基于多部情感詞典和規則集的中文微博情感分析研究
2019-09-13 03:37:04吳杰勝
計算機應用與軟件 2019年9期
吳杰勝 陸 奎
(安徽理工大學計算機科學與工程學院 安徽 淮南 232001)
0 引 言
微博是近些年來一個新生的適用于大眾的社交媒體平臺,隨著移動互聯網的普及,大眾對微博的使用率越來越高,微博也得以快速發展。廣大的用戶群體都可以通過微博來發表自己對當前的一些熱點話題的看法,所以他們每天都在提供海量且豐富的觀點文本數據,而這些數據中包含著很多情感信息。如何充分挖掘情感信息并進行分析就是情感分析。情感分析在當今的研究很廣泛,提取情感信息對社會發展起到一定的作用,而微博除了作為一個社交媒體平臺之外,還具有其他特性,因此對微博的情感分析研究至關重要。
目前國內外都在對微博進行研究,但中文微博和英文微博的研究進展差距很大,英文微博的研究成熟度高于中文微博,而且中文微博與英文微博的特性幾乎不同,因此如何能利用中文微博情感信息來進行研究分析是我們現在要做的工作。本文利用多部情感詞典和中文語義規則集相結合的方式判斷中文微博的情感極性。
1 相關工作
文獻[1]中指出情感即文本作者的意見和觀點,因此對情感的分析也可以理解為對意見的挖掘,文本意見挖掘屬于數據挖掘的子類,主要是利用現有的計算機技術挖掘出蘊含在文本間的觀點、情緒等元素。在當今可以通過構造相應的情感詞典和利用機器學習算法來對微博文本進行情感分析、極性分類。構造情感詞典來對微博進行情感分析出現比較早,而且它對微博文本這種細粒度的情感分析效果極佳。文獻[2]就是在基礎情感詞典的基礎上,構造了兩種計算詞匯語義的情感權值方法。文獻[3]也在基礎情感詞典的基礎上,構造了一種分類器,可以對文本語義之間的歧義進行消除,從而提高情感分析準確率。
基于機器學習的方法來進行情感分析,主要是通過選取一些特征來標注訓練集和測試集,接著利用樸素貝葉斯、支持向量機等分類器進行情感分類。文獻[5]利用支持向量機或樸素貝葉斯與支持向量機相結合的方法對微博進行情感分析。文獻[7]首先構造微博語料庫,再用樸素貝葉斯算法進行分類。
總之,微博情感分析常用的兩種方法都有一定的作用,但誰也不能做到更高的準確率,只能在這個基礎上不斷地加以改進方法提高準確性。基于情感詞典的方法擅長處理細粒度的文本情感分析,因此本文主要也是利用情感詞典,在此基礎上加以改進,并結合文本之間的語義規則集來對微博進行情感分析,最后通過各個部分的情感權值加權求和得到微博的情感極性。微博的整體情感分析流程圖如圖1所示。
