一種基于最大公共子圖的社交網絡對齊方法*
2019-08-13 05:06:56申德榮聶鐵錚
軟件學報 2019年7期
馮 朔, 申德榮, 聶鐵錚, 寇 月, 于 戈
(東北大學 計算機科學與工程學院,遼寧 沈陽 110819)
隨著 Internet的廣泛普及,各類社交網絡走進人們的視野,不同社交網絡為用戶提供了不同的社交服務,例如,豆瓣為用戶提供了圖書、電影、音樂交流分享服務,知乎為用戶提供了問答服務,微博為用戶提供了分享動態的服務,用戶為滿足不同的服務需求,往往不會局限于單一社交網絡中,而是在多個社交平臺中注冊賬號,因此,社交網絡對齊問題(通常也稱為用戶識別問題、用戶匹配問題、網絡反匿名化問題以及錨鏈接預測問題)逐漸引起了學者的關注.網絡對齊將有效集成分散于各個網絡中的用戶資源,將大大提高用戶推薦、廣告投放、用戶組形成等以用戶為中心的服務質量.
針對網絡對齊問題,在早期研究工作中,研究者們主要利用用戶E-mail[1]、用戶真實姓名[2]等信息進行識別,雖然依據E-mail和真實姓名能夠精確匹配用戶,但在真實社交網絡中,E-mail和真實姓名由于隱私保護的原因,通常難以獲取[3].因此,現階段工作主要集中于利用:(1) 用戶屬性信息,如用戶頭像、用戶喜好等[4,5];(2) 用戶行為信息,如發帖關鍵字、用戶行為軌跡等[6,7];(3) 用戶結構信息,如用戶朋友關系、用戶與帖子的評論關系等[3,8,9].雖然現有方法具有良好的準確性,但真實社交網絡通常面臨用戶數據匿名化嚴重、部分用戶數據難以獲取等問題,且現有公開數據也面臨數據缺失、數據不一致、數據分布不均、數據異構等問題.
本文利用用戶結構信息研究網絡對齊問題,相比于用戶屬性信息與行為信息,用戶結構信息具有易獲取、易識別的特點,例如,人人網中用戶的朋友關系、微博用戶的關注與被關注關系以及大部分社交網絡中用戶之間的互動關系,均可作為標識用戶的重要依據.但這并不意味著用戶屬性信息以及用戶行為信息是無用的,在處理真實數據的過程中,本文可結合用戶屬性信息和用戶行為信息,以取得更準確的用戶識別效果.
網絡對齊問題可抽象為最大公共子圖問題(α-MCS)[10-12],如圖 1所示,G,G′表示兩個不同的社交網絡,節點表示用戶,實線邊表示圖中用戶之間的朋友關系,α-MCS的目標是求取G到G′的映射函數F,使得Sco(F)=#重疊邊數量-α#非重疊邊數量,取值最大,其中,α表示平衡重疊邊與非重疊邊數量的參數.例如,當α=0時,對于F1={(1,b),(2,a),(3,f),(4,e),(5,d),(6,c)},Sco(F1)=8,不存在其他映射關系F2使得Sco(F2)>Sco(F1),因此,稱由F1形成的公共子圖為G,G′的最大公共子圖.
傳統的最大公共子圖問題在解決網絡對齊問題時,存在以下幾點不足:首先,其參數α無法自適應于不同類型網絡,傳統方法主要依賴于啟發式的方法確定α,然而,由于不同網絡結構的不同,使得該類方法具有一定的局限性;其次,傳統方法計算復雜度較高,這類算法通常只能處理數據量較小的網絡,隨著社交網絡規模的擴大,現有算法已不再適合處理大規模數據的社交網絡;此外,現有方法的目標通常追求代價函數最小的匹配結果,而非社交網絡用戶的真實匹配關系,并沒有結合社交網絡結構特征有效地解決問題.因此,本文針對現有方法的不足,提出基于最大公共子圖的社交網絡對齊方法,主要有以下貢獻點.
1) 本文利用最大公共子圖問題(α-MCS)對網絡對齊問題進行求解,并針對參數α的取值進行討論,使其自適應于不同社交網絡結構.
