基于聯合學習的跨領域法律文書中文分詞方法
2019-10-21 02:01:48江明奇李壽山
中文信息學報 2019年9期
江明奇,嚴 倩,李壽山
(蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
0 引言
中文分詞作為中文信息處理的基礎任務,其準確性直接影響其它中文信息處理任務的性能[1]。基于機器學習的方法在中文分詞領域上有優異的結果。例如,最大熵(maximum entropy)模型[2]、條件隨機場(conditional random field,CRF)模型[3-5]以及長短期記憶(long short-term memory,LSTM)神經網絡[6]。然而,傳統的方法需要大規模的分詞語料以訓練性能優異的分詞器,分詞語料的獲得需要大量人工參與,所耗費的成本太高。因此,傳統的方法在法律文書上不能取得較好的中文分詞性能[7]。
由于法律文書中各領域的語料匱乏,學者們使用跨領域的方法進行分詞性能的提升。然而,不同領域的樣本有一定的差異性,因此在跨領域任務上難以直接使用不同領域的樣本提升分詞性能。其主要原因在于各領域的詞語分布不同,當使用源領域的分詞器對目標領域進行分詞時,未登錄詞(out of vocabulary,OOV)的數目快速增加,因此該分詞器在目標領域上進行中文分詞時無法獲得較好的性能。除此之外,法律文書中的專有名詞的構詞規則和通用領域不同,同一個字符在不同領域中具有不同的標簽分布。例如,在法律文書中,“一審”和“二審”為常用詞。其中,“審”為詞尾,其標簽為“E”。但該字在通用領域中情況有所不同,“審”通常以詞首的形式出現,如“審稿”,其標簽為“B”。
鑒于獲得法律文書的各個領域的少量已標注語料的難度較小,各領域擁有相同的標注規則,本文提出了一種基于聯合學習的跨領域中文分詞方法。該方法通過使用法律文書某一領域(源領域)數據輔助另一領域(目標領域)的方式可以提高相應的分詞性能。此外,本文并沒有采用直接混合源領域的樣本和目標領域的樣本的方法,而是采用聯合學習的方法,在模型中存在主任務(目標領域的分詞)和輔助任務(源領域的分詞),輔助任務對主任務有一定的輔助作用。具體而言,首先,使用共享LSTM層得到兩個任務的輔助表示,讓主任務和輔助任務共同參與分詞結果的評判;其次,將該輔助表示與主任務的表示進行融合;最后,利用LSTM對主任務的結果進行預測。本文創建了法律文書的分詞語料庫,并針對法律文書的特點把本文的方法應用到法律文書的分詞當中。
本文的組織結構如下: 第1節介紹本文相關的一些工作;第2節詳細介紹基于聯合學習的跨領域中文分詞方法;第3節對中文分詞結果進行分析;第4節對本文做出總結,并對下一步工作進行展望。
1 相關工作
1.1 中文分詞
近些年來,隨著神經網絡的廣泛應用,越來越多的研究人員把神經網絡使用到分詞系統中。
Zheng等首次在中文分詞任務中使用深度學習模型,同時提出了一種感知器方法用來加速訓練過程[8]。Chen等將改進的長短期記憶神經網絡運用到中文分詞任務中,該模型是一種可以學習到長期依賴關系的循環神經網絡(recurrent neural network,RNN)[9]。實驗結果表明,該模型與傳統模型在中文分詞任務上性能相當。Yao等提出使用雙向LSTM層進行中文分詞任務,并在實驗中對比了含有不同數目的雙向LSTM層的實驗結果[10]。Xu和Sun提出了基于長短期記憶神經網絡的中文分詞方法,在其中采集局部特征,并通過門控遞歸神經網絡生成具有長距離依賴性的局部特征[11]。金等提出了一種雙向LSTM模型,并把它用在了分詞任務上[12]。Kamper等通過聲音的詞的嵌入進行無監督的中文分詞任務[13]。
1.2 跨領域的中文分詞
鄧等將基于通用領域標注文本的有指導訓練和基于目標領域無標記文本的無指導訓練相結合,即在全監督CRF中加入最小熵正則化框架,提出了半監督的CRF模型,提高了中文分詞上的F1值[14]。佟等提出了一種稱為上下文變量(context variables)的數據來衡量某個候選詞在篇章內的上下文信息,并使用語義資源,用其同義詞的節點代價作為自己的代價,提高了未登錄詞的召回率[15]。許等針對目標領域分詞語料的匱乏問題, 提出主動學習(active learning)算法與 N-gram統計特征相結合的領域自適應方法,用主動學習算法訓練的分詞系統各項指標上均有提高[16]。
2 基于聯合學習的跨領域中文分詞方法
2.1 基于LSTM模型的中文分詞方法
RNN模型是Rumelhart等提出的具有循環結構的網絡結構[17]。為了解決RNN中的長期依賴問題,Hochreiter和Schmidhuber[18]提出了一種新網絡,稱為長短期記憶(long short-term memory,LSTM)神經網絡,該網絡適用于處理和序列中長間隔的事件。LSTM神經網絡在每個時間步包含一個更新歷史信息的神經單元。Graves[19]對LSTM模型進行了相應的優化,此后LSTM廣泛應用于語音等領域。
如圖1所示,LSTM單元設置了記憶單元ct用于保存歷史信息。LSTM的t時刻的神經單元計算如式(1)~式(6)所示。

