基于半監督聚類的網絡嵌入方法
2019-09-10 07:22:44張靜李文斌張志敏
河北工業科技 2019年4期
張靜 李文斌 張志敏




摘要:GEMSEC(graph embedding with self clustering)在計算節點特征的同時學習節點聚類,通過強制將節點進行聚類來揭露網絡中的社區結構,但未考慮類別標簽信息,導致學到的節點嵌入缺乏區分性。針對這一問題,提出了一種基于半監督聚類的網絡嵌入方法(NESSC),將隨機游走序列和少量節點類別標簽作為輸入,在計算節點特征和學習節點k-means聚類的過程中,利用類別標簽信息指導聚類過程,同時重構已知節點類別標簽信息,學習具有區分性的節點表示。在6個真實網絡上進行節點聚類和節點分類評測實驗,實驗結果顯示,NESSC方法明顯優于無監督網絡嵌入方法DeepWalk和GEMSEC,可以通過加入節點的標簽信息來提高網絡嵌入的效果。因此,通過網絡節點的嵌入,可以高效地提取網絡的有用信息,對于相關網絡嵌入研究具有一定的參考價值。
關鍵詞:人工智能其他學科;網絡嵌入;聚類;半監督;區分性
中圖分類號:TP181文獻標志碼:Adoi: 10.7535/hbgykj.2019yx04004
Abstract:GEMSEC(craph embedding with self clustering) learns a clustering of the nodes simultaneously with computing their features, and reveals the natural community structure in the network by enforcing nodes to be clustered. However, it fails to consider label information, which leads to the lack of discrimination of learned node embedding. To solve this problem, a network embedding method based on semi-supervised clustering(NESSC) is proposed, which takes the random walk sequence and a small amount labels of nodes as input, and the label information is used to guide the clustering process in the process of learning node features and node clustering learning, and the known node label information is reconstructed to learn the discriminative node representation. Finally, an experimental evaluation of node classification is performed, using six real-world datasets. The results demonstrate that NESSC is obviously superior to unsupervised