HR-DCGAN方法的帕金森聲紋樣本擴充及識別研究
2019-09-09 03:38:42徐志京
小型微型計算機系統 2019年9期
王 娟,徐志京
(上海海事大學 信息工程學院,上海 201306) E-mail:wangjuan_y@foxmail.com
1 引 言
帕金森病(Parkinson′s Disease,PD)屬于常見的神經系統退行性疾病,目前尚不能治愈[1].因此探討PD的早期診斷對控制PD患者的病情,延長其生命具有重要意義[2].研究發現,90%的PD患者早期癥狀中存在聲帶損傷[3],經聲學分析表現為高振幅微擾,高基頻微擾,低諧信噪比,低基頻[4].考慮患者的嗓音特點,可以通過提取語音信號中的聲學特征進行PD的早期檢測,此方法具有非入侵性,便利性,高效率等優點,被國內外居民廣泛接受.
國內外學者主要采用傳統的特征提取方法和機器學習算法,通過分析語音信號實現PD識別.Max Little等[5]在2009年收集持續的元音發聲/a/作為首個語音數據庫.隨后,Max Little等證明元音足以進行PD檢測[6,7].2013年,Sakar等分析了從PD患者收集的多種類型的語音用于PD診斷[8].為提高識別準確率,Benba等在Sakar提供的數據集上繼續研究,分別利用梅爾頻率倒譜系數(Frequency Cepstrum Cofficient,MFCC)及其一階、二階導數[9],平均值來壓縮提取的MFCC[10],人因子倒譜系數(Human Factor Cepstral Coefficients,HFCC)[11]提取聲紋特征參數,結合不同核函數的SVM分類器進行分類.MFCC、HFCC等存在對高階音頻的聲紋特征表征能力差、參數階數選擇復雜及特征缺失或冗余問題,基于小樣本的淺層機器學習分類器如SVM,k-最近鄰分類器(k-Nearest Neighbor,KNN)以及球面聚類方法[12]調參困難且計算量大.
近年來,深度學習在語音處理中的應用如語音增強、情感識別和病理檢測,取得了很好的效果,為通過聲紋特征識別PD患者提供了基礎.Lucijano Berus等[13]使用原始音頻數據[8]輸入到人工神經網絡(Artificial Neural Network,ANN)微調后進行分類,但直接處理語音信號較復雜;師等[14]采用Alexnet對語譜圖分類,在數據集[8]上達到86.67%的精確度.將語音信號轉換為語譜圖,可以利用神經網絡識別并提取與研究目標相關的重要聲紋特征以自動對圖像進行分類.目前,最受歡迎的卷積神經網絡(Convolutional Neural Network,CNN)VGGNets中的VGG16模型是用于圖像識別和分類的主要工具.VGG16具有拓展性很強、泛化性好等優點,在其他領域的圖像數據集上達到很好的效果,作為一種數據驅動模型,依賴大量樣本.但現階段用于帕金森研究的音頻數據少且樣本獲取困難,導致深度學習算法過度擬合,達不到好的效果[15].因此,采用深度學習算法診斷帕金森病時,樣本擴充是亟待解決的問題.
生成對抗網絡(Generative Adversarial Network,GAN)被Goodfellow等[16]提出以來,產生諸多變體并被應用于半監督和監督學習領域的圖像處理或合成等工作.目前成熟的GAN框架深度卷積生成對抗網絡(Deep Convolutional Generative Adversarial Network,DCGAN)[17]通過合成或生成圖像數據進行樣本擴充,已經應用于半監督學習領域的高光譜圖像分類[15],肝臟病變分類[18]以及合成人工腦電圖信號(electroencephalographic,EEG)[19]等領域.但是DCGAN生成高分辨率圖像時易發生模型崩潰,訓練不穩定問題導致生成效果差.本文將DCGAN模型引入到聲紋識別領域,提出了一種基于DCGAN和特征匹配方法的高分辨率深度卷積生成對抗網絡(High Resolution Deep Convolutional Generative Adversarial Network,HR-DCGAN)模型.首先將語音信號轉換為語譜圖,利用語譜圖聯合時頻分析方法,采用HR-DCGAN-VGG16混合模型對小樣本擴充,并應用到帕金森患者的識別工作中,與無樣本擴充相比,提高了小樣本下的PD患者識別準確率,并比較了不同擴充系數下達到的識別效果.