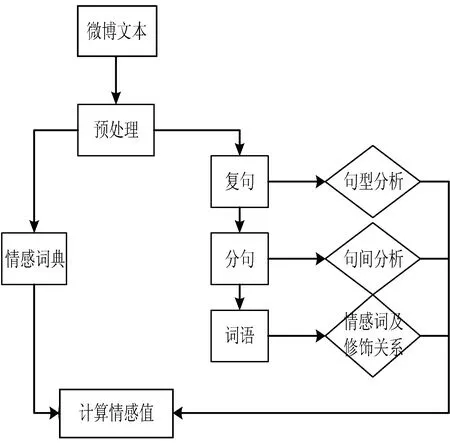
圖1 微博整體情感分析流程
2 情感詞典的構建
目前國外的情感詞典《General Inquirer》完善度很高,但在國內還沒有一部這樣比較完善的詞典,所以對微博來說,有一部完善的情感詞典是很有必要的。現在國內使用常見的代表性情感詞典有知網HowNet情感詞典,臺灣大學的正、負面情感詞典和大連理工大學中文情感詞典庫等等。所以本文在此基礎詞典的基礎上進行整合和優化,構建一個擴展的多部情感詞典,同時還需要單獨構建一個微博特定領域的情感詞典來一起組成微博情感詞典,從而進行微博情感分析。
2.1 微博文本的預處理
微博文本具有元素多樣性、隨意性、口語化等特點,所以需要進行預處理。預處理步驟如下:
1) 將網頁中的鏈接、圖片、視頻、動畫刪除;將“@+用戶名”刪除;將“#話題#”刪除。這些內容雖對微博情感分析有一定作用,但是影響不大,可以刪除。
2) 將文本中的繁體字、英文等其他語言都翻譯成中文,這是為了后續工作的方便,可使用特定的工具來進行翻譯。
3) 保留微博文本中的表情符號。因為表情是情感狀態的外在表現,與情感有關,可以參與情感權值計算。
4) 分詞,本文使用中科院ICTCLAS軟件進行分詞與詞性標注。
5) 刪除停用詞,比如助詞“的”,代詞“她”、“他”等之類的詞。
在預處理完成之后,微博文本就是詞語連接成串的形式,比如“我國運動員武大靖在短道速滑男子500米決賽中奪冠。”就會變為{我國,運動員,武,大靖,在,短道速滑,男子,500,米,決賽,中,奪冠 }。
2.2 構建多部情感詞典
目前中文情感詞典還沒有完整成熟的情感詞典,所以除了構造基礎情感詞典外,還有否定詞詞典和雙重否定詞詞典、程度副詞詞典、關系連詞詞典、表情符號詞典。
2.2.1基礎情感詞典
基礎情感詞典是取自大連理工大學的中文情感詞典庫。這個詞典庫將情感詞分成了五個強度和三類詞。本文用數字1表示正面詞,數字2表示反面詞,0表示中性詞且它的權值為0。示例如表1所示。
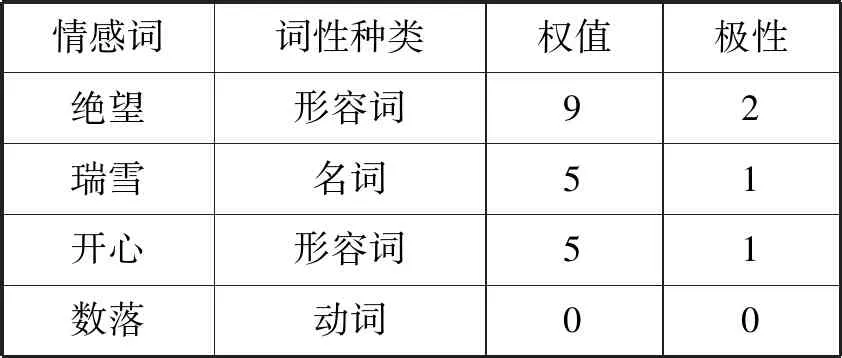
表1 基礎情感詞典示例
