基于深度學習的電子病歷實體標準化
2019-10-15 02:21:53趙逸凡鄭建立徐霄玲
軟件導刊 2019年8期
關鍵詞:電子病歷
趙逸凡 鄭建立 徐霄玲

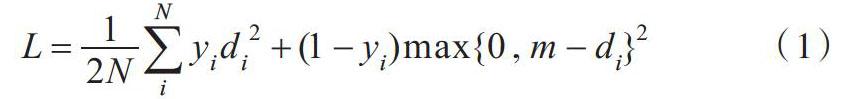

摘 要:電子病歷中同一醫療概念的提及形式具有多樣性,阻礙了醫療數據的分析和利用,研究電子病歷實體標準化具有現實意義。設計并實現了基于深度學習的電子病歷實體標準化算法,使用Siamese網絡架構和LSTM網絡搭建模型,采用Pairwise方法訓練模型,在測試集上與傳統基于編輯距離的方法進行比較。對手術實體標準化的實驗結果顯示,深度學習算法正確率達到79.71%,比傳統方法提高了17.4個百分點,表明深度學習算法在電子病歷實體標準化方面具有有效性。
關鍵詞:電子病歷;實體標準化;長短期記憶網絡;孿生網絡
DOI:10. 11907/rjdk. 182786 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2019)008-0012-04
Deep Learning Based Entity Normalization of Electronic Medical Records
ZHAO Yi-fan,ZHENG Jian-li,XU Xiao-ling
(School of Medical Instrument and Food Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
Abstract: The diversity of the mentioning forms of the same medical concept in electronic medical records hinders the analysis and utilization of medical data. Therefore, the entity normalization of electronic medical records has research significance. In this paper, we design and implement a deep learning-based entity normalization algorithm for electronic medical records. We use Siamese network architecture and LSTM network to build the model, and use pairwise method to train the model. Our method is compared to the traditional edit distance based method on the test set. The experimental results on surgery entity normalization showed that the accuracy of the deep learning algorithm is 79.71%,which is 17.4% higher than the traditional method, indicating the effectiveness of the deep learning algorithm on the entity normalization of electronic medical records.
Key Words: electronic medical record; entity normalization; long short-term memory network; Siamese network
基金項目:上海市衛計委中醫藥科技創新項目(ZYKC201702003)
作者簡介:趙逸凡(1994-),男,上海理工大學醫療器械與食品學院碩士研究生,研究方向為醫學信息學、自然語言處理;鄭建立(1965-),男,博士,上海理工大學醫療器械與食品學院副教授、碩士生導師,研究方向為醫學信息系統與集成技術、醫學儀器嵌入式控制系統;徐霄玲(1994-),女,上海理工大學醫療器械與食品學院碩士研究生,研究方向為自然語言處理。本文通訊作者:鄭建立。
0 引言
隨著醫療信息化的快速發展,各醫院積累了海量的電子病歷數據,如何有效利用這些數據提高醫療健康服務水平是研究熱點。電子病歷中同一醫療概念會有多種不同的表述形式,阻礙了醫療數據的檢索、分析和利用。把形式多樣的實體提及(Entity Mention)映射到標準的醫療術語,即實體標準化(Entity Normalization),是有效利用醫療健康數據的前提。
