基于帶權評論圖的水軍群組檢測及特征分析
2019-08-27 02:26:02張琪紀淑娟傅強張純金
計算機應用 2019年6期
張琪 紀淑娟 傅強 張純金

摘 要:針對在電子商務平臺上檢測編寫虛假評論的水軍群組的問題,提出了基于帶權評論圖的水軍群組檢測算法(WGSA)。首先,利用共評論特征構建帶權評論圖,權重由一系列群組造假指標計算得到;然后,為邊權重設置閾值篩選可疑子圖;最后,從圖的社區結構出發,利用社區發現算法生成最終的水軍群組。在Yelp大型數據集上的實驗結果表明,與K均值聚類算法(KMeans)、基于密度的噪聲應用空間聚類算法(DBscan)以及層次聚類算法相比WGSA算法的準確度更高,同時對檢測到水軍群組的特征與差異作了分析,發現水軍群組的活躍度不同,危害也不同。其中,高活躍度群組危害最大,應重點關注。
關鍵詞:電子商務;水軍群組;帶權評論圖;社區發現;聚類
中圖分類號: TP391.4 模式識別與裝置
文獻標志碼:A
Abstract: Concerning the problem that how to detect spammer groups writing fake reviews on the e-commerce platforms, a Weighted reviewer Graph based Spammer group detection Algorithm (WGSA) was proposed. Firstly, a weighted reviewer graph was built based on the co-reviewing feature with the weight calculated by a series of group spam indicators. Then, a threshold was set for the edge weight to filter the suspicious subgraphs. Finally, considering the community structure of the graph, the community discovery algorithm was used to generate the spammer groups. Compared with K-Means clustering algorithm (KMeans), Density-Based spatial clustering of applications with noise (DBscan) and hierarchical clustering algorithm on the large dataset Yelp, the accuracy of WGSA is higher. The characteristics and distinction of the detected spammer groups were also analyzed, which show that spammer groups with different activeness have different harm. The high-active group is more harmful and should be concerned more.