圖1 LSTM單元


圖2 基于LSTM模型的法律文書中文分詞方法的基本框架
2.1.1 LSTM層
我們將所有關于當前字符的特征拼接得到的向量作為LSTM的輸入。例如,若當前字符為chi,我們將前一個字符chi-1、當前字符chi以及chi+1的一元和二元字的信息進行拼接,形成輸入向量。輸入向量通過LSTM層得到隱層向量。
2.1.2 全連接層
全連接層用于接收LSTM層的輸出,我們在全連接層中加入激活函數,如式(7)所示。
其中,h為LSTM層的輸出,φ為非線性激活函數,本文使用中“ReLU”作為全連接層的激活函數。
2.1.3 Dropout層
Dropout為當前深度學習中主流方法之一,能有效避免深度神經網絡中的過擬合問題,提高基于深度學習模型的性能[20],Dropout層在訓練時屏蔽某些神經元,從而避免過擬合問題,Dropout操作的過程如式(8)所示。
其中,D為dropout操作符,p為可調超參(神經元以該超參的概率決定是否被屏蔽)。
2.1.4 Softmax層
Softmax層用于接收Dropout層的輸出,并輸出最終結果,如式(9)所示。
其中,p表示預測標簽的概率集,Wd為相應的權重向量,bd為偏置。
2.2 基于聯合學習的跨領域中文分詞方法
法律文書的特點在于其中存在許多專業詞匯,各領域的差異性體現在各領域存在不同的專業詞匯。然而,各領域含有共通的專業詞匯和相似的專業詞匯分詞規則。對于未登錄詞,由于目標領域的已標注樣本數目不足,不能較好地識別未登錄詞,因此我們使用將源領域的大量樣本加入輔助任務的方法來提升未登錄詞識別的性能,該方法的提升體現在以下兩點。(1)源領域可能含有目標領域中的某些未登錄詞(如“訴訟”“原告”),輔助任務能夠學習該未登錄詞中字對于分詞任務的表示。在共享中間表示的情況下,這些表示能夠幫助任務學習。(2)在輔助任務(源領域)和主任務(目標領域)都是未登錄詞的情況下,由于目標領域的訓練樣本規模有限,識別未登錄詞的性能有限,因此加入大量源領域的樣本,可能提升識別未登錄詞的性能。例如,在各領域的法律文書中,某些字(如“為”)常常出現在詞的開頭位置(如“為由”),加入大量樣本有利于提升識別這些字開頭的未登錄詞的能力。針對法律文書的上述問題,本文提出了一種基于聯合學習的跨領域中文分詞方法,有效利用源領域數據輔助目標領域。
圖3給出了基于聯合學習的跨領域中文分詞模型的基本框架。其中,目標領域的預測為主任務,源領域的預測為輔助任務,使用輔助LSTM層得到兩個任務的輔助表示,主任務利用該輔助表示進行預測。模型分為主任務、輔助任務以及聯合學習,其介紹如下。
2.2.1 主任務
首先,使用主LSTM層(Main LSTM Layer)和輔助LSTM層(Auxiliary LSTM Layer)分別生成目標領域的隱層表示hmain1和hmain2,如式(10)、式(11)所示。


