面向消化內科輔助診療的生成式對話系統①
2019-10-18 06:40:48程夢卓董蘭芳
計算機系統應用 2019年10期
關鍵詞:模型
程夢卓,董蘭芳
(中國科學技術大學 計算機科學與技術學院,合肥 230022)
社會的高速發展,帶來群眾各方面壓力的日益增加,工作強度越來越大,飲食不規律,不健康,欠缺睡眠,加上現在食品的安全性依然存在著很大的隱患,導致身患消化內科疾病的人群日益增多.有調查顯示接近80%的人在有醫藥和疾病的疑問時,首先會選擇上網尋找幫助,但是傳統的搜索引擎在提供相關信息時,大多采用關鍵詞匹配技術,在過去網絡中已錄入的信息進行匹配,具備諸多限制,類似于“過去幾周”的關鍵詞會被忽略,并且由于用戶的語言表達差異和網絡信息的混亂,網絡存在的知識庫并不能涵蓋用戶重要的意圖,無法滿足實際的應用需求.
消化內科對話系統的研究需要大量數據,而現有的醫學公開數據集多為影像數據集,沒有問診類的公開數據集.其次,同醫學自然語言理解處理研究的大部分挖掘研究類似,第一步都需要對數據進行分詞,但是因為消化內科疾病的種類繁多,還有很多新的疾病不斷被發現,所涉及疾病名、癥狀表現名和藥名很多,中科院的漢語分詞系統NLPIR、中文結巴分詞等常用的分詞工具在處理該領域分詞的結果并不能給生成式對話系統構建提供保障.國內中文醫學術語的標準化的研究也比較少,而國外如比較具備代表性如UMLS[1]等也缺乏對中文的支持.
本文在谷歌傳統 seq2seq 框架的基礎上,運用 butterfly爬蟲技術和主動學習結合獲取相關網站消化內科約48萬條問診語料,解決醫療問診語料缺少問題.在醫學院消化科同學的幫助下,結合醫藥庫的消化科常用藥名和常見病癥,通過統計分析構建約20萬消化科領域詞匯表,運用基于詞庫與最大規則相結合的分詞算法,對問診語料對進行分詞處理.結合Word2Vec構建自主的詞向量,并提出模型增強訓練法獲得消化科生成式問診對話模型.
1 處理流程
消化內科生成式問診系統的實現過程主要涉及3個模塊,語料獲取與處理、詞向量構建、對話模型,整體的框架如圖1所示.

