基于Xgboost和LightGBM算法預測住房月租金的應用分析
2019-09-13 06:34:40季孟忠黃益槐
計算機應用與軟件 2019年9期
謝 勇 項 薇 季孟忠 彭 俊 黃益槐
(寧波大學機械工程與力學學院 浙江 寧波 315211)
0 引 言
在我國,租房是居民獲取住房的主要方式之一。據《中國流動人口發展報告2017》顯示,全國流動人口總規模為2.45億人,流動人口在流入地的家庭規模為2.67人。另外根據中國指數研究院重點城市租金水平估算2017年全國戶均年租金為2.0萬元,據此測算流動人口帶來的住房租賃市場規模每年達1.2萬億元。住房租賃市場將在我國社會經濟的發展中扮演重要角色,住房租金問題也一直是研究人員關注的焦點。現有研究文獻主要集中關注住房租賃制度和租金影響因素。在住房租賃制度的相關研究中,劉洪玉[1]提出目前租房租賃行為不規范、市場化機構出租缺位影響了住房租賃市場的健康發展。施繼元等[2]認為住房租賃市場應該致力于服務中低收入人群。黃燕芬[3]建議以“租購同權”作為突破口,推進“租售并舉”,促進住房租賃市場健康發展。租金影響因素分為宏觀因素和微觀因素。宏觀因素進一步細分為住房租賃市場供需、住房租賃市場制度、國家經濟發展態勢以及國民經濟收入水平四個方面,微觀因素研究則主要基于特征價格理論(Hedonic Price Model)[4]。該理論認為價格是由商品所有特征帶給人們的效用決定的,具體對住房租金來說,影響租賃價格分為地段、房屋結構以及社區環境三大類。文獻[5-8]從政策、住房價格、居民收入水平等經濟發展指標對租金的影響進行研究并提出相應的政策建議。文獻[9-12]基于特征價格理論得出住房配套設施、裝修情況等建筑特征是影響租金的關鍵。
綜上所述,現有研究大都集中在住房租賃制度和租金影響因素,尚未有租金預測方面的研究。互聯網和大數據的發展給住房租賃市場帶來了很大的沖擊,如今越來越多的人利用互聯網進行租賃房屋,從某種程度上來說,互聯網已經成為租房者和房東之間的橋梁。房屋租金通常由住房租賃市場供需等宏觀因素以及位置地段等房屋商品特征因素綜合決定,但是對于租房這個相對傳統的行業來說,信息嚴重不對稱一直存在。一方面,房東不了解租房的市場真實價格,只能忍痛空置高租金的房屋;另一方面,租客也找不到滿足自己需求高性價比房屋,造成了租房資源的極大浪費。本文著眼于租房租賃市場的痛點,利用真實的租房市場數據,通過3種機器學習算法模型,建立住房月租金預測模型,在一定程度上給予租房者以及房東參考價值,同時挖掘出背后影響租金的關鍵因素。
1 相關方法
1.1 GBDT算法

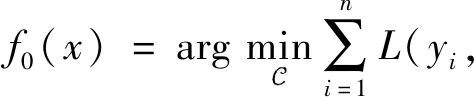
(1)
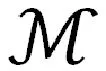
① 對i=1,2,…,n,計算殘差rim,即在當前模型下的損失函數的負梯度值:
(2)
② 根據rim擬合一個回歸樹,得到第m顆數的葉結點區域mj,j=1,2,…,。j表示葉子節點個數。
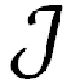
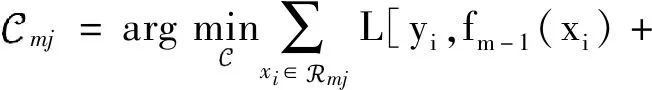
(3)
④ 更新回歸樹:其中I為指示函數,當回歸樹判定x∈mj時,其值為 1,否則為0。
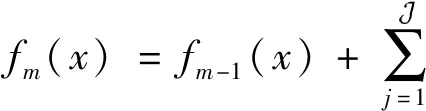
(4)

(5)
1.2 Xgboost算法
Xgboost是華盛頓大學陳天奇于2016年開發的Boosting庫,兼具線性規模求解器和樹學習算法[14]。它是GBDT算法上的改進,更加高效。傳統的GBDT方法只利用了一階的導數信息,Xgboost則是對損失函數做了二階的泰勒展開,并在目標函數之外加入了正則項,整體求最優解,用于權衡目標函數的下降和模型的復雜程度,避免過擬合,提高模型的求解效率,其步驟如下:
(1) 給定數據集D={(xi,yi):i=1,2,…,n,xi∈Rp,yi∈R},其中n為樣本個數,每個樣本有P個特征。假設我們給定k(k=1,2,…,K)個回歸樹,xi表示第i個數據點的特征向量,fk是一個回歸樹,F是回歸樹的集合空間,模型可表示為:
(6)
(2) 目標函數定義如下:
(7)

?
