一種改進的ELK日志采集與分析系統
2019-10-15 02:21:53鮮征征葉嘉祥
軟件導刊 2019年8期
鮮征征 葉嘉祥
摘 要:ELK架構是解決日志分布式采集與分析問題中具有代表性的解決方案。但原生ELK架構存在Logstash對CPU資源占用較大、無法動態更新日志相關配置和日志數據傳輸過程中數據易丟失等問題。為滿足現實中大型分布式服務的日志采集與分析需求,對原生ELK架構作如下改進:在收集過程中增加限速器以減少CPU占用率;增加分布式注冊中心實現相關配置動態更新;增加消息隊列使得消息傳輸過程更健全。實驗結果表明,改進后的ELK日志采集及分析系統與原生ELK相比,CPU占用率減少了近60%,日志速度提高了3倍,且消息丟失率為零。
關鍵詞:日志采集;分布式架構;ELK;消息隊列
DOI:10. 11907/rjdk. 191790 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP319文獻標識碼:A 文章編號:1672-7800(2019)008-0105-06
An Improved ELK Log Collection and Analysis System
XIAN Zheng-zheng,YE Jia-xiang
(Department of Internet Finance and Information Engineering, Guang Dong University of Finance, Guangzhou 510521,China)
Abstract:ELK architecture is a representative solution to the problem of distributed log collection and analysis. However, the native ELK architecture has problems such as Logstash consuming large CPU resources, unable to dynamically update log related configuration, and has data loss during log data transmission. In order to satisfy the needs of log collection and analysis of large distributed services in reality, the paper improves the native ELK architecture as follows: speed limiter is added to reduce CPU occupancy in the collection process; distributed registry is added to