Key words: e-commerce; spammer group; weighted reviewer graph; community discovery; clustering
0 引言
在電子商務平臺上,在線商品評論在用戶的決策中起著重要作用。用戶傾向于購買正面評論較多的產品,而不是負面評論較多的產品。為了抬高或降低某產品的信譽,賺取更多利益,很多商家往往會雇傭虛假評論者發布大量贊美自家商品或詆毀競爭對手商品的不實評論,誤導消費者,影響電商平臺的公平競爭環境。這些虛假評論者稱為水軍。近年來,隨著電子商務的迅猛發展,水軍的規模也越發壯大,甚至結成水軍群組協同作案。水軍群組即指那些有組織地協同發布虛假評論的一群人。相比水軍個體,水軍群組影響力更大(甚至能控制產品的輿論走勢、造成用戶逆向選擇)、隱秘性更強,因此對檢測算法的設計要求更高。
在水軍群組檢測方面,研究者也提出了一些有針對性的檢測方法。文獻[1]首次進行了電商平臺水軍群組的檢測工作,指出水軍群組的一個重要特征——“共評論”,即水軍成員通常共同評論相同的產品。為了檢測共評論的水軍群組,他們利用頻繁項挖掘的方法尋找共評論過多個產品的評論者集作為候選水軍群組,然后提出一種排序模型來定位最可疑的水軍群組。
繼文獻[1]之后,文獻[2]也使用頻繁項挖掘的方法來確定候選水軍群組,他們還評價了已有的用于識別評論者造假個體的特征與造假群組的特征的有效性;但是他們工作的目的是設計算法實現共謀者個體和非共謀者個體的檢測,而不是水軍群組的檢測。文獻[3]提出了一種水軍群組檢測算法。該算法分兩步實現:第一步,量化某產品為水軍目標產品的概率,定位目標產品;第二步,利用層次聚類算法得到水軍群組。文獻[4]提出基于評論產品構建二部圖,然后利用一系列群組造假特征作為識別標準,使用圖劃分方法得到水軍群組。文獻[5]依據評論者“共評論”的關系特征構建用戶關系網絡,然后使用一系列特征構建多特征尺度空間模型進行水軍群組的識別。
從已有群組檢測研究的發展來看,利用基于圖的方法來檢測水軍群組是一個趨勢。群組劃分多采用聚類算法、圖劃分算法。然而,上述方法只進行了水軍群組的劃分,沒有對水軍群組進行進一步的分析,探究不同水軍群組間的聯系和差別,以發現水軍群組的整體行為特征。
針對上述工作的不足,本文提出了基于帶權評論圖的水軍群組發現算法(Weighted reviewer Graph based Spammer group detection Algorithm, WGSA)。本文的主要工作總結如下:
1)本文在基于圖的水軍群組檢測方法基礎上,構建了帶權評論圖,然后利用權重篩選子圖。該方法能夠去掉大部分不重要的節點,大大降低計算的時空復雜度。
2)本文從圖的社區結構出發,認為水軍群組的造假行為會形成典型的社區結構,所以本文采用社區發現算法生成水軍群組,實驗證明效果較好。
3)基于Yelp的大型帶標簽數據集,本文對發現的水軍群組作了全面的可疑度分析以證明本文算法的有效性,同時探究了水軍群組的差異和整體行為特征。
1 水軍群組檢測算法
本章描述了本文提出的水軍群組檢測算法,算法由四個步驟組成,即水軍群組造假行為特征選擇、帶權評論圖的構建、可疑子圖的篩選以及基于社區發現算法的水軍群組的聚類。下面詳細介紹每個步驟細節。
1.1 造假行為特征選擇
