網絡輿情監測系統的分析與設計
2019-09-04 10:00:46洪小娟宗江燕于建坤黃衛東
軟件工程 2019年8期
洪小娟 宗江燕 于建坤 黃衛東
摘? 要:大數據時代下,網絡輿情監測對政府合理控制輿情方向、進行輿情治理具有重要意義。網絡輿情監測系統主要根據網絡輿情需求,構建在.NET平臺下基于Entity Framework模型的網絡輿情監測系統的C/S和B/S框架體系。系統對信息采集、信息過濾、關鍵詞挖掘、輿情主題分類等模塊進行優化分析設計和實現。應用馬爾可夫模型,將輿情發展態勢劃分為生成期、發展期、極速發展期和衰退期,通過對歷史數據的計算實現了輿情的未來發展區間。
關鍵詞:輿情監測;網頁文本分析;網絡爬蟲;輿情預警;預測
中圖分類號:TP399? ? ?文獻標識碼:A
Abstract:Under the era of big data,network public opinion monitoring is of great significance for governments to reasonably control the public opinion direction and public opinion governance.To meet the requirements in the network public opinion,the network public opinion monitoring system mainly constructs the C/S and B/S framework system of the network public opinion monitoring system based on the Entity Framework model under the .NET platform.The system optimizes the analysis and design of modules such as information collection,information filtering,keyword mining,and lyric topic classification.The Markov model is applied to the system to divide the development situation of the public opinion into the generation period,the development period,the rapid development period and the recession period.The calculation of the historical data realizes the future development range of the public opinion.
Keywords:public opinion monitoring;web page text analysis;web crawler;public opinion warning;prediction
1? ?引言(Introduction)
互聯網作為一種新的信息傳播形式迅速發展,對人們的日常生活產生了巨大影響[1],已然引起學術界的廣泛關注,目前研究方向包括網絡輿論的傳播、控制及相關問題[2,3]。據《中國互聯網絡發展統計報告》顯示,截至2018年上半年,我國網民數量已達8.02億人[4],互聯網已被公認為是繼報紙、廣播、電視之后能夠反映社會輿情的重要載體之一[5]。此外,超過六成的中國網民經常在網上就各種話題發表言論并進行討論[6],以充分表達自身的思想觀點和利益訴求。
由于網絡中的輿情在一定程度上能夠代表現實世界中人們的觀點,并且對現實世界的穩定產生一定的影響,因此如何才能監測和發現網絡輿情,為政府或者企業提供決策上的數據支持成為輿情問題研究的一個重要課題,本文旨在通過對網絡爬蟲、中文分詞、信息存儲方式、馬爾可夫模型等的研究,來實現一個可以及時、準確的輿情監測和預測系統,為相關領域的工作人員提供數據上的支持。
2 網絡輿情監測系統需求分析(Requirements analysis of the network public opinion monitoring system)