2) 為快速地解決α-MCS,本文提出基于最大公共子圖的迭代式網絡對齊算法 MCS_INA,主要分為兩個階段:第1個階段,分別在兩個社交網絡中選取易于識別的候選匹配用戶集合,第2個階段,針對候選匹配用戶集合進行識別.相比于傳統方法,該方法結合社交網絡特征,通過參數估計,快速定位候選集,降低了算法復雜度,該算法復雜度為O(DD′(D+D′)(|V|+|V′|)),遠小于現有方法,其中,D,D′分別表示G,G′的平均度數,V,V′表示G,G′的用戶集合.
3) 為驗證 MCS_INA的有效性,本文選擇在真實數據集和合成數據集上進行實驗,實驗結果表明,MCS_INA在識別準確率與召回率上明顯優于現有算法.
本文第1節簡述相關工作.第2節簡述相關預備知識,包括符號定義以及網絡對齊模型.第3節針對α-MCS中參數α進行討論,求取自適應的參數α.第4節提出算法MCS_INA,以有效解決α-MCS.第5節設計并展示實驗結果,分析算法的有效性.第6節對本文進行總結.
1 相關工作
現階段網絡對齊方法可分為 3類:基于用戶屬性信息的網絡對齊方法、基于用戶行為信息的網絡對齊方法、基于用戶結構信息的網絡對齊方法.
在網絡對齊領域中,最傳統的方法是利用用戶真實姓名和 E-mail進行用戶識別,該類方法通過衡量字符串之間的轉換規則以及相似性進行用戶識別.然而,用戶名和E-mail在具有較高識別準確性的同時,大大降低了召回率.因此,部分學者利用額外的用戶屬性信息進行網絡對齊.雖然額外屬性信息的加入提高了用戶識別的召回率,但真實網絡數據中用戶屬性信息往往具有隱私性、異構性,研究者獲取到的數據往往是不全面的,甚至是錯誤的.
基于用戶行為信息的對齊方法認為用戶在不同社交網絡中表現出相似的用戶行為特征,例如用戶寫作習性、用戶登錄時間地點特征、用戶主題偏好等.傳統方法主要通過提取用戶行為特征相似性進行用戶識別,例如文獻[13]針對用戶寫作特征,從用戶詞匯特征、語義特征、文章結構特征、文章主題特征進行特征抽取;文獻[6]分別從“用戶-時間”“用戶-空間”“用戶-關鍵字”3個方面進行用戶特征提取.通過計算用戶行為特征相似性,大部分已有方法將網絡對齊問題轉化為二分類問題,并利用 SVM、邏輯回歸、穩定婚姻匹配等分類方法進行識別.
基于用戶結構信息的網絡對齊問題,可抽象為最大公共子圖問題.該問題最早在文獻[14]中提出,作者認為重疊邊數量是衡量最大公共子圖問題的唯一條件,而文獻[10]認為最大公共子圖問題需要綜合考慮重疊邊數量與非重疊邊數量.傳統的最大公共子圖問題均為 NP完全問題,后續大量文獻針對最大公共子圖問題進行了近似求解,但現有近似求解方法的復雜度均大于O(nlogn),并不適用于真實網絡環境.
為了解決真實網絡環境下的網絡對齊問題,文獻[15]認為,少部分已知匹配用戶可顯著提升網絡對齊的準確性,該文獻通過部分節點迭代地識別其余用戶;之后,文獻[16]在有權重圖上提出基于隨機游走的用戶相似性算法;文獻[17]針對大規模網絡上時間代價過高的問題,以犧牲部分召回率為代價,有效降低了時間復雜度,文獻[3]有效解決了無已知匹配用戶情況下的網絡對齊問題.這些方法均利用網絡結構特征,通過求取用戶相似性,選擇匹配用戶.
此外,部分學者提出了基于網絡表示的網絡對齊算法.文獻[18]將用戶映射到多維空間中,他們認為不同網絡中相同用戶在該空間中距離相近;文獻[19]對有向網絡中的用戶進行識別,其用戶映射函數與用戶自身屬性、父母屬性、孩子屬性相關.此外,文獻[20]認為,映射函數同樣與用戶所處社群相關.
然而,以上算法均為啟發式算法,文獻[8]首次提出了網絡對齊模型,網絡對齊模型是描述現實社交網絡用戶關系的數學模型,文獻[8]中證明了其算法的正確性,并在現實網絡對齊問題中取得了較高的準確率.之后,文獻[9]在此基礎上,通過增加匹配迭代次數,顯著提升了準確率與召回率,文獻[21]證明了其方法在無標度網絡對齊模型中的正確性,文獻[22]針對已知匹配用戶過少的情況,以降低準確率為代價,提升了部分召回率.
