基于互信息和半監督學習的入侵檢測研究
2019-10-22 06:36:30石凱
現代計算機 2019年23期
石凱
(西南交通大學信息科學與技術學院,成都611756)
0 引言
隨著計算機網絡的日益普及和計算機服務的快速發展,其背后暴露的安全問題也更加突出。為了解決網絡安全的問題,提出了能針對網絡攻擊而主動采取反應措施的入侵檢測系統(Intrusion Detection System,IDS)[1]。IDS 能監視并分析主機和網絡,一旦發現異常情況,將馬上采取相應的措施并提供防護[2]。為了減少基于異常情況的IDS 的漏報率和誤報率,相關研究人員利用機器學習技術在大量的數據中提取特征和分類靈活快速的優勢,對未知攻擊數據集歸類。然而,現今研究仍然有以下問題:
(1)當目標網絡遭受攻擊時,大量的底層網絡數據包所包含的特征重要性不同,所以需要準確的對特征定性,并且剔除不重要或者可能降低檢測性能的特征。
(2)現今基于機器學習的未知攻擊檢測都需要大量的已有標記的數據進行訓練。在遭受攻擊時,大量的未知攻擊數據將產生,人工標注將降低檢測效率。
針對上述問題,本文提出一種基于相關性、冗余度和半監督學習的入侵檢測方案。主要貢獻有3 個方面:
(1)針對準確定性不同的特征,區分不同特征的重要性,使用改進的過濾算法,引入相關性、冗余度來確定不同特征對系統檢測性能的影響程度,從而減少多余特征的干擾,達到定量選取重要特征、加快檢測速度的目的;同時,使用相關性、冗余度也[3]可以定量的區分不同流量特征對于攻擊分類的重要程度。
(2)針對缺乏已標記數據的問題。為了很好地利用已有標記的數據,并且更好的得到未標記數據的標記,采用新型的CPLE 半監督學習利用數據特征相似性標記未標記的數據,從而得到大量可以參與訓練的已標記數據,達到增加檢測準確率的目的。