2.2.2否定詞詞典和雙重否定詞詞典
否定詞詞典包括否定副詞和反問詞這兩部分。文獻[10]中指出否定副詞和反問詞修飾情感詞時,都會改變詞的情感極性,但反問詞語氣更強,而雙重否定不會改變詞的情感極性,但是語氣會更加強烈。通過人工篩選共獲取25個否定詞,示例如表2所示。

表2 否定詞詞典和雙重否定詞詞典示例
2.2.3程度副詞詞典
程度副詞詞典來自于知網詞典庫。將這些詞一共分為6個等級。等級分別是超、最、很、較、稍、欠。分別對這6個等級給予一定的權值,對所修飾的情感詞的情感強度擴大一定的倍數。示例如表3所示。
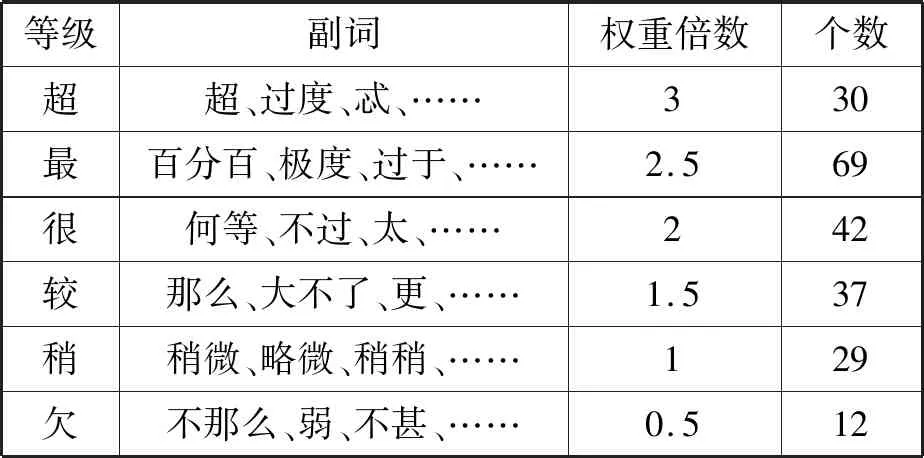
表3 程度副詞詞典示例
2.2.4關系連詞詞典
關系連詞主要有轉折、讓步、遞進、因果、假設等關系,它們在句子與句子之間的連接起到作用。本文收集整理常用的一些詞構建了一個關系連詞詞典,并賦予一定的權值,示例如表4所示。
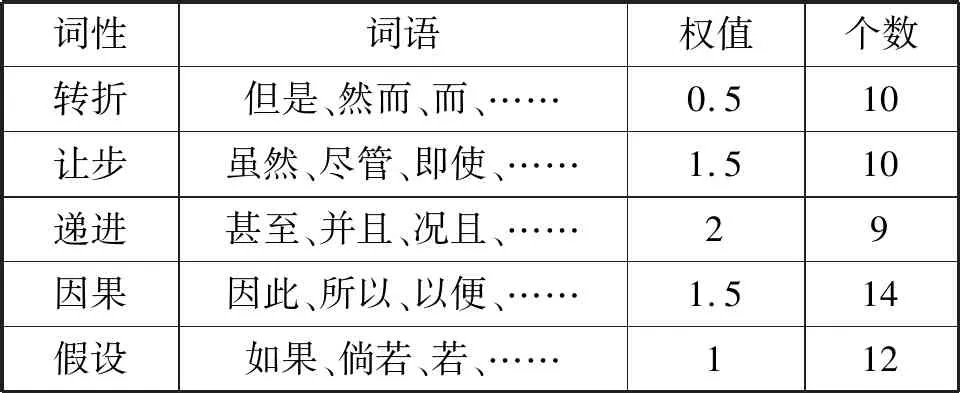
表4 關系連詞詞典示例
2.2.5表情符號詞典
微博表情在微博文本中具有很強的情感傾向性,可以通過它去判斷微博情感極性有一定的作用。本文通過微博抓取了一些頻率使用比較高的部分表情構造表情詞典,共計217個表情。示例如表5所示。

表5 表情符號詞典示例
2.3 微博領域情感詞典的構建
由于基礎的情感詞典還不完整,對情感詞的概括是有限的,所以還需要針對微博上一些特有的情感新詞進行識別,從而對這些新詞集合構建一個詞典。首先要基于統計信息來識別新詞,然后在新詞中進行情感識別。
2.3.1基于統計信息的新詞識別
文獻[6]中給出三個定義,分別稱作字串頻數、內部耦合度、鄰字集信息熵,一個字串能否成詞與這三個定義有關。微博文本是由一連串詞語組成的文本,首先我們用一個長字串來表示微博文本,同時將一個新詞的成詞長度設定為一個值,本文設定為7。同時再考慮上面三個定義,它們每個都要設定一個參數閾值,如果有任何一個條件不滿足,即超過閾值范圍,則這個字串不是一個詞。最后剩下的能構成的詞語集合中,仍需要比對情感詞典中的詞語,若該詞在已有的詞典中找不到,即成為新詞。
2.3.2新詞情感分析與PMI算法改進