本文方法與已有方法不同之處有二.首先,本文利用網絡對齊模型,對最大公共子圖問題中參數取值進行討論,給出嚴謹的理論推導過程,相比于傳統啟發式確定參數的方法,本文方法可自適應于不同類型的網絡;其次,本文在解決網絡對齊的過程中,借鑒最大公共子圖思想與網絡對齊模型,結合社交網絡特征,通過參數估計,快速定位候選集,有效降低了算法復雜度,本文算法的計算復雜度遠小于現有方法.
2 預備知識
2.1 符號和定義
定義1(網絡).給定網絡G(V,E),其中,V表示網絡G中用戶集合,E表示網絡G中用戶關系集合,若用戶i與用戶j之間存在邊,則表示Vi,j=Vj,i=1,否則,Vi,j=Vj,i=0,對于網絡中節點i,本文使用表示該節點i所對應的用戶個體.
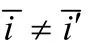
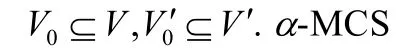

例如,如圖1所示,令α=1,初始映射函數F0={(2,a),(3,f)},則G,G′的最大公共子圖F為F={(1,j),(2,a),(3,f),(4,g),(6,i)},其中,重疊邊為(4,1),(4,3),(3,6),(3,2),(2,1),(6,1),無非重疊邊,因此,公共子圖F的得分為Sco(F)=6,而對于其他任意公共子圖,其Sco得分均不可能超過6.因此,公共子圖F為G,G′的最大公共子圖.
2.2 網絡對齊模型
網絡對齊模型[8]在跨社交網絡分析的過程中具有重要意義,該模型認為現實中不同的社交網絡均源起于相同的網絡,即對于任意對齊網絡G和G′,均源起于一個潛在網絡G*,其中,G*描述了用戶之間的全部社交關系.依據此假設,網絡對齊模型可描述為兩個獨立的過程:(1)G*的模型化,本文假設G*(V*,E*)滿足,對于任意i*,j*∈V*,i*與j*之間存在邊的概率為pi*,j*,本文不針對pi*,j*附加任何約束條件,即網絡G*可滿足均勻分布(如 ER模型[23]),也可滿足冪律分布(如 Stochastic blockmodels[24]).(2) 真實網絡G,G′的產生:本文假設對齊網絡G和G′均為網絡G*的子圖:對于G*中任意一個節點,其有SV的概率出現在網絡G中,有SV?的概率出現在網絡G′中;而對于網絡G*中任意一條邊Vi*,j*=1,若節點i*,j*已存在于在G中,則該邊存在于G中的概率為SE.同理,若節點i*,j*已存在于在G′中,則該邊在G′中存在的概率為SE?.
3 最大公共子圖自適應參數分析
本節著重針對最大公共子圖問題中參數α的取值進行分析,依據公式(1),公共子圖F得分的期望值為
其中,Pr(Vi,j,V′F(i),F(j))表示邊Vi,j與邊V′F(i),F(j)均存在的聯合概率,Pr(Vi,j,?V′F(i),F(j))表示邊Vi,j存在且邊V′F(i),F(j)不存在的聯合概率.

證明:依據定理1的描述,僅需證明存在α,使得以下兩個條件成立:
4 基于最大公共子圖的迭代式網絡對齊算法
在第3節中,本文討論了最大公共子圖問題中參數α的取值,本節將提出基于最大公共子圖的迭代式網絡對齊算法MCS_INA(α-MCS based iterative network alignment algorithm),如算法1所示.
算法 1.MCS_INA(G,G′,F0).
輸入:G,G′,F0;
輸出:F.
給定對齊網絡G和G′以及初始匹配用戶關系F0,MCS_INA的輸出是包含F0的用戶對應關系F.首先,算法利用初始匹配用戶集合F0初始化輸出集合F(第1行),之后,迭代地利用已匹配用戶識別其他用戶.在每次迭代過程中,主要分為兩步:第1步,分別從G和G′中選取識別度較高的候選匹配用戶集合C,C′(第3行~第4行),為降低計算復雜度,該步驟分別針對兩個網絡G,G′單獨進行處理,選取與已匹配用戶關系較近的用戶集合;第2步,分別針對候選匹配用戶集合C,C′進行用戶匹配,借鑒最大公共子圖思想,構建匹配用戶映射關系M:V→C′和M′:V′→C(第5行~第6行),并將M與M′重疊的部分作為匹配結果(第7行),加入到輸出集合F中,并執行下一次循環,若連續兩次迭代匹配結果F未發生改變,則停止迭代,將F作為算法的輸出.
