基于帶多數類權重的少數類過采樣技術和隨機森林的信用評估方法
2019-08-27 02:26:02田臣周麗娟
計算機應用 2019年6期
田臣 周麗娟


摘 要:針對信用評估中最為常見的不均衡數據集問題以及單個分類器在不平衡數據上分類效果有限的問題,提出了一種基于帶多數類權重的少數類過采樣技術和隨機森林(MWMOTE-RF)結合的信用評估方法。首先,在數據預處理過程中利用MWMOTE技術增加少數類別樣本的樣本數;然后,在預處理后的較平衡的新數據集上利用監督式機器學習算法中的隨機森林算法對數據進行分類預測。使用受測者工作特征曲線下面積(AUC)作為分類評價指標,在UCI機器學習數據庫中的德國信用卡數據集和某公司的汽車違約貸款數據集上的仿真實驗表明,在相同數據集上,MWMOTE-RF方法與隨機森林方法和樸素貝葉斯方法相比,AUC值分別提高了18%和20%。與此同時,隨機森林方法分別與合成少數類過采樣技術(SMOTE)方法和自適應綜合過采樣(ADASYN)方法結合,MWMOTE-RF方法與它們相比,AUC值分別提高了1.47%和2.34%,從而驗證了所提方法的有效性及其對分類器性能的優化。
關鍵詞:
不平衡數據集;機器學習;帶多數類權重的少數類過采樣技術;隨機森林;信用評估
中圖分類號: TP18;TP399
文獻標志碼:A
Abstract: In order to solve the problem of unbalanced dataset in credit assessment and the limited classification effect of single classifier on unbalanced data, a Majority Weighted Minority Oversampling TEchnique-Random Forest (MWMOTE-RF) credit assessment method was proposed. Firstly, MWMOTE technology was applied to increase the samples of minority classes in the preprocessing stage. Then, on the preprocessed balanced dataset, random forest algorithm, one of supervised machine learning algorithms, was used to classify and predict the data. With Area Under the Carve (AUC) used to evaluate the performance of classifier, experiments were conducted on German credict card dataset from UCI database and a companys car default loan dataset. The results show that the AUC value of MWMOTE-RF method increases by 18% and 20% respectively compared with random forest method and Naive Bayes method on the same data set. At the same time, random forest method was combined with Synthetic Minority Over-sampling TEchnique (SMOTE) and ADAptive SYNthetic over-sampling (ADASYN), respectively, and the AUC value of MWMOTE-RF method increases by 1.47% and 2.34% respectively compared with them. The results prove the effectiveness and the optimization of classifier performance of the proposed method.
