基于隱馬爾科夫模型集成學習的廣播關鍵詞檢測
2019-09-10 07:22:44杜淼黃天淏邊彤顏逸為余勤雒瑞森
河南科技 2019年35期
杜 淼 黃天淏 邊 彤 顏逸為 余 勤 雒瑞森


摘 要:由于無線電技術的日益成熟,盜用正常廣播頻段進行其他活動的非法廣播對國民經濟和安全造成相當大的危害,因此對非法廣播的監測非常重要。本文集成隱馬爾科夫模型對廣播關鍵詞進行識別,進而監測非法廣播。在試驗中,首先對采集的非法廣播進行人工切割與標定用于訓練,然后研究基于集成學習的方法組合多個模型,使用投票規則得到最終結果。將集成學習的PocketSphinx系統與單一模型進行比較,試驗結果顯示,與單一模型84.8%的識別率相比,集成的PocketSphinx系統識別率達到92%,并且具有更好的穩定性。
關鍵詞:關鍵詞識別;PocketSphinx;隱馬爾科夫模型;集成學習
中圖分類號:TN912.34 文獻標識碼:A 文章編號:1003-5168(2019)35-0008-04
Application of Hidden Markov Model with Ensemble Learning
in Broadcast Keyword Detection
DU Miao1 HUANG Tianhao BIAN Tong1 YAN Yiwei1 YU Qin1 LUO Ruisen1
(1.College of Electrical Engineering, Sichuan University,Chengdu Sichuan 610000;2. College of Electronic Engineering and Automation, Guilin University of Electronic Technology,Guilin Guangxi 541004)
Abstract: Due to the increasing maturity of radio technology, illegal broadcasts that use the normal broadcast band for other activities have caused considerable harm to the national economy and security, so the monitoring of illegal broadcasts is very important. This paper integrated hidden Markov models to identify broadcast keywords, and then monitored illegal broadcasts. In the experiment, the illegal broadcasts collected were first manually cut and calibrated for training, then the method based