基于Kafka和Storm的車輛套牌實(shí)時(shí)分析存儲(chǔ)系統(tǒng)①
2019-10-18 06:40:52任培花
計(jì)算機(jī)系統(tǒng)應(yīng)用 2019年10期
任培花,蘇 銘
(山西大同大學(xué) 計(jì)算機(jī)與網(wǎng)絡(luò)工程學(xué)院,大同 037009)
“套牌車”是指未在交管部門(mén)辦理手續(xù),偽造、冒用他人合法車輛和行駛駕照的車輛[1].近年來(lái),隨著機(jī)動(dòng)車數(shù)量的增加,車輛套牌現(xiàn)象屢見(jiàn)不鮮,嚴(yán)重?fù)p害了交通參與者的合法權(quán)益,增加了交管部門(mén)的工作難度,甚至增添了社會(huì)不穩(wěn)定因素等.因此,套牌行為已成為當(dāng)前交通和治安管理中的一個(gè)難點(diǎn)問(wèn)題.
現(xiàn)今城市的各個(gè)重要路口,均有車輛監(jiān)控系統(tǒng)可以記錄車牌號(hào)碼、經(jīng)過(guò)地點(diǎn)、時(shí)間、現(xiàn)場(chǎng)圖片等.傳統(tǒng)的車輛套牌監(jiān)測(cè)大多基于車輛監(jiān)控系統(tǒng)的日志信息采用人工識(shí)別、牌照識(shí)別、或射頻識(shí)別等方法識(shí)別套牌車輛.然而伴隨車輛數(shù)量和出行量地持續(xù)增加,城市交通采集范圍在逐步擴(kuò)大,按現(xiàn)有監(jiān)控系統(tǒng),每天會(huì)產(chǎn)生以億為單位的日志記錄,不管用哪種監(jiān)測(cè)方法面對(duì)海量交通數(shù)據(jù)集,必然會(huì)有成本高、效率低、實(shí)時(shí)性差等問(wèn)題.因此,為了解決這些難題,國(guó)內(nèi)外很多人研究將大數(shù)據(jù)技術(shù)引入到車輛套牌稽查系統(tǒng)中,對(duì)這些數(shù)據(jù)進(jìn)行實(shí)時(shí)分析和存儲(chǔ).
1 相關(guān)研究
隨著并行計(jì)算框架的產(chǎn)生,關(guān)于車輛套牌的大數(shù)據(jù)研究正在興起,很多學(xué)者專家紛紛展開(kāi)相關(guān)研究.以“套牌”、“大數(shù)據(jù)”為檢索詞,從 2014-2019年期間,對(duì)中國(guó)知網(wǎng)、萬(wàn)方數(shù)據(jù)庫(kù)、維普網(wǎng)公開(kāi)發(fā)表的有關(guān)車輛套牌大數(shù)據(jù)文章進(jìn)行檢索.發(fā)現(xiàn)車輛套牌監(jiān)測(cè)的研究主要停留在監(jiān)測(cè)方法方面,大數(shù)據(jù)技術(shù)在車輛套牌方面的應(yīng)用研究不足,采用的大數(shù)據(jù)分析框架也比較老.另外,研究?jī)?nèi)容主要集中在數(shù)據(jù)分析方面,數(shù)據(jù)存儲(chǔ)方面的研究很少.
代表性的如文獻(xiàn)[1]提出了一種基于歷史車牌識(shí)別數(shù)據(jù)(ANPR)集的套牌車并行檢測(cè)方法TP-Finder,實(shí)現(xiàn)了基于整數(shù)劃分的數(shù)據(jù)分塊策略,可準(zhǔn)確呈現(xiàn)所有疑似套牌車輛的歷史行車軌跡.文獻(xiàn)[2]提出一種基于路段閾值表和時(shí)間滑動(dòng)窗口的套牌計(jì)算模型,可以實(shí)時(shí)甄別交通數(shù)據(jù)流中的套牌嫌疑車.文獻(xiàn)[3]將實(shí)際車輛記錄遷移到Hadoop集群的HBase中,然后從Hive從HBase中獲取同一車牌號(hào)碼的時(shí)空分布情況,通過(guò)校正因子獲取最終的嫌疑套牌車.文獻(xiàn)[4,5]提出一種針對(duì)大規(guī)模數(shù)據(jù)集的分布式計(jì)算模型MapReduce.文獻(xiàn)[6]提出一種新的基于Hadoop的MapReduce算法模型,可以有效地解決處理海量數(shù)據(jù)時(shí)面臨的性能瓶頸問(wèn)題,該算法通過(guò)引入多臺(tái)硬件計(jì)算資源協(xié)同處理大規(guī)模數(shù)據(jù)下的套牌車檢測(cè).文獻(xiàn)[7]提出一種比Hadoop實(shí)時(shí)性好的分布式實(shí)時(shí)計(jì)算框架Storm.該框架具有健壯性、容錯(cuò)性、動(dòng)態(tài)調(diào)整并行度等特性.
