基于時間遞歸序列模型的短文本語義簡化
2019-07-29 00:56:35藺偉斌楊世瀚
物聯網技術 2019年5期
藺偉斌 楊世瀚

摘 要:針對傳統循環神經網絡訓練算法無法處理梯度消失和梯度爆炸等問題,基于循環神經網絡建立LSTM模型和seq2seq模型,提出時間遞歸序列模型TRSM,處理序列中間隔和延遲相對較長的輸入,使用BPTT反向傳播算法對中文微博語料庫進行訓練。建立三組不同的實驗作為對比,實驗結果表明,TRSM模型處理后的微博文本更加簡潔精煉,更適合文本語義的提取,大大減少了計算量,文字縮減率達到60%以上,語義保持率達到1.8,簡化了用戶要處理的大量信息,處理后的結果能夠更好地用于幾個關鍵中文語義的處理任務。
關鍵詞:短文本信息;文本簡化;LSTM模型;TRSM模型;BPTT反向傳播算法;循環神經網絡
中圖分類號:TP391 文獻標識碼:A 文章編號:2095-1302(2019)05-00-06
0 引 言
隨著互聯網的高速發展,各種互聯網信息(如語音信息、圖片信息、文本信息等)也呈爆發式增長。人們每天都能接觸到大量多樣的信息,如來自新聞報導、博客、微博等各個渠道的文本信息。為了對這些海量信息進行快速、高效地分析與處理,使機器準確理解這些信息,經研究發現,基于高語義保持度的文本簡化就是一個可行的方法。所以文本簡化逐漸成為人們的重要需求之一,也是自然語言處理領域的熱點問題。
目前,文本簡化的研究方法大致可以分為抽取型和生成型兩種類型。自然語言處理領域的研究員用不同的方式從這兩種類型中做文本簡化。文獻[1]采用Hedge Trimmer句子壓縮技術對英文語句進行壓縮,劃分出原句的語法結構,組織成語法樹,再應用一定的語法規則修改語法樹的一些組成部分。由于其主要依賴語法規則實現語句簡化,可能會忽略原文的某些語義,因此壓縮后的句子可能會丟失原句中的一些重要信息。文獻[2]提出基于句法規則的新聞稿首句壓縮技術,其目的是實現新聞標題的自動生成,采樣文本為新聞稿首句,依照句法規則進行壓縮,生成更為簡潔的新句子作為新聞標題。由于缺少對語義的規則限制,因此會相對減少壓縮后新句中核心內容的保留度。文獻[3]提出帶有LSTM(Long Short-Term Memory)單元的編碼-解碼器,循環神經網絡模型用于提取新聞內容生成標題,根據神經網絡計算關鍵單詞的權重,生成摘要時有利于提高核心內容在語義上的保留度。文獻[4]提出指針生成網絡和覆蓋機制處理生成的詞語未出現在詞匯表中以及生成詞的重復問題,其自動生成文本摘要的方法可提高生成句子的語義流暢度,從而提高了對原文內容的語義保留。綜上可知,在文本簡化中提高語義保持度成為了一個非常重要的研究課題。
本文針對語義保持度,提出時間遞歸序列模型(Time Recursive Sequence Model,TRSM),結合序列到序列(seq2seq)的框架以及基于循環神經網絡長短時記憶模型(LSTM)的方法來處理短文本的語義簡化,能夠緩解訓練中梯度消失和梯度爆炸的問題,同時又能處理序列中間隔和延遲相對較長的輸入。該方法采用循環神經網絡中的LSTM,能夠學習長期依賴信息,通過刻意設計來處理長期依賴問題,從而可以更好地處理向量空間中距離過長的時間序列,并能夠對更早時間位置的信息保留記憶。通過實驗可以發現,采用該模型能更準確地對文本進行簡化。
1 相關工作
1.1 基于循環神經網絡的文本簡化
人工神經網絡[5]技術起源于20世紀60年代,當時被稱為感知機,包含輸入層、隱含層和輸出層。輸入層輸入的特征向量經過隱含層變換到達輸出層,輸出層得到具有特征的分類結果。卷積神經網絡、循環神經網絡、深度神經網絡等都屬于人工神經網絡的分支,其中循環神經網絡與其他神經網絡的主要區別是輸出不僅取決于這一時刻的輸入,同時還取決于上一時刻的輸出,如圖1所示。
其中,t表示時刻,xt是輸入層的值,U是輸入xt的權重,st是隱含層的值,W是上一時刻隱含層的輸出st-1的權重,V是隱含層的輸出st的權重,ot是t時刻輸出層的值,可用公式表示為:
循環神經網絡在自然語言處理領域中應用最廣、效果最好。如建立語言模型、新聞標題生成、文本生成、文本簡化等。Tomas Mikolov[6]提出的基于RNN的語言模型主要根據循環神經網絡處理上下文時沒有文本長度的限制,通過各層神經元的循環連接,文本信息可在網絡中傳遞和學習更長的時間。李[3]在新聞標題生成結合RNN的LSTM模型中引入注意力(Attention)機制,當信息輸入至編碼器(Encoder)后,不再限制編碼器輸出的向量長度。
1.2 中文語義分析中的文本簡化
中文語義分析是自然語言處理領域的眾多任務之一。任何對中文的理解都可以認為是屬于中文語義分析的范疇。一段文字通常由單詞、句子和段落組成,可進一步分解為詞匯層面的語義分析、句子層面的語義分析和文本層面的語義分析[7]。語義分析的目的是通過建立有效的語言模型和系統實現每個語言級別(包括詞、句子、章節等)的自動語義分析,得到并理解整個文本表達的真實語義。
文本簡化是中文語義分析的技術之一,用一段短文本作為輸入,經過系統處理后,輸出為一小段文本,并且文本語義不變,相對于輸入來說文本更加簡潔精練,這個過程就叫做文本簡化。近年來,文本簡化在神經網絡技術中的應用越來越廣泛,其中使用最多的框架是seq2seq模型。seq2seq是一種編碼器-解碼器(Decoder)架構,模型如圖2所示。
seq2seq模型中,編碼器將輸入的文本編碼為語義表達向量(對應于圖2中第4個節點的隱含狀態),使用解碼器的語義向量輸入序列和表達式來生成目標文本序列W-X-Y-Z-〈EOS〉。〈EOS〉表示序列的結尾(End of Sequence),符號表示輸入序列或輸出序列的結束[8]。解碼器接收到〈EOS〉符號后開始解碼過程,直到〈EOS〉符號形成標記解碼過程結束。本文使用的編碼器框架是基于循環神經網絡的LSTM模型,解碼器框架同樣也是LSTM模型。
序列模型是一個字符在逐一處理序列過程中,逐個編碼器接收一個輸入字符的編碼過程,解碼器輸出在解碼過程中逐個字符地產生。原始模型的訓練過程中,解碼器每接收一個答案中的字符序列(如W),就預測下一個字符輸出(如X)。經典的訓練目標編碼器-解碼器架構在編碼器輸入中給出,解碼器的輸出能夠最大化擬合訓練集概率模型中的答案,即最大化數據似然[9]。
2 基于RNN的長短時記憶模型
2.1 把單詞表示成詞向量(word2vec)
word2vec過程分為三步:數據預處理、分詞及訓練詞向量。
由于計算機無法直接識別自然語言,因此要先把文本中的每個詞轉化成計算機可以識別的語言,即把單詞用詞向量表示。采用word2vec構建中文詞向量時,word2vec的文本輸入是需要分詞的,故在PyCharm開發環境下使用jieba工具對文本進行分詞。
word2vec中常用的重要模型有CBOW連續詞袋模型和Skip-Gram模型,前者是已知上下文預測當前時刻的詞,后者是已知當前時刻的詞預測上下文。采用語料庫訓練word2vec模型,得到每個詞的詞向量表示并保存。
2.2 建立RNN模型RNN模型如圖3所示。
由圖3可知,隱含層s當前時刻的輸出經過權重W之后又返回自身作為下一時刻隱含層的輸入。用公式表達為:。其展開模型如圖4所示。
在計算s0,即第一個單詞的隱含層狀態時,需要用到上一時刻的隱含狀態st-1,但是這個狀態不存在,實現時一般設為0向量。
各隱含層單元相連接,網絡在t時刻的輸出ot用公式表達為:
對RNN的訓練與對傳統ANN訓練相同,均使用相同的BP誤差反向傳播算法。而在梯度下降算法中,每個時刻的輸出不僅取決于當前網絡,還取決于前幾個時刻的網絡狀態。例如,當t=4時,還需要向后傳遞3個步驟,接下來的3個步驟需要添加各種梯度,這就是BPTT(Backpropagation Through Time)反向傳播算法。需要指出的是,在RNN訓練中,BPTT不能解決長期依賴問題(即當前輸出與之前的長序列有關),一般來說,不要超過10個步驟。當然,有很多方法可以解決這個問題,如LSTM模型。因此,將LSTM模型添加到RNN中,以解決訓練中出現梯度消失和梯度爆炸[10]的問題。
2.3 建立LSTM模型