Key words: umbalanced dataset; machine learning; Majority Weight Minority Oversampling TEchnique (MWMOTE); random forest; credit assessment
0 引言
伴隨著互聯網金融的日漸興起,數據挖掘和機器學習等新興技術在企業經營和科學決策中的普遍應用,在線信貸作為一種更高效的借貸服務早已顛覆了傳統銀行相關部門的地位,傳統的信用評分模型已經不能高效準確地處理信貸客戶數據。因此,構建并應用精確、客觀和可靠的信用風險評估方法,對于銀行業和有信貸業務的公司,在不同的商業周期和環境下減輕信貸業務危機和損失[1]有著十分重要的現實意義。
迄今為止,大量數據分析技術和建模技術被應用到風險評估領域,從而出現了四大類風險評估方法:統計學方法、運籌學方法、非參數分析法和人工智能方法。基于統計學方法中最具代表性的就是邏輯回歸分析,其是當前理論體系中最為成熟的一種分類模型,最早由Wiginton等[2]于1980年應用于信用風險評估 中。人工智能方法中包括專家系統、神經網絡評估系統、支持向量機、遺傳算法和隨機森林方法。Desai等[3]于20世紀90年代將神經網絡應用于信用風險分析,同時期Baesens等[4]將支持向量機方法運用于信用評分領域。Davis 將[5]遺傳算法應用在了信用評分領域。國內的諸多學者也在信用評估領域中有所研究,李志輝等[6]采用主成分分析法和Fisher線性方法、Logit模型、BP神經網絡技術構造我國商業銀行信用風險識別模型,通過實證分析得出相對于其他兩類模型,Logit模型具有更強的信用風險識別和預測能力。王春峰等[7]改進了蟻群算法并將其應用在了商業銀行信用風險評估中,分析結果相較于判別分析、回歸分類算法更好。隨機森林方法是一種既可用于分類也能用于回歸任務的數據挖掘方法,預測準確率高、不容易出現過擬合、訓練速度快等優點使其在很多領域都有廣泛的應用[8-10]。
就我國銀行業的個人信貸業務而言,發展較晚,信貸風險控制方面還存在著明顯的不足[11],而最為核心的問題,仍然是如何有效地對不對稱信息進行處理,如何高效解決數據類別不平衡問題。所謂類別不平衡數據就是在數據集中,各類別樣本數目差別很大,樣本分布不均,其中類別數量多的為多數類,類別數量少的為少數類,又稱為稀有類。在多數情況下,諸如如網絡入侵檢測[12]、欺詐檢測、垃圾郵件識別,信用評估領域等少數類往往是研究的重點。目前處理不平衡問題的主要數據層面方法是過采樣或者欠采樣,重新分配類別分布,例如:合成少數類過采樣技術(Synthetic Minority Over-sampling TEchnique, SMOTE)方法[13]、自適應綜合過采樣(ADAptive SYNthetic over-sampling, ADASYN)方法[14]和Borderline-SMOTE方法[15]等。
基于以上分析與認識,考慮到單一方法難以在不平衡數據集上達到良好預測效果,本文提出了一種基于帶多數類權重的少數類過采樣技術和隨機森林(Majority Weighted Minority Oversampling Technique-Random Forest, MWMOTE-RF)結合的信用評估方法。本文方法的基本思想是將MWMOTE數據處理作為隨機森林算法的前置預處理系統,通過MWMOTE對信用樣本數據進行少數類樣本數量增加,從而改善隨機森林向多數類類別樣本的傾向性問題。最后結合UCI數據集和汽車違約貸款數據集與傳統的隨機森林方法和樸素貝葉斯方法進行實驗分析對比。除此之外,分別通過SMOTE方法、ADASYN方法和Borderline-SMOTE方法產生平衡數據集訓練隨機森林模型作為實驗對比模型。
1 相關方法及模型的構建
1.1 MWMOTE
在信用評估領域,客戶評估數據中履約的客戶占絕大多數,而違約的客戶作為少數類樣本是我們重點研究的對象。隨機森林算法在處理不平衡數據的問題上存在著缺陷,主要是由于少數類樣本占比少,在此數據集上訓練出來的決策樹不能很好地體現少數類的特點,只有增大少數類占有量或是平衡多數類樣本數量才能使隨機森林算法更加健壯。針對不平衡數據的處理方法有三大類[16]:抽樣法、代價敏感方法和集成方法。其中抽樣方法分為欠抽樣和過抽樣,在處理不平數據集問題上目前應用最廣的是SMOTE方法,作為過抽樣方法的一種,其主要是結合少數類樣本按照一定規則合成少數類樣本,最終達到平衡數據集的目的[17]。但其存在著幾點不足[18]:不能精確控制合成新樣本數量;不能對少數類樣本進行區別性選擇;樣本混疊現象嚴重。