2 小樣本帕金森識別模型
利用HR-DCGAN模型擴充樣本,VGG16提取聲紋特征并進行分類識別,本文構建了小樣本帕金森識別模型如圖1所示.首先將原始語音信號轉換為語譜圖,經HR-DCGAN模型生成PD患者和健康人的語譜圖,根據SSIM指標篩選語譜圖用于擴充數據集,擴充樣本和原始樣本輸入到VGG16模型進行分類,實現帕金森識別.
2.1 語音信號預處理及語譜圖原理
由于環境背景噪聲,發音器官與音頻采集設備產生的混疊干擾、諧波失真等,采集到的語音信號質量參差不齊,因此對原始的語音信號進行預處理是必要的,且是影響識別準確率的重要過程.預處理包括預加重、分幀、加窗和端點檢測四個過程[10].經預處理后,本文將語音信號轉換為語譜圖,作為二維圖譜可以聯合時頻分析方法提取譜特征.像素灰度值表示對應時間和頻率的語音能量信息,并且語譜圖可以保留更多的高頻信息并更好地呈現參與者的聲紋,尤其是其中所包含的聲紋特征信息如頻譜,基音,共振峰等.另外,可直接提取語譜圖中的聲紋特征,解決了傳統譜特征中相鄰幀之間相關性被忽略及特征冗余問題.
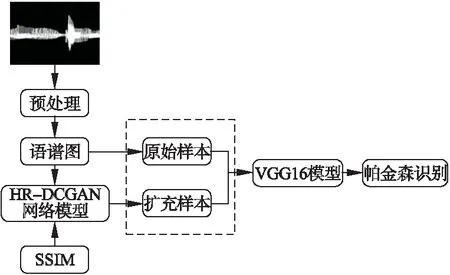
圖1 小樣本帕金森識別模型Fig.1 Parkinson′s Disease recognition model with a small number of samples
語譜圖的生成過程步驟如下:
1)對預處理后的語音信號進行傅里葉變換[14],如公式(1)所示.
(1)
其中w(n)是窗函數類型,本文采用漢明窗.Xn(ejw)是關于w和n的函數.
2)令w=2πk/N,(0≤k≤N-1),N代表快速傅里葉變換(Fast Fourier Transform,FFT)的點數,對每一幀信號做FFT,得到短時傅里葉變換如公式(2).
(2)
3)計算短時功率譜Sn(ejw).
Sn(ejw)=Xn(ejw)·Xn(ejw)=|Xn(ejw)|2
(3)
其中:
Rn(k)為x(n)的短時自相關函數,Sn(ejw)為Rn(k)的傅里葉變換.n,w分別為橫縱坐標,Sn(ejw)的值為點(n,w)的像素灰度級表示.
4)灰度圖映射:依次連接每幀的灰度級表示,便生成灰度語譜圖.為提高圖像內容的可辨識度,采用Matlab2016a中的偽彩色映射函數colormap(map)(其中map為采用的偽彩色映射矩陣,默認為jet)進行功率譜偽彩色顯示[20]便得到偽彩色語譜圖.
為方便網絡模型的處理以及更清晰地可視化語譜圖的共振峰、基頻和諧波的變化,本文采用分辨率為256×256×3的語譜圖進行研究.圖2為健康人和PD患者發出元音/a/時的窄帶語譜圖.健康人的語譜圖其諧波的變化范圍為(0,16000),基頻區域紋理清晰,中高頻區域噪聲極少且諧波紋理規則.PD患者的語譜圖其諧波變化范圍為(0,6000),語音能量主要在基頻附近和中低頻區,高于2000Hz左右的高頻區域諧波紋理分布不連續,出現斷裂和消失,共振峰不完整,高于6000Hz的諧波基本消失.相比傳統的時域序列或頻譜特性,PD對聲音系統造成的損傷更好的呈現在語譜圖上.兩者的明顯區別在于諧波的范圍,中高頻區諧波分布是否連續有規則,共振峰是否完整,噪聲是否增多.