通過(guò)對(duì)文獻(xiàn)研究可知,目前普遍做法將實(shí)際的海量數(shù)據(jù)導(dǎo)入或并行連接到大數(shù)據(jù)平臺(tái)上,然后再進(jìn)行數(shù)據(jù)分析,進(jìn)而監(jiān)測(cè)套牌車輛.但這些做法的實(shí)時(shí)性普遍不足,如文獻(xiàn)[1-3]均采用對(duì)歷史記錄的分析,車輛運(yùn)行每時(shí)每刻在發(fā)生,這種做法顯然實(shí)時(shí)性很差.文獻(xiàn)[4-6]中雖然考慮了實(shí)時(shí)性,但MapReduce屬于批處理算法,等數(shù)據(jù)集到一個(gè)量的時(shí)候才啟動(dòng),勢(shì)必會(huì)有一個(gè)時(shí)間延遲.因此,本文充分考慮車輛套牌監(jiān)測(cè)的實(shí)時(shí)性要求,借鑒文獻(xiàn)[7],引入Kafka (分布式消息隊(duì)列)和Storm(分布式實(shí)時(shí)大數(shù)據(jù)處理系統(tǒng))來(lái)解決海量車牌數(shù)據(jù)的實(shí)時(shí)分析和信息存儲(chǔ)問(wèn)題,Kafka作為中間件可以為日志信息提供緩沖機(jī)會(huì),有效緩解了數(shù)據(jù)采集和數(shù)據(jù)分析的不同步問(wèn)題,提高了數(shù)據(jù)的高可用性和實(shí)時(shí)性,避免了由于服務(wù)器故障而造成數(shù)據(jù)丟失的問(wèn)題.Storm中的運(yùn)行的是拓?fù)?topology)算法相對(duì)于MapReduce而言,進(jìn)程是永駐的,只要有數(shù)據(jù)就可以進(jìn)行實(shí)時(shí)處理,從而可以實(shí)現(xiàn)實(shí)時(shí)分析,實(shí)現(xiàn)套牌監(jiān)測(cè)的實(shí)時(shí)性、準(zhǔn)確性.
2 Kafka和Storm的車輛套牌實(shí)時(shí)分析存儲(chǔ)系統(tǒng)分析
為了實(shí)現(xiàn)實(shí)時(shí)分析、存儲(chǔ)車輛套牌信息,本文提出一個(gè)基于Kafka和Storm的車輛套牌實(shí)時(shí)分析存儲(chǔ)系統(tǒng)(簡(jiǎn)稱車輛套牌實(shí)時(shí)分析存儲(chǔ)系統(tǒng)).從系統(tǒng)功能模塊的邏輯結(jié)構(gòu)和劃分兩個(gè)角度分別進(jìn)行描述.
2.1 邏輯層次結(jié)構(gòu)
該系統(tǒng)包含的邏輯執(zhí)行過(guò)程:日志獲取、日志緩沖、數(shù)據(jù)分析和數(shù)據(jù)存儲(chǔ).圖1是邏輯過(guò)程分層結(jié)構(gòu)圖.

