一種基于深度神經網絡的水軍識別模型
2019-07-30 08:30:30楊昊吳愛華屈青英
現代計算機 2019年18期
楊昊,吳愛華,屈青英
(上海海事大學信息工程學院,上海201306)
0 引言
隨著互聯網的發展迅速以及普及,直接帶動了在線社交網絡的急速發展,使得用戶可以通過像新浪微博等這樣的社交網絡平臺發布信息、傳播信息、接受信息等,這使得網絡平臺聚集了大量的極具價值的用戶信息,在重大新聞迅速傳播、網民交流溝通便利等方面表現出了積極作用。但與此同時也衍生出了網絡水軍,網絡水軍是一群在特定時間發布特定內容被雇傭的網絡寫手,網絡水軍的出現導致了網絡平臺謠言盛行、引導輿論走向,詐騙恐嚇猖獗,給國家政治經濟文化活動帶來不可估量的損失,并使得社會輿情不可控制,虛假信息泛濫,甚至引發了多個層次的社會事件,如百姓對抗政府,醫患、警民、軍民關系惡化。所以水軍識別是一個非常有意義非常有價值也亟待解決的問題。
目前,國內一些學者針對微博水軍事件進行分析。莫倩等人[1]總結了目前的水軍識別研究現狀,網絡水軍檢測選取的特征屬性主要包括:微博內容、用戶行為和網絡環境。相關研究多關注基于特定類型的網絡水軍的特征,例如基于內容、行為以及網絡環境等單個類型,這些方法無法全面分析網絡水軍行為,因此其識別準確率具有瓶頸。在此基礎上,綜合多種特定類型的網絡水軍識別方法對于各個目標領域的網絡水軍都具有較高的識別準確率。本文提出一種基于Tensor-Flow 深度神經網絡的水軍檢測模型,將內容特征、行為特征和網絡特征于一體,獲取相對應的特征目標作為模型的輸入。
1 相關研究
對于如何快速識別網絡水軍的研究,相關科學家取得了不少結果.這些成果主要是從用戶內容特征、用戶靜態特征以及網絡特征三個方面進行網絡水軍的識別。
Gao 等人[4]提出了一種在臉書平臺上通過分析照片墻帖子中包含的常見URL 和相似文本,從而識別水軍活動。Yang 等人[6]分析了Twitter 中網絡水軍的隱藏方法,并提出基于鄰節點特征去識別Twitter 中網絡水軍的方法。但此方法從網絡水軍的鄰節點入手,可能會將非水軍用戶節點誤判為水軍用戶,導致識別準確率不高。本文提出的模型避免了從單特征出發檢測網絡水軍的片面性,降低錯判的概率,本實驗選取十四個對識別水軍有影響的特征屬性,同時利用TensorFlow框架[8],結合深度神經網絡學習算法,大大提高了迭代的速度,提高了準確率,為網絡水軍識別研究提供了有力的技術支持。
2 水軍識別算法模型設計
2.1 問題的定義
由于目標對象的不同,水軍用戶從本質上和正常用戶有很大的區別,因此導致了其行為特征、發布內容以及用戶關系等有很大差異。換言之,針對某用戶而言,其行為表現為和水軍用戶相似或和正常用戶相似兩種形式。所以我們就將水軍識別問題轉化成一個二分類問題。

簡化后的目標函數即為U →{ }0,1 的映射。其中0 表示正常用戶,1 表示水軍用戶。
2.2 特征屬性的選取和分析
(1)數據集的獲取
實驗數據集采集自中國最大的在線社交網站新浪微博。新浪微博的信息內容被限定在140 個漢字以內,對于博主的博文允許陌生人評論、轉發以及點贊,其中博文內容以及評論轉發內容可以包括圖片和視頻鏈接。
本文選取熱門話題及博文萬達地產債今天被砸得很慘,通過內部渠道獲取了413 個水軍用戶以及2102個非水軍用戶,然后通過Python 的Scrapy 爬蟲框架對用戶特征信息進行爬取。同時利用Scrapyd 技術,定時將獲得用戶的所有特征信息存入到MongoDB 數據庫中。
(2)特征選取
本文選取除了Regression[11]和NavieBayes[12]等其他論文選取的基本特征外(如粉絲數(followers_count)、關注數(follow_count)、微博總條數(statuses_count)、微博原創數(original_count)、微博轉發數(forward_count)),還加了其他相關特征作為輸入進行深度神經網絡(DNN)的訓練,具體全部特征選取如表1。