network embedding methods DeepWalk and GEMSEC, which indicates that the effect of network embedding can be improved by adding the label information of nodes. This method can extract useful internet information effectively by embedding of network nodes, which provides reference for the study of network embedding methods.
Keywords:other disciplines of artificial intelligence; network embedding; clustering; semi-supervised; discrimination
現實世界中的復雜系統通常都可以建模為網絡,如社交網絡、生物網絡、引文網絡等,其中數據樣本對應于網絡的節點,數據樣本之間的關聯對應于網絡的邊。對這些網絡的分析在許多新興應用中發揮著重要的作用[1],如在社交網絡中,將用戶劃分為有意義的社交群體對于用戶搜索、定向廣告和推薦等許多重要任務都是有用的;在生物網絡中,推斷蛋白質之間的相互作用可以促進形成疾病治療的新方法。但由于高維度和數據稀疏等問題,使得傳統的基于鄰接矩陣的網絡表示形式很難在大數據環境下推廣。因此,尋找網絡節點的有效低維向量表示,高效提取網絡的有用信息,具有重要的學術意義和廣泛的應用價值[2]。
網絡嵌入[3-5]通過保留網絡拓撲結構等信息,將復雜網絡中的節點嵌入到低維、連續的向量空間,使得具有相似結構的節點在向量空間中有相近的向量表示。網絡嵌入通過優化算法自動得到網絡節點表示,可以有效降低復雜度,方便進行分布式并行計算,同時還可以直接應用前沿的機器學習算法對網絡數據進行高效分析與處理。
1相關工作
傳統的網絡嵌入方法是基于矩陣特征向量計算的,例如,局部線性表示(locally linear embedding,LLE)[6]和拉普拉斯特征映射(Laplacian eigenmaps,LE)[7]。該類方法依賴于關聯矩陣的定義和構建,需要對關聯矩陣進行特征值計算,時間、空間復雜度較高,不適用于大規模網絡的嵌入學習。
近年來,基于神經網絡的網絡嵌入技術逐漸引起學術界的關注。受神經網絡語言模型Word2vec[8]的啟發,PEROZZI等[9]提出了DeepWalk方法,將在復雜網絡中隨機游走得到的節點序列看作是文本中的句子,將序列中的節點看作是文本中的單詞,通過Skip-Gram模型得到網絡節點嵌入表示。由于隨機游走序列只依賴于局部信息,使得DeepWalk模型計算時間、空間消耗較小。之后,Node2vec[10]對DeepWalk的隨機游走策略做出了改進,引入深度優先搜索和寬度優先搜索來捕獲節點的結構對等性和同質性特點,因此可以得到更高質量的嵌入表示。LINE[11]通過對網絡節點的一階相似性和二階相似性建模優化,來捕獲網絡的一階和二階鄰近特征。為了獲取節點的高階特征表示,GraRep[12]在LINE基礎上進行更高階相似性關系的建模。
