應用于音樂節目分類的Apriori挖掘算法設計
2019-10-14 03:18:09李臻
現代電子技術 2019年19期
李臻

摘 ?要: 傳統Apriori挖掘算法需多次掃描數據庫、多次連接頻繁項集,導致挖掘效率較低,為此對Apriori挖掘算法加以改進,設計一種新的Apriori挖掘算法用于音樂節目分類。改進的Apriori挖掘算法采用萊特準則對音頻數據進行野值與噪聲平滑處理,改進Apriori挖掘算法的音頻數據庫映射令兩個線性表分別負責音頻數據存儲和對應項存儲,音頻數據庫掃描次數降為一次;改進Apriori挖掘算法的連接次數無需對不具備交運算能力的元素進行交運算操作,減少頻繁項集連接次數。基于改進頻繁項集Apriori挖掘算法挖掘頻繁項集、生成音頻數據關聯規則,基于關聯規則集構建分類器,實現音樂節目分類。實驗結果顯示,改進Apriori挖掘算法用于音樂節目分類的效率優勢突出,準確度高。
關鍵詞: 音樂節目; 節目分類; Apriori挖掘算法; 分類器構建; 頻繁項集; 關聯規則
中圖分類號: TN911.1?34; TP301.6 ? ? ? ? ? ? ? ? ?文獻標識碼: A ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)19?0090?05
Abstract: Traditional Apriori mining algorithm needs to scan database and connect frequent itemsets many times, which results in low mining efficiency. To improve the Apriori mining algorithm, a new Apriori mining algorithm is designed for music program classification. The Wright criterion is used in the improved Apriori mining algorithm to smooth the outliers and noises of audio data, and improves the mapping of the audio database of Apriori mining algorithm, so as to make the two linear tables responsible for the storage of audio data and corresponding items respectively, and the scanning times of the audio database reduced to one time. The improved Apriori mining algorithm does not need to operate the connection times of the elements that do not have the ability of intersection operation. Row intersection operation reduces the number of frequent itemset connections. Based on the improved Apriori mining algorithm of frequent itemsets, frequent itemsets are mined and audio data association rules are generated. A classifier is constructed based on association rules to realize music program classification. The experimental results show that the improved Apriori mining algorithm has prominent efficiency advantages and high accuracy in music program classification.