圖3 基于聯合學習的跨領域中文分詞方法框架

2.2.2 輔助任務
首先,源領域的數據通過輔助LSTM層獲得相應的表示,輔助LSTM層連接了目標領域和源領域,使主任務和輔助任務對分詞同時參與評判,輔助LSTM層對于不同領域的數據有相同的權重,如式(15)所示。
其中,haux是共享的LSTM層對源領域進行編碼生成的表示。
其次,haux通過輔助任務的隱藏層獲得新的表示,輔助任務的隱藏層與主任務中的相同,如式(16)所示。
2.2.3 聯合學習
使用Softmax層(Softmax Layer)對主任務中的表示進行預測,并使用另一個Softmax層對輔助任務中的表示進行預測,如式(17)、式(18)所示。

(17)

(18)

最后,基于聯合學習的中文分詞模型的損失函數為主任務的損失函數和輔助任務的損失函數的加權線性損失之和,如式(19)所示。

3 實驗設計與分析
本節將給出本文提出的基于聯合學習的中文分詞模型的結果,同時對各個方法進行詳細分析。
3.1 實驗設置
(1) 數據設置: 本文的實驗數據集的來源為中國裁判文書網(1)http://wenshu.court.gov.cn/,我們對其中的婚姻領域和合同領域進行數據的收集和分詞的標注。在實驗時,本文在兩個領域中分別隨機選取100篇作為實驗樣本,據統計,在這100個樣本中,合同領域共存在66 755個詞,婚姻領域共存在46 425個詞。主任務的訓練數據分別為目標領域數據的10%、20%、30%和40%樣本,驗證集為目標領域數據的10%,測試集為目標領域的20%,輔助任務的訓練集為源領域相同數量的樣本,測試集與主任務中的樣本一致。
(2) 文本表示: 本文使用Word2Vec方法對樣本中字的一元特征和二元特征進行訓練,得到字對應的向量。我們將上下文窗口的長度設置為2。
(3) 參數設置: 本文使用LSTM模型進行中文分詞實驗,模型中的具體超參數如表1所示。