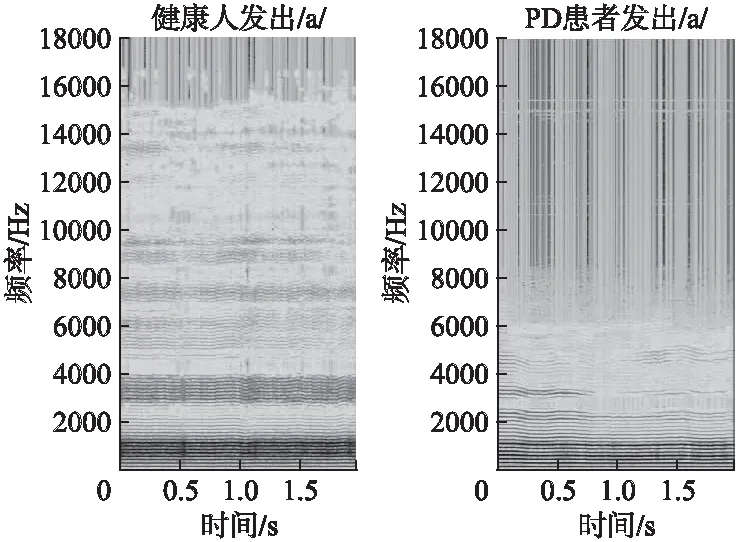
圖2 健康人和PD患者發出元音/a/時的語譜圖Fig.2 Spectrogram of healthy people and PD patients who are pronouncing the vowel /a/
綜上,語譜圖表現的不同特征信息對于PD患者和健康人有較好的區分度.另外,通過處理語譜圖間接地處理語音信號,能夠利用GAN強大的圖像生成能力,并且避免GAN直接處理連續語音信號的復雜性難題.同時利用語譜圖聯合時頻分析方法,以提取到時域和頻域的聲紋特征,比傳統的MFCC、HFCC保留更多有用信息,保證較高分類精度.利用GAN擅長生成更注重紋理而沒有結構限制的圖像類別的優勢[21],所以能更好的捕捉語譜圖的紋理特征.
2.2 網絡結構
2.2.1 GAN原理
GAN由生成器G和判別器D構成,根據對抗思想采用極大極小策略無監督的生成新圖像.生成器的目的是輸入服從概率分布Pz(均勻分布或高斯分布)中采樣的隨機噪聲矢量z,不斷學習真實訓練樣本x的分布,輸出近似于真實樣本潛在分布的假樣本G(z).判別器的實質是分類器,輸入G(z)或x,計算輸入屬于Pdata的概率,判斷輸入來自真實樣本Pdata還是假樣本G(z).兩者對抗訓練并交替更新D和G的參數,最大化D區分度的同時最小化G(z)和Pdata之間的數據分布誤差,最終達到納什均衡.當D無法正確估計出輸入是來自于G(z)還是Pdata時,G能夠擬合真實樣本的分布.GAN的損失函數[16]如下:
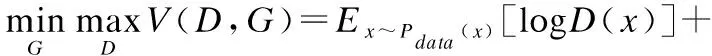
(4)
由于GAN在訓練時不穩定,因此本文采用DCGAN模型.它具有特定的架構約束并且D和G均采用CNN結構,適用于圖像處理任務.DCGAN能夠無監督的學習表征,用于有監督學習[17].最初的DCGAN模型用于生成分辨率為64×64的圖像,隨后在分辨率為28×28的MNIST數據集以及分辨率為32×32的CIFAR-10數據集上能夠生成高質量的樣本.目前,DCGAN依據其結構優勢能夠為廣泛的數據集提供相對穩定的訓練.本文構建更深的DCGAN網絡結構,結合特征匹配方法,提出HR-DCGAN模型,以構建更深入的生成模型,提高模型在生成高分辨率的語譜圖圖像時的生成能力和穩定性.
2.2.2 HR-DCGAN模型的網絡結構
HR-DCGAN模型中G和D的架構設計是基于DCGAN模型結構以適應分辨率為256×256×3的語譜圖.通過增加G的網絡層數,逐層增加生成圖像的尺寸,其變化過程為4×4→8×8→16×16→32×32→64×64→128×128→256×256,最終生成高分辨率的語譜圖.D網絡根據輸入圖像的大小,增加網絡層數以適應解卷積過程中高分辨率圖像的逐層下采樣,其特征圖的變化過程為256×256→128×128→64×64→32×32→16×16→8×8→4×4.為提高模型生成高分辨率圖像時的穩定性,本文引入特征匹配方法.特征匹配指生成器產生的“偽”樣本與真實樣本通過判別器卷積層時輸出的特征圖盡可能相同[22].添加到生成樣本的過程中,阻止D過度訓練的同時,促進G捕捉語譜特征圖中的紋理信息,生成與真實樣本的統計數據近似的“偽”樣本.
