東巴象形文字特征曲線提取算法研究
2019-08-08 08:03:20楊玉婷康厚良
圖學學報 2019年3期
關鍵詞:特征
楊玉婷,康厚良
東巴象形文字特征曲線提取算法研究
楊玉婷1,康厚良2
(1. 云南開放大學文化旅游學院,云南 昆明 650000;2.蘇州市職業大學體育部,江蘇 蘇州 215000)
東巴文是一種原始的圖畫象形文字,要提高東巴文字的識別率,準確提取字符的特征曲線是關鍵。現階段對東巴文字的檢索和識別研究大多仍停留在使用已有的、通用的及成熟的識別技術,對東巴文字本身的分析和討論較少。因此,結合東巴象形文字的形態特征和結構要素,給出了基于鏈碼的連通域優先級標記算法(CDPM),該算法通過擴展Freeman鏈碼在邊緣檢測及曲線局部分割方面的功能,實現了使用一種算法完成輪廓型及結構型兩種不同類型東巴字素的特征曲線提取,通過大量實驗及與其他經典邊緣檢測算法的比較表明,CDPM算法具有良好的通用性、可擴展性及健壯性,并且準確率達到了98.2%,從而為東巴文字的檢索和識別奠定堅實的基礎。
CDPM算法;東巴象形文字;邊緣檢測;字符分割
1 東巴文字及特征
東巴文是一種十分原始的圖畫象形文字[1],作為人類早期圖畫文字向象形文字、標音文字過渡的文字形式,其既具有圖畫文字以圖表意,又具有現代文字使用簡單線條表意的特點[2]。2003年,使用東巴文撰寫的東巴古籍被聯合國教科文組織列入世界記憶遺產名錄[3]。
東巴文在檢索和識別方面的研究起步較晚,相關文獻較少且連貫性不強。其中,GUO等[4-7]給出了多種用于東巴象形文字識別的方法,LI等[8]提出了東巴文字識別的預處理系統。楊萌等[9]提出了基于神經網絡的東巴文字識別算法,王海燕等[10-11]使用支持向量機的方法實現了對東巴文字的識別。另外,WANG等[12]提出了構建納西東巴手稿語料和知識數據庫的設想,而YANG等[13]則基于鏈碼(chain code)在.Net平臺上實現了用于單個東巴字符的輸入與識別系統。
分析相關文獻可知,現階段對東巴文字的檢索和識別研究大多仍停留在使用已有的、通用的及成熟的識別技術,對東巴字本身的分析和討論較少。分析東巴文字的結構,準確提取能夠反映文字本質特征的曲線,有利于提高東巴文字檢索和識別的準確率,同時也有助于分析東巴文字的結構和形態、比較東巴文與其他象形文字的演變過程等方面的研究。為了獨立分析不同文字的特征,將東巴文字的基本字素再細分為輪廓型字素和結構型2類字素。輪廓型字素通過臨摹物體的外在形狀來表達實際含義,并且文字的線條細化后,輪廓特征仍非常明顯且閉合性好;而結構型字素一般使用簡單的字符筆劃通過描繪事物的結構或骨架來表達含義,文字的線條細化后能夠得到顯著的文字結構或骨架特征,其中人形字最具代表性,見表1。

表1 東巴字素的分類
顯然,輪廓型字素的特征曲線應為文字的外在輪廓,而結構型字素的特征曲線應為文字局部細化線條的有序組合。為了滿足2類東巴字素特征曲線提取的需求,結合東巴象形文字的形態特征和結構要素,給出了基于鏈碼的連通域優先級標記算法(chain code based connected domain priority marking, CDPM),該算法通過擴展Freeman鏈碼[14]在邊緣檢測及曲線局部分割方面的功能,實現了使用一種算法完成2種不同類型東巴字素的特征曲線提取,為東巴文字的檢索和識別奠定基礎。
2 基于鏈碼的連通域優先級標記算法