圖1 系統模塊圖
1.1 語料獲取與預處理
1.1.1 構建詞庫
因為消化科文本的特殊性,包括方位詞、副詞以及大量的專業詞匯和否定詞匯,直接利用結巴分詞類通用分詞工具進行分詞,結果顯示,這些詞當中大部分無法被識別,分詞效果極差.但對話模型的訓練過程涉及詞之間相關性的建立過程,且鍵值對向量的處理對分詞的準確率有一定的要求,為了提高分詞的結果準確率,本文構建自定義消化內科分詞詞庫,其主要由兩大部分組成:消化專業詞庫和停用詞詞庫.
消化內科專業詞庫主要來源于以下幾部分:從現存醫學網站爬取獲得的消化科常見疾病和癥狀表現名稱,包括有問必答網、尋醫問藥網;百度文庫提供的消化科藥品字典;以及醫學院同學對字典的補充.詞庫內部結構如“胰腺炎 nz 260”,其中“胰腺炎”為消化科專業詞匯,nz代表其他專有名詞,260代表詞頻.
停用詞庫包含在問診語料之中具有高頻率但實際意義不大的詞,如:“的”、“請”,包含介詞、副詞、語氣詞等.
1.1.2 數據預處理
在問答對進行分詞操作之前,都會先進行文本的預處理.第一,根據自定義的停用詞庫,去除文本中“的”、“①”等停用詞;第二,由于網絡獲取的問答對經常會出現多個標點的情況,如“?????”,去掉重復;第三,很多藥名有簡稱或者別名,本文為了降低復雜性,將有別名的藥統一為同一藥名,如“奧美拉唑腸溶片”統一為“蘭尼”.
1.1.3 分詞
現存的分詞大致有3大類:基于理解的分詞方法、基于規則的分詞方法和基于統計的分詞方法[2].由于本文詞典的構建花費時間比較多,相對比較完整,因此在基于最大逆向匹配算法的結巴分詞算法的基礎上,采用改進規則和統計相結合的方式行進行分詞的改進.
文獻[3]提出歧義檢測,在對句子進行正向和逆向切分得到的兩個結果的比較過程中,發現兩種方式切分的結果有90%的概率重合且正確,有約9%的概率其中必有一個結果是正確的.因此,本文在此基礎上,在進行問答對分詞的時候增加比較機制,同時對句子進行正向和逆向最大匹配切分,然后將兩個結果進行比較,若前后分詞所產生詞的個數有差異,則選擇其中單字少的分詞作為結果,若所得分詞數相同,則隨機選擇一個作為結果.
1.1.4 分類
消化內科一般分為“胃腸病”、“肝病”、“胰膽疾病”、“內鏡”和其他疾病五大類,對話模型的訓練過程中,為了避免過擬合,需要五大類的語料數據均衡.由于每條問答對可以具備多種疾病的癥狀表現,且不受其他類影響,并且一個類的疾病具備常見的術語,如“胃腸病”常出現“胃炎”類關鍵詞,因此本文將多標簽分類問題轉化成單標簽分類問題進行求解.
分類模型的訓練的過程結合主動學習[4],先準備兩萬條問答對,人工先對其中6000條數據進行分類處理,完成類別標注,然后將這些數據用Word2Vec向量表示,作為支持向量機的輸入獲得簡單的分類模型,然后每次由分類模型處理2000條新數據,根據結果評測分類器的好壞,并且每次將標記好的數據加入訓練集,重新獲得新的分類器,直至分類模型達到給定的閾值,過程如圖2所示.

圖2 獲取語料流程
得到滿足的要求模型后,通過該模型本文從有問必答網、尋醫問藥網共獲取約48萬條消化科問答對.
1.2 詞向量構建
詞向量又稱Word嵌入式自然語言理解中的一組語言建模和特征學習技術的統稱,是讓計算機理解自然語言手段之一,很多研究都表明當將其用作底層輸入表示時,可以很大程度的提高NLP任務的性能,如語法分析和情感分析.
為了在有限的數據集下能獲得較好的詞與詞之間的相關性,本文使用兩種詞向量:鍵值對向量和Word2Vec向量.
1.2.1 鍵值對向量
分詞之后獲得初始語料,對分詞之后的語料中詞語的出現頻次進行統計,從高到底進行排序,形成形同“123-膽囊炎”的鍵值對,通過實驗比較排序字典大小的影響,得到相對于合理的是統計前20 000個高頻詞,也就是在問答對里各抽出前20 000個高頻詞,形成鍵值對序號,高頻詞的選擇之后會經過比對,如果自定義詞典有詞未出現在這20 000個詞內,問答對同時增加未出現的詞,因此序號的取值范圍會多個“+”.
1.2.2 Word2Vec向量
Word2Vec[5,6]包括兩種模型:CBOW和Skip-Gram.CBOW模型的訓練輸入是某一個特征詞的上下文相關的詞對應的詞向量,輸出的是這特定的一個詞的向量.Skip-Gram與CBOW剛好相反,是在已知當前詞的情況下預測上下文.兩者均可以和哈夫曼樹結合訓練得到最終的詞向量,但考慮到時間序列GRU[7],是根據句子前面的詞預測后面的詞,課題選擇基于Hierarchical Softmax 哈夫曼樹的 Skip-Gram 模型獲取本文的 Word2Vec向量.
1.3 對話模型
生成話對話這個場景,與機器翻譯有很多相似之處,都可以可以簡單理解為建立原句和翻譯結果兩者相同位置的詞的相關性,都是根據當前詞推算下一個詞,現在的研究部分是在不改變主模型的基礎上,在傳統的Sutskever等[8]提出seq2seq框架上改變編解碼結構、神經元等,如加入注意力機制[9],有的已達到比較好的效果.由于對話場景的特殊性,一個極有潛力的改變辦法是長短期記憶網絡LSTM[10](包含其各種變體)結合seq2seq框架,加入注意力機制,理由在于LSTM能夠避免長期的依賴問題,適合于解決包含時序先后順序的序列生成的問題,如阿里小蜜[11]和百度自我診斷[12].當本文直接使用基本模型seq2seq模型時,所得結果很不好,生成詞的困惑度高,整個句子的結構不全,可讀性很差.為了得到更好的結果,本文對模型進行篩選,在公開數據集WSJ第23部分同等前提下,加州伯克利分校NLP實驗室開發的BerkeleyParser開源句法分析器在測試集上F1的分數達到了90.5,Google提出的句法成分分析所采取的結構[13]F1分數達到了95.7.而GRU與LSTM相比,只有兩個門(更新門和重置門),參數少更容易收斂,本文的實驗對比也表明GRU比LSTM更適用于對話處理場景.因此本文最終選擇multi_encoder+attention_decoder+GRU+beamsearch模型結構,網絡結構如圖3所示.

