基于Web的科技信息管理系統開發與管理
2019-10-23 03:20:30鄭宇
微型電腦應用 2019年10期
鄭宇
(國網福建省電力有限公司 電力科學研究院, 福州 350007)
0 引言
隨著互聯網信息技術的快速發展,通過網絡獲取科技信息以其快速便捷的優勢成為信息獲取的重要途徑之一,對科技信息管理系統的開發與實現成為研究的熱點,能夠實現科技信息的自動跟蹤管理,通過對互聯網科技信息的跟蹤與獲取,并據此完成分析與處理,便于其掌握科技信息的焦點最新動向,完成網絡信息簡報的自動生成,滿足用戶的信息獲取需求。
1 系統設計
1.1 總體架構設計
系統主要由信息管理、信息采集、數據庫等服務器構成,相互間的通信均通過互聯網實現,系統主要面向兩類用戶:普通用戶和系統管理員(按照操作權限可細分為操作員和管理員),普通用戶只有查看和下載相應文檔的權限,管理員登錄信息管理服務器可對采集任務進行創建,并將相關配置數據存入數據庫,信息采集服務器負責讀取采集任務相關配置數據后對信息進行采集和分析,再將分析結果存儲至數據庫中;信息管理服務器讀取采集任務結果后完成相關統計和展示,系統總體拓撲結構如圖1所示[1]。
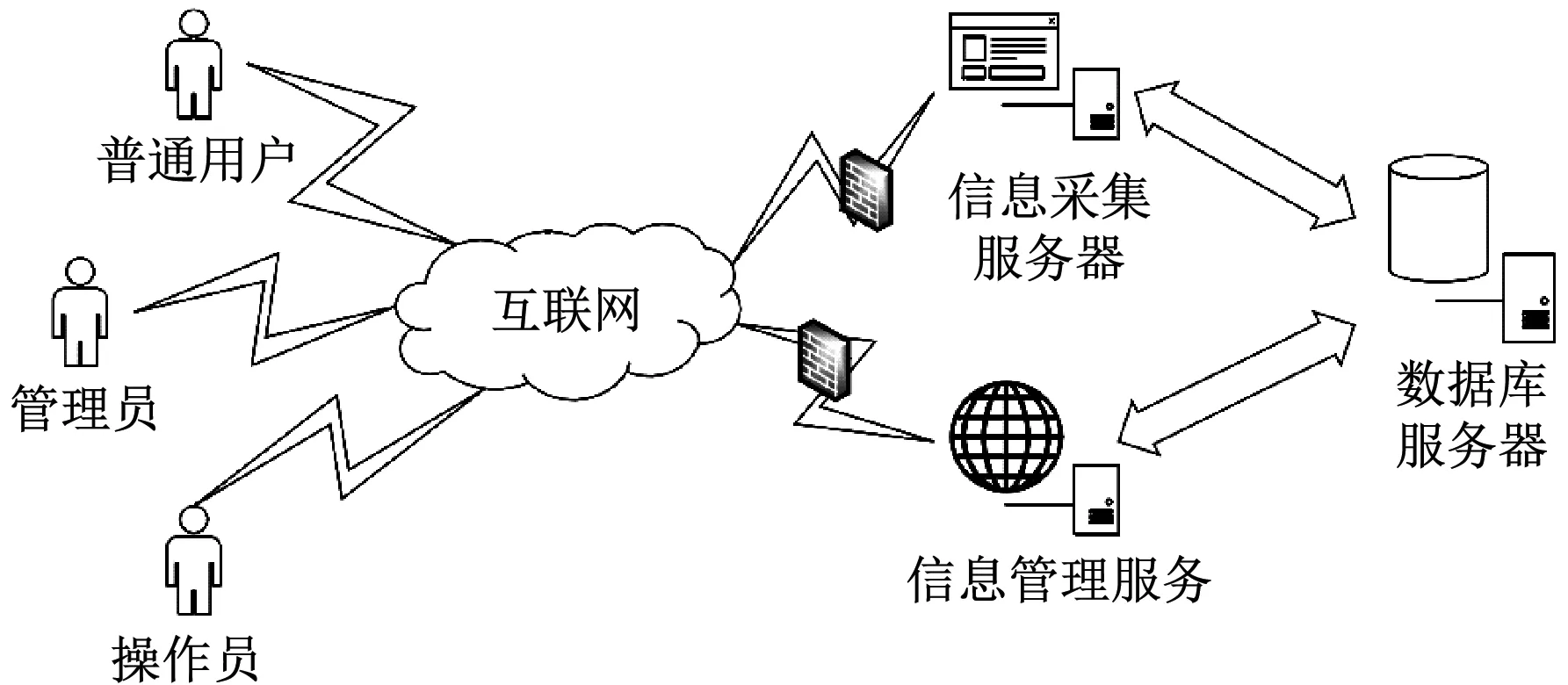
圖1 總體拓撲結構圖
1.2 功能模塊設計
系統功能主要劃分為信息采集、信息處理、信息分析、信息服務四個子系統,具體如圖2所示。
(1) 信息采集子系統
系統抓取收集指定范圍的網站內容(定向采集),支持動態內容分頁抓取(JSP、ASP、PHP、Word、PDF等),抓取信息后單獨保存為文件方式,或存儲于數據庫的字段中,采集過程中可采集部分欄目、版塊內容也可整站采集。在主流的搜索引擎中通過關鍵詞自動進行數據搜索,根據實際需要對采集的數量、狀態及開始/結束采集數據進行設置,具備添加、修改、刪除、查找站點資源數據等管理操作;對要采集的主題進行自動識別后據此完成采集任務的跟蹤,可從多角度對該

圖2 系統功能劃分
主題進行后續跟蹤[2]。
(2) 信息處理子系統