on ensemble learning was used to combine multiple models, and the voting rules were used to obtain the final results. Comparing the integrated learning PocketSphinx system with a single model, the experimental results show that compared with the single model's 84.8% recognition rate, the integrated PocketSphinx system has a recognition rate of 92% and has better stability.
Keywords: keyword recognition;PocketSphinx;Hidden Markov Model;ensemble learning
隨著無線電技術應用的成熟,部分不法分子采用盜用調頻廣播的手段進行非法活動,擾亂正常廣播秩序,對國民經濟和安全造成了嚴重威脅。在實際的應用過程中,非法廣播關鍵詞識別往往存在諸多復雜問題,例如,存在設備和環境影響產生的噪聲,沒有標準數據集進行訓練,人聲混合等。因此,本文的研究環境是一個非常復雜的實際應用場景。隱馬爾科夫模型(Hidden Markov Model,簡稱HMM)可分為:離散隱馬爾科夫模型(DHMM)、連續隱馬爾科夫模型(CHMM)和半連續隱馬爾科夫模型(SCHMM)[1]。SCHMM作為DHMM和CHMM的折衷方法,盡量避免DHMM因矢量化信息造成信息損失和CHMM由于待估計參數過多需要大量訓練集[2,3]。
由于實際的非法廣播信號中存在噪聲、不同人聲和方言等問題,所以本研究采用集成學習的方法提高模型的魯棒性。將不同模型結合可能會帶來以下好處[4]:從統計學角度來看,由于學習任務假設空間很大,可能有多個假設在訓練集上達到同等性能,結合多個模型,避免誤選而導致泛化能力不佳的問題;從計算角度來看,多次運行的結合,可以降低陷入局部極小點的風險;結合多個模型,可以擴大假設空間,有可能更好地接近未在假設空間內的最優解。
為了更好地檢測非法廣播中的關鍵詞,本文在PocketSphinx系統[5]上使用集成學習的方法,將多個模型識別的關鍵詞結果通過投票機制獲得最終的識別結果,最后通過非法廣播試驗證明采用集成學習的方法能獲得更高的識別率。
1 相關背景工作
為了監測廣播是否非法,打擊非法頻段的廣播,本文將利用集成學習的PocketSphinx系統對廣播進行關鍵詞識別。
1.1 SCHMM模型
隱馬爾科夫模型是一種時間序列的概率模型。該模型描述了由一個隱藏的馬爾科夫鏈隨機生成不可觀測的狀態隨機序列,再由各個狀態生成一個觀測而產生觀測隨機序列的過程。在語音系統中,通常以音素[6]為基本識別單位。從語音中提取音素特征,狀態之間的轉移表示了音素之間的關系和鏈上每個狀態的一個概率分布。SCHMM可以表示為:
[λ={π,A,B}]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (1)
式中,[π]為SCHMM的初始化參數;A為狀態轉移矩陣;B為觀察值概率矩陣。
[A=a0N×N],N為模型的狀態數,記N的狀態為[s1,...,sN],記[t]時刻馬爾科夫鏈所處狀態為[qt],顯然[qt∈(s1,...,sN)],則:
[ai,j=P(qt+1=si|qi=si) 1≤i , j≤N]? ? ? (2)
[B=bjkN×M],其中,[bjk]滿足以下條件:
[bjk=P(oi=vk|qt=sj) 1≤j≤N ,1≤k≤M]? ? ? (3)
HMM是一個雙重隨機過程,在概率統計學的基礎上解決實際應用中的三個問題:評估問題、解碼問題、學習問題。HMM的參數[λ={π,A,B}]通過Baum-Welch算法利用觀測到的數據進行估計,由估算的HMM組成分類器,實現對觀測序列的分類。
1.2 PocketSphinx
PocketSphinx是一種輕量級的語音識別系統,其主要基于隱馬爾科夫模型,程序主要使用C語言進行編寫。PocketSphinx是一種應用在大詞匯量連續語音識別系統的開源項目,由于其成本低且開源,所以本文將對PocketSphinx系統在非法廣播中的關鍵詞檢測進行應用與開發。PocketSphinx語音識別系統是一種包含多種技術的系統。其中,MFCC特征提取為Mel Frequency Cepstral Coefficents,是一種能準確包絡語音短時功率譜的一種方法[6]。
1.3 集成學習
集成學習通過將多個分類器進行結合來完成學習任務,通常可以獲得比單一分類器更顯著的優勢[7]。集成學習的一般結構為:先產生一組“個體學習器”,再使用某種策略將它們結合起來,其中個體學習器一般由訓練集數據產生。在學習任務中,最優點可能不存在整個假設空間中,使用單一模型進行訓練時,無論如何訓練都不可能獲得最優解,通過結合多個模型,有可能學習得到更好的近似[7]。
2 試驗數據與方法
本試驗將集成學習應用到PocketSphinx系統,使用截取的關鍵詞片段對模型進行訓練。為了進一步提高PocketSphinx系統在廣播檢測中的識別率,本節使用了集成學習的方法,目的是訓練對不同關鍵詞敏感的模型,提高非法廣播的識別率。本文對非法廣播的判斷依據為,如果廣播中出現了試驗中定義的非法關鍵詞,則認為廣播為非法廣播,具體試驗過程將在本節詳細展示。
2.1 試驗數據
本次數據進行識別的關鍵詞使用了首字母表示,如廣播-gb。本試驗的原始廣播數據長短不一,所以使用軟件Audacity對原始數據集進行了人工切割,將原始的廣播數據切分成1min左右的數據,圖1展示了切分割好的一個非法廣播語音中的部分,時間長度為1min,其中紅色虛線框部分為非法關鍵詞cdkf、lglc,其他部分為廣播的其他內容。
圖1 一條廣播語音中的信息
2.2 試驗方法