(8)
(4) 將式(8)的結果代入式(7)中,可得:
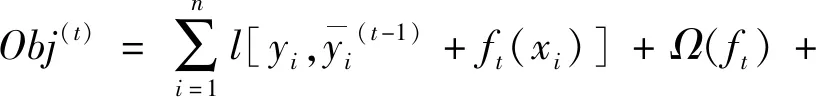
(9)
(5) 將目標函數做二階泰勒展開,并且引入正則項:
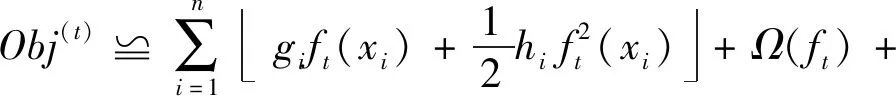
(10)
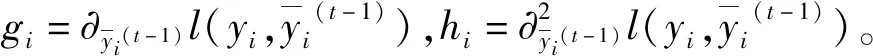
1.3 Lightgbm算法
LightGBM是微軟2015年提出的新的boosting框架模型[15],該算法在傳統的GBDT基礎上引入了兩個新技術:梯度單邊采樣技術和獨立特征合并技術。梯度單邊采樣技術(Gradient-based One-Side Sampling,GOSS)可以剔除很大一部分梯度很小的數據,只使用剩余的數據來估計信息增益,從而避免低梯度長尾部分的影響。由于梯度大的數據對信息增益更加重要,所以GOSS技術在較傳統GBDT少很多的數據前提下仍然可以取得相當準確的估計值。獨立特征合并技術(Exclusive Feature Bundling,EFB)實現互斥特征的捆綁,以減少特征的數量。另外,傳統GBDT算法中,最耗時的步驟是利用Pre-Sorted的方式在排好序的特征值上枚舉所有可能的特征點,然后找到最優劃分點,而LightGBM中使用histogram直方圖算法替換了傳統的Pre-Sorted以減少對內存的消耗。
