惡意域名檢測(cè)研究與應(yīng)用綜述
2019-09-13 03:39:04王媛媛吳春江劉啟和周世杰
計(jì)算機(jī)應(yīng)用與軟件 2019年9期
王媛媛 吳春江 劉啟和 譚 浩 周世杰
(電子科技大學(xué)信息與軟件工程學(xué)院 四川 成都 610054)
0 引 言
域名系統(tǒng)協(xié)議是互聯(lián)網(wǎng)的重要組成部分,它將難以記憶的互聯(lián)網(wǎng)協(xié)議地址映射到易于記憶的域名[1-2]。大量的網(wǎng)絡(luò)服務(wù)依賴于域名服務(wù)來(lái)展開(kāi)。由于域名系統(tǒng)并不對(duì)依托于其開(kāi)展的服務(wù)行為進(jìn)行檢測(cè),DNS服務(wù)被濫用于各種惡意活動(dòng):傳播惡意軟件、促進(jìn)命令和控制(Command and Control,C&C)服務(wù)器[3]通信,發(fā)送垃圾郵件、托管詐騙和網(wǎng)絡(luò)釣魚(yú)網(wǎng)頁(yè)[4]等。
惡意軟件控制器或僵尸程序利用惡意軟件進(jìn)行各種未經(jīng)授權(quán)的惡意活動(dòng)。為了成功實(shí)現(xiàn)其目標(biāo),惡意軟件與命令和控制中心的連接至關(guān)重要。因此,以惡意域名解析的連接方式成為網(wǎng)路惡意攻擊的主要手段。所謂惡意域名解析,是指用戶的正常DNS解析請(qǐng)求解析到他人的服務(wù)器上或是攻擊者的惡意服務(wù)器上,而被解析的服務(wù)器上實(shí)際沒(méi)有相應(yīng)的站點(diǎn)[5]。以域名為依托的網(wǎng)絡(luò)攻擊方式的發(fā)展變化如圖1所示。
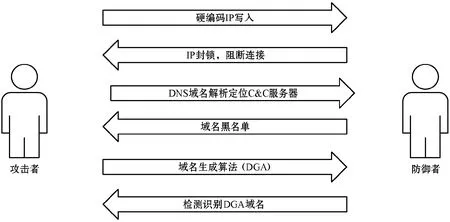
圖1 域名攻擊發(fā)展變化
最初,攻擊者通過(guò)對(duì)惡意軟件(如僵尸網(wǎng)絡(luò)程序)內(nèi)部的IP地址進(jìn)行硬編碼,建立了與C&C中心的通信通道。當(dāng)惡意軟件的可疑IP被發(fā)現(xiàn),網(wǎng)絡(luò)安全管理員就可以針對(duì)IP進(jìn)行流量阻斷,以阻止惡意軟件與攻擊者的連接。為了應(yīng)對(duì)IP封鎖,攻擊者使用DNS域名解析來(lái)定位C&C服務(wù)器。通過(guò)將注冊(cè)的域名寫(xiě)入惡意程序中,然后惡意程序利用域名解析得到攻擊者的命令控制服務(wù)器C&C的IP地址,以進(jìn)行連接通信。即使IP地址被查了出來(lái),攻擊者通過(guò)更換域名的IP地址就可以繼續(xù)保持與惡意程序的通信[6]。但這種方式不能抵抗安全人員逆向分析的域名黑名單,為應(yīng)對(duì)黑名單的域名防御機(jī)制,攻擊者引入域名算法生成技術(shù),利用特定的域名生成算法(Domain Generation Algorithms,DGA),生成大量域名用于自身的組織和控制。攻擊者從算法生成的大量域名中,選取幾十個(gè)或幾百個(gè)域名進(jìn)行注冊(cè)來(lái)掩護(hù)真正的C&C服務(wù)器的域名。而網(wǎng)絡(luò)安全管理員為應(yīng)對(duì)DGA域名,也相應(yīng)提出了基于DGA域名的檢測(cè)方法。
使用DGA的優(yōu)勢(shì)在于模糊了控制服務(wù)器的節(jié)點(diǎn)位置,該方法的靈活性還讓網(wǎng)絡(luò)安全管理員無(wú)法阻止所有可能的域名,并且注冊(cè)一些域名對(duì)攻擊者來(lái)說(shuō)成本很低。利用DGA域名實(shí)施的攻擊是網(wǎng)絡(luò)安全中重要的攻擊形式。因此,捕獲由惡意軟件生成的域名已成為信息安全的核心主題。
1 域名生成算法