LSTM模型對傳統RNN中的隱含層做了一些修改,在一個隱含單元中加入遺忘門(Forget Gate)、輸入門(Input Gate)、輸出門(Output Gate)和細胞狀態(Cell State),如圖5所示。
其中,σ是Sigmoid 函數,遺忘門控制上一時刻細胞狀態Ct-1傳遞到當前時刻細胞狀態Ct的信息量,bf是前面所有時刻遺忘門的值,公式表示為:
輸入門控制當前時刻產生的新信息C't加入到細胞狀態Ct的信息量,bi是前面所有時刻新信息的值,bC是前面所有時刻細胞狀態的值,公式表示為:
細胞狀態根據遺忘門和輸入門的輸出更新,即上一時刻細胞狀態通過遺忘門的輸出與輸入門的輸出(當前時刻的新信息)C't相加,公式表示為:
輸出門控制當前時刻已更新的細胞狀態傳遞的信息量,并得到當前時刻隱含單元的輸出ht,公式表示為:
LSTM模型主要是增加了遺忘門機制。例如,當有序列輸入到模型時,模型可選擇在較長時刻的信息中保留重要信息,選擇遺忘不重要信息,避免模型一直學習。
2.4 建立seq2seq模型
seq2seq模型主要由編碼器和解碼器組成,編碼器和解碼器都由基于循環神經網絡的LSTM模型構成,其模型如圖6所示。
圖6中,h1,h2,…,hn是編碼器在每個時刻的隱含層狀態,C是經過編碼器編碼之后的原始語料文本向量,s1,s2,…,sn是解碼器在每個時刻的隱含層狀態。整個過程是把原始語料數據輸入到編碼器中進行編碼,得出編碼器中隱含層的狀態映射,即得出文本向量C,然后輸入到解碼器中進行解碼,經過解碼器隱含層狀態計算后得到序列的輸出結果。
3 TRSM模型
TRSM模型是結合基于循環神經網絡建立的LSTM模型和seq2seq模型提出的處理文本簡化的一種時間序列模型。結合基于LSTM模型的編碼器中細胞狀態Ct與基于LSTM模型解碼器中的輸出門ot,訓練后得到TRSM模型的輸出。公式表示為:
建立好各結構所需模型后,將各模型合并起來,建立TRSM模型。
TRSM模型的建立步驟為:
(1)得到可用的原始語料數據,即使用word2vec對原始語料文本進行向量化處理,得到詞向量的結果;
(2)將由步驟(1)得到的詞向量作為編碼器的輸入,聯合LSTM模型構成編碼器,在編碼器中輸出隱含層狀態的映射,得到文本向量;
(3)采用LSTM模型構成解碼器,將由步驟(2)得到的文本向量輸入到解碼器LSTM模型中,經過隱含層狀態計算后得到輸出的文本結果。合并各模型后的框架如圖7所示。
TRSM模型的優點主要體現在以下幾點:
(1)輸入。傳統循環神經網絡模型框架的輸入只能是固定大小的詞向量輸入,本文提出的TRSM模型突破了固定大小輸入的問題。
(2)訓練。傳統循環神經網絡在訓練時會出現梯度消失和梯度爆炸等問題,而本文LSTM模型很好地緩解了模型訓練中產生的梯度消失和爆炸問題。
但是使用時聯合模型也會出現一些不足,如原始數據庫的大小對實驗結果的影響,訓練時各參數的調試對實驗結果的影響等。
構建網絡模型的訓練算法是BPTT反向傳播算法,文獻[11-12]給出了該算法的詳細推導過程,訓練的基本思想如下:
(1)正向計算得出每個神經元的輸出值,即6個變量ft,it,C't,ot,ht,Ct。
(2)反向計算得出每個神經元的誤差項值,分為兩個方向:一是網絡沿時間序列的反向傳播,二是誤差項向上一層傳播[13]。
前向細胞輸出:
后向細胞輸出:
(3)根據得出的相應的誤差項值,計算得出每個權重的梯度。
在處理全部編碼器與解碼器過程中,使用梯度優化算法以及最大似然條件概率對損失函數loss值進行模型訓練與優化:
4 實驗與分析
4.1 測試訓練語料庫
本文選取NLPIR微博語料庫[14],先抽取大約20萬條數據進行訓練與實驗,同時抽取大約100萬條數據進行橫向對比實驗。對兩組實驗原始語料數據作相同預處理。首先去掉正文插入時間,正文發布時間,轉發、來源、評論數目等對實驗無影響的因素,同時去掉無用的符號和停用詞;然后對過濾后的數據進行分詞;再把數據作為輸入代入word2vec模型中進行訓練,得到每個詞的向量表示并輸出文件“vector.bin”,計算兩個詞向量之間的余弦值得出詞向量之間的余弦相似度。以輸入數據樣本作為樣例測試詞向量訓練結果,選取余弦相似度值最靠前的2個作為樣本示例,實驗結果及余弦相似度比較見表1所列。
