醫(yī)院網(wǎng)站日志挖掘數(shù)據(jù)預(yù)處理的研究
2019-09-19 07:41:28李立峰翟玉蘭
重慶理工大學(xué)學(xué)報(自然科學(xué)) 2019年8期
蒙 華,蘇 靜,李立峰,翟玉蘭
( 廣西醫(yī)科大學(xué) a.第一附屬醫(yī)院 計算機管理中心;b.信息與管理學(xué)院 教研科, 南寧 530021)
醫(yī)院網(wǎng)站日志挖掘研究即利用數(shù)據(jù)挖掘技術(shù)分析用戶訪問模式等信息,從網(wǎng)站日志中發(fā)現(xiàn)并抽取有效信息,挖掘訪客感興趣的潛在有用信息。醫(yī)院網(wǎng)站的用戶訪問模式較為復(fù)雜,具有時間分布的隨機性、不均勻性,用戶瀏覽器及其版本的不確定性以及使用網(wǎng)絡(luò)代理多樣性等特點[3-4]。數(shù)據(jù)挖掘?qū)ο蠓秶菙?shù)據(jù)庫中的結(jié)構(gòu)化數(shù)據(jù),針對醫(yī)院網(wǎng)站訪問用戶無結(jié)構(gòu)或者半結(jié)構(gòu)化的行為數(shù)據(jù)進行挖掘分析的難度較大,分析效果不理想,無法有效接近用戶行為。針對以上存在的問題,需對Web日志數(shù)據(jù)進行預(yù)處理,將原始Web日志數(shù)據(jù)中錯誤、缺漏、干擾的信息轉(zhuǎn)換成相對完整和準確的用戶訪問事務(wù)數(shù)據(jù)庫,以適應(yīng)新挖掘應(yīng)用需求[5-7]。數(shù)據(jù)預(yù)處理操作主要是通過清洗原始數(shù)據(jù)和用戶識別、進行會話處理、標準化頁面和建立用戶相似度矩陣等操作,獲取反映用戶瀏覽行為的有效數(shù)據(jù)并轉(zhuǎn)換成后續(xù)挖掘算法可識別的格式,以此提高挖掘質(zhì)量[8-10]。
本文對用戶訪問廣西某大型綜合性醫(yī)院官網(wǎng)的日志數(shù)據(jù)進行預(yù)處理,旨在從繁雜數(shù)據(jù)源中抽象出適合數(shù)據(jù)挖掘算法所需模式,提高預(yù)處理結(jié)果矩陣的有效信息含量。
1 數(shù)據(jù)預(yù)處理流程
Web日志記錄數(shù)據(jù)挖掘模型的算法流程如圖1所示,分成2個步驟:① 日志記錄數(shù)據(jù)的預(yù)處理操作,包括過濾日志數(shù)據(jù)、識別用戶、識別會話數(shù)據(jù)及路徑補充,確保日志數(shù)據(jù)應(yīng)用于數(shù)據(jù)挖掘模型的有效性。② 頁面聚類處理得到日志數(shù)據(jù)。
1.1 日志數(shù)據(jù)預(yù)處理
Web日志數(shù)據(jù)預(yù)處理包括清洗、過濾日志數(shù)據(jù),識別用戶,識別會話,數(shù)據(jù)標準化。其中數(shù)據(jù)預(yù)處理是基礎(chǔ),決定后期數(shù)據(jù)挖掘的質(zhì)量。數(shù)據(jù)挖掘流程見圖1。
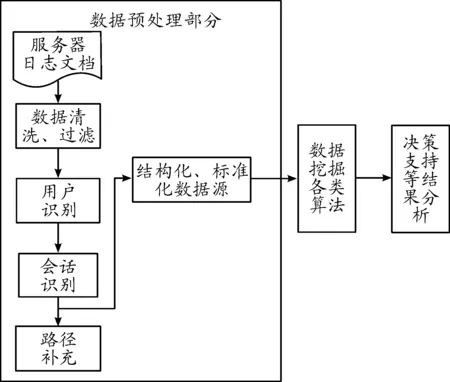
圖1 數(shù)據(jù)挖掘流程
1) 清洗數(shù)據(jù)及過濾
清洗數(shù)據(jù)是在數(shù)據(jù)的多種屬性中抽取對挖掘目標影響較大的屬性,從而降低數(shù)據(jù)維數(shù),提高日志數(shù)據(jù)中信息有效率。日志源數(shù)據(jù)表共有14項屬性,根據(jù)挖掘需求,清洗相關(guān)系數(shù)較小的屬性,保留用戶訪問時間、方式、IP地址、請求頁面、瀏覽器類型及用戶計算機操作系統(tǒng)共6個屬性。
過濾日志數(shù)據(jù)訪問頁面痕跡中包含的圖片、圖像、視頻、音頻以及服務(wù)器對用戶請求響應(yīng)失敗的信息等,這些數(shù)據(jù)對后續(xù)分析無影響[5]。
[10]Selected Works of Jawaharlal Nehru, Second Series, Vol.11, New Delhi: Oxford University Press, 1991, p.372.
