網絡社區劃分在軟件質量問題分析中的應用
2019-09-09 03:38:40胡學飛李增揚
小型微型計算機系統 2019年9期
胡學飛,李 兵,2,李增揚
1(武漢大學 計算機學院,武漢 430072)2(武漢大學 復雜網絡研究中心,武漢 430072)3(華中師范大學 計算機學院,武漢 430079) E-mail:huxuefei@whu.edu.cn
1 引 言
計算機行業的快速發展使得軟件工程受到越來越多的關注,軟件系統也變得更加復雜.在如今信息化的時代,隨著人們對軟件的依賴程度不斷增加,提出的功能點也變得多樣,相應的軟件系統必須不斷的升級或者打補丁來滿足需求,相應的對代碼的質量、整個軟件的架構和安全性都有更高的標準,這都大大的增加了軟件系統的復雜性[1].如何對這些復雜系統進行研究,幫助其更好的發展顯得愈發重要.
20世紀90年代,復雜系統成為了一門獨立學科,90年代末,為了研究復雜系統,產生了復雜網絡[2].復雜系統可以看作是由大量的有關聯的子系統構成,我們如果把子系統視為結點,把它們之間的作用視為邊,那么復雜系統就可以看成是一個復雜網絡.1998年,在復雜網絡的領域中,Watts和Strogatz提出了小世界網絡(Small World Network,簡稱SWN)模型[3].1999年,Barabási和Albert又提出了無標度特征[4,5].無數學者投入到復雜網絡理論的研究之中,大大促進了其發展.
復雜網絡研究具有很強的跨學科特色,它可以與數理學科、生命學科和工程學科等其他學科聯系起來,成為其他領域的研究方法[6].因此,復雜網絡研究作為一個新興的研究領域,受到格外的關注.同樣,復雜網絡理論研究給軟件工程研究也打開了新思路.以復雜網絡理論作為基礎,將軟件中的源文件看作節點,文件之間的關系看作邊,軟件系統則視為節點和邊的集合,對軟件系統結構的研究就轉化為對其網絡圖的研究[7-9].
軟件項目開發的過程中,由于軟件故障或新功能需求,開發人員會對源文件不斷地修改,并將這些修改提交到版本控制系統.通常,一次提交(commit)包括源文件的增加、刪除和修改,這些信息被保存在版本控制系統中.軟件項目源文件之間的引用調用數量可視為源文件間依賴(dependency)的強度,軟件開發的提交信息中源文件被同時修改(co-change)的次數視為其被同時修改的頻度.已有研究發現在Windows 7中,具有依賴關系的源文件更容易被同時修改[10,11],我們希望通過實驗證實在開源軟件中也存在這個規律,即依賴關系的強度和它們的同時修改的頻度具有一致性.如果存在同時大量被修改的源文件不存在依賴關系,我們發現其中往往有問題,這些問題會導致整個項目質量的降低.所以,我們通過不符合一致性的源文件進一步探索其中存在的問題.
復雜網絡理論研究給我們提供了很好的方法.對于一個軟件系統,將文件視為點,文件之間的關系視為邊,關系的強弱視為邊權,復雜的軟件系統就可以用加權網絡來表示.我們分別根據兩源文件的依賴和同時修改關系,構建依賴關系網絡(dependency network)和同時修改關系網絡(co-change network).使用了Girvan-Newman算法[12](GN算法)對軟件的依賴關系網絡和同時修改關系網絡進行了社區劃分.我們猜想根據兩種關系劃分出來的結果會表現出一致性,對于成功優秀的項目,實驗結果證實了我們的猜想,而對于質量較低的項目則結果不理想,我們對有出入的地方進行分析,找出不一致源文件出現的原因,如代碼的復制粘貼、混亂的引用等,給軟件中問題的發現方法提供新思路.
本文的組織結構如下:第2節我們將具體的介紹實驗的方法,對實驗中的項目選擇、數據收集和處理、實驗過程等做詳細的說明;第3節,給出實驗結果,驗證猜想并分析出現不一致的原因;第4節,對實驗和未來的工作進行討論;第5節,得出結論.
2 研究設計
本節闡述了本文的研究目的,并根據研究目的提出研究問題,設計分析項目中源文件的依賴關系和其同時修改關系一致性的研究過程.