保持網絡結構是網絡嵌入的基本要求,以上方法只考慮網絡的局部結構,如節點的一階和二階相似性,忽略了全局結構。MNMF[13]將社區結構納入到網絡嵌入中,然后在統一的框架中共同優化基于NMF的嵌入表示學習模型和基于模塊的社區檢測模型,從而使學到的節點表示能夠同時保持網絡的微觀結構和社區結構。但該方法是基于矩陣分解的,復雜度較高,不能處理大規模網絡。GEMSEC[14]將聚類約束引入節點嵌入優化目標,在學習節點特征的同時,對節點進行k-means聚類,用聚類的結果來影響節點嵌入的學習,使得到的節點嵌入表示能夠保持網絡的潛在聚類結構。同時,由于該方法是基于序列的網絡嵌入模型,運行時間復雜度在節點數上是線性的。但以上網絡嵌入方法都是無監督的,學到的特征缺少區分性,導致在某些特定任務上效果不好。
網絡中除了網絡拓撲結構信息,還有著豐富的伴隨信息,如節點的類別標簽信息。引入節點的類別標簽信息可以增強學到嵌入表示的區分性。CHEN等[15]提出一種融合群內部結構和跨群信息的網絡嵌入訓練模型GENE, 通過在游走序列中添加包含節點標簽信息的標簽節點, 實現網絡結構信息與標簽信息的融合。TU等[16]提出基于最大間隔的DeepWalk模型MMDW(max-margin DeepWalk),將節點的類別標簽信息融入到節點嵌入向量中,學習有區分性的節點嵌入表示。
本文從融合網絡結構與節點標簽類別信息出發,提出了一種基于半監督聚類的網絡嵌入方法NESSC,該方法首先受GEMSEC的啟發,在計算節點嵌入特征的同時對節點進行k-means聚類,使學到的節點嵌入能更好地保持網絡的潛在聚類結構,但在聚類的過程中加入了類別標簽信息,利用少量已知節點的類別標簽指導節點聚類過程;其次,為了更加充分地利用已知節點的類別標簽信息,將最小化已知節點所屬類別損失加入到節點嵌入優化的目標中,學習最優化的嵌入表示。
2基于半監督聚類的網絡嵌入方法
2.1定義
為更好地描述所提出的模型及其具體算法,首先給出以下相關符號及其含義,如表1所示。
定義1網絡嵌入:又稱網絡表示學習,給定一個網絡G=(V,E),通過學習一個映射函數f: v→f(v)∈Rd,將網絡結構嵌入到低維向量空間,其中d|V|。映射函數f保留了網絡G的結構信息,使得具有相似結構的節點具有相近的向量表示。
定義2半監督網絡嵌入:給定一個含有少量節點類別標簽L的網絡G=(V,E,L),通過整合給定少量節點標簽與網絡拓撲結構來學習網絡節點的嵌入表示。
2.2模型描述
筆者提出的基于半監督聚類的網絡嵌入方法NESSC,以DeepWalk模型為基礎,最大化觀察源節點與其上下文鄰居節點共現的概率,保留網絡的鄰近結構特征;其次,添加k-means聚類損失強制節點嵌入表示進行聚類,同時利用已知節點的類別標簽對節點聚類過程進行指導,保持網絡的全局潛在聚類結構;最后,添加重構已知節點類別標簽信息損失,聯合訓練優化,學習具有辨別性的嵌入表示。
首先基于頂點個數、類別個數和嵌入維度初始化模型參數。之后,進行N次迭代,每次迭代中,先對節點集進行重新洗牌,再逐點遍歷打亂后的節點集,采樣節點序列,并根據窗口w提取鄰居節點集合,更新聚類平衡參數和學習率,最后使用隨機梯度Adam算法更新節點和類中心的嵌入向量。在針對每個節點的計算過程中,采用負采樣來降低復雜度,計算次數從|V|次減少為m次。遍歷整個節點集合,計算次數為(1+m+k)·w·len,迭代N次,整體計算復雜度為O((1+m+k)·w·len·|V|·N)。由于m,k,w,len,N|V|,所以NESSC方法時間復雜度為O(|V|),可以應用于大規模網絡嵌入學習任務中。
3實驗結果分析