電子病歷實體標準化研究由國際公開評測任務推動,最具代表性的兩個評測任務是2013年的 ShARe/CLEF eHealth Shared Task 1b[1]和 2014年的 SemEval Task 7[2],這兩個任務都是要找到電子病歷中的實體(如疾病和癥狀)在“醫學術語系統命名法—臨床術語[3]”(Systematized Nomenclature of Medicine - Clinical Terms,簡稱 SNOMED-CT)中的編碼。現有實體標準化方法大多基于實體提及與標準術語的相似度得分。Rohit J Kate[4]通過改進的編輯距離計算相似度;Robert Leaman等[5]采用成對排序學習方法,用向量空間模型表示實體提及并引入權重矩陣計算相似度得分;Li Haodi等[6]使用深度學習方法取得在ShARe/CLEF 數據集和NCBI疾病數據集[7]上的最高正確率,該方法先使用人工編寫的規則從標準術語集中挑出候選,再基于卷積神經網絡輸出語義向量對候選排序。
上述研究都面向英文電子病歷,針對中文電子病歷的實體標準化研究相對較少,且缺乏公開可用的標注數據集。趙亞輝[8]選取國內某醫院的門診和住院病歷作為實驗數據,以國際疾病分類第10版(ICD-10)為目標術語集,研究了疾病名的標準化。在門診病歷上改進的編輯距離效果最好,正確率為76.6%,在住院病歷上Rank SVM的正確率最高,達到74.7%。
1 實體標準化算法
1.1 算法總體結構
基于深度學習的實體標準化算法總體結構見圖1。
圖1 基于深度學習的實體標準化算法總體結構
本算法主要思想是計算手術名與各個標準術語的匹配度,選擇最匹配的術語。匹配度計算采用Siamese網絡。Siamese 網絡是一種神經網絡結構而不是具體的某種網絡,在自然語言處理和計算機視覺中應用廣泛[9-13],它有兩個結構相同共享權值的子網絡。圖1中的兩個字嵌入完全相同,兩個編碼器也完全一樣。輸入的短語中每個字都會映射到一個多維稠密向量,稱為字嵌入,也常稱為字向量。本文使用Li S等[14]在百度百科的文本上訓練出的字向量,并且在訓練階段使字向量保持不變,不再微調。然后使用編碼器分別將兩個字向量序列映射到目標向量空間(可以看成是特征提取),最后在目標向量空間使用歐氏距離表示兩個輸入的匹配度,歐氏距離越小則匹配度越高。
本文未采用分類模型。因為手術的標準術語有上萬條,如果把每個術語看作一個類別則類別數量龐大,而每個類別的樣本數量較少甚至沒有,用分類算法顯然效果不佳。而 Siamese 網絡能從訓練樣本中學習到匹配度模型,即使類別數量龐大也能獲得不錯的效果。
1.2 BiLSTM網絡
本文采用 BiLSTM網絡作為 Siamese 網絡結構中用于提取特征的編碼器。
長短期記憶網絡(Long Short-Term Memory,簡稱 LSTM)是循環神經網絡(Recurrent Neural Network,簡稱RNN)的一種。普通的循環神經網絡用于序列數據建模時容易產生梯度爆炸和梯度消失,難以訓練。LSTM 通過引入遺忘門、記憶門、輸出門的三態門結構,使網絡能夠選擇性地保留狀態信息,解決了梯度爆炸和梯度消失問題。因此,LSTM適用于對序列數據建模,如文本數據。
普通的LSTM只能捕捉到從前向后的信息,但在實體標準化任務中僅有單向信息是不夠的。雙向長短期記憶網絡(Bi-directional Long Short-Term Memory,簡稱BiLSTM)由前向LSTM與后向LSTM組合而成,也就是在單向LSTM基礎上增加了一個逆向的LSTM,前向和后向輸出連接在一起作為整個網絡輸出,這樣能更好地捕捉到雙向序列信息[15]。
1.3 訓練方法
模型訓練采用 Pairwise 方法,樣本是一對短語,即手術名和標準術語。正例是病歷手術名和對應的標準術語,反例是手術名和不對應的標準術語。
兩個短語的向量表示為[F1]和[F2],它們的歐氏距離記作[d(F1,F2)]。訓練目標是使匹配兩個短語的[d(F1,F2)]盡可能小,而不匹配兩個短語的[d(F1,F2)]盡可能大。所以,損失函數需要滿足兩個性質:①對于兩個匹配短語,[d(F1,F2)]越小,損失函數越小;②對于兩個不匹配短語,[d(F1,F2)]越小,損失函數越大。
本文使用對比損失[16]作為損失函數,定義如下:
[L=12NiNyidi2+(1-yi)max{0,m-di}2]? ?(1)