update the configuration dynamically; and message queue is added to make the message transmission process more sounder. The experimental results show that compared with the original ELK, the CPU occupancy of the improved ELK log acquisition and analysis system is reduced by nearly 60%, the log speed is increased by three times, and the excellent effect of zero message loss rate is achieved.
Key Words: log collection;distributed architecture;ELK;message queue
基金項目:廣東省自然科學基金項目(2017A030313391);廣東省科技廳國際合作項目(2017A050501042)
作者簡介:鮮征征(1977-),女,博士,廣東金融學院互聯網金融與信息工程學院講師,研究方向為數據挖掘、隱私保護、機器學習、軟件開發與測試;葉嘉祥(1996-),男,廣東金融學院互聯網金融與信息工程學院學生,研究方向為服務端開發。
0 引言
如今,互聯網在人們日常生活中扮演著不可替代的角色,當用戶在訪問、瀏覽或點擊電子商務、社交娛樂、金融保險等網站時,都會產生相應的日志數據。這些日志數據是軟件系統、硬件設備和用戶行為的記錄工具,旨在及時發現用戶異常行為和軟硬件故障,以確保網站穩定、安全運行,從而提升網站服務質量[1]。對于海量小文件存儲隨服務訪問量上升的情況,大型網站通常在系統部署策略上采用分布式架構,但這會導致所產生的日志也分散在各臺服務器中,而傳統對多臺服務器進行單機日志檢索的方法效率低下。由此,基于分布式架構的日志采集與分析系統應運而生,各大互聯網公司紛紛提出各種各樣的日志監控平臺方案。目前主流的監控平臺有:基于傳統 Web 框架的監控平臺,基于數據索引的監控平臺和基于大數據處理框架的監控平臺。其中,集Elasticsearch、Logstash和Kibana為一體的基于數據索引的ELK[2]開源框架,是實現企業通用輕量級大型日志監控平臺的常用技術。ELK的分布式日志采集與分析系統可根據不同場景,結合不同的工具或中間件,靈活簡單地處理復雜日志問題,在分布式日志收集與分析領域得到了廣泛研究和應用。