圖1 邏輯層次結(jié)構(gòu)圖
數(shù)據(jù)采集主要用來(lái)收集用戶操作產(chǎn)生的車輛日志信息.數(shù)據(jù)緩存減少了流量超峰給系統(tǒng)帶來(lái)的壓力,該模塊使用Flume[8](分布式日志收集系統(tǒng))、Kafka、Storm、Redis[9](云數(shù)據(jù)庫(kù))等大數(shù)據(jù)框架搭建后端服務(wù)架構(gòu).從結(jié)構(gòu)圖(如圖1)可知,道路監(jiān)控系統(tǒng)產(chǎn)生的日志信息,先通過(guò)Kafka進(jìn)行備份緩存,然后將Kafka、Storm進(jìn)行整合,將數(shù)據(jù)導(dǎo)入Storm運(yùn)行框架中.Storm中Spout (Storm消息源)會(huì)源源不斷地從Kafka上某個(gè)主題獲取數(shù)據(jù),并對(duì)數(shù)據(jù)進(jìn)行封裝發(fā)送到下游的Bolt (Storm消息處理者)計(jì)算節(jié)點(diǎn),Bolt節(jié)點(diǎn)對(duì)數(shù)據(jù)進(jìn)行實(shí)時(shí)計(jì)算,判斷是否出現(xiàn)套牌車輛,算法邏輯都會(huì)在Bolt節(jié)點(diǎn)中進(jìn)行運(yùn)算處理.最后系統(tǒng)將實(shí)時(shí)計(jì)算后的結(jié)果數(shù)據(jù)存儲(chǔ)到服務(wù)器的文件中,最后一次的車輛信息存入Redis中.
2.2 模塊功能分析
車輛套牌實(shí)時(shí)分析存儲(chǔ)系統(tǒng)的功能包括日志緩存與獲取、日志信息切分、套牌監(jiān)測(cè)和信息存儲(chǔ).
(1)日志緩存與獲取
通過(guò)連接道路監(jiān)控系統(tǒng),在數(shù)據(jù)實(shí)時(shí)采集與數(shù)據(jù)實(shí)時(shí)處理之間搭建一個(gè)Kafka消息隊(duì)列進(jìn)行緩存,解決數(shù)據(jù)實(shí)時(shí)采集與數(shù)據(jù)實(shí)時(shí)處理之間速度不同步和數(shù)據(jù)丟失的問(wèn)題,進(jìn)一步將道路車輛監(jiān)控系統(tǒng)產(chǎn)生的實(shí)時(shí)日志數(shù)據(jù)通過(guò)Kafka導(dǎo)入系統(tǒng).其次通過(guò)Kafka與Storm進(jìn)行整合,然后將數(shù)據(jù)導(dǎo)入Storm運(yùn)行框架中.
(2)日志信息切分
對(duì)采集到數(shù)據(jù)進(jìn)行切分,獲取系統(tǒng)需要使用的有效數(shù)據(jù).
(3)套牌監(jiān)測(cè)
通過(guò)車輛id從Redis數(shù)據(jù)庫(kù)中快速讀取道路車輛監(jiān)控系統(tǒng)對(duì)應(yīng)的最近監(jiān)控歷史記錄,計(jì)算當(dāng)前車輛的區(qū)間速度,如果車輛速度超過(guò)區(qū)間速度值就將對(duì)應(yīng)車牌號(hào)碼標(biāo)記為套牌號(hào)牌.
(4)信息存儲(chǔ)
從實(shí)時(shí)的道路監(jiān)控記錄中提取出必要的交通信息,并將實(shí)時(shí)交通信息存入數(shù)據(jù)庫(kù)中.
2.3 類的設(shè)計(jì)
本系統(tǒng)涉及的主要實(shí)體類包括:KafkaTopo、SplitBolt、SpeedBolt、StorageBolt、JedisPoolUtils.下面是整個(gè)系統(tǒng)的類圖結(jié)構(gòu),如圖2所示.
實(shí)體類介紹:
(1)KafkaTopo類主要是將Kafka與Storm進(jìn)行整合,這個(gè)類既具備緩沖特點(diǎn)又具備實(shí)時(shí)計(jì)算的特點(diǎn).
(2)JedisPoolUtils類主要是編寫(xiě)對(duì)Redis進(jìn)行讀寫(xiě)的Java客戶端代碼,讀取連接池配置文件,從而提供訪問(wèn)Redis的接口.
(3)SplitBolt類主要是對(duì)收到的日志信息進(jìn)行拆分,提取有用信息,發(fā)送到SpeedBolt.
(4)SpeedBolt類主要是對(duì)SplitBolt發(fā)送來(lái)的信息與Redis中的信息進(jìn)行對(duì)比,計(jì)算出動(dòng)態(tài)車速,并且檢測(cè)出套牌車輛,將套牌車輛信息發(fā)送到StorageBolt.
(5)StorageBolt類主要是對(duì)SpeedBolt發(fā)送來(lái)的套牌車輛信息進(jìn)行存儲(chǔ).
