基于音視頻的自動化低成本VR視頻生成方法研究
2019-10-09 00:00:00李鵬付則宇邱柯妮張梁
軟件 2019年7期
關鍵詞:自動化
李鵬 付則宇 邱柯妮 張梁
摘? 要: 虛擬現實(VR)技術的發展和相應硬件設備的普及,使得VR視頻內容具有非常大的發展潛力。但VR視頻的制作存在兩個方面的挑戰:一是新內容的VR視頻生成成本很高;二是過去的影音資料難以重新錄制成VR視頻。本文提出一種新穎、低成本的利用已有影音資料生成VR視頻的方法,該方法結合自然語言處理技術(NLP)、3D建模、虛擬現實等技術,可以快速、低成本生成VR視頻。實驗表明,本文方法可以大幅度節省制作成本,過去的音視頻也可以生成沉浸感強的VR視頻。
關鍵詞: VR視頻;NLP;自動化;低成本;沉浸感
中圖分類號: TP391.9; N39? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2019.07.004
本文著錄格式:李鵬,付則宇,邱柯妮,等. 基于音視頻的自動化低成本VR視頻生成方法研究[J]. 軟件,2019,40(7):2230
【Abstract】: With the development of virtual reality (VR) technology and the popularity of corresponding hardware devices, VR videos present a very bright developing prospect among the emerging technologies. However, there are two major challenges in the production of VR videos. First, the cost of producing new VR video is very high. Second, it is difficult to transform past audio or video data to VR formats using the normal VR generation approaches. Addressing these problems, this paper proposes an automatic and low-cost method to generate VR videos using the existing low-cost audio and video materials. The proposed method integrates the technologies of Natural Language Processing (NLP), 3D modeling, virtual reality to produce high quality VR videos in a fast, low cost and automatic way. Experimental results show that cost can be greatly saved by the proposed method. Furthermore, it is a novel way to provide VR videos for the old precious audios or videos.
【Key words】: VR video; NLP; Automatic video generation; Low-cost; Immersive experience
0? 引言
2016年1月國際CES(International Consumer Electronics Show)展會上,虛擬現實(Virtual Reality, VR)相關展品搶盡風頭。隨后國內外VR廠商陸續推出一大批消費級虛擬現實設備。硬件設備的爆發以及用戶對VR體驗的渴望,推動VR產業進入高速發展時期。如今虛擬現實(VR)技術在我們的生活[1]、科技[2]、醫療[3]、教育[4]中有廣泛的應用。豐富的內容是VR生態鏈中重要的一環[5],然而VR內容的創作是一件非常耗費時間、精力和財力的工作。再者,過去的音視頻資料限于當時的軟硬件水平和錄制手法,導致這些資料的畫面質感和錄音質量普遍不高。對于這些珍貴的影音材料,一方面修復會面臨諸多挑戰,另一方面也無法重新錄制成VR版本的視頻。