關于日志采集與分析技術,目前已取得一定研究成果。郝璇[3]基于Apache Flume設計并實現了一個適用于異構網站平臺間的分布式日志收集系統,該系統雖然可以將多個網站的日志集中存儲,但缺少過濾和分析功能;廖湘科等[4]從日志特征分析、基于日志的故障診斷和日志增強3個方面分析了日志研究現狀,然后通過對幾種常用大規模開源軟件的日志進行調研,發現一些日志相關的特征和規律以及現有工具難以解決的問題;李祥池[5]針對ELK在日志傳輸過程中可能丟失的情況,進行消息隊列優化,利用Redis、Kafka、Rockmq等消息隊列作為日志傳輸通道,達到了防止數據丟失、減緩服務器壓力的效果;陳波[6]等針對ELK的ElasticSearch離線存儲功能的性能瓶頸,進行存儲功能拓展,利用大數據工具如HBASE等分布式存儲系統提升日志的存儲能力;張彩云等[7]通過對ELK、Redis 進行整合,結合全國綜合氣象信息共享系統內蒙古氣象局實際場景設計了ELK 日志分析平臺;姚攀等[8]針對ELK的Logstash對CPU有較大壓力等問題,提出解析日志的規則和技巧,通過對Logstash作進一步優化,搭建能夠對海量日志進行實時采集和檢索的分析監控系統;湯網祥等[9]針對系統大規模部署下日志采集配置復雜、難以集中控制等問題,提出對各類源日志進行整合,并通過本地采集、網絡匯集、集中管控、異步分級處理等方式加以實現;王參參等[10]根據銀行業務發展需求,提出將全網范圍日志分析系統由總行的一級中心平臺和地級市的二級分行數據采集點組成,用以解決因日志規模過大造成的省級系統資源過載和網絡堵塞等問題,但由于日志源眾多,日志類型繁雜且未對收集的日志進行過濾,最終對業務系統運行帶來一定影響;羅學貫[11]通過與互聯網行業流行的配置管理數據庫及監控系統進行關聯,設計并實現了以ELK為基礎的日志分析系統,利用logstash 豐富的插件解決日志分析和處理難題,形成實際工作中豐富的日志字段,為重點日志增加了標識字段,為日志分析和故障診斷提供了便捷手段;袁華[12]提出ELK與大數據處理數據技術Spark相結合,用一種隨機 key 后綴方式優化 Spark 集群性能,從而提高集群計算效率;嚴嘉維等[13]為提高可信計算平臺日志數據分析效率,提出了一種基于Hadoop的可信計算平臺日志分析模型,將實時日志與規則庫匹配,實現對用戶異常行為的檢測,日志分析結果為主動防御提供了決策支持;王夢蕾[14]從網絡安全角度設計與實現了一個基于 Spark Streaming 的實時日志分析與信息管理系統,在發生 DDoS 攻擊時及時給予用戶警告;孫魯森[15]研究并使用Flume集群將Web應用集群所產生的日志進行匯總,搭建Hadoop集群并使用其內部組件HDFS來持久化Flume集群所匯總的日志數據,可以對網站的多維度Page View、訪客來源統計、用戶關鍵路徑轉化進行多維度且詳細的數據分析。但該研究與文獻[13]都是基于Flume平臺,Flume自身比較繁瑣,與ELK相比,它主要側重于數據傳輸而非采集。隨著容器虛擬化技術的進步與推廣,主流的服務部署均掛載在宿主機的虛擬容器里,如Docker[16],但是容器會根據不同的策略分布與漂移,這樣會導致日志過于分散。因此,基于如Kubernetes[17]容器編排管理的大型日志收集系統相關研究受到關注。