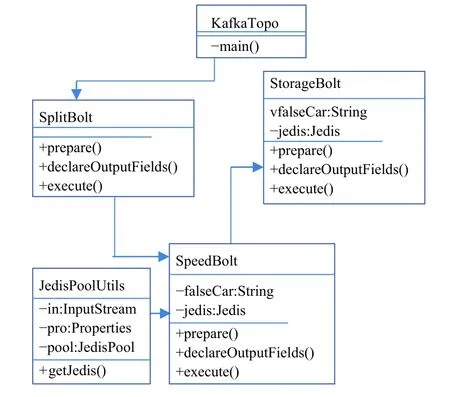
圖2 系統(tǒng)類圖
KafkaTopo類是整個(gè)系統(tǒng)的主要控制部分,通過(guò)將數(shù)據(jù)分析與計(jì)算流程串聯(lián)起來(lái);首先是設(shè)置Kafka的主題與配置其Broker的主機(jī)地址,通過(guò)配置可以將日志數(shù)據(jù)獲取進(jìn)來(lái);接下來(lái)設(shè)置3個(gè)Bolt組件,分別完成數(shù)據(jù)切分、動(dòng)態(tài)車速計(jì)算與數(shù)據(jù)存儲(chǔ)的功能;最后將整個(gè)工程打成jar包提交到配置好的服務(wù)器上,來(lái)完成實(shí)時(shí)的車輛套牌檢測(cè)功能.其具體的功能時(shí)序圖如圖3所示.
3 Kafka和Storm的車輛套牌實(shí)時(shí)分析存儲(chǔ)系統(tǒng)實(shí)現(xiàn)
本系統(tǒng)實(shí)現(xiàn)按照日志緩存與獲取、日志信息切分、套牌監(jiān)測(cè)和信息存儲(chǔ)4個(gè)功能展開(kāi).
3.1 日志緩存與獲取
日志緩存與獲取是通過(guò)Kafka來(lái)實(shí)現(xiàn),首先將Kafka分別安裝到3臺(tái)Linux服務(wù)器上,由于Kafka的高可用是通過(guò)Zookeeper[10]來(lái)實(shí)現(xiàn)的,因此需要在3臺(tái)服務(wù)器上安裝Zookeeper集群,Zookeeper集群的IP將作為Kafka的Broker的配置地址.接下來(lái)通過(guò)Storm提供的SpoutConfig來(lái)將Broker的主機(jī)地址、Kafka的主題、Zookeeper集群的服務(wù)器地址、Storm的SpoutId進(jìn)行設(shè)置,從而將整個(gè)數(shù)據(jù)的接收所需要依賴的環(huán)境搭建起來(lái).接下來(lái)對(duì)Storm從kafka獲取數(shù)據(jù)的方式進(jìn)行設(shè)置,將其設(shè)置成從數(shù)據(jù)流的起始位置開(kāi)始讀取數(shù)據(jù);這些配置設(shè)置完成后,最終實(shí)例化一個(gè)Topology Builder對(duì)象來(lái)將之前的配置信息進(jìn)行整合,從而使其成功獲取從車輛監(jiān)控系統(tǒng)獲取的數(shù)據(jù).
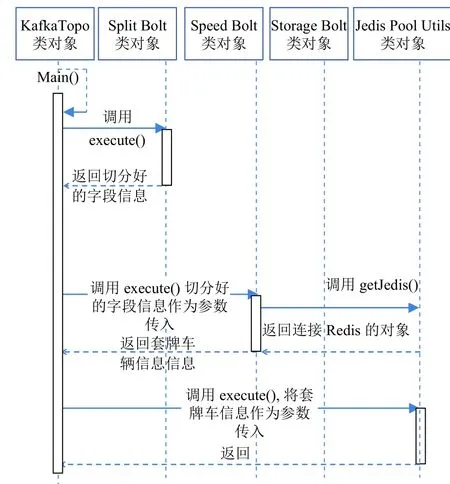
圖3 系統(tǒng)時(shí)序圖
整個(gè)數(shù)據(jù)流的緩存是通過(guò)Kafka來(lái)實(shí)現(xiàn)的.因?yàn)镵afka的broker結(jié)點(diǎn)上會(huì)有消費(fèi)者機(jī)制與生產(chǎn)者機(jī)制,通過(guò)設(shè)置生產(chǎn)者所生產(chǎn)消息的長(zhǎng)度來(lái)控制消費(fèi)者的消費(fèi).使得整個(gè)數(shù)據(jù)流經(jīng)過(guò)Kafka都會(huì)有一個(gè)緩存的過(guò)程,如果數(shù)據(jù)出現(xiàn)丟失,也可以通過(guò)設(shè)置ACK來(lái)實(shí)現(xiàn)回滾,使得消息不會(huì)產(chǎn)生丟失.整個(gè)Kafka的機(jī)制實(shí)現(xiàn)了日志信息數(shù)據(jù)流傳輸?shù)母呖捎眯?
