存儲容量可擴展區塊鏈系統的高效查詢模型*
2019-10-24 05:49:44賈大宇信俊昌王之瓊王國仁
軟件學報 2019年9期
賈大宇,信俊昌,2,王之瓊,郭 薇,王國仁
1(東北大學 計算機科學與工程學院,遼寧 沈陽 110819)
2(遼寧省大數據管理與分析重點實驗室,遼寧 沈陽 110819)
3(東北大學 中荷生物醫學與信息工程學院,遼寧 沈陽 110819)
4(沈陽航空航天大學 計算機學院,遼寧 沈陽 110136)
5(北京理工大學 計算機學院,北京 100081)
通訊作者:信俊昌,E-mail:xinjunchang@mail.neu.edu.cn
區塊鏈技術起源于2008 年化名為“中本聰”(Satoshi nakamoto)的學者在密碼學郵件組發表的奠基性論文《比特幣:一種點對點電子現金系統》[1].區塊鏈技術具有去中心化、透明性、開放性、自治性、匿名性和信息不可篡改等特點[2],被認為是繼大型機、個人電腦、互聯網、移動社交網絡之后,計算范式的第5 次顛覆式創新,是人類信用進化史上繼血親信用、貴金屬信用、央行紙幣信用之后的第4 個里程碑[3].區塊鏈技術為解決中心化機構普遍存在的高成本、低效率和數據存儲不安全等問題提供了解決方案[4].
但目前存在儲存擴展性較差的問題,以迄今為止最為成功的區塊鏈應用場景比特幣為例,截至2018 年5 月6 日,產生了521 534個區塊[5]、17 019 個比特幣,總容量為174.34GB.截至2017 年5 月7 日,鏈上已認證地址9 892 723 個[6],并且經過一年多大家對比特幣關注度的增加,已認證地址數量大幅提升.在區塊鏈系統中,節點有效保證區塊鏈數據安全的方法是作為完全節點保存完整的區塊鏈數據.如果目前比特幣系統中所有節點都作為完全節點,那么近1 000 萬個節點各自提供近200GB 的磁盤空間來儲存區塊鏈數據,整個系統將占用約2 000PB 的存儲容量保存200GB 左右的數據,這極大地浪費了存儲空間.在未來,區塊鏈技術將會被大規模地應用,預計到2027 年,全球10%的GDP 將會通過區塊鏈技術存儲[7].隨著區塊鏈容量的不斷增加,參與節點的存儲容量將逐漸不能滿足其存儲空間要求,這些不能滿足要求的節點就不能繼續作為完全節點保留在系統中.隨著系統中完全節點數量的減少,對區塊鏈系統的安全性必將產生影響,如:基于工作量證明(proof of work,簡稱POW)[8]機制的區塊鏈系統的總算力就會下降;基于股權證明(proof of stake,簡稱POS)[9]機制系統中的股權容易集中;基于委任權益證明(delegated proof of stake,簡稱DPOS)[10]機制的區塊鏈系統更容易被少數節點控制等.同時,如果不具備足夠存儲空間的節點不能加入到區塊鏈系統中,區塊鏈的可擴展性也會降低.因此,區塊鏈具有良好的存儲容量可擴展性是非常重要的.
目前,對于區塊鏈存儲容量可擴展性的研究不是很多,文獻[11]提出了名為ElasticChain 的區塊鏈模型,該模型在有效保證數據安全的前提下,增加了區塊鏈的存儲容量.但是在原有的區塊鏈模型中,全節點保存著完整的區塊鏈數據,在查詢數據時,全節點只需要在本地磁盤進行查找操作.而ElasticChain 模型在增加存儲容量之后,模型中的大部分節點沒有保存全部的區塊鏈數據,所以當一個節點發起查詢操作后,它將訪問系統中其他大量節點,遍歷一條完整的區塊數據.因此,ElasticChain 模型與原區塊鏈模型相比,數據的查詢效率明顯降低.同時,由于ElasticChain 模型在查詢時數據來自不同節點,系統中也存在一些惡意節點返回的虛假數據的現象,這也給數據查詢的準確度和數據的安全造成一定的影響.隨著區塊鏈技術的廣泛應用,人們對區塊鏈中數據查找速度和準確度的要求會越來越高,沒有有效的數據查詢方法,將會對未來區塊鏈技術的廣泛應用帶來巨大限制.
