基礎架構大提升 解析ARM Neoverse N1和E1平臺
2019-08-30 00:00:00李實
微型計算機 2019年6期
關鍵詞:設計
李實

ARM近期發布的兩個全新平臺指向了新的市場,甚至有挑戰AMD和英特爾的可能。不過歷史上ARM多次試圖進入利潤率更高的服務器或計算市場,然而都鎩羽而歸,那么這一次ARM會成功嗎?新的平臺又有哪些特性呢?
在移動計算市場擁有領先地位的ARM,卻一直在桌面計算、服務器等對性能要求更高的市場中表現不佳。誠然在過去數年中,ARM不止一次對高性能領域發起沖擊,但結果并不理想。回頭來看,ARM主要缺乏的是一整套生態系統來適應不同場合下的計算需求。為了解決這個問題,ARM計劃設計一整套計算平臺,它能夠通過大幅提高ARM產品的性能從而獲得進入新市場的能力。
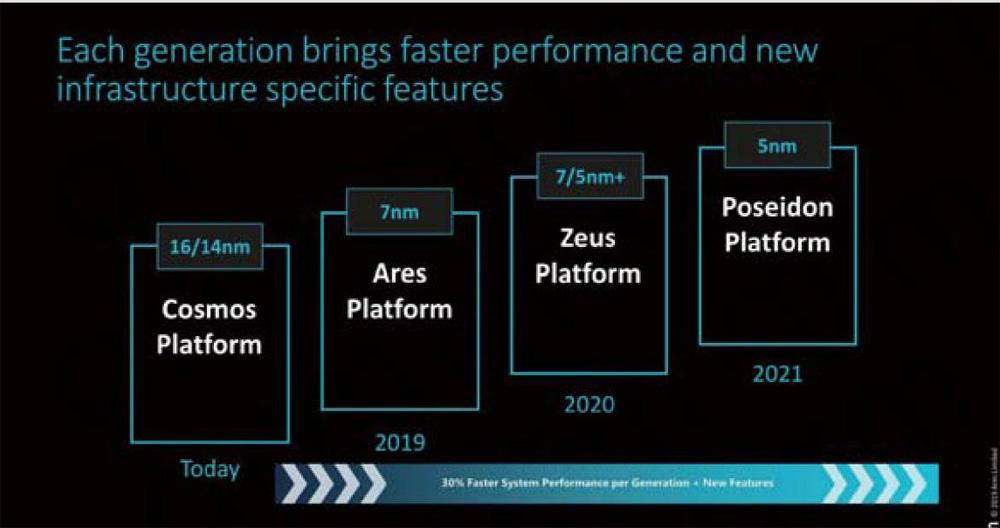
在近期的發布會上,ARM推出了2個全新平臺——Neoverse N1和Neoverse E1,這兩個平臺將成為未來幾年ARM Ares計算平臺的核心。所謂計算平臺是一種全新的提法,目前ARM規劃的以Cortex-A76為核心一整套產品被稱為Cosmos平臺,工藝采用14/16nm,2019年將進化至Ares平臺,工藝提升至7nm。2020年有zeus平臺,工藝提升到7/5nm+,2021年的Poseidon器。平臺包含處理器、總線、多核心系統等。Neoverse N1和相對應的處理器代表了ARM首款專為服務器和基礎設施市場設計的專用IP,這是對過去ARM在運營IP方案上的重大改變——消費市場和行業解決方案分離,面向消費市場以Cortex為主,面向行業客戶則由Neoverse披掛上陣。平臺將采用5nm工藝制造。今天我們的重點是Ares平臺。
Neoverse N1面向高性能設備,它是平臺名稱,與之對應的CPU核心架構名稱也一樣——Neoverse N1處理
Neoverse N1處理器淺析
首款Neoverse N1處理器的架構和Cortex-A76都是由ARM位于奧斯汀的設計團隊所主導,因此它們在內核設計上存在一定相似之處。這一部分本文不再贅述,而將重點放在對Neoverse
N1創新設計方面的介紹。
在Neoverse N1的設計目標上,ARM想讓它成為一個高性能架構,并擁有未來數年可重復使用的基礎。ARM將在這代處理器中重新調校微架構,使其能夠以最高頻率運行。在這—點上,ARM與AMD、英特爾的路線不同,后兩家面向高性能平臺的產品受制于功耗、面積等因素,頻率相比消費級產品更低,但是在ARM的設計中卻是相反的,處理器頻率可能更高。
Neoverse N1處理器的架構采用74發射讀取/解碼設計,流水線深度只有11級,ARM將其稱為“手風琴”管道。這種設計的特點是根據不同指令,流水線深度可以在運行延遲敏感型指令的時候將長度減少至9個階段,其中第二預測階段能夠和第一預測階段重合,并且調度階段能夠和第一個發布階段重疊。執行后端有2個簡單AIU,一個復雜的AIU用于計算乘法和除法,兩個全寬的128bit SIMD流水線用于處理矢量和浮點計算。在數據吞吐能力方面,ARM依舊設計了2個128位的加載/存儲單元,能夠維持足夠的帶寬來滿足流水線的需求。在前端,Neoverse N1擁有大型的低延遲L1和L2。ARM還采用分支預測設計和方向預測緩沖器,使得處理器不僅僅通過寬核心來提高性能,還可以通過最高效率的最小分支化和緩存的高效率來達到這個目的。在這些方面,它與Cortex-A76很類似。
