yè)技術(shù) 2019年19期
吳凌 段棠少 白竣仁

摘 要:連續(xù)攪拌反應(yīng)釜具有非線性、強(qiáng)耦合、參數(shù)時變的特點,為更好地控制反應(yīng)釜,提出一種基于事件觸發(fā)GDHP的連續(xù)攪拌反應(yīng)釜過程控制方法。首先設(shè)計事件觸發(fā)條件,之后運用神經(jīng)網(wǎng)絡(luò)技術(shù),設(shè)計事件觸發(fā)GDHP方法來近似最優(yōu)控制律和值函數(shù),最后得到控制變量冷卻劑溫度,實現(xiàn)反應(yīng)釜快速穩(wěn)定控制。實驗結(jié)果表明:該算法在保證控制效果的前提下,不但具有良好的動態(tài)性能,而且有效降低了計算量和通信量。
關(guān)鍵詞:連續(xù)攪拌反應(yīng)釜;事件觸發(fā);自適應(yīng)動態(tài)規(guī)劃;神經(jīng)網(wǎng)絡(luò)
DOI:10.16640/j.cnki.37-1222/t.2019.19.114
0 引言
連續(xù)攪拌反應(yīng)釜是一種復(fù)雜的的聚合反應(yīng)器,在生物發(fā)酵、石油化工、化學(xué)制藥等工業(yè)生產(chǎn)過程中得到廣泛應(yīng)用[1]。
在實際生產(chǎn)過程中,CSTR經(jīng)常受到如反應(yīng)物濃度變化、副反應(yīng)、溫度和氣液相位不均、外部干擾等因素的影響,CSTR的自適應(yīng)控制顯得更加重要。
自適應(yīng)動態(tài)規(guī)劃(adaptive dynamic programming,ADP)作為一種新的自適應(yīng)控制算法[2],克服了動態(tài)規(guī)劃難以求解最優(yōu)控制策略的缺點,從而更適合應(yīng)用在具有強(qiáng)非線性、高復(fù)雜性、強(qiáng)耦合的系統(tǒng)中,如:電力系統(tǒng)、智能交通系統(tǒng)、導(dǎo)航飛行系統(tǒng)等。
但是,傳統(tǒng)ADP算法需要在每次采樣時刻進(jìn)行神經(jīng)網(wǎng)絡(luò)的更新,計算量和通信負(fù)擔(dān)較大。因此,本文將事件觸發(fā)機(jī)制引入ADP控制算法中,只有當(dāng)某些條件違反時才對系統(tǒng)狀態(tài)進(jìn)行采樣,從而提供了一種非周期性的策略來更新系統(tǒng)的狀態(tài)和控制輸出,極大地減少了計算量。
1 CSTR模型
考慮CSTR的動態(tài)方程如下:
其中,狀態(tài)變量為生產(chǎn)物的濃度,反應(yīng)器溫度為輸出量,輸入量為夾套內(nèi)的冷卻裝置的溫度,為達(dá)姆科勒數(shù),為無因式化的活化能,為反應(yīng)熱,為熱交換系數(shù)。
2 事件觸發(fā)GDHP控制算法
本文采用精度最高、控制效果最理想的全局二次啟發(fā)式規(guī)劃(Globalized dual heuristic programming,GDHP)結(jié)構(gòu)。
但由于GDHP結(jié)構(gòu)復(fù)雜,所需計算量大,因此,引入事件觸發(fā)機(jī)制。事件觸發(fā)機(jī)制不僅能保持穩(wěn)定有效的控制效果,還能降低計算成本,避免通信資源和計算資源的不必要浪費。