(3)NSL-KDD[4]數據集是KDD99 數據集的改進,解決了KDD99 很多潛在的問題,是網絡入侵檢測的標準數據。本方案在NSL-DD 上進行對比實驗,驗證了本方案的有效性。
1 基于機器學習的入侵檢測
機器學習在海量數據的處理上有著天然的優勢,所以在入侵檢測信息分析階段可以很流暢的引入機器學習的方法。Duan Xindong 等[5],提出了在云計算環境中設計一種新的非法用戶入侵行為檢測模型。利用主成分分析選擇非法用戶入侵行為的特征,并采用最小二乘支持向量機對入侵行為特征進行分類和檢測,采用粒子群優化算法確定最小二乘支持向量機的參數。Du Shao-Bo 等[6],針對入侵檢測算法的獨立冗余屬性導致入侵檢測算法檢測速度慢,檢測率低的問題,提出了一種基于鄰域距離的入侵特征選擇方法。
在大數據時代,依靠人工專家標注的數據仍然太少,較少的有效數據將極大的降低檢測系統的效率。在對攻擊數據特征進行篩選時,有效快速地選取特征十分重要,如果沒有很好地特征選擇,將減少接下來分類的準確率,所以如何在減少特征維數時速度更快、更準確變得尤為重要。
因此,本文提出一種基于最大相關最小冗余和半監督學習的入侵檢測方案,在更快速地降低網絡攻擊特征維數的同時,選取檢測更準確的特征,去除干擾檢測的特征,同時,自動化的標記以降低標注成本,盡可能多地保留分類信息以更準確的檢測未知攻擊。
2 我們的方案
為了提升檢測系統的效率,篩選出妨礙檢測的特征,本方案首先采用改進的最大相關最小冗余的方法,對數據集的特征進行選擇。之后為了應對未知攻擊檢測以及訓練數據集的規模較小的挑戰,采用半監督學習的方法利用少量標注的數據生成大量的訓練數據集進行訓練。
2.1 基于MR-MD的特征選擇方法
