融合多層注意力機制與雙向LSTM的語義關系抽取
2019-10-11 11:24:36周文燁劉亮亮張再躍
軟件導刊 2019年7期
周文燁 劉亮亮 張再躍

1. 江蘇科技大學 計算機科學與工程學院,江蘇 鎮江 212003;
2. 上海對外經貿大學 統計與信息學院,上海 201620)
摘 要:關系抽取是構建如知識圖譜等上層自然語言處理應用的基礎。針對目前大多數關系抽取模型中忽略部分文本局部特征的問題,設計一種結合實體位置特征與多層注意力機制的雙向LSTM網絡結構。首先根據位置特征擴充字向量特征,并將文本信息向量化,然后將文本向量化信息輸入雙向LSTM模型,通過多層注意力機制,提高LSTM模型輸入與輸出之間的相關性,最后通過分類器輸出關系獲取結果。使用人工標注的百科類語料進行語義關系獲取實驗,結果表明,改進方法優于傳統基于模式匹配的關系獲取方法。
關鍵詞:位置特征;多層注意力機制;雙向LSTM;關系抽取
DOI:10. 11907/rjdk. 182763 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2019)007-0010-05
Multi-level Attention-based Bidirectional Long Short-Term
Memory Networks for Relation Extract
ZHOU Wen-ye1,LIU Liang-liang2,ZHANG Zai-yue1
(1. College of Computer, Jiangsu University of Science and Technology, Zhenjiang 212003,China;
2. School of Statistics and Information, Shanghai University of International Business and Economics, Shanghai 201620, China)
Abstract:Relational extraction is the basis for constructing upper natural language processing applications such as knowledge graph. Because most of state-of-the-art systems ignore the importance of the local feature, in this paper, we design a bidirectional LSTM network structure which combines position eigenvector and multi-level attention mechanism. Firstly, the model embedded the text information by extending word vector feature which was based on positional features. Secondly, the information was introduced into the bidirectional LSTM model, and multi-level attention was used to improve the probability between the input and output of LSTM model. Finally, it obtained the result by classifier. The proposed method in this paper achieves an better result than the tradition method.
