基于嵌入式系統(tǒng)的手寫(xiě)數(shù)字識(shí)別實(shí)驗(yàn)設(shè)計(jì)
2019-08-15 03:41:06劉科征曾德港重慶郵電大學(xué)
數(shù)碼世界 2019年8期
劉科征 曾德港 重慶郵電大學(xué)
近年來(lái),隨著人工智能,邊緣計(jì)算的興起,嵌入式系統(tǒng)的應(yīng)用已經(jīng)不僅僅局限在傳統(tǒng)的工業(yè)控制、消費(fèi)電子、家用電器等領(lǐng)域,而是轉(zhuǎn)向計(jì)算機(jī)視覺(jué)等新興應(yīng)用。嵌入式系統(tǒng)的課程設(shè)計(jì)上應(yīng)該與時(shí)俱進(jìn),新增與人工智能相融合的實(shí)驗(yàn)內(nèi)容。本文總結(jié)了通信學(xué)院開(kāi)設(shè)嵌入式課程的改革創(chuàng)新經(jīng)驗(yàn)。學(xué)院在原有課程內(nèi)容基礎(chǔ)上,將人工智能,計(jì)算機(jī)視覺(jué)等新技術(shù)融入課程的實(shí)驗(yàn)教學(xué)中,增加了圖像分割,卷積神經(jīng)網(wǎng)絡(luò)等新技術(shù)的運(yùn)用,拓展了學(xué)生對(duì)新技術(shù)的理解,豐富了學(xué)生對(duì)跨專(zhuān)業(yè)應(yīng)用的視野。為嵌入式系統(tǒng)課程建設(shè)提供了新的思路。
1 計(jì)算機(jī)視覺(jué)與卷積神經(jīng)網(wǎng)絡(luò)
在各種深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)中,卷積神經(jīng)網(wǎng)絡(luò)是應(yīng)用最為廣泛的一種,它由LeCun 在1989 年提出最早被成功的應(yīng)用在手寫(xiě)數(shù)字圖像的識(shí)別上,卷積神經(jīng)網(wǎng)絡(luò)通過(guò)卷積和池化自動(dòng)學(xué)習(xí)圖像在各各層次上的特征,這符合我們理解圖像的常識(shí)。人在認(rèn)知圖像時(shí)是分層抽象的,首先理解的是顏色和亮度,然后是邊緣、角點(diǎn)、直線(xiàn)等局部細(xì)節(jié)特征,接下來(lái)是紋理、幾何形狀等更復(fù)雜的信息和結(jié)構(gòu),最后形成整個(gè)物體的概念。通常在計(jì)算機(jī)視覺(jué)課程的實(shí)驗(yàn)設(shè)計(jì)中,卷積神經(jīng)網(wǎng)絡(luò)是教學(xué)的重點(diǎn)內(nèi)容。因此在嵌入式系統(tǒng)的實(shí)驗(yàn)拓展中,嘗試將卷積神經(jīng)網(wǎng)絡(luò)的實(shí)驗(yàn)內(nèi)容遷徙到嵌入式系統(tǒng)中完成。
2 實(shí)驗(yàn)設(shè)計(jì)與分析
在卷積神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)過(guò)程中,由于對(duì)訓(xùn)練集處理的運(yùn)算壓力較大。嵌入式系統(tǒng)的處理器運(yùn)算能力不可能在短時(shí)間內(nèi)完成模型的訓(xùn)練和驗(yàn)證。因此本實(shí)驗(yàn)的內(nèi)容我們分成了兩個(gè)部分來(lái)進(jìn)行。第一階段是在高性能計(jì)算機(jī)上設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),訓(xùn)練并導(dǎo)出網(wǎng)絡(luò)訓(xùn)練模型,在這個(gè)階段主要應(yīng)該考慮神經(jīng)網(wǎng)絡(luò)的模型選擇,訓(xùn)練集測(cè)試集的選擇。第二階段是利用樹(shù)莓派進(jìn)行圖像獲取和圖像處理,將第一階段所得出的訓(xùn)練模型用于嵌入式系統(tǒng)并得出識(shí)別結(jié)果,該階段主要考慮圖像獲取方式,圖像處理步驟,圖像如何格式等內(nèi)容。
2.1 神經(jīng)網(wǎng)絡(luò)的模型選擇
2.1.1 BP 神經(jīng)網(wǎng)絡(luò)
誤差反向傳播神經(jīng)網(wǎng)絡(luò)是一種多層的前饋神經(jīng)網(wǎng)絡(luò),也是我們學(xué)習(xí)中最先接觸到的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),由輸入層、隱含層、輸出層組成,其主要的特點(diǎn)是信號(hào)前向傳遞,誤差反向傳播。根據(jù)預(yù)測(cè)的誤差調(diào)整網(wǎng)絡(luò)權(quán)值和閾值,使得預(yù)測(cè)輸出不斷逼近期望輸出,使輸出誤差最小或者既定條件為止。