Keywords: music program; program classification; Apriori mining algorithm; classifier establishment; frequent itemset; association rule
0 ?引 ?言
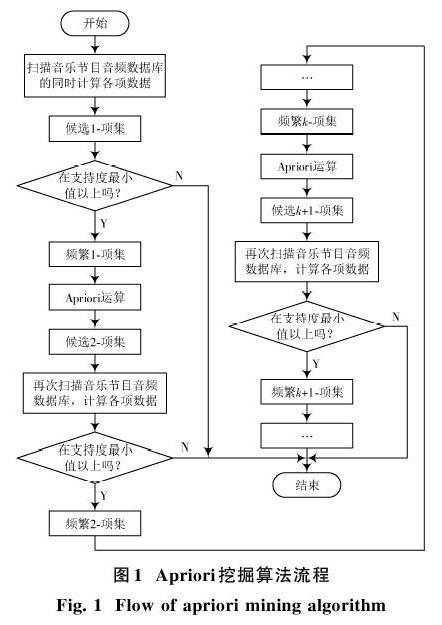
Apriori算法是一種高效、準確的數據挖掘算法,用于挖掘數據庫頻繁項集、生成關聯規則,得到的關聯規則符合置信度與支持度最小原則[1]。基于生成的關聯規則可完成數據挖掘,從海量數據中獲取目標數據。基于關聯規則集構造分類器進行數據分類已經取得良好成效。因此,Apriori挖掘算法在海量數據處理方面具有廣泛的應用前景,目前涉及醫療、教育、電子商務等熱門行業,實現經濟效益與社會效益雙豐收[2]。待挖掘數據庫中的海量數據往往存在噪聲和缺失部分,為保障挖掘精度和效率,需對數據庫進行過濾處理,降低數據關聯規則挖掘難度[3]。本文設計一種應用于音樂節目分類的Apriori挖掘算法,對傳統Apriori挖掘算法加以改進。待挖掘數據為音樂節目的音頻數據,首先基于野值處理與噪聲平滑處理方式清理音頻數據,其次采用改進的Apriori挖掘算法挖掘音頻數據間的關聯規則,該關聯規則的支持度與置信度最小。基于改進Apriori挖掘算法獲取的關聯規則提取音樂節目音頻數據間的關聯關系,最后實現音樂節目分類。
2) 掃描音頻數據庫即可獲取全部1?候選項集的音頻標識,繼而掃描[Bk],[Hk],生成其余候選集,上述過程只進行一次音樂節目音頻數據庫掃描。
1.3.2 ?連接操作改進
定義如下情況,[L3={{]1,2,3},{1,2,4},{1,2,5},{1,2,6},{1,2,7},{2,3,4},{2,3,5},{2,3,6},{2,3,7}},此時支持度最小值已知,求取[H4]數值。采用Apriori挖掘算法求取時,生成的[H4]候選集包括16個候選子集,生成的候選項冗余內容占比較大,降低了音頻數據挖掘效率、提升了數據挖掘難度,若想獲取頻繁項集挖掘的最終結果需經過數次連接操作。
通過優化交運算改進Apriori挖掘算法中的連接操作,減少連接操作的次數,節約數據挖掘時間[9]。采用Apriori挖掘算法挖掘關聯規則過程中,頻繁項集生成候選集時,在音頻數據集生成新音頻數據集過程中進行交運算[10]。候選項集支持度通過音頻數據模與音頻數據數量集得到,任意頻繁項集中的[xi]與[xj]不具備交運算的能力時,無需對[xi]與[xj]之后的元素進行交運算操作,節約連接次數,提升算法效率。
1.3.3 ?分類器構建
根據改進Apriori挖掘算法生成高質量的音樂節目分類關聯規則,構建音樂節目分類器。基于改進Apriori挖掘算法得到關聯規則集,定義為[S],[M]表示訓練音頻數據集。分類器構建原理為:查找具備覆蓋數據集[E]能力的規則集命名為[V?S],查找范圍是[S],根據[S]中不同的規則排序情況選取[L]中的規則,此時默認類別存在[V]中。由此完成分類器構建,實現音樂節目高效分類。
2 ?實驗分析
基于本文設計的改進Apriori挖掘算法進行音樂節目分類實驗,驗證本文算法用于音樂節目分類的優越性。實驗采用的音樂節目音頻數據由某權威數據平臺提供,包括流行、美聲、古典、民族、說唱5個音樂節目類別,數據總規模為500 MB,依據測試實際情況劃分成不同大小的小規模音頻數據庫,分別命名為數據庫A、數據庫B、數據庫C、數據庫D、數據庫E。