針對現實中的復雜場景,以上方法都未從原生ELK架構自身缺點出發,原生ELK架構存在服務器處理效率低下、Logstash對CPU資源占用過多、可擴展性差、無法動態更新日志相關配置和日志數據傳輸過程中數據易丟失等問題。本文通過使用Etcd搭建配置中心集群,使用Gin框架與Nginx實現日志產生器,模擬分布式系統下產生日志,使用Vue.js搭建前端,提出對收集模塊和轉發模塊的改進方案,即實時收集產生的日志,同時能限制日志收集頻率,從而替代ELK框架中的Logstash,達到減少CPU壓力的目的;還使用Kafka與Zookeeper搭建一個消息隊列集群,將收集到的日志發送至消息隊列中,達到削峰、保證消息健全的作用,并用go語言實現轉發模塊,從消息隊列中拉取日志;最后使用Elasticsearch與Kibana構建日志存儲與展示模塊,向用戶提供強大的日志搜索與分析功能。本文基于ELK、Kafka與Etcd等技術,通過對ELK的改進,彌補了原生ELK在大型分布式業務系統中不能直接使用的缺陷,設計并實現了一個日志健全、配置便捷、性能更高效的分布式日志采集與分析系統。
1 系統設計
1.1 系統業務架構設計
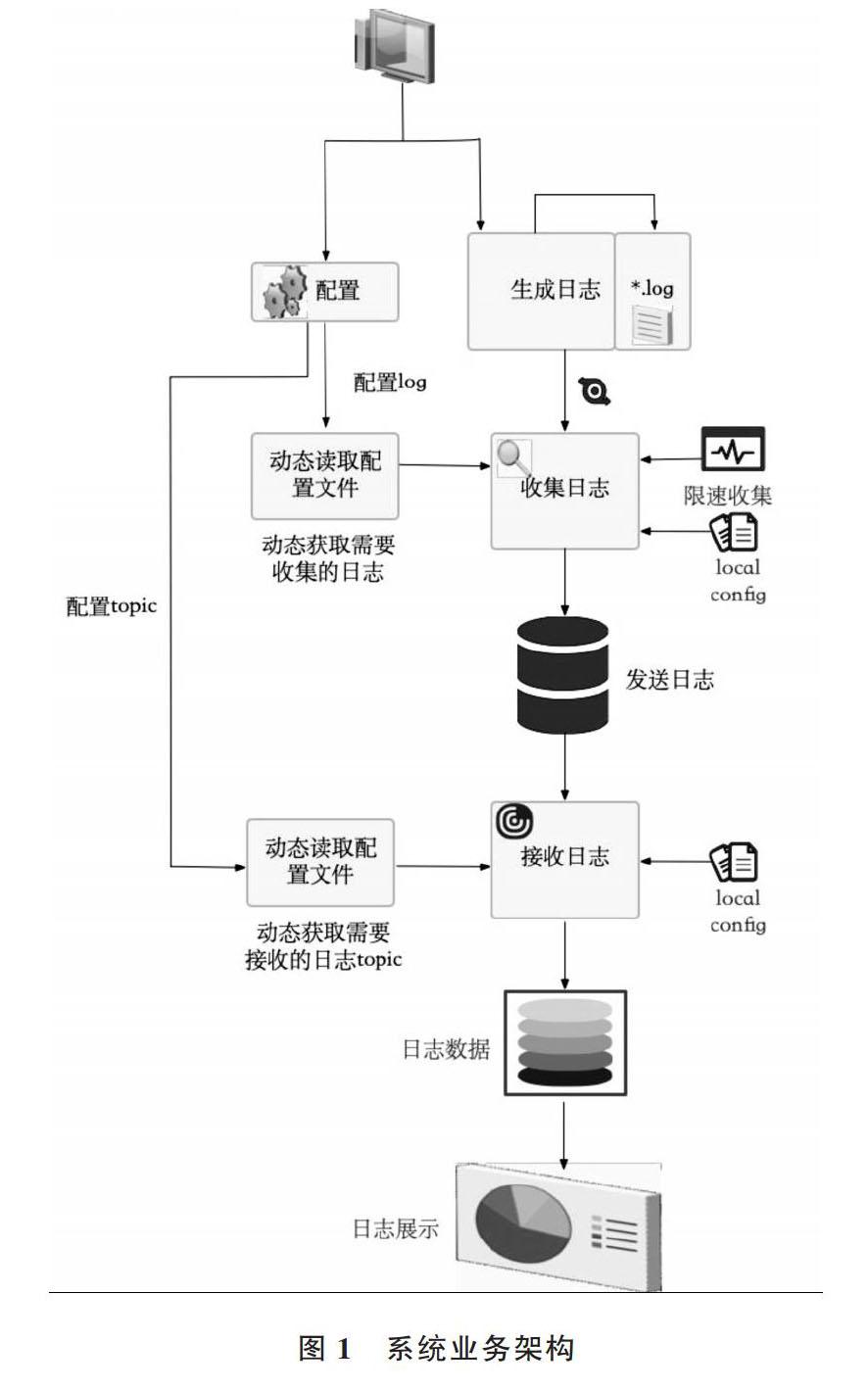
系統分為四大模塊,分別是系統入口模塊、日志收集模塊、日志轉發模塊和日志展示模塊,如圖1所示。
圖1 系統業務架構
圖1中,其核心關注點在于日志收集模塊和日志轉發模塊的消息健全、高性能以及高可用設計。系統入口模塊直接對終端設備提供服務,同時入口模塊通過調用http服務生成日志、配置文件等;日志收集模塊主要是獲取配置中心上的路徑配置,對特定日志進行收集,并發送到消息隊列中;日志轉發模塊主要是獲取配置中心上的主題配置,對特定主題的日志進行過濾接收,并發送至ElasticSearch;日志展示模塊主要對日志進行搜索、分析和展示。
1.2 系統執行時序分析
系統業務在執行過程中是按照一定的時序進行,圖2展示了本系統的業務執行時序。
圖2 系統執行時序圖
圖2中,Logweb服務是系統入口模塊,產生日志;Logagent是日志收集模塊,對產生的日志進行收集,并將消息推送到kafka消息隊列;Logtransfer是日志轉發模塊,將從Kafka拉取的日志消息推送到ElasticSearch,并且通過Kibana進行日志分析與展示。
1.3 系統物理架構設計
原生的ELK架構中沒有嵌入消息中間件、配置中心等內容,因此,只適合日志量較少、業務簡單的系統。隨著業務逐漸復雜,ELK原生架構已不能支撐龐大復雜的日志信息。因此,需要設計一個適合分布式系統的日志采集與分析系統,并考慮消息隊列集群及應用集群。本系統針對此種場景,從分布式系統、高可用集群方面入手,對原生ELK架構進行改進。系統物理架構如圖3所示。
圖3 系統物理架構