其中[di]、[yi]分別表示第[i]項樣本的編輯距離和標簽。[yi=1]表示兩個短語匹配,[yi=0]表示兩個短語不匹配。當[yi=1]時,該樣本的損失是[yidi2],顯然滿足第一個性質。當[yi=0]時,該樣本的損失是[max{0,m-di}2],距離小于[m]時獲得[(m-di)2]的懲罰,距離大于[m]時沒有懲罰,距離越小損失越大,距離足夠大時損失為0,滿足第二個性質。
本文使用隨機梯度下降的改進算法Adam[17]使損失函數最小,訓練時采用mini-batch模式。
2 實驗
2.1 實驗數據
手術是電子病歷實體中的重要類別,本文選擇中文電子病歷中手術實體標準化問題進行實驗。我國一直采用國際疾病分類第9版臨床修訂本(International Classification of Diseases,Ninth Revision,Clinical Modification,簡稱 ICD-9-CM)作為手術與操作分類代碼的填寫標準,并于2015年對其擴碼修訂,收錄了醫院各個科室的各種手術與操作共計1萬余條,內容準確完備[18]。因此,本文使用擴碼后的 ICD-9-CM 中的標準術語作為手術實體標準化術語集。
本文選取某三甲醫院的300份電子病歷中出現的345個不同手術名作為實驗數據,并標注這些手術名對應的 ICD-9-CM 標準術語。隨機選取20%作為測試集,剩下的80%用于訓練。訓練需要成對的短語,訓練集中的手術名與對應的標準術語作為正例,反例是手術名與隨機選取的不對應ICD術語。通過上述方式構建的數據對總計5 429條,正負例比例為19∶1。
2.2 實驗環境、超參數與評價指標
實驗代碼使用 Python 3.6,Tensorflow 1.8 編寫;硬件環境:Intel E5-1620v4,NVIDIA GeForce GTX 1080;操作系統:Windows 10。
經過多次實驗,選定的超參數見表1。
表1 實體標準化算法超參數值
大部分實體標準化研究都采用正確率作為算法的評價指標。標準術語數量多,實體標準化難度較大,因此本文除top-1正確率外,還加入top-5正確率作為額外的評價參考[19]。top-5 正確率指算法給出的前5個候選中的正確答案比率。
2.3 實驗結果與分析
本文選擇基于編輯距離的相似度算法[20]作為比較基準,計算公式為:
[Sim(A,B)=1-d(A,B)max (len(A), len(B)]? ? ?(2)
式(2)中,A,B為待計算的兩個字符串,[len(A)]和 [len(B)]分別是字符串A和B的字符個數,[ d(A,B)]是A和B的編輯距離,即將A變成B的最小操作次數,允許的編輯操作為替換一個字符、插入一個字符、刪除一個字符3種。
表2 電子病歷手術實體標準化實驗結果
表2中,Siamese-LSTM表示編碼器部分使用單向的LSTM網絡,LSTM單元數量為20。Siamese-BiLSTM表示編碼器使用雙向LSTM,每個方向有10個LSTM單元,共20個。編輯距離算法的top-5正確率比top-1 正確率高了約14.5個百分點,差距較大。通過分析編輯距離算法出錯的樣本,發現與手術名在字面上相似的標準術語有多個,匹配時易造成干擾,比如“左肺上葉切除術”對應標準術語是“肺葉切除術”,但對“余肺肺葉切除術”造成了干擾,使得編輯距離算法無法作出正確匹配。兩種Siamese網絡在top-1、top-5正確率上都明顯好于編輯距離,可見對于手術實體標準化,僅依靠字面形式上的相似度,融合語義信息和序列信息的向量空間模型能有效消除干擾項影響,提升標準化正確率。對于Siamese網絡編碼器部分,雙向LSTM 在top-1、top-5正確率上均明顯好于單向LSTM,尤其是在最重要的top-1正確率上提升了約11.6個百分點,說明手術實體標準化任務僅有單向序列信息是不夠的,增加逆向序列信息能有效改善手術實體標準化效果。
3 結語
電子病歷實體形式多樣,嚴重阻礙了醫療數據的分析和利用。本文針對中文電子病歷實體標準化進行了研究,基于Siamese神經網絡結構和Pairwise訓練方法實現了手術實體標準化算法。實驗結果顯示,基于深度學習的方法比基于編輯距離的相似度算法準確率明顯提高,表明深度學習算法可有效應用到實體標準化問題上。但目前算法的正確率尚未達到實際應用程度,還需對現有算法進一步優化,或者使用更優的模型和訓練方法。
參考文獻:
[1] SUOMINEN H, SALANTER? S, VELUPILLAI S, et al. Overview of the share/clef ehealth evaluation lab 2013[C]. International Conference of the Cross-Language Evaluation Forum for European Languages, 2013: 212-231.