在已有工作中,研究者提出了很多評估個人或群組的造假指標,例如語言指標[1, 3, 6-7]、行為指標[1-4, 8-12]、關系指標[2-6, 8-14]等。與之前提出的指標不同,本文使用行為指標量化兩個評論者之間的共謀程度,具體指標如下。
1.1.1 共評論次數
水軍群組的成員通常同時針對多個產品發表評論,協同合作完成任務。兩兩評論者,如果只共同評論過一件或兩件產品,有可能只是因為巧合,是正常用戶的評論,不能因此判定為水軍組織成員;而評論用戶作為分散的網絡用戶,若共同評論的產品數很多,就可視為非正常用戶行為。本文利用共評論次數(Co-Reviewing Time, CRT)[1]來捕捉兩兩評論者的共評論特征。
1.1.2 評分相似度
水軍群組通常協同發布虛假評論來抬高或貶低目標產品的評分。因此,水軍群組成員往往發布相似評分來控制目標產品的評分趨勢。本文定義了評分相似度(Similarity of Rating, SR)[5]來捕捉這種行為。
其中:Rp1是評論者n1對產品p的評分,評分R∈[1,5];本文引入了一個參數β以減少誤差,β取值為2.5。SR(n1,n2)∈[1,5],SR值越趨近于-1,表示兩兩評論者在同一維度上的評分值偏差越大;越趨近于1,表示兩兩評論者的觀點一致性越強。
1.2 帶權評論圖的構建
在電子商務網站中,不同的用戶可以通過兩種方式建立聯系:一種是用戶之間的直接交互,例如用戶發表評論和其他用戶回復其評論。另一種隱含的聯系是兩個用戶對同一產品進行評論,即共評論。一個水軍群組的成員通常共同評論相同的產品,這是識別水軍群組成員間聯系的關鍵。
本文將評論者個體作為節點,將用戶的共評論關系作為邊的聯系,構建帶權評論圖G=(N, E,W)。N是由全體評論者組成的節點集,邊e=(n1,n2)∈E存在當且僅當評論者n1、n2至少共同評論過一個產品。邊的權重w∈W,對應著每一條邊,代表了兩兩評論者節點間共謀的可疑度。
邊的權重w由1.1節描述的造假行為特征計算得到,計算式如下:
1.3 可疑子圖的篩選
本文構建的評論圖是基于評論者的共評論特性,邊的權重代表了兩兩評論者間共謀的可疑度。因為原始評論圖十分龐大,計算難度較高,本文首先進行可疑子圖的篩選,既可以保證算法的準確度,也可以降低算法的時間復雜度。詳見算法1。
1) 構建原始帶權評論圖G= (N, E, W) ,將邊的權重初始化為1
2) for 邊e=(n1,n2)∈E do
3)計算權重
4)if we< δ then
5) 移除邊e
6) end for
7) 輸出篩選得到的可疑子圖
程序后
在算法1中,在第1)行,首先構建帶權評論圖G,將邊的權重初始化為1;第2)~7)行,計算邊的權重,設置邊權重的閾值δ,移除邊權重we<δ的邊,得到篩選后的子圖。邊篩選閾值δ的確定在實驗部分具體說明。
1.4 水軍群組的聚類
水軍群組的造假行為會在評論圖中形成典型的社區結構,基于此,本文利用Louvain社區發現算法[16]來生成水軍群組。Louvain算法是典型的社區發現算法,它基于最大化模塊度進行社區劃分,能夠有效地發現網絡中社區結構,即本文中的水軍群組。
2 實驗及結果分析
2.1 數據集
與文獻[6,10-11]中的實驗研究相同,本文也使用來自美國著名商戶點評網站Yelp自2006年起歷時7年的旅店評論數據。該數據集包含了評論虛假與否的標簽,數據集的評論真率為61.1%。特別的,數據集中沒有重復交易的買家和賣家對。每條評論包含以下屬性:日期、評論ID、評論者ID、評論內容、評分、認為該評論有用的用戶個數、認為該評論很酷的用戶個數、認為該評論有趣的用戶個數、標簽、旅店ID。