CDPM算法的基本思想是:首先,確定字符特征曲線的提取方向為逆時針方向;然后,將字符的起點作為參考點,根據初始參考向量方向計算與參考點相鄰的8個鄰域點的權值,選擇權值最大的點作為特征點;接著,以新的特征點作為參考點,計算新的參考向量方向及與參考點相鄰的8個鄰域點的權值,重復上述操作,直到回到字符的起點或者完成字符所有終端點的遍歷為止。其中,對于輪廓型字素,當算法回到字符起點,說明字符的特征曲線提取完成;而對于結構型字素,當算法遍歷完字符的所有終端點,說明已完成字符局部曲線的分割和排序。
2.1 確定字符特征曲線的起點及初始參考向量
統一起點使不同字符的特征曲線也能具有相同的對應關系。假設給定的東巴字為,P(x,y)是所包含的像素點,若設置始終位于坐標的第一象限,則選取字符中距離坐標原點最近的終端點或像素點作為特征曲線的起點,則起點的選取步驟為:

(2) 細化文字線條,獲得包含個像素點的細化字符。由于東巴文字是使用“竹筆”書寫的,線條寬度基本一致,線條的細化不會對文字本身產生太大的影響;
(4) 若1,則將該終端點作為特征曲線的起點;若1,則選取距離坐標原點最近的終端點作為起點;若1,說明具有閉合的外在輪廓,則選取中距離坐標原點最近的像素點P作為起點。因此,特征曲線的起點1為

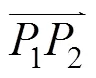
2.2 計算鄰近點的優先級權值

高中學生在生物學科中的核心素養體現高中學生在生物教學中核心素養的培養,就是為了讓學生對生物學科的全面了解,也幫助學生情感態度的培養與形成.知識素養是培養學生核心素養的基礎,而核心素養則是學生各個方面的培養,情感態度的培養與價值觀的培養是建立在知識教育能力的培養之上.
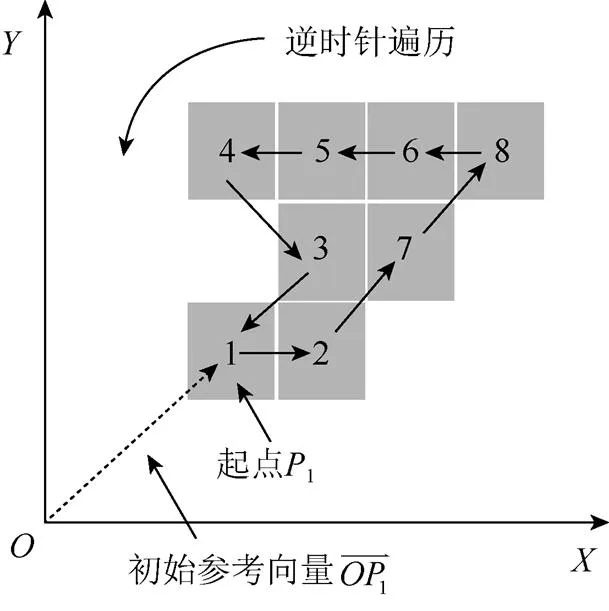
圖1 CDPM算法的基本原理(以終端點P1為起點,為 初始參考向量,按照逆時針方向提取字符輪廓)
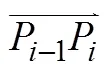
表2 方向向量對點Pi的8個鄰接點優先級的影響

2.3 CDPM算法在輪廓型字素中的應用

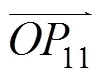

圖2 包含單像素線條的輪廓型字素的特征曲線提取
結論1. 當輪廓型字素中包含由單像素點組成的線條時,使用CDPM算法同樣能夠得到連續、按逆時針順序排列的特征曲線。
2.4 CDPM算法在結構型字素中的應用
結構型字素的特征曲線是局部細化線條的有序組合,為了驗證CDPM算法能實現字符局部細化線條的分割并按照逆時針順序排列,使用圖3中的例子進行說明。

由于存入交點隊列的候選像素點也是按照權值從大到小的順序存儲的,因此,若字符的骨架具有相似結構,則得到的分割結果及分割順序也應具有相似性,如圖3(c)所示,由此可得結論2。
(a) 確定算法的起點和方向
(b) 使用CDPM算法進行分割
(c) 按分割順序重新排列曲線,獲得字符的特征曲線 圖3 結構型字素的骨架分割及排序
以(人)、(抖,裝模作樣)、(立)和(坐)為例,使用CDPM算法分割并按先后順序排列字符的局部骨架曲線,如圖4所示。顯然,第1行2個字符的第j~m條局部曲線與第2行2個字符的第k~n條局部曲線段不但形態相似,而且曲線段的排列順序也一一對應,說明結論2是正確的。
圖4 結構型字素的骨架分割及排序實例
2.5 復雜度分析
CDPM算法根據參考點和參考向量的方向來標記參考點的8鄰域點的優先級權值,選擇權值最大的鄰接點作為新的參考點,并計算新的參考向量方向,繼續計算參考點的8鄰域優先級權值,反復執行上述過程直到遇到字符的終端點或回到起點為止。由于計算參考點的8鄰域點權值及查找最大權值點的計算在最壞情況下將執行8次,若共有n個待測特征點,則算法的時間復雜度為O(8×n)≈O(n)。因此,CDPM算法的時間復雜度是線性的。