圖3 對話模型網絡結構圖
給定輸入為 (x1,···,xT),文獻[14]表明采取倒序輸入能夠增加輸入詞之間的相關性,因此本文也采取倒序原句作為輸入.
用xt,ht,h?t分別代表t時刻的輸入、輸出狀態、隱藏狀態,GRU結構如圖4所示.

圖4 GRU結構圖
第一層得到中間狀態 (h1,h2,···,ht)和的計算如下:

其中,[]表示兩個向量相連接,*表示矩陣的相乘,·表示矩陣的點乘,Wz,Wr,Wh?是模型需要學習的模型參數.rt重置門決定是否將之前的狀態忘記,當其值趨近0的時候,前一個時候的狀態信息ht?1會被忘掉,隱藏狀態h?t會被重置成當前輸入信息,更新門zt決定是否將隱藏狀態更新為新的狀態ht.
在一個深層的GRU,每層將上一層的得到的ht作為該層的輸入序列X,定義輸出的分布為:

輸入序列X=A1,···,ATA,B1,···,BTB,A1,···,ATA代表上一層的輸出ht,(B1,···,Bt?1)代表t-1時刻前面t-1神經元的輸出,Wo為權重參數,δBt為克羅內克函數.
直接使用該方法去處理醫療問答會出現一些問題,其一在于問句對疾病的描述語句可能會很長,解碼階段GRU無法很好的針對序列前面部分進行解碼,其二在于沒有關鍵點,解碼階段應該更關注于疾病癥狀詞,而直接單純的使用同一個中間向量進行解碼,顯然是不合理.因此,本文加入注意力機制,來源于文獻[10],也就是圖3中最上方的黑線曲線,使得每一步解碼都有不同的中間向量c.中間狀態表示為 (h,···,h,()(1TA)Decoder中間狀態用d1,···,dTB:=hTA+1,···,hTA+TB定義,計算過程:

其中,t指的是t時刻,i∈[1,TA],ν和矩陣W1′,W2′是模型需要學習的參數,由于前面說過編解碼都使用相同規格GRU,因此W1′,W2′的維度一樣.uti的長度與Encoder產生的TA具備相同長度,其中中i的值代表關注Encoder中hi的程度,使用Softmax進行規范化,最后通過將dt′,dt拼接得到新的中間狀態,作為解碼的中間向量c.
2 實驗分析
2.1 分詞實驗結果
從獲取的48萬對問答對中隨機抽取2000條問答對,進行人工分詞并統計作為標準.結果評估采用第二屆國際漢語分詞評測發布的國際中文分詞標準進行評測,計算方法:

其中,precision表示準確率,recall表示召回率,F值為正確率和召回率的調和平均值,CN表示正確切分詞數,CS表示切分的總詞數,TS表示答案中的詞語總數.
對這2000條問答對,使用3種方法進行分詞:直接使用結巴分詞、結巴結合清華醫學詞庫、結巴分詞+清華醫學庫+自定義詞典,以及結巴分詞+清華醫學庫+自定義詞典+歧義消除.分詞結果如表1所示,分詞樣例如表2所示.