[2] PRADHAN S,ELHADAD N,CHAPMAN W,et al. SemEval-2014 task 7: analysis of clinical text[C]. Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014),2014: 54-62.
[3] DE SILVA T S,MACDONALD D, PATERSON G, et al. Systematized nomenclature of medicine clinical terms to represent computed to mography procedures[J]. Computer methods and programs in biomedicine, 2011, 101(3): 324-329.
[4] KATE R J. Normalizing clinical terms using learned edit distance patterns[J]. Journal of the American Medical Informatics Association, 2015, 23(2):380-386.
[5] LEAMAN R,ISLAMAJ DO?AN R, LU Z. DNORM: disease name normalization with pairwise learning to rank[J]. Bioinformatics, 2013, 29(22): 2909-2917.
[6] LI H,CHEN Q,TANG B,et al. CNN-based ranking for biomedical entity normalization[J]. BMC bioinformatics,2017,18(11): 385-392.
[7] DO?AN R I, LEAMAN R, LU Z. NCBI disease corpus: a resource for disease name recognition and concept normalization[J]. Journal of biomedical informatics, 2014(47): 1-10.
[8] 趙亞輝. 臨床醫療實體鏈接方法研究[D].? 哈爾濱:哈爾濱工業大學,2017.
[9] VARIOR R R,SHUAI B,LU J, et al. A siamese long short-term memory architecture for human re-identification[C]. European Conference on Computer Vision. Springer, Cham, 2016: 135-153.
[10] MUELLER J,THYAGARAJAN A. Siamese recurrent architectures for learning sentence similarity[C]. AAAI,2016:2786-2792.
[11] NECULOIU P,VERSTEEGH M,ROTARU M. Learning text similarity with Siamese recurrent networks[C]. Proceedings of the 1st Workshop on Representation Learning for NLP,2016: 148-157.
[12] 龐亮,蘭艷艷,徐君,等. 深度文本匹配綜述[J]. 計算機學報, 2017,40(4): 985-1003.
[13] 吳漢釗. 基于孿生卷積神經網絡的人臉追蹤[J]. 計算機工程與應用,2018,54(14):175-179.
[14] LI S, ZHAO Z, HU R, et al. Analogical reasoning on Chinese morphological and semantic relations[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2018(2): 138-143
[15] GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J].? Neural Networks, 2005, 18(5-6): 602-610.
[16] GU J, WANG Z, KUEN J, et al. Recent advances in convolutional neural networks[J].? Pattern Recognition, 2018(77): 354-377.
[17] KINGMA D P, BA J. Adam: a method for stochastic optimization[C].? San Diego:the 3rd International Conference for learning Representations,2015.
[18] 劉愛民. 手術、操作分類與代碼應用指導手冊2017臨床修訂版[M]. 北京: 中國協和醫科大學出版社, 2017:1-2.
[19] RUSSAKOVSKY O, DENG J, SU H, et al. Imagenet large scale visual recognition challenge[J].? International Journal of Computer Vision, 2015, 115(3): 211-252.
[20] 劉震,陳晶,鄭建賓,等. 中文短文本聚合模型研究[J].? 軟件學報,2017,28(10): 2674-2692.
(責任編輯:杜能鋼)
猜你喜歡
電子技術與軟件工程(2017年1期)2017-03-06 23:54:05
法制博覽(2016年12期)2016-12-28 13:05:51
電子技術與軟件工程(2016年18期)2016-11-14 01:24:53
電腦知識與技術(2016年12期)2016-06-14 01:52:51
中國當代醫藥(2015年4期)2015-08-03 18:28:34
軟件導刊(2015年6期)2015-06-24 12:58:39