本文在第4.1節中將深入討論候選用戶集合選取問題;在第4.2節中將深入討論候選用戶集合匹配問題.
4.1 候選匹配用戶選取策略
為便于描述,本節僅針對G中候選匹配用戶選取問題進行討論.給定網絡G(V,E)以及已匹配用戶映射關系F,候選匹配用戶選取算法Candidate(G,F)的目標是,在G中選取與匹配用戶集合VF關系緊密的用戶群體C.結合最大公共子圖思想,對于用戶k,構建其代價函數如下:
公式(5)中,SE(本文僅對SE進行分析,SE?同理)、Pr(Vi,k)、α均為未知參數,下面將對這些參數進行分析估計.
首先,SE表示網絡對齊模型中網絡G*中的邊保留到G的概率,可通過以下公式進行估計:
其次,Pr(Vi,k)表示G中用戶i與k之間存在邊的可能性,可通過i,k之間的間接關系進行預測,本文認為Pr(Vi,k)與用戶i與k的共同鄰居數量相關.
其中,N(i)表示用戶i的鄰居集合,δ(p,q,|N(i)∩N(k)|)表示用戶對p,q的共同鄰居數量是否等于|N(i)∩N(k)|的判斷.若相等,則δ(p,q,|N(i)∩N(k)|)取值為 1;否則,δ(p,q,|N(i)∩N(k)|)取值為 0.公式(7)的分子部分表示網絡中公共鄰居數量為|N(i)∩N(k)|且存在邊的節點對數量,分母為網絡中公共鄰居數量為|N(i)∩N(k)|的節點對數量.顯然,若網絡中大部分公共鄰居數量為|N(i)∩N(k)|的節點對之間存在邊,則Pr(Vi,k)取值應該較高,否則,Pr(Vi,k)取值較低.

算法 2.Candidate(G,G′,F).
輸入:G,G′,F;
輸出:C.
在算法2中,首先,利用公式(6)對參數SE,SE?進行估計,并賦值β=1(第1行).之后,利用已識別用戶集合VF,獲取待分析的候選匹配用戶集合Tmp(第2行~第5行),從第6行開始,迭代地分析Tmp中用戶是否適合作為候選匹配用戶.若對于用戶i∈Tmp-VF,其ΔScoE(i)>0,則認為用戶i適合作為候選匹配用戶,并將其放入候選匹配用戶集合C中(第9行~第12行),并輸出結果集C.若結果集C為空集,則有可能參數β取值過高,降低參數β,并重新計算候選匹配用戶集合(第 15行).在算法 2中,通過迭代降低參數β,可有效提高算法識別精度,初始情況下,β取值為 1,相對應的α取值較高,候選匹配用戶集合選取相對嚴格.而隨著迭代的進行,β取值逐漸降低,進而α取值隨之降低,候選匹配用戶集合選取逐漸寬松,最終,當β取最低值時,若候選匹配用戶集合依然為空,則無適合匹配的用戶.
通過算法 2,可獲取有序的候選匹配用戶集合C,集合C中用戶依據與已匹配用戶之間的關系強度進行排序,與已匹配用戶關系緊密的用戶具有較高排名,相反地,關系疏遠的用戶具有較低排名.另外,對于每個候選匹配用戶,計算其代價函數的時間復雜度為O(D2).因此,在MCS_INA中,候選匹配選取算法Candidate(G,G′,F)的時間復雜度為O(D2|V|+D′2|V′|).
4.2 用戶匹配策略
給定G中候選匹配用戶集合C,用戶匹配算法Match(G,G′,F,C)的目標是,構建映射函數M′:V′→C.由于最大公共子圖問題為 NP完全問題,為降低計算復雜度,本節利用第 4.1節中候選匹配用戶排名,結合貪婪思想,提出近似求解算法.
對于候選匹配用戶集合C中任意用戶k∈C,令k′為G′中未匹配用戶,借鑒最大公共子圖思想(見公式(1)),則k′與k的匹配度可表示為
公式(8)表示,若匹配用戶k與k′,可提升匹配結果Sco得分ΔSco(k,k′).