設f(x)為判別器網絡中間層輸出的特征圖,最小化G和D特征圖之間的誤差,目標函數為:
min(w)=‖Ex~pdataf(x)-Ez~pzf(G(z))‖2
(5)
D的損失函數不變,按預設的方式最大化判別網絡輸出.G的損失函數變為訓練時生成“偽”樣本的誤差和特征匹配過程的誤差,公式如下:
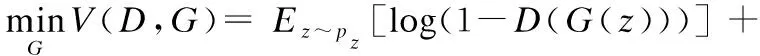
(6)
HR-DCGAN中的G和D的網絡模型圖如圖3所示.本文采用偽彩色語譜圖,所以G的輸出和D的輸入為三通道.另外,G和D在第一個卷積層的維度設置為64,在第一個全連接層的維度設置為2048.
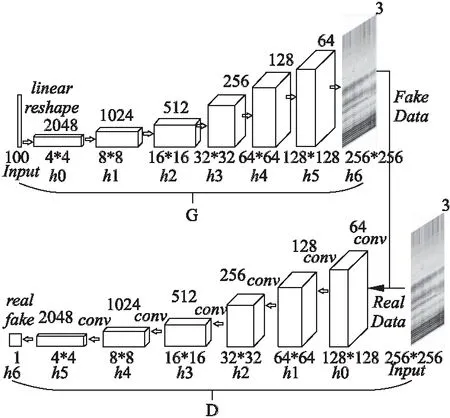
圖3 HR-DCGAN的網絡架構Fig.3 Network architecture of HR-DCGAN
如圖3所示,G包含7層網絡,將服從高斯分布的100維向量作為噪聲z輸入,用上采樣到4×4空間范圍的卷積表示,其具有2048個特征圖,產生4×4×2048張量.h0~h5層為微步幅卷積層,包括5×5的卷積核大小,步幅為2,G的學習過程即進行空間上采樣.經批量標準化(Batch Normalization,BN)后[17],每個隱層的單元都通過歸一化為零均值和單位方差,以此來穩定學習過程,解決了因初始化不良導致的生成模型崩潰問題,使梯度能更深層次傳播.然后采用Relu激活函數進行激活.每經過一個微步幅卷積層,生成的特征圖的尺寸加倍,數量減半.h6層為tanh函數激活,最終輸出256×256×3的語譜圖圖像,并作為D的“偽”數據的輸入.
D包含7層網絡,h0~h5為卷積層,采用5×5卷積核,步幅為2.所有層均有BN層和leakey Relu激活函數的非線性映射,D的輸入層除外.卷積層對輸入的語譜圖進行特征提取,每經過一個卷積層進行下采樣,特征圖的尺寸減少一半,數目加倍.h6層利用Sigmoid激活函數判別真實樣本和生成的“偽”樣本,其輸出表示輸入圖像是來自真實樣本的概率.
本文的HR-DCGAN模型中G和D的網絡層數加深,并添加了特征匹配項的約束.分別將不同類別的原始語譜圖輸入到HR-DCGAN模型,以適應其無監督式的訓練過程,生成具有相似紋理特征的高分辨率樣本擴充原始數據集.
2.2.3 分類器設計
PD患者的聲紋識別過程包括聲紋特征提取和分類,本文直接將原始語譜圖樣本和經樣本擴充后的訓練樣本分別添加類別標簽后輸入到VGG16中,自動提取聲紋特征并分類.本文采用的VGG16模型由3×3的卷積核和2×2的最大池化層構成,共13個卷積層和3個全連接層[23].相比8層的Alexnet網絡,其采用較小的卷積核,堆疊多層卷積層增加了網絡深度,以提取更深層次的聲紋特征,增強網絡的擬合能力.本文采用遷移學習的思想,利用基于ImageNet數據集預訓練好的VGG16模型參數,保留前13層并釋放后3層的權重,微調后進行特征提取和分類.本文的VGG16模型圖如圖4所示.
