泛化誤差界指導(dǎo)的鑒別字典學(xué)習(xí)
2019-08-01 01:54:12徐濤王曉明
計(jì)算機(jī)應(yīng)用 2019年4期
徐濤 王曉明

摘 要:在提高字典鑒別能力的過程中,最大間隔字典學(xué)習(xí)忽視了利用重新獲得的數(shù)據(jù)構(gòu)建分類器的泛化性能,不僅與最大間隔原理有關(guān),還與包含數(shù)據(jù)的最小包含球(MEB)半徑有關(guān)。針對這一事實(shí),提出泛化誤差界指導(dǎo)的鑒別字典學(xué)習(xí)算法GEBGDL。首先,利用支持向量機(jī)(SVM)的泛化誤差上界理論對支持向量引導(dǎo)的字典學(xué)習(xí)算法(SVGDL)的鑒別條件進(jìn)行改進(jìn);然后,利用SVM大間隔分類原理和MEB半徑作為鑒別約束項(xiàng),促使不同類編碼向量間的間隔最大化,并減小包含所有編碼向量的MEB半徑;最后,為了更充分考慮分類器的泛化性能,采用交替優(yōu)化策略分別更新字典、編碼系數(shù)和分類器,進(jìn)而獲得編碼向量相對間隔更大的分類器,從而促使字典更好地學(xué)習(xí),提升字典鑒別能力。在USPS手寫數(shù)字?jǐn)?shù)據(jù)集,Extended Yale B、AR、ORL三個(gè)人臉集, Caltech101、COIL20、COIL100物體數(shù)據(jù)集中進(jìn)行實(shí)驗(yàn),討論了超參數(shù)和數(shù)據(jù)維度對識(shí)別率的影響。實(shí)驗(yàn)結(jié)果表明,在七個(gè)圖像數(shù)據(jù)集中,多數(shù)情況下所提算法的識(shí)別率優(yōu)于類標(biāo)簽一致K奇異值分解(LC-KSVD)、局部特征和類標(biāo)嵌入約束字典學(xué)習(xí)(LCLE-DL)算法、Fisher鑒別字典學(xué)習(xí)(FDDL)和SVGDL等算法;且在七個(gè)數(shù)據(jù)集中,該算法也取得了比基于稀疏表示的分類(SRC)、基于協(xié)作表示的分類(CRC)和SVM更高的識(shí)別率。
關(guān)鍵詞:字典學(xué)習(xí);泛化誤差界;支持向量機(jī);最小包含球;數(shù)字圖像分類
中圖分類號:TP391.41
文獻(xiàn)標(biāo)志碼:A
文章編號:1001-9081(2019)04-0940-09
Abstract: In the process of improving discriminant ability of dictionary, max-margin dictionary learning methods ignore that the generalization of classifiers constructed by reacquired data is not only in relation to the principle of maximum margin, but also related to the radius of Minimum Enclosing Ball (MEB) containing all the data. Aiming at the fact above, Generalization Error Bound Guided discriminative Dictionary Learning (GEBGDL) algorithm was proposed. Firstly, the discriminant condition of Support Vector Guided Dictionary Learning (SVGDL) algorithm was improved based on the upper bound theory of about the generalization error of Support Vector Machine (SVM). Then, the SVM large margin classification principle and MEB radius were used as constraint terms to maximize the margin between different classes of coding vectors, and to minimum the MEB radius containing all coding vectors. Finally, as the generalization of classifier being better considered, the dictionary, coding coefficients and classifiers were updated respectively by alternate optimization strategy, obtaining the classifiers with larger margin between the coding vectors, making the dictionary learn better to improve dictionary discriminant ability. The experiments were carried out on a handwritten digital dataset USPS, face datasets Extended Yale B, AR and ORL, object dataset Caltech 101, COIL20 and COIL100 to discuss the influence of hyperparameters and data dimension on recognition rate. The experimental results show that in most cases, the recognition rate of GEBGDL is higher than that of Label Consistent K-means-based Singular Value Decomposition (LC-KSVD), Locality Constrained and Label Embedding Dictionary Learning (LCLE-DL), Fisher Discriminative Dictionary Learning (FDDL) and SVGDL algorithm, and is also higher than that of Sparse Representation based Classifier (SRC), Collaborative Representation based Classifier (CRC) and SVM.