至此,用戶匹配算法Match(G,G?,F,C)如算法3所示.
算法 3.Match(G,G′,F,C).
輸入:G,G′,F,C;
輸出:M.
算法3中采用貪婪思想有序地對用戶集合C中用戶進行識別,優先識別與已匹配用戶關系緊密的用戶,可有效降低識別錯誤的發生.
在算法3中,對于每個候選匹配用戶k,其對應的Tmp集合中用戶的個數為O(DD′),而對于Tmp中每個用戶t′,計算k與t′匹配度的時間復雜度為O(D+D′),因此,識別每個候選匹配用戶k的時間復雜度為O(DD′(D+D′)),且在 MCS_INA 中,用戶匹配算法Match(G,G′,F,C)的時間復雜度為O(DD′(D+D′)(|V|+|V′|)).
綜上,算法 MCS_INA 的時間復雜度為O(DD′(D+D′)(|V|+|V′|)).
5 實 驗
5.1 實驗環境
實驗環境:本文采用Java編程語言實現相關算法,實驗主機采用Intel i5-4590處理器,主頻3.30GHz,8GB內存,操作系統為64位Windows 7.
數據集:本文所使用數據集見表1.首先,Facebook表示匿名化的真實Facebook數據集,其中,第1個網絡(FL)為Facebook新奧爾良市用戶關系網絡,另一個網絡(FW)為Facebook新奧爾良市用戶信息墻交互網絡,其中,重疊的用戶數量為25 538,重疊的邊的數量為151 580,該數據集可參考文獻[25];其次,本文利用真實社交網絡生成部分數據集,其中,Twitter表示真實Twitter用戶數據集,T1.0表示原始的Twitter數據規模,T0.8表示T1.0中80%的邊以及80%的節點被保留到數據集T0.8中,T0.7和T0.9同理.在生成T0.7、T0.8和T0.9時,均采用隨機概率保留點和邊.另外,本文采用不同隨機圖生成算法生成合成數據集ER和PA,其中,ER表示該網絡分布滿足ER隨機圖模型[23],PA表示該網絡節點關系分布滿足冪律分布[26],所有隨機圖均通過igraph生成.最后,本文隨機地選取匹配用戶作為已知匹配用戶,該方式將有效降低識別瓶頸的發生,若已知匹配用戶集中于單一社區內,將造成社區外部節點識別準確率的下降.
對比算法:由于啟發式的解決方法適用性較低,與本文研究內容有差異;基于網絡表示的網絡對齊算法,需要大量訓練數據,而本文方法僅基于預先匹配的少量用戶節點數量(占比通常為 10%以下),兩種方法環境不同.為此,本文僅選取與本文研究方法密切相關的兩種經典算法CN和CNR進行比較:(1) CN[8]:CN算法為迭代算法,每次迭代過程中,選取共同鄰居數量最多的用戶對作為匹配用戶;(2) CNR[9]:與CN算法類似,但CNR算法在每次迭代過程中優先匹配度數較高的用戶;(3) MCS_INA:本文提出的算法.
效果評價:本文采用準確率(precision)、召回率(recall)、F-measure以及運行時間(runtime)這4個方面進行評估.
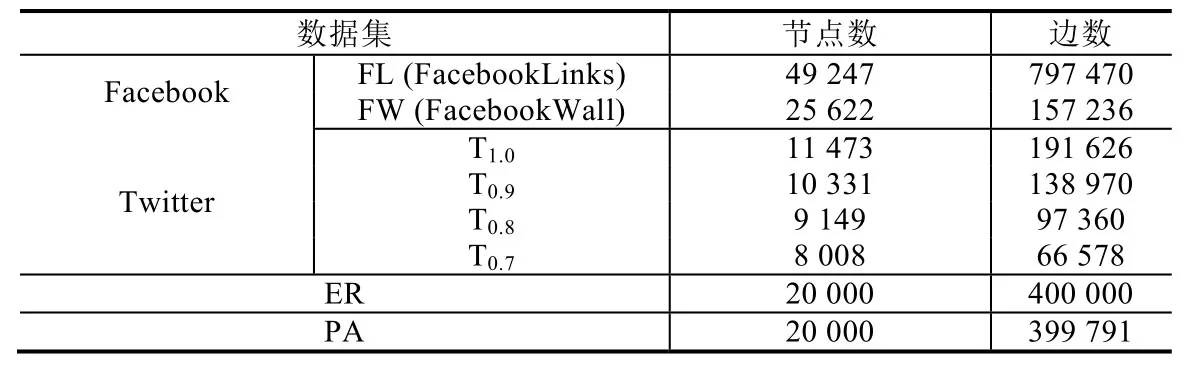
Table 1 Datasets表1 數據集
5.2 真實數據集中的實驗效果
首先,為比較不同算法在不同數據集中的識別準確率,該組實驗采用 FL&FW、T0.7&T0.8、T0.7&T0.9和T0.8&T0.9這4個數據集,對于每組數據集,隨機地選取10%的匹配用戶作為已知,實驗結果如圖2所示.在3種不同算法中,本文算法MCS_INA的準確率最高,而CN算法準確率最低.另外,對比Twitter的3組數據集,3種算法在數據集T0.8&T0.9上具有較高準確率,而在T0.7&T0.8數據集上具有較低準確率.原因是,T0.8&T0.9重疊用戶數量以及重疊邊較多,期望情況下其重疊邊為T1.0邊數量的37%,而T0.7&T0.8的重疊邊比率僅為17%.因此,T0.8&T0.9相對更容易識別.