3 實驗分析
為方便測試,從1 591個東巴文字中為結構型字素和輪廓型字素分別選取10類字符,每類包括數量不等的東巴字(表3)。
表3 輪廓型和結構型字素的10種類型 類別結構型(基本型)結構型(擴展型)類別輪廓型(基本型)輪廓型(擴展型) 人魚蟲 蹲鳥 單手持物花 雙手持物手 右側偏移山 頭戴冠房屋 心水 植物祭祀 行走牲畜 坐山坡
其中,輪廓型字素包括魚蟲、鳥、花、手、山、房屋、水、東巴祭祀、牲畜和山坡等,結構型字素包括人、蹲、單手持物、雙手持物、右側偏移、頭戴冠、心、植物、行走和坐等。并且,每種類型的東巴字都分為基本型和擴展型。基本型中的東巴字基本保持了字素的原有特征,變異較少;而擴展型一般是對基本型的擴展,在形態上具有一定的變異。
3.1 基礎性測試
基礎性測試是將2種類型中的“基本型”作為測試對象,驗證當待測字符僅包含輪廓型或結構型單素字的基本特征時,使用CDPM算法提取輪廓特征曲線或分割骨架曲線段的正確性。在使用CDPM算法提取字符特征曲線前,首先需要對東巴字符的圖片進行二值化、筆畫線條細化和字符中離散綴加元素的去除等預處理操作。
圖5顯示了使用CDPM算法提取輪廓型字素(基本型)的輪廓特征曲線并按照逆時針順序排列的效果。其中,綠色的線條為文字的細化線條,而黑色線條為文字的輪廓特征曲線。通過測試,CDPM提取“基本型”輪廓特征曲線的準確率為100%。
圖6顯示了使用CDPM算法實現結構型字素(基本型)的骨架分割,且局部骨架曲線按照先后順序排列的效果。各局部曲線段排序時對應的顏色順序為:藍色、綠色、紅色、青綠色、桃紅色、黑色。當局部曲線段超過6條時,重復上述顏色。對10種結構型字素中的46個“基本型”字符的測試中,錯誤分割1個(紅框標記),正確率為97.83%。發生錯誤的原因是,字符的2個組成部分在構字中均為主成分,導致成分提取錯誤。
解法1:設u=,v=,則u2+v2=1且u≥0,v≥0,該曲線方程為四分之一圓,于是問題轉化為:y為何值時,直線u+v=y與該四分之一圓有交點。由圖1容易得到,y的取值范圍為,即為所求函數值域。
圖5 使用CDPM提取輪廓型(基本型)字素的特征曲線
圖6 使用CDPM提取結構型字素(基本型)的特征曲線
3.2 擴展性測試
擴展性測試是將2種類型中的“擴展型”作為測試對象。與“基本型”相比,“擴展型”中的字符存在少量變異,而不同類型字符的變異又各不相同。其中,輪廓型字素的變異內容包括:綴加離散或粘連元素(包括綴加點、線或字塊)、輪廓閉合不完全等。而結構型的變異內容包括:綴加離散或粘連元素、少量旋轉(≤60°)、平移及大幅度旋轉(>60°且<120°)等。
當然,園方防止人流擁堵引發安全隱患的初衷是好的,只是方法過于簡單。其實,游樂園門票不少都是網上預訂或團購的,完全可以提前告知游客驗票時持兒童票者須出示身份證件。此外,不少游樂園的廣告宣傳力度也很大,在推介游樂項目的同時,順帶講一下“驗票須知”也非難事。兒童票與成人票相差幾百元,家長們算得清這筆賬,多半不會嫌麻煩。
圖7顯示了使用CDPM算法提取輪廓型字素(擴展型)的輪廓特征曲線并按照逆時針順序排列的效果。其中,有2個字符(紅框標記)由于輪廓閉合性不好,使用CDPM算法得到的結果不正確。因此,對于輪廓型單素字,當字符的輪廓閉合性不好時,使用CDPM算法可能無法得到正確的特征曲線,對(擴展型)輪廓型字素測試的正確率為95%。
圖7 使用CDPM提取輪廓型(擴展型)字素的特征曲線