圖2.1 全連接神經(jīng)網(wǎng)絡(luò)模型
2.1.2 LeNet-5 神經(jīng)網(wǎng)絡(luò)模型
LeNet-5 模型是Yann LeCun 教授在1998 年論文Gradient-Based Learning Applied to Document Recognition 中 提 出,是一種應(yīng)用與手寫(xiě)體數(shù)字識(shí)別的高效卷積神經(jīng)網(wǎng)絡(luò)。標(biāo)準(zhǔn)的LeNet-5模型共有七層,其每一層依次按順序?yàn)椋壕矸e層、池化層、卷積層、池化層、全連接層、全連接層、全連接層(同時(shí)也為Output 層)。LeNet-5 模型結(jié)構(gòu)圖如圖3.3 所示,其中第一個(gè)卷積層濾波器大小為5×5,深度為6;第二層池化層池化采樣過(guò)濾器大小為2×2,步幅為2;第三層卷積層濾波器大小為5×5,深度為16;第四層池化采樣過(guò)濾器大小為2×2,步幅為2。

圖2.2 LeNet-5 模型結(jié)構(gòu)圖
當(dāng)采用MNIST 數(shù)據(jù)集作為輸入數(shù)據(jù)時(shí)作分析,對(duì)比可知LeNet-5 網(wǎng)絡(luò)參數(shù)個(gè)數(shù)遠(yuǎn)小于BP 神經(jīng)網(wǎng)絡(luò),結(jié)構(gòu)更為合理,而通過(guò)之后的編程結(jié)果可以知道,BP 神經(jīng)網(wǎng)絡(luò)準(zhǔn)確率約為98.4%,LeNet-5的準(zhǔn)確率約為99.2%,優(yōu)于BP 神經(jīng)網(wǎng)絡(luò)。因此從這兩方面得出結(jié)論:選擇LeNet-5 網(wǎng)絡(luò)作為本實(shí)驗(yàn)設(shè)計(jì)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
2.2 神經(jīng)網(wǎng)絡(luò)搭建與訓(xùn)練過(guò)程
利用Tensorflow 框架為L(zhǎng)eNet-5 網(wǎng)絡(luò)在訓(xùn)練完成后導(dǎo)出對(duì)應(yīng)模型,在測(cè)試和識(shí)別時(shí)直接導(dǎo)入模型可以保證后者所用參數(shù)為前者訓(xùn)練后所產(chǎn)生的參數(shù)。流程如下圖2.3:
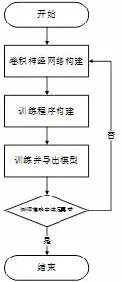
圖2.3 訓(xùn)練和驗(yàn)證流程圖