Neoverse N1當然有著一些獨特設計,比如緩存設計上。它的L1數據緩存和指令緩存部分都是64KB、4-way設計,其中最重要的改變是整個緩存完全采用了一致性設計,它大幅度簡化了虛擬環境的實現并且極大地提高了性能。而且這一設計對ARM在超大規模計算中保持競爭力也是必須的,因為這可以很方便地擴展核心數量。ARM宣稱Neoverse N1處理器的架構可以應對核心數量超過16個的處理器設計方案,并具有良好的擴展l生。L2緩存方面,ARM提供了512KB或者1MB兩種選項。512KB的配置方案和傳統的Cortex-A76配置方案相當,而1MB緩存主要針對基礎架構領域中對存儲空間較為敏感的應用。需要注意的是,將緩存增加到1MB并不是沒有代價的,這種配置中緩存的延遲會提升2個周期,從而帶來一定程度的性能下降,考慮流水線延遲,使用這種配置方案時最大延遲可能會達到11個周期。
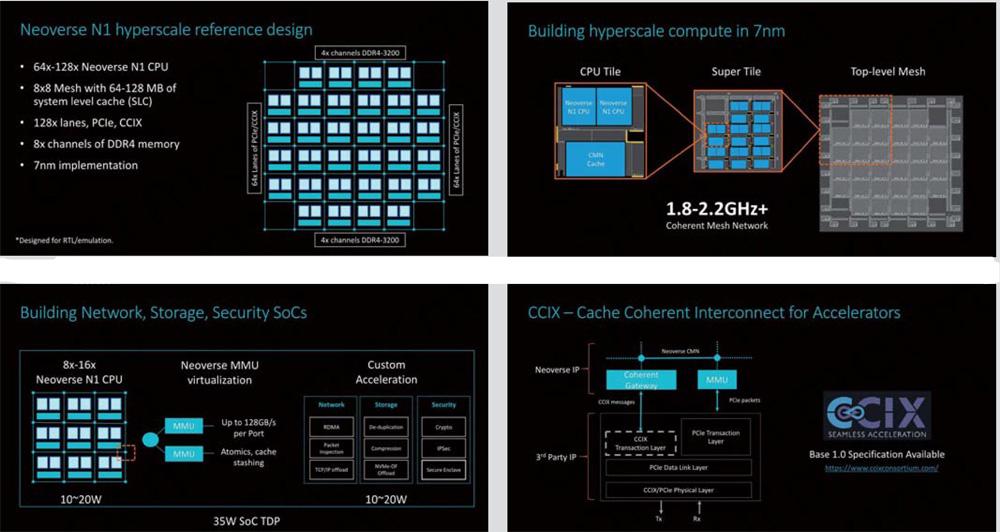
Neoverse N1和Cortex家族的根本差異來自于內存方案,前者采用網狀Mesh連接,而不是直接連接至CPu集群。這一點在cMN-600的網狀連接中已經有體現。這種連接首先通過CAI或者組件聚合層進行,每個CAI最多支持2個連接接口,這就是為什么ARM會為每個“集群”配置2個CPU核心(實際上并不是一個集群,只是為了滿足連接端口的需求)。然后CAI會連接到網絡的交叉點,它基本上是由網絡的交換機或者路由器構成。每個交叉點都有2個端口可用,A一個端口用于連接別的交叉點,剩余一個端口用于連接系統級高速緩存,也就是SLC。在64核心、32個區塊(每個區塊有2個CPu核心和具有2MB SLC)的系統中,整個64MB緩存的平均負載使用延遲為22ns。ARM以秒而不是常見的周期來顯示延遲的原因主要是因為SLC和通訊網絡運行在不同的時鐘頻率下,這個頻率通常為核心的2/3,和核心處于異步運行的狀態。
從Neoverse N1在核心連接架構上所體現出的功能來看,直接連接是新架構或者CMN-600總線所帶來的不可或缺的設計,這在之前的處理器上從未出現過。直連設計刪除了之前DSU上所有的通訊邏輯,轉而采用CPU核心直接連接到CMN的CHI接口。因此,存儲控制器和CPU之間也需要經過網狀網絡,而不是直連,這在桌面超多核心的設計中是比較常見的內容。考慮到ARM移動處理器背景,這種轉變幅度還是很大。
在這種新的架構中,內存控制器和CPU之間的數據存儲關系會有一些變化。當CPU向內存控制器發出數據請求時,CPu也會同時向后者發出一個預取類型的請求,這個請求會更早地抵達內存控制器。此時,正常的數據請求命令會通過監聽過濾器,開始向交叉主節點傳輸,然后交叉節點會將請求命令路由給內存控制器。由于預取的指令更為快捷,因此內存控制器將提前獲取請求即將到來并且有可能開始準備數據,從而隱藏部分存儲器延遲,而不是以串行的方式一步步獲取數據,這將帶來更高的延遲。預取設計方案將顯著影響系統性能,優秀的處理器設計方案會智能管理數據預取,以優化系統級帶寬。