Key Words: position feature; multi-level attention mechanism; bidirectional LSTM; relation extraction
基金項目:國家自然科學基金項目(61371114,611170165);江蘇高校高技術船舶協同創新中心/江蘇科技大學海洋裝備研究院項目(1174871701-9)
作者簡介:周文燁(1995-),女,江蘇科技大學計算機科學與工程學院碩士研究生,研究方向為軟件工程、模式識別與圖像處理;劉亮亮(1979-),男,博士,上海對外經貿大學統計與信息學院講師,研究方向為自然語言理解、知識工程與知識獲取;張再躍(1961-),男,江蘇科技大學計算機科學與工程學院教授,研究方向為數理邏輯與應用邏輯、知識表示與推理、智能信息處理。本文通訊作者:張再躍。
0 引言
在信息量快速增長的今天,如何利用信息抽取技術快速、有效地獲取準確信息,一直是自然語言處理領域的重要研究課題,受到了學術界與工業界的廣泛關注[1]。信息抽取包括概念抽取與關系抽取兩方面,關系抽取[2-3]的目標是自動識別相關三元組,該三元組由一對概念及其之間的關系構成。傳統關系抽取方法[4-5]通常采用基于手工標注語料的模式匹配方法,該方法在提取句子特征時依賴于命名實體識別的NLP系統,容易導致計算成本和額外傳播錯誤增加;另外,手工標記特征非常耗時,而且由于不同訓練數據集的覆蓋率較低,因而導致通用性較差[6]。近年來,基于深度學習框架的神經網絡模型成為實體關系抽取的新方法。深度學習是機器學習研究中的一個新領域,其動機在于建立、模擬人腦進行分析學習的神經網絡。神經網絡模型可自動學習句子特征,而無需復雜的特征工程[7-8]。研究過程中,Socher等[9]提出使用矩陣—遞歸神經網絡模型MV-RNN完成關系抽取任務。該方法能夠有效考慮句子的句法結構信息,但無法很好地考慮兩個實體在句子中的位置和句義信息,且方法運用準確率往往受限于句法分析準確率;Liu等[10]將卷積神經網絡(CNN)引入關系抽取任務,用于自動學習句子特征,但由于卷積神經網絡無法對較長的句子進行建模,因而存在兩個實體的遠距離依賴問題。另外,RNN 和CNN 都未充分利用局部特征以及全局特征,使得關系抽取準確性較差[11]。
LSTM(Long Short Term Memory)網絡是由Hochreiter & Schmidhuber[12]在1997年提出的一種RNN改進模型,其通過構造專門的記憶單元存儲歷史信息,能夠有效解決兩實體之間的長距離依賴問題。Xu等[13]以LSTM為基礎,利用詞向量、詞性標注、句法依存等方法對實體之間的最短依存路徑信息進行學習;劉燊等[14-15]則提出使用SDP-LSTM模型實現開放域實體關系抽取,可以分別處理句子可能出現的多個依存路徑。以上方法使用LSTM進行關系抽取,然而LSTM無法對局部特征與全局特征加以充分利用。
注意力機制是Treisman & Gelade[16]提出的一種模擬人腦的模型,通過計算概率分布,突出關鍵輸入信息對模型輸出的影響以優化模型。Bahdanau等[17]將注意力機制應用在自然語言處理任務中,以提升機器翻譯的準確性。注意力機制可以充分利用句子的局部特征及全局特征,通過賦予重要特征更高權重,從而減少噪聲,提高關系抽取的準確性。因此,本文提出一種基于實體位置特征與多層注意力機制的LSTM實體語義關系獲取方法,運用兩層注意力機制,分別對字和句子增加注意力。實驗結果表明,該方法有利于提升實體語義關系獲取效果。