其整個(gè)獲取與緩存的流程圖如圖4所示.
3.2 日志信息的切分
通過(guò)從Storm的Spout將信息發(fā)送到指定的SplitBolt進(jìn)行切分字段,SplitBolt繼承BaseBasicBolt,通過(guò)對(duì)其execute()方法進(jìn)行重寫(xiě)來(lái)實(shí)現(xiàn)日志信息的切分.通過(guò)其方法的Tuple參數(shù)接收到Spout發(fā)送來(lái)的日志信息,將接收到的信息通過(guò)toString()方法轉(zhuǎn)換成字符串類型,從而進(jìn)一步使用split()方法來(lái)對(duì)整個(gè)字符串信息進(jìn)行切分,獲取車輛的id、車牌、坐標(biāo)、行進(jìn)方向、拍攝時(shí)間等字段信息.之后調(diào)用參數(shù)中Collector對(duì)象的emit()方法來(lái)將切分出來(lái)的字段信息進(jìn)行封裝,發(fā)送到下一個(gè)Bolt.
整個(gè)日志信息切分過(guò)程時(shí)序圖如圖5所示.
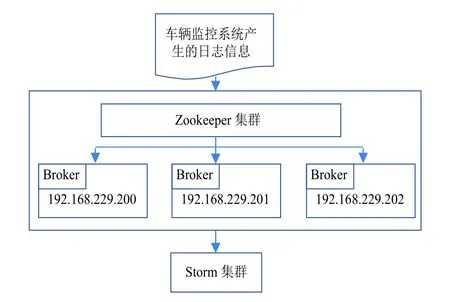
圖4 日志信息獲取與緩存流程圖
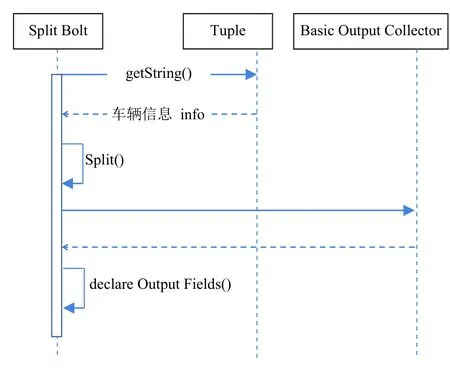
圖5 日志信息切分時(shí)序圖
3.3 套牌監(jiān)測(cè)
文獻(xiàn)[1]中提出一種利用車輛時(shí)空矛盾關(guān)系判斷套牌的算法,借鑒該算法.本文認(rèn)為正常行駛的車輛在區(qū)間內(nèi)的動(dòng)態(tài)車速在一個(gè)限速范圍內(nèi),如果某輛車出現(xiàn)了套牌情況,必然會(huì)出現(xiàn)在相同時(shí)間點(diǎn),坐標(biāo)位置不同的情況,而且算出的區(qū)間動(dòng)態(tài)車速遠(yuǎn)高于標(biāo)準(zhǔn)車速,因此可斷定該車輛為可疑套牌車輛.
算法步驟:
Step 1.創(chuàng)建Jedis客戶端,配置相關(guān)數(shù)據(jù),建立連接池,連接Redis數(shù)據(jù)庫(kù)接口.
Step 2.獲取當(dāng)前車輛id、車牌、坐標(biāo)、運(yùn)行方向、獲取時(shí)間等信息
Step 3.從Redis中通過(guò)id獲取車輛信息,若有,拿出來(lái)通過(guò)動(dòng)態(tài)車速對(duì)比,看是否發(fā)生套牌.若沒(méi)有,將信息存入Redis中
其主要業(yè)務(wù)邏輯是:從上一Bolt中獲取“id”,“registId”,“hangId”,“x”,“y”,“dir”,“time”和“info”信息,通過(guò)id判斷Redis中是否有該車輛信息,若沒(méi)有,則將該車輛整條信息保存進(jìn)入Redis中;若有,則將車輛信息拿出來(lái)切分,從而獲取“x”,“y”,“dir”,“time”等字段信息,將兩次的信息進(jìn)行對(duì)比計(jì)算出動(dòng)態(tài)車速;若此車速遠(yuǎn)大于區(qū)間車速,則該車為套牌車輛.