圖3中,Web端的http請求首先會經過Nginx負載均衡,轉發到服務器集群中1~3號服務器中的任意一臺;服務器集群中的日志收集器,會通過Etcd集群中的配置路徑,進行日志收集,然后將日志推送到Kafka集群;而Kafka集群之間的聯系是靠Zookeeper集群進行服務注冊與發現;日志轉發器通過Etcd集群中的主題配置,從Kafka集群中選擇相關主題的日志,拉取到服務器集群中;最后日志將發送至ElasticSearch,通過Kibana連接ElasticSearch獲取日志,進行日志展示與分析。
其中,日志消息隊列Kafka的高可用與消息健全性尤為重要,其集群架構如圖4所示。
圖4 消息隊列集群架構
圖4中,product是生產者,它從Zookeeper注冊中心獲取到Kafka集群的地址,然后將產生的消息發送至Kafka集群,而Kafka集群事先需要將自己本身的地址注冊到Zookeeper集群,并且保持心跳檢測,才能被生產者、消費者發現;consumer是消費者,同理,它也從Zookeeper注冊中心獲取到Kafka集群的地址,然后去Kafka集群拉取消息。本系統的生產者指日志收集器,它將收集的日志發送至Kafka中,消費者是指日志轉發器,將日志從Kafka中拉取下來。
2 系統功能模塊
2.1 系統入口模塊
系統入口模塊主要作用是配置收集規則、產生日志,用Nginx與Gin框架搭建,對外開放http接口,網頁端可以通過調用相關接口,完成該功能。Nginx在本系統中的作用是作為業務應用服務器集群的負載均衡器,應用服務器集群架構如圖5所示。圖5中,所有服務器都處理相同業務,所有請求經Nginx轉發到不同的服務器中。如果集群中的一個服務器發生故障,則Nginx能夠迅速將該系統的任務轉發到集群中其它正常工作的服務器上進行處理。業務具體處理則是用Gin框架支撐,大致分為兩個步驟:①配置收集規則、收集路徑等,主要完成對日志文件位置、日志主題過濾等功能模塊配置;②模擬生產環境下的日志產生過程。
圖5 應用服務器集群架構
2.2 日志收集模塊
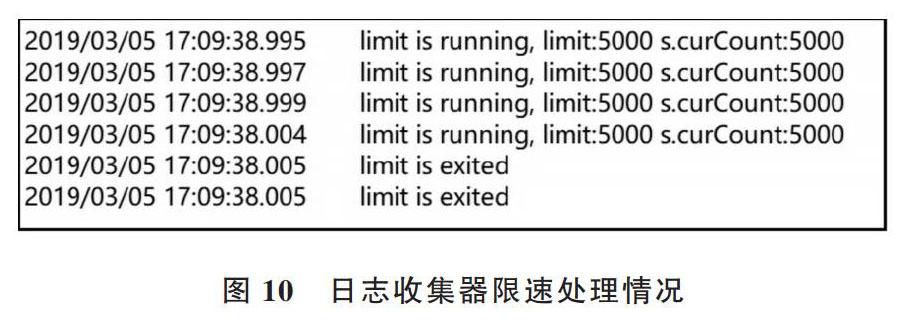
該模塊中日志收集器根據規則收集日志,并將日志發送到消息隊列中,包括收集器、限速器和推送子模塊。收集器和限速器主要根據配置規則收集相關日志,并配置特定的發送頻率,達到限速目的,其UML設計如圖6所示。
圖6 收集器與限速UMl設計
圖6中,日志收集器模塊分別由TailManager類(用作管理收集日志)、CollectObj類(實現日志收集器)、LogConfig類(實現日志配置)、Limit類(解決日志限速)4個類構成。
推送子模塊負責將收集的日志推送到kafka消息隊列中,其UML圖設計如圖7所示。該模塊功能實現包括Message和Sender兩個類。前者定義日志消息,后者解決日志消息推送。
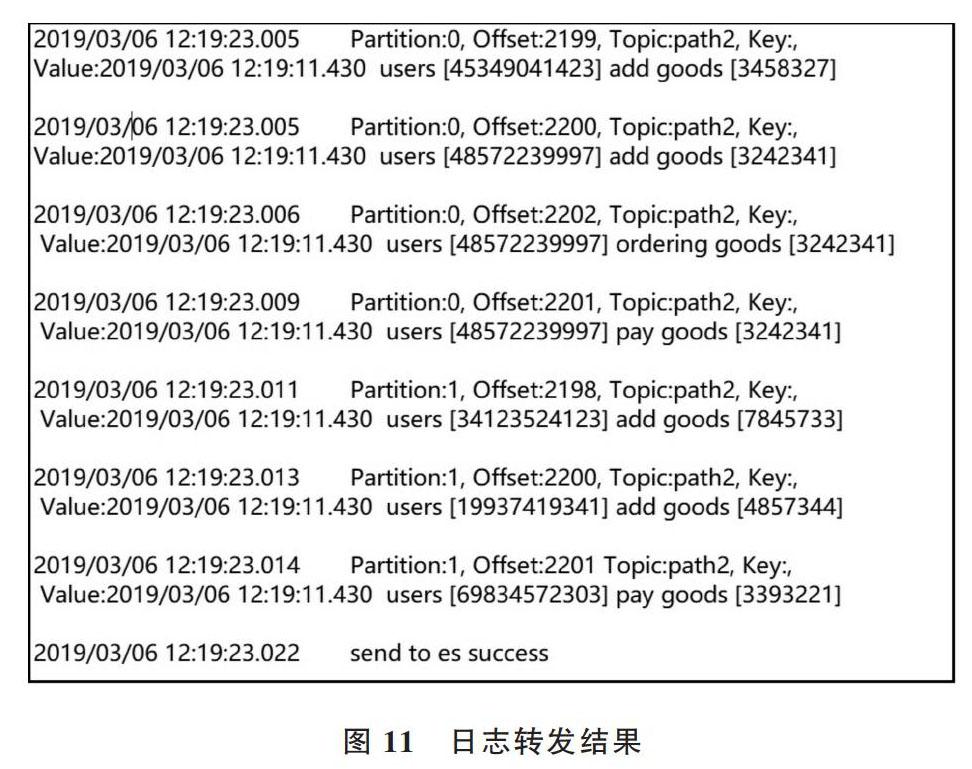
圖11 日志轉發結果