為了充分說明NESSC方法的有效性,在真實數據集Citeseer,Cora及WebKB上進行節點聚類和節點分類2個任務,并將得到的結果與DeepWalk,GEMSEC算法進行比較。
3.1實驗設定
3.1.1數據集
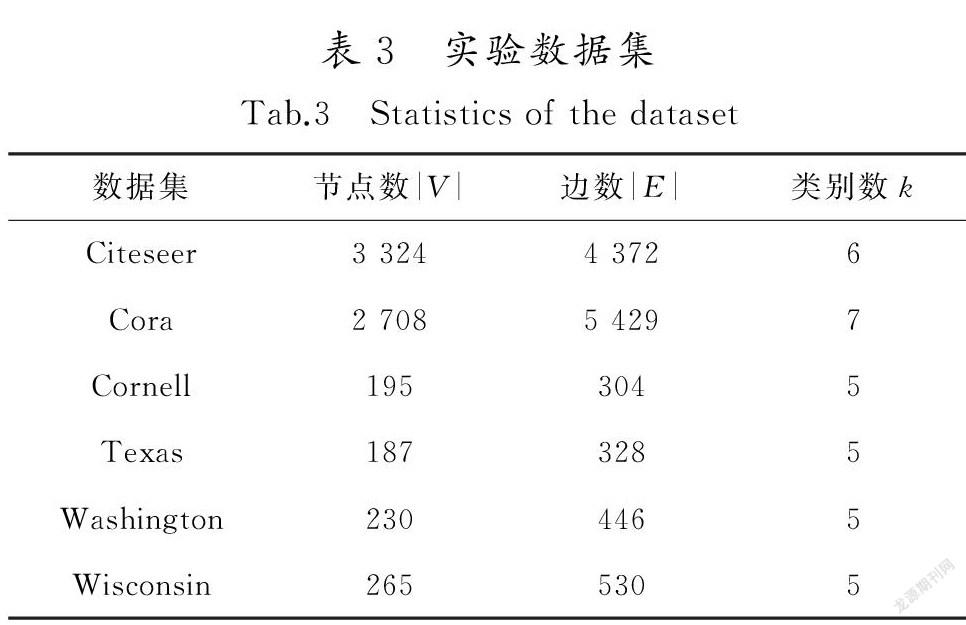
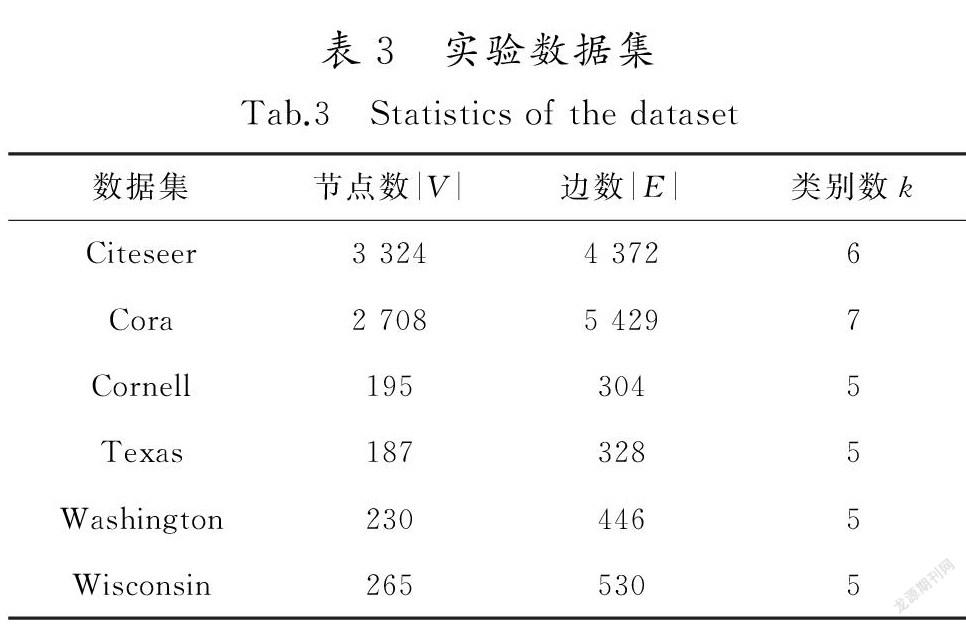
在數據集Citeseer,Cora及WebKB進行評測任務,其中WebKB包括Cornell,Texas,Washington和Wisconsin等4個子數據集。各個數據集去掉孤立點之后,統計信息如表3所示。
3.1.2實驗環境及參數設定
實驗硬件環境采用聯想臺式機,操作系統為Windows7,處理器為 Intel Core i7-3770,內存為 8 GB,硬盤為500 GB,軟件環境采用 Python3.6。
考慮算法比較的公平性,共同參數設置為嵌入維度d=64,負采樣個數m=5,窗口大小w=5,初始學習率ηinit=0.01,最小學習率ηmin=0.001。為了取得最優的節點嵌入向量,針對各數據集的參數設定如表4所示。針對半監督的網絡嵌入方法NESSC,設置已知類別標簽節點的比例為0.05, 01, 0.15, 0.2, 0.25, 0.3,選取方式為隨機選取。
3.2聚類結果及分析
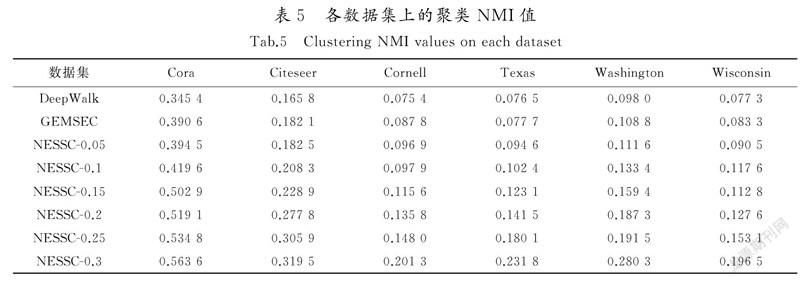
將NESSC學到的嵌入向量用于節點的聚類任務,以此來評估學到嵌入向量的質量。本實驗采用k-means聚類,采用標準互信息NMI[18]評估,進行獨立重復實驗10次,取其平均值作為最終結果。表5記錄了無監督方法DeepWalk,GEMSEC和半監督方法NESSC在Citeseer,Cora及WebKB數據集上的聚類NMI值,其中NESSC-0.05表示采用NESSC方法對已知類別標簽節點為5%的數據集進行實驗,以此類推。
從表5聚類結果可以看出:1)GEMSEC效果優于DeepWalk,在Citeseer數據集上表現更為明顯,NMI值提高4.52%,這說明了強制節點嵌入表示進行聚類,可以揭示網絡社區結構,使學到的節點嵌入表示保持網絡的潛在聚類結構;2)NESSC處理效果明顯優于GEMSEC和DeepWalk,這是因為GEMSEC和DeepWalk屬于無監督的算法,雖然計算簡單,但準確率低。而NESSC充分利用已知節點的標簽信息實現半監督的嵌入表示,因此性能更優,而且隨著已知類別標簽節點的增加,得到的效果更好。在實際應用中,可以通過加入少量節點標簽信息的代價來獲得網絡嵌入算法性能的較大提升。
3.3分類結果及分析
首先利用NESSC方法得到節點的嵌入表示,然后作為節點分類任務的輸入,用分類任務的效果來評價學到嵌入表示的質量。分類采用KNN[19],評估方法采用準確率Accuracy,數據集分割方法采用10折交叉驗證[19],同時為了減弱隨機性,獨立重復進行10次實驗,取其平均值作為最終結果。表6記錄了無監督方法DeepWalk,GEMSEC和半監督方法NESSC在Citeseer,Cora及WebKB數據集上的分類準確率值。