圖8顯示了使用CDPM算法實現結構型字素(擴展型)的骨架分割,并按照先后順序排列局部骨架曲線。其中,有6個字符(紅框標記)得到的結果與其他同類型的字符不同,準確率為87.17%。產生錯誤的原因是,CDPM算法一般選取距離坐標原點最近的終端點作為起點,當左下角的字符線條存在較多變異(例如,發生大弧度的旋轉,或者附加了較多具有粘連性的綴加線條或字塊)時,將對分割結果和局部骨架曲線的排列順序產生影響。
圖8 使用CDPM提取結構型字素(擴展型)的特征曲線
3.3 有效性實驗
為進一步驗證CDPM算法的有效性,連續選取10組數據,每組數據從1 591個東巴字符中隨機選取100個不重復的東巴字符作為測試對象。并且,分別采用基于Sobel算子[15]和Canny算子[16]的邊緣檢測算法與CDPM算法進行比較,結果如圖9所示。
在法學詮釋學中,應用體現的最為明顯。一個法律文本是在歷史中制定出來的,而且作為法律文本其必然具有普遍的約束力,然而在法律實踐中,每一個具體的案件都是特殊的。將一條法律應用于某一個既定的法律場合,如執行一個法律判決,就包含著對該法律條文的理解和解釋。“不論怎樣,這意味著各種法律規范的每一次運用(即得到公正的結果)都同時是對某一條既定法律之涵義的具體化和進一步闡明。”[5]因此,將普遍化的法律文本應用于某一具體的法律情境,就是對該法律文本的進一步的理解和解釋,體現了理解、解釋和應用的統一。
圖9 CDPM算法的通用性測試
通過測試,CDPM算法的平均準確率為98.2%,而Sobel算子和Canny算子分別為58.2%和59.2%。后兩者準確率較低的主要原因是,測試數據是從東巴字符庫中隨機選取的,其中所包含的結構型字素和輪廓型字素的數量是隨機的,雖然Sobel算子和Canny算子能準確提取輪廓型字素的特征曲線,但是對結構型字素的特征曲線提取結果卻非常不理想,錯誤率較高,導致平均準確率過低。說明,CDPM算法能夠更好的適應不同類型東巴字素的特征曲線提取要求。
4 小 結
CDPM算法實現簡單,通過擴展Freeman鏈碼在邊緣檢測及曲線局部分割方面的功能,滿足了輪廓型和結構型兩類東巴字素特征曲線提取的需求,具有良好的通用性、可擴展性及健壯性,并且當字素中存在少量變異(字素中存在綴加、離散或粘連元素,少量旋轉(≤60°)及平移)時也能得出正確結果。但是,當輪廓型字素中的字符輪廓閉合不完全,或者結構型字素變異較大(大幅度旋轉(>60°且<120°)或粘連元素較多)時,所提取的字符特征曲線仍可能發生錯誤。因此,在后續的工作中還需對CDPM算法不斷改進以提高特征曲線提取的準確率。
參考文獻
[1] 和力民. 試論東巴文化的傳承[J]. 云南社會科學, 2004(1): 83-87.
[2] 和金光. 納西族東巴文化研究發展趨勢[J]. 云南民族大學學報:哲學社會科學版, 2007, 24(1): 81-84.
[3] 戈阿干. 東巴文化攬勝[J]. 民族藝術研究, 1999, 12(2): 71-80.
[4] GUO H, ZHAO J Y, DA M J, et al. NaXi pictographs edge detection using lifting wavelet transform [J]. Journal of Convergence Information Technology, 2010, 5(5): 203-210.
[5] GUO H, ZHAO J Y. Research on feature extraction for character recognition of NaXi pictograph [J]. Journal of Computers, 2011, 6(5): 947-954.