(1)動(dòng)態(tài)車速計(jì)算
從上一Bolt中獲取車輛信息,通過(guò)車輛id判斷Redis中是否有該車輛信息,若沒(méi)有,則將該車輛整條信息保存進(jìn)入Redis中;若有,則將車輛信息拿出來(lái)切分,從而獲取坐標(biāo)、時(shí)間等字段信息,將兩次的信息進(jìn)行對(duì)比計(jì)算出動(dòng)態(tài)車速;若此車速遠(yuǎn)大于區(qū)間車速,則該車為套牌車輛.
具體的業(yè)務(wù)處理是在execute()方法中,通過(guò)其Tuple參數(shù)來(lái)接收SplitBolt發(fā)送過(guò)來(lái)的各個(gè)字段信息和車輛的整條info日志信息.通過(guò)創(chuàng)建carInfo、hangId、x、y、dir、time等字段來(lái)獲取車輛信息;之后通過(guò)調(diào)用Jedis對(duì)象的get()方法,將last_hangId傳入,看返回結(jié)果是否為空,若可以獲取到車輛信息,則將獲取到的車輛信息進(jìn)行再次切分,拿到上次記錄到的字段信息,分別設(shè)置為 last_x、last_y、last_dir、last_time;之后調(diào)用String對(duì)象的equals()方法來(lái)判斷相同車輛兩次的行駛方向是否相同,若相同并且為x方向,則將x于last_x相減取絕對(duì)值,其結(jié)果就是車輛的行駛路徑;將兩次時(shí)間相減取絕對(duì)值并進(jìn)行單位換算,從而獲得時(shí)間.路程與時(shí)間相除即可得到車輛的動(dòng)態(tài)車速.若行駛方向?yàn)閥,計(jì)算方法相同.最后將車輛信息存入Redis中,替換掉之前的車輛信息.若從Redis中獲取數(shù)據(jù)為空,則說(shuō)明此車輛還沒(méi)有被車輛監(jiān)控系統(tǒng)記錄過(guò),因此直接存入Redis中.
(2)套牌判定
獲取動(dòng)態(tài)車速后,接下來(lái)就是與此路段的區(qū)間標(biāo)準(zhǔn)車速進(jìn)行比較,若獲取的動(dòng)態(tài)車速遠(yuǎn)大于區(qū)間車速,則懷疑出現(xiàn)了兩輛相同車牌的車輛,將其判定為套牌車輛.并將此車輛信息通過(guò)調(diào)用Collector的emit()方法將套牌車輛信息發(fā)送出去.最后仍然要調(diào)用declare OutputFields()方法,來(lái)指定發(fā)送字段為info,即套牌車輛信息.
對(duì)以上整個(gè)車速計(jì)算和套牌車的檢測(cè)所做出的功能時(shí)序圖如圖6所示.