本控制算法包含兩個神經(jīng)網(wǎng)絡(luò):評價網(wǎng)絡(luò)和執(zhí)行網(wǎng)絡(luò),分別用來近似系統(tǒng)的性能指標(biāo)函數(shù)、偏導(dǎo)數(shù)(協(xié)函數(shù))和控制律。系統(tǒng)狀態(tài)通過采樣器進(jìn)行采樣,設(shè)置一個事件觸發(fā)閾值,當(dāng)事件被觸發(fā)后,采樣器才對系統(tǒng)進(jìn)行采樣,執(zhí)行網(wǎng)絡(luò)才會接受該采樣信號并作為其輸入,并用來近似最優(yōu)控制律和輸出控制信號,經(jīng)零階保持器轉(zhuǎn)化為近似最優(yōu)控制律輸入系統(tǒng)模型。
3 實驗結(jié)果與分析
為驗證本算法的有效性和穩(wěn)定性,本文將事件觸發(fā)GDHP算法運用于解決CSTR的控制問題。
當(dāng)觸發(fā)誤差滿足觸發(fā)條件,系統(tǒng)狀態(tài)會再次通過采樣器進(jìn)行采樣。評價網(wǎng)絡(luò)結(jié)構(gòu)為2-6-4,輸入為溫度和濃度這兩個采樣狀態(tài)量,輸出為代價函數(shù)對當(dāng)前狀態(tài)的偏導(dǎo)數(shù)、當(dāng)前狀態(tài)對上一時刻狀態(tài)的偏導(dǎo)數(shù);執(zhí)行網(wǎng)絡(luò)結(jié)構(gòu)為2-6-1,輸入為兩個采樣狀態(tài)量,輸出為控制量,即冷卻劑溫度。每個網(wǎng)絡(luò)的離散化采樣周期為。
評價網(wǎng)絡(luò)和執(zhí)行網(wǎng)絡(luò)的初始權(quán)值都在區(qū)間[0,1]中隨機(jī)選取,學(xué)習(xí)率會在一定程度上影響算法的收斂速度,通過實驗選取合適的學(xué)習(xí)率,選取折扣因子=0.9,GDHP技術(shù)的調(diào)節(jié)參數(shù)初始化為0.5。
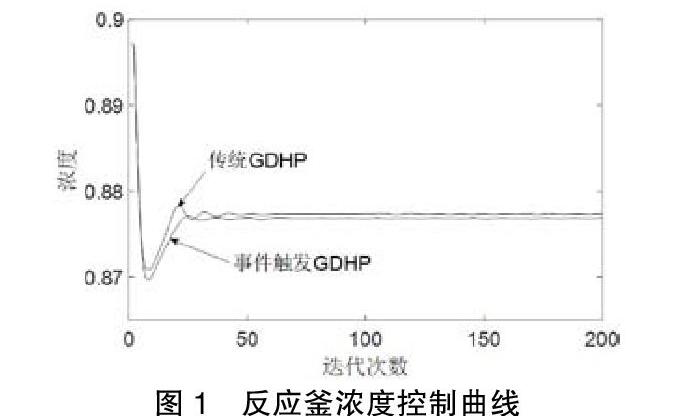
本實驗中,CSTR系統(tǒng)選擇以下物理參數(shù)。CSTR系統(tǒng)在本方法控制下的響應(yīng)圖如下,為了比較控制效果,本文也給出了初始權(quán)值相同情況下的傳統(tǒng)GDHP控制的實驗結(jié)果。
由上圖可以看出,本文提出的事件觸發(fā)GDHP方法和傳統(tǒng)GDHP方法相比,在60步內(nèi)濃度均能達(dá)到穩(wěn)定。
由于時間觸發(fā)是在每次迭代都會進(jìn)行采樣,故200步就會有200次采樣;事件觸發(fā)卻只在事件被觸發(fā)了才會進(jìn)行采樣,所以累計觸發(fā)數(shù)目遠(yuǎn)遠(yuǎn)小于時間觸發(fā)下的累計數(shù)目,本例中只有40步,僅占原始采樣點的20%,極大地減少了計算量。在控制效果基本保持一樣的情況下,事件觸發(fā)控制的計算代價和通信成本隨著累計數(shù)目的減少而減少,體現(xiàn)了事件觸發(fā)控制在減少計算和通信的巨大優(yōu)勢。
4 結(jié)論
對于非線性連續(xù)系統(tǒng),本文設(shè)計了一種基于事件觸發(fā)的GDHP控制策略。針對CSTR系統(tǒng),控制器只在觸發(fā)時刻進(jìn)行更新,保持理想控制效果的同時極大地降低了計算量。仿真實驗表明,本文提出的算法是確實有效的。
參考文獻(xiàn):
[1]朱群雄,王軍霞.連續(xù)攪拌釜式反應(yīng)器的魯棒最優(yōu)控制[J].化工學(xué)報,2013,64(11):4114-4120.
[2]張化光,張欣,羅艷紅等.自適應(yīng)動態(tài)規(guī)劃綜述[J].自動化學(xué)報,2013,39(04):303-311.
[3]劉德榮,李宏亮,王鼎.基于數(shù)據(jù)的自學(xué)習(xí)優(yōu)化控制:研究進(jìn)展與展望[J].自動化學(xué)報,2013,39(11):1858-1870.