Key words: dictionary learning; generalization error bound; Support Vector Machine (SVM); Minimum Enclosing Ball (MEB); digital image classification
0?引言
由于自然圖像可以表示為字典原子稀疏的線性組合,字典在稀疏表示應(yīng)用中起著非常重要的作用。字典學(xué)習(xí)(Dictionary Learning, DL)[1-4]是當(dāng)前研究的熱點(diǎn)之一,是計(jì)算機(jī)視覺和圖像處理領(lǐng)域的有效工具(如:超分辨率[1]、圖像降噪[2]和圖像分類[3-4]等),并取得了較好的效果。在計(jì)算機(jī)視覺領(lǐng)域,為特殊的視覺任務(wù)構(gòu)建恰當(dāng)高效的字典并不容易;在圖像分類領(lǐng)域,通過真實(shí)樣本圖像學(xué)習(xí)一個(gè)理想的字典,可以恰當(dāng)并有效地完成圖像分類任務(wù)。
面向分類的字典學(xué)習(xí)方法被稱為鑒別性字典學(xué)習(xí)(Discriminative DL, DDL)[5-9]。目前,字典學(xué)習(xí)大致可分為無監(jiān)督字典學(xué)習(xí)和監(jiān)督字典學(xué)習(xí)方法。無監(jiān)督字典學(xué)習(xí)通過最小化目標(biāo)函數(shù)的重構(gòu)誤差獲得一個(gè)恰當(dāng)?shù)淖值洌苯邮沟米值渚哂需b別性,并利用重構(gòu)誤差準(zhǔn)則分類。監(jiān)督字典學(xué)習(xí)方法從監(jiān)督學(xué)習(xí)和數(shù)據(jù)的鑒別信息出發(fā),同時(shí)學(xué)習(xí)字典和分類器,并在字典的優(yōu)化過程中充分解釋數(shù)據(jù)的鑒別信息使得表示系數(shù)具有鑒別性,該方法使用表示系數(shù)作為新的特征進(jìn)行分類。
K奇異值分解(K-means-based Singular Value Decomposition, KSVD)方法[5]通過對K鄰域求解距離獲得鑒別字典;Zhang等[6]在KSVD的基礎(chǔ)上通過同時(shí)學(xué)習(xí)字典和分類器提出鑒別性D-KSVD(Discriminative KSVD)方法。Jiang等[7]在D-KSVD基礎(chǔ)上通過施加鑒別信息對其進(jìn)行了擴(kuò)展,進(jìn)一步提出了標(biāo)簽一致LC-KSVD(Label Consistent KSVD)方法;但LC-KSVD方法忽略了原子間的相似特征,鑒別性能提高有限。為此,Li等[8]利用局部特征和原子的類標(biāo)構(gòu)造嵌入約束的字典學(xué)習(xí)(Locality Constrained and Label Embedding DL, LCLE-DL) 算法。
Yang等[9]提出的FDDL(Fisher DDL)方法通過對字典學(xué)習(xí)模型施加Fisher鑒別準(zhǔn)則來提高字典的鑒別性能;該方法提高了鑒別能力,但是算法在處理大規(guī)模的分類問題上時(shí)間花費(fèi)巨大。相對于FDDL算法,Cai等[10]通過引入固定參變量提出支持向量引導(dǎo)的字典學(xué)習(xí)(Support Vector Guided DL, SVGDL)方法,證明了FDDL的固定權(quán)值分配策略僅是SVGDL自由分權(quán)模式的特例。
上述大部分鑒別字典學(xué)習(xí)方法都采用l0或l1范數(shù)作為稀疏控制條件,但是l0或l1范數(shù)計(jì)算開銷非常巨大。
最近,文獻(xiàn)[11-12]的研究工作中討論了稀疏性在分類任務(wù)中對模型識(shí)別率的影響。
Mehta等[13]進(jìn)一步分析了稀疏系數(shù)的工作機(jī)制和泛化誤差界,認(rèn)為稀疏性在DDL模型中是必要的。由于使用l1范數(shù)正則化稀疏系數(shù)的求解復(fù)雜度遠(yuǎn)遠(yuǎn)高于使用l2范數(shù),尤其是當(dāng)訓(xùn)練樣本和字典原子巨大時(shí),l1范數(shù)正則化稀疏系數(shù)的DDL無效性增加。