該子系統的功能在于:對不同網站站點(包括報紙類、行業用戶信息類)進行開發時可設置優先級,信息分類和管理可通過專題的設置完成(支持多級分類),根據需要對數據進行管理和維護(包括整理、編輯、刪除、新增等);按照媒體來源、版面、時間等分類整理目標媒體所收集到的信息,分類統計后生成平面媒體信息目錄;采集到的具體信息內容以平面媒體報告集萃的形式展現,可按天、月自動生成目錄或集萃;系統同時支持手動錄入后生成簡報的功能,己生成的信息簡報可進行編輯;為簡化采集配置過程,對可配置的采集模板(包括平面媒體目錄和報告集萃)進行開發,據此實現地址中指定內容的獲取;對于需要采集的站點數據可進行導入導出操作。
(3) 信息分析子系統
該子系統的功能在于:分析采集到的信息,系統自動識別出主題后進行多角度信息跟蹤具體通過聚類、熱詞(包括熱點技術、話題、事件、詞匯等)等分析方法,提取所需內容或預判其發展趨勢;在此基礎上對所采集內容按照采集時間、站點分布等進行統計,以圖表等形式展示給用戶。
(4) 信息服務子系統
該子系統的功能在于:管理系統的賬戶及權限,設置具體的信息采集熱詞;進行專題(用戶設定)采集監測及信息詳情顯示;收藏關注信息以便用戶后續使用。
1.3 整體業務功能流程
整體業務功能的運作流程如圖3所示。

圖3 信息分析過程
分別對專題采集和網站采集進行更加深入的配置說明(根據專題、詞頻出結果),包括網站(針對指定的科技網站)、專題(針對網站具體的欄目板塊,需提前設置)、和全網(針對主流的搜索引擎,如百度、搜狗等搜索引擎)三種采集方式,需指定采集的數據類型,全網采集時需指定具體關鍵詞[3]。
系統的使用效果取決于信息采集的效率,為提高系統信息采集的效率,本系統采用多線程方式完成總體信息采集框架的設計,不同操作由各線程執行(可并發執行),提高服務器對系統資源的操作效率,系統采集時支持六類線程及多個隊列數據結構,同一隊列只能由一個線程訪問通過各隊列由多個線程加鎖的方式實現,系統采集框架總體結構如圖4所示。
2 數據庫設計
以具體的數據庫支撐環境為依據,根據系統的實際需求(包括業務、功能、用戶等需求),實現最優數據庫模式的構建,從而實現對數據的有效存儲和管理工作,考慮到系統涉及的數據表較多,均衡負載的實現需采用多表分離方式,因此選用了安全高效、易操作的MySQL數據庫解決數據存儲及檢索問題,以便后續對信息進行分析統計及管理。數據庫字段的建立與完善可使查詢數據的準確性和全面性得以有效提升。

圖4 采集框架結構圖
2.1 邏輯結構設計
采集任務信息表占據核心地位,數據庫邏輯結構如圖5所示。