本試驗研究了一個模型的訓練過程,先將語音數據進行歸一化,減少語音大小對識別效果的影響;將每個關鍵詞設置不同權重,對模型進行訓練,得到訓練好的單一模型;使用模型對測試集進行識別,得到識別后的文本信息。其中,關鍵詞權重設置越高,表示對識別該關鍵詞越嚴格;反之,表示越容易。使用集成學習時,本文將生成多個模型進行試驗,最后將每個模型生成的文本信息通過投票的方式判斷測試語音是否非法。
3 試驗結果
3.1 單一模型
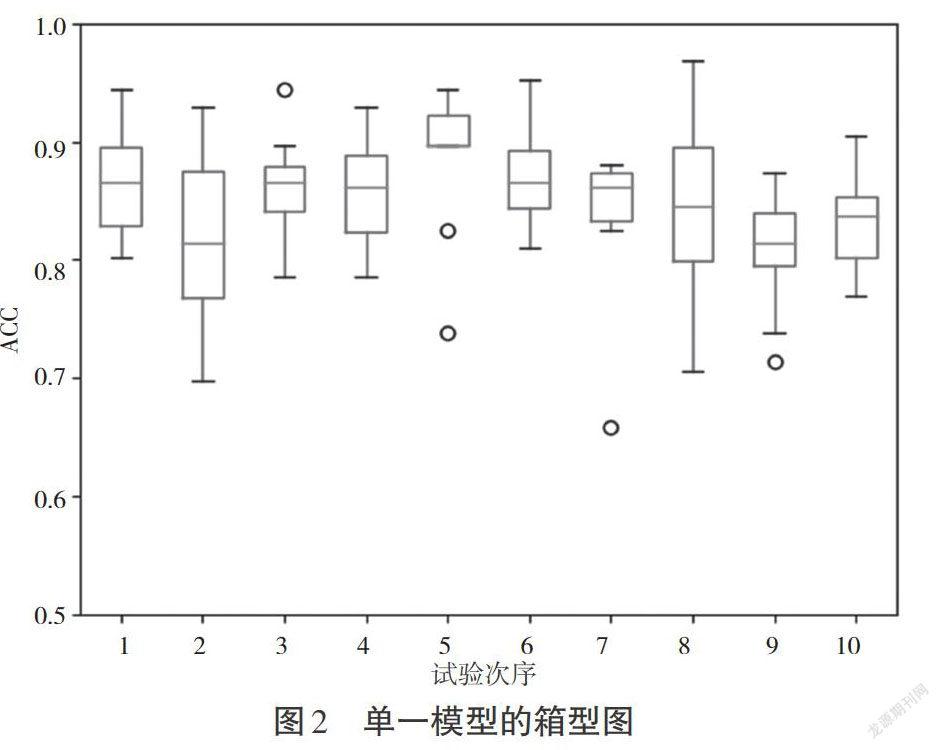
在訓練中,以[0,20]中隨機抽取的值作為關鍵詞權重,得到新的單一模型,通過100次試驗,得到平均識別率為84.8%。箱型圖是一種用作顯示數據分散情況的統計圖,直觀展示了異常值等數據分布特征,本試驗將使用箱型圖進行展示,圖2展示了100次試驗的結果。其中,橫軸為試驗次序(將100次試驗平均分成10次進行),縱軸為識別率(ACC)。
圖2 單一模型的箱型圖
3.2 多個模型
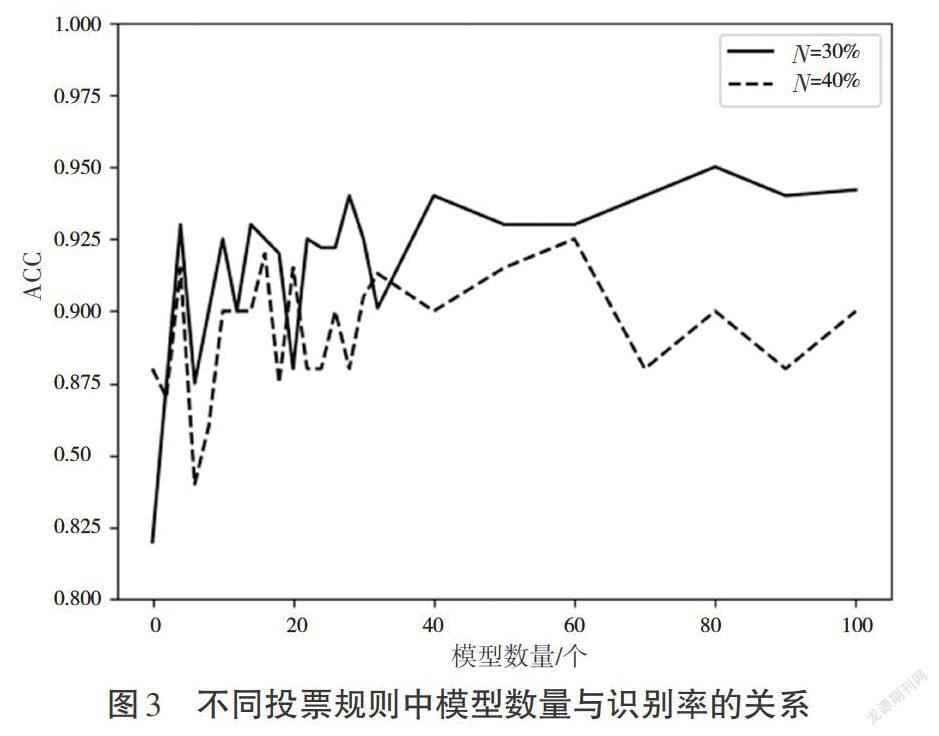
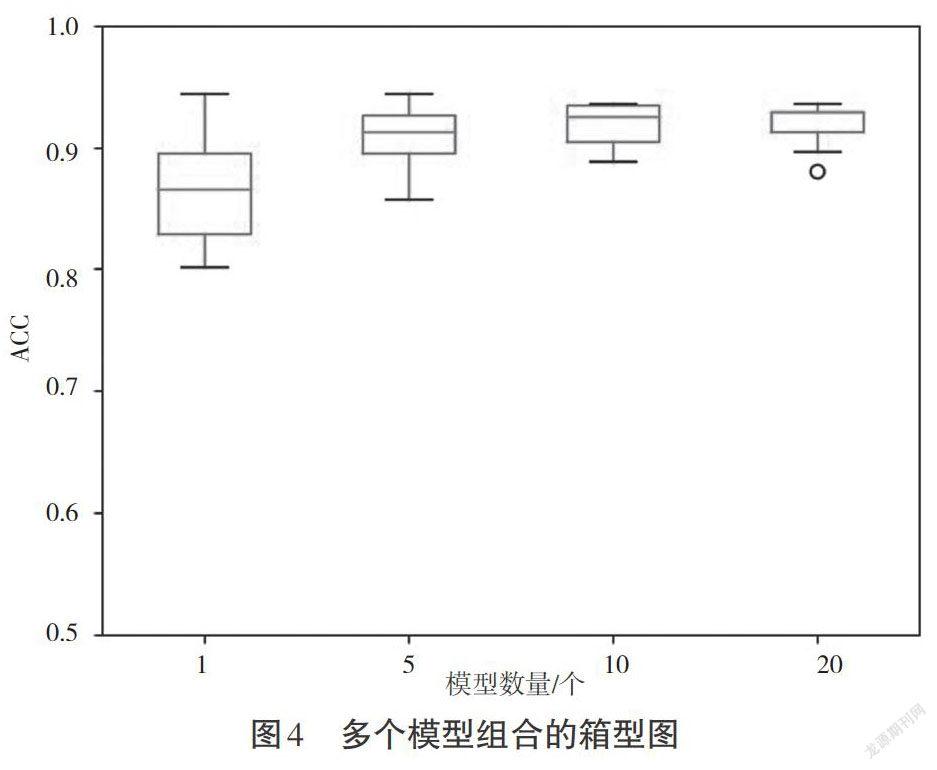
為了訓練多個不同的模型,本試驗從[0,20]中隨機抽取值作為關鍵詞權重,并重復抽取多次訓練多個權值不同的模型。使用多個模型對測試語音進行識別,最后得到多個語音文本,再使用投票規則,最后計算識別率。本次試驗模型數量為(1,100],投票規則為識別的關鍵詞數量大于模型數量(超出比例為[N]),則認為出現了該關鍵詞。本文通過固定模型數量(5,10,20),每種集成模型連續進行10次試驗,得到試驗結果,如圖3和圖4所示。其中,橫軸(Number)為集成的模型數量,縱軸(ACC)為通過投票規則后的識別率。
<E:\新建文件夾\2月份\未做\河南科技201935\內文排版文件-河南科技(創新驅動)2019年第35期\Image\10-圖3.pdf>[模型數量/個][ACC][N][N]
圖3 不同投票規則中模型數量與識別率的關系
圖4 多個模型組合的箱型圖
4 討論
4.1 集成學習對識別率的提高
集成學習對識別率的提高表現在兩個方面:一是最低識別率的提高;二是總體識別率的提高。通過圖2單一模型的箱型圖可以看到,整個假設空間中存在識別率為97%的解,但是從統計的均值來看,單一模型的識別率在81%~87%,中位數在85%上下浮動,并且大量數據在90%以下,使用單一模型進行識別可能面臨陷入識別率較低點的風險。由圖2可以明顯看到,試驗中出現較多的異常值點。通過單一模型的多次試驗可以得出,本次試驗數據中存在識別率較高的點,但是隨機抽取權重后的模型識別率不高,整個系統的識別率不穩定。從圖3可以看出,采用集成學習后,整體識別率提高,有效地減小假設空間,使平均識別率提高,并且隨著集成模型的增加,識別率逐漸穩定在90%以上。通過圖4多次試驗可以看到,隨著模型的增加,數據逐漸集中,并且識別率有了明顯的提高。
4.2 集成模型數量的影響