為此,本文提出一種新穎、低成本的利用已有影音材料生成VR視頻的方法。該方法結合NLP(自然語言處理技術)、3D建模、虛擬現實等技術,可以快速、低成本自動生成高質量VR視頻。
本文貢獻體現在以下三個方面:
(1)一套標準完整的自動化轉化步驟,無需計算機專業相關背景知識都可以用我們的設計架構很簡便地制作VR視頻內容。
(2)和用攝像機拍攝VR全景視頻、動態捕捉設備錄制VR視頻相比,本文方法可以節約技術成本、時間成本、金錢成本,短期內可以大量產生成熟作品。
(3)對一些由于年代久遠,視頻質量差或者只有音頻的情況,我們的方法也可以很容易的轉制成VR視頻。
1? ?背景
1.1? VR視頻
虛擬現實(VR)視頻,又稱全景視頻或360°視頻[6],是要借助于虛擬現實硬件設備進行播放的視頻作品,其目的是為觀看視頻的用戶帶來可交互的、沉浸式的臨場感體驗。
VR視頻是虛擬現實技術(Virtual Reality Technology, 又稱靈境或臨境技術)的一個重要應用方向[7],虛擬現實技術來源于計算機仿真技術。計算機仿真是通過構建虛擬環境來模擬真實世界的運動規律。通過計算機仿真技術構造的虛擬環境,既可以是一個符合現實世界規律的虛擬環境,也可以是一個完全假想的環境。虛擬現實從不同的角度定義有很多不同的描述方式,但是所有描述方式中最重要的一個共性是,虛擬現實可以通過虛擬環境給用戶營造一種不受時空控制的可交互的、沉浸式的臨場感體驗,這個共性也是VR視頻的最大特點。
1.2? VR視頻的生成方式
VR視頻制作流程涉及多種近現代尖端影像技術,如計算機仿真技術、圖形拼接技術、動態環境建模技術、實時三維圖形生成和顯示技術、適人化、智能化人機交互技術等。VR視頻內容的生產可以分為兩種方式,一種是借助全景攝像機拍攝并生成全景視頻;另一種是采用CG(computer graphic,計算機圖形)技術3D建模生成視頻[8]。接下來簡要的介紹下每種VR視頻生成方式的特點。
1.2.1? 用全景攝像機拍攝全景視頻
攝像機拍攝VR視頻,需要用全景攝像機即多鏡頭攝像機拍攝各個方向的圖像內容并進行圖像拼接[9]。中介紹了一種用于全景視頻采集的多鏡頭系統。全景視頻的生成可以分為攝像機標定、圖像融合與同步、視頻流生成三個階段。用攝像機拍攝的VR全景視頻分為五種,分別是全景3D交互視頻、局部全景3D視頻、全景3D視頻、非全景3D視頻、VR全景視頻。這五種VR視頻拍攝難度依次降低,最終體驗效果也有很大差異,其中全景3D交互視頻的沉浸性效果最好。在全景3D交互視頻中用戶可以參與到視頻的故事情節中去,通過與故事場景中的物體進行互動,作品根據用戶的選擇做出回應,從而影響故事情節的發展。全景3D交互視頻真正實現了用戶對虛擬現實環境的“真實”體驗,但是VR視頻中的交互問題一直是制作者的痛點[10]。用不用交互,哪里使用交互,如何用交互都是這類VR內容制作者不得不面臨的問題,而且全景3D交互視頻制作周期長、成本高,短時期內難以產生大量成熟的作品。
1.2.2? 計算機圖形技術3D建模生成VR視頻
采用CG(計算機圖形技術)3D建模生成的VR視頻類似于3D動畫的VR版本,在綜合運用各種貼圖、光效和渲染后,其視覺效果可以和全景相機拍攝的視頻相媲美。與使用全景攝像機拍攝VR視頻相比,CG技術生成VR視頻方便節奏控制和工作調度,同時不用購買昂貴的拍攝裝備,不需要專業的影視拍攝人員,但是同樣面臨創作難的問題。一是虛擬場景的搭建設計,內容劇本的設計,講演思路的設計等,都需要付出一些有創造性的智力勞動才能完成。二是虛擬場景中角色模型的肢體動畫多是通過動態捕捉設備實時錄制。全套動態捕捉設備不僅價格昂貴,而且操作繁雜,需要相關技術人員和軟硬件設備的協同工作。而這就在無形中抬高了制作生成VR視頻的門檻。
1.2.3? 生成VR視頻面臨的挑戰
綜上所述,基于現有的通用VR視頻生成方法想要低成本高質量的生產VR視頻面臨著一些挑戰。首先,不管采用以上兩種方法中的哪一種,繁雜的制作流程會大大降低視頻內容的生產效率[11]。中以全景微課視頻的設計與制作為例,完整的制作流程要包含教學設計、腳本構思、實景拍攝、后期制作等幾個步驟。其次,不管是采用全景攝像機拍攝全景視頻,還是使用動態捕捉裝備錄制肢體動畫,都需要購買昂貴的硬件設備。這就增加了生產VR內容的制作成本,而且對制作人員的技術要求很高。最重要是,以上兩種方法針對過去的一些珍貴音視頻材料都無法重新拍攝或錄制。