域名生成算法是指通過(guò)輸入的隨機(jī)種子,利用加密算法,比如MD5、異或操作等,生成一系列的偽隨機(jī)字符串[7],即域名列表。攻擊者通過(guò)與惡意軟件共享DGA的隨機(jī)種子,知道對(duì)方可能使用的域名,然后使用這些域名不斷嘗試連接直到連接成功。DGA使用的隨機(jī)種子主要分為三類:時(shí)間無(wú)關(guān)和確定性種子,時(shí)間依賴性和確定性種子以及時(shí)間依賴性和非確定性種子。隨著DGA域名的僵尸網(wǎng)絡(luò)的檢測(cè)方法在不斷地改進(jìn)與完善,但在檢測(cè)已有的DGA域名的同時(shí),新的DGA家族變體也在出現(xiàn)。迄今為止,基于360netlab公開(kāi)的DGA域名家族共有40個(gè)。
由于DGA家族眾多,這里我們主要介紹幾類常用的DGA域名。表1中列出了5類常見(jiàn)DGA家族域名的樣例。
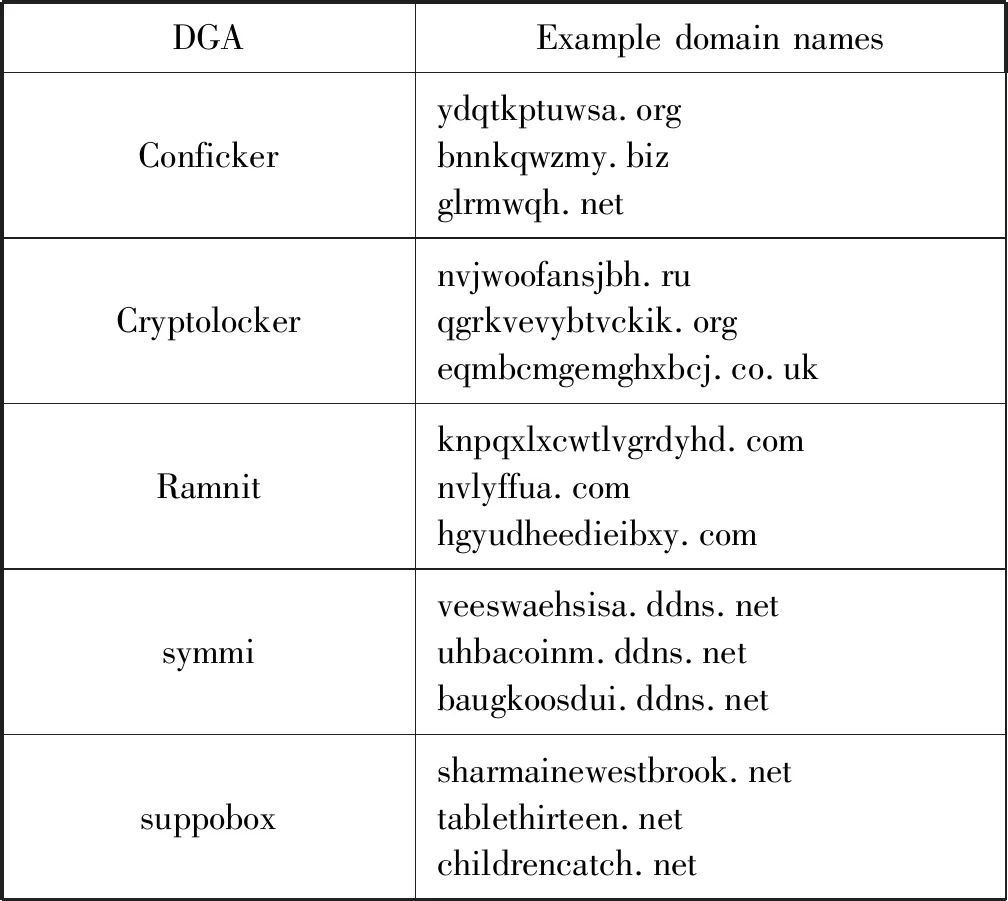
表1 常見(jiàn)DGA域名實(shí)例
Conficker[8-9]是針對(duì)Microsoft Windows操作系統(tǒng)的計(jì)算機(jī)蠕蟲(chóng),最初于2008年末被發(fā)現(xiàn)。它使用Windows操作系統(tǒng)軟件中的缺陷和對(duì)管理員密碼的字典攻擊在形成僵尸網(wǎng)絡(luò)時(shí)傳播。幾乎所有以Conficker為依托的高級(jí)惡意軟件技術(shù)都已被研究人員所熟知,但這種病毒的綜合使用使得它難以根除。
CryptoLocker[10]勒索軟件攻擊是一種針對(duì)運(yùn)行Microsoft Windows的計(jì)算機(jī)的木馬,它通過(guò)受感染的電子郵件附件以及現(xiàn)有的Gameover Zeus[11]僵尸網(wǎng)絡(luò)傳播。它使用DGA從英文字母表a~y中隨機(jī)選取生成字符串長(zhǎng)度為12至15的二級(jí)域名,每周大約生成1 000個(gè)域名。
Ramnit[12]是一種類似Zeus的惡意軟件。它使用DGA與其C2服務(wù)器通信。感染后,樣本開(kāi)始快速連續(xù)地對(duì)許多不同的域進(jìn)行DNS查詢。DGA使用隨機(jī)數(shù)生成器首先通過(guò)均勻地選擇8到19個(gè)字符之間的長(zhǎng)度來(lái)確定第二級(jí)域的長(zhǎng)度。接下來(lái),DGA通過(guò)從“a”到“x”統(tǒng)一選取字母來(lái)確定第二級(jí)域(字母“z”不能被選中),然后附加靜態(tài)頂級(jí)域“.com”。
與著名的conficker相比,symmi[13]的所有隨機(jī)方面都是真正的偽隨機(jī),它通過(guò)當(dāng)前的日期和編碼常量,利用隨機(jī)數(shù)生成器生成種子。它包含三級(jí)域名,在第三級(jí)域中,除字母“j”之外,從元音和輔音中隨機(jī)交替的挑選字母,因此隨后的字母總是來(lái)自其他字符類,這樣選取的字符組成的域名幾乎是可讀的。生成第三級(jí)域后,DGA會(huì)附加配置的第二級(jí)和頂級(jí)字符串,如“.ddns.net”。
Suppobox[14]與現(xiàn)有的大部分DGA都是利用偽隨機(jī)字符串生成的域名家族不同,它利用英文單詞列表,從英文單詞列表中隨機(jī)選擇兩個(gè)單詞連接在一起生成惡意域名。
隨著針對(duì)DGA檢測(cè)技術(shù)的不斷提高,傳統(tǒng)的DGA技術(shù)的復(fù)雜性從簡(jiǎn)單的隨機(jī)繪制字符的方法到嘗試模擬真實(shí)域中的字符或單詞分布的方法。例如:ramnit使用從隨機(jī)種子開(kāi)始的乘法、除法和模數(shù)的組合來(lái)創(chuàng)建域名;symmi為了能夠生成幾乎可發(fā)音的域名,隨機(jī)交替選擇元音或輔音類。另一方面,suppobox通過(guò)連接兩個(gè)偽隨機(jī)選擇的英語(yǔ)詞典單詞來(lái)創(chuàng)建域。
2 DGA域名檢測(cè)的研究與應(yīng)用