1 LSTM網絡結構
Long Short Term Memory(LSTM)網絡是一種RNN的特殊類型,可以對長期依賴信息進行學習[18]。LSTM模型在文本處理領域的很多問題上都取得了很大成功,并得到了廣泛應用。
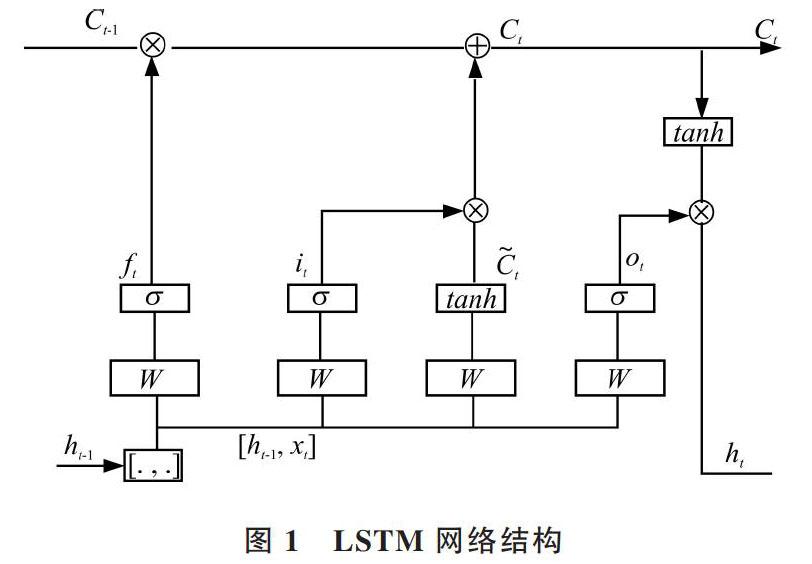
LSTM通過特殊設計以避免長期依賴問題。LSTM與RNN一樣,具有一種重復神經網絡模塊的鏈式結構,但LSTM重復的模塊擁有不同結構。在[t]時刻,LSTM有3個輸入:當前時刻網絡輸入值、上一時刻LSTM輸出值與上一時刻單元狀態,以及2個輸出:當前時刻LSTM輸出值與當前時刻單元狀態。LSTM使用3個控制開關即3個門進行控制,分別是遺忘門、輸入門和輸出門。LSTM通過遺忘門決定從細胞狀態丟棄什么信息,通過輸入門決定將什么新信息存放在細胞狀態中,并通過輸出門決定輸出什么值。LSTM網絡結構如圖1所示。
其中,公式(1)用于計算輸入門,[ht-1]表示上一狀態輸出值,[xt]表示當前狀態輸入值,公式(2)用于計算遺忘門,公式(3)用于計算輸出門。[W]表示權值矩陣,[b]表示偏置量,激活函數采用sigmoid函數,[Ct]表示單元狀態。
LSTM模型的工作機制是將當前記憶與長期記憶進行組合,其最終輸出由輸出門和單元狀態共同確定。由于將長短期記憶進行了有機關聯,LSTM模型解決了關系抽取過程中的長期依賴問題,但缺乏對句子中局部特征與全局特征加以利用的環節。為此,本文引入多層注意力機制,對于相關字與句子分別賦予相關權重,并減少噪聲,以提高關系獲取的準確性。
2 改進的關系抽取模型
本文結合實體位置特征與多層注意力機制的雙向LSTM網絡結構構建關系抽取模型,采用位置嵌入、字嵌入相結合的字向量表示方法,增加語義相關度,采用LSTM模型以避免傳統深度學習方法的長距離依賴問題,同時采用多層注意力機制,充分利用句子的局部特征以及全局特征。該模型框架主要包括以下兩部分:①融合特征的字向量生成。對語料庫中的文本信息進行向量化處理,提取文本的實體特征與位置特征,然后將這些特征轉換為字向量,得到句子融合特征的字向量表示;②關系抽取模型構建。將文本的字向量表示導入雙向LSTM模型中,采用多層注意力增強文本的局部特征與全局特征,將增強后的特征導入分類器進行分類,輸出分類結果。模型框架如圖2所示。
2.1 融合特征的字向量表示
向量化表示是一種分布式表示,一般使用字向量表示作為神經網絡的輸入,本文將每個輸入字轉換為向量。考慮到在關系抽取任務中,越靠近實體的字通常越能表示句子中兩個實體的關系,因此本文融合位置信息以擴充字向量維度,改進后的字向量稱為融合特征的字向量。
(1)字向量:構建字向量是將文本信息轉換為向量形式。將每個句子轉換成一個多維矩陣,給定一個由[T]個字組成的句子[S=x1,x2,?,xi,?,xT],對于句子[S]的每個字,使用word2vec[19]將每個字[xi]映射到一個低維實值向量空間中,通過公式(6)對句子進行字向量處理。
其中,[ei]是字[xi]的字向量表示,[vi]是輸入字的one-hot形式,[Wword∈Rdωm],其中[m]是固定長度的詞典,[dω]表示字向量維度,[Rdωm]是一個向量空間,由此得到句子中每個字的向量化表示[e=e1,e2,?,eT]。