2? 研究目的
近年來,隨著計算機技術和網絡技術的高速發展,網上積累了大量、優秀、高質量內容的視頻資源。這些視頻無論從內容、講授形式、講授思路等都是很好的資源,借助這些已有的資源進行VR內容的轉制,可以有效的降低VR視頻制作的創作門檻。同時,虛擬現實技術、人工智能相關技術的快速發展,相應軟硬件設備的迅速普及也為傳統視頻向VR視頻轉化提供了技術支持和設備支撐。另一方面,運用現有的VR視頻的生產方法又面臨著上文所介紹的諸多挑戰。因此在考慮技術成本、時間成本、金錢成本的情況下,運用新的技術和研究方法同時依托已有的視頻資源進行創造性的三維視頻轉制變得很有必要。這將會有效降低VR視頻的創作難度,縮短VR視頻的制作周期,同時保證視頻內容質量的優質性。而這方面的研究工作還很少有人涉及。
因此,本文提出了一種新穎、低成本的創作VR視頻的方法,利用人工智能相關研究和虛擬現實相關技術并結合網絡上已有的一些優秀的、高質量的影音材料進行VR視頻轉制。該設計方法尤其針對課堂、演講等場合具有很高的應用價值。[12]中針對課程錄像制作引入虛擬現實技術,通過構建虛擬場景,提供逼真的學習環境,但是該研究沒有探討虛擬形象取代真實講師形象的可能性。我們提出的VR視頻轉制方法通過沉浸的虛擬環境、生動的虛擬形象,以另一種更加生動活潑的方式真實的再現課堂或演講場景。因此本研究提出的設計架構不僅具有很強的學術價值更具有很廣泛的實際應用需求。
3? ?研究方案
3.1? 工作流程概述
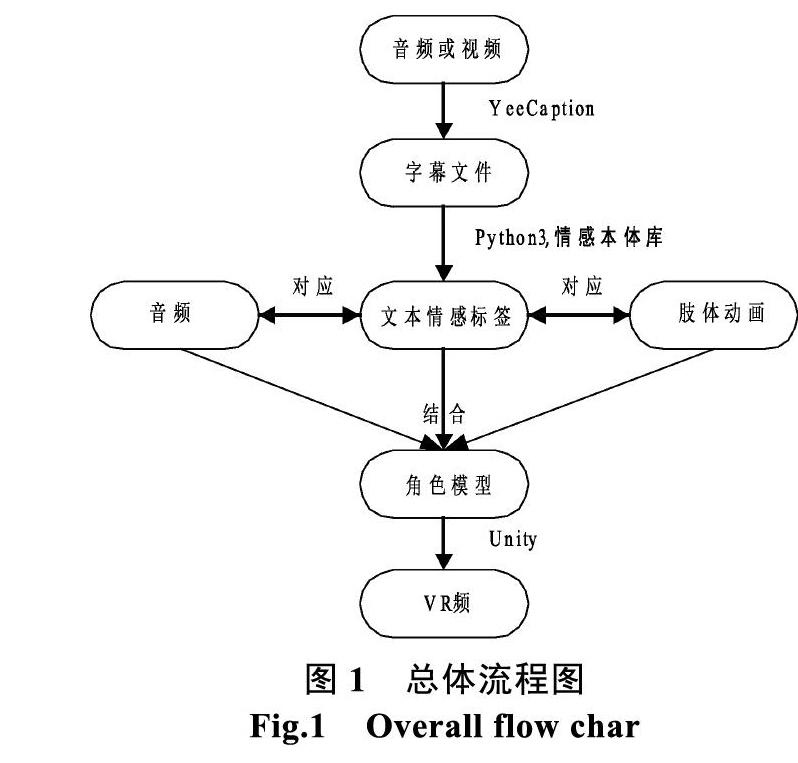
本文提出的多媒體視頻或音頻轉為VR視頻的方法概括起來可以分為三個步驟。
① 用語音識別工具提取視頻或音頻的文本信息。
② 對語音轉化的文本進行自然語言處理獲取每一句文本的情感標簽。
③ 文本,音頻,演講者角色模型,肢體情感動畫在三維虛擬現實場景中匹配生成VR視頻。
圖1為總體流程圖,圖中的①,②,③,代表上述三個步驟中用到的主要工具和關鍵技術。
3.2? 語音識別獲取音頻字幕文件
用本文的方法進行VR視頻轉制,第一步是把多媒體音頻或視頻用語音識別工具進行文本化處理,獲取影音材料的字幕文件。在選擇語音識別軟件方面我們要以保證語音識別一定準確度的情況下同時方便獲取語音的字幕文件為出發點。
目前市面上有很多成熟的商用語音識別軟件,例如科大訊飛、微軟speech sdk等。經過對市面上多款語音識別軟件進行實測和效果對比后,本研究采用YeeCaption這款免費智能視頻翻譯軟件。該軟件的智能性體現在能夠自動對語音軸進行切分,對字幕內容和語音信息進行識別,最后字幕文件也可以很方便的一鍵導出。同時這款軟件界面設計簡單明了,功能設定明確區分,初學者也能輕松入手。最重要的是,此軟件音頻轉文本的準確度高、導出的字幕文件包含每一句文本的時間戳信息,完全符合本研究的需要。
本文以俞敏洪老師經典的一分鐘演講《水的精神》為例,演示獲得視頻或音頻字幕文件的過程。
(1)語音切軸獲取影音材料的時間信息
把視頻或者音頻文件導入YeeCaption中,對導入音頻進行語音切軸操作,把演講者每一句話切分開來,獲取每一句話的時間信息。如圖2所示,右側上方框框住的是每一句語音切軸,界面下方左側框框住的是每一句語音切軸所對應的時間間隔信息。
(2)進行語音識別字幕,獲取語音的字幕信息
圖3是語音識別后的結果,從圖中方框框住的部分我們可以看出,每一句語音切軸出現了字幕文本信息。語音轉化成了對應時間間隔內相應文字。
(3)導出字幕文件
YeeCaption可以很方便的導出字幕文件。圖4是導出選項中所支持的字幕文件導出形式。
3.3? 自然語言處理獲取文本情感標簽
3.3.1? 本文所用獲取文本情感標簽方法
以自然語言文本形式描述的信息占總信息資源的80%,對文本信息進行分析處理屬于自然語言處理技術的研究范疇。現階段自然語言處理的研究方法主要分為兩類:一類是最近比較火熱的基于數學統計的機器學習方法,另一類是基于傳統語法規則的自然語言處理方法。具體采用哪種方法還是要看實際的工作需要。