DGA的靈活性及低成本使惡意軟件大量利用DGA來(lái)生成惡意域名以連接控制和命令服務(wù)器。為針對(duì)以DGA生成的域名的檢測(cè)研究最先是從DGA生成算法入手的。文獻(xiàn)[15]通過(guò)逆向惡意樣本的DGA算法,提前搶注域名來(lái)控制惡意軟件與C&C通信。雖然逆向技術(shù)可以深入了解惡意樣本采用的域名生成算法以及對(duì)域名的使用機(jī)制,但這種方法所消耗的人力資源過(guò)大且應(yīng)用受限。因此后續(xù)在異常域名檢測(cè)識(shí)別方面研究主要包括基于網(wǎng)絡(luò)流量上下文特征提取的機(jī)器學(xué)習(xí)方法的檢測(cè)、基于無(wú)特征提取的深度學(xué)習(xí)方法的檢測(cè)和基于附加條件的深度學(xué)習(xí)方法的檢測(cè)。
2.1 基于特征提取的機(jī)器學(xué)習(xí)方法的檢測(cè)
通過(guò)特征提取的惡意域名檢測(cè)方法主要分為兩類:一是根據(jù)域名字符統(tǒng)計(jì)特征的檢測(cè),二是根據(jù)DNS流量信息的檢測(cè)。
2.1.1域名字符統(tǒng)計(jì)特征的檢測(cè)
域名在構(gòu)造上可以分為主機(jī)名和域名(包含頂級(jí)域名和可能存在的二級(jí)和三級(jí)域名)。由于域名部分?jǐn)?shù)據(jù)相對(duì)固定,變化較少,因此大部分對(duì)域名的研究處理是針對(duì)主機(jī)名的處理,以下提及的域名都是指域名的主機(jī)名。
利用合法域名與DGA域名在字符分布上有明顯的差異,Davuth等[16]以域名的bigram作為特征,通過(guò)人工閾值的方式過(guò)濾出現(xiàn)頻率較低的bigram,采用支持向量機(jī)分類器檢測(cè)隨機(jī)域名。Yadav等[17]通過(guò)查看同一組IP地址的所有域中的unigram和bigram特征分布,查找算法生成的域名的固有模式來(lái)檢測(cè)DNS流量中的域名。在域名長(zhǎng)度上,Mowbray等[18]在域名查詢服務(wù)中通過(guò)使用不尋常的字符串長(zhǎng)度分布來(lái)檢測(cè)惡意域名。王紅凱等[19]提出了一種基于隨機(jī)森林的隨機(jī)域名檢測(cè)方法。該方法以人工提取的域名長(zhǎng)度、域名字符信息熵分布,元音輔音比、有意義的字符比率等特征來(lái)構(gòu)建隨機(jī)森林模型訓(xùn)練分類,實(shí)現(xiàn)對(duì)隨機(jī)域名的檢測(cè)。隨后Agyepong等[20]也利用算法生成域名與正常域名的字符分布的不同,分別利用域名K-L距離、編輯距離、Jaccard系數(shù)分別作為特征向量的識(shí)別效果。除了利用域名傳統(tǒng)定量的域名特征之外,文獻(xiàn)[21]使用分詞算法將域名分割成單個(gè)詞,來(lái)擴(kuò)展特征集的大小以提高檢測(cè)惡意域名的能力。
2.1.2DNS流量信息的檢測(cè)
在DNS流量分析上面,文獻(xiàn)[22]提出了一種依賴于fast-flux僵尸網(wǎng)絡(luò)的三個(gè)特征:委托代理模式、惡意活動(dòng)的執(zhí)行者和硬件性能,來(lái)檢測(cè)Web服務(wù)是否被fast-flux僵尸網(wǎng)絡(luò)實(shí)時(shí)托管。Bilge等[23]介紹了一個(gè)名為Exposure的系統(tǒng),它利用DNS分析技術(shù)來(lái)檢測(cè)涉及惡意活動(dòng)的域,通過(guò)從DNS流量中提取15個(gè)特征來(lái)描述DNS名稱的不同屬性以及查詢它們的方式。與之前的DNS流量分析不同,Antonakakis等[24]通過(guò)分析因名稱錯(cuò)誤響應(yīng)的域名的DNS查詢,也稱為NXDOMAIN響應(yīng),即不存在IP地址的域名,并設(shè)計(jì)了一個(gè)名為Pleisdes的系統(tǒng)來(lái)檢測(cè)DGA生成的域。