通過以上方法能識別并挖掘出新詞,但是對這些詞的情感極性還需要繼續識別,從而構建出一個微博特定領域的情感詞典。首先根據以上方法識別出新詞,按照詞頻進行統計并排序,按照從上到下的方式來篩選,篩選出情感極性較強而且詞頻比較高的詞語作為種子詞。然后對這些詞的情感極性作出判斷,緊接著利用PMI算法計算其他未知詞與它們之間的語義相似度,最后計算未知新詞的情感極性,方法如下:
點互信息主要是可以計算詞與詞之間的相似度。兩個詞w1和w2之間的相似度計算公式為:
(1)
式中:P(w1,w2)表示w1、w2共同出現的概率,p(w1)、p(w2)分別表示w1、w2單獨出現的概率。
w1表示未知詞,w2表示種子詞,若式(1)的計算結果較大即相似度高,則可知兩個詞情感極性相同,否則就不同。但僅僅計算一對詞的語義相似度在微博情感分析中不具有說服力,所以本文在考慮這個的基礎上,在詞閾的范圍內選取了30對正負面情感極性的種子詞,同時考慮到使用頻率高的表情元素,選取了5對正負面情感極性表情符號作為種子詞,一起構成正面的情感詞集合WP和負面情感詞集合WN,用來考察多詞之間的語義相似度。同時對PMI公式進行改進,得出新詞w的情感極性判斷的新公式:
(2)
式(2)的值如果大于0,則新詞w的情感極性為正面;等于0,新詞w的情感極性為中性;小于0,新詞w的情感極性為負面。
最后一起構建成微博特定領域的情感詞典,本文識別并挖掘出2018年微博新詞共計164個,將這些詞分為4個級別,并賦予一定權值,示例如表6所示。
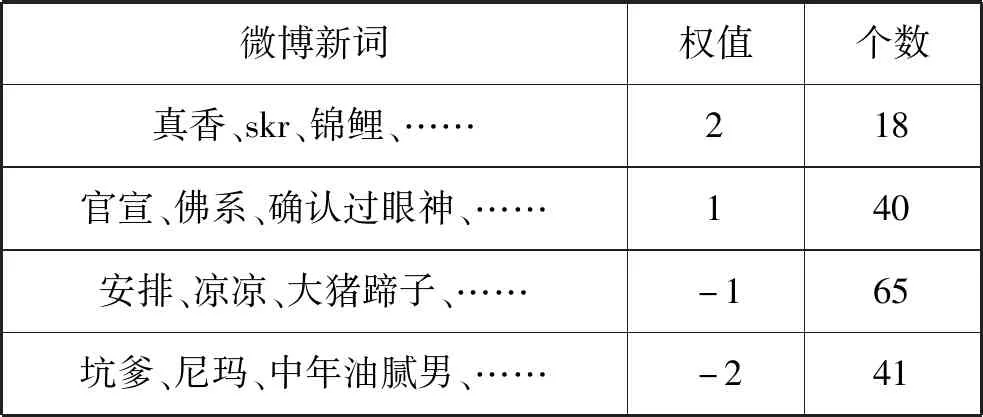
表6 微博新詞詞典示例
3 微博文本規則集的情感分析
微博文本也是普通文本,都是由漢字等其他元素構成的表達文本,而文本之間肯定存在著一些語法關系和語義規則,它們對文本的情感分析也有一定作用。
3.1 句間分析規則
一條微博文本可以通過標點符號劃分成若干個復句,一條復句可以分成若干個分句,句間分析規則就是考慮分句與分句之間的關系,而句間關系主要有三類:轉折、遞進、假設。這里用S表示整個復句,Si表示復句的各個分句。定義集合{S1,S2,…,Si}為復句的分句集合,Ri表示句間規則對分句Si的情感權值。
3.1.1轉折關系規則
轉折關系中,基本都會實現前后的情感翻轉作用,轉折之前的分句情感會變弱,而主要突出后面分句的情感,后面分句與前面分句的情感極性相反。規則定義如下:
1) 若復句S中只有單一的轉折后接詞出現(如“但”,“可是”,“卻”等)在分句Si中,則Si之前的分句權值Ri都設為0,Si之后的分句權值Ri都設為1。
2) 若復句S中只有單一的轉折前接詞出現(如“雖然”,“如”,“盡管”等)在分句Si中,則Si之前的分句權值Ri都設為1,Si之后的分句權值Ri都設為0。
3) 若復句S中出現成對的轉折連接詞(如“雖然…但是…”等),且轉折后接詞出現在分句Si中,則Si之前的分句權值Ri都設為0,Si之后的分句權值都Ri設為1。
3.1.2遞進關系規則
遞進關系,顧名思義,在這個關系規則中,復句的每個分句根據從前到后的順序逐漸增強情感。規則定義如下:
若復句S中出現遞進關系的連接詞(如“更”,“更加”,“更重要的是”等),則分句的權值為:
Ri=1Ri+1=1.5 …Rj=1+0.5×(j-i)
3.1.3假設關系規則
假設關系建立在現實情況中的一種設想,它表達的情感主要在假設復句的前半分句,而對后半分句的情感相對弱化一些。比如:如果A,那么B。則句子強調的是內容A。
1) 若復句S中未出現否定的假設連接詞,但是出現假設關系的后接詞(如“那么”),且假設后接詞出現在分句Si中,則Si之前的分句權值Ri都設為1,Si之后的分句權值Ri都設為0.5。
2) 若復句S中出現否定的假設連接詞,而且假設后接詞(如“那么”)出現在分句Si中,則Si之前的分句權值Ri都設為-1,Si之后的分句權值Ri都設為-0.5。
上面描述的這三種句間關系都能影響到整個微博文本的情感極性,所以情感分析中要考慮到它們。至于其他的句間關系如因果、并列等,對情感分析的影響可以忽略不計。
3.2 句型分析規則
上一節所說的是復句的分句之間的關系,這一節說明的是復句的句型對整個文本的情感極性的影響。本文主要討論陳述句、疑問句、反問句和感嘆句這四類常見句型。它們常以“?”、“!”、“。”等標點符號結尾。一個文本用D來表示,則文本分割成各個分句即復句,用集合定義為{D1,D2,…,Di,…,Dn}。復句用Di來表示,定義Ti為句型規則對復句Di的情感權值。具體的規則定義如下:
1) 如果微博文本中有復句Di以感嘆號“!”結尾,則表示此復句為感嘆句,它的權值Ti設為1.5。
2) 如果微博文本中有復句Di以反問號“?”結尾且結尾處有反問標志詞或者沒有以反問號“?”結尾但有反問標志詞,則表示此復句為反問句,它的權值Ti設為-1。