由表6可以看出:1)在數據集Cora,Citeseer,Texas和Wisconsin上,GEMSEC效果略優于DeepWalk,這表明在計算節點嵌入特征的過程中強制節點嵌入表示進行k-means聚類,學習網絡的社區結構,對節點嵌入向量的學習產生一定的積極影響;2)NESSC處理效果明顯優于GEMSEC和DeepWalk,而且隨著已知類別標簽節點的增加,得到的效果更好,這在數據集Texas和Washington上表現尤為明顯。這表明少量節點類別標簽信息的加入可以明顯提升節點嵌入表示的質量。NESSC充分利用少量節點的類別標簽信息實現半監督的網絡嵌入,學習具有區分性的嵌入表示,性能更優,但仍然存在一定的錯誤率,這是因為NESSC屬于半監督模型,加入已知標簽的節點較少,但隨著已知標簽節點的比例增大,NESSC會取得更好的結果。
3.4參數敏感性分析
基于半監督聚類的網絡嵌入方法NESSC含有2個主要參數:聚類損失平衡參數γ和重構已知節點類別標簽信息平衡參數β。選擇數據集Citeseer和Cornell,已知類別標簽節點的比例是20%,用Accuracy進行分析它們的分類準確率。首先,分別對γ和β進行大范圍搜索,發現γ取值范圍為{0.000 1,0.001,0.01,0.1,1},β取值范圍為(0,2]時,NESSC方法性能較好。然后對γ和β的詳細取值作具體分析,結果如圖1和圖2所示。
圖1是改變γ初始值對算法結果的影響。當γ值為0時,不考慮聚類結果對節點嵌入計算的影響。隨著γ值的增大,數據集Citeseer和Cornell的分類準確率逐漸提高,說明聚類過程的加入對計算節點嵌入有積極的影響。當γ值為0.01時,分類準確率最高。之后,又隨著γ值的增大,分類準確率逐漸降低,這說明聚類結果的過多加入會影響節點特征的學習,從而導致學到的嵌入表示質量不佳。由此,在數據集Citeseer和Cornell的實驗仿真中設置γ初始值為0.01。
圖2是改變β值對算法結果的影響。當β值為0時,不考慮重構已知節點類別標簽信息對節點嵌入計算的影響,此時學到的節點嵌入表示缺乏區分性。隨著β值的增大,數據集Citeseer和Cornell的分類準確率逐漸提高,說明重構已知節點類別標簽信息可以積極地影響節點嵌入的計算。對數據集Citeseer而言,當β值為1.8時,分類準確率最高,之后,又隨著β值的增大,分類準確率逐漸降低;對數據集Cornell而言,當β值為1時,分類準確率最高,之后,隨著β值的增大,分類準確率逐漸降低。這說明可以適當運用重構已知節點類別標簽信息結果來提升節點嵌入表示的質量。因此,在數據集Citeseer和Cornell的實驗仿真中,分別設置β值為1.8和1。
4結語
筆者提出的基于半監督聚類的網絡嵌入方法NESSC,首先在計算節點嵌入特征的過程中強制節點進行k-means聚類,同時利用已知節點類別標簽信息來指導其聚類過程,以此來保持網絡的潛在社區結構。其次,通過重構已知節點類別標簽信息來學習具有區分性的嵌入表示。在數據集Citeseer,Cora及WebKB上聚類和分類實驗結果說明,NESSC融入節點類別標簽信息提高了網絡嵌入的質量。
現實網絡中節點不僅包含復雜的拓撲結構信息,還擁有豐富的屬性信息。下一步工作中,將在本文的基礎上融入節點屬性信息,進一步提高網絡嵌入的質量。另外,異構信息網絡因為包含不同類型的節點和邊,可以更加完整自然地對現實世界的網絡數據進行建模,后續也將對此展開深入探究。
參考文獻/References:
[1]GOYAL P, FERRARA E.Graph embedding techniques, applications, and performance: A survey[J]. Knowledge Based Systems, 2018,151:78-94.