它主要利用由DGA生成的域名中,只有相對(duì)較少的域名成功解析為C&C服務(wù)器的地址的特點(diǎn)。當(dāng)Pleiades找到一組NXDOMAIN時(shí),它應(yīng)用統(tǒng)計(jì)學(xué)習(xí)技術(shù)構(gòu)建DGA模型,然后用它來(lái)檢測(cè)用同一種DGA算法的受感染的主機(jī),并檢測(cè)與DGA看起來(lái)類似的活動(dòng)域名,因?yàn)槠溆锌赡苤赶蚪┦W(wǎng)絡(luò)C&C服務(wù)器的地址。Pleiades具有能夠發(fā)現(xiàn)和建模新的DGA而無(wú)需勞動(dòng)密集型惡意軟件逆向工程的優(yōu)勢(shì)。另外Pleiades通過(guò)監(jiān)控本地網(wǎng)絡(luò)中的DNS流量來(lái)實(shí)現(xiàn)這些目標(biāo),而無(wú)需大規(guī)模部署先前工作所需的DNS分析工具。文獻(xiàn)[25]也通過(guò)分析NXDOMAIN響應(yīng)來(lái)檢測(cè)DGA域名。此外,文獻(xiàn)[26-27]通過(guò)DNS數(shù)據(jù)源及其豐富度、數(shù)據(jù)分析方法以及評(píng)估策略和度量,對(duì)近年來(lái)使用DNS數(shù)據(jù)的惡意域名檢測(cè)技術(shù)的一般框架分類,并就DNS領(lǐng)域下的檢測(cè)提出了一些挑戰(zhàn):大規(guī)模的真實(shí)DNS數(shù)據(jù)日志很少公開(kāi)可用,惡意域的特征彈性以及缺少評(píng)估的具體方案。
通過(guò)網(wǎng)絡(luò)的DNS流量的上下文信息及域名的統(tǒng)計(jì)特征對(duì)潛在的DGA分類有一定的成果,但是這些不能滿足實(shí)時(shí)檢測(cè)和預(yù)防的現(xiàn)實(shí)安全應(yīng)用的需求。為滿足實(shí)時(shí)檢測(cè)的要求,諸多的實(shí)時(shí)方法都使用手工挑選的特征(例如:熵、字符串長(zhǎng)度、元音比、輔音比等)。機(jī)器學(xué)習(xí)模型,例如隨機(jī)深林分類器[19]就是比較典型的一個(gè)。然而,這些依賴人工提取特征檢測(cè)方法存在著誤報(bào)率較高、整體檢測(cè)率低的問(wèn)題。主要原因有兩方面:一方面,大多數(shù)現(xiàn)有的基于網(wǎng)絡(luò)的僵尸網(wǎng)絡(luò)檢測(cè)方法僅限于數(shù)據(jù)包檢測(cè)級(jí)別,大多數(shù)方法也主要關(guān)注網(wǎng)絡(luò)流的部分特征,不能完全表征僵尸網(wǎng)絡(luò)的異常行為;另一方面,僵尸網(wǎng)絡(luò)與時(shí)俱進(jìn),利用先進(jìn)的思想和技術(shù)來(lái)逃避檢測(cè)。特別是為了應(yīng)對(duì)人工提取的特征檢測(cè),攻擊者可以設(shè)計(jì)新的DGA算法以繞過(guò)某些固定的特征。隨著檢測(cè)技術(shù)的不斷發(fā)展,僵尸網(wǎng)絡(luò)變得越來(lái)越復(fù)雜和智能化,在一定程度上表現(xiàn)出復(fù)雜性和對(duì)抗性,這使得網(wǎng)絡(luò)安全形勢(shì)依然嚴(yán)峻。
2.2 基于無(wú)特征提取的深度學(xué)習(xí)方法的檢測(cè)
在以往依賴手工提取的特征來(lái)檢測(cè)惡意域名有兩個(gè)主要的缺點(diǎn):手工提取的特征容易規(guī)避,手工提取特征耗時(shí)。Antonakakis等[28]提出了無(wú)特征的實(shí)時(shí)技術(shù)隱馬爾可夫模型(HMM)。但HMM在檢測(cè)DGA方面表現(xiàn)不佳。深度學(xué)習(xí)方法是傳統(tǒng)機(jī)器學(xué)習(xí)機(jī)制的復(fù)雜模型,具有將輸入信息提取為最佳特征表示的巨大能力,在語(yǔ)音識(shí)別和圖像識(shí)別領(lǐng)域取得了顯著的成果,也為惡意域名檢測(cè)技術(shù)提供了一個(gè)全新的思路。