因此,本文在ElasticChain 模型基礎上提出一種新的容量可擴展區塊鏈系統的高效查詢方法——ElasticQM(elastic query model).ElasticQM 的框架共有4 層,分別是用戶層、查詢層、存儲層和數據層.
· 在用戶層中,包括了數據緩存、數據驗證和數據同步等模塊:數據同步模塊保證了數據的時效性;數據緩存模塊將查詢過的數據緩存在本地磁盤中,增加再次查詢該數據的查詢速度;
· 在查詢層中,ElasticQM 結合了P2P 網絡超級節點查找技術,提出了容量可擴展區塊鏈模型的全局查詢優化算法.通過建立具有高可靠性和高穩定性的查詢超級節點,在模型響應數據查詢請求時,優先訪問查詢超級節點,在保證數據安全的前提下,提高了數據查詢效率;
· 在存儲層中,模型采用基于ElasticChain 的區塊鏈模型,保證了區塊鏈數據的容量可擴展性;
· 在數據層中,我們提出了B-M tree 的數據存儲結構.該存儲結構結合了平衡二叉樹(balanced binary tree)[12]和梅克爾樹(Merkle tree)[13]的各種特點,在保證區塊數據驗證速度的同時,提高了每個區塊內的局部查詢速度,并使區塊鏈支持數據范圍查詢.
本文的主要貢獻如下.
(1)提出了一種區塊鏈存儲容量可擴展模型的高效查詢方法——ElasticQM.此查詢模型由用戶層、查詢層、存儲層和數據層共4 層模塊組成;
(2)在ElasticQM 查詢層,提出了一種容量可擴展區塊鏈模型的全局查詢優化算法,增加了查詢超級節點、查詢驗證節點和查詢葉子節點這3 種模型中的角色,提高了查詢效率;
(3)在ElasticQM 數據層,提出了一種基于B-M 樹的區塊鏈存儲結構,并給出了B-M 樹的建立算法和基于B-M 樹的查找算法.區塊鏈基于B-M 樹的存儲結構,會在區塊鏈進行的塊內局部查找時,提高區塊鏈的查詢速度;
(4)通過在不同節點可擴展區塊鏈中對不同數據量區塊進行的查詢實驗結果表明,ElasticQM 查詢方法具有高效的查詢效率.
1 相關工作
近年來,對于區塊鏈技術的研究越來越受到人們關注.首先,在提高區塊鏈中數據查詢效率方面,文獻[14]開發了基于Ethereum 的高效查詢層EtherQL.EtherQL 會自動同步區塊鏈系統中新的區塊數據,并將其存儲在專用數據庫中,以確保查詢準確性和高效性.同時,EtherQL 提供了比其他區塊鏈應用系統更高效、更靈活的數據查詢接口,并且支持對區塊鏈數據的范圍查詢和top-k查詢.在區塊鏈系統性能評價方面,文獻[15]首次提出了區塊鏈應用的評價框架——Blockbench.文獻中,Blockbench 在Hyperledger Fabric 和以太坊的兩個客戶端(Parity 和Geth)這3 個區塊鏈私有鏈平臺上,評價了每個平臺在吞吐量、延遲、可擴展性和容錯方面的性能,并做了詳細的比較和分析.并且,區塊鏈技術在未來也是計算機、數據庫領域的研究熱點.文獻[16]通過查閱大量區塊鏈系統的框架和應用情況,分析出未來在區塊鏈數據管理和分析方面的主要研究方向:區塊鏈充分利用現有成熟的數據和信息系統的方法、增強區塊鏈數據安全性和隱私性的有效方法、在區塊鏈上和區塊鏈下的數據分析方法和如何使基于區塊鏈的系統更加活躍和智能.