在數據被使用之前,本文對數據集進行了如下預處理:
1)刪除評論集中匿名的用戶及評論數據。因為無法確定匿名是被同一人發表還是被多人發表。
2)刪除不活躍的用戶和產品。在本文研究中關注的是活躍度較高的用戶,以及具有較高關注度的產品,不活躍的用戶可疑性小,可以忽略。在數據集中評論用戶發表的評論數少于三個,以及產品的評論數少于三個,則首先將其刪除。
3)將數據表中未使用的屬性去除,以精簡數據集。
經過以上三個方面的數據處理之后,數據集的概況如表1所示。
2.2 邊篩選閾值δ的確定
δ的大小決定了篩選得到的可疑子圖的大小與質量:如果δ取值過大,刪除的邊過多,可能嚴重破壞子圖的結構,影響后面社區劃分的質量;如果取值太小,又無法保證得到的子圖中邊和節點的可疑度。由于邊的權重是通過特征CRT與SR計算得到,本文分別探究了CRT的閾值,記作ωCRT和SR的閾值ωSR。如果一條邊的CRT≥ωCRT,SR≥ωSR,則該邊是可疑的。在這兩個閾值的基礎上,本文提出了如下δ計算方法:
2.2.1 ωCRT的計算
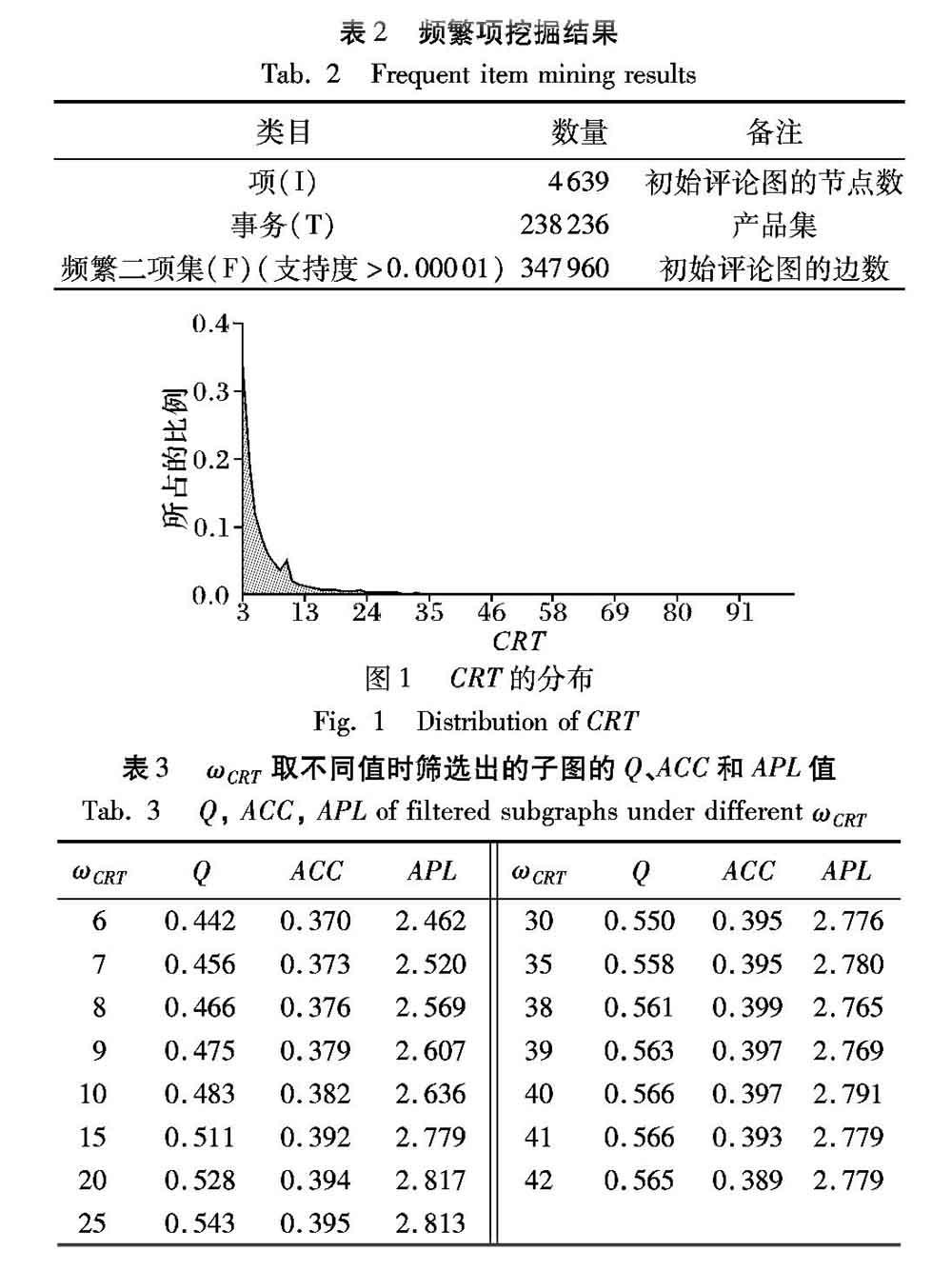
用式(2)計算評論圖中邊的CRT值,頻繁2項集挖掘的結果如表2所示。邊的CRT值統計數據如圖1所示,其中61%的邊的CRT值為3、4和5。
接下來的問題就是ωCRT的選取,以篩選可疑的邊。如果ωCRT取值過大,會過濾掉大部分邊,嚴重破壞圖的結構;如果ωCRT取值過小,過濾效果不明顯。為了避免過度破壞圖的結構,本文選取了3個通用的指標:模塊度(Modularity, Q)[17]、平均聚類系數(Average Clustering Coefficient, ACC)[18]和平均路徑長度(Average Path Length, APL)[19]來評價網絡社區結構。Q、ACC、APL值越大,則代表相應的圖更緊密,社區結構更明顯。本文采用插值法,計算了ωCRT取不同值時,篩選得到的子圖的Q、ACC、APL值。計算結果如表3所示,當ωCRT=40時,Q、ACC、APL均取得最大值,這說明,此時的網絡社區結構達到了最佳,所以,ωCRT取40。
2.2.2 ωSR的計算
用式(3)計算SR的值,對SR值的分布進行統計,如圖2所示。從圖2中可以看出,大部分邊的SR值都大于0.5,這說明大部分邊所連接的兩兩評論者之間的評分相似度極高,觀點一致性較強。這里取ωSR為0.5。
2.3 水軍群組的聚類
2.4 結果分析
鑒于本文使用的Yelp數據集只有評論虛假與否的標簽,首先從虛假評論比例出發,分析了檢測到的水軍群組的特征與差異。然后選取K均值聚類算法(K-Means clustering algorithm, KMeans)、基于密度的噪聲應用空間聚類算法(Density-Based spatial clustering of applications with noise, DBscan)以及層次聚類算法進行對比,驗證本文算法的有效性。
2.4.1 基于虛假評論比例的造假度分析