本文引入了一種基于距離函數的方法來度量每個特征的獨立性。距離越遠,獨立性越高。MRMD 的主要關注點是搜索一種特征排序度量,它包含兩個方面:一是特征子集與目標類之間的相關性,二是特征子集的冗余度。在本文中,Pearson 相關系數[6]被用來衡量相關性,利用三種距離函數來計算冗余度。
為了便于理解,我們將作如下規定。D 表示數據集,N 表示數據集D 數據的數量,M 表示數據集有M個特征。在F={ fi,i=1,2,3…,M }中,F 表示特征集合,其中fi代表各種不同的特征,c 表示分類目標,我們的目標是找到m 個特征(F 的特征子集),能夠使得盡可能多的數據符合分類目標c。
(1)最大相關性
對目標類條件進行分類的最大貢獻通常意味著最小的分類錯誤,最小誤差通常需要分類目標y 與F 的子空間有最大相關性,這要求我們選擇的特征子空間是與分類目標y 具有最高相關性的特征集。Pearson 相關系數可以測量正相關和負相關,因此選擇Pearson 相關系數作為特征與目標類c 之間的相關度量。給定兩個向量和,Pearson 相關系數的計算為:
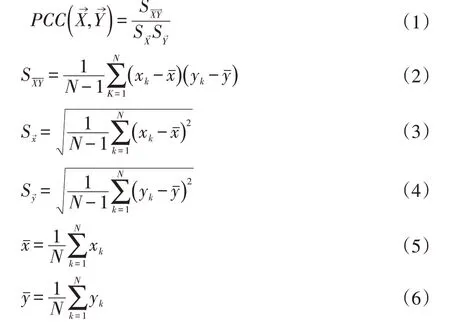
xk、yk分別是向量和的第k 個元素,向量X→和都是數據集D 中所有例子的屬于一個特征或者分類目標的值所組成的向量。最大相關則定義為:
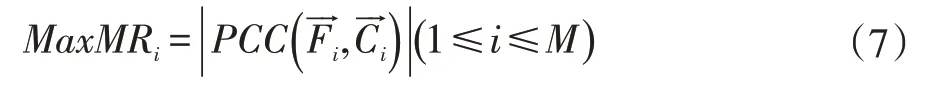
(2)最大距離
使用最大距離來測量兩個特征向量之間的相似度。為了綜合考慮各種維度的距離,選擇了歐氏距離,余弦相似度和Tanimoto 系數。計算方式分別為:
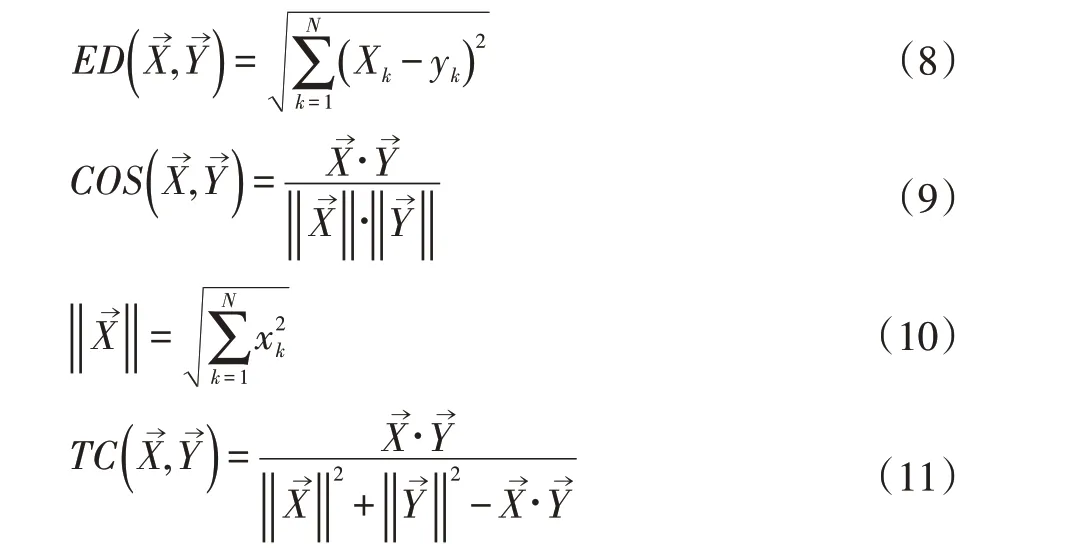
每個特征根據以下公式,我們可以得到第i 個特征的歐氏距離,余弦相似度和Tanimoto 系數:
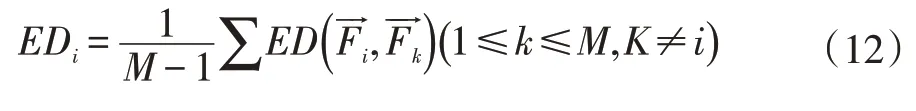
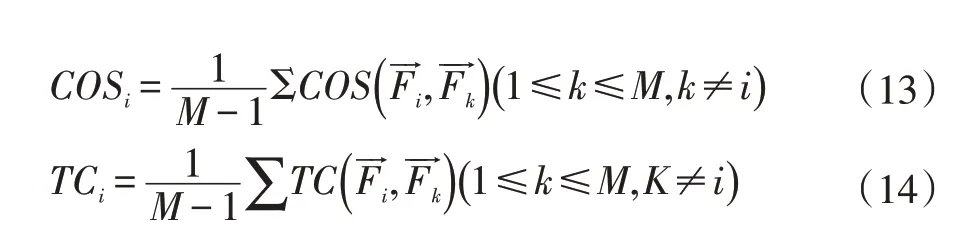
根據公式(12-14)可得到平均距離。
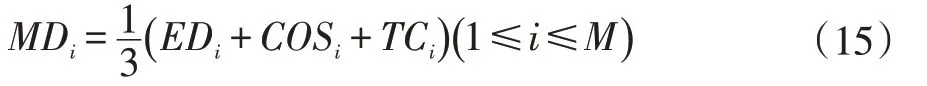
(3)本方案第一個模塊特征選擇
組合上述兩個約束的標準稱為“最大相關、最大距離”(MRMD)。假設我們選擇了具有m-1 個特征的子特征集。接下來的任務是從剩余特征集中選擇第m 個特征。該算法選擇最優特征的條件為:

即選擇相關性與距離之和的最大值為下一個選擇的特征。以上兩小節組成了入侵檢測方案的第一個模塊,特征選擇模塊。
2.2 基于CPLE的半監督學習
本小節將介紹最初的基于CPLE 的方案[7]。
半監督學習是監督和無監督組合的一種學習方法,并試圖通過合并標記和無標記的數據提供改進的分類。訓練集表示為表示xi是d維向量,表示為每個樣本的標記值。生成模型的對數可能性損失函數L 定義為:
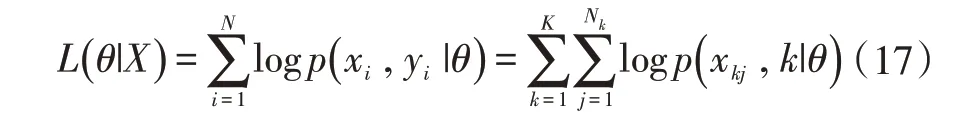
Nk表示分類標簽為k 的樣本數量,且表示為所有樣本數量。Θ 表示分類器的參數集,最大似然估計通常用于優化監督學習中的損失函數。最佳參數表示為:

半監督學習中的參數通過使用來估計標記和未標記的樣品。未標記的樣品表示為ui表示未標記樣本的特征,vi表示未觀察的響應變量,M 是未標記樣本數量。半監督分類器通過最大化可能性來優化的參數:
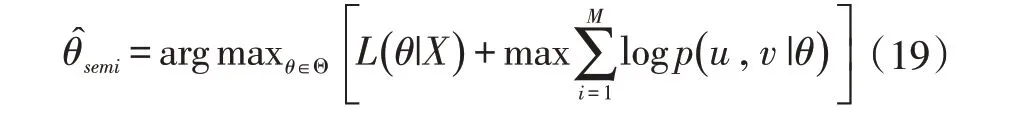

對于給定的q,相對改進半監督的對比似然CL 相對于受監督的參數估計θ可以表示為:
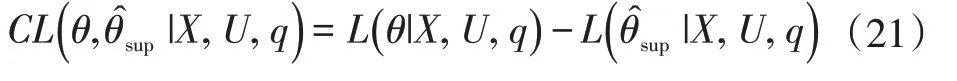
LOOG[8]提出q 的“悲觀”選擇,估計未知的軟標簽q 以達到之后優化的目的,即選擇q,能使CL 最小化,因此,CPL 目標函數變為:
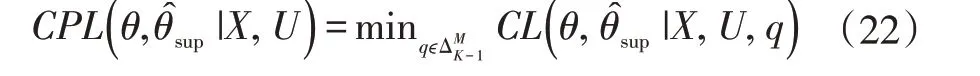
為了確保判別可能性的悲觀最小化,引入一個新的函數,表示如下:
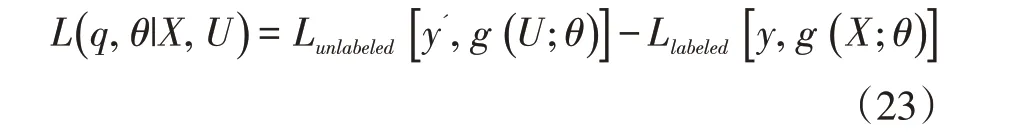
其中g( x;θ)=p( f=1 ]x,θ)表示后驗概率預測分類器,y'是基于后驗證的未標記的樣本預測的硬標簽,公式(23)可以通過以下步驟優化。
(1)初始化一個分類器C0,并且生成軟標簽q0
(2)對第i 次迭代(i=1,2,3,…,N):
①計算未標記數據硬標簽,計算公式為:
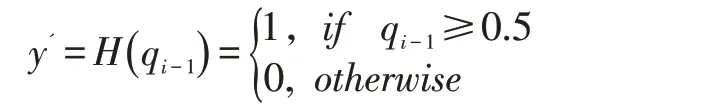
(3)迭代了N 次時,以CN為最終分類器。對于之后無標簽的樣本,使用分類器CN進行標簽預測或者分類。
2.3 本方案第二個模塊CPLE半監督模塊
本方案第二個模塊將接著利用第一個模塊選擇的特征,已經剔除不需要的特征及相關特征的數據。圖1為CPLE 半監督模塊模型。
在圖1 中,第一步,將已經過特征選擇的數據分裂為訓練集和測試集。第二步,使用在第一步中準備的可接受數據集構建監督分類器。使用來自接受和拒絕數據集的樣本訓練模型。第三步,將第二步中得出的分類規則是適用于測試集。第四步,重復以上步驟50次評估模型性能。
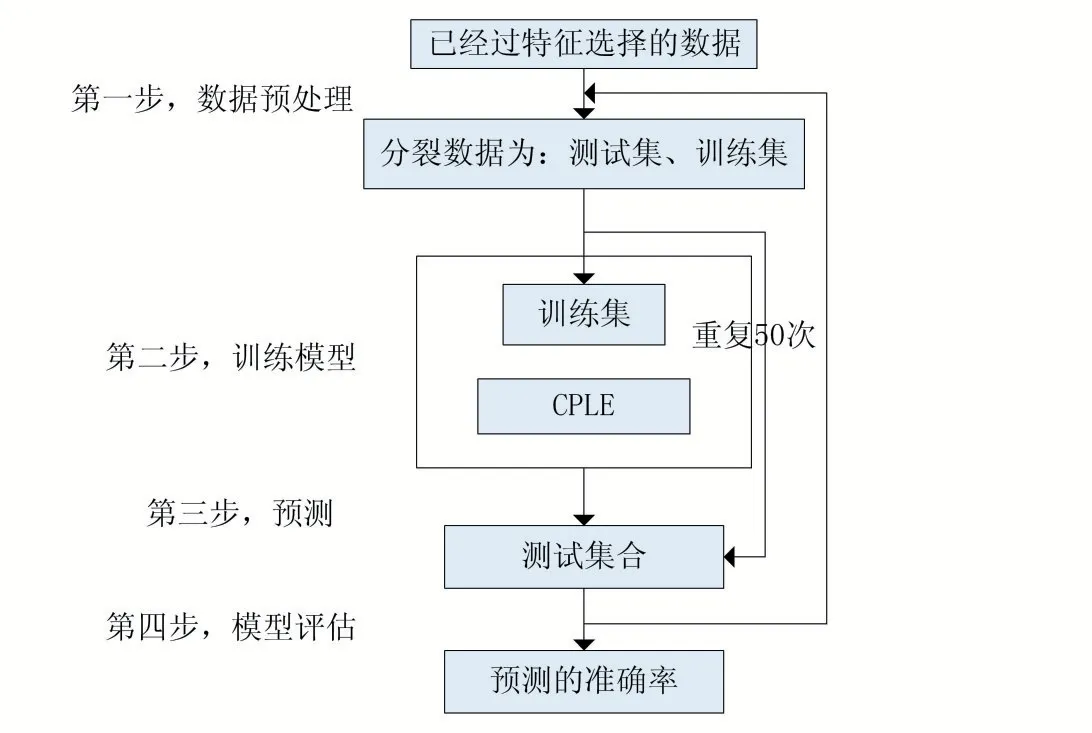
圖1 N-CPLE半監督模型
3 實驗及結果分析
3.1 實驗環境