其次,在保證區塊鏈數據安全性方面,文獻[17]提出了基于股權證明(POS)的區塊鏈協議Ouroboros Praos.該協議通過設置安全的數字簽名和一種新型可驗證隨機函數,來保證在半同步狀態下區塊鏈的安全性.文獻開發了一個通用的基于新協議的區塊鏈模型,并通過建立隨機預言機模型進行模擬實驗,驗證了新協議的高安全性.文獻[18]提出ForkBase 數據庫存儲引擎,ForkBase 解決了在數據容易產生分叉或分歧的系統中出現的多版本、交叉語義和惡意篡改攻擊等問題.同時,文獻提出了名為POS-Tree 的管理大型數據對象的索引結構,減少了系統的存儲開銷.文獻評估了ForkBase 與區塊鏈平臺、wiki 服務和一個協作分析應用軟件OrpheusDB 等3 個具有代表性的復雜應用各自的性能,展示了Fork-Base 的可用性和高效性.文獻[19]分析了比特幣以外的區塊鏈的安全性和網絡可靠性,分析發現,Namecoin 區塊鏈系統中擁有單個礦工在數月里的計算能力超過全網的51%,這是區塊鏈系統中非常嚴重的安全隱患.因此,文獻提出了開源軟件Blockstack,在Blockstack 框架中設計了4 層架構——區塊鏈層、虛擬層、路由層和數據存儲層,避免了Namecoin 區塊鏈系統檢測出來的安全問題.文獻[20]提出了量化框架來分析基于PoW 共識機制的區塊鏈系統在不同網絡參數下的安全性.框架分析了區塊鏈系統在實際應用中存在的網絡傳播、不同區塊大小、區塊生成時間間隔、信息傳播機制以及日食攻擊(eclipse attacks)等影響系統安全性的約束.設計了應對雙重支付(double-spending)和自私挖掘(selfish mining)的最優對抗策略.
2 預備知識和問題定義
2.1 區塊鏈的區塊結構和查詢方法
目前,區塊鏈應用的主要模型架構基于中本聰的論文[1],如圖1 所示,在每個區塊中,存儲了版本號、上一個區塊的哈希值、本區塊產生的隨機數、時間戳、難度值和由交易信息生成的Merkle 樹的根.
· 版本號也是該區塊的區塊號;
· 上一個區塊的哈希值是上一個剛剛生成區塊的區塊頭通過SHA256 算法生成的哈希值,并填入到當前區塊中;
· 本區塊產生的隨機數是在區塊鏈工作量證明機制下,區塊鏈各個節點根據上一個區塊的哈希值,并通過反復嘗試來找到的符合設定哈希函數的隨機數;
· 時間戳記錄了該區塊產生的時間,標識了該區塊的唯一性;
· 難度值會根據之前一段時間區塊的平均生成時間進行調整,以應對整個網絡不斷變化的整體計算總量,如果計算總量增長了,則系統會調高數學題的難度值,使得預期完成下一個區塊的時間依然在一定時間內;
· Merkle 樹的根是由區塊主體中所有交易的哈希值再逐級兩兩哈希計算出來的數值,主要用于快速檢驗一筆交易是否在這個區塊中存在[13].當系統驗證區塊鏈中是否包含某筆交易時,只需要一個交易哈希,一個Merkle 樹根哈希和一個Merkle 路徑,實現了區塊鏈的簡易支付驗證(simplified payment verification,簡稱SPV)[21].
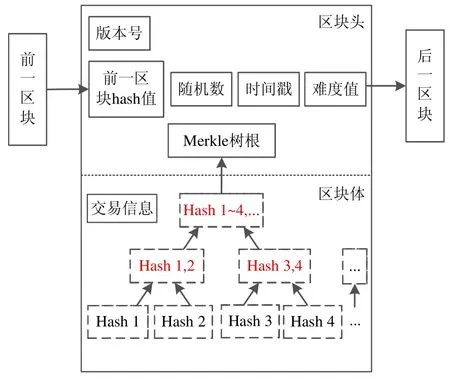
Fig.1 Structure of blocks圖1 區塊結構
因為在區塊鏈的機制中,要求每個完全節點必須存儲一個區塊鏈的完整副本.當查詢其中一條交易信息時,會在本地完整的區塊鏈副本中進行遍歷查詢.但隨著越來越多的人使用區塊鏈系統,不太可能每個人都去運行全節點,一部分區塊鏈的用戶會選擇使用輕量級錢包.輕量級錢包不會保存區塊鏈的數據,當其發起查詢請求時,需將查詢請求發送到相鄰全節點,在全節點中進行查詢操作,并將查詢結果返回給輕量級節點.