4.2.1 集成模型數量對識別率的影響。由于訓練片段與測試集的不同,為了得到較好的識別率,關鍵詞的權重在每個測試集中的權重也不相同。圖4展示了多個模型組合的箱型圖,每個集成學習箱型圖進行了10次試驗。從圖4中可以看到,通過集成學習,整個系統的平均識別率達到92%,高于單一模型84.8%的識別率,其中中位數上升到93%,大量數據保持在90%以上。通過圖3與圖4的試驗結果可以看到,集成學習方法可以有效地減小假設空間,使平均識別率提高到92%。
4.2.2 集成模型數量對識別穩定性的影響。由圖2可知,單一模型試驗頻繁出現異常值點,說明單一模型容易進入一個局部糟糕的點,系統穩定性較差。由圖4可知,模型數量為20時出現了一個異常值點,但是該點識別率高于單一模型的平均識別率,整個系統在識別率上展示了較強的穩定性。同時,使用集成學習使模型減少了陷入糟糕局部解的風險,使數據集中較好的識別率接近識別率較高的點。
5 結語
本文將集成學習的PocketSphinx系統用于廣播關鍵詞檢測,這是一種監測非法廣播的有效手段。本文的試驗數據為實地采集數據,在本文使用的數據集和關鍵詞中,通過集成學習試驗結果與單一模型試驗結果可以發現,集成學習PocketSphinx系統在識別率和穩定性上的效果明顯。試驗結果表明,集成不同權重的PocketSphinx模型可以有效提高關鍵詞的識別率和系統的穩定性。但是,由于本文采集數據中噪聲低的數據較少,所以本試驗沒有從訓練數據來調整模型的多樣性。本文使用的廣播數據為中文數據,但是非法廣播關鍵詞的檢測可以應用不同語種,為了更好地打擊違法犯罪行為,利用語音關鍵詞識別對更多地區進行廣播監測將是非常必要的手段。本文使用集成學習的PocketSphinx模型可以進一步提高中文關鍵詞識別率和系統穩定性,并在其他語言的關鍵詞識別方面具有一定的參考價值。
參考文獻:
[1]向東,劉虎,陳先橋,等.半連續隱馬爾科夫模型脫機阿拉伯手寫識別[J].武漢理工大學學報(信息與管理工程版),2011(3):349-353.
[2]嚴斌峰,朱小燕,張智江,等.基于鄰接空間的魯棒語音識別方法[J].軟件學報,2007(4):878-883.
[3]高家寶,來羽.一種新的HMM/SVM混合語音識別模型[J].控制工程,2016(11):1802-1807.
[4]Dietterich T G.Ensemble methods in machine learning[C]//International workshop on multiple classifier systems.2000.
[5]袁翔.基于Sphinx的機器人語音識別系統構建與研究[J].電腦知識與技術,2017(7):154-155.
[6]邵明強,徐志京.基于改進MFCC特征的語音識別算法[J].微型機與應用,2017(21):48-50.
[7]余恩澤,努爾布力,于清.一種基于集成學習的釣魚網站檢測方法[J].計算機工程與應用,2019(18):81-88.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