采用最新的NSL-KDD 數據集,實驗環境為Intel i7 6700K,編譯環境為Pycharm。該方案對數據集進行歸一化處理,采用max-min 標準化法,將數據值映射到[0,1],計算方法為:

其中xcriterion是某個特征數據值標準化處理后的數據,xinitial是某個特征標準化前的原始樣本值,xmin是某個特征原始樣本中最小值,xmax是某個特征原始樣本中最大值。
3.2 實驗結果分析
分別將基于MRMD,信息增益,相關系數的特征選擇方案利用SMO、貝葉斯,隨機樹分類器,在選擇8、20、30 個特征和使用完整特征的情況下,對分類準確率進行比較。實驗結果如圖2、圖3、圖4 所示。
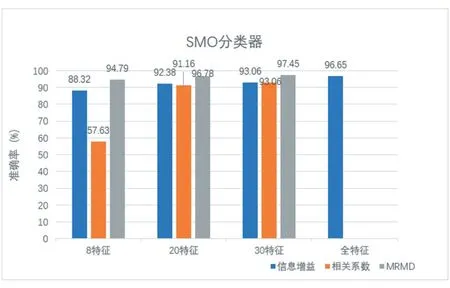
圖2 基于SMO分類器在各特征數下準確率
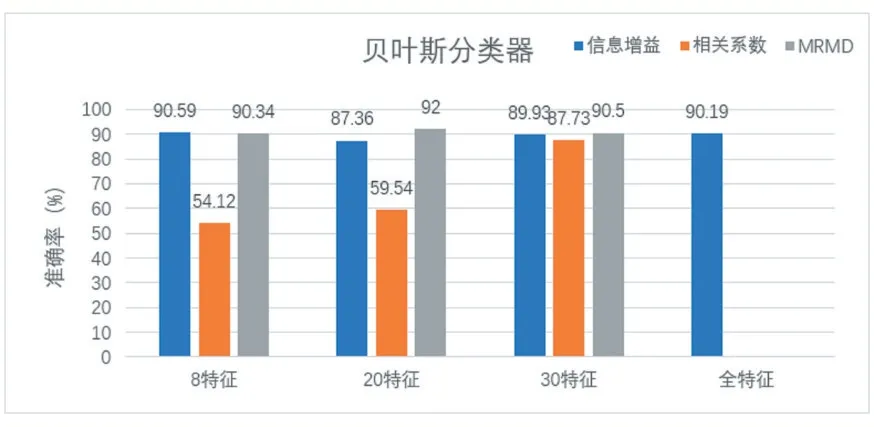
圖3 基于貝葉斯分類器在各特征數下準確率
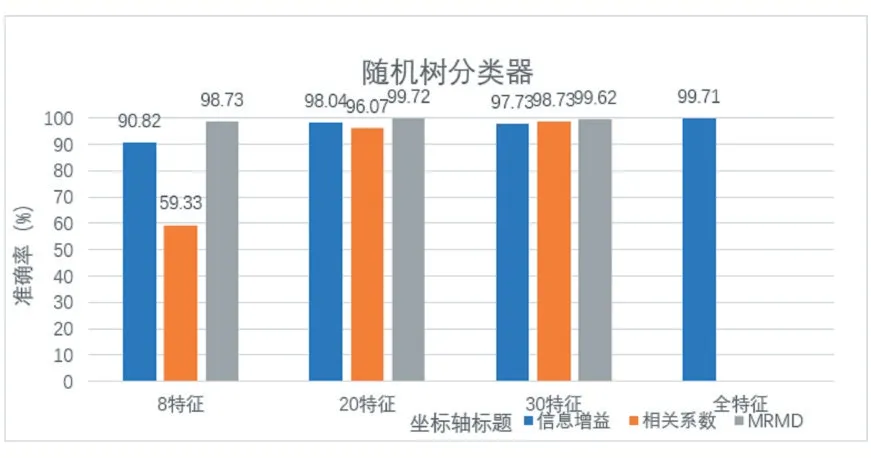
圖4 基于隨機樹分類器在各特征數下準確率
圖2 、3、4 分別表示在各種分類器下的分類準確率比較,在較低特征數時,基于相關系數的方式無法取得有效的效果。基于信息增益的方式,雖然各種特征數都有較好的分類準確率,但是分類準確率較MRMD 的方式更低,所以驗證了本方案對少量特征地選擇的有效性。
分別將基于MRMD、信息增益、相關系數的特征選擇方案利用SMO、貝葉斯、隨機樹分類器,在選擇8、20、30 個特征的情況下運行時間如表1 所示。
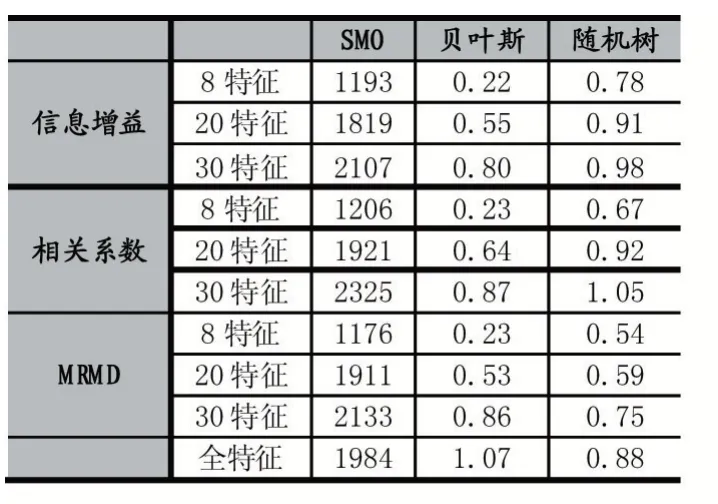
表1 各種分類器下不同特征數運行時間
在表1 中,運行時間單位為秒(s),可以看到特征數越多,運行時間越長的特點,所以在選擇少量特征時,可以達到檢測的高效率,提高檢測速度的目的。
