基于微操作的Hadoop參數(shù)自動調(diào)優(yōu)方法
2019-08-27 02:26:02李耘書滕飛李天瑞
計算機(jī)應(yīng)用 2019年6期
李耘書 滕飛 李天瑞


摘 要:Hadoop作為大規(guī)模分布式數(shù)據(jù)處理框架已經(jīng)在工業(yè)界得到廣泛的應(yīng)用,針對手動和經(jīng)驗調(diào)優(yōu)方法中參數(shù)空間龐大和運行流程復(fù)雜的問題,提出了一種Hadoop參數(shù)自動優(yōu)化的方法和分析框架。首先,對作業(yè)運行流程進(jìn)行解耦,從可變參數(shù)直接影響的更細(xì)粒度的角度定義微操作,從而分析參數(shù)和單次微操作執(zhí)行時間的關(guān)系;然后,利用微操作對作業(yè)運行流程進(jìn)行重構(gòu),建立參數(shù)和作業(yè)運行時間關(guān)系的模型;最后,在此模型上應(yīng)用各類搜索優(yōu)化算法高效快速得出優(yōu)化后的系統(tǒng)參數(shù)。在terasort和wordcount兩個作業(yè)類型上進(jìn)行了實驗,實驗結(jié)果表明,相對于默認(rèn)參數(shù)情況,該方法使作業(yè)執(zhí)行時間分別縮短了至少41%和30%。該方法能夠有效提高Hadoop作業(yè)執(zhí)行效率,縮短作業(yè)執(zhí)行時間。
關(guān)鍵詞:Hadoop;參數(shù)調(diào)優(yōu);微操作;重構(gòu);搜索算法
中圖分類號: TP311.13
文獻(xiàn)標(biāo)志碼:A
Abstract: As a large-scale distributed data processing framework, Hadoop has been widely used in industry during the past few years. Currently manual parameter optimization and experience-based parameter optimization are ineffective due to complex running process and large parameter space. In order to solve this problem, a method and an analytical framework for Hadoop parameter auto-optimization were proposed. Firstly, the operation process of a job was broken down into several microoperations and the microoperations were determined from the angle of finer granularity directly affected by variable parameters, so that the relationship between parameters and the execution time of a single microoperation was able to be analyzed. Then, by reconstructing the job operation process based on microoperations, a model of the relationship between parameters and the execution time of whole job was established. Finally, various searching optimization algorithms were applied on this model to efficiently and quickly obtain the optimized system parameters. Experiments were conducted with two types of jobs, terasort and wordcount. The experimental results show that, compared with the default parameters condition, the proposed method reduce the job execution time by at least 41% and 30% respectively. The proposed method can effectively improve the job execution efficiency of Hadoop and shorten the job execution time.