本文提出一種自動化的、低成本的VR視頻轉制方法,出發點之一就是要盡量減少人工操作,節省時間成本、人力成本。因此本研究采用基于詞典的情感分析方法,針對句子級語料進行情感分析,提取每一條字幕文本的情感標簽。本文針對句子級語料而不是針對篇章級語料進行處理的原因是,語音識別導出的字幕文件是以每一個時間戳對應一行字幕文本的形式呈現的。所以我們的情感分析是以句子級為單位進行處理的。相比于篇章級的語料處理我們的方法可以進一步的降低情感分析的難度。
3.3.2? 基于情感詞典獲取文本情感標簽
在大多數情況下,人們習慣直接用情感詞來表達自己的態度和觀點。例如用“excellent”來表達一種積極的觀點,而用“poor”來表達一種是消極的觀點。這種情感表達式稱為直接情感表達(direct sentiment expression)。因此我們可以根據一句話中的情感詞來大致判斷該句話的情感類型。每一個領域都有各自領域不同的情感詞,而不可能生成一個完備的適用于所有領域的情感詞典。但是全人類情緒大的分類是一致的,例如人類的情感不外乎喜、怒、哀、樂等。本研究采用[13]中大連理工大學的中文情感詞匯本體庫作為情感詞典進行情感分析。
Ekman是國際上具有廣泛影響力的情感分類庫,總共包含6大類的情感。大連理工大學的情感詞典本體庫在Ekman的基礎上加入了情感類別“好”,構建成了包含七大情感類別(樂、好、怒、哀、懼、惡、驚)21小類別的本體情感庫。本體庫中的每個情感詞都被分為正向、負向、中性三個情感極性,并具有從0到10等不同大小的情感程度值。大連理工大學的情感詞典本題庫從情感類別、情感強度及極性等方面對每一個中文詞匯或者短語進行描述完全符合本研究的需求。另外我們還準備了一個否定詞表(negation words)詞典,以便對句子中含有否定詞的情感詞進行極性反向處理。
詞典匹配的過程如下:
首先對句子進行分詞、去停用詞處理,獲得只包含主干和核心詞的精簡句子。
然后將精簡句子中的每一個詞去和情感詞典中的每一個詞進行比對,如果詞典中出現了該詞就記錄下該詞的情感類型、情感極性、情感強度等屬性。依次進行下去直到句子中的每一個詞都進行了比對。
接下來再將精簡后句子中的每一個詞去和否定詞表詞典中的詞進行對比,查看句子中是否包含否定詞,以便對句子的情感極性進行反向處理。
3.3.3? 處理字幕文件中的時間軸標簽
打開音頻轉化后的字幕文件,我們可以看出每一句文本上面包含一個文本序號、一個時間軸標簽,如圖5中方框框住的部分所示,我們把這三項看成一個字幕元素。上一小節中介紹的是對字幕元素中的文本進行自然語言處理提取文本的情感標簽。這一節對字幕元素中的時間軸標簽進行處理,獲得每一句文本出現的時間差值,最后將 srt格式字幕文件轉化為Unity 中可以處理的字幕文件。
時間軸標簽中包含兩個時間節點,每一個時間節點中又包含時、分、秒、毫秒四個時間元素。我們把每一個時間節點都換算成毫秒,計算兩個時間節點的差值,然后再用差值除以1000換算成秒為單位。這樣就獲得了一段文本在視頻中出現的時間差值。如圖6中方框框住的是第17句文本在視頻或音頻中持續的時間間隔。
每一句文本的情感標簽,文本內容,出現在視頻中的時間差值,組成一個新的字幕元素,如圖6所示每一行就是一個新的字幕元素。對原始音頻轉化后的字幕文件中的每一個字幕元素都做以上處理,srt格式字幕文件就轉化為了新的Unity 中可以處理的字幕文件。圖6是新的字幕文件的一部分截圖,每一行都是一個新的字幕元素,字幕元素中的元素項用$符分隔開。每一行的元素項從左到右依次是文本序號、情感標簽、情感強度、文本內容、在視頻或音頻中持續的時間間隔。
3.4? 情感動畫的匹配
3.4.1? 角色動畫和場景模型構建
在匹配文本、語音和動畫之前,需要對虛擬場景、演講者角色模型、肢體情感動畫進行構建。本研究角色動畫采用3DS MAX這款軟件進行建模,場景模型在Unity中構建。
3DS MAX是目前世界上應用最廣泛的三維建模、動畫、渲染軟件[14]。使用3DS MAX建模大體上可以分為三個步驟:①對于簡單幾何體,使用3DS MAX內置圖形庫可以很方便的建模;對于復雜的圖形多采用Nurbs面片建模或者Poly多邊形建模;②對建好的模型賦予材質,所謂材質就是模型的外表在3DS MAX中多采用貼圖的方式給模型賦材質,貼圖可以采用Photoshop軟件進行加工制作;③精細調節,最后要對模型進行精修,包含調整攝像機的位置,調整模型可視角度和反光度,等這一系列操作都完成之后最后把模型渲染輸出成TGA序列圖像格式。