[2]齊金山, 梁循,李志宇, 等. 大規模復雜信息網絡表示學習: 概念、方法與挑戰[J]. 計算機學報,2018,41(10):2394-2420.
QI Jinshan, LIANG Xun, LI Zhiyu,et al. Representation learning of large-scale complex information network:Concepts,methods and challenges[J]. Chinese Journal of Computers, 2018,41(10):2394- 2420.
[3]HAMILTON W L, YING R, LESKOVEC J. Representation learning on graphs: Methods and applications[J]. IEEE Data Engineering Bulletin, 2017: 1709.05584.
[4]ZHANG Daokun, YIN Jie, ZHU Xingquan, et al. Network representation learning: A survey[J]. IEEE Transactions on Big Data, 2018:2850013.
[5]涂存超,楊成,劉知遠,等. 網絡表示學習綜述[J]. 中國科學:信息科學,2017,47(8):980-996.
TU Cunchao,YANG Cheng,LIU Zhiyuan, et al. Network representation learning: An overview[J].Scientia Sinica (Informationis),2017,47(8): 980-996.
[6]WANG J. Locally linear embedding[C]// Geometric Structure of High-Dimensional Data and Dimensionality Reduction. Heidelberg:[s.n.], 2012:203-220.
[7]BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering[J]. Advances in Neural Information Processing Systems,2002,14(6):585-591.
[8]LE Q, MIKOLOV T. Distributed representations of sentences and documents[C]//Proceedings of the 31th International Conference on Machine Learning.Beijing:[s.n.],2014:1188-1196.
[9]PEROZZI B, Al-RFOU R, SKIENA S. DeepWalk: Online learning of social representation[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. NewYork: ACM, 2014:701-710.
[10]GROVER A, LESKOVEC J. Node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. NewYork: ACM, 2016:855-864.
[11]TANG Jian, QU Meng, WANG Mingzhe, et al. Line:Large-scale information network embedding[C]//Proceedings of the 24th International Conference on World Wide Web.Florence:[s.n.], 2015: 1067-1077.
[12]CAO Shaosheng, LU Wei, XU Qiongkai. GraRep: Learning graph representations with global structural information[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management.New York:ACM, 2015:891-900.
[13]WANG Xiao, CUI Peng, WANG Jing, et al. Community preserving network embedding[C]//The 31st ?AAAI Conference on Aritificial Intelligence. [S.l.]:[s.n.],2017:1-7.
[14]ROZEMBERCZKI B, DAVIES R, SARKAR R, et al. GEMSEC: Graph embedding with self clustering[J]. Computer Science, 2018: arXiv:1802.03997.
[15]CHEN Jifan, ZHANG Qi, HUANG Xuanjing. Incorporate group information to enhance network embedding[C]//Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. New York:ACM, 2016:1901-1904.
[16]TU Cunchao, ZHANG Weicheng, LIU Zhiyuan, et al.Max-margin deepwalk: Discriminative learning of network representation[C]// Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. NewYork:[s.n.], 2016: 3889-3895.
[17]KINGMA D P, BA J. Adam: A method for stochastic optimization[J]. Computer Science, 2014: eprint arXiv:1412.6980.
[18]STREHL A, GHOSH J. Cluster ensembles: A knowledege reuse framework for combining multiple partitions[J]. Journal of Machine Learning Research, 2003, 3(1): 583-617.
[19]周志華. 機器學習[M]. 北京: 清華大學出版社, 2016.