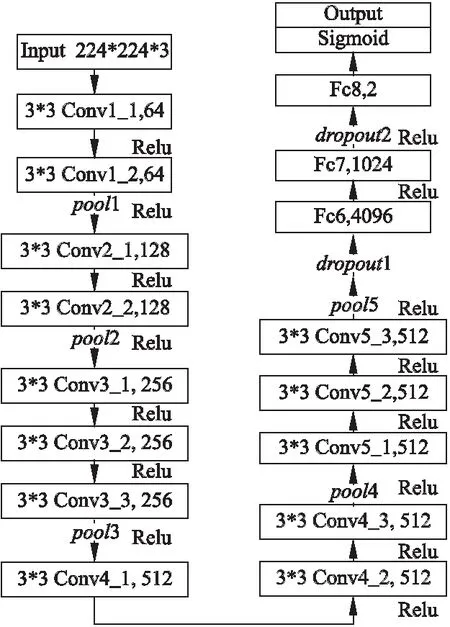
圖4 VGG16模型結構圖Fig.4 Structure of VGG16 model
為適應VGG16輸入層的要求,采用python的pillow庫中crop操作,設定固定的裁剪區域將256×256分辨率的語譜圖統一裁剪為224×224,再輸入到卷積層.具體方法如下:
已知pillow坐標系統的原點(0,0)位于圖像的左上角,坐標中數字的單位為像素點.裁剪區域表示為(xmin,ymin,xmax,ymax),其中(xmin,ymin)為圖像左上角的橫縱坐標,(xmax,ymax)為圖像右下角的橫縱坐標.由于語譜圖的基音頻率、諧波等紋理信息都集中在中低頻區即語譜圖的中下部和底部區域,高頻區域含有的有用信息較少,所以本文將裁剪區域設為(32,32,256,256).裁減掉位于語譜圖頂端和左側邊緣區域的影響較小或無用的信息,保留語譜圖底部區域有效特征信息,使裁剪后的語譜圖最大化保留聲紋特征信息,便于輸入到網絡的同時,也能對網絡性能和輸出準確率影響較小.
由于本研究進行二分類,修改VGG16的Fc7層的輸出神經元個數為1024個和Fc8層的輸出神經元個數為2個.由于訓練的特征數量非常大,容易使訓練出的模型過擬合.本文在最后一個池化層和Fc7全連接層后加入Dropout層[18],并將Dropout率設為0.5,改變網絡架構以抑制過擬合問題.通過模型訓練對前13層的權重進行微調,更新全連接層的權重,實現對語譜圖的分類識別.
采用訓練的VGG16模型預測測試集的標簽,根據準確度(Accuracy,ACC),特異性(Specificity,SPE)和靈敏度(Sensitivity,SEN)指標[11],評估分類器的分類結果,從而評估所提出的算法的性能.通過HR-DCGAN樣本擴充后,再利用VGG16分類識別的網絡模型稱作HR-DCGAN-VGG16混合模型.
2.3 樣本擴充的選取標準
評估GAN生成的圖像的質量是一項復雜的工作,且通過主觀視覺評估和選取樣本的方法實踐困難、說服力差.本文將結構相似度(Structural Similarity Index,SSIM)指標作為生成的語譜圖樣本的選取標準,以判斷是否用于擴充訓練樣本.
SSIM公式[24]如下:
(7)
其中,μx,μg,σx,σg分別為真實圖像x和生成圖像g的像素值的均值和方差,σxg為x和g的協方差.c1=(k1*L)2,c2=(k2*L)2是用于維持穩定的常數,L=255是圖像像素值的最大值,k1=0.01,k2=0.03.
SSIM的值域為[0,1],其值的大小與兩個圖像在像素級別的相似度成正比.由于語譜圖圖像的像素間存在很強的相關性,這些相關性攜帶著與語音信號的能量以及共振峰、諧波等聲紋特征相關的重要信息.因此,SSIM指標能夠表示生成圖像和真實圖像的相似度.為選取高相似度的語譜圖樣本,本文設置SSIM的閾值為0.85,通過計算生成的語譜圖和原始語譜圖樣本之間的SSIM,當SSIM指標的值大于或等于閾值時,可用作樣本擴充,否則不用作樣本擴充.
3 實 驗
3.1 實驗設備
實驗環境配置如下,64 bit Windows10操作系統,CPU為Intel(R)Core(TM)i7-7800X 3.50GHz,內存16GB,GPU為NVIDIA GeForce GTX 1080 Ti,顯存為11GB,CUDA 9.0和cuDNN 7.0加速包支持.軟件要求:Python3.6.6,Tensorflow1.10.0框架,Matlab2016a.