故此,SVGDL方法為了獲得更快的運(yùn)算速度和良好的分類識(shí)別率采用l2范數(shù)作為該模型的稀疏控制條件,通過真實(shí)數(shù)據(jù)分析了l1和l2范數(shù)對分類模型識(shí)別率的影響,模型的分類識(shí)別率對l2和l1范數(shù)并不敏感,并把這種不敏感性歸結(jié)為只有少量的支持向量自動(dòng)的引導(dǎo)字典學(xué)習(xí)。
最近,Cai等[14]提出的基于協(xié)作表示的分類(Collaborative Representation based Classifier, CRC)方法的模式分類模型中采用l2范數(shù)作為稀疏系數(shù)控制條件,并通過理論和分類實(shí)驗(yàn)驗(yàn)證,在模式分類任務(wù)中,相對于基于稀疏表示的分類(Sparse Representation based Classifier, SRC)[3]方法,CRC能取得良好的分類精度和節(jié)約大量算法的訓(xùn)練時(shí)間。
SVGDL采用標(biāo)準(zhǔn)的支持向量機(jī)(Support Vector Machine, SVM)[15]作為DDL模型的鑒別項(xiàng),僅考慮了最大化間隔原理,忽視了SVM利用重新獲得數(shù)據(jù)所構(gòu)建的分類器的泛化性能不僅與大間隔原理有關(guān),還與包含數(shù)據(jù)的最小包含球(Minimum Enclosing Ball, MEB)的半徑有關(guān)的基本事實(shí)。
針對這個(gè)基本事實(shí),泛化誤差界指導(dǎo)的鑒別字典學(xué)習(xí)(Generalization Error Bound Guided Discriminative DL,GEBGDL)將SVM的泛化誤差上界作為基于協(xié)作表示(Collaborative Representation, CR)的鑒別字典學(xué)習(xí)方法的鑒別條件,控制編碼系數(shù)的更新。
由于SVGDL編碼向量更新過程中沒有考慮到MEB半徑的變化限制了模型的泛化能力的提高。為進(jìn)一步降低模型的泛化誤差界,GEBGDL算法在模型的更新中充分考慮MEB半徑的變化情況,同時(shí)在訓(xùn)練分類器的過程中減小相似編碼向量間的距離,擴(kuò)大異類編碼向量的分類間隔,從而獲得更加具有鑒別能力的字典,更好地完成分類任務(wù)。
為進(jìn)一步提高鑒別字典的分類性能,本文提出GEBGDL算法利用SVM的泛化誤差上界理論,擴(kuò)大相異編碼向量間的間隔,同時(shí)減小包含所有編碼向量MEB的半徑;采用交替優(yōu)化策略分別更新字典、編碼系數(shù)和分類器,充分考慮分類器的泛化性能,進(jìn)而獲得編碼向量相對間隔更大的分類器促使字典更好地學(xué)習(xí),減小了多分類任務(wù)中二分類器的泛化誤差界,提升字典的鑒別能力;最后在手寫數(shù)字識(shí)別、人臉識(shí)別、物體識(shí)別等數(shù)據(jù)集上驗(yàn)證算法的鑒別性能。
1?相關(guān)工作
鑒別字典學(xué)習(xí)的目的是通過樣本訓(xùn)練字典提高表示系數(shù)的鑒別能力。本章的目標(biāo)是為數(shù)字圖像分類建立一個(gè)有效的鑒別字典學(xué)習(xí)方法。
1.1?支持向量引導(dǎo)的字典學(xué)習(xí)模型
支持向量引導(dǎo)的字典學(xué)習(xí)方法(SVGDL)是一種改進(jìn)的鑒別字典學(xué)習(xí)算法。假定字典學(xué)習(xí)鑒別項(xiàng)中所有權(quán)值都是通過引入變量獲得,參數(shù)化定義為一個(gè)函數(shù),并通過理論證明鑒別項(xiàng)是SVM分類器。同時(shí)采用了SVM的最大化間隔思想學(xué)習(xí)得到鑒別字典。SVGDL算法模型可表述為:
其中:l(si, yi,w,b)是用以訓(xùn)練分類器的Hinge損失函數(shù);θ是一個(gè)固定常數(shù);〈w,b〉可用表示系數(shù)(支持向量)的線性組合表示。
1.2?支持向量機(jī)及其泛化誤差界
SVM是典型的大間隔分類器,其基本的分類問題是二分類問題,進(jìn)而采用不同策略擴(kuò)展為多分類問題。
目前,SVM模式選擇的研究主要集中于交叉驗(yàn)證技術(shù)、優(yōu)化核函數(shù)評估標(biāo)準(zhǔn)和最小化期望風(fēng)險(xiǎn)上界三個(gè)方面。Vapink等[21]提出的留一法誤差(Leave-One-Out Error, LOOError)風(fēng)險(xiǎn)上界估計(jì)方法是分類器真實(shí)錯(cuò)誤率的無偏估計(jì),尋優(yōu)效果準(zhǔn)確。LOOError數(shù)學(xué)化描述如下:
2?泛化誤差界指導(dǎo)的字典學(xué)習(xí)模型
本章中首先建立二分類目標(biāo)模型,并擴(kuò)展為多類字典學(xué)習(xí)模型;其次給出模型的優(yōu)化求解過程;最后給出模型的分類方法。
2.1?模型
支持向量引導(dǎo)的字典學(xué)習(xí)模型采用標(biāo)準(zhǔn)的SVM[15]作為新獲得表示系數(shù)的分類器。監(jiān)督學(xué)習(xí)方面,SVM作為大間隔分類器,在理論和實(shí)踐中替代線性分類器取得了良好的分類效果。字典學(xué)習(xí)方面,SVM與DDL模型相結(jié)合的方法[10,22]已獲得了良好的結(jié)果。
2.1.1?二分類模型
首先,使用基于半徑/間隔界的R-SVM替換支持向量引導(dǎo)的字典學(xué)習(xí)模型(2)的鑒別條件。其數(shù)學(xué)化描述如下:
2.1.2?多分類模型
標(biāo)準(zhǔn)SVM將間隔平方γ2的倒數(shù)‖w‖2作為正則項(xiàng)。然而,SVM的泛化誤差界依賴于R2/γ2(即:R2‖w‖2),這也是GEBGDL采用泛化誤差上界改進(jìn)SVGDL算法的動(dòng)機(jī)。當(dāng)訓(xùn)練樣本固定,MEB的半徑R是一個(gè)固定常數(shù)。然而,在DDL模型的更新過程中,由模型產(chǎn)生的表示系數(shù)S在迭代的過程中不斷變化,即包含所有表示系數(shù)si的MEB的半徑R也隨之改變。
SVGDL算法簡單地為表示系數(shù)空間乘以一個(gè)固定的常數(shù)可以增加正負(fù)樣本間的間隔,但這并不是最真實(shí)分類效果。因此,為了獲得真實(shí)的分類效果,SVM泛化誤差上界理論對SVGDL模型分類器的改進(jìn)提供了理論依據(jù)。
2.2?求解模型
由于多類字典模型(9)對于所有的變量并非聯(lián)合的凸優(yōu)化問題,因此,借鑒文獻(xiàn)[10]所采用的交替優(yōu)化策略對多類字典模型涉及到的所有變量進(jìn)行交替優(yōu)化。詳細(xì)過程可以分為三個(gè)部分:固定S、〈W,b〉和R2,更新字典D;固定D、〈W,b〉和R2,更新表示系數(shù)S;固定D和S,更新〈W,b〉和R2可以轉(zhuǎn)變成求解SVM和MEB最小包含球的兩個(gè)子過程。
2.2.1?更新表示系數(shù)S
2.2.3?更新〈W,b〉和R2
當(dāng)D和S固定后,更新〈W,b〉和R2。模型的更新問題轉(zhuǎn)變成求解多類SVM和MEB最小包含球的兩個(gè)子問題。通過多次求解二次規(guī)劃問題獲得其解。借鑒文獻(xiàn)[21]方法,分別求得〈W,b〉和R2。
綜合以上模型的求解步驟,概括GEBGDL算法的訓(xùn)練過程如下:輸入?訓(xùn)練樣本X∈Rm×n,初始化權(quán)衡參數(shù)λ和τ,懲罰系數(shù)θ,訓(xùn)練數(shù)據(jù)的類標(biāo)簽Y∈Rn,最大迭代次數(shù)T和收斂閾值。
輸出?字典D和多類R-SVM的〈W,b〉。
1)初始化字典D,表示系數(shù)S,采用交替優(yōu)化策略更新。
2)固定D,{W,b}和R2使用式(10)更新表示系數(shù)S:a)當(dāng)?shù)螖?shù)t=1和yi(wTcsi+bc)≤1時(shí),使用式(19)更新S;
b)當(dāng)?shù)螖?shù)t≥2和yi(wTcsi+bc)>1時(shí),使用式(14)更新S。
3)固定S,{W,b}和R2,使用式(20)更新字典D。
4)固定D和S,使用式(3)和(4)分別更新{W,b}和R2。
5)若相鄰兩次迭代后目標(biāo)函數(shù)值之差小于收斂閾值,則迭代終止;否則返回2)繼續(xù)執(zhí)行,直到收斂或達(dá)到最大迭代次數(shù)T終止。
2.3?分類方法
模型訓(xùn)練完成得到字典D和R-SVM的最優(yōu)分類超平面以及偏置{W,b}。當(dāng)輸入一個(gè)新的測試樣本x,首先將x通過固定的矩陣M進(jìn)行投影編碼,映射成編碼向量矩陣的列向量s=Mx,矩陣M=(DTD+λI)-1DT。然后,利用C個(gè)線性分類器{wc,bc}作用于編碼向量s,通過式(23)預(yù)測樣本x類別標(biāo)簽y。
結(jié)合算法的訓(xùn)練過程和測試過程,圖1為GEBGDL算法的流程。