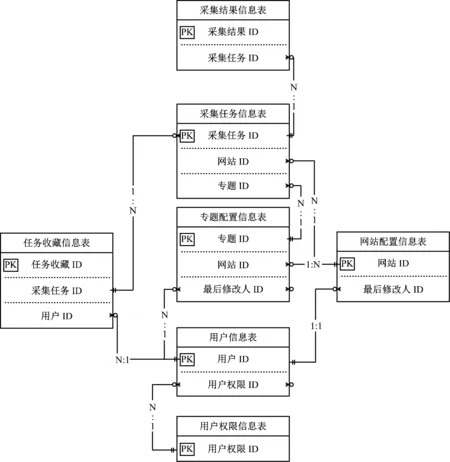
圖5 數據庫實體一關系圖
對所涉及的比較關鍵的數據庫表進行關聯設計,并依據系統功能結構設計說明了數據庫表間的關系,展示了各數據庫表的關鍵字段及表間的主外鍵關系。
2.2 數據表設計
本文完成了數據庫中各表的內部結構設計,對字段名稱、數據類型等要素進行了定義,由于涉及到的數據表較多,只對較為重要的表進行闡述,其中用戶權限信息表如表1所示,采集任務信息表如表2所示,網站配置信息表如表3所示,任務收藏信息表如表4所示,采集結果信息表如表5所示,用戶信息表如表6所示[4]。
3 系統主要功能的實現
3.1 用戶管理功能的實現
系統主要面向兩類用戶:普通用戶和系統管理員(按照操作權限可細分為操作員和管理員),普通用戶只有查看和下載相應文檔的權限;系統管理員權限最高,可對各模塊內容進行管理(包括增、刪、改、查等操作),完成采集時間權限的設置。操作員對用戶管理模塊沒有操作權限,可對自己在其他模塊中建立的內容進行增、刪、改查等操作。根據系統需求在功能實現過程中,需先確定系統中各模塊的功能,對這些功能點完成排序標號操作,并組合成對應的三種不同用戶類型后存儲于數據庫的user right表中,降低功能點的耦合度,在此基礎上將指定的用戶類型同新建用戶進行關聯匹配,實現了權限的可配置化管理,同時提高了系統的擴展性。

表1 用戶權限信息表
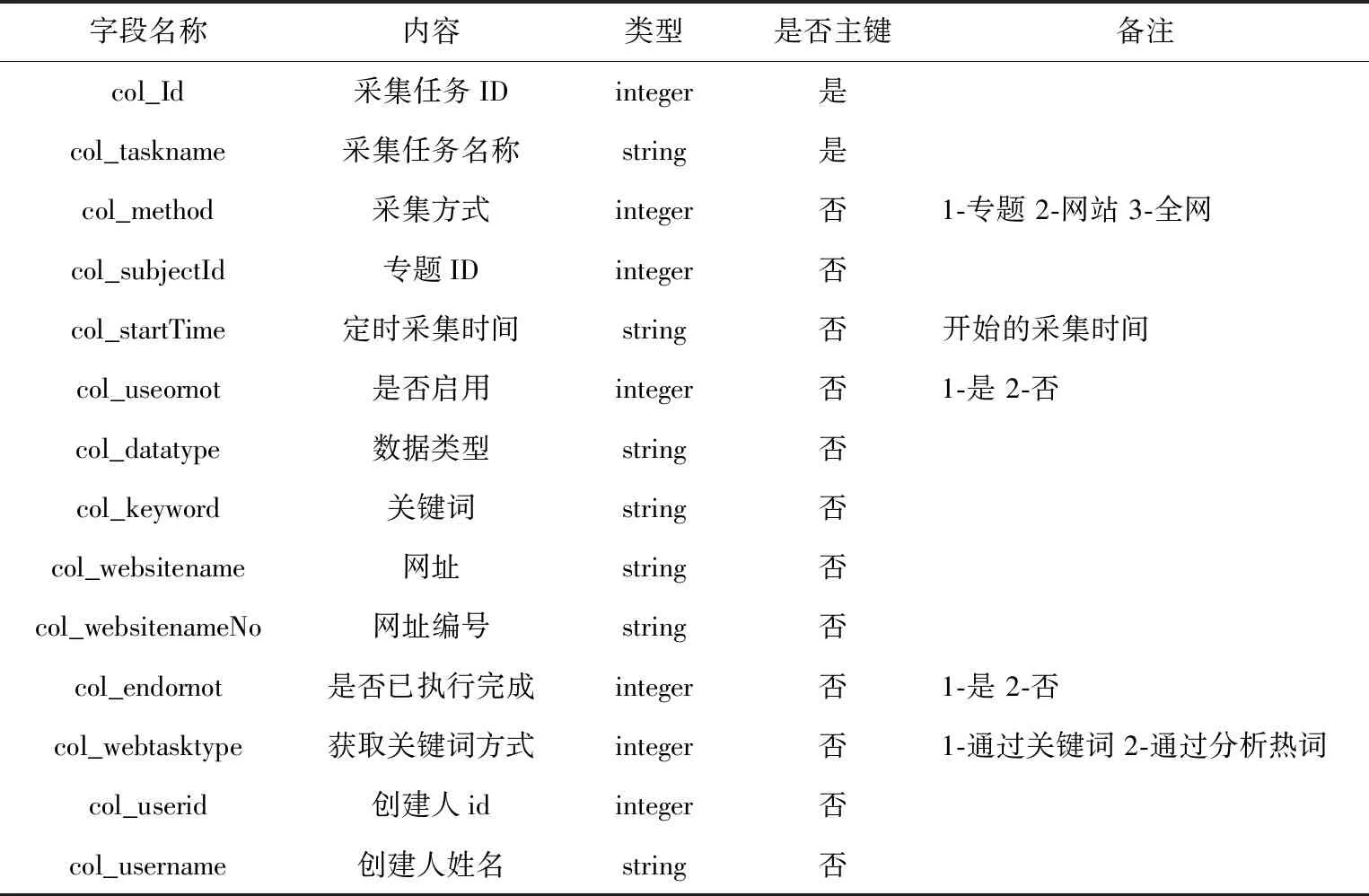
表2 采集任務信息表

表3 網站配置信息表

表4 任務收藏信息表
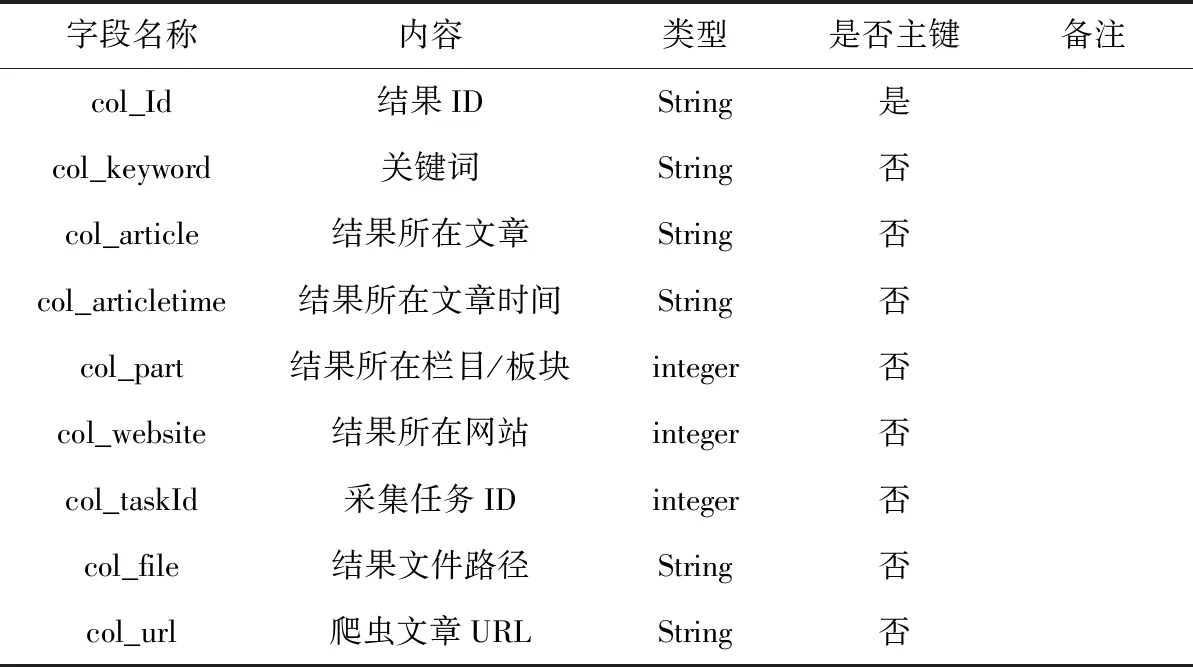
表5 采集結果信息表
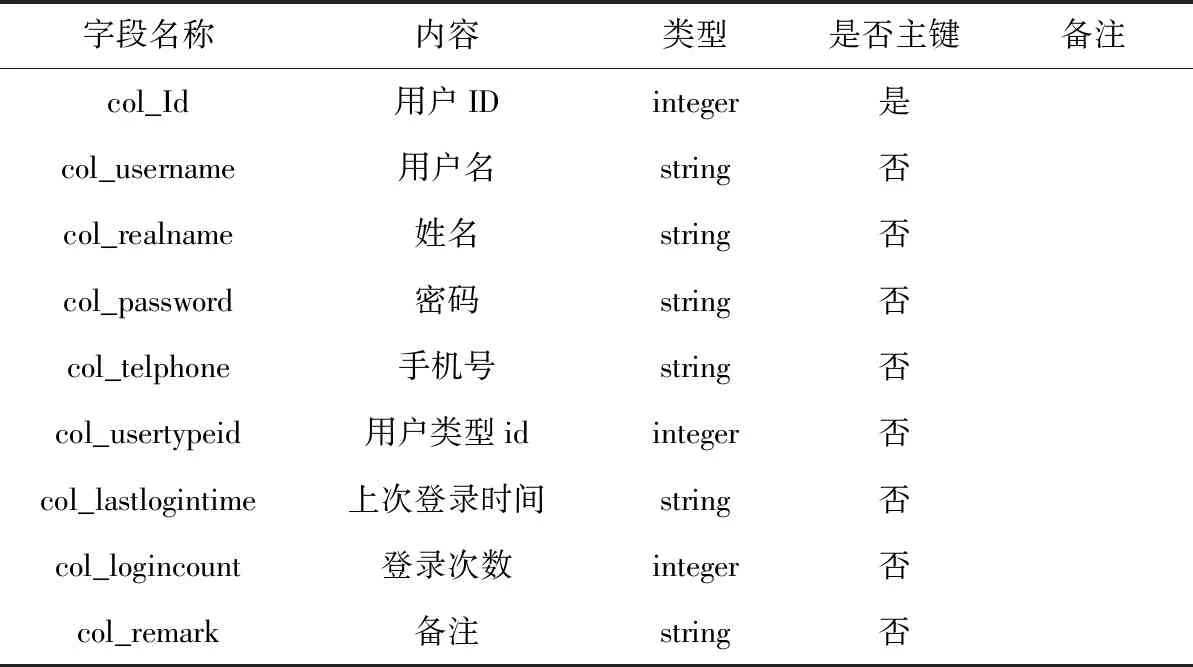
表6 用戶信息表
3.2 采集與分析功能的實現
(1) 采集網站的解析配置
對所需采集的各網站進行分析,在此基礎上完成信息的采集規則和處理流程的定義,對各科技網站在RootDir/spiders/目錄下,完成相應.pY格式配置文件的自定義,然后對相應網站的處理代碼進行編寫,采集網站各板塊URL配置的核心代碼如下[5]。
1. def parse(self, response):
2. '從給定的開始url爬取網頁,并根據取得信息確定爬取指定模塊'