構建完成模型和場景之后,接下來的就可以在Unity中對模型、音頻、字幕、動畫進行匹配生成VR視頻。關于拼接視頻,文獻[15]中方案是對全景圖片的拼接,實現網絡視頻的三維全景展示和本文方法有本質的區別。本文是對視頻元素進行處理而非對視頻中的幀圖片進行處理。
為了生動有趣的還原音頻中演說場景,我們用《瘋狂動物城》中Judy(朱迪)的虛擬形象來代替俞敏洪老師在虛擬場景中進行演講。關于虛擬人物文獻[16]中提到在沉浸式虛擬現實中,與虛擬人物的交互是最令人信服的一種體驗。因為參與者和角色共享一個三維空間,參與者能夠準確地感知角色的肢體語言。卡通虛擬人物構建完成之后還需構建一個卡通風格的 3D虛擬場景[17],虛擬化交互將成為一種比較有發展潛力的交互形式[18]。中探討將環境擴展到動畫和虛擬現實的下一代數字流派。圖7是在3DS MAX中對Judy模型進行建模的示例圖。
給Judy角色模型綁定骨骼,制作演講狀態中的肢體動畫,根據實際需要我們定制出演講中表達情緒的肢體動畫,僅作為演示我們給出圖8中四種演講狀態中的肢體動畫效果。
給角色模型綁定骨骼和動畫,生成獨立的動畫文件之后就可導入Unity場景中進行文本,音頻,演講者角色模型,肢體情感動畫的匹配。我們在Unity中導入一個林中小屋場景,導入Judy模型后的效果如圖9所示。
情感標簽和角色動畫匹配后,角色在Unity場景中的演講狀態我們也給出部分截圖,效果如圖10所示。
3.4.2? 字幕、音頻、角色、情感動畫匹配算法
把字幕文件、音頻文件、角色模型文件、情感動畫文件導入到Unity3D游戲引擎中,設計算法進行匹配,在虛擬場景中還原傳統視頻中的演說場景。
類似于傳統的流媒體視頻,本研究最后生成的VR視頻是一個包含人物、肢體動作、字幕、音頻的完整視頻,而且字幕、語言、肢體動作互相匹配。因為字幕是從語音轉化來的所以語音和字幕是一致的,所以匹配算法的關鍵有兩點,一是要讓字幕和出現該字幕的時間相一致;二是字幕內容和相應肢體動畫相一致。
時間和字幕同步的處理方法如下:
本研究使用的方法是借助Unity中的協程機制,播放音頻的同時讓Unity的主程序首先調用text字幕文件出現一行字幕文本,然后調用協程讓主程序等待一段時間再去調用text字幕文件中第二行要顯示的字幕文本。這個協程等待的時間就是text字幕文件中字幕文本相應行中最后一項的時間差值。與此同時,在主程序等待的這段時間內,調用情感標簽和肢體動畫文件匹配的算法,使字幕文本的內容和肢體動作相一致。通過以上方法就做到了語音、字幕、肢體動作相匹配。
字幕內容和相應肢體動畫一致的方法如下:
每條動畫制作的時候都有自己的播放時間即動畫自身時間長度ClipLength。每一段字幕出現也有一個時間差值WordTime。即在WordTime時間內,相應的動畫要播放完,這樣才能保證字幕內容和肢體動畫相一致。因為字幕出現的時長WordTime是定值,所以只有通過控制動畫的播放速度來使字幕內容和肢體動畫相一致。
動畫速度的處理方式有以下三種情況:
1. WordTime=ClipLength? ? Speed=1。
2. WordTime>ClipLength Speed=ClipLength/ WordTime,減慢動畫播放速度。
3. WordTime 通過以上三種不同情況的處理,就做到了肢體動作動畫和字幕內容相匹配。 4? ?實驗 4.1? 實驗環境設置 本文所提出的VR視頻制作方法,從前期各種轉制材料的準備到后期結果的呈現,是要依托一些軟硬件設施的。即使沒有計算機相關專業知識的人群,依照本文所提出的方法流程,運用VR視頻制作各個階段的軟硬件設施,完全可以復現實驗結果。下面給出各個階段所用到的軟硬件設施。 (1)軟件 提取視頻的音頻操作,本研究使用的是格式工廠這款軟件,這款軟件界面簡潔、操作方便,可以很容易的提取到所需格式的音頻文件。 音頻的語音識別文本化處理操作,本研究使用的是YeeCaption這款智能視頻翻譯軟件。這款軟件將繁瑣的視頻字幕翻譯制作最大程度的便捷化,成功實現從切分時間軸、字幕(語音)識別,到字幕翻譯校對及成品導出的一站式操作。 