1.4 住房租金預測建模分析流程
本文建模過程如圖1所示,首先對住房租金數據進行預處理,包括異常數據的刪除、缺失值數據的處理及數據集切分,然后使用python語言建立GBDT、Xgboost、LightGBM三種機器學習模型算法,采用網格搜索進行參數自動尋優。最后通過對比預測精度確定最優預測模型。
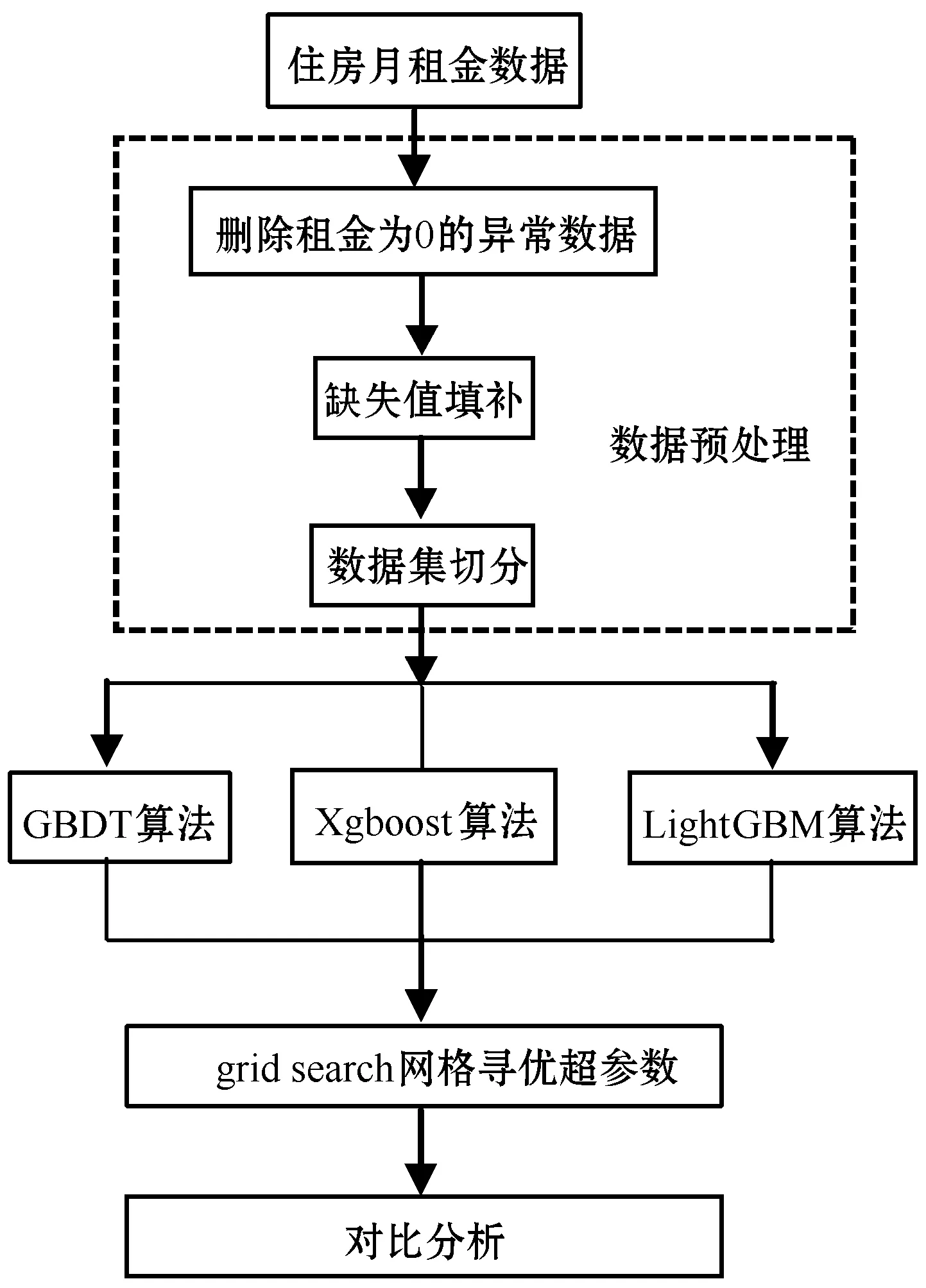
圖1 建模過程
2 建模與實證分析
2.1 住房月租金數據描述及預處理
本文所采用的數據是由Data Castle住房月租金預測大數據競賽數據集,總共196 539個樣本。該數據集包括月租金以及房屋的基本信息,其中月租金為輸出標簽值,房屋基本信息提煉成M0特征(房屋信息采集的時間、房屋所在的區級行政單位、房屋所在樓層、房屋朝向方位、小區所在的商圈位置、房屋面積、房屋所在建筑的總樓層數、小區房屋出租數量、臥室數量、廳的數量、衛生間的數量)、M1特征(房屋裝修檔次、居住狀態、出租方式)、M2特征(房屋附近的地鐵線路、房屋附近的地鐵站點、房屋距離地鐵的距離)合計17個輸入特征。為便于排版依次從A至Q給這些特征編號。統計分析得知,月租金分布如圖2所示,租金變化范圍主要集中在0至40之間,原數據集所含特征、特征編號和缺失值比例表1所示。
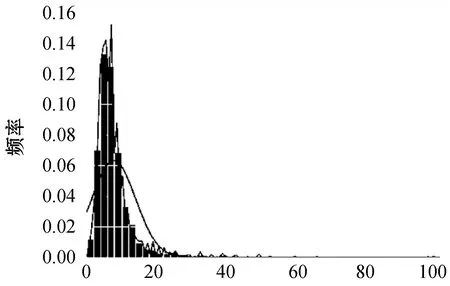