3.2 數據集介紹及預處理
本文采用UCI數據集,由Sakar等人收集[8],訓練集包括20名PD患者(6名女性和14名男性)和20名健康人(10名女性和10名男性)發出/a/,/o/和/u/三種元音的語音信號,共120個語音樣本.PD患者的診斷時間介于0至6年之間,年齡在43歲至77歲之間.健康人的年齡在45歲至83歲之間.測試集包括28名PD患者發出/a/,/o/兩種語音信號,共56個語音樣本.患者的診斷時間介于0至13年之間,年齡在39至79歲之間.錄音設備為 Trust MC-1500 麥克風.參與者的每個/a/,/o/和/u/語音樣本中包含3次連續的發音,每次發音過程持續6s的時間.所有的語音記錄都為立體聲模式和wav格式.
數據集共計176個語音信號.分別將每次發音分割成時間為2s的語音片段,所以一個wav格式的語音文件可以分割為3個2s的語音片段,包括原始語音片段,可以將數據集初步擴大四倍.再對每個語音片段利用Matlab2016a進行語音信號預處理后分別生成256×256×3分辨率的JPEG格式的語譜圖.已知語音信號的采樣頻率為44.1kHz,本文將NFFT點數設為2048,幀長為46.44ms,幀移為幀長的1/4,幀重疊部分取為幀長的3/4,此時生成的語譜圖諧波紋理清晰且聲紋特征明顯,參數設置如表1所示.
表1 語音信號轉換為語譜圖的參數設置數據表
Table 1 Parameter settings data table for extracting speech signals into spectrogram
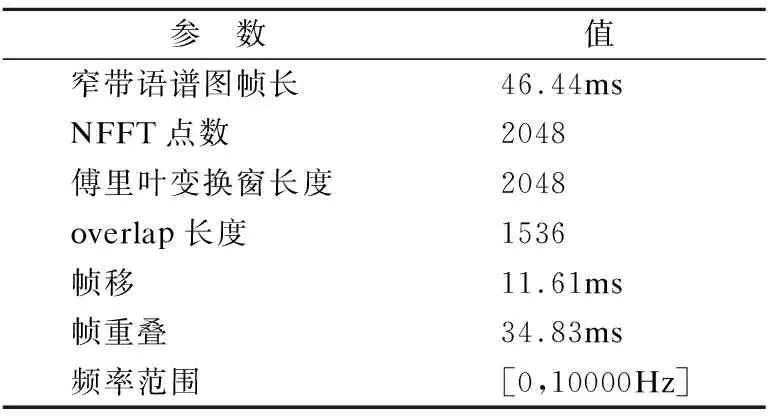
參 數值窄帶語譜圖幀長46.44msNFFT點數2048傅里葉變換窗長度2048overlap長度1536幀移11.61ms幀重疊34.83ms頻率范圍[0,10000Hz]
原始數據集共704張語譜圖,并添加one_hot編碼格式的類別標簽.健康人和PD患者的語譜圖對應的標簽分別為“01”,“10”.
3.3 網絡訓練
3.3.1 HR-DCGAN模型的訓練
分別用PD患者的語譜圖樣本和健康人的語譜圖樣本訓練HR-DCGAN模型.均值為零,標準差為0.02的高斯分布作為G的輸入并初始化網絡權重,本文采用批量隨機梯度下降算法(Stochastic Gradient Descent,SGD)訓練,Batch size設置為16,Leaky Relu的斜率為0.2,用Adam優化器調節超參數,learning rate為0.0002,momentum termβ1設置為0.5時可以穩定訓練.D訓練兩次,G訓練一次,Epoch數目設置為600.每隔10個Epoch輸出一次SSIM的平均值,作為選取擴充樣本的標準.
3.3.2 VGG16模型的訓練
本文首先按7∶3的比例將704張帶標簽的語譜圖劃分為訓練集和測試集,Batch_size設置為16,迭代次數為1000,微調添加Dropout層的預訓練模型VGG16以實現自動特征提取和分類.將選取SSIM值大于等于0.85的生成語譜圖并添加標簽,用于擴充訓練樣本.根據SSIM值首先取第110,150,200,220,240,300,320,350,400,450 Epoch下的生成語譜圖將數據集擴大10倍后,按照7∶3劃分訓練集和測試集,統一裁剪后輸入到VGG16模型進行識別和分類.