3) 如果微博文本中有復句Di以反問號“?”結尾且結尾處無反問標志詞,則表示此復句為疑問句,它的權值Ti設為0。
4) 如果微博文本中有復句Di以句號“。”等其他標點符號結尾,則表示此復句為陳述句,它的權值Ti設為1。
4 微博綜合情感計算
本文基于多部情感詞典和規則集的微博情感分析,對微博從詞到句進行整體綜合情感計算。用D表示整個文本,文本中各個復句用Di表示;S對應一個復句Si表示復句中的各個分句;E表示情感權值,Ri表示分句的句間關系規則情感權值,Ti表示復句的句型關系規則情感權值,seni表示詞典匹配得到的權值。
1) 詞語情感值E(Wi)計算公式為:
E(Wi)=N×A×seni
(3)
式中:N表示情感詞前對應的否定詞或者雙重否定詞,A表示情感詞前對應的程度副詞,seni表示情感詞與詞典匹配得到的權值,Wi表示情感詞語。
詞語的情感權值計算不僅與它自身的權值有關,還與在其前面修飾的程度副詞、否定詞有關,所以在情感權值計算時要將它們考慮進去。
2) 分句情感值E(Si)計算公式為:
(4)
3) 復句情感值E(Di)計算公式為:
(5)
4) 文本情感值E的計算公式為:
(6)
5) 表情情感值Em計算公式為:
(7)
6) 微博情感值Elast計算公式為:
Elast=m×E+n×Em
(8)
式(8)表示微博的最終情感值計算,m和n表示文本情感值和表情情感值在微博情感權值計算中所占分量的大小,本文根據文獻[9]中分析分別設置為0.6和0.4,計算得出Elast的大小。如果Elast大于0,則表示此微博的情感傾向為正面的,如果Elast小于0,則表示此微博的情感傾向為負面的,如果Elast等于0,則表示此微博情感為中性的。
5 微博情感分析實驗
5.1 實驗方法
首先通過爬蟲工具爬取了微博上兩個相關的微博話題,然后對這些數據進行情感分析,具體的實驗步驟如下:
1) 獲取實驗數據。利用爬蟲軟件爬取微博上比較兩個熱門話題“#短視頻整頓#”和“#《我不是藥神》爆紅引社會熱議#”的文本數據。
2) 情感極性的人工標注。獲取數據的情感極性沒有進行標注,采用人工方法對這兩個話題進行標注。人工標注主要是通過統計抽取隨機選擇三名實驗同學對這兩個話題進行主觀判斷,標注情感極性,最后統計結果。
3) 預處理。根據上述對應的方法構建六部情感詞典。