圖2 月租金分布圖

表1 數據集所含特征、特征編號及缺失值比例
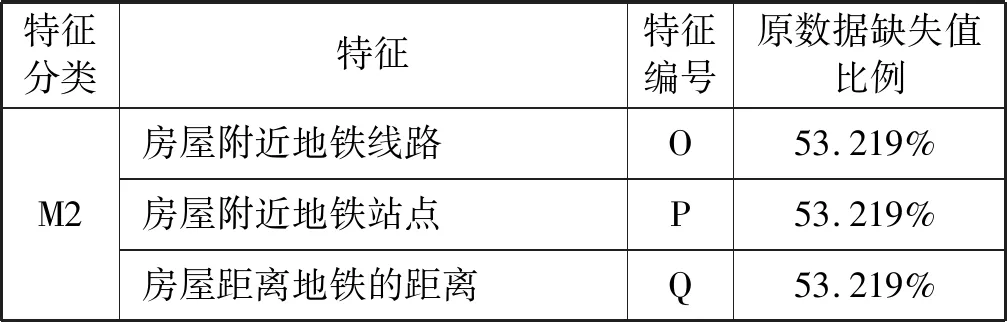
續表1
預測建模需要對數據進行異常數據剔除和缺失數據處理,在196 539個初始樣本中,剔除月租金為0、距離為0及房屋面積為0的三個異常樣本,剩余196 536個樣本。缺失數據的處理按照缺失比例區別對待,對原數據缺失值較少的特征(區、位置、小區房屋出租數量)采用眾數填充法,而原數據中M1特征(裝修情況、居住狀態、出租方式)缺失值達到90%左右,M2特征(距離、地鐵線路、地鐵站點)都是關于周邊交通(地鐵)的特征,缺失值均為53.219%,對于缺失超過50%的數據一般的方法是刪除該特征。然而考慮到這些特征對于租金可能存在較大的影響,需要全面分析M1特征、M2特征對租金的影響。因此,把數據樣本是否含有M1特征、M2特征作為切分依據,將原數據集切分成5個新的數據集:數據集①刪除M1、M2特征;數據集②保留M1、M2特征都缺失的數據;數據集③保留M1特征缺失、M2特征不缺失的數據;數據集④保留M1不缺失、M2缺失的數據;數據集⑤保留M1、M2特征都不缺失的數據。這5個數據集納入的特征分類如表2所示,√表示該數據集納入該特征,×表示該數據集刪除該特征和清洗后的各數據集的樣本數。此外,為了評估模型的性能,對切分好的數據集分別隨機選取90%的數據為訓練集,10%的數據為驗證集。