3. global n_url, keywords, taskId, webType, last_keyword, now_keyword
4. switch_urls={}
5. switch_urls["1"]="http://www.bjtest.org.cn/News/List.aspx?cid=01"
6. ……
請求網頁下載功能實現的核心代碼如下。
1. def parse_content(self, response):
2. '獲取網頁內容,并調用相應Pipeline'
3. global n_url, keywords, taskId, webType, last_keyword, now_keyword
4. item=ItemLoader(item=BJTESTItem(), response=response)
5. item.add_value('url', str(response, url))
6. item.add_xpath('title_time','//td[@class="GCItemTitle"]')
7. item.add_xpath('text', '//table/tr/td/div')
8. item.add_xpath('hit_time','//table/tr[5]/td/span/text()')
9. ……
(2) 采集任務讀取
讀取時需先連接數據庫,然后編寫SQL語句,部分代碼如下:
1. def main():
2. ……
3. conn=MySQLdb.connect(host=setting.HOST, user=setting.USER, passwd=setting.PASSWD, db=setting.DB, charset='utf8')
4. cur=conn.cursor()
5. cur.execute("SELECT col_id, col_method, col_keyword, col_websitenameNo, col_useornot, col_webtasktype FROM tbl_task where col_useornot=1")
6. data=cur.fetchall()
7. ……
(3) 采集信息
解析讀取采集任務中的采集方式、關鍵字、時間間隔、網站模塊ID等,并據此開啟采集線程執行采集任務,核心代碼如下:
class Mythread(threading.Thread):
def_init_(self, name, Id, d, threadingSum):
super(Mythread, self)._init_()
self.name=name
self.Id=Id
self.d=d
self.threadingSum=threadingSum
def run(self):
with self.threadingSum:
conn=MySQLdb.connect(host=setting.HOST, user=setting.USER, passwd=setting.PASSWD, db=setting.DB, charset='utf8') #連接數據庫
cur=conn.cursor()
……
cmd="python"+setting.Hot_words+"muti.py"+str(self.d[0]).strip()
a=subprocess.Popen(cmd, shell=True)
a.wait()
end_info="TaskId:"+str(self.d[0])+"end……"
time.sleep(s)
在提取成功采集到的結果中的主要內容時,以處理html網頁為例,先根據文章位置完成正則表達式的編寫,將結構化標簽過濾掉后,對文章的主要文本信息進行提取。在RootDir/spiders/pipelines.py文件中編寫代碼如下:
1. class SDTJPTPipeline(object):
2. def process_item(self, item, spider, t_url, n_url, keywords, taskId, webType):
3. #處理網頁正文
4. pattern2=re.compile(r'', re.S)
6. pattern4=re.compile(r'', re.S)
7. text=re.sub(pattern2, "", item['text'][0])
8. text=re.sub(pattern1, "", text)
9. text=item['title'][0].strip()+r' '+text