2.2 區塊鏈存儲容量可擴展模型的結構和查詢方法
目前,對于增加區塊鏈可擴展性的研究還不是很多.文獻[11]提出了區塊鏈存儲容量可擴展模型ElasticChain,將一條完整的區塊鏈副本進行分片處理,并將分片數據保存在一定比例的節點中,提升了區塊鏈的存儲容量.ElasticChain 模型首先采用了區塊鏈數據副本分片策略,計算出了安全、合適的每個分片大小和分片被存儲的副本數.然后,ElasticChain 模型增加了驗證節點對存儲數據的節點進行基于POR(數據可檢索性證明)方法的實時檢測,并記錄更新存儲節點穩定性值,依此選擇高穩定性節點來儲存新產生的數據副本,提高了數據存儲的穩定性.
如圖2 所示,ElasticChain 模型包括了用戶節點、儲存節點和驗證節點.用戶節點是原始數據擁有者,儲存節點是副本的保存者,而驗證節點是儲存節點穩定性的驗證者.一個節點可以同時具備兩種或者3 種角色.當用戶節點查詢區塊鏈數據時,需要首先訪問保存本地的P 鏈(P 鏈存儲區塊鏈數據分片存儲的位置),查找到分片數據保存的相應存儲節點.然后訪問存儲節點,將每個分片數據逐一返回到用戶節點.最后才能在返回數據中進行查詢操作.
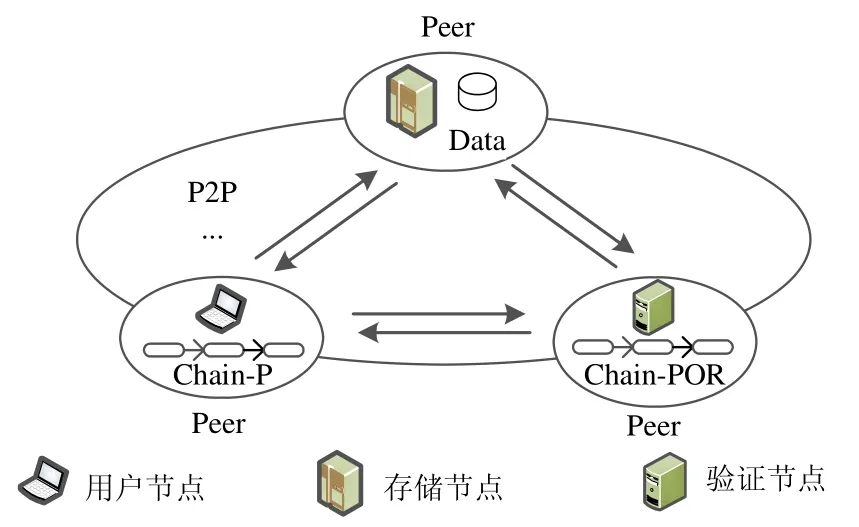
Fig.2 Structure of ElasticChain model圖2 ElasticChain 模型架構
2.3 問題定義
令S表示包含n個區塊的一條完整的區塊鏈數據集合,即S={B1,B2,...,Bn}.并且每一個區塊B被表示為元組B=〈H,K〉,其中,H表示區塊B的區塊頭信息;K表示區塊B中的交易數據,交易數據K是由m個交易組成的集合,即K={T1,T2,...,Tm}.每一個交易T被表示為一個元組T=〈V,O,N,R,E〉,其中,V表示此時交易T的版本號,O表示交易T發起者的地址,N表示交易的數額,R表示交易T接收方公鑰的哈希,E表示交易的其他信息.一個區塊中第i個交易可以表示為Ti=〈Vi,Oi,Ni,Ri,Ei〉.
本文要解決的問題是,當區塊鏈S存儲在區塊鏈存儲容量可擴展模型中,進行基于交易發起者的地址O、交易的數額N、交易接收方地址R的條件查詢查詢時,提高其查詢速度.在本文中,以對地址為Oi的節點所發起的所有交易進行查詢操作為例進行闡述說明.
3 ElasticQM 查詢模型總覽
基于ElasticChain 區塊鏈存儲容量可擴展模型,我們提出了在擴展模型上的高效查詢方法——ElasticQM.ElasticQM 查詢模型一共由4 層模塊組成,分別是用戶層、查詢層、存儲層和數據層.ElasticQM 模型架構如圖3所示.