2) 用戶識別原則
對日志中訪問的用戶,根據(jù)用戶IP、瀏覽器及其版本、操作系統(tǒng)等對用戶進行劃分。當(dāng) IP地址一致時,若客戶機操作系統(tǒng)或使用瀏覽器類型、版本不同,則視為不同用戶[3,11-12]。
3) 會話識別
識別用戶的訪問行為,并劃分每個訪問用戶瀏覽的頁面序列到相應(yīng)的會話事務(wù),即進行事務(wù)識別。根據(jù)文獻[6,13],25.5 min為最佳用戶會話中止的界定時間,此即為時間戳[14]。
4)會話補充
① 客戶端瀏覽器Cache存儲近期瀏覽的文件,包括某些點擊率很高的網(wǎng)頁點擊信息。本文根據(jù)Web日志和Web站點結(jié)構(gòu)中鏈接信息填補會話空缺。
② 若在瀏覽站點設(shè)置中,當(dāng)前瀏覽網(wǎng)頁與用戶前一次請求的網(wǎng)頁之間無鏈接路徑,則用戶可能使用瀏覽器返回鍵,調(diào)取客戶機的緩存頁面,獲得一個完整的用戶訪問路徑。但實際情況中該方法很難獲取客戶機的緩存信息進行會話補充[8-9]。
5) 結(jié)構(gòu)化、標準化
網(wǎng)站日志經(jīng)過清洗等處理操作后,需轉(zhuǎn)換為符合數(shù)據(jù)挖掘算法的輸入格式,并保存到關(guān)系型數(shù)據(jù)庫表或數(shù)據(jù)倉庫中,即將數(shù)據(jù)標準化或結(jié)構(gòu)化。本文選擇頁面序列作為指標進行聚類。
1.2 頁面聚類
后期聚類分析結(jié)果準確程度受Web頁面相似度分析的影響,相似度分析也是歸類不同頁面群體的重要依據(jù)。選取頁面序列作為相似性度量指標[6],從預(yù)處理結(jié)果數(shù)據(jù)中統(tǒng)計用戶對各頁面的訪問次數(shù)。
根據(jù)式(1)計算頁面Pi和用戶clientj之間的關(guān)聯(lián)度矩陣L。
(1)
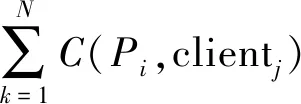
根據(jù)頁面和用戶的關(guān)聯(lián)度矩陣計算出頁面之間的相似度矩陣R,如式(2)所示[14],R即為日志數(shù)據(jù)標準化后的結(jié)果。