(2)位置向量:在關系抽取任務中,越靠近目標實體的字通常更能表示句子中兩個實體的關系。本模型使用位置向量標記實體對,可以幫助LSTM判斷句中每個字與實體對的位置,將句子中第[i]字分別到[e1]和[e2]相對距離的組合定義為位置向量。句子實例如圖3所示。
圖3 句子實例
其中,“千金”是指“關系”,其關聯實體是“盧恬兒”(用[e1]表示)和”盧潤森”(用[e2]表示)。假設在句子向量化過程中,字向量維度為[dw],位置向量維度為[dp],則將字向量與位置向量組合在一起,將句子表示成一個向量[w=][ω1,ω2,?,ωT],其中[ωi∈Rd(d=dw+dp×2)]。
在圖3實例中,該句子從關系“千金”到實體[e1]“盧恬兒”的距離[s1]為19,從關系“千金”到實體[e2] “盧潤森”的相對距離[s2]為5,則“千金”的向量化表示如圖4所示。
圖4 融合特征字向量表示
2.2 注意力機制
注意力機制的思想來自于模仿人們在讀取句子信息時注意力的行為。因為中文信息對關系抽取的影響可能來源于某個關鍵字,所以類似關鍵字這種局部特征具有重要影響力,本文使用注意力機制增強局部特征與全局特征。
(1)字級注意力機制: 將句子向量[w=ω1,ω2,?,ωT]輸入LSTM模型中,獲得句子初步訓練結果[ht],并使用公式(7)進行處理。
在實際場景中,并非所有字都對句子含義的表示具有同等作用,在訓練過程中隨機初始化并共同學習字上下文向量[uω]。因此,引入字級注意機制衡量字與關系的相關程度,并匯總信息字的表示以形成句子向量。字級注意力機制具體公式如下:
在使用字級注意力機制時,[αt]為該字[ut]與單字上下文向量[uω]的歸一化表示,[s]為兩者加權和。
(2)句級注意力機制:將通過字級注意力機制得到的[s]組成的句子輸入LSTM模型得到輸出[hi]。與字級注意力機制相似,在訓練過程中隨機初始化并共同學習句子上下文向量[us,v]是所有句子的向量集合,具體公式如下:
2.3 結果分類
將實驗得到的結果通過分類器進行關系分類,輸出分類結果[S(x)]。
其中,[Wm]表示分類器權值矩陣,[bm]表示分類器偏置,[s]表示分類器選擇,本文選擇Softmax作為分類器。Softmax一般用于多分類過程中,其將多個神經元的輸出映射到(0,1)區間內。本模型輸出[S(x)={p1,p2,,p3,?,pi,?,][p12}]是12維向量,第[i]維表示屬于第[i]類的概率[pi]。
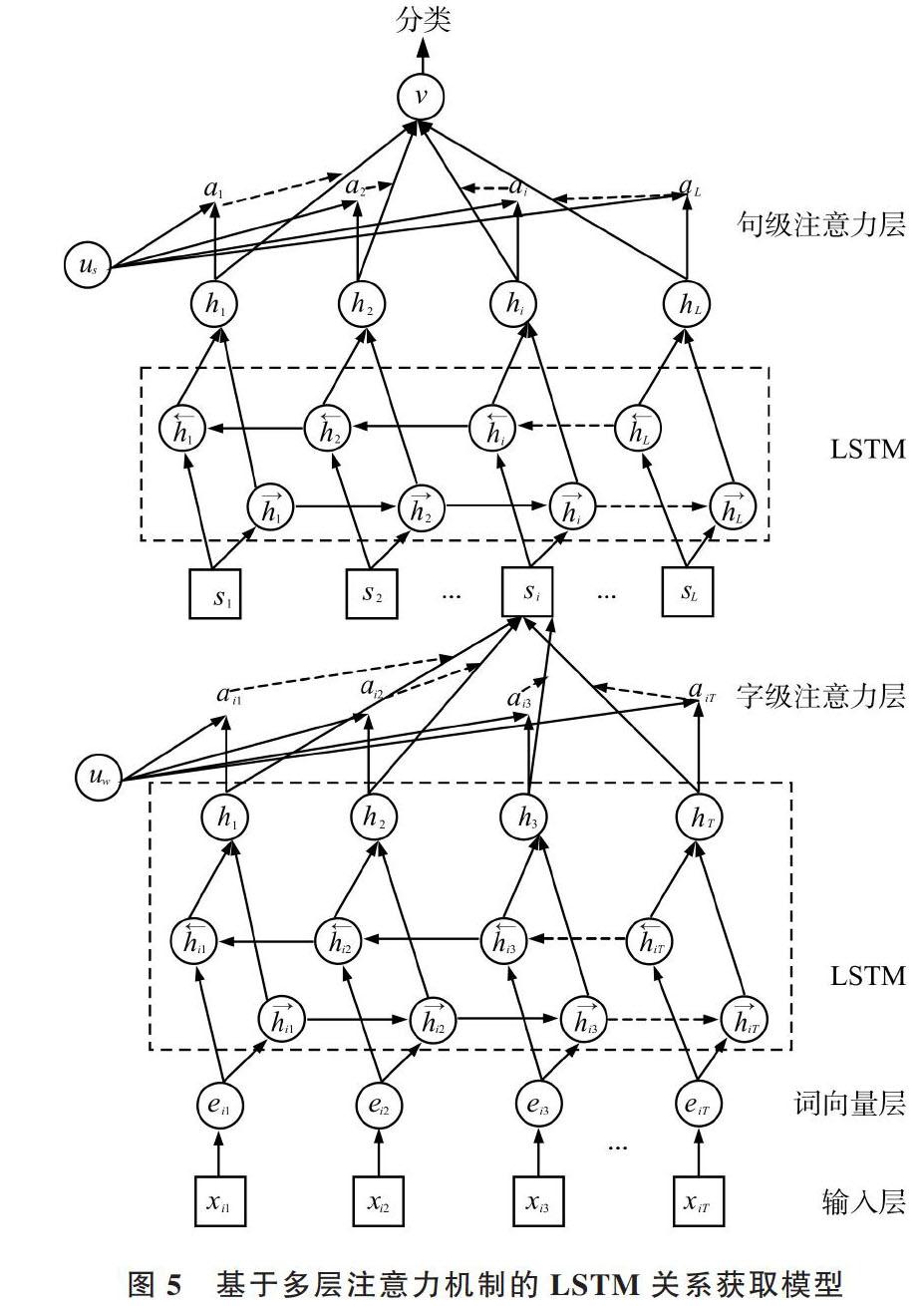
2.4 基于多層注意力機制的雙向LSTM關系獲取模型
基于多層注意力機制的LSTM關系獲取模型構建主要包括LSTM構建、注意力機制引入與分類3部分,其模型如圖5所示。
圖5 基于多層注意力機制的LSTM關系獲取模型
本模型采用雙向LSTM網絡結構與雙向LSTM模型,其網絡包含左右序列上下文的兩個子網絡,分別是前向與后向傳遞。將上一節得到的句子向量化表示作為輸入,以第[i]個字為例,其輸出為:
綜上所述,基于多層注意力機制的雙向LSTM關系獲取模型由兩層LSTM神經網絡與兩層注意力機制組成。為了對句子局部與全局特征加以充分利用,本文選擇LSTM輸出層加入注意力機制,步驟如下:①輸入語料中的句子,對句子進行向量化處理,得到句子的融合特征向量化表示;②將向量化表示后的句子輸入LSTM網絡中進行初步學習,然后對其結果增加字級注意力機制,對句子局部特征增加權重;③將步驟②得到的結果輸入LSTM網絡中進行學習,然后對其結果增加句級注意力機制,并對全局特征增加權重;④將步驟③輸出結果輸入分類器中,得到輸入句子的實體關系類別,完成模型訓練。
3 實驗