圖2.4 識(shí)別程序流程圖
2.3 識(shí)別程序工作過(guò)程
此程序主要包括在樹(shù)莓派上進(jìn)行圖像拍攝,圖像處理,識(shí)別輸出等功能,其中也包括在圖2.3 中搭建的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)用于識(shí)別。是設(shè)計(jì)最終展示的程序,其流程圖如圖2.4 :
2.4 硬件平臺(tái)選擇
樹(shù)莓派是一個(gè)基于定制化Linux 操作系統(tǒng)的微型電腦。樹(shù)莓派體積小、攜帶方便、功能齊全。支持python 編程,本設(shè)計(jì)使用的樹(shù)莓派版本為3 代B+,這個(gè)平臺(tái)包括ARM 核心的64 位微處理器,運(yùn)算頻率1.2GHz,還有專(zhuān)用攝像頭接口、多個(gè)USB 接口、一個(gè)hdmi接口、千兆以太網(wǎng)接口、1GB 內(nèi)存等,能夠很方便的實(shí)現(xiàn)我們的設(shè)計(jì),是一個(gè)在嵌入式人工智能學(xué)習(xí)上非常理想的實(shí)驗(yàn)平臺(tái)。如下圖:

圖2.5 樹(shù)莓派實(shí)驗(yàn)板
2.5 軟件開(kāi)發(fā)流程
軟件開(kāi)發(fā)分為兩個(gè)部分,首先需要對(duì)攝像頭輸入的圖像進(jìn)行處理,這里用到了Open CV 開(kāi)源計(jì)算機(jī)視覺(jué)庫(kù),Open CV 主要由C 函數(shù)和C++類(lèi)構(gòu)成,同時(shí)也提供Python 的接口,Open CV 同時(shí)也支持樹(shù)莓派,使用pip 組件在樹(shù)莓派上能直接安裝。
2.5.1 圖像二值化
在調(diào)用Open CV 完成攝像頭調(diào)用獲取被拍攝的圖片后,需要對(duì)圖像進(jìn)行二值化處理。圖像經(jīng)由灰度化以后進(jìn)行二值化操作,圖像灰度化處理在OPENCV 中使用cv.cvtColor(image, cv.COLOR_RGB2GRAY)函數(shù)直接操作,返回的便是灰度化以后的圖像數(shù)據(jù),然后使用平均閾值劃分法求灰度平均值。
2.5.2 圖像分割
圖像的切割實(shí)際就是找到單個(gè)字符在圖片中所在的像素區(qū)域,然后記錄坐標(biāo)以后進(jìn)行分別儲(chǔ)存。本部分程序主要實(shí)現(xiàn)的切割原理依次為:1.頂?shù)撞壳懈睿コ數(shù)撞堪咨糠郑瑯?biāo)記并記錄對(duì)應(yīng)行數(shù)。2.字符分割,分割相鄰字符。圖片切割過(guò)程如下圖4 所示:
最后需要將切割以后的數(shù)字圖片周?chē)畛浒咨蔀檎叫危@樣圖像才不會(huì)變形,才不會(huì)影響識(shí)別結(jié)果。