GEBGDL算法的訓(xùn)練過程采用交替優(yōu)化策略分別更新字典D、編碼系數(shù)S,支持向量機(jī)的分類法矢量W和偏置b以及最小包含球的半徑的平方R2。
測試過程通過訓(xùn)練所得到的字典D獲得映射矩陣M,將測試樣本x映射成測試樣本的編碼系數(shù)s,
最后通過支持向量機(jī)的分類法矢量和偏置預(yù)測測試樣本的類別,獲得分類結(jié)果。
GEBGDL訓(xùn)練過程的時(shí)間開銷主要由3個(gè)部分組成:更新學(xué)習(xí)字典D的時(shí)間復(fù)雜度是O(K3mn),更新編碼系數(shù)的時(shí)間復(fù)雜度是O(K3mn),更新線性SVM和MEB的時(shí)間復(fù)雜度分別是O(Cmn)和O(mn)。由于目標(biāo)優(yōu)化函數(shù)是非凸函數(shù),并不能獲得全局最小值,經(jīng)驗(yàn)上可以通過目標(biāo)函數(shù)值的遞減變化獲得一個(gè)理想的字典和線性分類器。分類測試環(huán)節(jié)的時(shí)間復(fù)雜度是O(Km)。其中:m是樣本維度,n是樣本個(gè)數(shù),K是字典原子個(gè)數(shù)(或編碼系數(shù)矩陣逐列向量的維度),C是樣本所包含的類別數(shù)。
3?實(shí)驗(yàn)與結(jié)果分析
為了對本文提出的鑒別字典學(xué)習(xí)方法進(jìn)行定量評價(jià),實(shí)驗(yàn)在7個(gè)標(biāo)準(zhǔn)數(shù)據(jù)集(包括USPS、Extended Yale B[24]、AR[25]、ORL和Caltech101[26]、COIL20和COIL100)上進(jìn)行仿真實(shí)驗(yàn)。實(shí)驗(yàn)平臺(tái)為處理器Intel i3-4130 @3.40GHz的64位Windows 7旗艦版,Matlab R2013b。
3.1?模型參數(shù)對識(shí)別率的影響
GEBGDL模型涉及3個(gè)主要參數(shù),分別為平衡參數(shù)λ和τ,以及SVM和MEB的懲罰系數(shù)θ。為防止過擬合的產(chǎn)生,平衡參數(shù)均采用交叉驗(yàn)證自動(dòng)選取。為保證實(shí)驗(yàn)的公平性,實(shí)驗(yàn)結(jié)果為獨(dú)立運(yùn)行20次后的平均識(shí)別率。
為了討論多個(gè)參數(shù)變量的綜合影響,實(shí)驗(yàn)中對3個(gè)主要參數(shù)進(jìn)行了綜合測試,首先,在Extended Yale B數(shù)據(jù)集上固定選取每一類別20個(gè)樣本作為訓(xùn)練數(shù)據(jù),同時(shí)固定訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)。
圖2是在Extended Yale B數(shù)據(jù)集控制其中一個(gè)變量后,其余兩個(gè)可變參數(shù)對識(shí)別率影響的曲面。
圖2依次給出三個(gè)可變參數(shù)對SVGDL和本文算法在平均識(shí)別率上的影響,為模型的綜合參數(shù)選擇提供了實(shí)驗(yàn)依據(jù)。當(dāng)兩種算法參數(shù)設(shè)置一致時(shí),通過圖2中的顏色標(biāo)簽可看出,本文GEBGDL算法的識(shí)別率優(yōu)于SVGDL,這說明本文算法采用SVM的泛化誤差上界理論的改進(jìn)可以提高字典的鑒別能力。圖2的實(shí)驗(yàn)結(jié)論同時(shí)為交叉驗(yàn)證方法快速的參數(shù)選擇提供了合理的參考范圍。表1給出了通過交叉驗(yàn)證方法自動(dòng)選取參數(shù)后模型對于7個(gè)標(biāo)準(zhǔn)數(shù)據(jù)集的參數(shù)設(shè)置。
3.2?標(biāo)準(zhǔn)數(shù)據(jù)介紹和實(shí)驗(yàn)設(shè)置及其結(jié)果
本文采用7個(gè)不同的標(biāo)準(zhǔn)數(shù)據(jù)集對方法SVM[15]、CRC[14]、SRC[3],近似對稱人臉圖像人臉識(shí)別和稀疏表示分類方法ASF-SRC[27]和其余幾種不同的字典學(xué)習(xí)方法(D-KSVD[6]、LC-KSVD[7]、LCLE-DL[8]、DLSPC[28]、FDDL[9]、SVGDL[10]和BDLRR[29])進(jìn)行對比實(shí)驗(yàn),包含手寫數(shù)字識(shí)別、人臉識(shí)別、物體識(shí)別。