運用互聯網平臺進行交流具有匿名、及時、參與程度廣、影響面寬、破壞面大等特點,這些特點給輿情監督的工作人員帶來了極大的困難和挑戰。因此,國內外普遍重視輿情監測關鍵技術的研究,目前,輿情監測涉及的技術非常多,其核心多為網絡信息抓取技術、網絡信息提取技術、自然語言處理技術。其中,網絡信息抓取技術多指利用網絡爬蟲工具進行信息抓取工作[7];網絡信息提取技術則指將文本里的信息進行結構化處理,多被處理為表格形式[8];自然語言處理技術主要研究人與計算機交互的語言問題,通過分詞、關鍵詞提取等一系列操作對輿情狀況進行分析,從而達到輿情監測的目的。
國內對網絡輿情的監測起步較晚,又由于中西文的差異造成中文分詞技術、文本挖掘技術等許多先進技術無法借鑒,同時研究機構與應用機構又嚴重脫節,直接導致我國的輿情產品比較昂貴同時發展也較為遲緩。不過,隨著電子計算機和互聯網絡在中國的普及,網絡輿情對社會生活的影響越來越大,網絡輿情監控的產品也越來越多,其中以網智天元、北大方正、西盈信息、人民網輿情為代表的軟件公司紛紛推出了自己的產品,并且都實現了24小時實時監控、關鍵詞監測設置、輿情分析報告等基本功能。雖然國內的軟件可以完成對網絡輿情的監測任務,并且提供完整的分析報告,但是還沒有提供對于輿情事件的趨勢預測功能。
3? 網絡輿情監測系統概要設計(Overview of network public opinion monitoring system)
3.1? ?系統總體功能介紹
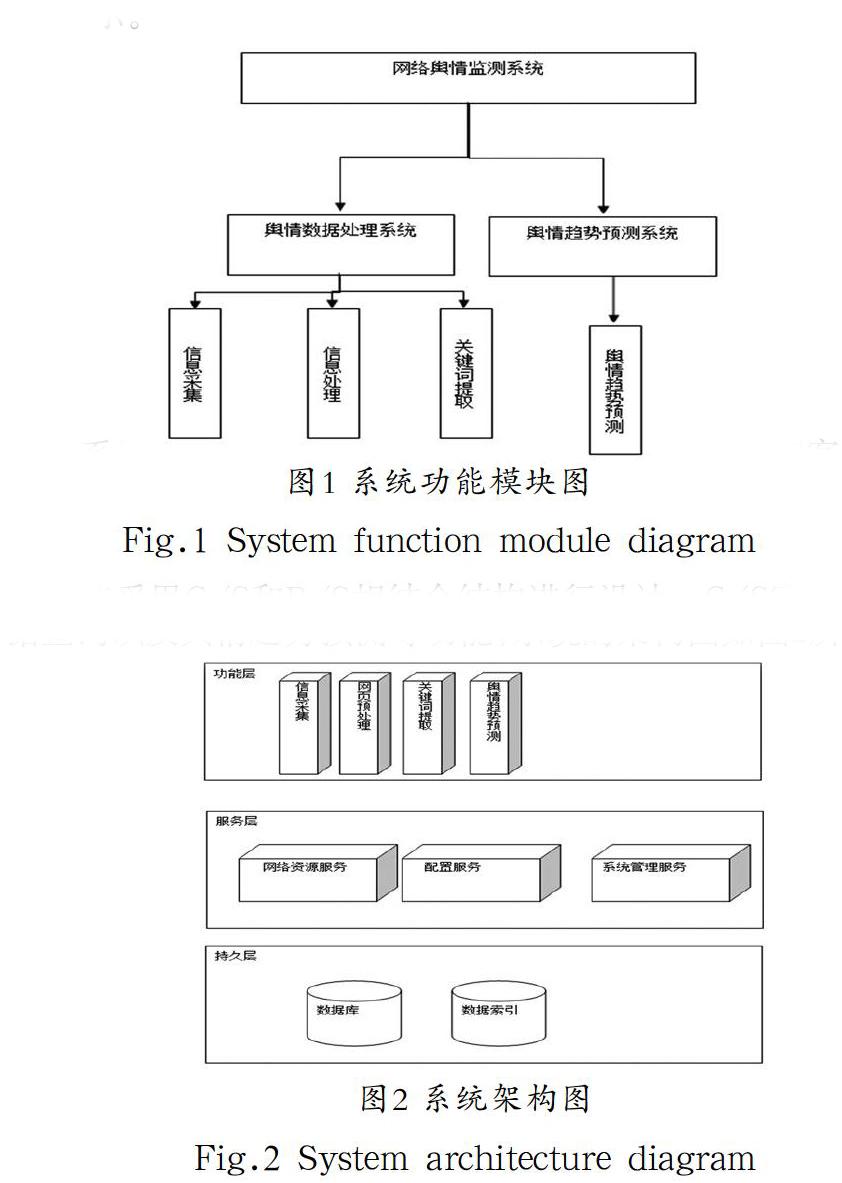
網絡輿情監測系統主要由輿情數據處理系統和輿情趨勢預測系統兩個部分組成,在輿情數據處理系統中,又包括信息采集、信息處理、關鍵詞提取等模塊。系統的功能模塊圖如圖1所示。
系統采用C/S和B/S相結合結構進行設計,C/S客戶端主要負責自動采集指定網站上的信息,并且對信息進行過濾和分析,最后對信息進行存儲;B/S系統主要用于數據展現、數據查詢以及輿情趨勢預測等功能,系統的架構圖如圖2所示。
3.2? ?系統數據流程圖
系統的數據流來自采集模塊,從自定義的采集網站中開始采集網絡信息,采集的結果直接通過信息過濾模塊,將用戶所需信息從采集的網頁源代碼中分離出來,保存到本地數據庫。隨后,關鍵詞提取模塊讀取采集信息的正文,利用中科院的ICTCLAS 2013版分詞系統提取正文信息中的關鍵詞及關鍵詞在文本中權重,并將其保存到數據庫中,系統的數據流圖如圖3所示。
4? 網絡輿情監系統關鍵模塊的設計與實現(Design and implementation of the key modules in the network public opinion monitoring system)
網絡輿情監測系統主要分為兩大部分,即輿情數據處理系統以及數據查詢顯示系統。其中輿情數據處理系統又包括信息采集、信息處理、趨勢預測等三個主要模塊。該系統主要用于數據的采集分析與處理,為用戶提供有效的輿情信息。數據查詢顯示系統主要用于信息查詢與趨勢預測。該系統主要為用戶提供輿情信息、輿情分析統計,以及輿情趨勢判斷等功能。其中,信息采集、信息處理、趨勢預測也是網絡輿情監測系統中的重點與難點。
信息采集模塊的實現步驟如下:
Step1:在數據庫中準備好需要抓取信息的網站的URL地址,并且配置好每個網站中的信息過濾規則。
Step2:根據用戶預設的采集空間信息,初始化信息采集模型,并且通過該采集模型,對URL地址列表進行循環采集,下載當前頁面的HTML代碼到本地,然后由HTML解析模型進行數據解析。
Step3:在HTML解析過程中,將網頁的HTML代碼根據相應的網站信息過濾規則進行解析,并且將有效的信息保存到本地數據庫中。
Step4:循環上述過程,24*7小時執行數據采集的過程,保持采集的數據的及時性。
信息處理模塊的實現步驟如下:
Step1:系統讀取數據庫中為被處理的帖子的信息。
Step2:利用中科院的ICTCLAS 2013分詞系統,提取出文本中的關鍵詞,以及關鍵詞所占有的權重。
Step3:將關鍵詞信息保存到數據庫中,并且以此作為相應帖子的內容標簽。
趨勢預測模塊的實現步驟如下:
Step1:將熱度趨勢劃分為四個狀態區間,大于0的分為兩個區間, =急速上升, =緩慢上升,小于0的也分為兩個區間 =緩慢下降, =快速下降。
Step2:統計出熱度趨勢值從當前狀態到下一刻狀態的數目。
Step3:計算初始狀態概率向量以及轉移矩陣,預測對象在任何一個時期處于任何一個狀態的概率。
5? 網絡輿情監測系統的測試(Testing of the network public opinion monitoring system)