為了驗證具有實體位置關系與注意力機制的雙向LSTM關系獲取模型可以使關系獲取準確率更高,使用本文設計的網絡結構進行實驗。首先介紹實驗中使用的數據集與評估指標,并使用交叉驗證確定模型參數;然后評估多層注意力的影響,并在不同大小的數據上顯示其性能;最后,將設計的模型與幾種關系抽取方法在同一數據集上進行實驗比較。
3.1 實驗數據
實驗采用的數據集是以百度百科、互動百科等中文類百科的語料為基礎,進行人工標注后整理生成的。該數據集包括18 636個訓練樣本與2 453個測試樣本,共包含12種關系。樣本關系如表1所示,樣本示例如表2所示。
表1 樣本關系
表2 數據集示例
3.2 實驗指標評價
本文采用準確率([precision])、召回率([recall])和[F1]值作為模型性能評價指標,指標計算公式如下:
[precision=right_outall_out] (15)
[recall=right_outthis_all] (16)
[F1=2?recall?precisionrecall+precision] (17)
[right_out]表示輸出的判斷正確的個數,[all_out]表示輸出的所有關系個數,[this_all]表示測試集中所有此類關系的個數。
3.3 參數設置
本次實驗模型激活函數選用sigmoid函數,并采用Softmax作為分類器。為了避免模型在計算過程中出現過擬合現象,采用L2正則化方法對網絡參數進行約束。訓練過程引入dropout策略,采用批量的Adadelta優化方法用于模型訓練,并采用交叉驗證方式進行驗證,具體參數設置如表3所示。
表3 參數設置
3.4 實驗結果分析
將3.1節語料庫的訓練樣本作為訓練集進行模型訓練,采用測試樣本對訓練后的模型進行測試。實驗抽取12類關系的評價指標如表4所示。
表4 12類關系評價指標
由表4可以看出,對類似于“父母”、“祖孫”等表達較為簡單、容易辨別的語義關系,本模型抽取結果要比“情侶”、“朋友”等表達更為復雜,且容易混淆的語義關系抽取效果更好。這是由于復雜的語義關系在進行關系抽取時對上下文語境要求更為嚴格,抽取難度較高,而簡單的語義關系更容易被模型所學習,抽取難度較低。
3.5 對比試驗分析
為了體現本文模型在關系抽取的準確度和穩定性上存在一定優勢,將本模型與傳統基于模式匹配[20-21]的關系抽取方法進行比較。同時,為了突顯本文模型的優勢,實驗設定了3個模型:一是只采用LSTM結合的模型,二是只采用句級注意力機制的模型,三是本文提出的模型,實驗結果如表5所示。
表5 實驗對比結果
由表5可以看出:
(1)LSTM方法相比于傳統基于模式匹配的關系提取方法,具有更高的召回率,且減少了手工標注的繁瑣過程,提取準確率更高。
(2)LSTM+句級注意力機制方法相比于單純的LSTM方法,對LSTM模型輸入句子與輸出句子之間的相關行進行權重計算,提高了LSTM模型的準確率,[F1]值更高,性能更好。
(3)本文設計的模型對局部特征進行處理,增加了句子中字的位置向量特征與字級注意力機制,提高了重要字的權重,增加了局部特征。相比于LSTM+句級注意力機制,該模型在召回范圍內精度較高,準確率也有所提升,表明本文提出的模型是有效的。
4 結語
本文提出一種新的端對端神經網絡模型用于實體關系獲取,該模型不僅保留了LSTM可避免長距離依賴問題的優勢,還利用整個句子的序列信息,增加了位置向量特征與多層注意力機制,并充分利用了局部特征與全局特征,提高了關系抽取準確率。但該方法只能抽取預先設定好的關系集合,而對于開放領域的自動關系獲取方面仍有待進一步研究。
參考文獻:
[1] 郭喜躍,何婷婷. 信息抽取研究綜述[J]. 計算機科學,2015,42(2):14-17,38.