數(shù)據(jù)集和實(shí)驗(yàn)設(shè)計(jì)如下:
1)USPS手寫數(shù)字?jǐn)?shù)據(jù)集收集了數(shù)字0~9的9298張圖像,每一張是16×16像素。由于本文算法采用二范數(shù)的正則項(xiàng)作為稀疏控制條件和使用了SVM的分類理論作為鑒別性條件,故在USPS手寫數(shù)據(jù)集上將本文算法和CRC、SRC、SVM、SVGDL進(jìn)行對比。借鑒http://www.cad.zju.edu.cn的USPS數(shù)據(jù)集的實(shí)驗(yàn)設(shè)置方式,選擇7291張圖像作為訓(xùn)練數(shù)據(jù),剩余的2007張作為測試數(shù)據(jù),并固定字典原子。表2是不同算法的平均識(shí)別率,相對于CRC、SRC、SVM,本文算法的平均識(shí)別率提高了2~3個(gè)百分點(diǎn),SVGDL提高了1~2個(gè)百分點(diǎn),
這說明將SVM作為基于協(xié)作表示的字典學(xué)習(xí)的鑒別條件或者基于稀疏表達(dá)的鑒別條件,可以增強(qiáng)字典模型的鑒別能力,提高分類性能。
2)Extended Yale B人臉數(shù)據(jù)集收集了包含38個(gè)類別的2414張正臉圖像。每一類別分別有192×168像素的64張正臉。
本數(shù)據(jù)集的識(shí)別難點(diǎn)在于多變光照條件和豐富的面部表情。借鑒文獻(xiàn)[6]的實(shí)驗(yàn)布局方式,對Extended Yale B人臉集隨機(jī)地為每一類別選擇5、10、15、20張圖像作為訓(xùn)練數(shù)據(jù),其余的作為測試數(shù)據(jù),每張圖像裁剪為32×32大小,為了保證實(shí)驗(yàn)的公平性,借鑒文獻(xiàn)[6]方法對所有算法的實(shí)驗(yàn)數(shù)據(jù)利用過主成分分析法(Principal Component Analysis, PCA)降低特征維度到m=300。
從表3可看出,本文算法的平均識(shí)別率比SVGDL算法提高了1.5個(gè)百分點(diǎn),比其他方法提高2~8個(gè)百分點(diǎn)。
3)AR人臉數(shù)據(jù)集包含126個(gè)類別的超過4000張人臉圖像。與Extended Yale B所不同的是,它具有更加豐富的面部表情(微笑、生氣和尖叫等)和光照變化。借鑒文獻(xiàn)[6]的實(shí)驗(yàn)布局方式,對于AR人臉集,分別選擇50位男性和50位女性的共2600張圖像(每人26張)作為實(shí)驗(yàn)數(shù)據(jù);每一類別選取3、5、7張作為訓(xùn)練數(shù)據(jù),剩余的作為測試數(shù)據(jù),并利用PCA降低特征維度到m=300。從表4可看出,本文算法的平均識(shí)別率相對于其他算法提高了1~10個(gè)百分點(diǎn),比典型的字典學(xué)習(xí)方法提高了1~3個(gè)百分點(diǎn),比SVGDL提高了1.4個(gè)百分點(diǎn)。
4)ORL人臉數(shù)據(jù)集(http://www.cl.cam.ac.uk)包含了40個(gè)類別的400張人臉圖像,每一個(gè)類別10張圖像。該數(shù)據(jù)包含每一個(gè)人不同時(shí)期、不同視角、多變的面部表情和不同的面部細(xì)節(jié)。為了公平,所有實(shí)驗(yàn)采用64×64像素的圖像作為訓(xùn)練數(shù)據(jù),并隨機(jī)選擇2、4、6張圖像作為訓(xùn)練數(shù)據(jù),剩余的作為測試數(shù)據(jù)。
從表5可看出,本文算法的平均識(shí)別率比SVGDL算法提高了約1個(gè)百分點(diǎn),比其他算法提高了約3個(gè)百分點(diǎn)。
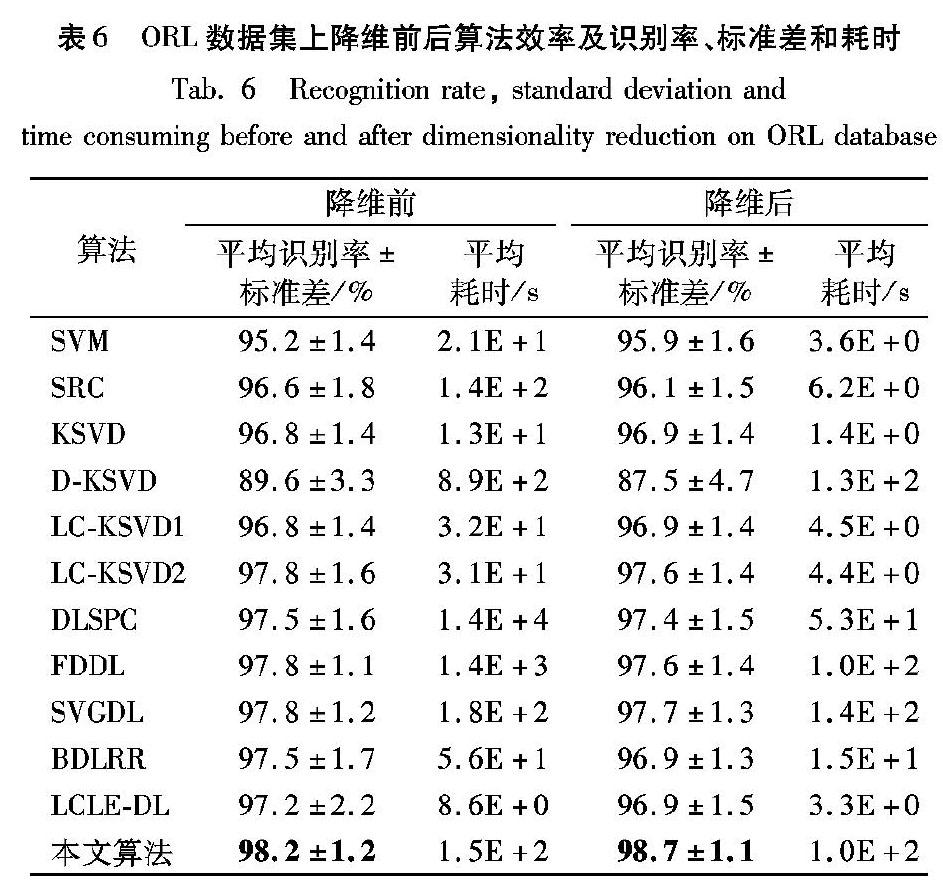
實(shí)驗(yàn)中,為了說明采用PCA對裁剪后的圖像降維前后對識(shí)別率和算法效率的影響,隨機(jī)地為每一類別選擇8張圖像降維和不降維的實(shí)驗(yàn),并在表6中給出了降維前后算法效率及識(shí)別率、標(biāo)準(zhǔn)差和耗時(shí)。
從表6可看出:采用PCA降維前后算法的平均識(shí)別率沒有顯著的變化,但是,降維后大幅降低了算法的運(yùn)行時(shí)間。
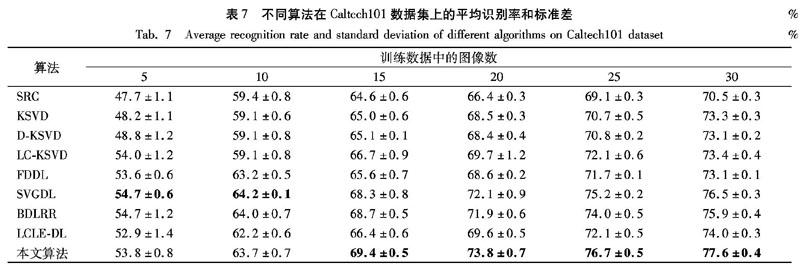