2.1 研究目的和研究問題
本文的研究目的是用復雜網絡理論的方法,證明項目中源文件依賴關系和其同時修改關系具有一致性,并通過不符合一致性的源文件發現其中存在的問題.基于該研究目標,我們定義以下研究問題(Research Question,簡稱RQ):
RQ1:項目中源文件之間的依賴關系和同時修改關系是否存在一致性?
通過此研究問題,我們希望驗證我們提出的兩種關系存在一致性的猜想.為進一步研究奠定基礎.
RQ2:出現源文件依賴關系和同時修改關系不一致現象的項目可能存在哪些問題?
通過此研究問題,我們希望從兩種關系不一致的項目中發現可能存在的問題.發現一種新的項目問題的識別方法.
2.2 實驗設計
為了得到研究問題的答案,我們設計本次實驗分為四個階段,分別是數據收集、數據處理、源文件劃分、實驗結果分析.具體流程見圖1.

圖1 實驗流程圖Fig.1 Experiment procedure
A:數據收集
此次實驗研究對象是Java項目,僅僅分析Java源文件,忽略其他類型的源文件.近些年來網站和各種企業管理系統快速發展,Java作為開發此類項目的流行語言受到越來越多的關注,并且應用范圍越來越廣,再者,關于Java的分析工具比較成熟,所以我們選擇了Java項目.
軟件項目源文件之間的引用調用數量可視為源文件間依賴的強度,如文件A中有2處引用了文件B中的類,我們就認為文件A與文件B之間存在依賴關系,并且依賴強度為2.為了研究項目源文件的依賴關系,我們使用靜態項目分析軟件Understand(http://understand-china.com),它集成了代碼編輯器,能將分析結果以各種形式呈現給用戶.借助Understand,將項目代碼導入后可以方便地獲取到源文件之間依賴關系的相關數據.
為了研究項目中源文件的同時修改關系,我們在GitHub上獲得項目的代碼及其提交日志.通過Git版本控制系統的源客戶端TortoiseGit我們可以下載項目的全部代碼,并得到開發過程的提交日志.
B:數據處理
借助Understand工具,很方便能導出源文件的依賴關系.我們開發了一個工具從Understand導出的Excel文件中提取出兩文件名和總依賴數.最后得到的是項目中每兩個有依賴關系的源文件名稱及其調用引用的數目,即源文件名A,源文件名B,調用引用數目x.
軟件項目源文件之間的同時修改關系要對項目開發過程中的提交日志進行數據處理.在項目的提交日志中,每兩個在同一個提交記錄中增加或者修改的源文件都被認為是同時修改,其他情況,如刪除或者修改版本號則不視為修改.我們計算每兩個源文件在所有提交記錄中同時修改的次數.得到的是每兩個有同時修改關系的源文件名稱及其同時修改的次數,即源文件名A,源文件名B,同時修改次數x.圖2中,我們會得到如下三條記錄:A.java,B.java,1;A.java,C.java,1;B.java,C.java,2.
需要指出的是,在數據中存在大量同時修改次數很少的記錄,它們產生的原因主要是項目一次提交中提交了大量源文件的修改信息,其中存在沒有任何關系的源文件也被同時提交.在后續的實驗中進行了社區劃分,經過對衡量網絡中社區穩定度的模塊化度量值Q[12,13]的計算,我們發現這種數據對源文件的劃分的準確性產生了很大的影響,即Q值很低,這些數據也極大的影響了數據處理的速度,所以我們嘗試著去除掉次數較少的數據使社區比較穩定,即Q值大于0.5.經過不斷試驗,對于我們研究的幾個項目中,去掉次數小于3的數據能使Q值大于0.5,數據的處理速度也在可以接受的范圍.我們刪除了次數小于3的數據,但是這種處理也對實驗結果造成一定的影響.

圖2 同時修改數據處理說明附圖Fig.2 co-change data processing
在源文件劃分階段,我們開發了一個程序進行數據處理,程序輸入為數字格式而不是文本格式.為了讓數據符合下一步劃分所使用程序的輸入格式,我們需要將項目中的文件進行編號,并記錄下源文件名和數字編號的對應關系,然后將依賴關系數據和同時修改數據中的源文件名稱都改為相應的編號.此步驟結束后,我們會得到均為數字的依賴關系數據和同時修改數據,還有兩數據共用的一份源文件名與編號對應表.