正如許多研究中所提到的,Yelp、Amazon和Dianping等大型電子商務網站的數據集只能得到虛假/真實的評論標簽,很難得到評論者個體的標簽,更不用說水軍群組了。在文獻[6]中,至少發布過一條假(被電商網站過濾掉的)評論的評論者將被視為虛假評論者,沒有假評論的評論者將被視為正常評論者。在文獻[13]中,如果評論者至少有10%的評論被Dianping網站檢測到是假的,則將其視為虛假評論者。在文獻[14]中,一個評論者發布的評論中如果有超過50%的評論是假的,即被認為是垃圾郵件用戶。為了獲取水軍群組的標簽,文獻[1-2,4]中只能采用手動標記的方法。而在文獻[14]中通過評估聚類質量來評價得到的水軍群組的好壞,這樣做說服力明顯不足。
結合上述文獻對標簽的處理,本文進行了有趣的分析,對于每個水軍群組,本文計算了在這個群組中,虛假評論超過一定百分比的評論者所占的比例,統計情況如表5所示。
表5中的值指的是每個群組中至少發布了10%、20%、…虛假評論的評論者的比例。例如,在第一組中,有190個成員。在這一組中,100%(表5中的第一組)的評審員發布了超過10%的虛假評論,這意味著第一組的所有成員都發布了超過10%的虛假評論。注意到,第6組第8行出現的0,指的是群組6中沒有成員的虛假評論比例超過45%,換言之,群組6中的成員發布的虛假評論比例均低于45%。特別地,第一組的成員中有69%的成員至少發布了50%的虛假評論。這種群組可疑度極大。
本文還計算了每個水軍群組中成員虛假評論比例的平均值,結果如圖5所示。由圖5可以看出,不同群組間有極大的差異性,例如群組1、2、3、7和12中成員的平均虛假評論比例均高于40%,群組4、5、8和9為30%~40%,群組6、10、11為10%~30%。從圖5中可以看出,不同群組的活躍度是不同的。因此本文將12個群組分為3類:群組1、2、3、7和12為高活躍度群組,群組4、5、8和9為一般活躍群組,群組6、10、11為低活躍度群組。
三類群組中成員的虛假評論比例如圖6所示。從圖6中可以看出,高活躍度群組,成員數較多,大部分成員的虛假評論比例均超過30%,危害極大;一般活躍群組,成員規模一般,虛假評論比例也較高,但遠低于高活躍度群組;相對來說,低活躍度群組成員數較少,虛假評論比例也較低。綜上所述,高活躍度群組因為人數多、每個人的造假比例高,對整個市場環境的危害也最大,因此應重點關注。
2.4.2 對比實驗
為了驗證本文算法的性能,本文選舉經典的聚類算法KMeans算法、基于密度的聚類算法DBscan算法作為基準算法進行對比。在現有工作中,文獻[3]利用層次聚類算法生成水軍群組,所以,本文也與層次聚類算法作了比較。
本文利用KMeans算法、DBscan算法、層次聚類算法以及本文所提出的基于帶權評論圖的水軍群組發現算法(WGSA)對檢測出的top12個群組的4個特征進行評估。具體特征為一天最大評論數 (Maximum One day Review, MOR)[20]、極端評分比率 (EXtreme rating Ratio, EXR)[20]、評論時間間隔(Review Time Interval, RTI)[1,20]和評論者比率(Reviewer Ratio, RR)[4]。之所以選擇這些特征作為評估指標,主要因為它們具有很好的通用性,在相應文獻采用這4個特征對個體或群體作可疑度的評估和比較,表現較好。
1)一天最大評論數 (MOR)。