Key words: Hadoop; parameter optimization; microoperation; reconstitution; search algorithm
0 引言
Google在早年提出了最原始的用于大規(guī)模數(shù)據(jù)并行處理的分布式架構(gòu)模型MapReduce[1-2],在幫助企業(yè)解決大數(shù)據(jù)處理效率的問題上邁出了很大的一步。隨著處理數(shù)據(jù)的規(guī)模越來越大,提升優(yōu)化Hadoop的性能和數(shù)據(jù)處理的時效性成為研究重點。Hadoop系統(tǒng)擁有200多個可配置參數(shù),雖然默認(rèn)參數(shù)配置經(jīng)過精心設(shè)計,但是由于多種多樣的任務(wù)類型使得大多數(shù)情況的任務(wù)執(zhí)行效率并不高。Hadoop中對性能有影響的參數(shù)繁多,雖然Hadoop2.0對少量參數(shù)進(jìn)行了修改和刪除,但面對復(fù)雜的作業(yè)類型,依靠人工對Hadoop系統(tǒng)進(jìn)行調(diào)優(yōu)依然是一個充滿挑戰(zhàn)的任務(wù)[3-4]。
本文提出一種基于微操作重構(gòu)的Hadoop參數(shù)自動調(diào)優(yōu)方法,該方法通過建立比階段更細(xì)粒度的微操作模型來刻畫參數(shù)變化和單次微操作執(zhí)行時間的關(guān)系,再基于運行原理對微操作模型進(jìn)行組合得到階段(phase)執(zhí)行時間和參數(shù)的關(guān)系,在此基礎(chǔ)上可以應(yīng)用不同算法搜索找出優(yōu)化參數(shù)。綜上所述,本文的主要工作如下:
1)提出了微操作模型的概念。該模型能夠直觀準(zhǔn)確地描述系統(tǒng)參數(shù)變化對執(zhí)行時間帶來的影響,從數(shù)據(jù)流的角度使得對多參數(shù)同時變化時作業(yè)執(zhí)行時間變化的分析變得方便且準(zhǔn)確,同時建立了單次微操作執(zhí)行時間與配置參數(shù)之間的函數(shù)關(guān)系。
2)提出了微操作模型求解方法,通過基準(zhǔn)測試運行簡單的實際作業(yè)來建模求解模型參數(shù),得到微操作模型。
3)提出了一種利用微操作對運行過程進(jìn)行解構(gòu)重構(gòu)的策略。該方法不隨作業(yè)類型和集群配置變化而變化,同時查找最優(yōu)參數(shù)具有耗時短、效率高、可移植性好的優(yōu)點。該方法可視為一種優(yōu)化問題的描述方法和分析框架,從更細(xì)粒度的角度刻畫參數(shù)變化原理,建立模型尋找最優(yōu)參數(shù)組合。
1 相關(guān)工作
近年來,關(guān)于Hadoop參數(shù)自動調(diào)優(yōu)的研究吸引了眾多研究者的參與。基于成本分析的(cost-based)方法通過預(yù)測未知任務(wù)各類資源的利用情況,最大化資源利用率使得作業(yè)運行時間更短。文獻(xiàn)[5]利用動態(tài)作業(yè)分析來捕獲Map階段和Reduce階段的運行行為幫助用戶微調(diào)Hadoop作業(yè)參數(shù);文獻(xiàn)[6]通過改變MapReduce的執(zhí)行策略來提高shuffling和sorting操作的執(zhí)行效率來提升整個MapReduce過程的性能。cost-based性能建模是一種較成熟的方法,但是它是一種白盒建模方法,需要研究者對非常復(fù)雜的系統(tǒng)內(nèi)部組件有很好的了解,包括軟件系統(tǒng)和硬件系統(tǒng),這一點給用戶帶來了巨大挑戰(zhàn)。基于機(jī)器學(xué)習(xí)(Machine Learning-based, ML-based)的性能建模是一種基于機(jī)器學(xué)習(xí)的調(diào)優(yōu)模型 [7-13]。文獻(xiàn)[7]主要應(yīng)用各類回歸算法來分析建模;文獻(xiàn)[9]通過神經(jīng)網(wǎng)絡(luò)來預(yù)測作業(yè)時間再進(jìn)行調(diào)優(yōu)。ML-based方法在龐大的參數(shù)空間內(nèi)收集訓(xùn)練樣本,選擇機(jī)器學(xué)習(xí)模型用于訓(xùn)練自動調(diào)優(yōu),在給定任務(wù)類型的情況下自動給出最優(yōu)參數(shù)集。它是一個黑盒模型,建立在對特定任務(wù)類型和系統(tǒng)實際性能表現(xiàn)的觀察基礎(chǔ)上,不需要詳細(xì)的系統(tǒng)內(nèi)部信息;但它在收集訓(xùn)練數(shù)據(jù)非常困難,需耗費大量時間,實際應(yīng)用效率并不高。基于搜索(Search-based)調(diào)優(yōu)模型是一種利用搜索算法的自動調(diào)優(yōu)模型[14-16]。Search-based調(diào)優(yōu)模型將所有會影響Hadoop性能的關(guān)鍵參數(shù)構(gòu)成一個參數(shù)空間,利用搜索算法如文獻(xiàn)[14]采用遺傳算法、文獻(xiàn)[16]采用遞歸隨機(jī)抽樣,通過在實際集群中迭代執(zhí)行作業(yè)任務(wù),在參數(shù)空間中自動迭代搜索優(yōu)化的參數(shù)組合。該方法和ML-based方法相比,不用構(gòu)造完整參數(shù)空間的訓(xùn)練樣本,在獲取樣本的時間上會有所減少。但是,針對不同的任務(wù)類型,參數(shù)的影響方式不同,搜索策略也會隨之改變;同時,在收集樣本時需要執(zhí)行大量的實際作業(yè),優(yōu)化過程耗費時間長也是其主要缺點。