表1 分詞評估結果(%)

表2 分詞樣例對比
通過表1結果不難看出,當直接使用結巴分詞進行消化內科語料的分詞操作時,準確率最低,為70.5%,可以從表2中發現此時分詞產生的結果中,“胃粘膜炎癥”、“胃炎膠囊”、“999胃泰顆粒”、“麗珠得樂”和“嗎丁啉”藥名和癥狀名出現錯分,且“腸胃病惡化”通過查詢中間結果發現,出現歧義,有多種切分結果:“腸胃/病/惡化”、“腸胃病/惡化”、“腸/胃/病/惡化”.增加清華醫學詞庫后,3個指標都得到提升,準確率達到73.8%,可以從樣例中發現,“胃黏膜炎癥”得到正確且切分,同時也發現,藥名仍然處于錯分狀態,且歧義沒有得到解決.進一步增加自定義詞典,由于本文的自定義詞典花費的時間和人力較大,包含絕大部分的消化內科常見疾病名稱和藥名,因此通過表1可以發現,實驗結果得到了很大提升,準確率達到96.6%,召回率達到96.4%,F值達到95.3%,從樣例中可以發現,“胃炎膠囊”、“999胃泰顆粒”、“麗珠得樂”和“嗎丁啉”都得到正確切分,但歧義仍然存在.
最后一步,歧義的消除,可以發現準確率有了進一步的提升,針對表2例子中“腸胃病惡化”,根據本文采取得取最大操作,直接被切分成一個詞,符合人工切分要求.
2.2 對話模型實驗
2.2.1 數據處理
獲取的48萬條問答對,長短不一,短的問句只有十幾個詞,長的超過60個詞,本文采取桶裝方式對數據進行分組,共分 (10,15)、(20,30)、(30,45)、(40,60)、(40+,60+)5個桶,(20,30)代表問句詞數在10~20之間,答句詞數在15~30之間,如果問句和答句的詞數分布在兩個桶內,以答句詞數為準,如“12,40”放至(30,45)桶內,(40+,60+)代表多問答句詞數超過40和60的放至該桶.將五組分開進行模型的訓練.2.2.2 模型訓練
本文提出一種加強訓練法,過程如下:
1)使用鍵值對向量進行預訓練,得到初始模型Model_1;
2)將鍵值對問句前后顛倒,加載Model_1進行訓練,得到Model_2;
3)在Model_2的基礎上,使用Word2vec向量進行訓練,得到Model_3;
4)將Word2vec向量表示的問句前后顛倒,加載Model_3,得到最終模型Model_4.2.2.3 評估方法
本文在48萬問答對隨機選擇1萬條問答對作為測試集,通過兩個方面進行對話模型質量評估:困惑度和詞向量匹配評價.
(1)困惑度是衡量一個語言模型好壞的指標,用來估算一句話是否通順,主要根據每個詞來估計一句話出現的概率,計算方法:
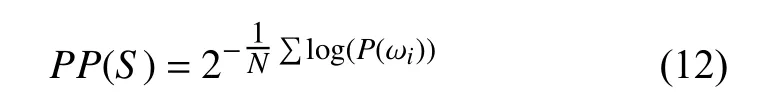
其中,S代表句子,N代表句子的長度,P(ωi)代表第i個詞的概率,困惑度越小,期望句子出現的概率也就越大.
(2)詞向量的評價方法是通過計算目標句子與生成句子之間句向量之間的余弦距離的大小來估算兩者的相似度,本文采取BLEU值進行評估,也就是比較兩者中的n-gram (實驗取值為3,也就是每次三詞一組進行比對)詞組在整個訓練語料中出現的總次數,出現的次數越高,則模型的效果越好.計算方法:

其中,Pn(r,r?)計算n-gram的短語詞組在整個數據集中的準確度,h(k,r)表示每個n-gram詞組在參考答案語句中出現的次數(因為對于每個n而言,都會存在多個n-gram詞組,因此有一個求和);ω表示各個ngram的權重;BP是長度過短懲罰因子,取值范圍(0,1],候選句子越短,越接近0,加入該因子的目的在于改善生成答案過短的效果.2.2.4 測試階段
在測試解碼階段,傳統的廣度優先策略雖然能夠找到最優的路徑,但是由于本文數據有限,困惑度會很大,因此搜索的空間會非常大,如果使用廣度優先策略會導致內存占用指數級增長,內存會溢出,因此采用Beamsearch算法[15]進行尋找最優解,該算法是一種啟發式圖搜索算法,一般當解空間特別大時會被使用到,該算法的優點在于能夠減少空間和時間的使用,在每一步路徑的選擇中,不同于傳統的廣度優先策略,會根據定義的策略對一些質量差的點進行去除操作,保留質量高點,最終找到最優的路徑.算法的流程如下:
1)初始化節點,將節點插入到列表中;
2)從列表中提取節點出堆,如果為目標節點,則結束,否則擴展該節點,并取集束的寬度的節點入堆,既取前k個概率最大的節點入堆,不斷循環,直至找到最優解或堆為空.每個t時刻有幾個大概率的詞候選,選擇可能性最大的前幾個候選,降低復雜度.
2.2.5 對話模型實驗結果
表3表明,在Encoder和Decoder層數都為3層,單元數都為256的條件下,GRU比LSTM所產生的困惑度降低約18,得出GRU更適用于對話系統模型;表格也顯示在使用GRU作為神經元的前提下,神經元數目超過256個,模型會出現不收斂和困惑度持續增加的情況;而在神經元為256個相同數目下,3層因為計算量少,比5層的效果好,困惑度降低21,因此最終本文選擇3層256個神經元進行最終的模型的實驗對比,結果如表4所示.

表3 模型層數選擇對比

表4 對話模型對比
表4表明層數都為3層,神經元都為256個,訓練次數都為2000 000的情況下,本文所使用的模型結構和訓練方法獲得最好的結果,困惑度只有3.55,且bleu值能提高到0.2675.
對于表5中的問句,模型最后獲得兩個句子:“你好,根據你的描述,你這種情況應該是有便秘的情況.建議口服,可以口服潤腸通便的藥物,如可以口服潤腸通便的藥物.”和“你好,根據你的描述,我們的需求,最終模型取第一個作為最終結果.

表5 對話模型問答樣例
我們咨詢了消化內科領域的專家,給出的回答考慮是胃腸脹氣的癥狀,建議您首先注意飲食,避免吃生冷辛辣刺激油膩的食物,可以適當口服嗎丁啉,再熱敷一下腹部,癥狀應該會有所改善”.概率分別為0.87和0.81,其實可以發現兩種答案都滿足為:“考慮胃腸功能紊亂的可能性較大,可以吃點促進胃腸蠕動藥物,比如多潘立酮片或者是枸櫞酸莫沙必利膠囊,適當運動,不要長時間久坐”.在語義方面和模型生成的是接近的,都是腸胃蠕功功能出現異常的回答,證明本文得出的模型能夠有效的回答.
3 結論與展望
通過實驗發現增加消化科比較充足的自定義詞典和增加前后選擇機制,分詞的準確率能夠達到97.3%,支持向量機和主動學習的結合能夠有效獲取均衡數據.本文使用的模型結構,與傳統主流的模型相比,困惑度和BLEU值都要好,且在鍵值對向量和Word2Vec向量兩者組合增加訓練法,對話系統的性能得到了進一步的提升.為了進一步提高實用性,接下來的研究工作,會研究消化科語料中的語義信息和數據特征,然后研究增強詞之間的相關性,以及尋找更好的模型結構和訓練方法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