C:源文件劃分
社區結構是復雜網絡的一個特性,整個網絡是由很多社區組成的,社區中的結點聯系很緊密,社區之間的聯系比較少.為了比較兩個網絡,我們將問題轉化為社區的比較,因為如果兩種關系具有一致性,社區劃分也會具有一致性,通過社區比較,可以發現關系不一致的地方.我們使用了GN算法對軟件的依賴關系網絡和同時修改關系網絡進行了社區劃分.
GN算法最初由Michelle Girvan和Mark Newman提出[12],是經典的社團發現算法,屬于分裂的層次聚類算法,常用于研究復雜網絡中的聚類特性.該算法根據網絡中社團內部高內聚、社團之間低內聚的特點,逐步去除社團之間的邊,取得相對內聚的社團結構.算法用邊介數的概念來探測邊的位置[13],某邊的邊介數定義為網絡上所有頂點之間的最短路徑通過該邊的次數.由定義可知,如果一條邊連接兩個社團,那么這兩個社團節點之間的最短路徑通過該邊的次數就會最多,相應的邊介數最大.如果刪除該邊,那么兩個社團就會分割開.GN算法就是基于此思想反復計算當前網絡的最短路徑,計算每條邊的邊介數,刪除邊介數最大的邊.最后在一定條件下,算法停止,即可得到網絡的社團結構,網絡中社區穩定度用模塊化度量值Q衡量[13].
我們將源文件視為節點,它們之間的依賴關系,同時修改關系作為兩源文件的邊,軟件系統可以視為復雜網絡,這里用依賴網絡和同時修改網絡來命名根據兩種關系形成的復雜網絡.將依賴關系數據和同時修改數據作為GN算法的輸入,對兩種網絡進行劃分.得到的是根據兩種關系得到的兩種網絡社區劃分結果.
D:實驗結果分析
為了幫助分析依賴關系網絡和同時修改關系網絡,我們定義了兩個概念:關系簇和奇異點.
1.關系簇(relation cluster)定義為:
在同一個軟件系統中,一部分源文件無論在依賴關系網絡中還是同時修改關系網絡中都被分進同一個社區,這部分源文件被稱為一個關系簇.
2.奇異點(strange node)定義為:
在依賴關系網絡中或者是同時修改關系網絡中,如果存在某個文件不屬于當前社區中任何一個關系簇,則稱這個文件為奇異點.
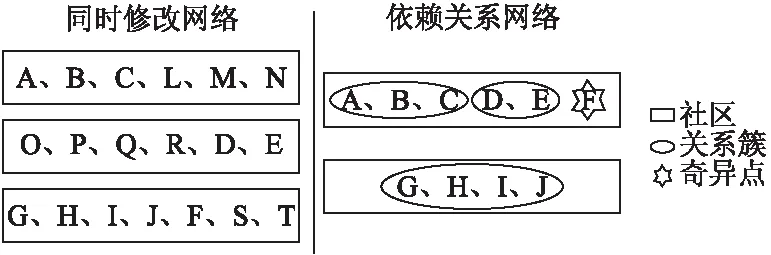
圖3 關系簇和奇異點概念圖Fig.3 Concept graphs of relation clusters and strange points
圖3中,A、B、C三個點在兩個網絡中都被分在一個社區中,因此,它們組成一個關系簇,而F不屬于依賴關系網絡社區1中任何一個關系簇,所以F為奇異點.我們對每個社區計算它的總節點數,關系簇數和奇異點數.如果存在奇異點,它對應的源文件可能指示質量問題,我們將對奇異點出現的原因做仔細的探究.
3 實驗結果
軟件項目數目龐大,質量參差不齊.為了更好的研究源文件依賴關系及其同時修改關系的一致性,我們選取了評價較好,關注度高的項目Tomcat_9_0_0_M21(https://codeload.github.com/apache/tomcat/zip/TOMCAT_9_0_0_M21),截取2006年3月27日至2017年5月5日的提交信息進行研究.為了尋找項目的源文件中兩種關系不一致情況下可能存在的問題,我們選取了Tomcat(https://github.com/apache/tomcat)早期版本,即2013年7月2日之前的版本,和評價次數較少,關注度較低的Restunit(https://github.com/davetron5000/restunit)項目,更新截止時間為2008年12月21日.
每一個項目供實驗使用的數據首先包括項目文件名稱與編號對應表,其次,根據兩文件之間的依賴關系和實際關聯,分別得到的依賴關系表和實際關聯表,格式均為“文件編號1,文件編號2,強度”,最后是根據兩種關系的劃分結果數據,每一行為一個社區,社區以文件編號組成.具體數據我們提交至github(https://github.com/huxuefei/hu.git)上.