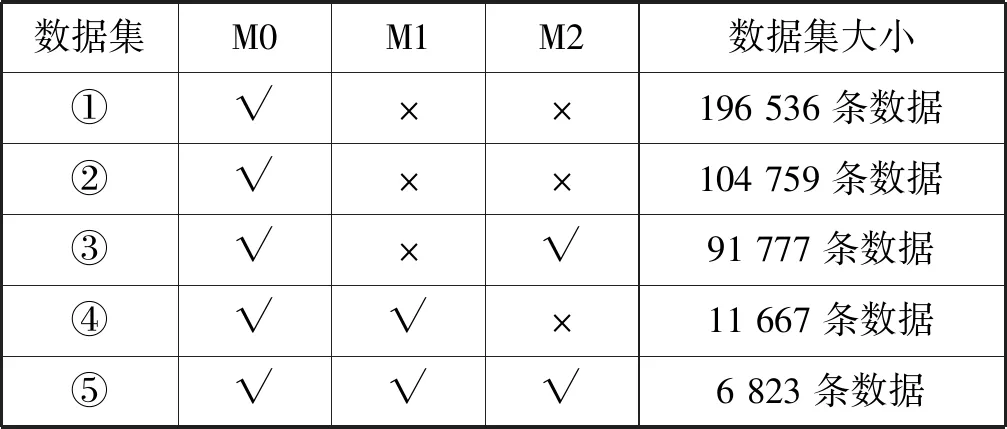
表2 數據集大小及所含特征
2.2 模型評價標準
實驗采用均方根誤差(Root Mean Square Error,RMSE)來度量預測模型的精確度,RMSE計算結果越小,預測越精準。其中N為樣本個數,Xobs,i為第i個樣本實際值,Xmodel,i為第i個樣本預測值。
(11)
2.3 計算過程與結果分析
住房月租金預測計算采用PC配置3.10 GHz的Intel Pentium G2120處理器,4 GB內存64位Windows7操作系統,使用python3.5編程語言進行分析建模,建模過程中主要使用到的包和機器學習庫有pandas、numpy、matplotlib、seaborn、sklearn、Xgboost和LightGBM。
使用GBDT、LightGBM 和Xgboost模型建模分析時,參數的選擇對模型的預測結果有著較大的影響,故需要對若干參數進行調優。對于GBDT模型,本文主要對學習率、迭代次數、最大樹的深度以及最大葉子節點數這4個主要參數進行調優;對于LightGBM模型,本文主要對學習率、迭代次數、葉節點數以及最大直方圖樹這4個主要參數進行調優; 對于Xgboost模型,本文主要對學習率、迭代次數、最大樹的深度以及每個葉子節點樣本權重和這4個主要參數進行調優。