(2)
計算后得到Web日志數(shù)據(jù)標準化后的結(jié)果矩陣R(詳見實驗結(jié)果)。R凝聚了用戶和訪問頁面之間聯(lián)系的信息量,運用聚類分析、神經(jīng)網(wǎng)絡(luò)等算法對R聚類,得出頁面聚類模式等以利于對醫(yī)院網(wǎng)站結(jié)構(gòu)的分析優(yōu)化。
2 醫(yī)院日志挖掘預(yù)處理實驗
2.1 實驗數(shù)據(jù)
本文數(shù)據(jù)來源于廣西某大型綜合性三級甲等醫(yī)院網(wǎng)站2011年10月31日日志.txt文件,總大小為31.2 M。日志文件是非結(jié)構(gòu)化的文本文件,記載用戶訪問該醫(yī)院網(wǎng)站的記錄總計152 500多條,見圖2。
圖2 醫(yī)院網(wǎng)站日志片段
2.2 實驗結(jié)果分析
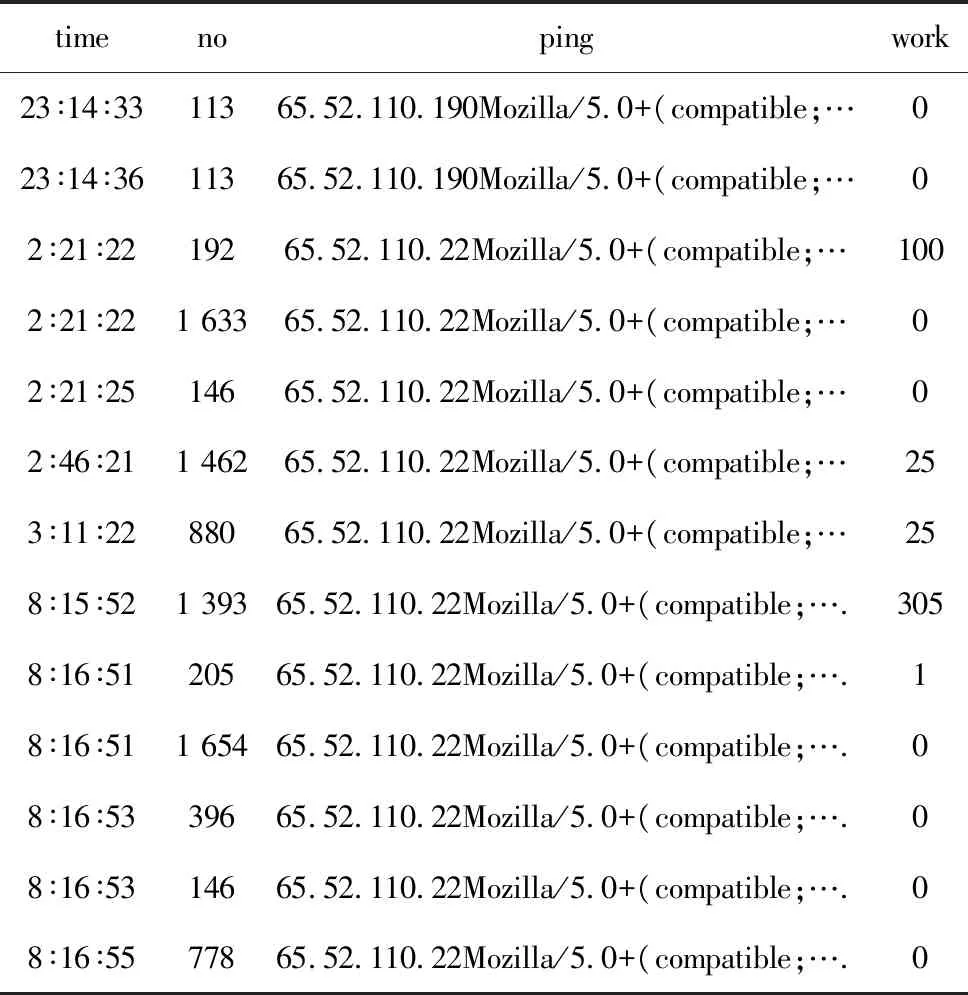
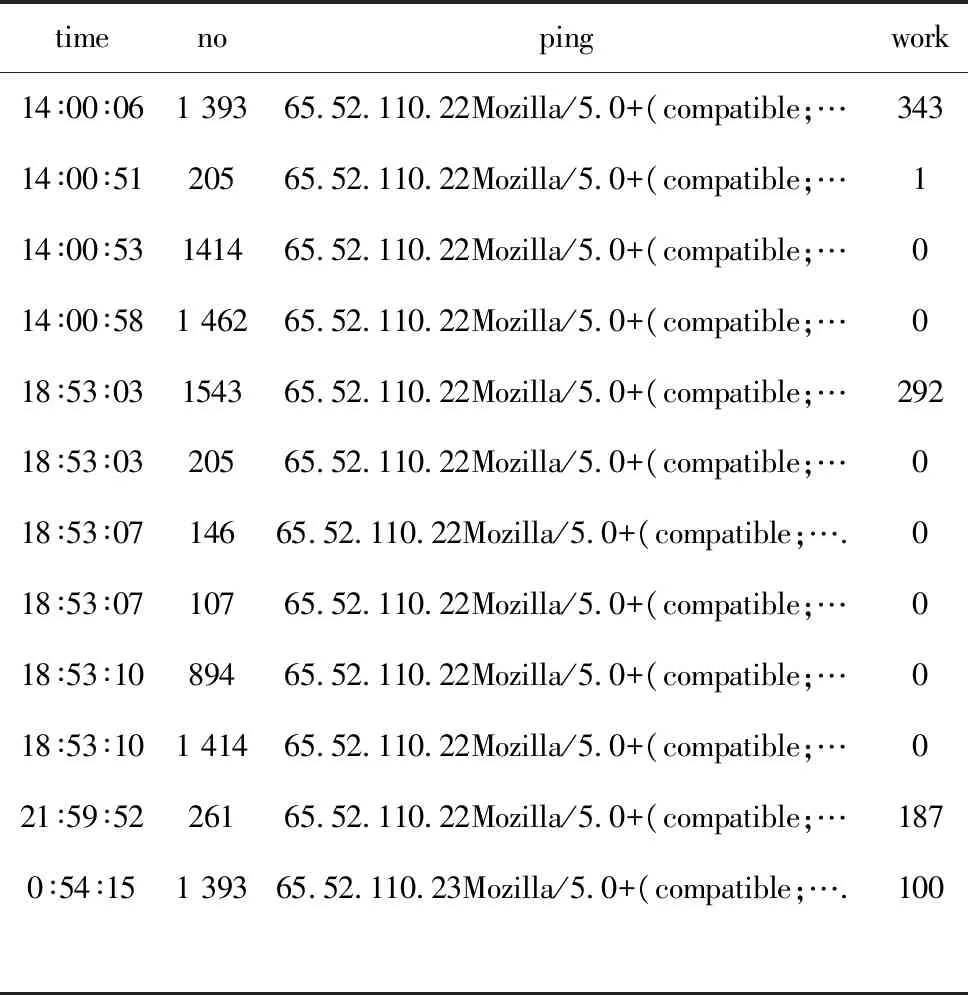
利用SQL2000數(shù)據(jù)庫技術(shù)刪除音頻等數(shù)據(jù),得到32 500多條醫(yī)院網(wǎng)站訪問記錄,清除率為80%。網(wǎng)頁唯一性編碼共計1 850多個,即為經(jīng)過數(shù)據(jù)過濾后該日用戶瀏覽的所有界面集合。對這些記錄進行會話識別和補充,得到2 800多個不同會話,見表1。其中:time表示當(dāng)日時間;no表示該用戶訪問醫(yī)院網(wǎng)頁對應(yīng)的編碼;ping表示融合IP地址、瀏覽器和操作系統(tǒng)等內(nèi)容的字段;work表示區(qū)分會話字段。若ping相同,用戶會話會分割記錄點,兩者time字段相差≥25.5 min,即分為兩個會話記錄。
表1 網(wǎng)站日志文件會話集片段