表1 輸入特征
部分解釋如下:
①粉絲數Nfollowers
粉絲數反映用戶的受歡迎的程度,正常用戶的粉絲數相對來說比較穩定,而水軍用戶為了偽裝自己的身份,大都會關注大量正常用戶,然而得到對方回粉的比例就很小,所有水軍用戶粉絲數占比就相對很少。
②關注數Nfollows
關注數,顧名思義為用戶所關注的對象,一般反映的是直接的社交圈。正常用戶大都只會對自己親朋好友或者感興趣的領域博主進行關注,因此用戶的關注數的數量相對比較合理,而水軍用戶為了完成自己的任務,會關注大量不同領域的博主。由此可以得出,水軍用戶的關注數比正常用戶的關注數要高很多。
③粉絲/關注比Rff

其中,Nfollowers 是關注數,Nfollows 是粉絲數。由于為了完成上級派發的任務,水軍用戶會大量關注正常用戶,而獲取對方回粉的機率較低,因此從圖的狀態特征來說,就會呈現出高出度和低入度。
④微博轉發Nforward
水軍用戶為了完成任務,通常要轉發大量微博,而正常用戶通常轉發量相對較少。
⑤原創/轉發比Rof

其中,Norigin 為用戶微博原創的數量,Nforward為用戶微博轉發的數量,水軍通常會轉發大量微博來完成任務,所以水軍用戶通常會呈現出高轉發,低原創的狀態。
⑥陽光信用Sun sh ine Credit
陽光信用是微博2016 年新加入的屬性,分數是結合用戶的注冊時間、微博等級、違規與否、所發微博質量、活躍程度、實名與否以及微博互動等行為,分為極低、較低、一般、較高、極高共5 個不同的等級,在本實驗進行預處理時將級別設置數值1~5 作為訓練集的輸入。
⑦賬戶注冊時間Re gis tr ation Date
以往的相關工作,很少注意到注冊時間的這一屬性,其實在互聯網平臺尤其是新浪微博,可以通過其注冊時間來判斷是否是水軍,非水軍用戶通常注冊時間年限很久,大量的水軍用戶通常注冊時間比較新,加上轉發的微博數量,作為深度學習的輸入,更能準確識別水軍用戶。
⑧微博等級Urank
微博等級是根據用戶活躍天數確定的,是用戶使用微博時間長短及活躍情況等綜合體現,用戶只需每天登錄并使用微博,積累在線時長,就可以獲得活躍天數,從而獲取等級。等級越高。水軍用戶普遍等級不高。
2.3 模型的定義和表示
(1)模型總體框架
TDN 模型旨在利用TensorFlow 的深度神經網絡的準確性,加上重要特征屬性的選取,從而提高檢測出網絡謠言水軍的準確率,其TensorFlow 模型運行流程框架如圖1 所示。基本步驟大致分為四步:①初始化變量。②構建session 會話。③訓練算法。④實現神經網絡。其中包括ReLU 函數(激活函數)和Loss(損失函數)的選取。其中Identity 為激活函數設置為全等映射,目的是暫且不使用Softmax,會放在之后的損失函數中一起計算,并且identity 是返回一個一模一樣新的tensor 的op,這會增加一個新節點到gragh 中。global_step 在滑動平均、優化器、指數衰減學習率等方面都有用到,代表著全局步數,類似于一個鐘表,管理者全局迭代次數。其中圖2 為圖1 中DNN 的展開。里面包含了輸入輸出、隱層,以及各種函數之間的關系。