5)Caltech101物體數(shù)據(jù)集包含了101個(gè)類別物體的29780張圖像,每一個(gè)類別超過80張圖像。借鑒文獻(xiàn)[6]的實(shí)驗(yàn)布局和設(shè)置方式,由于物體數(shù)據(jù)集的固有特性,公平起見使用與該文獻(xiàn)相同特征維度m=3000的圖像作為訓(xùn)練和測試數(shù)據(jù),并為每一類別物體選取5、10、15、20、25和30張不同圖像作為訓(xùn)練數(shù)據(jù),剩余部分作為測試數(shù)據(jù),分別固定字典的原子數(shù)量K。從表7可看出:本文算法在增加訓(xùn)練數(shù)據(jù)、固定原子個(gè)數(shù)K的條件下識(shí)別率明顯提高,說明了模型足夠稀疏;模型在小樣本5和10的情況下,識(shí)別率略低于SVGDL算法,但是隨著訓(xùn)練樣本的增加,本文模型表現(xiàn)出了更好的分類性能。
6)COIL20數(shù)據(jù)集包含了20個(gè)類別從不同角度拍攝的1440張圖像,每一類別72張圖像;COIL100數(shù)據(jù)集包含了100個(gè)類別從不同角度拍攝的7200張圖像,每一類別72張圖像,均并裁剪為32×32像素。借鑒http://www.cad.zju.edu.cn的實(shí)驗(yàn)數(shù)據(jù)設(shè)置,每一張采用32×32像素的圖像。為了公平每次隨機(jī)選取每一類別的5、10、15和20張圖像作為訓(xùn)練數(shù)據(jù),剩余的作為測試數(shù)據(jù)。每一張圖像的特征維度m=1024,并分別為COIL20和COIL100固定字典原子。從表8~9可看出:在多類別不同物體的識(shí)別上,本文算法識(shí)別率相對于FDDL和SVM并沒有顯著提高,但是相對于SVGDL方法平均識(shí)別率提高了1個(gè)百分點(diǎn),說明了本文采用SVM泛化誤差上界理論對SVGDL方法的改進(jìn)是有效的,對新構(gòu)建分類器的泛化性能上考慮是必要的。
3.3?模型收斂性討論
為了說明本文算法的收斂性質(zhì),給出優(yōu)化目標(biāo)函數(shù)(9)的數(shù)值的變化曲線。目標(biāo)函數(shù)是一個(gè)單調(diào)遞減的函數(shù),迭代優(yōu)化的過程中其值在每一輪迭代中呈現(xiàn)出遞減趨勢。圖3為本文算法在3個(gè)數(shù)據(jù)集的收斂曲線,從中可明顯看出:3個(gè)數(shù)據(jù)集上本文算法在5次迭代后迅速收斂到極小值,并在20次迭代范圍內(nèi)可以迅速收斂達(dá)到目標(biāo)函數(shù)最小最優(yōu)化目標(biāo),充分說明了本文算法的收斂性。
4?結(jié)語
為了提高字典的鑒別性能,在SVGDL算法的基礎(chǔ)上充分考慮到重新獲得數(shù)據(jù)構(gòu)建的分類器的泛化性能,提出了泛化誤差界指導(dǎo)的鑒別學(xué)習(xí)算法。在實(shí)際情況下,支持向量引導(dǎo)字典學(xué)習(xí)方法,通過學(xué)習(xí)后的字典映射到系數(shù)空間進(jìn)行分類。
與SVGDL方法所不同的是,GEBGDL不僅考慮到了不同類別間的編碼系數(shù)空間的大間隔分類,同時(shí)使得同類別間的分布更加緊湊,促使同類原子之間盡可能地反映類別信息,增強(qiáng)字典的鑒別能力。實(shí)驗(yàn)結(jié)果表明本文GEBGDL算法的識(shí)別率在大多數(shù)情況不僅比直接訓(xùn)練原始的SVM、CRC和SRC算法高,而且比D-KSVD、LC-KSVD、LCLE-DL、FDDL、BDLRR和SVGDL典型的字典學(xué)習(xí)算法高,人臉識(shí)別方面也比融合圖像預(yù)處理的ASF-SRC的識(shí)別率高。因此,在模型的訓(xùn)練中考慮分類項(xiàng)的泛化性能,促使了字典鑒別能力的提高。由于在求解SVM和MEB的問題上時(shí)間花銷巨大,下一步的研究方向是如何提高分類器的訓(xùn)練速度,減小字典訓(xùn)練過程的時(shí)間開銷。
參考文獻(xiàn)(References)
[1] WANG Z, LIU D, YANG J, et al. Deep networks for image super-resolution with sparse prior[C]// ICCV 2015: Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2016: 370-378.