鑒于SMOTE方法存在的不足,本文采用了帶多數類權重的少數類過采樣法[19],相較于應用廣泛的SMOTE方法,可以有效避免新合成樣本混疊問題。該方法的核心思路是首先識別難以學習的信息豐富的少數類樣本,并根據它們與最近的多數類樣本之間的歐氏距離給它們賦值;然后,使用聚類方法從加權信息量大的少數類樣本中合成新樣本。通過這種方式,所有生成的新樣本都位于某個少數類簇中。
1.2 隨機森林
隨機森林是一種統計學理論,是bagging算法和分類回歸樹(Classification And Regression Tree, CART)的結合。通過組合多個CART進行預測,最終通過投票得到預測結果。
Bagging算法又稱自舉匯聚法,是一種基于數據隨機重抽樣的分類器構建方法,在原始數據集上進行有放回的抽樣N次,得到N個新數據集。新數據集與原始數據集大小相等。在這N個數據集上分別對學習算法進行訓練,得到了N個弱分類器,由此方法集成為一個強分類器并最終選擇分類器投票結果中最多的類別作為分類結果。此處的學習算法為CART,一種改進的決策樹。與ID3和C4.5兩種影響較大的決策樹方法相比,CART算法是基于基尼系數的決策樹算法。CART包括分類樹和回歸樹兩部分,其中分類樹根據基尼系數進行特征空間的劃分,回歸樹通過最小化平方誤差進行特征選擇和特征值選擇。
隨機森林的構建過程如下:
1)假設原樣本集有N個樣例,則每輪從原始樣本集中有放回地抽取n個樣例,得到一個與原始樣本集相同大小的樣本集。經過K輪的抽取獲得的訓練集分別為T1,T2,…, TK。
2)每個訓練集訓練一個決策樹模型。共得到K個CART模型。
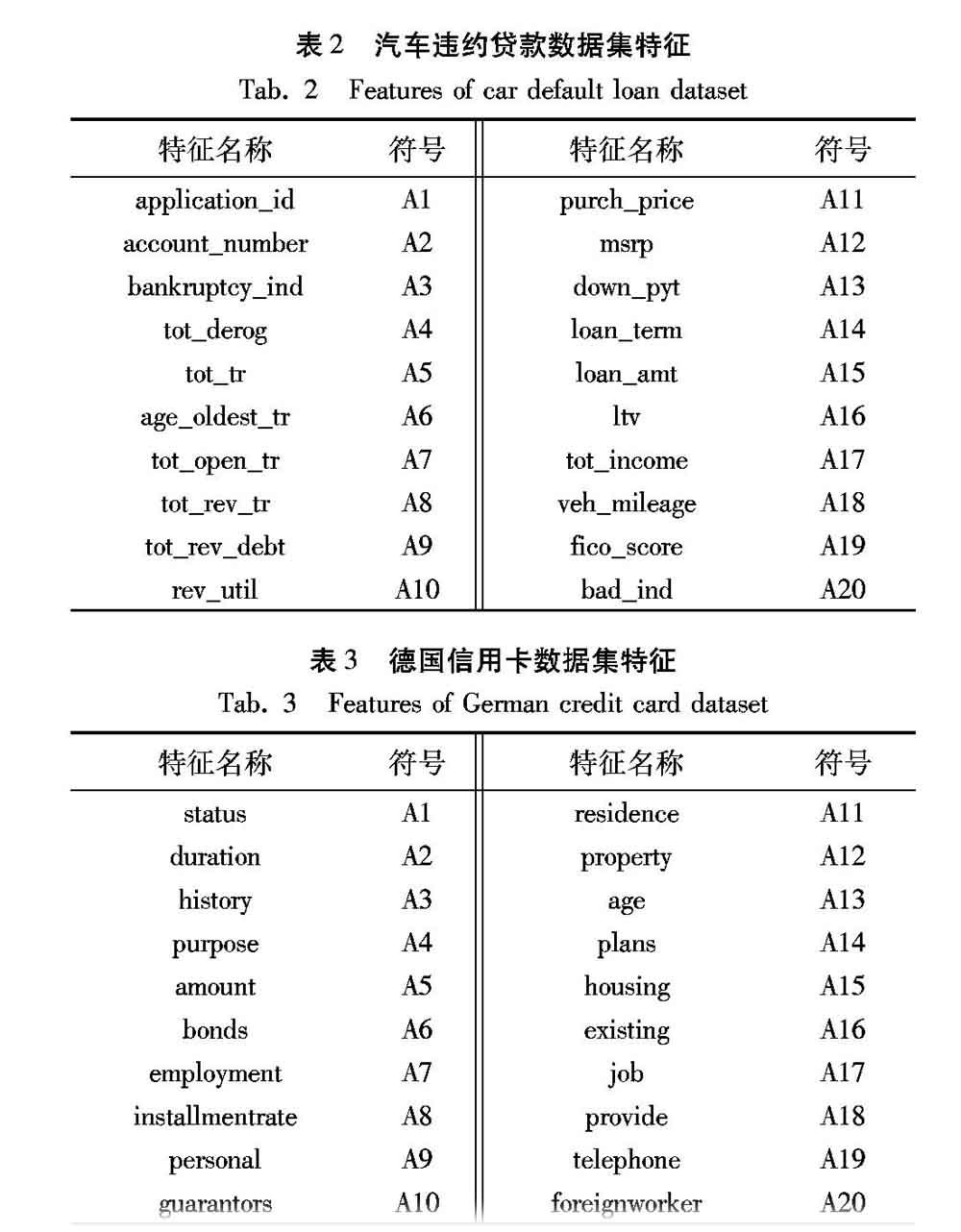
3)假設原始樣本的特征個數為D,從D個特征中隨機選擇其中的d個特征(d 4)每棵樹不斷分裂,直到該節點的所有訓練樣本都屬于同一類。這期間不需要剪枝處理。 5)K個CART相互獨立,其被賦予的權重均相等。對于分類問題,最終的分類結果使用所有的CART投票來確定最終分類結果;對于回歸問題,使用所有決策時輸出的均值來作為最終的輸出結果。 選擇隨機森林方法主要基于以下考慮:隨機森林方法作為一種集成學習方法相較于單一學習器有著優越的泛化性能。文獻[9]中,通過實驗分析對比可知,隨機森林方法的準確率和穩定性要優于支持向量機方法、k-近鄰方法、CART方法、基于徑向基的神經網絡方法和梯度提升決策樹(Gradient Boosting Decison Tree, GBDT)方法等。 本文所用的隨機森林算法是python的sklearn庫中封裝好的。隨機森林在sklearn的分類庫中所屬類是RandomForestClassifier,重要的調節參數如表1所示。 1.3 模型融合過程 在MWMOTE的實現過程中,構建了一個用來合成新樣本的少數類信息集Simin。然而,這個集合的所有樣本可能并不同等重要。一些樣本可能比其他樣本為數據提供更有用的信息,因此,有必要根據樣本的重要性為其分配權重。權重越大的樣本意味著需要從它附近產生許多合成樣品。MWMOTE所用到的選擇權重計算公式是鑒于三點觀察:接近決策邊界的樣本包含的信息比距離遠的樣本多;稀疏簇中的少數類樣本比稠密簇中的樣本更重要;在密集多數類群附近的少數類樣本比在稠密多數類群附近的樣本更重要。 2 實驗數據和評價指標 2.1 數據集 本文所用的是UCI KDD Archive提供的德國信用卡數據以及某公司提供的汽車違約貸款數據作為有信用記錄的樣本。汽車違約貸款數據含有5845個樣本,每一個樣本有19個連續變量、1個離散性變量。通過類別標簽劃分用戶,其中,4648個信用好的用戶、1197個信用差的用戶。按照4∶1的比例,本文選取793個信用好的用戶,207個信用差的用戶,共計1000個用戶樣本作為最終的實驗使用數據集。汽車違約貸款數據集的基本特征如表2所示。德國信用卡數據有1000個樣本,每一個樣本有7個連續型變量、13個離散型變量。類別標簽將樣本用戶進行區分,其中,700個信用好的樣本數據作為多數類,300個信用差的樣本數據作為少數類,是一個非平衡數據集。德國信用數據集的基礎特征如表3所示。 參考文獻[20]數據預處理的特征選擇,消除不相關和冗余的特征,最終實驗用的德國信用數據訓練集中,只選取{status,amount,duration,age,purpose,history,employment,bonds,property,installmentrate}作為最后的特征集,以達到提高分類精度和縮短訓練時間的目的。 