3.1 軟件項目中源文件的依賴關系和其實際關聯存在一致性(RQ1)
表1是tomcat根據同時修改劃分的實驗結果.其中,有一部分社區有相同的總節點數,關系簇數,奇異點數,因此我們把這些社區表示在同一行.例如,表1第一列的17-21表示社區編號在17至21之間的所有社區.對于項目Tomcat的實驗結果,我們從表1可以看出,根據同時修改劃分的每一社區中的源文件之間大部分是有依賴的,這在一方面證明了我們的猜想,大量同時修改的源文件往往是有依賴關系的.
比如劃分塊4,其中源文件在根據同時修改關系的劃分和根據依賴關系的劃分上都被劃分在一個社區,這是由于有依賴的源文件一旦其中一個做出修改,調用此源文件和被此源文件調用的源文件就有很大可能需要做出修改.
我們發現實驗結果中存在奇異點,它們表示源文件被大量提交而它們之間不存在依賴關系,這似乎與我們的假設有出入,仔細探究其出現原因,我們發現奇異點跟關系簇中的某些結點有很少的引用數目,但是在根據依賴關系的劃分中并沒有歸為一個社區,從而成了奇異點.所以,單純以引用和調用的數量來判定兩源文件的依賴關系大小并不全面,但是只是在少量的源文件點中出現差錯,經過排查,我們的猜想是成立的.

表1 Tomcat根據同時修改劃分Table 1 Tomcat partition according to co-change
表2描述了tomcat根據依賴關系劃分的情況,我們可以看出根據依賴關系被劃分到一個社區中的源文件在同時修改關系劃分中也很可能被分到同一個社區,說明具有較強依賴性的源文件在實際開發中更容易被同時修改.這在另一方面證明了我們的猜想,具有依賴關系的源文件往往會被同時修改.
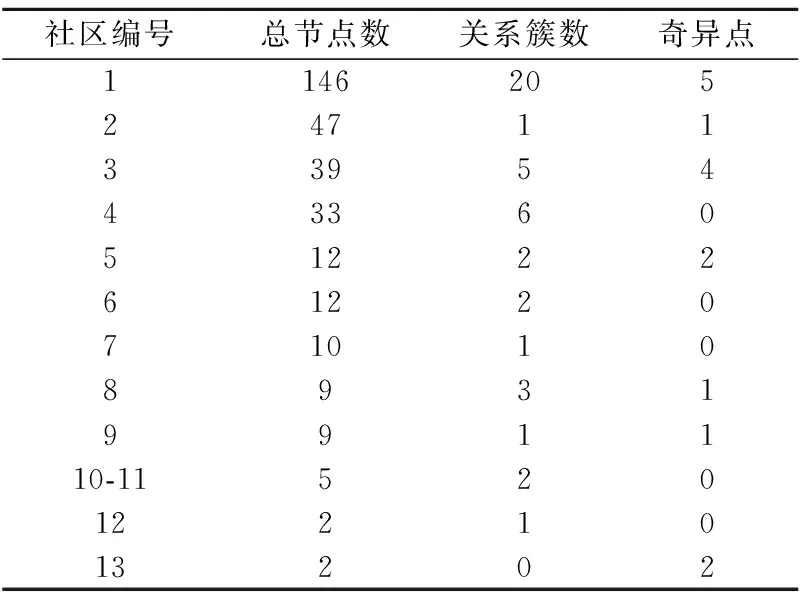
表2 Tomcat根據依賴關系劃分Table 2 Tomcat partition according to dependencies
同樣,根據依賴關系劃分的社區中也存在奇異點,它們表示源文件有較強的依賴關系而它們沒有被大量提交.我們分析發現其存在也是合理的.有些源文件與其他源文件有很強的依賴關系,但其本身修改的次數就非常少,在刪除同時修改次數小于3的數據的處理中,這些數據被刪除,從而產生了奇異點.但這與我們的猜想并不違背.
綜上,雖然兩種劃分中都存在奇異點,但數量很小,并且其存在有合理的解釋,所以說Tomcat項目的源文件依賴和其同時修改關系有較好的一致性,在評價高,優秀的Tomcat項目中,我們的猜想得到了證實.