2 建模策略
本章主要介紹微操作模型的相關(guān)概念和微操作模型的建立方法。
2.1 MapReduce運行原理
一個MapReduce Job可以分為Map stage 和 Reduce stage兩個主要過程,一個stage由多個task組成,例如map task和reduce task,而一個task可以分為多個按順序執(zhí)行的phase。如圖1所示,對MapReduce任務(wù)按照運行流程進(jìn)行解構(gòu)。MapReduce任務(wù)可以分為兩個主要過程:
1)Map stage。Map stage中多輪map task組依次執(zhí)行,每輪中多個map task并行處理數(shù)據(jù),map task運行過程分為三個階段:read phase,map phase和collection phase。其中參數(shù)對性能有較大影響的是collection phase,其余兩個階段中參數(shù)對性能的影響并不明顯,所以本文方法在map task中主要對collection phase進(jìn)行分析,得到參數(shù)和collection phase運行時間的關(guān)系。
2)Reduce stage。Reduce stage中同樣存在多輪reduce task,每輪多個reduce task組并行處理數(shù)據(jù),每個reduce task從多個map輸出中獲取所需數(shù)據(jù),最終將處理結(jié)果輸出磁盤。reduce task的運行過程分為三個階段:shuffle phase,reduce phase和sort_write phase。其中參數(shù)對性能由較大影響的是shuffle phase,所以本文方法在reduce task中只對shuffle phase從微操作的角度進(jìn)行分析,得到參數(shù)和shuffle phase運行時間的關(guān)系。在sort_write phase中,雖然沒有參數(shù)對其性能有直接影響,但是shuffle phase中的某些參數(shù)對sort_write phase的性能有間接的影響,所以后面章節(jié)也會對sort_write phase階段進(jìn)行分析介紹。
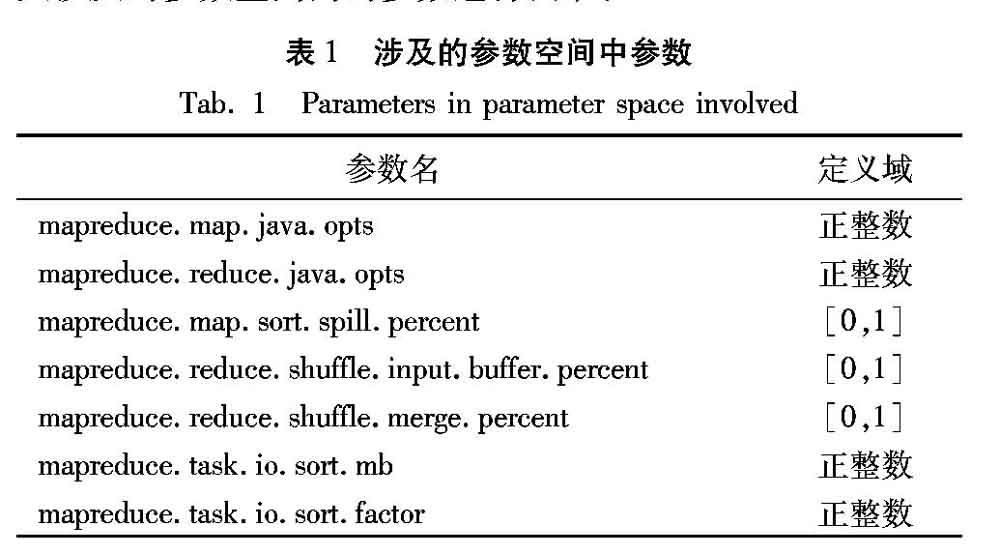
在眾多參數(shù)中,關(guān)于決定map task并行個數(shù)的參數(shù)map.cpu.vcores和map.memory.mb、決定map task輸入數(shù)據(jù)塊大小的參數(shù)dfs.blocksize、決定reduce task并行個數(shù)的參數(shù)reduce.cpu.vcores和reduce.memory.mb,以及決定reduce task個數(shù)的參數(shù)mapred.reduce.task等參數(shù)的經(jīng)驗調(diào)優(yōu)已有大量研究 [4],本文的調(diào)優(yōu)目標(biāo)主要針對那些依靠經(jīng)驗調(diào)優(yōu)較具挑戰(zhàn)的參數(shù)。map task輸入數(shù)據(jù)塊的大小一般視實際作業(yè)執(zhí)行需求和并行個數(shù)而定,通常為128MB和256MB。map task并行個數(shù)參數(shù)通常和輸入數(shù)據(jù)塊大小配合設(shè)置,小數(shù)據(jù)量作業(yè)時所有數(shù)據(jù)在一輪處理完,數(shù)據(jù)量較大時根據(jù)實際內(nèi)存在每一輪中分配盡量多的并行map task個數(shù)使得性能最大化。reduce task并行個數(shù)通常設(shè)置為使得性能最大化的個數(shù),根據(jù)實際內(nèi)存分配盡量多的并行個數(shù),所有reduce task盡量在一輪中處理完。在某些業(yè)務(wù)中,這些參數(shù)的值根據(jù)業(yè)務(wù)需求已經(jīng)確定,不屬于可變參數(shù),所以本文主要針對map task和reduce task個數(shù)都確定的情況進(jìn)行調(diào)優(yōu),對如表1所示的本文涉及的參數(shù)空間內(nèi)的參數(shù)進(jìn)行調(diào)節(jié)。
2.2 微操作定義