近年的多數(shù)研究采用深度學(xué)習(xí)方法,如文獻(xiàn)[29]提出了一種基于word-hashing技術(shù)的深度學(xué)習(xí)網(wǎng)絡(luò)對(duì)域名進(jìn)行分類,其不僅避免了手工提取特征還發(fā)現(xiàn)了傳統(tǒng)統(tǒng)計(jì)方法無(wú)法發(fā)現(xiàn)的特征。接下來(lái)我們介紹兩種主要的神經(jīng)網(wǎng)絡(luò)模型在惡意域名檢測(cè)上的應(yīng)用。
2.2.1RNN在域名檢測(cè)的應(yīng)用
循環(huán)神經(jīng)網(wǎng)絡(luò)[30](RNN)因其能捕獲序列之間有意義的時(shí)間關(guān)系被應(yīng)用于各種自然語(yǔ)言任務(wù)中。因此,初期主要應(yīng)用循環(huán)神經(jīng)網(wǎng)絡(luò)、遞歸神經(jīng)網(wǎng)絡(luò)來(lái)檢測(cè)偽域名。但RNN在長(zhǎng)鏈操作中易導(dǎo)致梯度消失問(wèn)題,不具備學(xué)習(xí)長(zhǎng)期依賴信息的能力。LSTM[31-32]在RNN的基礎(chǔ)上增加一個(gè)狀態(tài)信息使其能夠?qū)W習(xí)長(zhǎng)期依賴信息,在長(zhǎng)時(shí)間的學(xué)習(xí)模式方面非常擅長(zhǎng)文本和言語(yǔ)處理,因此被廣泛應(yīng)用。Woodbridge等[33]利用長(zhǎng)短期記憶網(wǎng)絡(luò)實(shí)現(xiàn)對(duì)DGA的實(shí)時(shí)預(yù)測(cè),而無(wú)需上下文信息或手動(dòng)創(chuàng)建的特征。其模型框架如圖2所示,包括一個(gè)嵌入層,一個(gè)基本上用作特征提取器的LSTM層以及一個(gè)邏輯回歸分類器。基于RNN的DGA檢測(cè)模型都是類似于此模型框架。另外其所提出的技術(shù)可以準(zhǔn)確地執(zhí)行多種分類,從而能夠?qū)GA生成的域歸屬于特定的DGA家族。
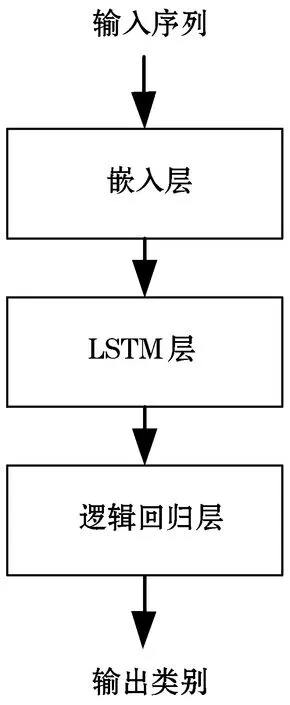
圖2 基于LSTM的DGA域名檢測(cè)模型
Yu等[34]為了比較深度學(xué)習(xí)方法的優(yōu)勢(shì),以傳統(tǒng)的機(jī)器學(xué)習(xí)方法中比較有效的基于特征構(gòu)建的隨機(jī)森林模型作為基準(zhǔn)實(shí)驗(yàn),利用LSTM網(wǎng)絡(luò)和CNN網(wǎng)絡(luò)進(jìn)行域名檢測(cè)分類比較。在整體檢測(cè)率上,CNN和LSTM模型相對(duì)于隨機(jī)森林有突出的表現(xiàn),但在個(gè)別DGA上表現(xiàn)不佳。存在的原因大概有兩方面:一是因數(shù)據(jù)不平衡導(dǎo)致檢測(cè)率低或識(shí)別誤差大;二是傳統(tǒng)的DGA和基于字典的DGA之間存在偏差的樣本分布。為解決DGA家族中個(gè)體識(shí)別率低,Tran等[35]提出了一種改進(jìn)的成本敏感的LSTM算法來(lái)應(yīng)對(duì)DGA域名數(shù)據(jù)多類不平衡的問(wèn)題,相對(duì)原始敏感LSTM算法,具有較高的準(zhǔn)確率。
之后,Vinayakumar等[36]也比較了幾種常見(jiàn)的神經(jīng)網(wǎng)絡(luò)模型。他們對(duì)遞歸神經(jīng)網(wǎng)絡(luò)(RNN)、身份-遞歸神經(jīng)網(wǎng)絡(luò)(I-RNN)、長(zhǎng)期短期記憶(LSTM)、卷積神經(jīng)網(wǎng)絡(luò)(CNN)和卷積神經(jīng)網(wǎng)絡(luò)長(zhǎng)短期內(nèi)存(CNN-LSTM)體系結(jié)構(gòu)五類神經(jīng)網(wǎng)絡(luò)進(jìn)行實(shí)驗(yàn)比較。結(jié)果表明,深度學(xué)習(xí)方法,特別是遞歸神經(jīng)網(wǎng)絡(luò)系列和混合網(wǎng)絡(luò)顯示出優(yōu)越的性能,最高檢測(cè)率分別為0.994 5和0.987 9。主要原因是深度學(xué)習(xí)方法具有捕獲層次特征提取和序列輸入中的長(zhǎng)期依賴性的固有機(jī)制。