4.2.4 日志搜索和分析
當日志成功收集后,需對這些日志數據進行搜索和分析,其結果如圖12所示。柱狀圖表示每秒鐘收集到的日志,其下是按時間先后順序排列的日志數據,默認情況下是全量顯示,若需要搜索特定規則的日志,可以通過搜索欄進行搜索匹配。
圖12 日志展示效果
通過上述實驗,系統可以完成收集、轉發和展示分析等功能,體現了其強大的分布式日志采集與分析能力。
4.3 對比實驗
在同樣的實驗環境下,針對同一實驗對象,將改進后的系統與原生ELK在性能方面作對比實驗。
較原生ELK而言,改進后的系統優勢主要體現在日志收集時多項性能的提升。具體壓測方案設計如下:
(1)壓測環境:Core i5-4200H處理器,8G內存,1T硬盤。
(2)Logstash / Logagent 讀取 500 000條日志,單行數據 500B。
(3)壓測實驗一:正常收集日志數據,統計CPU平均占用率、總耗時和收集速度,結果如表1所示。
(4)壓測實驗二:在收集日志數據時,人工對網絡進行實驗性阻斷,產生網絡抖動,統計消息丟失數和丟失率,結果如表2所示。
表1 壓測實驗一結果
表2 壓測實驗二結果
從表1可看出,原生ELK系統中Logstash CPU占用率高達75.6%,而改進后的收集器 CPU占用率降低到44.8%,且收集速度為原生ELK的3倍。從實驗結果來看,改進后的系統解決了原生ELK中Logstash對CPU資源消耗問題,且提升了日志收集速度與系統的穩定性。
從表2可以看出,在產生網絡抖動時,原生ELK系統會丟失一些數據,500 000條消息丟失了698條,消息丟失率達0.14%,改進后的日志收集系統,500 000條消息丟失0條,消息丟失率為0。從實驗結果來看,改進后的系統解決了原生系統日志消息容易丟失的問題,顯著提高了日志收集過程中消息的健全性。
5 結語
隨著云計算、物聯網技術的迅速發展,數據已呈爆炸式增長,人們進入大數據時代[19]。而對于Web日志數據量的增加,文件的分布式存儲和數據挖掘技術也成為Web日志挖掘研究領域的重點分支[20]。因此,日志的采集和分析將是其研究的重要支撐。
本文系統主要著眼于日志系統的簡易實用性、高可用性與日志的健全性。簡易實用性的實現途徑主要是:可配置的Web管理后臺、簡易操作的搜索與分析Web頁面等;高可用性的實現途徑主要是:分布式、集群、負載均衡、限流等;日志的健全性實現途徑主要是:消息隊列、注冊中心等。
下一步工作將關注兩個問題:一是將日志收集與分析系統整合到Docker容器,并且用Kubernetes進行管理編排,這樣能極大方便開發者和運維者,后續迭代開發也具有敏捷性;二是改進現有系統,增加分布式鏈路追蹤系統,以獲得服務之間調用的耗時、吞吐量、是否故障等信息,從而為運維和監控提供更好的參考。
參考文獻:
[1]? 應毅,任凱,劉亞軍.? 基于大數據的網絡日志分析技術[J]. 計算機科學, 2018, 45(11A): 353-355.