一個map task分為三個階段:read phase、map phase和collection phase。其中參數(shù)對性能有較大影響的是collection phase,在該階段中,定義兩種類型的微操作:
1)將輸入數(shù)據(jù)寫入到內(nèi)存,內(nèi)存大小由參數(shù)io.sort.mb決定,定義內(nèi)存寫微操作cm_mic_op。
2)當(dāng)內(nèi)存數(shù)據(jù)寫入量到達(dá)閾值時觸發(fā)磁盤寫操作,將內(nèi)存中所有數(shù)據(jù)寫入磁盤,閾值由參數(shù)sort.spill.percent決定,定義磁盤寫微操作cd_mic_op。
微操作的意義在通過參數(shù)可以定量分析某次微操作處理的數(shù)據(jù)量,從而得到微操作時間。
同樣,一個reduce task分為三個階段:shuffle phase、reduce phase和sort_write phase。其中參數(shù)對性能有較大影響的是shuffle phase,在該階段中定義三種類型的微操作:
1)從map端拉取輸入數(shù)據(jù)存入內(nèi)存,內(nèi)存空間大小由參數(shù)reduce.java.opts和參數(shù)shuffle.input.buffer.percent決定,定義單次內(nèi)存寫操作為微操作sm_mic_op。
2)當(dāng)內(nèi)存寫達(dá)到閾值時,將內(nèi)存中的數(shù)據(jù)按照閾值大小寫入磁盤存為本地文件。閾值由參數(shù)shuffle.merge.percent決定,定義單次磁盤寫微操作sd_mic_op。
3)當(dāng)寫入磁盤的本地文件個數(shù)到達(dá)閾值時,在磁盤中進(jìn)行文件合并,將閾值個數(shù)的文件合并為一個大文件,閾值由io.sort.factor決定,定義單次merge操作為磁盤合并微操作merge_mic_op。
參數(shù)對shuffle phase階段性能的影響直接體現(xiàn)在這三種類型的微操作中,通過分析參數(shù)變化對微操作處理數(shù)據(jù)量的影響,可以得到參數(shù)變化對階段運行時間所造成的影響。
本節(jié)在參數(shù)對性能有較大影響的階段中定義了幾種微操作方式,在其余階段,參數(shù)對其性能影響較小,本文不予討論,僅通過優(yōu)化上述階段中的參數(shù)即可達(dá)到優(yōu)化整個作業(yè)的目的。
2.3 微操作基準(zhǔn)測試
在2.2節(jié)中定義了幾種不同階段的微操作,在本節(jié)將介紹如何建立微操作模型,得到微操作執(zhí)行時間與參數(shù)的關(guān)系。
Hadoop中參數(shù)影響性能的本質(zhì)在于,參數(shù)值不同時單次微操作處理的數(shù)據(jù)量不同,而內(nèi)存寫和磁盤寫微操作在處理不同大小的數(shù)據(jù)時速率不同,同時總數(shù)據(jù)量一定時微操作執(zhí)行的總次數(shù)會因為單次微操作處理的數(shù)據(jù)量不同而變化,所以參數(shù)通過影響內(nèi)存寫和磁盤寫微操作的總執(zhí)行次數(shù)和單次微操作速率影響作業(yè)總執(zhí)行時間。通過確定單次微操作在不同參數(shù)值下處理數(shù)據(jù)的速率,再完成所有數(shù)據(jù)處理流程得到微操作執(zhí)行次數(shù),即可得到階段總時間。接下來介紹如何建立微操作速率模型。
與Map task的collection phase中兩種微操作相關(guān)的系統(tǒng)參數(shù)是io.sort.mb和sort.spill.percent,這兩個參數(shù)決定了內(nèi)存寫入時的空間大小和觸發(fā)磁盤寫操作的閾值。將這兩個參數(shù)值設(shè)為不同的離散值,并使用相應(yīng)參數(shù)值在實際集群中執(zhí)行實際的單map task任務(wù),在系統(tǒng)執(zhí)行日志中收集內(nèi)存寫和磁盤寫在不同數(shù)據(jù)量下的速率表現(xiàn),通過擬合速率和數(shù)據(jù)量大小的關(guān)系建立微操作速率模型,通過速率和數(shù)據(jù)量即可得到執(zhí)行時間。該基準(zhǔn)測試的目的在于測試出cm_mic_op和cd_mic_op處理不同大小數(shù)據(jù)時的速率表現(xiàn),只需執(zhí)行簡單的單map task任務(wù),執(zhí)行時間短,建模效率高,這里高效率的建模方式也是本方法可移植性好的根本體現(xiàn)。基準(zhǔn)測試時任務(wù)類型須和目標(biāo)作業(yè)類型相同,因為不同作業(yè)的數(shù)據(jù)結(jié)構(gòu)不同,微操作的速率也就可能不同,需要建立不同的微操作模型。