在具有64個核心和8個DDR-3200內存通道的Neoverse N1參考系統中,其實現了高達175GB/s的DRAM帶寬。在LMBench測試結果的對比中,Corrtex-A72的延遲為110ns,Neoverse N1只有83ns,這個測試配置7256MB深度測試和2MB的大頁面緩存。大頁面的選擇減少了TLB未命中并且更接近實際的內存延遲,因此這個測試數據只代表某些情況下的延遲信息。與此類似的是AMD的EPYC 7610。采用LRDIMM DDR4-266619-19-19,相似場景的測試成績顯示延遲大約為73ns,DRAM負載應用大約為57ns。英特爾的W-3175X,采用RDIMM DDR-2666 24-19-19,相似場景下的測試大約為94ns和64ns。當然這里的測試無法和ARM的相關測試直接比較,但是了解一下延遲數量級和相對的場景,就能大概判斷ARM的設計處于一個什么層次。
另外一點是工藝和具體的實現,ARM給出了一些參考值,單Neoverse N1核心,所用工藝全部是TSMC 7nm的情況下,當采用512KB L2配置方案的時候,裸片尺寸為1.2平方毫米,和Cortex-A76基本相當,后者為1.26平方毫米。當L2緩存提升至1MB時,每個內核占位面積會提升至1.4平方毫米,面積依舊很小。
最后來看看頻率,ARM的預期是2.6GHz到3.1GHz,其中前者是0.75V電壓時所能實現的頻率,后者則采用71V驅動。值得注意的是,頻率提高19%會帶來44%的功耗提升,因此實際應用中會仔細調教,使得頻率盡可能接近功率曲線的極值。功耗方面,單核心依舊只有lW到1.8W。如此低的功耗為64核心的實現提供了充足的功率空間,64核心Neoverse N1自勺參考功耗僅為105W,隨后本文還會進一步討論這個問題。
采用Neoverse N1架構的超大規模處理器參考設計
之所以在一開始提到平臺有關內容,是因為ARM提供了一整套方案,包括超大規模處理器的參考設計方案,這在之前是從未出現過的。面對實際應用,ARM提供了三種選擇,一種就是本節需要詳細敘述的超大規模處理器方案,另外兩種分別是邊緣計算方案和另一種核心,也就是本文另一個主角Neoverse E1的邊緣設計方案。那么先來看第一個。
Neoverse N1的超大規模方案有64核心和128核心兩種配置,分別繼承了64MB或者128MB的SLC緩存,采用的是CMN-600網狀總線實現,這個配置還提供T128個通道可以用于PCI-E4.0或者CCIx接口用于提供足夠的I/O帶寬。內存控制器方面,ARM選擇的是8通道DDR4 3200方案。ARM實際上已經放棄了內存控制器的開發,因為客戶一般都會擁有自己的內部設計,或者從第三方供應商中選擇成熟IP。對于目前的參考設計而言,ARM給出的方案采用了DMC-520,如果未來使用更新的DDR5內存的話,可能又將引入第三方供應商了。
在具體的核心架構排布方面,ARM采用的是可復制的分層構建方案。具體來說,最基本的單元就是前文敘述過的CPU區塊,每個CPU區塊中包含T2個CPu內核和一個SLC緩存、CMN交叉節點和組節點的一部分構成。這個CPU區域可以通過不斷的復制生成一個超級區域,超級區域中還加入了部分I/0單元和內存控制器。然后超級區域通過不斷的鏡像復制或者翻轉復制,形成了一個CPU的Top級別的Mesh網絡系統,完成了整個超大規模處理器的構建。
這種基于Mesh的構建方法的一個顯著特色就是它可伸縮性能非常好。用戶可以根據情況來選擇配備核心數量,或者在其它情況下選擇處理器的搭配方案。舉例來說,當生產制造對面積較大的晶圓不夠友好時,比如64核心的處理器面積接近400平方毫米,此時廠商可以通過生產多個小芯片,再通過CCIX鏈路將這些小芯片連接在一起的方法實現處理器規模的擴展。當然,究竟如何做最終還是取決于應用人員和具體使用環境。另外,SmartNIC集成功能也是設計的重要方面,這個功能是實現最大化系統規模、加速網絡和實現高效吞吐的關鍵。