圖1 TDN處理流程
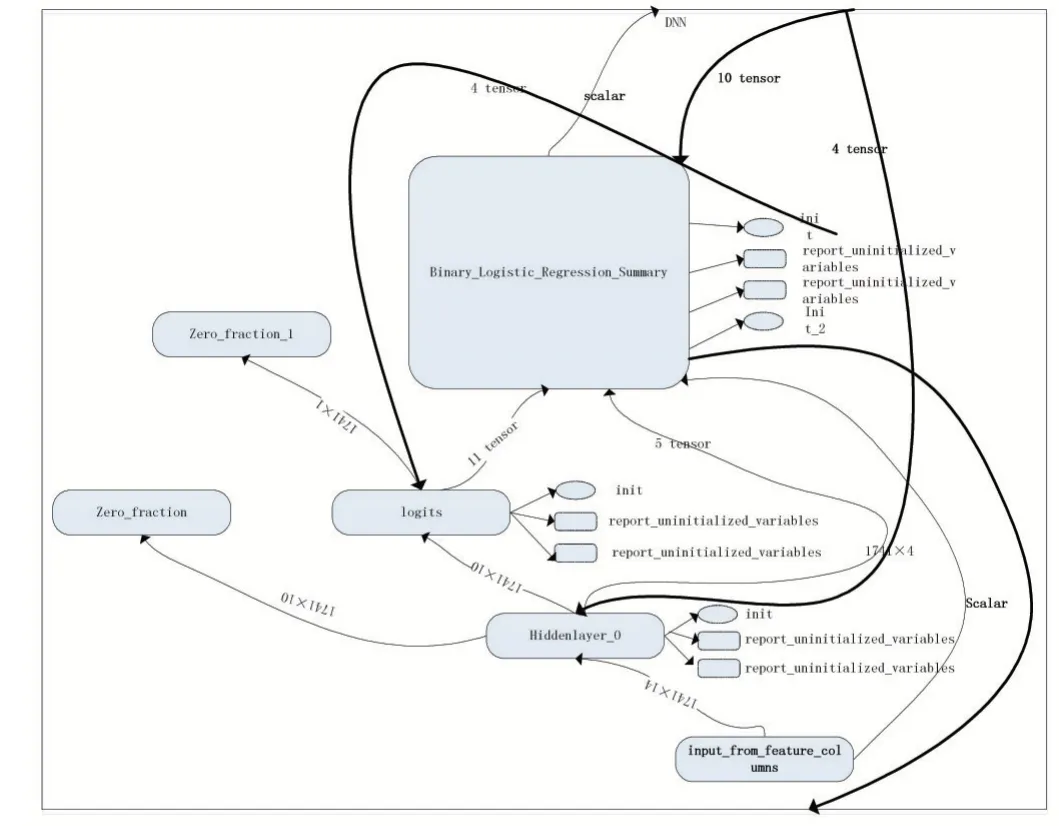
圖2 DNN內部關系
(2)激活函數的選取
在深度神經網絡中激活函數對實驗結果有著直接的影響,本文使用的是一種叫修正線性單元(Rectified Linear Unit,ReLU)9]作為神經網絡的激活函數。ReLU函數其實是一種簡單的分段線性函數,把所有小于零的值都變為0,正值不變,這種操作被業界成為單側抑制,單側抑制有著它不可替代的優勢,因為單側抑制使得神經網絡中的神經元具有稀疏激活性。對比其他的激活函數來說,ReLU 激活函數的不僅在深度神經網絡中表達能力強,而且對于非線性的函數而言,ReLU 函數由于非負區間為常數,因此不存在梯度逐漸消失問題,使得算法模型的收斂速度維持在一個穩定狀態。
3 實驗
3.1 實驗環境和配置
實驗運行環境為:Windows 7 操作系統,1.80GHz 4核處理器,8GB 內存,模型的框架為TensorFlow,編寫語言為Python。
實驗數據:實驗選取了五組數據,是通過特殊渠道購買來的真實數據,共包含413 個水軍用戶和2102 個正常用戶,14 個特征屬性,實驗將這些用戶等比例分成五組,在同一條件下,進行三種算法模型準確性的比較。
3.2 算法準確性
本文對比了以下3 種方法:基于邏輯回歸的方法(簡稱Regression)[11]、基于樸素貝葉斯的方法(簡稱Naive Bayes)[12]以及本文算法TDN。其中Regression 由謝忠紅等人提出,他選取了用戶的行為特征、內容特征等,實現對網絡水軍的檢測,NaiveBayes 則是張艷梅等人設計的微博水軍識別分類器,它選取了6 個特征屬性作為分類依據。本組實驗比較各個模型之間的準確度,以及不同參數對本模型準確度的影響,如圖4 所示,圖中每一組實驗中的左邊為Regression 算法的準確率,中間為TDN 的準確度,右邊為Naive Bayes 的準確度。由于深度神經網絡的核心是利用了反向傳播算法,加上梯度下降算法對神經網絡做進一步優化,使得TDN 無論從準確性還是穩定性都由于其他兩種算法。