與Reduce task的shuffle phase中三種微操作相關(guān)的系統(tǒng)參數(shù)是reduce.java.opts、shuffle.input.buffer.percent、shuffle.merge.percent和io.sort.factor,這四個參數(shù)是reduce task中影響性能的主要參數(shù),其決定了內(nèi)存寫入時的空間大小和觸發(fā)磁盤寫操作的閾值,以及在磁盤進(jìn)行文件合并時的閾值。同樣,這些參數(shù)對時間性能的影響主要體現(xiàn)在影響微操作處理的數(shù)據(jù)量大小。為了建立sm_mic_op、sd_mic_op和merge_mic_op的速率模型,將這幾個參數(shù)值設(shè)為不同的離散值,并使用相應(yīng)參數(shù)值在集群中執(zhí)行實際的單reduce任務(wù),然后在系統(tǒng)日志中收集不同操作在不同數(shù)據(jù)量下的速率表現(xiàn),通過擬合微操作執(zhí)行速率和數(shù)據(jù)量大小的關(guān)系建立模型,通過速率和數(shù)據(jù)量便可得到執(zhí)行時間。這里建立的內(nèi)存寫微操作sm_mic_op可以看作是網(wǎng)絡(luò)傳輸速率模型。通過定義微操作的方式定量地分析網(wǎng)絡(luò)傳輸速率和數(shù)據(jù)量大小的關(guān)系,在對reduce端的微操作進(jìn)行基準(zhǔn)測試時,map端的task需能完整體現(xiàn)網(wǎng)絡(luò)結(jié)構(gòu)的性能,即在每一個nodemanager中都需要執(zhí)行map task,存儲中間數(shù)據(jù)供reduce task拉取。由于只是測試單reduce task作業(yè),所以數(shù)據(jù)量無需過大,以測試效率為主。
在集群和作業(yè)類型固定的情況下,本文假設(shè)微操作速率符合以下線性模型:
3 作業(yè)重構(gòu)與優(yōu)化
3.1 作業(yè)重構(gòu)
在本節(jié)中,將詳細(xì)介紹如何根據(jù)建立好的微操作模型重構(gòu)得到階段(phase)的原始運行過程,從而得到階段運行時間和參數(shù)的關(guān)系。
在第2章中,對兩個階段進(jìn)行了解構(gòu),針對不同的階段,利用該階段定義的微操作對該階段的運行流程進(jìn)行重構(gòu)。Map task中的collection phase,作如下定義:
其中:記參數(shù)io.sort.mb的值為x,參數(shù)sort.spill.percent的值為y;Tc表示collection phase執(zhí)行時間;cm_mic_op微操作時間模型表示為M(a),a表示輸入數(shù)據(jù)量大小,返回處理時間;cd_mic_op微操作時間模型表示為D(a),a表示輸入數(shù)據(jù)量大小;Din表示collection phase處理數(shù)據(jù)的總大小。
當(dāng)?shù)谝淮蝺?nèi)存寫達(dá)到閾值時,觸發(fā)磁盤寫操作并將寫入了數(shù)據(jù)的內(nèi)存空間鎖定(內(nèi)存空間被鎖定后,不再有數(shù)據(jù)寫入),與此同時,內(nèi)存寫操作會繼續(xù)在剩余空閑的內(nèi)存空間內(nèi)寫入數(shù)據(jù)直到當(dāng)次磁盤寫操作結(jié)束,此時解鎖之前被鎖定的內(nèi)存空間,若:
1)此次磁盤寫操作過程中內(nèi)存中被寫入的數(shù)據(jù)量大于等于x*y,則再次觸發(fā)磁盤寫操作,將內(nèi)存中的數(shù)據(jù)全部存入磁盤。
2)此次磁盤寫操作過程中內(nèi)存中被寫入的數(shù)據(jù)量小于x*y,則在被解鎖的內(nèi)存空間中繼續(xù)寫入數(shù)據(jù),直到內(nèi)存中的數(shù)據(jù)量達(dá)到閾值x*y時,再次觸發(fā)磁盤寫操作。
如此交替執(zhí)行內(nèi)存寫操作和磁盤寫操作直至所有數(shù)據(jù)被寫入磁盤。在式(2)中,y>0.5時對應(yīng)上述情況1),y≤0.5時對應(yīng)上述情況2)。
對于reduce task中的shuffle phase,有四個主要影響性能的參數(shù):reduce.java.opts、shuffle.input.buffer.percent、shuffle.merge.percent和io.sort.factor。其中reduce.java.opts和shuffle.input.buffer.percent決定了sm_mic_op內(nèi)存寫入時的空間大小。參數(shù)shuffle.merge.percent決定了觸發(fā)sd_mic_op磁盤寫入時內(nèi)存中存在數(shù)據(jù)的閾值,參數(shù)io.sort.factor決定了觸發(fā)merge_mic_op文件合并時本地存在的文件個數(shù),例如當(dāng)io.sort.factor=n時,當(dāng)本地存在的文件個數(shù)為2*n-1個時,觸發(fā)merge_mic_op操作,合并大小最小的n個文件為一個文件。