2.2 評價指標 受測工作者特征曲線(Receiver Operating Characteristic Curve, ROC)作為公認的不平衡數據集分類器的評價標準,并不能定量評價分類器[21],因此本文采用AUC(Area Under Curve)值作為性能度量標準。AUC值被定義為ROC曲線下的面積。對于二分類問題,文獻[22]給出了計算式如下: 3 實驗和結果分析 為了提高實驗分析的準確性,本文采用多次隨機實驗進行驗證,將原始數據集劃分為訓練集和測試集,共進行100次實驗驗證。數據劃分情況如表4所示,模型相關參數如表5所示。 將實驗數據劃分出的測試集作為最終模型實驗分析對比所用的測試集。在實驗用的德國信用數據集的基礎上通過MWMOTE方法擴充200個少數類合成新樣本,在實驗用的汽車違約貸款數據集的基礎上通過MWMOTE方法擴充300個少數類合成新樣本以達到平衡數據集的目的,作為新的樣本數據集,其數據劃分標準和原始數據集一樣。在平衡數據集上訓練出的模型稱之為MWMOTE-RF,在原始數據集上訓練出的隨機森林模型稱為RF,樸素貝葉斯模型稱為NB。 除此之外,本文分別通過SMOTE方法,自適應綜合過采樣方法和Borderline-SMOTE方法對實驗數據進行處理,在各自產生的平衡數據集上訓練隨機森林模型,對應生成的模型分別稱之為SMOTE-RF、ADA-RF和BSMOTE-RF。 4 結語 為了提高不平衡數據中對可能存在的少數類樣本(違約客戶)的預測準確率,本文提出了一種基于MWMOTE和隨機森林結合的信用評估方法,改進了對違約客戶的信用評估分析預測能力。經過MWMOTE技術處理后,該方法有效解決了信用評估中不平衡數據集的問題,一定程度上解決了分類器向多數類類別樣本的傾向性問題。實驗結果表明,在處理后的平衡數據集上訓練的隨機森林模型,其AUC值有很大程度提升。但隨機森林和MWMOTE中的部分參數為人工設置,不一定是最優的模型參數,其次在高維和規模大的數據集上存在訓練效率低的問題,因此如何選取合理參數并提升模型訓練效率是下一步解決的問題。 參考文獻 (References) [1] WIN S. What are the possible future research directions for banks credit risk assessment research? A systematic review of literature [J]. International Economics and Economic Policy, 2018, 15(4): 743-759. [2] WIGINTON J C. A note on the comparison of logit and discriminant models of consumer credit behavior [J]. Journal of Financial and Quantitative Analysis, 1980, 15(3): 757-771. [3] DESAI V S, CROOK J N, JR OVERSTREET G A. A comparison of neural networks and linear scoring models in the credit union environment [J]. European Journal of Operational Research, 1996, 95(1):24-37. [4] BAESENS B, van GESTEL T, VIAENE S, et al. Benchmarking state-of-the-art classification algorithms for credit scoring [J]. Journal of the Operational Research Society, 2003, 54(6):627-635. [5] DAVIS S, ALBRIGHT T. An investigation of the effect of Balanced Scorecard implementation on financial performance [J]. Management Accounting Research, 2004, 15(2): 135-153. [6] 李志輝,李萌.