網絡輿情監測系統的測試主要分為功能測試和性能測試。功能測試中,主要對系統的UI界面操作,以及查詢顯示功能進行測試,確保系統能夠給用戶提供簡潔、準確的數據以及良好的用戶體驗。性能測試主要對系統的輿情主體分類和輿情趨勢預測的準確性進行測試,測試的結果表明,本系統可以準確地對信息進行輿情事件的劃分和對輿情趨勢進行預測。
系統包括首頁、輿情監測、輿情管理、輿情站點這四個欄目,涵蓋了系統需求部分所提及的所有功能。主頁為用戶提供了關鍵詞搜索界面,用戶在搜索的文本框中,輸入想要監測的輿情的關鍵詞,并且選擇想要監測的時間段和監測的網站范圍,就可以得到與關鍵詞相關的帖子數量日均變化圖、帖子熱度日均變化圖、帖子各站點比例圖,以及帖子在未來一段時間內的趨勢預測,搜索的結果頁面如圖4至圖6所示。
6? ?結論(Conclusion)
綜觀本文的研究過程和結果,存在以下幾點不足與改進:
(1)在輿情趨勢預測方面,通過將馬爾可夫模型運用到輿情監測的機制當中,有效地對大區間內的輿情事件趨勢進行了預測。
(2)在輿情數據獲取方面,系統所建立的規則不僅可以對單個論壇使用,而是可以應用于多個論壇當中,保證了系統所監測的論壇的普遍性。
(3)信息處理過程未詳細研究,只是借鑒了中科院的ICTCLAS分詞系統,對中文分詞等過程及方法還需要進一步的分析和研究。
(4)由于時間倉促,本文對于輿情信息傾向性分析,時候評估分析等技術及應用未進行深入研究。
根據本文總結的改進之處和不足,本課題展望如下:
通過實驗論證,系統可以進一步完善中文分詞模塊;對于本文未深入研究的技術和應用,將進行進一步的研究,旨在全面提高網絡輿情監測系統的準確性、合理性以及實用性,為輿情監測領域提供優秀的技術平臺。
參考文獻(References)
[1] ZHANG Le-jun,TONG Wang,JIN Zi-long,et al.The research on social networks public opinion propagation influence models and its controllability[J].中國通信,2018,15(07):98-110.
[2] WANG Qi-yao,JIN Yue-hui,ZHEN Lin,et al.Influence maximization in social networks under an Independent cascade-based model[J].Physica a:Statistical Mechanics and Its Applications,2016(444):20-34.
[3] FEI Xiong,YUN Liu,CHENG Jun-jun.Modeling and predicting opinion formation with trust propagation in online social networks[J].Communications in Nonlinear Science and Numerical Simulation,2017(44):513-524.
[4] 李朋朋,李英武.“互聯網+”背景下降低員工網絡閑散行為的思考[J].決策探索(下),2019(01):87.
[5] 尉譯心.網絡輿情監控系統的關鍵技術[J].電子技術與軟件工程,2018(07):26-27.
[6] 楊華.網絡言論失范與政府管理[J].采寫編,2011(05):54-56.
[7] 胡亞楠.社交網絡數據獲取技術與實現[D].哈爾濱工業大學,2011.
[8] 程楠.一種基于大數據技術快速處理醫療文本的方法[J].中國數字醫學,2017,12(09)45-46;58.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
第一財經(2021年6期)2021-06-10 13:19:08
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
Coco薇(2017年9期)2017-09-07 21:23:49
中華手工(2017年2期)2017-06-06 23:00:31
紡織服裝流行趨勢展望(2016年2期)2016-05-04 03:47:15
汽車科技(2015年1期)2015-02-28 12:14:44
中外會展(2014年4期)2014-11-27 07:46:46