對于shuffle phase運行過程的重構(gòu),首先sm_mic_op從起始位置開始查找內(nèi)存中空余空間,往未被鎖定的內(nèi)存空間中寫入數(shù)據(jù),當(dāng)?shù)谝淮蝺?nèi)存寫達(dá)到閾值時觸發(fā)磁盤寫操作并將該部分內(nèi)存空間鎖定,直到本次磁盤寫操作結(jié)束時對其解鎖;與此觸發(fā)磁盤寫操作的同時,內(nèi)存寫操作繼續(xù)在剩余空閑且未被鎖定的空間內(nèi)寫入數(shù)據(jù),達(dá)到閾值時再次觸發(fā)磁盤寫操作,如此往復(fù),當(dāng)本地文件個數(shù)達(dá)到觸發(fā)merge_mic_op的閾值時,觸發(fā)文件合并操作;當(dāng)sm_mic_op查找到內(nèi)存空間尾部位置時,開始等待,停止寫入數(shù)據(jù)直到所有磁盤寫操作結(jié)束即內(nèi)存中所有空間被解鎖時,再次從內(nèi)存起始位置開始查找空余空間寫入數(shù)據(jù);當(dāng)sm_mic_op處理過的數(shù)據(jù)量達(dá)到reduce task所需處理的數(shù)據(jù)總量時,重構(gòu)過程完成。
基于微操作模型,可以在不同參數(shù)值的情況下對shuffle phase進(jìn)行作業(yè)重構(gòu),得出參數(shù)和階段執(zhí)行時間的關(guān)系。
在reduce task中還有一個階段是sort_write phase(sw_phase),該階段利用多路歸并算法將所有數(shù)據(jù)進(jìn)行排序并輸出到磁盤得到最終結(jié)果。該階段的特殊性在于雖然沒有直接影響該階段性能的參數(shù),但是在shuffle phase中產(chǎn)生的本地文件個數(shù)會間接影響該階段的數(shù)據(jù)排序效率。為了提高整個job執(zhí)行時間優(yōu)化的準(zhǔn)確性,需要對該階段進(jìn)行建模。將sort_write phase整個階段定義為一個磁盤寫微操作,影響該操作的參數(shù)是決定shuffle phase本地文件個數(shù)的參數(shù)和總數(shù)據(jù)量,所以在第2章的基準(zhǔn)測試中,測試shuffle phase相關(guān)微操作的同時,在系統(tǒng)日志中提取出sort_write phase執(zhí)行時間與shuffle phase的本地文件個數(shù)和數(shù)據(jù)量的關(guān)系。定義如下微操作模型:
(3)
其中:Tsw_phase表示sort_write phase的執(zhí)行時間;Dsw_input表示sort_write phase處理的數(shù)據(jù)量大小;Nspill表示shuffle phase中sd_mic_op執(zhí)行的次數(shù); αsw_phase和βsw_phase表示模型參數(shù),通過基準(zhǔn)測試擬合可以得到模型參數(shù)。
3.2 基于微操作的參數(shù)調(diào)優(yōu)
針對本文的Hadoop參數(shù)調(diào)優(yōu)問題,優(yōu)化目標(biāo)是最小化mapreduce job的運行時間,將job解構(gòu)為六個phase之后,優(yōu)化目標(biāo)從最小化job整體運行時間轉(zhuǎn)換為最小化collection phase、shuffle phase和sort_write phase運行時間之和。基于微操作模型對各階段運行時間進(jìn)行最小化即可得到最小化的job運行時間。
本文方法可視為一種優(yōu)化問題的描述方法和分析框架,在此模型基礎(chǔ)上可以應(yīng)用不同的參數(shù)搜索算法來優(yōu)化作業(yè)運行時間。下面給出基于微操作模型的調(diào)優(yōu)框架:
1)解構(gòu)運行過程,分析參數(shù)影響方式,定義微操作類型。
2)基于定義的微操作進(jìn)行基準(zhǔn)測試,建立微操作執(zhí)行時間和參數(shù)的關(guān)系。
3)基于微操作對運行過程進(jìn)行重構(gòu),建立整體運行時間與參數(shù)的關(guān)系。
4)選擇搜索算法在參數(shù)空間內(nèi)進(jìn)行搜索,迭代執(zhí)行模型,得到在不同參數(shù)值情況下運行時間的情況選擇運行時間達(dá)到要求的參數(shù)組合。
5)結(jié)束參數(shù)優(yōu)化。
4 實驗結(jié)果與分析
使用本文提出的方法構(gòu)建了微操作模型和運行過程重構(gòu)模型進(jìn)行實驗。實驗環(huán)境配置為:型號為DELL PowerEdge R710的服務(wù)器6臺,磁盤500GB/臺,內(nèi)存8GB/臺,默認(rèn)設(shè)置一個nodemanager上并行4個map task,并行2個reduce task。用terasort和wordcount兩種作業(yè)測試了本文的方法。