表3 Tomcat根據同時修改關系劃分Table 3 Earlier versions of Tomcat partition according to co-change
3.2 出現依賴關系和實際關聯不一致現象的項目可能存在的問題(RQ2)
對于評價高,星數多的優秀項目Tomcat的研究中,我們的猜想得到了證實.而對于與我們猜想不相符的項目,它們中是否存在一定的問題.為了探究出現依賴關系和同時修改關系不一致現象的項目可能存在哪些問題,我們選取了Tomcat和評價較低,關注度較低的項目Restunit(2008年12月21號之前)進行分析.
我們選擇Tomcat(2013年7月2號之前)的數據是因為在此之后的一次提交中,項目進行了大量文件的增加與刪除,開發者可能對項目的結構做出了調整,修復了很多問題,這將不利于我們發現問題,所以將此時間節點之前的數據進行分析更可能找出潛在質量問題.Tomcat根據同時修改關系劃分的結果見表3.
我們發現,社區17中的奇異點源文件el/ImplicitObjectELResolver.java和同一社區中的所有源文件沒有任何依賴,但是卻大量與它們一起提交.經過分析,此源文件與同一社區中的el/BeanELResolver.java代碼十分相似,大部分是重復的.這種情況不止一處,社區43中,文件authenticator/TesterDigestAuthenticatorPerformance.java和同一社區中另一文件authenticator/TestDigestAuthenticator.java之間沒有依賴卻同時提交,經過兩文件對比分析,發現存在部分代碼重復的現象.而在社區26中,我們發現三個文件valves/RemoteIpValve,filters/RemoteIpFilter 和 filters/ExpiresFilter的部分代碼均是按照同一模板而寫,社區22中的四個文件startup/WebRuleSet,startup/NamingRuleSet,starup/SetNextNamingRule,startup/ConnectorCreateRule也是同一個模板.可見,通過此方法分析奇異點可以發現軟件中可能存在問題的地方.
對于Restunit,我們也計算了每個社區的總節點數,關系簇和奇異點,實驗結果見表4.
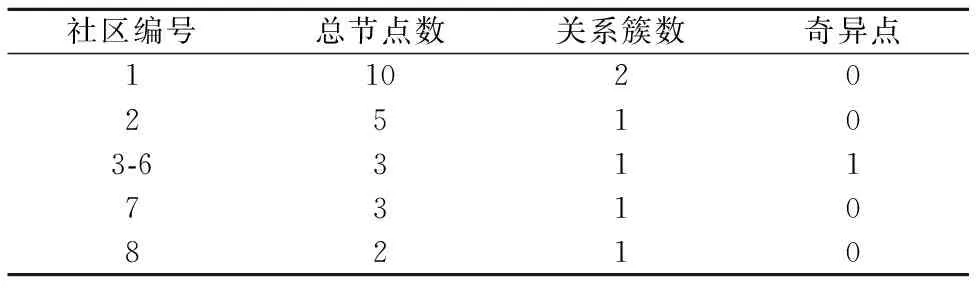
表4 Restunit根據同時修改關系劃分Table 4 Restunit partition according to co-change
對奇異點進行分析我們發現影響項目質量的問題,我們將現象以圖的形式展示,并做分析.圖4展現了文件之間的依賴關系和它們在社區劃分中的情況.記奇異點源文件restunit/SSLRequirement.java為S,記同一社區中的其他兩個源文件restunit/RestTest.java為A,restunit/RestTestResult.java為B.我們發現S與A和B沒有任何的依賴關系,但是存在源文件P,即restunit/RestCall.java,引用了S,而A和B都直接或者是間接的引用了P,B引用了源文件Q,即restunit/RestCallResult.java,而Q源文件引用了源文件P.有趣的是P源文件沒有和任何的源文件一起提交過,反而是S頻繁與A和B源文件一起提交.
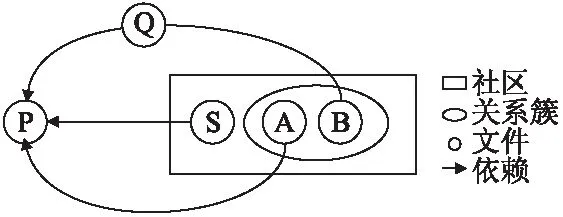
圖4 質量問題1說明圖Fig.4 Description of quality issue 1
如果兩個文件之間有很強的關系,即在提交中大量被同時修改,但它們之間不是直接引用或者調用的話,在出現bug或者維護時需要修改文件時會十分不方便.例如程序員在做出修改時很可能不會發現另一個文件也要做出修改,因為它們之間沒有直接調用.所以出現這種現象會降低軟件的可維護性,也反映出設計上的失誤.