4.2 模型參數設置
本文采用PyCharm開發工具,在PyCharm中搭建并安裝TensorFlow深度學習工具以及數據處理需要用到的word2vec,jieba分詞等工具,調試各代碼塊功能。同時給模型中的可調參數賦初始值,見表2所列。
參數設置過程偽代碼如下:
1.batch_size=256#batch大小
2.num_epochs=200#訓練循環次數
3.seq_length=20#訓練步長
4.learning_rate=0.001#學習速率
5.embed_dim=512#embedding layer大小
4.3 實驗結果與分析
抽取訓練語料庫(NLPIR微博語料庫)中微博正文長度在50個中文字左右的幾條微博作為樣本進行3組實驗,同時在模型中讀出loss值并打印,取第1條微博樣本作為對比實驗,3組實驗設置如下:
(1)原始參數值;
(2)訓練循環次數為200~300,其他參數值不變;
(3)學習速率為0.001~0.01,其他參數值不變;
實驗結果分別見表3、表4所列。
通過以上實驗結果可得:
(1)第1組實驗中使用原始參數值,經過模型處理后,輸出的語句通順程度一般,loss值大約為1.87。
(2)第2組實驗把原始參數值中的訓練循環次數從200增加至300,經過模型處理后,輸出的語句通順程度一般,loss值大約為1.83,相比表1的loss值下降了0.04。
(3)第3組實驗把原始參數值中的學習速率從0.001增加至0.01,經過模型處理后,輸出的語句通順程度一般,loss值大約為1.76,相比表1的loss值下降了0.11。
(4)在橫向對比實驗中,訓練數據量由20萬增至100萬,經過模型處理后,輸出的語句通順程度較為優化,調參后的各組實驗中loss值普遍下降,loss值平均下降0.05左右。
文字縮減率橫向對比實驗結果如圖8所示,語義保持率橫向對比實驗結果如圖9所示。
由圖8可知,3組實驗的文字縮減率分別為67.2%,72.5%,62.5%,文字縮減率都在60%以上,說明實驗模型在文本簡化的效果中比較顯著,文字縮減是實驗的前提,體現樣本簡化的程度,而語義保持是實驗的目的。由圖9可知,3組實驗的語義保持率由模型結果與正文相比較,大致可用實驗結果數據中的loss值體現,即3組樣本的語義保持程度分別為1.87,1.86,1.81,根據數據可以判斷實驗模型對正文簡化后的語義保持程度一般,對比每組更改后的參數值,訓練循環次數和學習速率都能夠提升loss值,其中增加訓練循環次數,對loss值提升4%,增加學習速率對loss值提升11%,即增加學習速率對loss值的增大效果更為明顯,同時也提高了模型輸出結果的語義保持率。
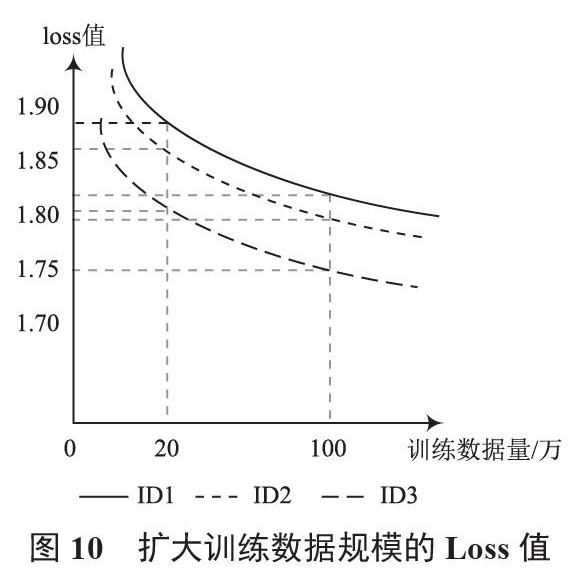
橫向對比實驗中,擴大訓練數據的規模至100萬,模型輸出的語句相比20萬訓練數據量下的語句較為流暢。擴大訓練數據規模的loss值如圖10所示,ID1,ID2,ID3在20萬訓練數據量下loss值分別為1.87,1.86,1.81,在100萬訓練數據量下loss值分別為1.81,1.80,1.76。由loss值分析可得,隨著訓練數據量增加,loss值逐漸下降,3組實驗下loss值平均下降5%左右,從而表明擴大訓練數據量,模型結果更加優化。
綜上所述,采用TRSM模型的輸出結果已經出現“結婚”“辛苦”“迅速”“祝福新人幸福”這樣的詞語和短句,說明該模型在微博正文簡化中是有效的。通過以上3組實驗結果以及橫向對比實驗,可分析得出:調試模型參數值及擴大訓練數據量能夠影響到模型的輸出結果;增加訓練循環次數、增大學習速率值可減小loss值;但模型輸出的語句通順程度與loss值的下降程度不算可觀,除參數值這個影響因素外,還可能存在其他影響因素,如訓練語料庫的數據量不夠大等。由此可見,TRSM模型在處理文本簡化方面具有可行性與可靠性,對于如何提高可靠性以及實驗結果,將成為今后需要進行的工作。
5 結 語