4.1 度量標(biāo)準(zhǔn)
在實驗結(jié)果中主要對作業(yè)默認(rèn)配置的運行時間和調(diào)優(yōu)后的運行時間進(jìn)行對比,并對默認(rèn)配置的運行時間歸一化為1,調(diào)優(yōu)后執(zhí)行時間為與默認(rèn)配置下執(zhí)行時間的比率。
作業(yè)默認(rèn)參數(shù)值如表2所示,在參數(shù)名后標(biāo)記序號是為在后續(xù)參數(shù)表中表示對應(yīng)參數(shù)名,不再寫具體參數(shù)名。
4.2 數(shù)據(jù)集
實驗在terasort和wordcount 2個作業(yè)類型上測試本文提出的方法,terasort和wordcount是常用的benchmark。針對collection phase分別測試50GB、100GB和200GB的輸入數(shù)據(jù)量;針對shuffle phase分別測試100GB、200GB和300GB的輸入數(shù)據(jù)量。針對job的運行時間分別測試100GB和200GB的輸入數(shù)據(jù)量。
4.3 結(jié)果分析
如圖2的實驗結(jié)果所示,第一個實驗是對terasort任務(wù)中的sd_mic_op微操作(tr_sd_mic_op)進(jìn)行擬合建模,可以得到該微操作執(zhí)行速率和數(shù)據(jù)量的關(guān)系。從圖2可以看出,線性擬合程度很高,個別離群點是由集群的不穩(wěn)定帶來的系統(tǒng)隨機(jī)誤差。
第二個實驗是在terasort任務(wù)和wordcount任務(wù)上對collection phase的優(yōu)化效果進(jìn)行對比,結(jié)果如表3所示。在terasort任務(wù)中,單map task處理的數(shù)據(jù)量大小是1GB,平均運行時間相對于默認(rèn)參數(shù)可以優(yōu)化43%左右;wordcount任務(wù)中,單map task處理的數(shù)據(jù)量大小也是1GB,平均運行時間相對于默認(rèn)參數(shù)情況下可以優(yōu)化33%左右。參數(shù)調(diào)優(yōu)后的值如表4所示,因為該階段只涉及三個參數(shù),所以其余參數(shù)為默認(rèn)值。terasort任務(wù)是一個排序任務(wù),處理過程中數(shù)據(jù)量不會有太大的變化,而wordcount任務(wù)處理過程中數(shù)據(jù)量會減少,這是導(dǎo)致優(yōu)化程度不一樣的主要原因。
第三個實驗是在terasort和wordcount任務(wù)上對shuffle phase的優(yōu)化效果進(jìn)行對比,結(jié)果如表5所示。相對于默認(rèn)參數(shù)情況下,terasort的shuffle phase運行時間平均優(yōu)化了45%左右,wordcount的shuffle phase運行時間平均優(yōu)化了30%左右。shuffle phase參數(shù)調(diào)優(yōu)后的值如表6所示,因為該階段只設(shè)計四個參數(shù),所以其余參數(shù)為默認(rèn)值。究其原因與collection phase分析的原因類似,不同任務(wù)數(shù)據(jù)變化方式也不一樣,調(diào)優(yōu)效果也不一樣。
5 結(jié)語
本文針對基于手動或者經(jīng)驗的Hadoop參數(shù)調(diào)優(yōu)存在的問題,提出了一種基于微操作重構(gòu)的Hadoop參數(shù)自動優(yōu)化的方法。該方法通過將整體運行過程進(jìn)行解構(gòu),定義參數(shù)直接影響的微操作模型,可以對參數(shù)的變化進(jìn)行定量的分析,再基于微操作對運行過程進(jìn)行重構(gòu),從而建立整體運行時間和參數(shù)的關(guān)系。實驗結(jié)果表明,本文提出的方法在調(diào)節(jié)那些人工調(diào)優(yōu)很有難度的參數(shù)上有較好的效果,表明了本文所提的方法是可行且高效的。接下來,我們會針對其他更復(fù)雜的參數(shù),如單機(jī)并行的map task和reduce task個數(shù)等進(jìn)行調(diào)優(yōu),這會涉及到運行流程和硬件設(shè)備的相關(guān)分析,將是未來進(jìn)一步的研究方向。
參考文獻(xiàn) (References)
[1] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [C] // Proceedings of the 6th Conference on Symposium on Opearting Systems Design and Implementation. Berkeley, CA: USENIX Association, 2004: 137-149.