timenopingwork23∶14∶3311365.52.110.190Mozilla/5.0+(compatible;…023∶14∶3611365.52.110.190Mozilla/5.0+(compatible;…02∶21∶2219265.52.110.22Mozilla/5.0+(compatible;…1002∶21∶221 63365.52.110.22Mozilla/5.0+(compatible;…02∶21∶2514665.52.110.22Mozilla/5.0+(compatible;…02∶46∶211 46265.52.110.22Mozilla/5.0+(compatible;…253∶11∶2288065.52.110.22Mozilla/5.0+(compatible;…258∶15∶521 39365.52.110.22Mozilla/5.0+(compatible;….3058∶16∶5120565.52.110.22Mozilla/5.0+(compatible;….18∶16∶511 65465.52.110.22Mozilla/5.0+(compatible;….08∶16∶5339665.52.110.22Mozilla/5.0+(compatible;….08∶16∶5314665.52.110.22Mozilla/5.0+(compatible;….08∶16∶5577865.52.110.22Mozilla/5.0+(compatible;….0
timenopingwork14∶00∶061 39365.52.110.22Mozilla/5.0+(compatible;…34314∶00∶5120565.52.110.22Mozilla/5.0+(compatible;…114∶00∶53141465.52.110.22Mozilla/5.0+(compatible;…014∶00∶581 46265.52.110.22Mozilla/5.0+(compatible;…018∶53∶03154365.52.110.22Mozilla/5.0+(compatible;…29218∶53∶0320565.52.110.22Mozilla/5.0+(compatible;…018∶53∶0714665.52.110.22Mozilla/5.0+(compatible;….018∶53∶0710765.52.110.22Mozilla/5.0+(compatible;…018∶53∶1089465.52.110.22Mozilla/5.0+(compatible;…018∶53∶101 