其次,對比不同算法在不同數據集中的召回率,如圖3所示.在3種算法中,本文算法MCS_INA的召回率依然最高,其次為 CNR,算法 CN 召回率最低;對比圖 2中的準確率,算法 CNR 在數據集 T0.7&T0.8、T0.7&T0.9、T0.8&T0.9中的召回率略高于準確率,這是由于 Twitter數據集中包含大量單獨存在于單個網絡中的用戶,算法CNR錯誤地識別了這一部分用戶.而在數據集FL&FW中,算法CNR的準確率略高于召回率,這是由于FW數據集幾乎為FL數據集的子集.
最后,綜合準確率與召回率,F-measure的比較結果如圖4所示,MCS_INA的綜合性能明顯優于算法CN和CNR.
為測試不同算法在不同數據集中的運行時間,本組實驗記錄了不同算法的運行時間,見表2.由表2可知,算法CN的運行時間最短,其次為MCS_INA,CNR的運行時間最長.雖然算法CN具有最短的運行時間,但綜合圖4中F-measure的比較結果來看,MCS_INA依然具有最高的綜合性能.另外,對于算法CNR,無論從算法執行時間還是算法精度,MCS_INA均優于CNR.

Table 2 Runnin time on real-world datasets (min)表2 真實數據集中運行時間比較結果 (分鐘)
5.3 合成數據集中的實驗效果
在第5.2節中,本文針對真實數據集進行了實驗,雖然在真實數據集中算法MCS_INA具有較優性能,但并不代表在所有數據集中算法 MCS_INA均表現優異,為此,在第 5.3節中,本文利用不同類型的合成數據集,測試算法的性能.
1) MCS_INA在不同類型網絡中的性能實驗
為驗證算法MCS_INA在不同類型數據集中的表現,本節分別在ER數據集與PA數據集中測試MCS_INA算法的性能,見表3和表4.以ER數據集為例,數據集ER0.5、ER0.6、ER0.7、ER0.8、ER0.9分別表示從數據集ER中以概率[0.5,0.6,0.7,0.8,0.9]提取點和邊,對于每組數據集,本實驗選取10%的用戶作為已知匹配用戶.由表3和表4可知,當數據集重疊部分較大時(ER0.6&ER0.7、ER0.7&ER0.8、ER0.8&ER0.9、PA0.7&PA0.8、PA0.8&PA0.9),MCS_INA 具有較高的準確率與召回率,而當數據集重疊部分較小時(ER0.5&ER0.6、PA0.5&PA0.6、PA0.6&PA0.7),MCS_INA具有較低的準確率與召回率,其原因是,當數據集重疊部分較小時,非匹配用戶之間相似性相對較強,從而錯誤地匹配非匹配用戶,降低了準確率與召回率.另外,對比表3與表4,MCS_INA在ER數據集中的表現明顯強于PA數據集,其原因是,ER數據集中用戶之間相似程度較低,而PA數據集中,尤其是度數較低用戶之間,相似程度較高,當刪除部分用戶以后,MCS_INA錯誤地將這些相似度較高的用戶進行匹配,從而降低了準確率與召回率.