使用網格搜索對上述模型參數進行自動尋優,具體步驟如下:(1) 先確定學習率,把learning_rate設置成0.1,其他參數使用默認參數,使用GridSearchCV函數進行網格搜索確定合適的迭代次數;(2) 找到合適的迭代次數后使用GridSearchCV函數對模型的其他兩個主要參數進行網格搜索自動尋優;(3) 減小(增大)學習率,同時增大(減小)迭代次數,找到合適的學習率是使得在誤差最小時迭代次數最少。使用5折交叉驗證的方法來選擇參數,即每次將訓練數據集分成5份,輪流將4份用于訓練集訓練剩下1份用于測試集測試,每次試驗都會得到相應的分數(RMSE),最后將5次測試分數的均值當做最后的分數(RMSE)。在確定參數后,即可對驗證集進行預測,預測結果見表3、表4、表5所示。對于LightGBM 和Xgboost使用模型plot_importance內置函數提取特征對于模型的重要度,GBDT使用模型內置函數feature_importances提取特征對于模型的重要度,每個模型的特征重要度百分比如表6、表7、表8所示。通過特征重要度可以識別影響租金的關鍵特征。

表3 GBDT模型預測精度(RMSE)
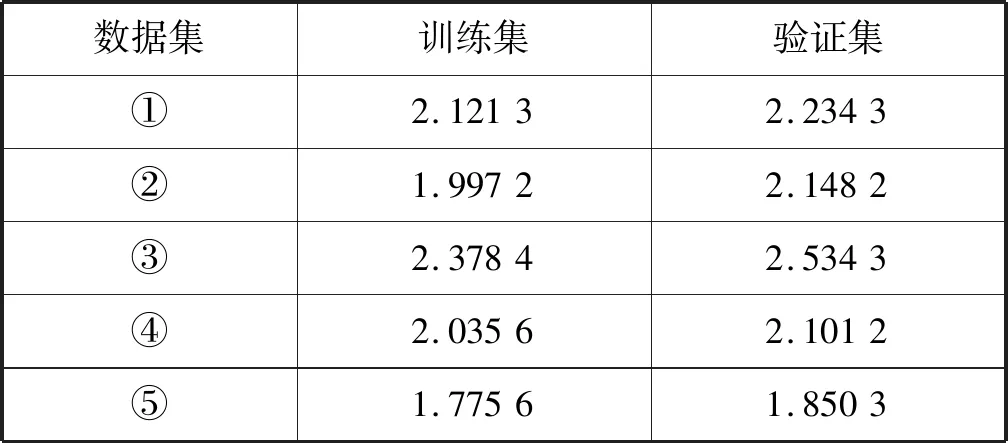
表4 Xgboost模型預測精度(RMSE)
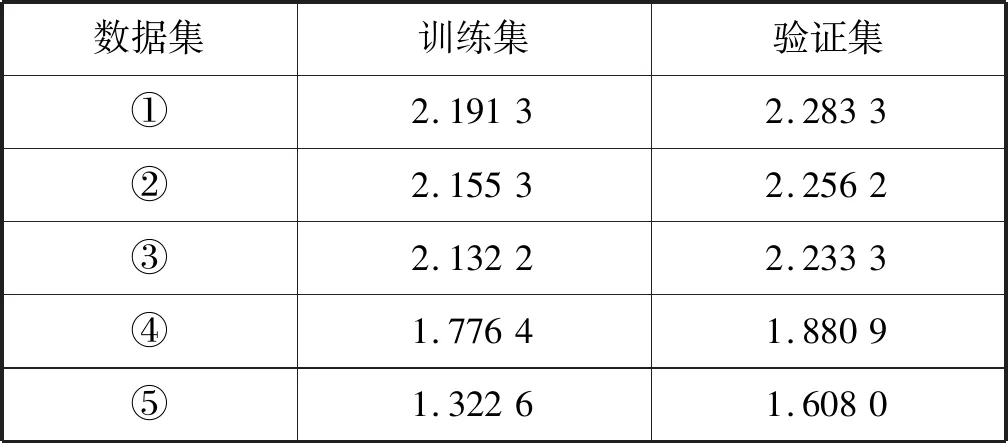