Srt格式字幕文件的自然語言處理操作,本研究使用的Python3.6.3版本程序語言構建流程函數,自然語言處理庫用的是NLTK庫,句子分詞用的是jieba分詞,情感詞典用的是大連理工大學信息檢索研究室整理和標注中文情感詞匯本體庫。 音頻、字幕、動畫的匹配過程是在3D游戲引擎Unity3D中完成的,我們使用的Unity3D軟件的版本是Unity 2017.2.0f3 (64-bit)。 PC操作系統是Win10系統,機身運行內存8GB,存儲內存500G,處理器是Intel i7處理器。 (2)硬件 制作VR及3D視頻過程中所需硬件設備為個人PC, VR及3D視頻完成之后結果呈現的方式之一是用VR頭顯。本研究結果呈現運用HTC Vive虛擬現實平臺。該平臺配有高清晰頭盔顯示器(HMD)、兩個運動控制器和兩個紅外跟蹤站。本項目在Unity3D中開發,所有腳本都是用C#語言中完成的。與虛擬環境的交互主要是通過Vive控制器完成的,控制器有幾個按鍵可用于交互。此外,制作完成的VR視頻也可以直接在PC上顯示3D視頻,呈現方式并不局限于VR環境。 (3)參與者 為了對我們所提出的VR視頻轉制方法和最后的視頻呈現效果進行評價,我們通過發送電子郵件給首都師范大學不同專業背景的學生來招募實驗志愿者。我們一共選擇了20位志愿者,為了消除性別、年齡差異,我們招募了10名男同學,10名女同學,他們的年齡都介于22歲至23之間,所有人的平均年齡為22.28歲。所有志愿者中其中10人宣稱之前體驗過虛擬現實技術,大多情況下這些體驗僅限于體驗過虛擬現實頭盔,或者基于智能手機的VR盒子。 在本實驗中我們把志愿者分成兩組,為了消除性別差異和對VR熟悉程度的差異,我們保證兩組人員總數相同,男女比例相同,對VR了解情況相一致。 4.2? 實驗流程 1. 對傳統制作VR視頻的方法進行調研,查詢整理材料,給出傳統方法所花費的時間、財力、和人力成本數據并和我們所提方法的成本進行對比。 2. 讓實驗受試者在VR演示裝備中去觀看轉制的視頻,觀看之后填寫調查問卷,對視頻沉浸性進行評價。 4.3? 實驗結果 4.3.1? VR全景視頻成本 (1)拍攝設備的價格花費大 國內外比較著名的全景相機品牌有:GoPro Omni、NextVR、Facebook surrond 360、LG 360cam、Samsung Gear 360、DetuTWIN 360、Ricoh THETA S、Nokia OZO、Insta 360,暴風魔眼等,部分品牌擁有多種不同型號相機,我們只選其中一種進行價格統計,由于受市場供求關系影響和商家戰略部署影響,同種品牌同型號的全景相機在不同時間、不同地區,價格會有差異。統計結果如表1所示。 (2)時間成本大,人員動用多且復雜 因VR全景視頻對于拍攝者及現場拍攝環境等要求比普通跟拍視頻要高,所以前期準備工作復雜,需要的策劃人員溝通人員會更多,對有較多經驗的全景攝影師需求也更大,同時相比較普通跟拍視頻而言,VR全景視頻的拍攝時間成本也會更大。 (3)后期難度高 普通視頻的后期制作主要在剪輯和布置特效兩項之中,而VR全景視頻首先要做的是將不同方位的素材進行拼合,還要進行畫面的校準等步驟,使成片塑造的環境更顯真實。所以從VR全景視頻后期制作方面來說,也是需要相當的時間耗費與制作功底。 4.3.2? 動捕裝備錄制CG視頻成本 (1)金錢成本大 通過對各種捕捉設備的市場行情分析,目前最低成本的小型硬件實時捕捉設備都要萬元以上RMB,而且僅僅是身體運動捕捉功能部分,而表情、手部,眼睛捕捉等都需要單獨購買相應的設備,全套購買齊全估計也要數十萬RMB,而像Vicon跟MotionAnalysis這樣著名的捕捉公司的最低配置都要100萬以上。部分品牌動捕裝備的價格統計如表2所示。 (2)人員動用多且操作流程復雜 捕捉設備包含身體運動捕捉設備,表情、手部,眼睛捕捉等相應設備,同時還需要多角度的控制器定位系統,而這些都需要專業人員提前進行調試、布置。如圖12中所示,角色演員要穿戴布滿傳感器的設備,在可定位的區域內活動,專業的技術人員要實時的操控相應的軟件進行動作的捕捉。整個過程是非常繁雜的,如果設備某個部分發生了故障,設備調試也要花費很長時間。 4.3.3? 