我國商業銀行信用風險識別模型及其實證研究[J].經濟科學,2005(5):61-71.(LI Z H, LI M. Credit risk identification model of Chinese commercial banks and its empirical study [J]. Economic Science, 2005(5):61-71.) [7] 王春峰,趙欣,韓冬.基于改進蟻群算法的商業銀行信用風險評估方法[J].天津大學學報(社會科學版),2005,7(2):81-85.(WANG C F, ZHAO X, HAN D. A model on modified ants algorithm for credit risk assessment in commercial banks [J].Journal of Tianjin University (Social Sciences), 2005, 7(2): 81-85.) [8] 方匡南,吳見彬,朱建平,等.隨機森林方法研究綜述[J].統計與信息論壇,2011,26(3):32-38.(FANG K N, WU J B, ZHU J P, et al. A review of technologies on random forests [J]. Statistic & Information Forum, 2011, 26(3): 32-38.) [9] 蕭超武,蔡文學,黃曉宇,等.基于隨機森林的個人信用評估模型研究及實證分析[J].管理現代化,2014,34(6):111-113.(XIAO C W, CAI W X, HUANG X Y, et al. Research and empirical analysis of personal credit evaluation model based on random forest [J]. Modernization of Management, 2014, 34 (6): 111-113.) [10] 李進.基于隨機森林算法的綠色信貸信用風險評估研究[J].金融理論與實踐,2015(11):14-18.(LI J. Study on green-credit risk assessment based on random forest algorithm [J]. Financial Theory & Practice, 2015 (11): 14-18.) [11] 楊愛香.淺析我國商業銀行信貸風險管理的現狀及對策[J].時代金融,2015(30):37,39.(YANG A X. A brief analysis of Chinas commercial banks credit risk management status and countermeasures [J]. Times Finance, 2015(30): 37,39.) [12] 封化民,李明偉,侯曉蓮,等.基于SMOTE和GBDT的網絡入侵檢測方法研究[J].計算機應用研究,2017,34(12):3745-3748.(FENG H M, LI M W, HOU X L, et al. Study of network intrusion detection method based on SMOTE and GBDT [J]. Application Research of Computers, 2017, 34(12): 3745-3748.) [13] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique [J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321-357. [14] HE H B, BAI Y, GARCIA E A, et al. ADASYN: adaptive synthetic sampling approach for imbalanced learning [C] // Proceeding of the 2008 IEEE International Joint Conference on Neural Networks. Piscataway, NJ: IEEE, 2008: 1322-1328. [15] HAN H, WANG W Y, MAO B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning [C]// ICIC 2005: Proceedings of the 2005 International Conference on Advances in Intelligent Computing. Berlin: Springer, 2005: 878-887. [16] 趙楠,張小芳,張利軍.