[2] 郭喜躍,何婷婷,胡小華,等. 基于句法語義特征的中文實體關系抽取[J]. 中文信息學報,2014,28(6):183-189.
[3] 臺麗婷. 基于半監督機器學習的實體關系抽取算法研究[D]. 北京:北京郵電大學, 2018.
[4] 陳立瑋,馮巖松,趙東巖. 基于弱監督學習的海量網絡數據關系抽取[J]. 計算機研究與發展,2013,50(9):1825-1835.
[5] 賈真, 何大可, 楊燕,等. 基于弱監督學習的中文網絡百科關系抽取[J]. 智能系統學報, 2015(1):113-119.
[6] 徐健,張智雄,吳振新. 實體關系抽取的技術方法綜述[J]. 現代圖書情報技術,2008(8):18-23.
[7] 李楓林,柯佳. 基于深度學習框架的實體關系抽取研究進展[J]. 情報科學,2018,36(3):169-176.
[8] 劉紹毓, 李弼程, 郭志剛,等.? 實體關系抽取研究綜述[J].? 信息工程大學學報, 2016, 17(5):541-547.
[9] 郭麗,劉磊. 基于關系相似度計算的實體關系分類研究[J]. 軟件導刊,2013,12(4):130-131.
[10] SOCHER R,HUVAL B, MANNING C D, et al. Semantic compositionality through recursive matrix-vector spaces[C]. Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2012:1201-1211.
[11] LIU C Y, SUN W B, CHAO W H, et al. Convolution neural network for relation extraction[C]. International Conference on Advanced Data Mining and Applications,2013:231-242.
[12] SUNDERMEYER M,SCHLüTER R,NEY H. LSTM neural networks for language modeling[EB/OL]. http://www-i6.informatik.rwth- aachen.de/publications/download/820/Sundermeyer-2012.pdf.
[13] GERS F A,SCHMIDHUBER J,CUMMINS F. Learning to forget: continual prediction with LSTM[J]. Neural Computation, 2014, 12(10):2451-2471.
[14] YAN X,MOU L,LI G, et al. Classifying relations via long short term memory networks along shortest dependency path[J].? Computer Science, 2015, 42(1):56-61.
[15] 劉燊. 面向《大詞林》的中文實體關系挖掘[D]. 哈爾濱: 哈爾濱工業大學,2016.
[16] TREISMAN A,SYKES M,GELADE G. Selective attention and stimulus integration[J]. Attention and performance VI,1977,333:97-110.
[17] BAHDANAU D,CHO K,BENGIO Y. Neural machine translation by jointly learning to align and translate[J]. Computer Science, 2014.
[18] HOCHREITER S. The vanishing gradient problem during learning recurrent neural nets and problem solutions[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based, Systems, 1998, 6(2):107-116.
[19] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]. International Conference on Neural Information Processing Systems. Curran Associates Inc, 2013:3111-3119.
[20] BRIN S. Extracting patterns and relations from the World Wide Web[M]. Berlin:Springer Berlin Heidelberg,1998.
[21] 李夢瑤,向卓元. 基于語音識別技術的移動全能秘書平臺設計[J].? 軟件導刊,2015,14(8):127-129.
(責任編輯:黃 健)