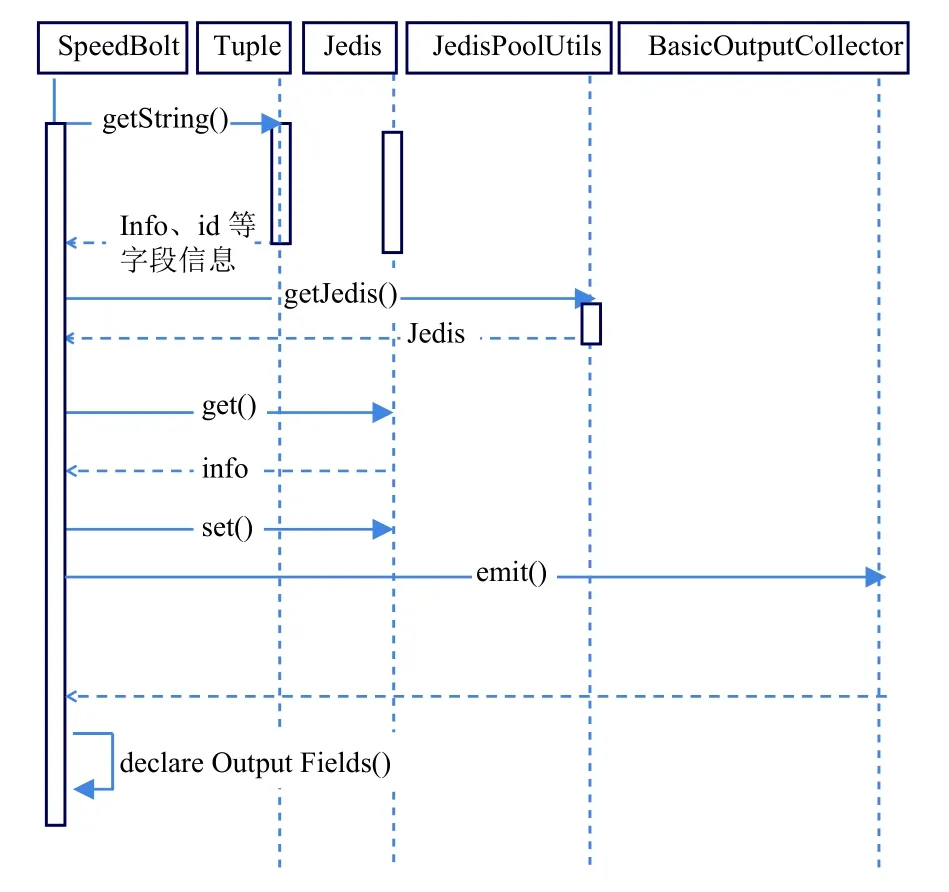
圖6 套牌監(jiān)測(cè)功能時(shí)序圖
3.4 信息存儲(chǔ)
將檢測(cè)出的套牌車輛信息通過(guò)編寫(xiě)輸出代碼和修改相關(guān)配置文件,存入分布式服務(wù)器上指定的文檔中,從而可以完成信息的分布式存儲(chǔ).
首先,通過(guò)Tuple對(duì)象獲取SpeedBolt發(fā)送過(guò)來(lái)的套牌車輛信息,調(diào)用FileWriter的write()方法,來(lái)對(duì)日志信息進(jìn)行寫(xiě)操作;然后調(diào)用其flush()方法來(lái)刷新數(shù)據(jù)流,從而使得之前寫(xiě)入的數(shù)據(jù)能完整輸出到指定的文件中.信息存儲(chǔ)的功能時(shí)序圖如圖7所示.
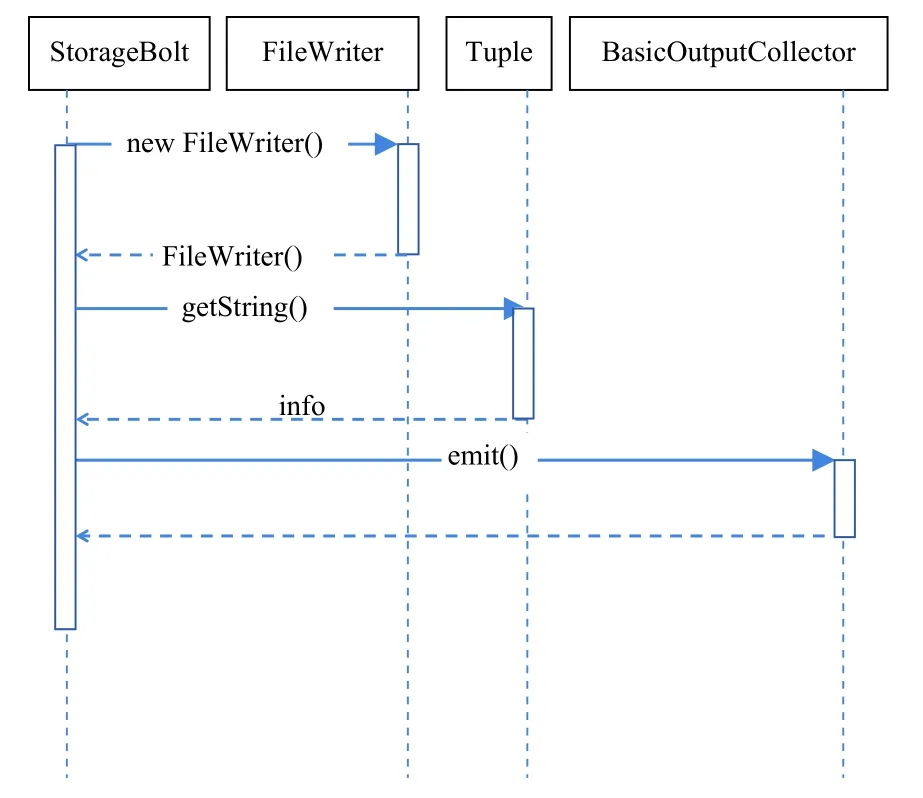
圖7 套牌車輛信息存儲(chǔ)時(shí)序圖
通過(guò)對(duì)4個(gè)功能模塊的實(shí)現(xiàn)過(guò)程敘述與部分功能時(shí)序圖的介紹,對(duì)系統(tǒng)的整個(gè)功能進(jìn)行了詳細(xì)的實(shí)現(xiàn).對(duì)接收到的日志信息進(jìn)行了詳細(xì)的分析與計(jì)算,整個(gè)系統(tǒng)的業(yè)務(wù)邏輯實(shí)現(xiàn)完畢,接下來(lái)工程的部署模塊可以直接將工程打成jar包來(lái)進(jìn)行實(shí)時(shí)的運(yùn)行.至此,系統(tǒng)實(shí)現(xiàn)已全部完成.