圖2.6 圖像切割示意圖
2.5.3 圖像轉(zhuǎn)換為MINST 格式
轉(zhuǎn)換為MINST 格式應(yīng)該經(jīng)由以下步驟:1.圖片大小調(diào)整2.灰度值翻轉(zhuǎn)3.灰度值歸一化4.按次序?qū)⒍鄠€(gè)數(shù)字錄入到同一個(gè)數(shù)組中。這樣就得到了可以送入神經(jīng)網(wǎng)絡(luò)模型中進(jìn)行識(shí)別的圖片。
2.5.4 神經(jīng)網(wǎng)絡(luò)搭建和訓(xùn)練
因?yàn)長(zhǎng)eNet-5 網(wǎng)絡(luò)在訓(xùn)練以及測(cè)試還有最終程序中都有用到,因此將其編寫(xiě)為一個(gè)單獨(dú)的庫(kù)函數(shù)在訓(xùn)練完成后導(dǎo)出對(duì)應(yīng)模型,在測(cè)試和識(shí)別時(shí)直接導(dǎo)入模型可以保證后者所用參數(shù)使前者訓(xùn)練后所產(chǎn)生的參數(shù)。整個(gè)程序主要采用Tensorflow 框架中的tf.get_varible()函數(shù)創(chuàng)建變量用于存儲(chǔ)權(quán)重以及偏置項(xiàng),填充適當(dāng)?shù)碾S機(jī)數(shù)值然后訓(xùn)練。通過(guò)Tensorflow 框架依次完成卷積層、池化層和全連接層的創(chuàng)建。并使用滑動(dòng)平均模型更新參數(shù)并使用交叉熵作為損失函數(shù)。最后通過(guò)驗(yàn)證程序完成準(zhǔn)確率的計(jì)算。
3 實(shí)驗(yàn)測(cè)試
3.1 神經(jīng)網(wǎng)絡(luò)模型的測(cè)試
在神經(jīng)網(wǎng)絡(luò)訓(xùn)練進(jìn)行時(shí),每經(jīng)過(guò)1000 次訓(xùn)練便會(huì)輸出一次損失函數(shù)值,這個(gè)值越小越好,最后得出選擇模型的判斷的輸入結(jié)果以及準(zhǔn)確率,如下圖所示,其中第一行為訓(xùn)練網(wǎng)絡(luò)結(jié)果,第二行為依次判斷是否準(zhǔn)確結(jié)果,第三行為準(zhǔn)確率,單位為%,由結(jié)果可見(jiàn)準(zhǔn)確率為99.3%,符合設(shè)計(jì)要求。

圖3.1 訓(xùn)練結(jié)果測(cè)試
3.2 識(shí)別結(jié)果測(cè)試
通過(guò)實(shí)際拍攝圖像進(jìn)行測(cè)試,經(jīng)過(guò)二值化,圖像分割,格式轉(zhuǎn)換后得到的數(shù)字圖片。最后將圖片送入樹(shù)莓派最后進(jìn)行圖像的識(shí)別,拍攝圖片和最后的測(cè)試結(jié)果如圖3.2 和3.3 所示。

圖3.3 最后的識(shí)別結(jié)果

圖3 .2 攝像頭拍攝圖片
4 總結(jié)
本文以嵌入式人工智能為出發(fā)點(diǎn),設(shè)計(jì)了一個(gè)基于樹(shù)莓派的手寫(xiě)數(shù)字識(shí)別實(shí)驗(yàn)。該實(shí)驗(yàn)綜合了卷積神經(jīng)網(wǎng)絡(luò)的搭建與訓(xùn)練,結(jié)合了Open CV 的圖像處理。內(nèi)容涵蓋了嵌入式系統(tǒng)設(shè)計(jì)、人工智能和數(shù)字圖像處理等內(nèi)容。該實(shí)驗(yàn)有助于通信學(xué)院的通信、電子和信息工程等相關(guān)專(zhuān)業(yè)學(xué)生深入了解人工智能,計(jì)算機(jī)視覺(jué)等關(guān)鍵技術(shù),有助于提高學(xué)生跨學(xué)科專(zhuān)業(yè)的創(chuàng)新能力與工程實(shí)踐能力,使非計(jì)算機(jī)專(zhuān)業(yè)的學(xué)生能在自己的專(zhuān)業(yè)領(lǐng)域更好的接觸人工智能的相關(guān)應(yīng)用。
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經(jīng)理世界(2018年20期)2018-10-24 02:38:24
鐵道通信信號(hào)(2018年2期)2018-04-18 12:18:23
小康(2017年16期)2017-06-07 09:00:59
電鍍與環(huán)保(2016年3期)2017-01-20 08:15:32
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
南風(fēng)窗(2016年19期)2016-09-21 16:51:29