以循環(huán)神經(jīng)網(wǎng)絡(luò)為基本框架的檢測(cè)模型對(duì)隨機(jī)性高的DGA域名檢測(cè)準(zhǔn)確率高,但對(duì)隨機(jī)性低的DGA域名識(shí)別率低,導(dǎo)致對(duì)正常域名產(chǎn)生較高的誤報(bào)。因此,此類網(wǎng)絡(luò)在低隨機(jī)性和基于字典的DGA域名成為其未來(lái)的主要發(fā)展點(diǎn)。
2.2.2GAN在域名檢測(cè)的應(yīng)用
Goodfellow等[37]在2014年提出的生成對(duì)抗網(wǎng)絡(luò)(GAN)是一種深度學(xué)習(xí)[38]模型,為生成模型提供了一個(gè)新的框架。它借鑒博弈論中的納什均衡思想[39],使生成器和鑒別器相互學(xué)習(xí)以生成模擬數(shù)據(jù)。生成器捕獲實(shí)際數(shù)據(jù)的分布,而鑒別器估計(jì)樣本來(lái)自訓(xùn)練集的概率。Anderson等[40]利用了生成對(duì)抗網(wǎng)絡(luò)的思想,構(gòu)建了基于深度學(xué)習(xí)的DGA域名生成對(duì)抗樣本方法。在一系列的對(duì)抗輪回中,生成器學(xué)習(xí)生成檢測(cè)器越來(lái)越難以檢測(cè)的域名。相反地,檢測(cè)器通過(guò)更新其參數(shù)以提高檢測(cè)。其提出的生成對(duì)抗網(wǎng)絡(luò)是基于預(yù)先訓(xùn)練的自動(dòng)編碼器(編碼器+解碼器),其中自動(dòng)編碼器先在Alexa的一百萬(wàn)個(gè)域中訓(xùn)練,以生成看起來(lái)更像真實(shí)域名的域。然后在生成對(duì)抗網(wǎng)絡(luò)中競(jìng)爭(zhēng)性地重新組裝編碼器和解碼器,模型框架大致如圖3所示。由于編解碼器是預(yù)訓(xùn)練好的,因此,在對(duì)抗訓(xùn)練中,只訓(xùn)練生成模型的生成層和判別模型的邏輯回歸層。最后用隨機(jī)森林DGA分類器來(lái)驗(yàn)證生成的對(duì)抗樣本的表現(xiàn)力。
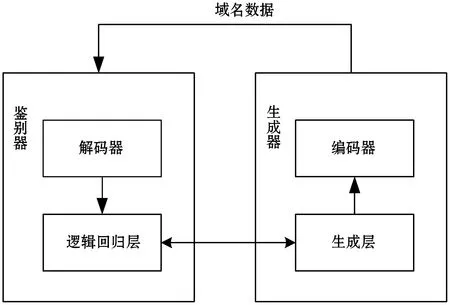
圖3 基于生成對(duì)抗網(wǎng)絡(luò)的域名對(duì)抗樣本生成模型
雖然在基于人工特征提取的隨機(jī)森林DGA分類器上,對(duì)抗樣本表現(xiàn)良好,但實(shí)驗(yàn)對(duì)比較少,只驗(yàn)證了在隨機(jī)森林模型上的檢測(cè)效果。之后,文獻(xiàn)[41]也采用了GAN的思想來(lái)生成惡意域名對(duì)抗樣本,不同之處在于編碼器部分的設(shè)計(jì),后者設(shè)計(jì)了基于的Ascall編碼方式定義域名編、解碼器對(duì)域名字符進(jìn)行向量映射及逆映射,然后將處理好的數(shù)據(jù)輸入對(duì)抗網(wǎng)絡(luò)。接著用生成的樣本與真實(shí)的數(shù)據(jù)的檢測(cè)率作對(duì)比實(shí)驗(yàn),以驗(yàn)證生成的對(duì)抗樣本的有效性。
然而,我們知道GAN在自然圖像分類處理上取得了較好的成果,但是樸素GAN在處理像序列這種離散數(shù)據(jù)上存在兩個(gè)問(wèn)題:一是生成器難以傳遞梯度更新;二是鑒別器難以評(píng)估非常完整的序列。因此由于域名數(shù)據(jù)的序列性,利用GAN生成域名數(shù)據(jù)應(yīng)用上的研究較少。