一個評論者在一天中發布大量評論是十分可疑的。MOR度量的是一個評論者一天發布評論的最大值。文獻 [20]的研究結果顯示一名水軍一天的理論評論數至少為5,而正常評論者一般為2。對每個水軍群組的成員計算其MOR值,然后取每個水軍群組中成員MOR的平均值,得到如圖7所示的結果。從圖7可以看出,各算法檢測出的水軍群組平均一天最大評論數均超過6,有些群組甚至超過20,十分可疑,而本文算法與DBscan算法的表現相對更加突出。
2)極端評分比率 (EXR)。
水軍往往發布極高或極低的評分來抬高或降低目標產品的評分。EXR度量的是一個評論者的評分是否極高或極低。由于評分范圍為[1,5],本文采用與文獻[20]一樣的處理方法,即將1、5作為極端評分,然后計算每個評論者極端評分的比例。計算得到的每個水軍群組中成員的平均極端評分比率如圖8所示。從圖8可以看出,本文算法檢測出的水軍群組中成員的平均極端評分比率均大于0.6,而其他算法只有0.3左右,本文的算法表現較好。
3)評論時間間隔(RTI)。
水軍通常在較短的時間內連續發布虛假評論,所以相鄰評論間較短的時間間隔揭示了疑似的水軍行為。文獻[1, 20]指出,如果一個評論者的相鄰評論時間間隔小于28天,則是可疑的。本文亦取小于28天的評論時間間隔為可疑時間間隔。RTI計算的是一個評論者的所有相鄰評論時間間隔中可疑時間間隔的比例。每個群組中成員的平均RTI值如圖9所示。從圖9可以看出,本文算法檢測出的水軍群組的平均RTI值均在0.9左右,而其他算法的表現差一些,在0.7左右。
4)評論者比率(RR)。
如果目標產品主要由某水軍群組的成員所評論,該水軍群組就能完全控制該產品的輿論,危害極大。RR度量的是一個產品的評論者中身為某水軍群組成員的比例。本文取一個群組中該比例的最大值作為RR的值。每個水軍群組的最大RR值如圖10所示。從圖10可以看出,所有算法中每個水軍群組的RR值均為1,這說明這些水軍群組完全控制了部分產品的輿論走勢,危害極大。
從上述分析可以得到,本文提出的算法WGSA,在MOR、RR指標上表現相對較好,在EXR、RTI指標上比其他算法有較大提升,總體來看,本文算法得到的水軍群組可疑度更高,更有效。
3 結語
本文提出了基于帶權評論圖的水軍群組發現算法(WRBA)。該算法首先構建帶權評論者網絡圖,權重由一系列特征計算得到;然后設置閾值篩選可疑子圖;最后利用社區發現算法生成水軍群組。本文從虛假評論比例出發,發現檢測到的水軍群組成員的平均虛假評論比例均超過10%,表明了本文所提算法的有效性。而且本文研究發現,水軍群組可以分成三類:高活躍度群組、一般活躍群組以及低活躍度群組。其中,高活躍度群組發布的評論多,虛假評論比例高,危害極大,應重點關注。為了驗證本文算法的性能,本文選取了多個已有算法在4個群組虛假度特征(MOR、EXT、RTI和RR)上進行比較。實驗結果表明,本文算法檢測出的水軍群組可疑度更高,算法性能表現更好。但本文只考慮了兩種特征來構建帶權評論者網絡圖,而且沒有考慮時間因素,在今后的工作中,將考慮更多的特征,完善水軍群組的檢測方法。
參考文獻 (References)
[1] MUKHERJEE A, LIU B, GLANCE N. Spotting fake reviewer groups in consumer reviews [C]// Proceedings of the 21st Annual Conference on World Wide Web. New York: ACM, 2012: 191-200.