總線上的一些功能也有助于類處理器的實現,比如CMN-600的總線交叉端口上的MMU連接速度高達128GB/s,因此,附加固定功能的硬件單元將非常容易。此外,CCIX的出現也使得ARM能夠輕松組合第三方IP.為外部IP啟用高速緩存一致性是非常有吸引力的,因為它能夠大大簡化供應商的軟件設計。高速緩存一致性意味著軟件需要面對的就是一個巨大的內存塊,而不是非一致性下相關系統需要集成驅動程序并且跟蹤內存數據才能判斷哪個部分是有效的,這無疑大幅度降低了效率。
目前xilinx將成為首批在2019年第三季度推出支持CCIX的中端產品供應商之一,由于AMD也采用CCIX,因此第三方加速器的潛力非常巨大,可能出現之前完全不曾出現的搭配方案,令人充滿期待。
雖然這是面向高性能計算的產品,但是相應的功耗控制和電源管理還是能帶來效能的提升。ARM在設計時加入了專用的微控制器,能夠提供極細粒度的DVFS機制從而實現對頻率和電源的控制。有這個設計以后,供應商在電源方面就可以采用比較寬泛的方案,從而節約成本。
性能指標:超越,繼續超越
在擁有如此規模后,我們自然對這款處理器能達到怎樣的性能充滿了興趣。ARM首先展示了和相同頻率Cortex-A72處理器的性能對比,Neoverse N1在性能上實現了對前代處理器大幅度的超越。在單線程性能中,整數工作負載的每時鐘性能大約是前代產品的1.7倍和1.6倍,浮點性能則大幅度提升至Cortex-A72的2.2信和2倍。這里的數據來自于建模和仿真估計,考慮到軟件方面的改進,實際數值可能還會更高。計算n生能方面,Neoverse N1的矢量工作負載是Cortex-A72的2.2信,機器學習性能則達到了接近5倍,也就是4.7倍的數值。值得注意的是,Neove rse N1所采用的ARIv8.2 ISA意味著它支持8位點計算和半精度浮點指令,這些指令特別適合機器學習,因此性能能到巨大.的提升。
除了一些倍數上的比較外,ARM還給出了一些具體數字。比如2.6GHz,64核心的Neoverse N1處理器,ARM給出的SPECint2006單線程性能是37,多線程性能是1310,TDP功耗為105W,需要注意的是,這里的數據并不是實際運行SPECint2006而得來的,這是在帶有RTL仿真環境中的ARM服務器上估算而得到的數據。
除了硬件外,ARM還給出了一些軟件性能提升,尤其是編譯器。在過去的幾年,ARM花費了大量的精力在開源工具和編譯器上,比如GCC,最新的GCC9和之前老的GCC5相比,整數和浮點l生能的改進大約為13%-15%,值得注意的是,這里的改進是實際的改進,并不是測試成績的分數。
總的來看,ARM的新處理器在性能上的提升是非常巨大的,再加上多核心方面的優化,這有助于ARM在服務器市場實現自己的目標。
用于數據平面的小型STM核心:Neoverse E1
除了Neoverse N1外,ARM還發布了一個相對輕量的處理器核心,稱作Neoverse E1。從研發關系上來看,Neoverse E1實際上來自于Cortex-A65AE的深度改進,后者是一款定位于Cortex-A76AE之下的面向自動駕駛市場的處理器核心,因此兩者架構存在不少相似點。從定位上來看,NeoverseE1更注重高效性和經濟性。