10. path=settings.SDTJPT_path+"/"+id
11. if os.path.exists(path):
12. pass
13. else:
14. os.makedirs(path)
(4) 信息分析
在spider/HotWords中將文本中的無用符號過濾掉后,先完成系統的通用詞庫的構建,具體通過Dir/spider/words.txt文件的創建實現,然后通過Python中jieba.analyse.set_ words方法的調用實現文本中的通用詞的去除,然后再使用TextRank算法提取文本中的關鍵詞,文章標題已存放在數據庫中(信息采集階段),文章正文已存放在磁盤上(信息處理階段),對相關的文章信息(包括標題和正文)進行依次讀取,并運用TextRank算法對其進行關鍵詞分析,直到分析完所有同采集任務相關的文章后,提取五個關鍵詞(熱度最高)作為關鍵詞[6]。
4 系統測試
為檢測本文所設計的基于Web的科技信息管理系統的實用性和穩定性,采用黑盒測試法對信息采集、信息處理、信息分析、信息服務子系統的主要功能進行測試,測試結果表明系統管理員可實現對系統的有效管理,可根據實際用戶需求對信息采集的主題、時間間隔、目標站點進行設置,可從多角度對指定主題進行后續跟蹤,并且系統能夠有效實現信息采集、信息讀取、信息分析等功能,最終以平面媒體報告集萃的方式展現給用戶,系統具備良好的穩定性和可拓展性,具備較高的實用價值,為科技信息管理的系統化提供參考。
5 總結
為有效滿足科技信息管理的用戶需求,本文主要研究了科技信息管理系統的開發路徑,結合HTTP協議及WEB開發技術,完成了系統總體架構的設計,并對系統的總體功能進行劃分和詳細的闡述,在系統整體拓撲結構的基礎上,采用MYSQL數據庫完成了系統的信息采集、分析及管理過程的設計,使用Python、Javascript、HTML程序設計語言實現主要模塊的功能,設計了系統高性能的采集框架。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
中國科技論壇(2017年7期)2017-07-25 08:49:53
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
創業家(2015年5期)2015-02-27 07:53:25