41465.52.110.22Mozilla/5.0+(compatible;…021∶59∶5226165.52.110.22Mozilla/5.0+(compatible;…1870∶54∶151 39365.52.110.23Mozilla/5.0+(compatible;….100
最后,經(jīng)過頁面聚類分析,得出頁面聚類矩陣R,即信息含量較大、較可靠的相似度矩陣。矩陣R大小為2 363×2 363,反映了頁面和用戶的關(guān)聯(lián)程度。圖3所示為R矩陣的片段A,大小為11×11。
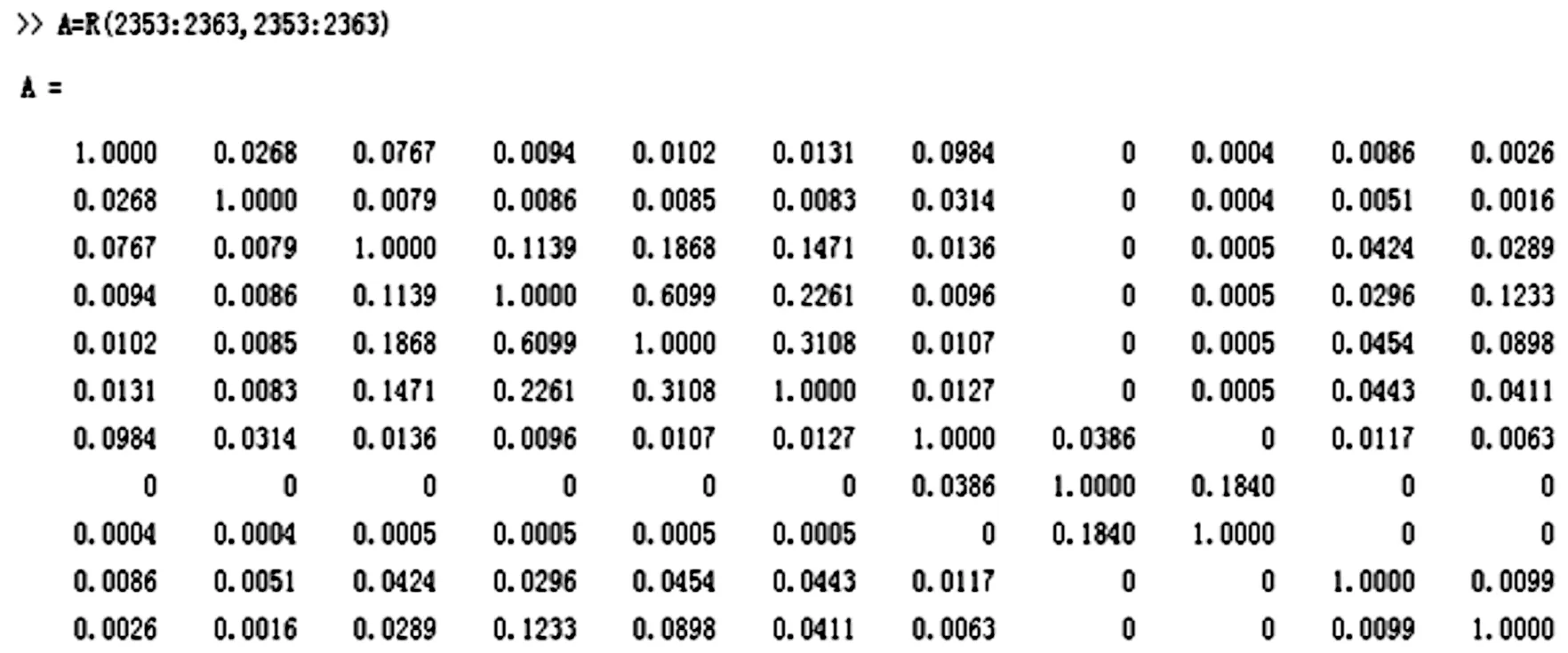
圖3 頁面聚類輸出矩陣片段
實驗基于預(yù)處理原理及流程,采用win7操作系統(tǒng)、SQL2000、Matlab7.1實現(xiàn)網(wǎng)站日預(yù)處理過程。將存在缺失、錯誤、噪音的原始數(shù)據(jù)轉(zhuǎn)化為信息含量較大,較可靠、完整的相似度矩陣R,直接用于網(wǎng)站日志挖掘分析。
收集醫(yī)院官網(wǎng)一段時間內(nèi)的網(wǎng)站日志數(shù)據(jù),通過預(yù)處理,提取主要特征量,降低聚類分析數(shù)據(jù)維度和復(fù)雜性,組成更龐大的相識度矩陣R群。R群可作為進一步深入聚類分析的徑向基神經(jīng)網(wǎng)絡(luò)(radial basis function,RBF)輸入向量群。RBF網(wǎng)絡(luò)一般由輸入層、隱層和輸出層組成,其非線性映射能力和逼近性能較強[15]。隱層一般采用高斯型函數(shù),第i個隱層節(jié)點輸出為
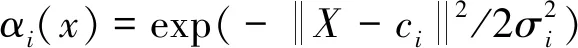
i=1,2,…,m
(3)