SMT上陣:小而美的核心
很多人對SMT的認知來自英特爾超線程技術,其主要目的在于改善大型處理器的后端資源利用率,但SMT對小型處理器依舊有意義。一般來說,處理器在數據處理中,緩存未命中將主導處理器的工作周期。這是因為數據并沒有在處理器核心中停留很長時間。無論是在之前Cortex-A65AE的相關用例中描述的流式傳輸,還是在處理器工作負載的情況下,網絡數據傳輸的情況,都反映了處理器必須面對存儲器的訪問延遲,這才是引發CPU管線停頓的原因。
Neoverse E1處理器是一種帶有SMT的小型亂序設計方案。在數據平面繁重的工作負載中,引入處理器內核上的輔助線程實際上代表了微架構幾乎可實現免費的吞吐量增益,因為在這種情況下,微架構可以填充更多的執行周期。在最佳工作負載中,除了Neoverse E1本身微架構所能帶來的性能增益外,SMT甚至可能會帶來吞吐量翻倍。在集群級別,NeoverseE1的配置選項和之前DynamIQ系統中可以部署的配置非常相似,集群看起來像DSU,擁有最多8個內核,還包括偵聽過濾器以及4MB的L3緩存等。
Neoverse E1的管線設計
Neoverse E1采用了全新的設計方案,它更像是基于順序執行的C0rtex-A55微架構、通過深度調整而設計的小型亂序執行微架構。亂序執行是處理器非常重要的能力之一,它能夠避免負載周期很長的情況下停止整個流水線,從而使得核心能夠擁有更多的數據吞吐量大幅度提升。
Neoverse E1的指令獲取、解碼和分派單元都采用了雙發射設計,亂序窗口則設計了一個40深度的ROB。后端則和cortex-A55一樣采用了類似的執行單元方案和布局。不過NeoverseE1的整數AIU采用了不同的分區,一個用于簡單的算術運算,另一個則接管了整數乘法和除法。Neoverse E1的SIMD和NEO流水線和Cortex-A55幾乎完全一樣,不過ARM還是有可能改動一些指令循環以提高性能。
在SMT功能方面,Neoverse E1的SMT加倍了部分核心資源,這意味著CPU具有2信的通用、矢量和系統寄存器。在軟件級別,這樣的設計自然是作為2個獨立的CPU核心呈現,可以執行不同任務,處于不同的級別甚至執行不同的操作系統。
處理器前端,Neoverse E1帶來了一些顯著的改進,主要是分支預測和預取機制。近期ARM在其亂序執行架構上都采用了類似的改進。后端方面,前文提到了改進不大,實際上ARM在延遲方面做出了一些新的設計,比如FMAC的延遲減半、整數除法單元變成了Radix-16單元,還支持ARMv8.2所要求的雙吞吐模式的FPl6指令和int8點積等。
內存子系統方面和Cortex-A55則更為相似了,唯一質的變化的是數據預取器和L2 TLB為了配合SMT加入了多線程感知,并進行了一些設計上的優化。一些具體的數據包括,4-way的32KB或者64KB L1數據緩存,L2緩存可配置為64KB到256KB不等。L1延遲為2個周期,L2從讀取到使用為6個周期。
性能:更小、更強
Neoverse E1是從cortex-A55這樣的小心核心改進而來的產品,因此核心面積非常小,性能功耗比非常高。在7nm工藝下、32KB L1和128KBL2的配置方案下,Neoverse E1的CPu內核面積僅為0.46平方毫米,主頻可達2 5GHz同時功耗僅有183mW。其中最令人意外的是時鐘頻率,如此高的頻率顯示Neoverse E1在內核架構上做出的改進。