根據不同Epoch下的SSIM值,選取高相似度的生成語譜圖,將數據集擴大不同的倍數分組訓練VGG16模型,對比不同樣本擴充系數對PD識別結果的影響.樣本擴充系數在1~30倍之間,并比較分類結果.
4 實驗結果與分析
4.1 可視化HR-DCGAN模型的生成結果
首先,本文可視化了HR-DCGAN模型訓練的結果.對PD患者和健康人的語譜圖訓練過程中g_loss,d_loss前期出現震蕩,最終分別穩定收斂到1.08027147和1.38497926,1.00317682和1.29376531.隨機取不同Epoch下的生成圖像,部分生成結果如圖5、圖6.其中(a)~(h)表示HR-DCGAN模型訓練時Epoch的數字順序.

圖5 不同Epoch下生成的PD患者的語譜圖Fig.5 Generated PD patients′ spectrogram after different epochs
由圖5和圖6可以看出,第 0 Epoch時,生成的全是噪聲點和語譜圖的色彩輪廓;第50 Epoch 生成基音頻率和共振峰位置明顯但紋理模糊的圖像;第100 Epoch 時,基音頻率和共振峰較清晰;第200 Epoch時,語譜圖的諧波紋理清晰,基頻和中高頻噪聲平滑;第300、400 Epoch時,可看出共振峰是否完整和各次諧波的分布,紋理更加清晰;第500、599 Epoch時,共振峰突出,諧波紋理較清晰.由不同Epoch下的語譜圖可以看出模型收斂速度較快,肉眼可見生成的語譜圖質量穩定提高.
然后根據SSIM的閾值選取高相似度的生成語譜圖添加標簽后用于擴充樣本,由于訓練前期網絡的生成效果不好,所以前100 Epoch的生成圖像不予考慮.100 Epoch后,PD患者和健康人的生成語譜圖和原始語譜圖計算得到的SSIM值范圍為0.7835~0.9374,由于訓練前期訓練不收斂以及語譜圖中共振峰和諧波等聲紋特征的位置、范圍和結構的多樣變化,以及噪聲的平滑化引起像素值的變化,導致SSIM值不穩定.隨著網絡逐漸穩定,SSIM值大多數處于0.85~0.90之間,表明HR-DCGAN生成的語譜圖樣本在紋理、顏色、色彩對比度等方面和真實樣本相似.并且模型的測試結果顯示紋理清晰且聲紋特征明顯的分辨率為256×256×3的語譜圖.因此通過對抗學習和特征匹配不斷提高特征的質量,能夠較好的保留語譜圖中的聲紋特征,訓練和測試結果表明HR-DCGAN模型在生成高分辨率語譜圖的穩定性.

圖6 不同Epoch下生成的健康人的語譜圖Fig.6 Generated healthy people′s spectrogram after different epochs
4.2 分類識別
在分類訓練和測試階段,在相同數據集下,分別將VGG16網絡直接處理語譜圖提取聲紋的特征提取方式與MFCC[10]、HFCC[11]對比,并與KNN、SVM、ANN[13]、Alexnet[14]分類器比較,最后進行有無樣本擴充的對比;針對VGG16模型討論不同樣本擴充系數的對比.