[2] LUO Y, XU Y, JI H. Removing rain from a single image via discriminative sparse coding[C]// ICCV 2015: Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 3397-3405.
[3] WRIGHT J, YANG A Y, GANESH A, et al. Robust face recognition via sparse representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227.
[4] LIU Q, LIU C. A novel locally linear KNN model for visual recognition [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1329-1337.
[5] AHARON M, ELAD M, BRUCKSTEIN A. K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation [J]. IEEE Transactions on Signal Processing, 2006, 54(11): 4311-4322.
[6] ZHANG Q, LI B. Discriminative K-SVD for dictionary learning in face recognition[C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. ?Washington, DC: IEEE Computer Society, 2010: 2691-2698.
[7] JIANG Z, LIN Z, DAVIS L S. Label consistent K-SVD: learning a discriminative dictionary for recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2651-2664.
[8] LI Z, LAI Z, XU Y, et al. A locality-constrained and label embedding dictionary learning algorithm for image classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(2): 278-293.
[9] YANG M, ZANG L, FENG X, et al. Sparse representation based Fisher discrimination dictionary learning for image classification[J]. International Journal of Computer Vision, 2014, 109(3): 209-232.
[10] CAI S, ZUO W, ZHANG L, et al. Support vector guided dictionary learning [C]// ECCV 2014: Proceedings of the 13th European Conference on Computer Vision, LNCS 8692. Berlin: Springer, 2014: 624-639.
[11] RIGAMONTI R, BRWON M A, LEPTIT V. Are sparse representations really relevant for image classification?[C]// Proceedings of the CVPR 2011. ?Washington, DC: IEEE Computer Society, 2011: 1545-1552.
[12] ZHANG L, YANG M, FENG X. Sparse representation or collaborative representation: Which helps face recognition?[C]// Proceedings of the 2011 International Conference on Computer Vision. ?Washington, DC: IEEE Computer Society, 2011: 471-478.
[13] MEHTA N A, GRAY A G. Sparsity-based generalization bounds for predictive sparse coding[EB/OL]. [2018-05-10]. http://www.jmlr.org/proceedings/papers/v28/mehta13.pdf.
[14] CAI S, ZHANG L, ZUO W, et al. A probabilistic collaborative representation based approach for pattern classification[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. ?Washington, DC: IEEE Computer Society, 2016: 2950-2959.
[15] PLATT J C. 12 Fast training of support vector machines using sequential minimal optimization[M]// SOENTPIET R. Advances in Kernel Methods: Support Vector Learning. Cambridge, MA: MIT Press, 1999: 185-208.
[16] MAIRAL J, BACH F, PONCE J. Task-driven dictionary learning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 791-804.
[17] RAMIREZ I, SPRECHMANN P, SAPIRO G. Classification and clustering via dictionary learning with structured incoherence and shared features[C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. ?Washington, DC: IEEE Computer Society, 2010: 3501-3508.
[18] GAO S, TSANG W H, MA Y. Learning category-specific dictionary and shared dictionary for fine-grained image categorization[J]. IEEE Transactions on Image Processing, 2013, 23(2): 623-634.
[19] ZHOU N. Learning inter-related visual dictionary for object recognition[J]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. ?Washington, DC: IEEE Computer Society, 2012: 3490-3497.
[20] KONG S, WANG D. A dictionary learning approach for classification: separating the particularity and the commonality[C]// ECCV 2012: Proceedings of the 12th European Conference on Computer Vision, LNCS 7572. Berlin: Springer, 2012: 186-199.
[21] VAPNIK V, CHAPPLE O. Bounds on error expectation for support vector machines[J]. Neural Computation, 2000, 12(9): 2013-2036.
[22] LIAN X C, LI Z, LU B L, et al. Max-margin dictionary learning for multiclass image categorization[C]// ECCV 2010: Proceedings of the 11th European Conference on Computer Vision, LNCS 6314. Berlin: Springer, 2010: 157-170.
[23] SCHOLKOPF B, PLATT J, HOFMANN T. Efficient sparse coding algorithms[EB/OL]. [2018-05-10]. http://papers.nips.cc/paper/2979-efficient-sparse-coding-algorithms.pdf.
[24] LEE K C, HO J, KRIEGMAN D J. Acquiring linear subspaces for face recognition under variable lighting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 684-698.
[25] MARTINEZA M, BENAVENTE R. The AR face database, TR #24 [R]. Barcelona, Spain: Computer Vision Center, 1998.
[26] LI F F, FERGUS R, PERONA P. Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories[C]// Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop. Washington, DC: IEEE Computer Society, 2004: 178.
[27] XU Y, ZHANG Z, LU G, et al. Approximately symmetrical face images for image preprocessing in face recognition and sparse representation based classification[J]. Pattern Recognition, 2016, 54: 68-82.
[28] WANG D, KONG S. A classification-oriented dictionary learning model: explicitly learning the particularity and commonality across categories[J]. Pattern Recognition, 2014, 47(2): 885-898.
[29] ZHANG Z, XU Y, SHAO L, et al. Discriminative block-diagonal representation learning for image recognition[J]. IEEE Transactions on Neural Networks & Learning Systems, 2017, 29(7): 3111-3125.