[2] CUTTING D. Apache Hadoop [EB/OL]. (2015-02-25)[2018-08-12]. http://hadoop.apache.org.
[3] BABU S. Towards automatic optimization of MapReduce programs [C]// Proceedings of the 1st ACM Symposium on Cloud Computing. New York: ACM, 2010: 137-142.
[4] TIPCON T. 7 tips for improving MapReduce performance [EB/OL]. (2009-12-17)[2018-08-12]. http://www.cloudera.com/blog/2009/12/7-tips-for-improving-mapreduce-performance/.
[5] HERODOTOU H, LIM H, LUO G, et al. Starfish: a self-tuning system for big data analytics [C]// Proceedings of the 2011 5th Biennial Conference on Innovative Data Systems Research. Asilomar, CA: [s.n.], 2011: 261-272.
[6] WANG J H, QIU M K, GUO B, et al. Phase-reconfigurable shuffle optimization for Hadoop MapReduce [EB/OL]. [2018-08-12]. IEEE Transactions on Cloud Computing, 2015, 3: 1-1.https://www.onacademic.com/detail/journal_1000038191224210_fd14.html.
[7] YIGITBASI N, WILLKE T L, LIAO G, et al. Towards machine learning-based auto-tuning of MapReduce [C]// Proceedings of the IEEE 21st International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems. Piscataway, NJ: IEEE, 2013: 11-20.
[8] CHAUDHURI S, NARASAYYA V. Self-tuning database systems: a decade of progress [C]// Proceedings of the 2007 International Conference on Very Large Data Bases. Framingham, MA: VLDB Endowment, 2007: 3-14.
[9] IPEK E, de SUPINSKI B R, SCHULZ M, et al. An approach to performance prediction for parallel applications [C]// Proceedings of the 2005 European Conference on Parallel Processing, LNCS 3648. Berlin: Springer, 2005: 196-205.
[10] SINGER J, KOVOOR G, BROWN G, et al. Garbage collection auto-tuning for Java MapReduce on multi-cores [C]// Proceedings of the 2011 International Symposium on Memory Management. New York: ACM, 2011: 109-118.
[11] CHENG D Z, RAO J, GUO Y F, et al. Improving performance of heterogeneous MapReduce clusters with adaptive task tuning [J]. IEEE Transactions on Parallel & Distributed Systems, 2017, 28(3): 774-786.
[12] WASI-UR-RAHMAN M, ISLAM N S, LU X, et al. MR-Advisor: a comprehensive tuning tool for advising HPC users to accelerate MapReduce applications on supercomputers [C]// Proceedings of the 28th International Symposium on Computer Architecture and High Performance Computing. Piscataway, NJ: IEEE, 2016: 198-205.
[13] 童穎.基于機(jī)器學(xué)習(xí)的Hadoop參數(shù)調(diào)優(yōu)方法[D].武漢:華中科技大學(xué),2016:1-52.(TONG Y. Hadoop parameters tuning method based on machine learning [D]. Wuhan: Huazhong University of Science and Technology, 2016: 1-52.)
[14] LIAO G, DATTA K, WILLKE T L. Gunther: search-based auto-tuning of MapReduce [C]// Proceedings of the 2013 European Conference on Parallel Processing, LNCS 8097. Berlin: Springer, 2013: 406-419.
[15] DEB K. An introduction to genetic algorithms [J]. Sadhana, 1999, 24(4/5): 293-315.
[16] 祝春祥,陳世平,陳敏剛.基于遞歸隨機(jī)抽樣的Hadoop配置優(yōu)化[J].計算機(jī)工程,2016,42(2):26-32.(ZHU C X, CHEN S P, CHEN M G. Configuration optimization of Hadoop based on recursive random sampling [J]. Computer Engineering, 2016, 42(2): 26-32.)