不平衡數據分類研究綜述[J].計算機科學,2018,45(6A):22-27,57.(ZHAO N, ZHANG X F, ZHANG L J. Overview of imbalanced data classification [J].Computer Science, 2018, 45(6A): 22-27,57.) [17] 沈學利,覃淑娟.基于SMOTE和深度信念網絡的異常檢測[J].計算機應用,2018,38(7):1941-1945.(SHEN X L, QIN S J. Anomaly detection based on synthetic minority oversampling technique and deep belief network [J]. Journal of Computer Applications, 2018, 38(7): 1941-1945.) [18] 王超學,張濤,馬春森.面向不平衡數據集的改進型SMOTE算法[J].計算機科學與探索,2014,8(6):727-734.(WANG C X, ZHANG T, MA C S. Improved SMOTE algorithm for imbalanced datasets [J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(6): 727-734.) [19] BARUA S, ISLAM M M, YAO X, et al. MWMOTE — Majority weighted minority oversampling technique for imbalanced data set learning [J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(2): 405-425. [20] 葉曉楓,魯亞會.基于隨機森林融合樸素貝葉斯的信用評估模型[J].數學的實踐與認識,2017,47(2):68-73.(YE X F, LU Y H. Credit assessment model based on random forest and navie bayes [J]. Mathematics in Practice and Theory, 2017, 47(2): 68-73.) [21] 李詒靖,郭海湘,李亞楠,等.一種基于Boosting的集成學習算法在不均衡數據中的分類[J].系統工程理論與實踐,2016,36(1):189-199.(LI Y J, GUO H X, LI Y N, et all. A boosting based ensemble learning algorithm in imbalanced data classification [J]. Systems Engineering — Theory & Practice, 2016, 36(1): 189-199) [22] HAND D J, TILL R J. A simple generalization of the area under the ROC curve for multiple class classification problems [J].Machine Learning, 2001, 45(2): 171-186 [23] 蔣帥.基于AUC的分類器性能評估問題研究[D].長春:吉林大學,2016:10-17.(JIANG S. Researches of performance evaluation of classifier based on AUC [D]. Changchun:Jilin University, 2016: 10-17.)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