4) 話題情感分析。分別在一部基礎情感詞典、六部情感詞典和基于六部情感詞典與規則集的基礎之上對這兩個話題進行三組實驗,得出微博的情感分析結果。
5.2 實驗數據
本文通過爬蟲軟件爬取到關于兩個微博話題的數據集,接著利用人工標注的方法,將這些文本進行情感極性標注,給出每條微博的情感權值并進行分類。共篩選出話題“#短視頻整頓#”共計25 720條,其中正面數據18 634條,負面數據1 385條,中性數據5 701條;話題“#《我不是藥神》爆紅引社會熱議#”共計17 695條,其中正面數據10 672條,負面數據2 856條,中性數據4 167條。判斷標準是:微博情感權值大于0為正面,小于0為負面,等于0為中性。從篩選結果可知正面微博數據所占比例較大,負面微博數據和中性微博數據所占比例較小,且數據較少。
5.3 實驗性能評估指標
本實驗根據本文提出的微博情感分析方法對每一條微博文本進行情感分析,然后將在此方法下自動分析得出的結果與我們人工分類得出的結果進行比對,看情感分析的效果如何。采用以下三個指標進行分析,分別是正確率P、召回率R和綜合度量F指標值,具體公式如下:
(9)
(10)
(11)
5.4 實驗分析與結果
為了驗證本文提出的方法具有更好的作用,還另外做了只基于一部情感詞典和只基于六部情感詞典的實驗。將本文提出的方法實驗結果與這兩種方法得出的實驗結果進行對比,利用性能評估指標對結果進行分析。
對兩個話題分別做如下三組實驗:
第一組實驗:分別對話題“#短視頻整頓#”和“#《我不是藥神》爆紅引社會熱議#”采用基于一部基礎情感詞典的微博情感分析,并進行微博分類。
第二組實驗:分別對話題“#短視頻整頓#”和“#《我不是藥神》爆紅引社會熱議#”采用基于六部基礎情感詞典的微博情感分析,并進行微博分類。
第三組實驗:分別對話題“#短視頻整頓#”和“#《我不是藥神》爆紅引社會熱議#”采用基于六部基礎情感詞典和規則集的微博情感分析,并進行微博分類。
實驗結果如表7和表8所示。
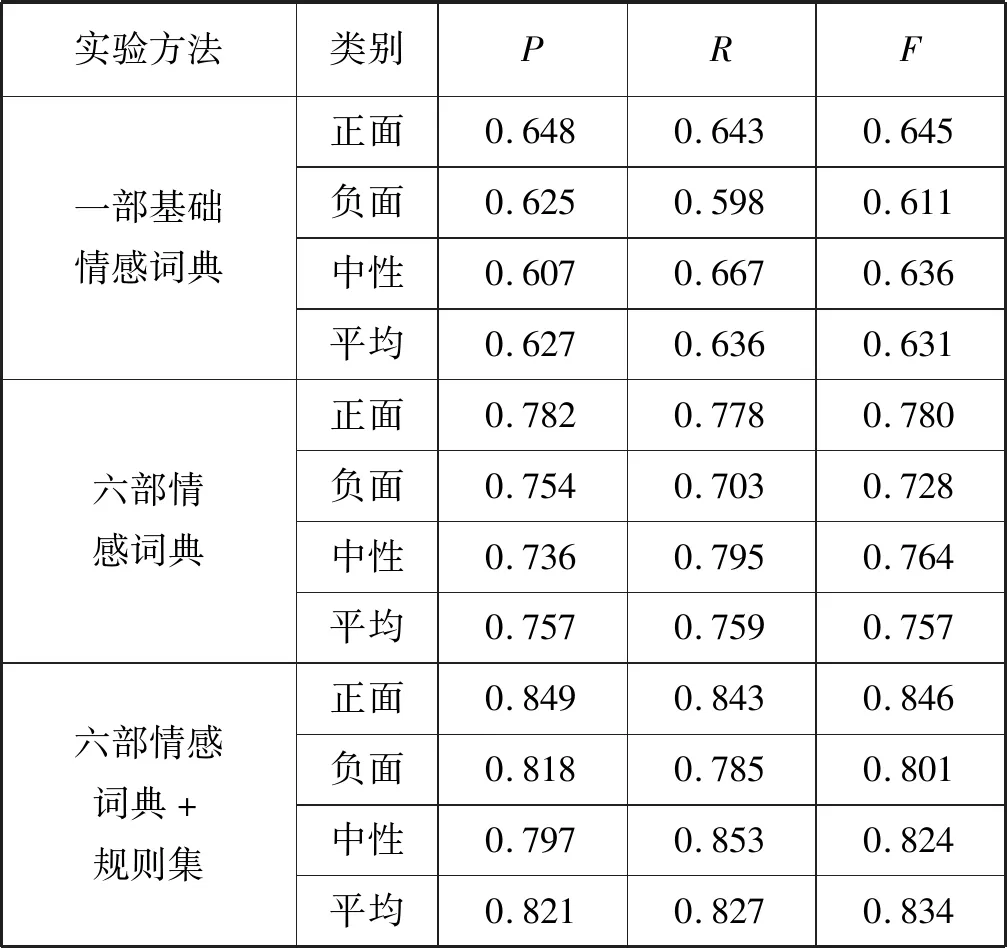
表7 #短視頻整頓#實驗結果
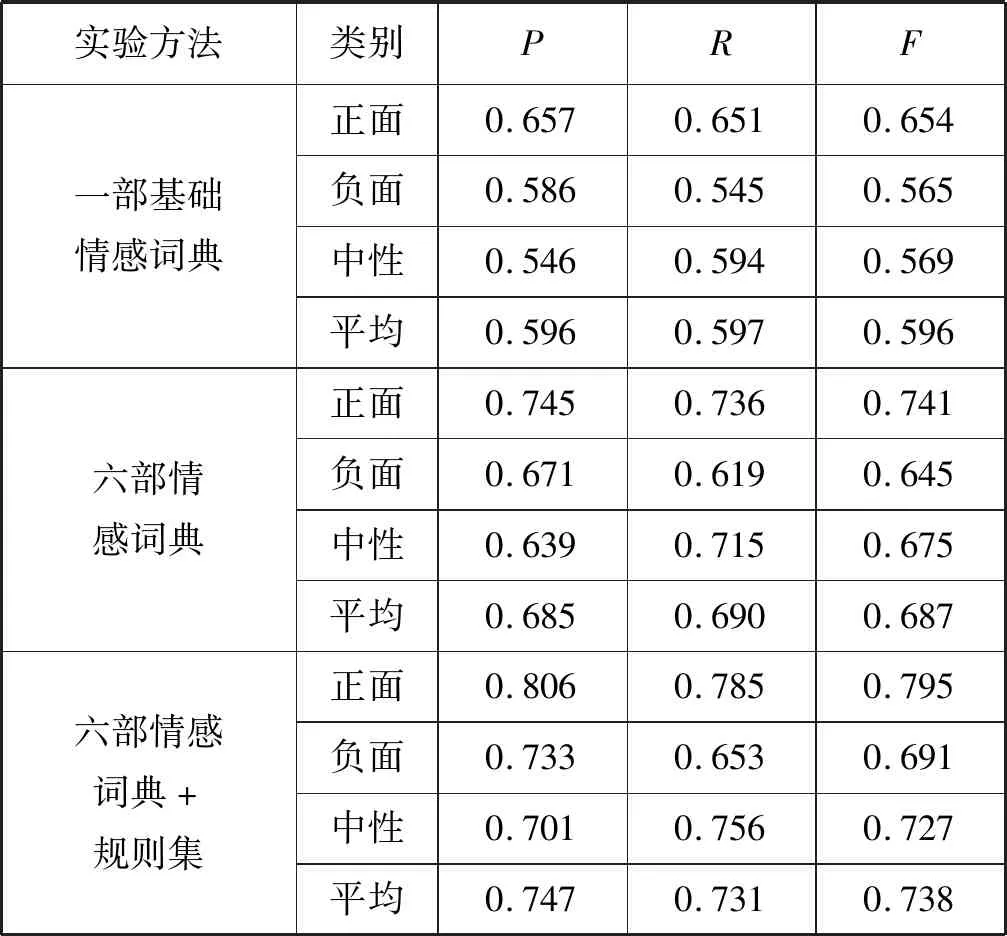
表8 #《我不是藥神》爆紅引社會熱議# 實驗結果
通過表7和表8的數據,對實驗結果進行如下分析:
1) 實驗結果表明本文提出的方法提高了微博的情感分析的正確率。若只單純靠一部基礎情感詞典,那么正確率是較低的,因為微博的特殊的文本包含了很多普通文本不具有的特性,所以要在原來的基礎上擴建多部情感詞典,提高詞典的覆蓋面,同時將文本語義規則集考慮進去,更有利于微博的情感分析。
2) 通過兩個話題的實驗結果可以看出,話題“#短視頻整頓#”的正確率高于話題“#《我不是藥神》爆紅引發社會熱議#”的正確率。這是因為前者所獲取的正面數據居多,而且對后者話題中一些判斷失誤的微博文本進行分析發現這是一部關于電影反諷刺的話題,有網友發表微博就使用了一些反諷刺的表達。比如“電影中的藥商真的好棒啊,竟然可以把藥賣給病人,真的是好樣的!”,這其中“好棒”“好樣”都是正面情感詞,但實際上是起到諷刺作用,是負面的微博,因此在后續對微博的情感分析中還可以繼續對語義規則進行完善分析。
3) 通過表格中數據發現正確率和F值都是正面微博偏高,通過微博分析得知是由于正面、負面、中性數據分布不平衡造成的,因為這兩個微博都是社會熱點話題,眾多網友持支持態度。
4) 通過對比F值可以發現在引入六部情感詞典之后,F值相對于一部情感詞典下有很大提高,這是因為在六部情感詞典下,匹配微博文本的面更廣,尤其加入了微博特定領域的情感詞典,而且在加入規則集以后,F值又有了一定的提升。雖然F值總體上提高了,但還可以繼續提高,因為實驗預處理過程中有個分詞過程,還有語義規則的分析過程,這兩個過程的優劣程度都會影響最后結果。當然還有一些其他因素,比如一詞多義現象等。
實驗表明,本文提出的方法利用多部情感詞典,并考慮文本語義規則集,對微博的情感分析效果有明顯的提升,且在三個指標下,都驗證了此方法對微博情感分析有效果。
6 結 語
基于詞典的情感分析是已有的研究方法,本文在基于詞典的基礎上,構建了除基礎情感詞典之外的其他五部詞典,這些詞典范圍更廣,其中微博特定領域的情感詞典構造至關重要,未來還需要繼續不斷完善這部詞典。最后在六部詞典的基礎上,考慮文本之間的語義規則,因此提出一種基于多部情感詞典和規則集的中文微博情感分析方法,通過實驗驗證了此方法具有很好的作用。
微博的情感分析研究還有很多可以改進之處,比如要考慮微博的點贊數、轉發數和閱讀數等。我們將繼續改進方法,力爭使中文微博情感分析更上一個臺階。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