2.1 ?音頻數據規模與運行時間的關系
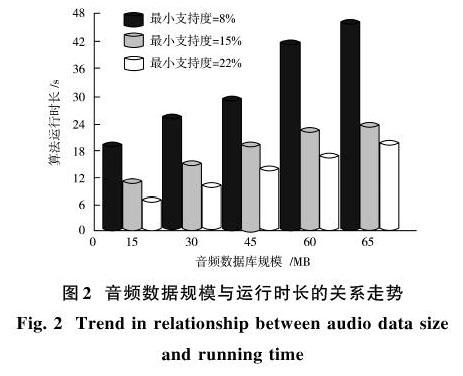
設定支持度最小值為定值,研究音頻數據規模與運行時間的關系,當本文算法的最小支持度設定為8%,15%,22%時,音頻數據規模與運行時長的關系如圖2所示。
分析圖2能夠看出,音樂節目音頻數據規模與本文算法挖掘頻繁項集用時成正比,兩者為同時增長趨勢。數據規模相等的情況下,最小支持度越小,算法挖掘用時越長,這是因為本文算法最小支持度增加,而符合條件的支持度值相應減少,減少了算法運算步驟與用時,算法挖掘效率有所提升。
由此可知,本文算法挖掘音樂節目音頻數據過程中,挖掘效率受數據庫規模與算法最小值支持度的影響。
2.2 ?支持度最小值與運行時間的關系
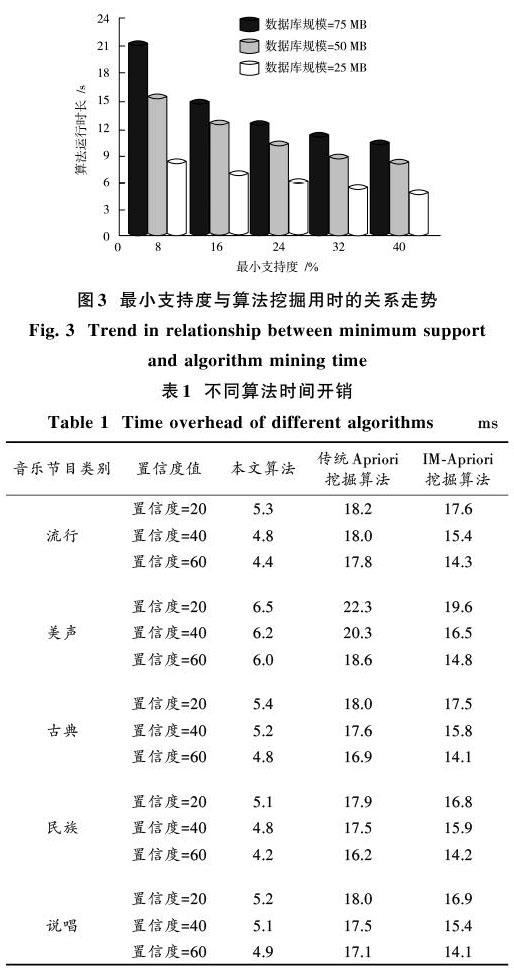
設置25 MB,50 MB,75 MB三種規模的音樂節目音頻數據庫,采用本文算法完成音樂節目分類中的關聯規則挖掘,得到最小支持度與算法挖掘用時關系,如圖3所示。
分析圖3能夠看出,音頻數據庫規模為75 MB,50 MB,25 MB時,算法運行最大用時出現在最小支持度為8%時,分別為21 s,15.8 s,8.8 s,三種規模數據庫運行曲線均為下降趨勢,即隨著算法最小支持度的增加,算法運行時長降低,此現象與2.1小節結論一致。圖中數據顯示,音頻數據庫規模越大,算法運行時間越長,這是因為數據庫規模大,掃描數據的用時較長,導致算法運行效率降低。上述實驗結果表明,改善本文算法挖掘關聯規則效率的方法是減少音樂節目音頻數據庫掃描次數。
2.3 ?不同挖掘算法用于音樂節目分類
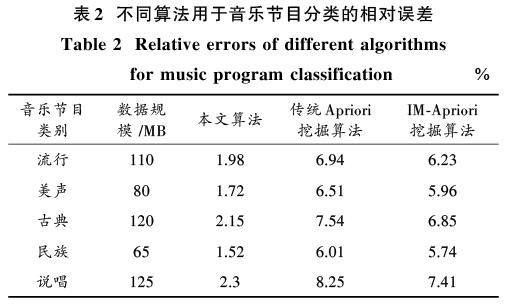
采用傳統Apriori挖掘算法、IM?Apriori挖掘算法作為對比算法進行測試,測試三種算法在音樂節目分類中的應用情況,記錄三種算法進行音樂節目分類的時間開銷情況,不同算法時間開銷如表1所示。
由表1能夠看出三種算法用于音樂節目分類的效率,其中,本文算法時間開銷最短,在4.4~6.5 ms之間,傳統Apriori挖掘算法與IM?Apriori挖掘算法時間開銷分別在14.1~22.3 ms之間,本文算法呈現較優的挖掘效率。這是因為本文算法在傳統Apriori挖掘算法基礎上對音頻數據庫映射和連接操作加以改進,數據庫映射改進后包含兩個線性表,分別負責音頻數據存儲、對應項存儲,只需進行一次音頻數據庫掃描,大大節約了算法挖掘時間。此外,判斷頻繁項集的交運算能力,對于不具備交運算能力[xi]與[xj]之后的元素無需進行交運算操作,節約了連接次數,提升了本文算法效率。
三種算法進行音樂節目分類結果如表2所示。
分析表2能夠看出,本文算法進行音樂節目分類誤差較小,低于2.5%,傳統Apriori挖掘算法與IM?Apriori挖掘算法的分類誤差均在5%以上,因此,本文算法精度最高。同時,三種算法的分類誤差均隨音樂節目音頻數據庫規模的增加而增加,證明數據庫規模影響算法進行關聯規則挖掘的準確度,影響音樂節目分類誤差。
3 ?結 ?論
本文對傳統Apriori挖掘算法進行優化,設計一種新的Apriori挖掘算法用于音樂節目分類。本文算法改進體現在兩個方面:音頻數據庫映射改進和連接操作改進。一方面,數據庫映射改進后存在兩個線性表,分別負責音頻數據存儲、對應項存儲,掃描數據庫次數由多次變為一次,提高了算法挖掘效率;另一方面,通過判斷頻繁項集的交運算能力,終止任意頻繁項集中不具備交運算能力的元素進行交運算操作,減少連接次數,提升算法效率。本文算法改進后,挖掘音頻數據關聯規則的效率大大提升,進一步提升了音樂節目分類效率。
參考文獻
[1] 鄭銀環,王嘉珺,郭威,等.基于特征旋律挖掘的二階馬爾可夫鏈在算法作曲中的研究與應用[J].計算機應用研究,2018,35(3):849?853.