在ARM的設想中,Neoverse E1這樣的處理器將用于對功耗敏感的邊緣應用中。在一些低端設備中,擁有8-16個核心的Neoverse E1處理器將用于無線接入或者網關數據計算,提供10-25Gbps的數據吞吐量。更高一些的層級上,可能會有16-32核心的Neoverse E1處理器用在諸如邊緣數據聚合等場景,實現1006bps的數據吞吐。
ARM給出了可能是市場上最受歡迎的16核心Neoverse E1的設計參考方案,依舊采用了CMN-600的2X4網絡配置,其中集成T8個核心,另外還允許自選系統緩存以及配置額外的第三方加速核心。內存方面配置方案是雙通道DDR4。
性能和功耗方面,根據ARM的數據,類似配置的Neoverse E1的SoC功耗不高于15W,CPU內核的實際功率不高于4W,SPECinte_rate2006成績大約為153分,系統吞吐能力大約為25Gb/s(僅為軟件層啟動,未使用硬件加速),處理器的性能還是相當值得期待的。同之前的Cortex-A53或者Cortex-A55相比,Neoverse E1的吞吐量也有顯著優勢,這些都意味著效率的大幅度提升。
ARM展示Neoverse N1芯片和開發平臺
ARM也給出了有關Neoverse N1的開發平臺。在發布會上,ARM還回顧了自己幫助開發人員的一些歷史,包括cortex-A57、Cortex-A72等產品都推出了相應的開發平臺,并且一共向合作伙伴提供了大約1400張開發板用于各種設計驗證。一般來說,這種開發版的芯片產量較低,往往使用MPW技術實現,即使如此,芯片生產和制造的成本也會由于較低的數量而變得很高,投入往往非常巨大。
ARM在2018年12月收到了首個可用的Neoverse N1的芯片,并提供了一整套SDP系統開發平臺方案。這不但是ARM首個7nm工藝的芯片,還附帶了大量的第三方知識產權,包括PCIe以及DDR內存控制器等。
ARM展示了這款開發平臺的大量信息。包括一個四核心的NeoverseN1處理器,1MBL2配置,采用2XMP2的方案,CMN-600總線連接等。此外還包含一個PCIe 4.0 x16插槽,支持高速緩存一致性等關鍵特性。
ARM:生態系統加強
從ARM對于Neoverse N1和Neoverse E1的研發和推進不難看出,它希望通過有技術含量、性能出色的產品以及更為完整、易用的研發平臺,來吸引更多行業內用戶的注意,從而進一步拓寬自己的市場空間。
從技術上來看,Neoverse N1性能出色、擴展能力強悍并且能耗比表現非常出色,ARM認為它有希望從英特爾、AMD掌控的高端服務器市場中搶走一部分份額,尤其是那些對多核心要求更多的場合。對Neoverse E1而言,ARM瞄準的是不斷擴大的高吞吐處理器市場,包括即將到來的5G市場等,這相當于是為這些應用場合專門定制了一款高性能功耗比的處理器產品。
除了強悍的處理器外,ARM本次更為注重生態環境的建設了。無論是和業內其他供應商聯合打包IP的方案,還是自己提供了大量的開發板和相關技術指南,ARM都在努力構建一個更為容易接觸和更為開放的產業環境。考慮到ARM的新產品在未來12~18個月內就要進行商業部署了,我們應該能夠在1-2年的時間看到這些變化,擁抱開放和生態,行業也應該給出更為積極的反饋。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