表1 模型中的參數值
在實驗中,采用F1值作為衡量分詞效果的標準。F1值具體的計算方法如式(20)所示。
其中,P表示分詞準確率,R表示分詞召回率,β為平衡因子。β大于1時,準確率比召回率更重要;β小于1時,召回率比準確率更重要;β等于1時,二者同等重要。在本文的實驗中,β取1。
3.2 實驗結果
本節中,我們將介紹幾種中文分詞方法,對所有方法進行結果統計和實驗結果進行分析。
(1) 面向源領域的中文分詞方法(Source_LSTM): 該方法僅使用LSTM模型對源領域數據進行訓練。
(2) 面向目標領域的中文分詞方法(Target_LSTM): 該方法僅使用LSTM模型對目標領域數據進行訓練。
(3) 面向混合領域的中文分詞方法(Mix_LSTM): 該方法將目標領域數據與源領域數據一起作為訓練樣本,并使用LSTM模型對所有訓練樣本進行訓練。
(4) 基于特征增強的中文分詞方法(Feature_Augmentation): 該方法由Daumé III[21]通過擴展不同領域中數據的特征提升領域適應性,在跨領域任務中可以有效改善性能。本節將源領域和目標領域混合后的樣本進行特征的擴展,并使用LSTM模型對其訓練。
(5) 基于聯合學習的跨領域中文分詞(Multi_LSTM): 該方法為本文提出的分詞方法。在實驗中,我們將λ設為0.7、0.8和0.9,表2和表3展示了λ值為0.7、0.8和0.9在驗證集中的實驗結果。
從表2和表3得知,λ為0.8時,在各個規模的樣本下均取得了最優結果,源領域的樣本產生的噪聲最小,因此本文聯合學習模型中的入定為0.8。
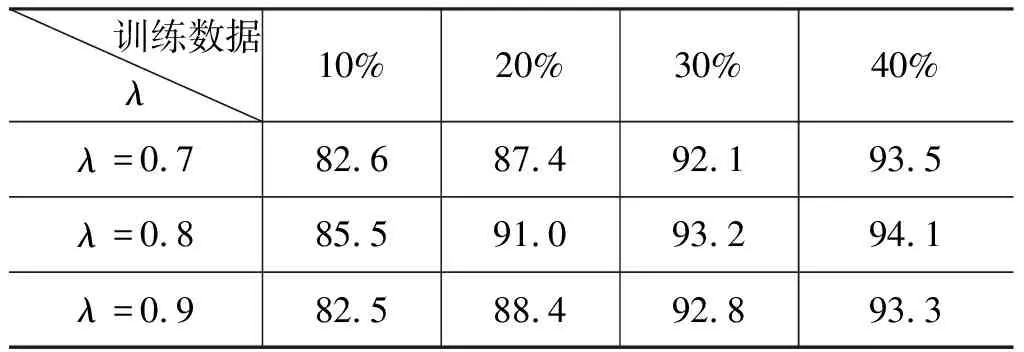
表2 基于不同參數的跨領域聯合學習F值(%)

表3 基于不同參數的跨領域聯合學習F值(%)
表4和表5給出了所有方法的結果,從表中可以得出以下4點。
(1) 面向目標領域的法律文書中文分詞方法在訓練樣本規模相同時分詞性能明顯優于面向源領域的法律文書中文分詞方法。原因在于跨領域訓練具有領域適應性問題。具體而言,針對源領域訓練獲得的分詞器不能有效適應目標領域的數據,因此獲得了較差的性能。
(2) 在樣本較少時,Target_LSTM方法的性能遠不及其余的跨領域的方法(Mix_LSTM、 Feature_Augmentation和Multi_LSTM)。因此,單任務的中文分詞方法難以適應目標領域語料匱乏的情況。
(3) Mix_LSTM方法直接混合源領域和目標領域的樣本,增加了訓練樣本數目,因此其分詞性能優于基線方法。
(4) 本文的Multi_LSTM方法分詞結果優于所有基線方法。在語料匱乏的情況下提升更為顯著。該方法的有效性體現在可以快速地加入法律專業詞匯(如“裁定書”“判決書”“糾紛”“訴訟”等),其他方法則不能在缺乏語料的情況下快速識別。因此,本文的方法能夠有效地降低人工標注數據的成本,并在此基礎上擁有優異的分詞性能。

表4 法律文書上各方法的F值(%)

表5 法律文書上各方法的F值(%)
4 結語
針對法律文書,本文提出了一種基于聯合學習的跨領域中文分詞方法。該方法通過聯合學習結合源領域和目標領域的少量已標注樣本,使其更加準確地識別目標領域中的詞語。具體而言,首先,本文將目標領域的預測作為主任務,將源領域的預測作為輔助任務;其次,使用共享LSTM層得到兩個任務的輔助表示,讓主任務和輔助任務共同參與分詞結果的評判;再次,將該輔助表示與主任務的表示進行融合;最后,利用LSTM對主任務的結果進行預測。實驗結果表明,本文的方法在目標領域擁有較少的訓練樣本條件下可以獲得較好的分詞性能。
下一步的工作,我們將使用目標領域中的未標注樣本進行半監督的分詞任務。此外,我們想收集更多相關領域法律文書,并對本文提出的方法進行有效性檢驗,希望解決跨領域的中文分詞中的領域適應性問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