4 實(shí)驗(yàn)
本系統(tǒng)的實(shí)驗(yàn)環(huán)境包括集群搭建和數(shù)據(jù)庫(kù)服務(wù)器安裝,主要包括Zookeeper集群、Kafka集群、Storm集群、Redis安裝等.實(shí)驗(yàn)環(huán)境配置完畢,將工程打成jar包上傳到搭建好的集群運(yùn)行,通過(guò)連接車輛模擬系統(tǒng)產(chǎn)生實(shí)時(shí)數(shù)據(jù),可以看見(jiàn)Redis數(shù)據(jù)庫(kù)上存儲(chǔ)所有收集到的車輛信息,如圖8所示.
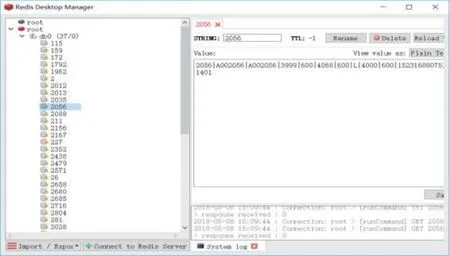
圖8 Redis測(cè)試數(shù)據(jù)圖
/home/hadoop/stormoutput目錄下存儲(chǔ)有套牌車輛嫌疑的車輛信息,如圖9所示.以這些信息為基礎(chǔ),交管人員只需后期和車輛具體核實(shí),即可按照相關(guān)交通法規(guī)進(jìn)行處理.
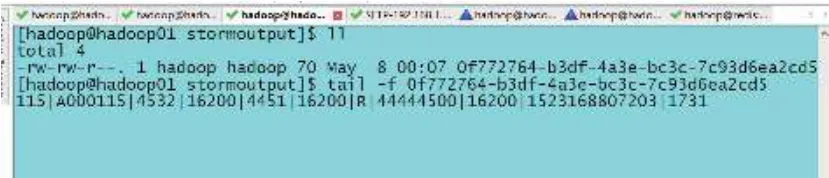
圖9 套牌車輛信息圖
5 總結(jié)
針對(duì)當(dāng)前海量車輛數(shù)據(jù)套牌檢測(cè)實(shí)時(shí)性差的難點(diǎn),引入了大數(shù)據(jù)技術(shù),經(jīng)過(guò)文獻(xiàn)對(duì)比研究,發(fā)現(xiàn)Kafka作為中間件進(jìn)行緩存,不僅保證了數(shù)據(jù)采集的效率而且還保證了數(shù)據(jù)的高可用性.再加上,Storm比Hadoop實(shí)時(shí)性處理能力強(qiáng),所以Kafka結(jié)合Storm提高了車輛套牌監(jiān)測(cè)的實(shí)時(shí)性.最后通過(guò)集群環(huán)境的搭建,實(shí)驗(yàn)分析發(fā)現(xiàn)系統(tǒng)性能已達(dá)到設(shè)計(jì)目標(biāo).在今后的研究工作中,將探索研究套牌識(shí)別的精準(zhǔn)度,進(jìn)而更有效地幫助交管部門(mén)完成套牌識(shí)別工作.
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國(guó)洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
中外會(huì)展(2014年4期)2014-11-27 07:46:46
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