類似的,我們還發現另一種情況,并將文件之間的依賴關系和它們在社區劃分中的情況展示見圖5.記奇異點源文件restunit/TestRestUnit.java為S,記同一社區中的其他兩個源文件restunit/TestAssertions.java為A,http/RESTTreeHttp.java為B.我們發現S與A和B沒有任何依賴關系,但是存在源文件P,即restunit/RestCallResponse.java,S、A、B源文件都引用了P源文件.P源文件幾乎沒有被修改過,而S、A、B卻大量同時被修改.這種情況下,P被視為不活躍的點而在兩種劃分中都被去掉,一定意義上影響了根據依賴關系的劃分中,S與A和B劃分到同一社區.這種現象的產生可能是因為使用者對P中類錯誤的引用,這也加大了項目風險.
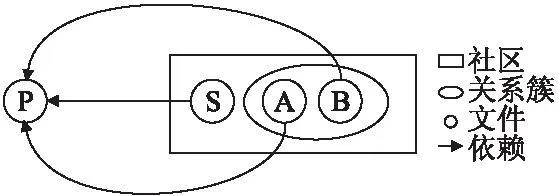
圖5 質量問題2說明圖Fig.5 Description of quality issue 2
綜上,我們可以說出現依賴關系和同時修改關系不一致現象的項目可能存在問題.最典型的問題是代碼的復制粘貼現象,這種單純的復制粘貼降低了代碼的重用性,進而降低了軟件的可維護性,是影響軟件項目質量的重要原因.而實驗結果中提到的另外兩種引用造成的不一致,從項目本身出發,其中也存在一些設計上的不合理.所以我們可以從項目中源文件的依賴關系和其同時修改關系是否具有一致性來發現軟件項目中存在的問題.
4 討 論
實驗運用復雜網絡研究中的社團檢測方法對軟件工程中項目源文件依賴關系與同時修改關系的一致性進行了探究.實驗結果符合已知的規律,從中我們發現兩種關系不一致的軟件項目中可能存在問題,經過仔細對代碼分析,找出了其中的原因,最典型的有代碼的復制粘貼和混亂的引用關系.
實驗方法上具有一定的局限性.對于依賴關系大小的衡量上,我們單純的用源文件之間引用調用的數量來判斷,從實驗結果來看,這是不全面的,有些源文件引用調用數量很少,但是這少量的依賴卻是非常的重要,以至于它們大量同時被修改,即同時修改關系十分的緊密.對于根據同時修改關系對源文件進行劃分中,為了排除干擾,縮小數據規模,對數據做出一定的刪減,這種刪減是合理而有效的,但是這種處理也不可避免的在實驗結果上造成了小部分的錯誤,比如有些源文件與其他源文件有很強的依賴關系,但其本身修改的次數就非常少,在數據縮減中我們忽略了它與其他源文件的聯系,從結果上看就無法證明具有依賴關系的源文件更容易被同時修改的觀點.但在我們實驗中由于這種原因造成的奇異點數量占總結點數量不足3%,所以不影響整體的判斷.
實驗項目的選擇上,我們傾向于選擇中小型規模的項目,對于較大規模的項目因為條件所限沒有進行嘗試,有一定的局限性.
5 結 論
我們對項目中源文件的依賴關系與其在提交信息中同時修改關系的一致性進行了分析,得出以下結論:
在質量較高的軟件項目中,源文件的依賴關系與同時修改關系有非常強的一致性.有依賴的源文件更容易被同時修改,同時大量修改的源文件之間往往存在依賴.
如果存在沒有依賴關系而被同時大量提交的源文件,軟件項目中很可能存在一定的問題,比如代碼的復制粘貼現象,或者混亂的引用情況.
未來的研究中,我們可以嘗試更多不同規模的項目,看是否與我們的猜想相符.在項目中源文件的依賴關系和其同時修改關系具有一致性的前提下,我們可以探究更多造成不一致的原因,分析它們是否降低了軟件項目的質量.進而,我們可以用這種方法偵測軟件項目架構上的問題.為了分析實驗結果,我們提出了關系簇的概念,顯然關系簇數目越小,兩種關系更具有一致性,這種簡單指標一定程度上可以用作軟件項目質量的評定,但還需要更多的實驗來證明.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
公民與法治(2022年5期)2022-07-29 00:47:28
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
發明與創新(2016年38期)2016-08-22 03:02:52