在GAN研究應(yīng)用上,大多數(shù)研究更多地關(guān)注生成模型,如圖像超分辨率[42]、文本到圖像合成[43],圖像到圖像翻譯和語(yǔ)音增強(qiáng)[44]等。與其他的GAN變體不同,文獻(xiàn)[45]將視角放在了鑒別器上,提出了一種基于生成對(duì)抗網(wǎng)絡(luò)的僵尸網(wǎng)絡(luò)檢測(cè)增強(qiáng)框架,該網(wǎng)絡(luò)通過(guò)生成器連續(xù)生成“假”樣本,并擴(kuò)展標(biāo)記的數(shù)量,以幫助原始模型進(jìn)行僵尸網(wǎng)絡(luò)檢測(cè)和分類。
2.3 基于附加條件的深度學(xué)習(xí)方法的檢測(cè)
單純的深度學(xué)習(xí)的檢測(cè)方法在應(yīng)對(duì)越來(lái)越智能的DGA域名上的表現(xiàn)不佳,為此后面的研究都在深度學(xué)習(xí)方法的基礎(chǔ)上增加了附加條件以提高檢測(cè)率。
LSTM在域名很長(zhǎng)時(shí),很難學(xué)會(huì)合理的表達(dá),因此文獻(xiàn)[46]提出了一個(gè)結(jié)合注意機(jī)制的LSTM模型。該模型將注意力集中在域中更重要的子串并改善域的表達(dá),并在DGA檢測(cè)中實(shí)現(xiàn)更好的性能,尤其是對(duì)于長(zhǎng)域。在二元分類中,其誤報(bào)率分別低至1.29%和假負(fù)率0.76%。陳立皇等[47]也提出了一種基于注意力機(jī)制的深度學(xué)習(xí)模型,不同的是,他們提出一種域名的多字符隨機(jī)性提取方法,提升了識(shí)別低隨機(jī)DGA域名的有效性。Satoh等[48]通過(guò)詞法分析和Web搜索來(lái)估計(jì)域名隨機(jī)性,但該方法對(duì)域名長(zhǎng)度較短時(shí),無(wú)法區(qū)分,不包含在字典中的域名會(huì)被誤判。
為了逃避應(yīng)用神經(jīng)網(wǎng)絡(luò)的檢測(cè)技術(shù),惡意域名已升級(jí)為多個(gè)單詞的組合來(lái)欺騙神經(jīng)網(wǎng)絡(luò)的檢測(cè)。為此,Curtin等[49]提出了smash分?jǐn)?shù)來(lái)評(píng)估DGA域名像英文單詞的程度,然后設(shè)計(jì)了一種新的模型:遞歸神經(jīng)網(wǎng)絡(luò)架構(gòu)與域注冊(cè)信息的組合。雖然實(shí)驗(yàn)在對(duì)matsnu和suppobox這種看起來(lái)像自然域名的家族的檢測(cè)效果好,但是在那些看起來(lái)不像自然域名DGA系列表現(xiàn)效果欠佳。
3 結(jié) 語(yǔ)
以互聯(lián)網(wǎng)為依托的經(jīng)濟(jì)貿(mào)易圈日益增大,網(wǎng)絡(luò)信息安全成為了近年來(lái)關(guān)注的熱點(diǎn)。以域名欺騙技術(shù)為首的網(wǎng)絡(luò)攻擊方式也在不斷更新迭代。通過(guò)國(guó)內(nèi)外在惡意域名特別是算法生成的域名上的檢測(cè)研究分析,在惡意域名檢測(cè)的對(duì)抗環(huán)境中,惡意軟件從簡(jiǎn)單的利用域名生成算法生成偽隨機(jī)字符串的域名來(lái)和控制與命令服務(wù)器連接,發(fā)展到為躲避神經(jīng)網(wǎng)絡(luò)檢測(cè)的更智能化的域名,即由英語(yǔ)單詞構(gòu)成的域名。與之對(duì)抗的,網(wǎng)絡(luò)安全研究人員也從手工提取域名字符特征、DNS流量特征的機(jī)器學(xué)習(xí)方法發(fā)展到利用神經(jīng)網(wǎng)路自動(dòng)學(xué)習(xí)特征的轉(zhuǎn)變和改進(jìn)來(lái)提高模型的檢測(cè)率與性能。