圖3 三組不同算法的準確度
3.3 確定隱層節點數的試湊法
TensorFlow 深度神經網絡[13]主要分為三個層次,輸入層、隱層以及輸出層,其中隱層又可以分為不同的層數,不同層數又可以設置不同的結點數,得到的準確率會有很大的差異。一般來說,增加隱層的層數雖然可以使誤差變小和提高結果的精度,但與此同時也使得深度神經網絡變得很復雜,進而使網絡的迭代訓練時間增加,甚至會出現過擬合的現象。所以一般來說,設計神經網絡應將3 層隱層網絡作為首選。為了實驗更加準確,本文采用試湊法來確定隱層的節點數,試湊法的核心思想是在得知隱層節點數的上界和下界的前提下,構造出三層深度神經網絡并且對設置不同隱層節點數分別進行訓練迭代,然后按照統一指標對每一個網絡的性能進行評估,最后選擇最滿意的節點數。
設函數P 為性能函數,P(Mhid)代表隱層節點數為Phid時的網絡性能,P(Mhid)值越大,代表網絡性能越好。隱層節點數的上界為Mh,下界為M1,那么由試湊法得 到 的隱 層 節點 數 為Mhid=argmaxMl≤Mhid≤MhP(Mhid) 。利用試湊法以及仿真實驗得到的結果如圖5 所示,三層隱層的節點數分別為10,20,15 得到的準確率最高。
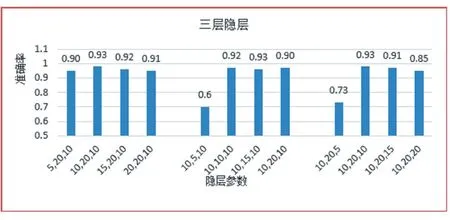
圖4 三層隱層不同節點數對算法的影響
3.4 訓練迭代次數對實驗準確度的影響
不同的訓練迭代次數對實驗結果的準確率也有很大的影響,本實驗在相同實驗下,共包含413 個水軍用戶和2102 個正常用戶,層數為3 層,每層節點分別為:10,20,10。分別測試了不同迭代次數對應的準確率,從圖5 中可以看出,訓練次數達到10000 次時到達一個峰值,隨后準確率逐漸降低,次數小于10000 次,實驗結果會出現欠擬合現象,也就是訓練的不夠,沒有盡可能擬合數據,然而超過1 萬次準確率出現下降的原因就是出現了過擬合的現象。

圖5 迭代次數對算法的影響

圖6 噪聲對算法的影響
3.5 不同層數對時間和精確度影響
眾所周知,神經網絡的不同層數對實驗準確度以及時間性能也有很大的影響[15],本實驗對于隱層的1 到8 層分別做了5 組實驗,實驗數據集取3.2 節的數據集,為了統一變量,對每一層的節點取相同節點數10,對實驗結果取其平均值,得到如圖9 兩組折線,其中系列一為準確度,系列二為時間。此圖可以看出對于準確度來說三層隱層為最佳層數,而隨著層數的增加,TensorFlow 的計算復雜度提高,進而導致需要更多的時間來對數據進行反向反饋。
4 結語
本文主要介紹了一種基于TensorFlow 的深度神經網絡的水軍檢測模型,選取了三個維度的14 個特征參數,對每一維度選取的特征都進行了必要的分析,并且證明了基于這些特征的判定方法可行性。利用新浪微博API 以及Python 的Scrapy 框架對微博數據進行實時爬取和處理,得到實驗所用數據集,對文章中提到的TDN 識別模型進行了準確度對比和性能測試。在同一條件下比較了TDN 和其他模型以及影響模型性能的因素都做了一一分析,TDN 模型具有準確度較高,迭代速度快,能夠大規模處理數據等特性,特別適合應用于水軍識別的二分類問題。但由于不均衡數據的輸入,深度神經網絡算法還是容易出現欠抽樣,從正常用戶訓練的很充分,而水軍用戶就訓練不足,從而導致精度下降,如何在正負樣本不均衡情況下充分利用現有的正負樣本,進一步提高準確度,是接下來我們繼續深入研究的方向。與此同時,統計機器學習中很多其他的監督學習模型,如支持向量機,Xgboost 分類器等是值得我們進一步深入研究的識別方法。

圖7 不同層數對時間和精確度的影響
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