[2]? 高凱. 大數據搜索與日志挖掘及可視化方案—ELK Stack:Elasticsearch、Logstash、Kibana[M]. 第2版. 北京:清華大學出版社,2016.
[3]? 郝璇. 基于Apache Flume的分布式日志收集系統設計與實現[J].? 軟件導刊,2014,13(7):110-111.
[4]? 廖湘科,李姍姍,董威,等. 大規模軟件系統日志研究綜述[J]. 軟件學報,2016,27(8):1934-1947.
[5]? 李祥池. 基于ELK和Spark Streaming的日志分析系統設計與實現[J]. 電子科學技術,2015,6(2) 674-678.
[6]? 陳波. 基于 HBASE 分布式存儲的通用海量日志系統設計方法研究[J]. 信息通信, 2017(6): 7-9.
[7]? 張彩云,牛永紅,趙迦琪.? ELK日志分析平臺在系統運維中的應用[J]. 電子技術與軟件工程,2017(6): 182-183.
[8]? 姚攀,馬玉鵬,徐春香,等. 基于ELK的日志分析系統研究及應用 [J].? 計算機工程與設計, 2018, 39(7):2090-2095.
[9]? 湯網祥,王金華,赫凌俊,等.? 大規模軟件系統日志匯集服務平臺設計與實現 [J]. 計算機工程與設計, 2018, 35(11):173-178.
[10] 王參參,姜青云,李彤.? 基于大數據的日志分析平臺在銀行中的研究與實現 [J].? 網絡安全技術與應用, 2018(5): 68-70.
[11] 羅學貫.? 基于ELK的Web日志分析系統的設計與實現[D]. 廣州: 華南理工大學, 2018.
[12] 袁華.? 基于ELK和Spark的日志分析系統的研究與實現[D]. 南昌: 南昌大學, 2018.
[13] 嚴嘉維, 張琛. 基于Hadoop的可信計算平臺日志分析模型[J].? 軟件導刊,2018,7(8): 71-75.
[14] 王夢蕾. 基于Spark Streaming的實時日志分析與信息管理系統的設計與實現[D].? 哈爾濱: 哈爾濱工業大學, 2018.
[15] 孫魯森.? 基于分布式Web應用的大數據日志分析方法研究 [J].? 電腦知識與技術, 2019, 15(3): 16-19.
[16] BOETTIGER C. An introduction to docker for reproducible research [J].? ACM SIGOPS Operating Systems Review-Special Issue on Repeatability and Sharing of Experimental Artifacts,2015,49(1):71-79.
[17] BERNSTEIN D.Containers and cloud: from LXC to docker to kubernetes[J].? IEEE Cloud Computing, 2014, 1(3): 81-84.
[18] DIEGO ONGARO, JOHN OUSTERHOUT. In search of an understandable consensus algorithm[C]. In Proc ATC14, USENIX Annual Technical Conference,2014.
[19] 孟小峰,慈祥.? 大數據管理:概念·技術與挑戰 [J].? 計算機研究與發展, 2013,50(1): 146-169.
[20] 班秋成. 基于Hadoop的Web日志存儲和分析系統的研究與實現[D]. 北京: 北京郵電大學, 2018.
(責任編輯:孫 娟)