當沒有樣本擴充時,傳統的HFCC特征提取方法結合SVM分類器優于采用神經網絡的分類方法,表明傳統機器學習方法在小樣本下的適用性,但分類性能取決于特征選擇和分類器選擇,而提取特征時倒譜系數的選擇、分類器核函數或聚類中心k的確定過程復雜.而語譜圖作為圖像可直接被神經網絡處理,同時提取到時頻域的聲紋特征并實現分類.由于初始樣本有限且VGG16網絡需要大量訓練樣本驅動,Dropout層在一定程度上抑制過擬合,僅達到77.5%的準確率,其低于利用ANN和Alexnet分類的識別準確率.樣本擴充后,VGG16網絡中的Dropout層達到一定的正則化效果,加快CNN的收斂速度,且精度較高,準確率增加到90.5%.因此本文的HR-DCGAN模型通過擴展訓練樣本的數量,加強了分類器的訓練,進一步提高了模型泛化性能.通過與其他特征提取方式和分類方法對比,對有無樣本擴充的語譜圖分類發現,
表2 有無樣本擴充的模型分類結果
Table 2 Model classification results with or
without sample augmentation

特征提取分類器ACCSENSPEMFCCMLP核SVM82.5%80%85%HFCCLIN核SVM87.5%9085HFCCKNN(k=5)73.75%75%72.5% ANN86.47%88.91%84.02% Alexnet86.67%90%83.34% VGG1677.5%80%75% HR-DCGAN-VGG1690.5%91%90%
HR-DCGAN生成的高分辨率語譜圖圖像進行樣本擴充的有效性,VGG16自動提取語譜圖的聲紋特征的能力和分類性能在大量數據驅動情況下的優越性.不同模型分類性能對比以及有無樣本擴充的分類器性能對比,如表2所示.HR-DCGAN-VGG16模型在不同樣本擴充系數下進行訓練和測試,對語譜圖的分類識別準確率對比如圖7所示.樣本擴充系數為0~10倍時,隨著訓練樣本的增加以及Dropout層的使用,逐步解決VGG16深層網絡的過擬合問題,對PD患者和健康人的語譜圖的分類結果得到顯著改善.當擴充系數為10時,達到最高的識別準確率90.5%.繼續增加訓練集樣本,當擴充系數為10~30倍時,識別準確率不再繼續增加,達到飽和度約90.5%.由于有限樣本中語譜圖的特征有限,再添加更多的生成樣本未能繼續改善分類效果.
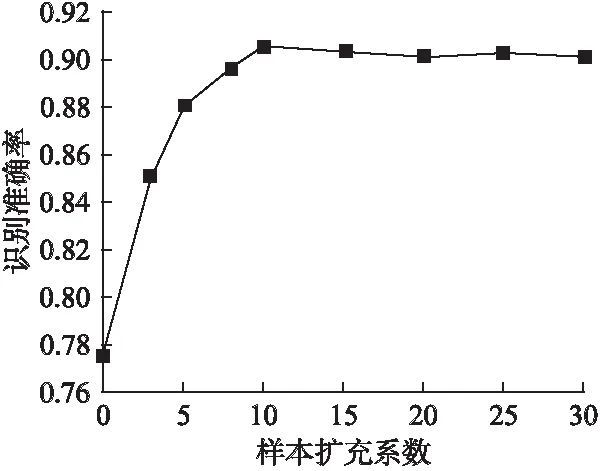
圖7 HR-DCGAN-VGG16模型在不同樣本擴充系數下的識別率的分布Fig.7 Distribution of recognition rate with HR-DCGAN-VGG16 model under different sample augmentation factors
實驗結果表明,HR-DCGAN-VGG16混合模型能夠對PD患者和健康人的語譜圖實現樣本擴充、特征提取和分類,獲得最佳識別準確率為90.5%,其優于無樣本擴充的ANN、Alexnet和其他傳統的機器學習方法.所以在小樣本情況下,一方面可以通過HR-DCGAN模型的對抗學習策略和特征匹配方法,提取語譜圖紋理特征并生成高分辨率圖像,結合SSIM標準作為一種樣本擴充的方式,彌補采用深度學習方法進行PD患者識別診斷時音頻樣本的不足;另一方面,原始數據集進行特定倍數的樣本擴充后,輸入到深層的CNN如VGG16模型中提取特征并分類,有效防止過擬合的同時也能夠提高分類精度和帕金森的識別率.
5 結束語
PD患者和健康人的語譜圖具有顯著性差異,對其采用聯合時頻分析方法解決了傳統的特征提取方式參數選擇復雜以及特征缺失和冗余問題.HR-DCGAN模型能生成高分辨率的語譜圖樣本且訓練過程穩定,通過設置SSIM閾值保證了樣本擴充的有效性.Dropout層優化VGG16模型改善過擬合的同時提高了網絡收斂速度和泛化性能.實驗結果表明,在小樣本下,本文提出的HR-DCGAN-VGG16混合模型得到最佳的分類識別準確率,說明了PD數據集采用GAN進行樣本擴充的可行性和有效性.此方法可有效改善小樣本下聲紋識別率低的問題,提高了帕金森篩查率.未來的工作將繼續深入研究不同的樣本擴充方法并改進分類識別方法,專注于改善在小樣本下對帕金森病的識別準確率.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