Table 3 Performance of MCS_INA on synthetic ER datasets表3 MCS_INA在合成ER數據集中的運行結果

Table 4 Performance of MCS_INA on synthetic PA datasets表4 MCS_INA在合成PA數據集中的運行結果
2) MCS_INA運行時間隨網絡規模變化的實驗
為測試MCS_INA運行時間隨網絡規模的變化趨勢,本實驗利用ER與PA數據集進行實驗.首先,固定合成網絡平均度數為 15,變化網絡中節點數量,生成不同的原始網絡.之后,采用參數SE=SE?=SV=SV?=0.8,生成對齊網絡,實驗結果如圖 5所示.橫軸表示生成網絡中節點數量,縱軸表示算法運行時間,可知,隨著網絡中節點數量的增多,MCS_INA算法的運行時間隨網絡中節點數量的增加基本呈線性增長.然后,固定合成網絡節點數量為 5 000,變化網絡中平均節點度數,生成不同的原始網絡.之后,采用參數SE=SE?=SV=SV?=0.8,生成對齊網絡,實驗結果如圖6所示.通過實驗可知,MCS_INA算法的運行時間隨網絡中節點度數的增加呈指數型增長,且MCS_INA處理ER數據集的能力要高于處理PA數據集的能力.
3) MCS_INA性能隨已知匹配用戶數量變化的實驗
本實驗數據集采用ER0.8&ER0.8,即依據ER數據集,采用參數SE=SE?=SV=SV?=0.8生成兩組不同ER0.8并對其進行匹配,本實驗隨機抽取不同數量百分比的用戶作為已知匹配用戶對,實驗結果如圖7所示.由圖7可知,隨著已知匹配用戶的減少,實驗準確率與召回率逐漸降低,當已知匹配用戶數量減少至0.3%時,準確率與召回率實現斷崖式降低.這是由于,當已知匹配用戶數量降低至 0.3%時,這些已知匹配用戶之間幾乎不存在直接關系,從而使得MCS_INA的準確率與召回率基本降至0.
4) 參數分析
首先,對自適應參數α進行實驗分析,如圖8所示,1-MCS_INA表示在每次迭代中不對參數α進行估計,并設定α為 1,同理于 0.5-MCS_INA.該實驗分別在 3個不同數據集 ER0.7&ER0.7、ER0.8&ER0.8、ER0.9&ER0.9中運行MCS_INA、1-MCS_INA和0.5-MCS_INA.由圖8可知,通過自適應調節參數α,在3個不同數據集中均取得最優性能.另外,0.5-MCS_INA的表現優于1-MCS_INA,其原因是,對于1-MCS_INA,其節點對相似性函數(見公式(8))中參數α過大,很多匹配用戶無法達到閾值,使得召回率降低.
其次,針對每次迭代過程中參數α、SE和SE?的估計準確性進行分析,本實驗采用數據集ER0.8&ER0.8,并記錄每次迭代過程中 3個參數值的大小,如圖 9所示.對于參數SE和SE?,其取值隨迭代過程逐漸降低,并維持在 0.8左右.對于參數α,其波動范圍較大,在前幾次迭代過程中,參數α的取值范圍較大,優先對識別度較高的用戶進行識別,之后,參數α的取值隨迭代過程逐漸降低,并最終穩定在0.4左右.通過理論計算參數α可知,當參數α理論取值0.52時最優(通過定理1可知),之所以會導致實際參數取值與理論取值不一致的情況,是因為在實際情況下,通常有少部分匹配用戶,其結構相似性較低,需適量降低參數α的取值.
6 結束語
本文主要針對基于用戶結構信息的跨社交網絡用戶識別問題進行研究.首先,借鑒傳統最大公共子圖問題,提出了求解自適應參數的方法,使得最大公共子圖問題可適用于求解不同類型的網絡對齊問題;其次,針對最大公共子圖計算復雜度過高的問題,本文提出了基于最大公共子圖的迭代式網絡對齊算法MCS_INA,相比于傳統算法,MCS_INA在每次迭代過程中,僅針對部分候選匹配用戶進行匹配,且本文所提出的候選匹配算法有效結合了網絡對齊模型,具有嚴格的理論支持;最后,本文在真實數據集和合成數據集上進行了實驗,實驗結果表明本文所提出算法具有較高的識別準確率與較低的時間代價.在未來的工作中,將著重針對初始匹配用戶過于集中的問題,同時結合用戶屬性信息、用戶行為信息以處理跨網絡用戶識別問題.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