本方案1000 次在有標記樣本和無標記樣本比分別為:1:1、1:3、1:5、1:7、1:10、1:20、1:100、1:1000 得到的準確率如圖5 所示。
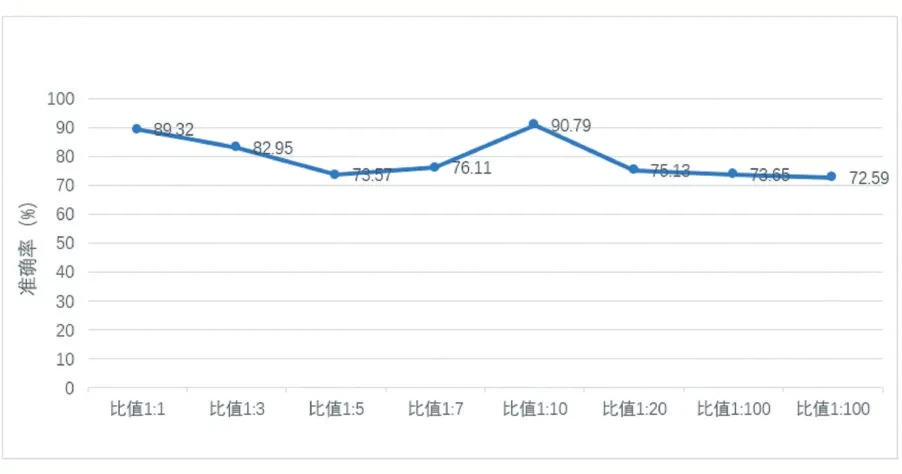
圖5 N-CPLE各比例準確率
由上圖所示,本方案并沒有隨著樣本比值的減少準確率一直下降,而是呈現一定波動,在1:1 和1:10 取得最大值。說明了本方案的有效性。并且我們將在1:10 的數據比值下進行特征選擇,得到的結果如圖6所示。
為了同時比較各特征數對準確率和運行時間造成的影響,取運行時間的1/10 在圖上表示(例如全特征運行時間為1302.4s,但是表示為130.24(十秒)。隨著特征數減少,運行時間持續減少,這是因為參與判斷的特征數量得到有效減少,從而增加了檢測速度。但是隨著特征減少,準確率先增大后減少,并且在特征數為35的時候達到高于全特征數的準確率,所以驗證了本方案的有效性,在減少特征數從而增大檢測速率的同時,對檢測準確率也有一定提高。
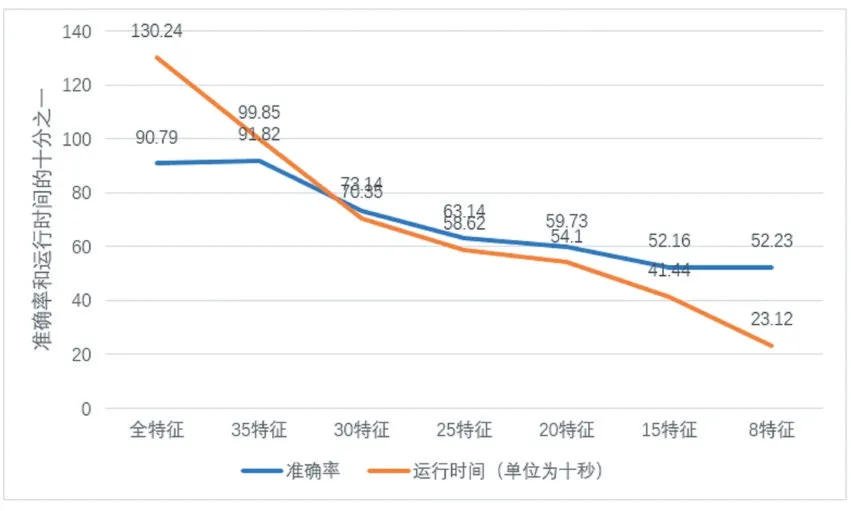
圖6 各特征數準確率和運行時間
4 結語
本文提出了一種基于相關性冗余度和半監督學習的入侵檢測方案,針對準確選擇網絡流量特征并且定性、定量分析以及缺少可靠標記流量數據而導致檢測率較低的問題,采用MRMD 特征選擇算法篩選重要特征,并改進CPLE 半監督方法,達到對未知攻擊的檢測。通過實驗對比,驗證了本方案的有效性,并且分析了不同規模數據集合和特征的選擇對檢測的影響以及檢測效率的影響。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