本文基于循環神經網絡的LSTM模型與seq2seq模型的復合提出時間遞歸序列模型TRSM,緩解了訓練中梯度消失與梯度爆炸的問題,同時又能處理序列中間隔與延遲相對較長的輸入。針對實驗所需微博語料數據,對用戶的微博內容進行語義分析與簡化,測試、驗證語料庫的訓練,通過對模型參數的調試,優化訓練算法與實驗結果,得到了文本簡化方面可行且可信的結果,為方便處理各種中文語義任務提供了高效的預處理機制,平均文字縮減率達到60%以上,語義保持度達到1.8左右。
未來的工作是繼續擴大訓練的語料庫,增至500萬甚至1 000萬級別,并擴展數據長度,引入注意力機制等,進一步提高實驗的精度與可信度,并評估其對后續中文語義處理任務的優化程度。
參 考 文 獻
[1]景秀麗.Hedge Trimmer句子壓縮技術的算法實現及改進[J].沈陽師范大學學報(自然科學版),2012,30(4):519-524.
[2] DAVID B D,ZAJIC D.Hedge Trimmer: a parse and trim approach to headline generation[J]. Proceedings of the HLT-NAACL,2003(3):1-8.
[3]李慧,陳紅倩.結合注意力機制的新聞標題生成模型[J].山西大學學報(自然科學版),2017,40(4):670-675.
[4]龐超.神經網絡在新聞標題生成中的研究[D]. 北京:北京交通大學,2018.
[5]朱大奇.人工神經網絡研究現狀及其展望[J]. 江南大學學報(自然科學版),2004,3(1):103-110.
[6] MIKOLOV T ,MARTIN KARAFI?T,BURGET L ,et al.Recurrent neural network based language model[C]// Interspeech,Conference of the International Speech Communication Association,Makuhari,Chiba,Japan,September. DBLP,2015.
[7]神州泰岳.人工智能中的語義分析技術及其應用[J].軟件和集成電路,2017(4):42-47.
[8] CHENG J P,LAPATA M.Neural summarization by extracting sentences and words[J].Computer science,2016(3):484-494.
[9] HU B,CHEN Q,ZHU F. LCSTS: a large scale chinese short text summarization dataset[J].Computer science,2015(7):2667-2671.
[10] PASCANU R,MIKOLOV T,BENGIO Y.On the difficulty of training recurrent neural networks[C]// International Conference on Machine Learning.JMLR.org,2013.
[11] CHELBA C,MIKOLOV T,SCHUSTER M.One billion word benchmark for measuring progress in statistical language models based on neural networks[J].Computer science,2013(12):34-39.
[12] BODEN M.A Guide to recurrent neural networks and backpropagation[Z].2002.
[13] GRAVES A.Supervised sequence labelling with recurrent neural networks[Z].Studies in computational intelligence,2008.
[14] NLPIR微博語料庫.自然語言處理與信息檢索共享平臺[OL].http://www.nlpir.org.