ZHENG Yinhuan, WANG Jiajun, GUO Wei, et al. Research and application on second?order Markov chains based on feature melody mining in algorithmic composition [J]. Application research of computers, 2018, 35(3):849?853.
[2] 李濤,林陳,王麗娜.一種改進的相關項對挖掘算法研究[J].計算機仿真,2016,33(8):223?228.
LI Tao, LIN Chen, WANG Lina. An improved algorithm research on mining correlation pairs [J]. Computer simulation, 2016, 33(8): 223?228.
[3] 徐開勇,龔雪容,成茂才.基于改進Apriori算法的審計日志關聯規則挖掘[J].計算機應用,2016,36(7):1847?1851.
XU Kaiyong, GONG Xuerong, CHENG Maocai. Audit log association rule mining based on improved apriori algorithm [J]. Journal of computer applications, 2016, 36(7): 1847?1851.
[4] 魏玲,魏永江,高長元.基于Bigtable與MapReduce的Apriori算法改進[J].計算機科學,2015,42(10):208?210.
WEI Ling, WEI Yongjiang, GAO Changyuan. Improved apriori algorithm based on Bigtable and MapReduce [J]. Computer science, 2015, 42(10): 208?210.
[5] 黃文成,賈立,彭道剛,等.基于Apriori的關聯規則算法及其在電廠中的應用[J].系統仿真學報,2018,30(1):266?271.
HUANG Wencheng, JIA Li, PENG Daogang, et al. Apriori?based association rule algorithm and its application in power plant [J]. Journal of system simulation, 2018, 30(1): 266?271.
[6] 楊俊瑤,蒙祖強,蔣亮.一種基于拓撲信息的物流頻繁路徑挖掘算法[J].計算機科學,2015,42(4):258?262.
YANG Junyao, MENG Zuqiang, JIANG Liang. Logistics frequent path sequence mining algorithm based on topological information [J]. Computer science, 2015, 42(4): 258?262.
[7] 黃俊杰,譚波,陳孝明,等.用Apriori關聯規則挖掘算法發現湖北電網雷擊災害的時空分布規律[J].應用科學學報,2017,35(1):31?41.
HUANG Junjie, TAN Bo, CHEN Xiaoming, et al. Spatiotemporal distribution of lightning disasters of power lines in hubei province using data mining based on Apriori association rules[J]. Journal of applied sciences, 2017, 35(1): 31?41.
[8] 孫學波,石飛達.基于Hadoop的Apriori算法研究與優化[J].計算機工程與設計,2018,39(1):126?133.
SUN Xuebo, SHI Feida. Research and optimization of Apriori algorithm based on Hadoop [J]. Computer engineering and design, 2018, 39(1): 126?133.
[9] 朱付保,白慶春,湯萌萌,等.基于改進Apriori算法的鐵路軌道質量分析與評價[J].微電子學與計算機,2015,32(10):159?162.
ZHU Fubao, BAI Qingchun, TANG Mengmeng, et al. Quality analysis and evaluation of tracks based on improved Apriori algorithm [J]. Microelectronics & computer, 2015, 32(10): 159?162.
[10] 趙學健,孫知信,袁源.基于預判篩選的高效關聯規則挖掘算法[J].電子與信息學報,2016,38(7):1654?1659.
ZHAO Xuejian, SUN Zhixin, YUAN Yuan. An efficient association rule mining algorithm based on prejudging and screening [J]. Journal of electronics & information technology, 2016, 38(7): 1654?1659.