大多數(shù)研究是基于域名字符特征的規(guī)律來(lái)識(shí)別合法域名與偽域名。由于DGA域名生成算法在不斷地更新,新的DGA家族變體在不斷涌現(xiàn),特別是目前對(duì)由英語(yǔ)單詞拼接的域名檢測(cè)上效果不佳。DGA家族因其算法實(shí)現(xiàn)不同,不同家族生成的域名數(shù)據(jù)量不一,導(dǎo)致訓(xùn)練數(shù)據(jù)過(guò)少、識(shí)別率低等問(wèn)題。雖然有研究提出了解決多類不平衡的算法,在一定程度上提高了檢測(cè)率,但沒(méi)有從根本上解決數(shù)據(jù)源的問(wèn)題。另外現(xiàn)有的檢測(cè)模型都是基于某一類問(wèn)題而提出的,例如文獻(xiàn)[49]提出的檢測(cè)模型只針對(duì)像matsnu這樣難以檢測(cè)的家族,而在一般DGA家族的檢測(cè)表現(xiàn)欠佳。針對(duì)以上問(wèn)題,DGA域名的檢測(cè)可以從以下三方面展開(kāi)研究:
(1) DGA域名變體的研究 DGA域名變體生成的域名大多數(shù)為了躲避基于字符特征的模型檢測(cè),利用英語(yǔ)單詞列表隨機(jī)生成。雖然這類偽域名從馬爾可夫模型或是n-gram分布的角度來(lái)看,都和正常域名沒(méi)有太大的區(qū)別。但是通過(guò)觀察這些域名可以看出域名的長(zhǎng)度與正常域名相差較大,以及這些域名都是由幾個(gè)毫無(wú)關(guān)聯(lián)的單詞拼湊而成,因此可以針對(duì)這兩個(gè)角度對(duì)這類域名檢測(cè)。
(2) 惡意域名對(duì)抗樣本的生成方法研究 現(xiàn)有的偽隨機(jī)域名生成方式大概分為兩類:一類是通過(guò)逆向工程等手段破解DGA生成算法,還原DGA算法生成偽隨機(jī)域名,但這類生成的域名大都具有固定模式,在有限數(shù)據(jù)集上訓(xùn)練的模型缺乏對(duì)新的DGA變體的預(yù)測(cè)。另一類就是通過(guò)生成對(duì)抗網(wǎng)絡(luò)來(lái)生成對(duì)抗樣本,文獻(xiàn)[21]利用GAN生成了域名的對(duì)抗樣本,并用實(shí)驗(yàn)證明了對(duì)抗樣本在充當(dāng)惡意域名數(shù)據(jù)及預(yù)測(cè)未知DGA家族上有可觀的表現(xiàn)。但由于GAN主要是處理連續(xù)數(shù)據(jù),對(duì)離散序列數(shù)據(jù)的上表現(xiàn)較差,所以針對(duì)文本序列數(shù)據(jù)處理,文獻(xiàn)[50]提出了SeqGAN(Sequence Generative Adversarial)來(lái)解決樸素GAN在離散數(shù)據(jù)處理上的問(wèn)題,并在語(yǔ)言文本上[51]有不錯(cuò)的表現(xiàn)。相信未來(lái)通過(guò)SeqGAN生成的域名對(duì)抗樣本會(huì)有更高的質(zhì)量。
因此,研究DGA惡意域名對(duì)抗樣本的生成方法有助于預(yù)測(cè)未來(lái)可能出現(xiàn)的DGA變體域名。另外,通過(guò)訓(xùn)練惡意域名對(duì)抗樣本也有益于解決由于DGA家族存在數(shù)據(jù)不平衡導(dǎo)致惡意域名檢測(cè)識(shí)別差的問(wèn)題。
(3) 惡意域名的檢測(cè)模型 基于現(xiàn)有的檢測(cè)模型,如何設(shè)計(jì)一個(gè)高效的檢測(cè)模型是一個(gè)難點(diǎn),因?yàn)閭斡蛎絹?lái)越智能化,可以逃避一般的神經(jīng)網(wǎng)絡(luò)模型的檢測(cè)。同時(shí)如何將模型設(shè)計(jì)成為一個(gè)既可以作為單獨(dú)的模型,也可以作為更大的DGA檢測(cè)系統(tǒng)的一部分,還可以包含網(wǎng)絡(luò)流量,運(yùn)用到實(shí)時(shí)的網(wǎng)絡(luò)安全系統(tǒng)中也是未來(lái)的可發(fā)展點(diǎn)。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