本文所提VR及3D視頻生成方法成本 我們所提方法不需要全景相機,不需要動捕裝備,因此可以很大程度降低金錢成本,同時也降低了時間成本和人力成本。只需要針對已有的音視頻進行再次創作就可以生成高質量的VR內容。在這個過程中幾乎不花費金錢成本,只需要幾款軟件就可以進行VR視頻的轉制。人力成本方面最多兩個人就足夠了,一個人負責建模,一個人負責Unity中視頻的拼接。綜合以上VR內容生產成本的調研和分析我們可以得出表3中的結論。 相較于全景相機錄制全景視頻的方法、全身動捕裝備錄制VR視頻的方法,我們所提出的利用已有音視頻資料生成VR視頻的方法,可以快速、低成本自動生成高質量VR視頻。 4.3.4? 對轉制VR視頻的效果進行評價 實驗受試者分A,B兩組。志愿者們首先觀看原視頻,然后體驗轉制的VR視頻,體驗之后針對“我認為轉制后的VR視頻和原始視頻相比更有吸引力、沉浸性更強。”問題對VR視頻的效果進行評價[19]。中針對VR環境下解剖學領域的空間結構學習能力的提升的對比實驗[20],中關于虛擬現實環境下條形按鈕和圓形按鈕的對比實驗,評價方法都是采用上面所述的調查問卷評價方法。評測效果分5個等級從高到底分別是非常同意、同意、中立、不同意、非常不同意。評測結果如下。 由圖13,14中數據可以看出A,B兩組橫軸每一項的數據差異不是很大,A組中40%的同學非常同意VR視頻的呈現效果要好于原視頻,同意占比為30%。在B組中也有相似的結果,同意以上占比為70%。綜合A,B兩組數據我們可以看出70%的同學對我們所提實驗方法轉制的VR視頻呈現效果表示滿意,5%的同學保持中立,不同意以下占比為25%。 5? 結語 隨著虛擬現實技術和價格更加親民化的硬件設備普及,VR視頻內容的需求在逐漸增加。但現有的VR視頻的生成方法面臨著制作成本高,創作難的問題,而且對于過去珍貴的音、視頻資料很難按照VR的傳統生成模式來重新錄制。由此,本文提出一種新穎、低成本的利用已有音視頻資料生成VR視頻的方法。實驗表明,相比于傳統的VR視頻的制作方式,我們提出的方法可以大幅度節省時間成本、人力成本、金錢成本。 在將來的工作中,我們將會繼續該方面的研究來提高自然語言處理的準確度、優化匹配算法、建立一個包含更精細情感分類的肢體動畫庫,加入面部表情的情感匹配, 使我們的VR視頻制作流程更加簡潔,生成的VR視頻內容更加的真實、細膩。我們還將會研究專門針對演講、授課的情感分析,由此增強VR視頻的現場感染力。 參考文獻 [1] 楊琪, 黃建明. 家居漫游系統的設計與實現[J]. 軟件, 2015, 36(1): 26-31. [2] 徐雯皓, 李忠, 蘇鑫昊. 基于 3D 引擎的汶川震前水文變化三維模擬演示系統設計[J]. 軟件, 2018, 39(4): 176-179. [3] 唐實, 任淑霞, 王佳欣, 等. 基于虛擬VR技術的心臟醫療輔助系統的設計與應用[J]. 軟件, 2018, 39(6): 23-25. [4] 高偉, 王昱霖, 吳倩蓮, 等. 基于VR技術的教育游戲在英語教學中的應用與發展前景[J]. 軟件, 2018, 39(5): 60-65. [5] 王躍華. 淺析虛擬現實視頻的發展和應用[J]. 現代電影技術, 2016(07): 21-23. [6] 郭宗明, 班怡璇, 謝瀾. 虛擬現實視頻傳輸架構和關鍵技術[J]. 中興通訊技術, 2017, 23(06): 19-23. [7] 趙樂明子, 劉榮. 虛擬現實視頻市場的問題及對策研究[J]. 現代商業, 2018(02): 39-40. [8] 董振江, 張東卓, 黃成, 等. 虛擬現實視頻處理與傳輸技術[J]. 電信科學, 2017, 33(08): 45-52. [9] Santos, Camilo Telles Pereira and Santos, Celso Alberto Saibel, “5Cam: A Multicamera System for Panoramic Capture of Videos, ” in Proceedings of the 12th Brazilian Symposium on Multimedia and the Web (WebMedia '06), 2006, pp. 99--107. [10] 吳遠志, 門濤, 羅誼恒, 等. 全景微課視頻的設計與制作[J]. 