[2] XU C, ZHANG J, CHANG K, et al. Uncovering collusive spammers in Chinese review website [C]// Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. New York: ACM, 2013: 979-988.
[3] YE J, AKOGLU L. Discovering opinion spammer groups by network footprints [C]// Proceedings of the 2015 Joint European Conference on Machine Learning and Knowledge Discovery in Databases, LNCS 9284. Cham: Springer, 2015: 267-282.
[4] WANG Z, HOU T, SONG D, et al. Detecting review spammer groups via bipartite graph projection [J]. The Computer Journal, 2016, 59(6): 861-874.
[5] 張慧杰.基于多特征尺度空間模型的網絡水軍組織發現技術研究[D].杭州:浙江工商大學,2015:2-66.(ZHANG H J. Research technology on found of spammer organizations based on multi-feature scale space model [D]. Hangzhou: Zhejiang Gongshang University , 2015:? 2-66.)
[6] RAYANA S, AKOGLU L. Collective opinion spam detection: bridging review networks and metadata [C]// Proceedings of the 2015 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 985-994.
[7] RAYANA S, AKOGLU L. Collective opinion spam detection using active inference [C]// Proceedings of the 2016 16th SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2016: 630-638.
[8] JINDAL N, LIU B. Opinion spam and analysis [C]// Proceedings of the 2008 International Conference on Web Search & Data Mining. New York: ACM, 2008: 219-230.
[9] LIM E, NGUYEN V, JINDAL N, et al. Detecting product review spammers using rating behaviors [C]// Proceedings of the 19th ACM Conference on Information and Knowledge Management. New York: ACM, 2010: 939-948.
[10] OTT M, CHOI Y, CARDIE C, et al. Finding deceptive opinion spam by any stretch of the imagination [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 309-319.
[11] YU P S, LIU B, XIE S, et al. Review graph based online store review spammer detection [C]// Proceedings of the 11th IEEE International Conference on Data Mining. Piscataway, NJ: IEEE, 2011: 1242-1247.
[12] AKOGLU L, CHANDY R, FALOUTSOS C. Opinion fraud detection in online reviews by network effects [C]// Proceedings of the 2013 7th International Conference on Weblogs and Social Media. Menlo Park, CA: AAAI, 2013: 2-11.
[13] LI H, CHEN Z, MUKHERJEE A, et al. Analyzing and detecting opinion spam on a large-scale dataset via temporal and spatial patterns [C]// Proceedings of the 9th International Conference on Web and Social Media. Menlo Park, CA: AAAI, 2015: 634-637.
[14] LI H Y, FEI G, SHAO W X, et al. Bimodal distribution and co-bursting in review spam detection [C]// Proceedings of the 26th International Conference on World Wide Web. Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee, 2017: 1063-1072.
[15] AGRAWAL R, SRIKANT R. Fast algorithms for mining association rules in large databases [C]// Proceedings of the 20th International Conference on Very Large Data Bases. San Francisco, CA: Morgan Kaufmann Publishers Inc., 1994: 487-499.
[16] BLONDEL V D, GUILLAUME J, LAMBIOTTE R, et al. Fast unfolding of communities in large networks [J]. Journal of Statistical Mechanics Theory & Experiment, 2008(10): 155-168.
[17] NEWMAN M E J. The structure and function of complex networks [J]. SIAM Review, 2003, 45(2): 167-256.
[18] WATTS D J, STROGATZ S H. Collective dynamics of ‘small-world networks [J]. Nature, 1998(393): 440-442.
[19] FRONCZAK A, FRONCZAK P, HOYST J A. Average path length in random networks [J]. Physical Review E, 2004, 70(5): 056110.
[20] MUKHERJEE A, KUMAR A, LIU B, et al. Spotting opinion spammers using behavioral footprints [C]// Proceedings of the 2013 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 632-640.