[6] GUO H, JYIN J H, ZHAO J Y. Feature dimension reduction of Naxi pictograph recognition based on LDA [J]. International Journal of Computer Science, 2012, 9(1): 90-96.
[7] GUO H, ZHAO J Y. Segmentation method for NaXi pictograph character recognition [J]. Journal of Convergence Information Technology, 2010, 5(6): 87-98.
[8] LI X, GUO H, SUO G J, et al. The design and realization of NAXI pictograph character recognition preprocessing system [C]//International Workshop on Computer Science for Environmental Engineering and EcoInformatics. Heidelberg: Springer, 2011: 54-59.
[9] 楊萌, 徐小力, 吳國新, 等. 東巴象形文字識別方法[J]. 北京信息科技大學學報:自然科學版, 2014, 29(3): 72-76.
[10] 王海燕, 王紅軍, 徐小力. 基于支持向量機的納西東巴象形文字符識別[J]. 云南大學學報: 自然科學版, 2016, 38(5): 730-736.
[11] DA M J, ZHAO J Y, SUO G J, et al. Online handwritten Naxi pictograph digits recognition system using coarse grid [C]//International Workshop on Computer Science for Environmental Engineering and EcoInformatics. Heidelberg: Springer, 2011: 390-396.
[12] WANG H Y, WANG H J, CHEN X. Construction of corpus and knowledge database for Naxi dongba manuscripts based on internationally sharing platform [C]//Proceedings of the 6th International Asia Conference on Industrial Engineering and Management Innovation. Paris: Atlantis Press, 2015: 325-331.
[13] YANG L P, GUO H, ZHAO J Y, et al. The research on software of individual characters recognition about the Naxi pictographs based on.Net and chain code [J]. Procedia Engineering, 2012, 29: 4068-4072.
[14] FREEMAN H. Boundary Encoding and Processing [C]// Proceedings of Picture Processing and Psy-chopictorics. New York: Academic Press, 1970: 241-266
[15] KANOPOULOS N, VASANTHAVADA N, BAKER R L. Design of an image edge detection filter using the Sobel operator [J]. IEEE Journal of Solid-State Circuits, 1988, 23(2): 358-367.
[16] DING L J, GOSHTASBY A. On the Canny edge detector [J]. Pattern Recognition, 2001, 34(3): 721-725.
Research on the Extracting Algorithm of Dongba Hieroglyphic Feature Curves
YANG Yu-ting1, KANG Hou-liang2
(1. Culture and Tourism College, Yunnan Open University, Kunming Yunnan 650000, China;2. Spotrs Department, Suzhou Vocational University, Suzhou Jiangsu 215000, China)
Abstract: Dongba hieroglyphic is a kind of very primitive picture hieroglyphs. In order to increase the recognition rate of Dongba words, extracting the feature curves of glyphs is the key. At present, the retrieval and recognition of Dongba hieroglyphs still use the existing, universal and mature technology, and there is less analysis and discussion on the Dongba hieroglyphs themselves. Therefore, we analyze the shape and structure of the Dongba hieroglyphs in depth, and give a connected-domain priority marking algorithm based on chain codes. It extends the characteristic of Freeman chain code in edge detection and local segmentation of curves, and satisfies the requirements of contour and structure type of feature curve extraction. We use a large number of experiments and comparison with other classical edge detection algorithms to show that the CDPM algorithm has good versatility, scalability and robustness, and the accuracy reaches 98.2%. It lays a foundation for the retrieval and identification of Dongba hieroglyphs.
Keywords: CDPM algorithm; dongba hieroglyphic; edge detection; words partitioning
中圖分類號:TP 391
DOI:10.11996/JG.j.2095-302X.2019030591
文獻標識碼:A
文章編號:2095-302X(2019)03-0591-09
收稿日期:2018-07-24;
定稿日期:2018-09-12
基金項目:云南省教育科學研究基金項目(2018JS748,2019J1152);國家社會科學基金項目(15BTY038)
第一作者:楊玉婷(1983-),女,云南昆明人,副教授,碩士。主要研究方向為圖形圖像處理、計算機視覺等。E-mail:tudou-yeah@163.com
通信作者:康厚良(1979-),男,四川瀘州人,教授,碩士。主要研究方向為民族文化及民族體育的傳承與保護。E-mail:kangfu1979110@163.com
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