表5 LightGBM模型預測精度(RMSE)
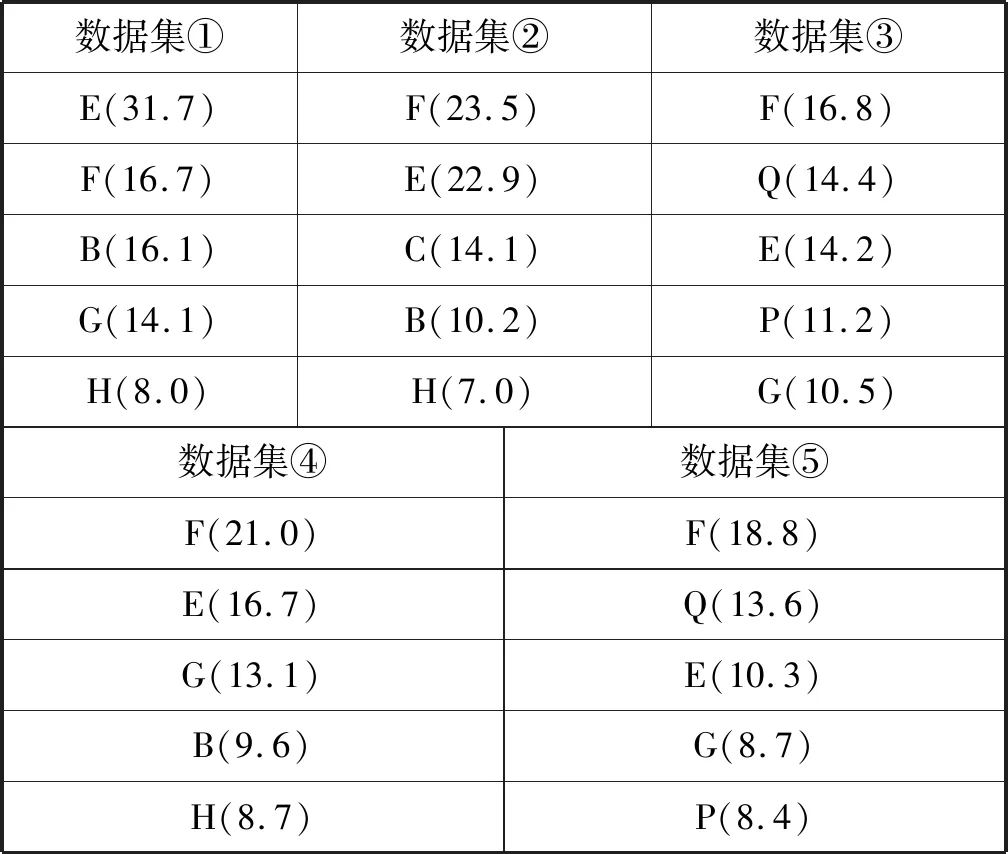
表6 GBDT模型特征排序 %
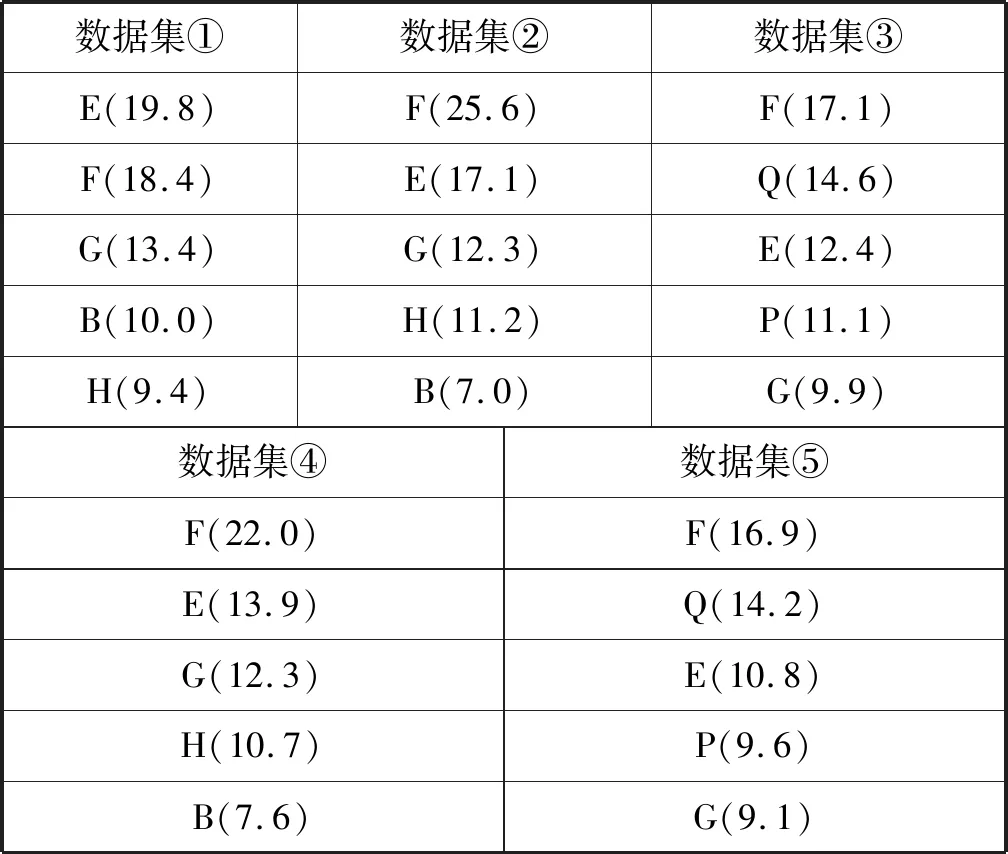
表7 Xgboost模型特征排序 %
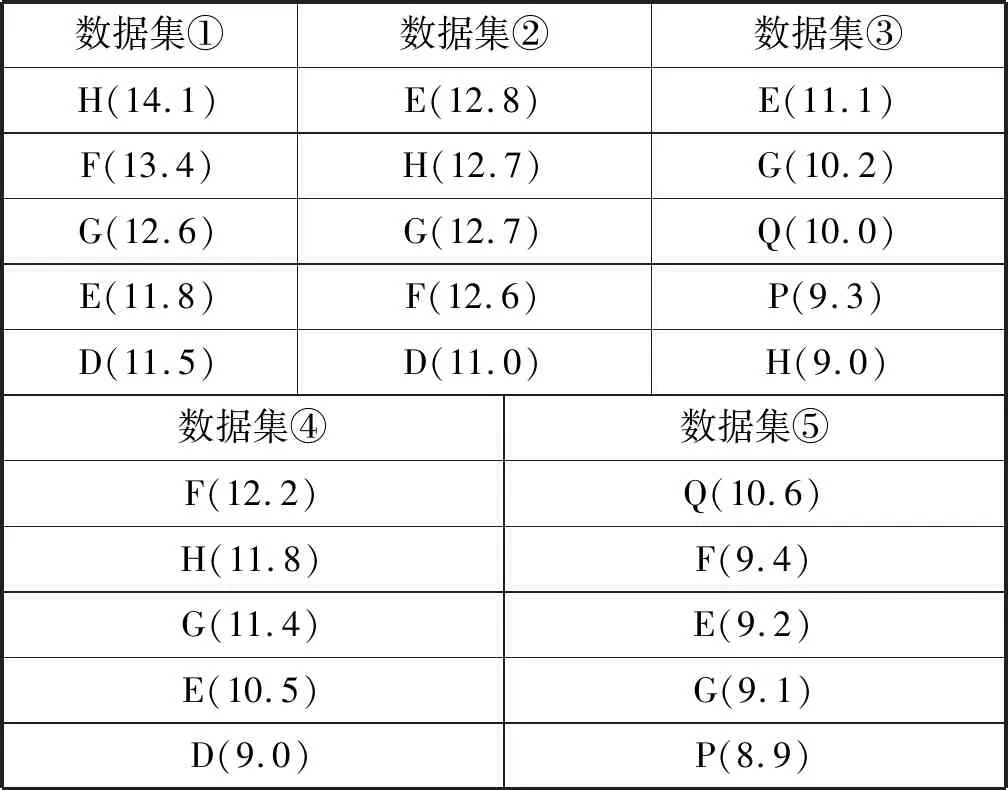
表8 LightGBM模型特征排序 %
根據表3、表4、表5綜合考慮各數據集的預測結果可得出以下結論:LightGBM和Xgboost優于GBDT,而LightGBM和Xgboost互有優劣。LightGBM在數據集③、數據集④、數據集⑤上優于Xgboost。Xgboost在數據集①、數據集②上優于LightGBM。LightGBM精度最優可達1.608,Xgboost最優精度為1.850 3,GBDT最優精度僅為2.248 5。
從表6、表7、表8可以得出以下結論:
結合所有數據集的特征重要度排序,可以得出影響租金的關鍵因素是房屋面積(F)、小區所在商圈位置(E)、房屋距離地鐵的距離(Q)、房屋所在建筑的總樓層數(G)、小區房屋出租數量(H)。房屋面積越大,租金越高是肯定的,小區所在商圈位置、房屋距離地鐵的距離都代表了房屋附近的基礎設施情況,這些本質上都屬于地段因素。這反映了租房就是租地段的現象。而房屋所在建筑的總樓層數、小區房屋出租數量則需要進一步研究,可能是出租總量越多的小區通常居民成分復雜,會影響小區的舒適安全性。高層住宅通常配置電梯,年代較新,住宅狀況較好,自然影響租金。
M1特征不是影響租金的關鍵因素,M2特征是影響租金關鍵因素;在含有M1特征(房屋裝修檔次、居住狀態、出租方式)的數據集④和數據集⑤中,前5名都沒出現該特征,說明M1特征不是關鍵因素。在含有M2特征(距離、地鐵線路、地鐵站點)的數據集③和數據集⑤中,房屋距離地鐵的距離(Q)和房屋附近的地鐵站點(P)均位于前列,說明關于地鐵的M2特征是影響租金關鍵因素。
3 結 語
本文使用3種機器學習模型對住房月租金進行預測, Xgboost和LightGBM作為機器學習近年提出的新
方法,和傳統GBDT相比較能達到較優的預測精度,Xgboost最低均方根誤差可達到1.850 3,LightGBM最低均方根誤差可達到1.608。同時,經過三個預測模型中特征重要度的排序,識別出影響租金最關鍵的特征是面積因素和地段因素。本文的不足之處在于Xgboost和LightGBM雖然能夠得到較好的預測精度,但是由于Xgboost和LightGBM都是基于啟發式算法,尋找的解為局部最優并非全局最優。另外,后續研究中也可以引入Filter、Wrapper等特征選擇方法,以進一步提升預測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