式(3)中:m為隱層神經(jīng)元個數(shù);X為多維輸入向量即相似度R矩陣集;ci第i個隱層節(jié)點高斯核函數(shù)中心;σi第i個隱層節(jié)點基寬度。結(jié)合遺傳算法優(yōu)化RBF神經(jīng)網(wǎng)絡(luò)的權(quán)值ci、閾值σi及隱層神經(jīng)元i,降低RBF聚類算法對初始數(shù)據(jù)中心的依賴,可使聚類結(jié)果更準確[16-17]。通過遺傳算法優(yōu)化RBF神經(jīng)網(wǎng)絡(luò)的聚類算法,分析網(wǎng)站訪問用戶的瀏覽行為、頻繁度、主題、歸類興趣、目標相同的用戶行為及相似用戶組頻繁訪問的頁面組,能持續(xù)優(yōu)化網(wǎng)站目錄結(jié)構(gòu)、推薦特色、針對性的網(wǎng)站[18-22],進而提高醫(yī)療結(jié)構(gòu)的服務(wù)滿意度。
3 結(jié)束語
數(shù)據(jù)挖掘是近年來研究的熱點,但針對醫(yī)院日志挖掘分析較少。日志文件的預(yù)處理工作著重考慮在提高信息含量時適合挖掘算法輸入的模式。但在完善用戶瀏覽路徑和會話識別對常態(tài)時間域的依賴上仍有不足,無法有效地將日志和站點拓撲結(jié)構(gòu)結(jié)合起來,這也是今后的研究工作。進一步需要深入分析空間數(shù)據(jù)挖掘聚類算法在醫(yī)院網(wǎng)站日志中的應(yīng)用以及網(wǎng)站日志大數(shù)據(jù)在監(jiān)測異常行為預(yù)警中的應(yīng)用。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
兒童繪本(2018年10期)2018-07-04 16:39:12
電力與能源(2017年6期)2017-05-14 06:19:37
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
中國衛(wèi)生(2015年8期)2015-11-12 13:15:20
中國衛(wèi)生(2014年7期)2014-11-10 02:33:12
電子設(shè)計工程(2014年18期)2014-02-27 12:00:13