電腦迷, 2017(03): 137-138. [11] 薛元昕, 李鷹. 基于虛擬現實技術的課程錄像制作研究與實現[J]. 煙臺職業學院學報, 2011, 17(01): 48-51. [12] 張敏. 虛擬現實VR(影視)內容的發展現狀和瓶頸[J]. 中國廣播電視學刊, 2017(09): 64-66. [13] 徐琳宏, 林鴻飛, 潘宇, 等. 情感詞匯本體的構造[J]. 情報學報, 2008, (2): 180-185. [14] 徐飛. 利用3DS MAX打造美麗世界——淺談3DS MAX的學習與應用[J]. 科技咨詢導報, 2007(10): 20. [15] 秦曉軍, 黃秋儒. 面向網絡視頻的三維全景展示技術[J]. 電視技術, 2014, 38(19): 120-122+154. [16] Gillies, Marco, “Creating Virtual Characters, ” in Proceedings of the 5th International Conference on Movement and Computing, 2018, pp. 22: 1--22: 8. [17] 曹瑜, 郭立萍, 杜紅燕, 等. 卡通風格3D 游戲場景設計制作技術[J]. 軟件, 2015, 36(3): 22-25. [18] Hailey, David E. , ”A Next Generation of Digital Genres: Expanding Eocumentation into Animation and Virtual Reality, ” in Proceedings of the 22Nd Annual International Conference on Design of Communication: The Engineering of Quality Documentation(SIGDOC '04), 2004, pp. 19--26. [19] Seo, Jinsil Hwaryoung and Smith, Brian Michael and Cook, Margaret E. and Malone, Erica R. and Pine, Michelle and Leal, Steven and Bai, Zhikun and Suh, Jinkyo, “Anatomy Builder VR: Embodied VR Anatomy Learning Program to Promote Constructionist Learning, ”in Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems(CHI EA '17), 2017, pp. 2070-2075. [20] Santos, A. and Zarraonandia, T. and D\'{\i}az, P. and Aedo, I, “A Comparative Study of Menus in Virtual Reality Environments, ”in Proceedings of the 2017 ACM International Conference on Interactive Surfaces and Spaces(ISS '17), 2017, pp. 294-299.
猜你喜歡
經營者(2016年12期)2016-10-21 07:39:01
中國科技博覽(2016年19期)2016-10-19 14:47:24
中國科技博覽(2016年19期)2016-10-19 13:40:37
中國科技博覽(2016年18期)2016-10-19 07:01:13
中國市場(2016年36期)2016-10-19 03:40:15
科學與財富(2016年28期)2016-10-14 21:28:54
科學與財富(2016年28期)2016-10-14 19:52:27
科學與財富(2016年28期)2016-10-14 19:49:55
科學與財富(2016年28期)2016-10-14 19:33:38
科學與財富(2016年28期)2016-10-14 03:14:22