· 用戶在發起查詢請求后首先訪問用戶層,在用戶層的緩存數據中進行查找:如果找到了相應數據,則停止查找,返回查詢結果;如果沒有在用戶層緩存中找到查詢結果,則訪問模型查詢層;
· ElasticQM 查詢層會根據容量可擴展區塊鏈模型的全局查詢優化算法找到查找到數據所在區塊;
· ElasticQM 的存儲層則是可擴展區塊鏈的基于ElasticChain 的區塊存儲方式,實現了區塊鏈數據的存儲可擴展性;
· 最后,ElasticQM 在數據層提出了基于B-M tree 的區塊數據存儲方式,提高了區塊鏈塊內查找效率.
在ElasticQM 模型中,區塊鏈系統既實現了存儲容量的可擴展性,又在不影響區塊鏈去中心化特性和安全性的前提下,實現了區塊鏈數據的全局和局部的快速查詢.
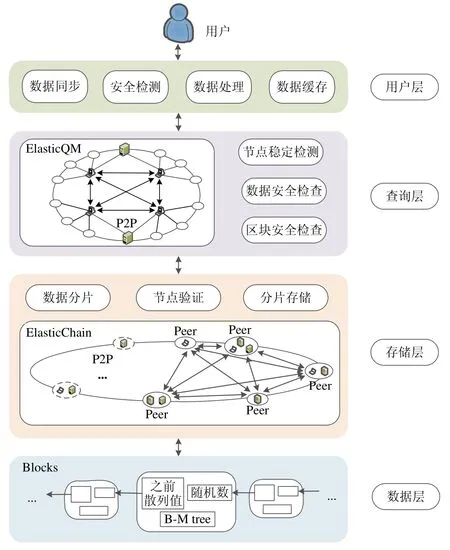
Fig.3 Structure of ElasticQM modle圖3 ElasticQM 模型架構
4 ElasticQM 查詢模型設計細節
用戶通過ElasticQM 查詢模型4 層模塊的處理,快速得到查詢結果.
· 首先,在ElasticQM 查詢層中,用戶在執行查詢操作后,ElasticQM 會與區塊鏈數據實時同步,并經過數據驗證緩存在支持SQL 查詢的數據庫中,第4.1 節將具體描述數據查詢過程;
· 然后,在ElasticQM 查詢層中,結合P2P 網絡超級節點查找技術,提出了容量可擴展區塊鏈模型的全局查詢優化算法.在算法中,將區塊鏈節點分為了查詢超級節點、查詢葉子節點和驗證節點,葉子節點在查詢數據時會優先訪問查詢超級節點,并將返回數據進行區塊安全檢驗和數據未被篡改檢驗.模型中的驗證節點實時記錄節點的穩定性,來確定是否可以作為超級查詢節點.查詢操作詳情可以在第4.2 節看到;
· 其次,在ElasticQM 存儲層中,基本采用了文獻[11]中ElasticChain 模型的數據存儲方法,實現了區塊鏈的容量可擴展存儲.但在ElasticChain 模型的節點可靠性驗證部分進行了改進.模型中,用戶節點不再存儲保存著分片存儲路徑的P 鏈,減少了ElasticChain 模型的存儲空間,存儲過程在第4.3 節詳細描述;
· 最后,在ElasticQM 數據層中,為了能高效查詢區塊鏈數據中一個區塊內的某一條數據,我們將區塊里的數據保存在了B-M tree 中,提高了每個區塊內的局部查詢速度.相關存儲過程在第4.4 節描述.
4.1 用戶層
在ElasticQM用戶層中,當一個節點發起查詢請求后,會首先訪問ElasticQM用戶層緩存數據:如果節點找到相應數據,則停止查找,返回查詢結果;如果節點沒有在用戶層中找到查詢結果,則訪問模型ElasticQM 查詢層進行查找操作.
因此,ElasticQM 在用戶層中設計了數據同步、安全檢測、數據處理和數據緩存這4 個模塊.數據緩存模塊的作用是:當用戶層在每個節點成功完成一次查詢之后,將查詢結果緩存在用戶層緩存模塊中.用戶層緩存模塊是一個持SQL 查詢的數據庫,因此在下一次查詢相同數據時,ElasticQM 就可以在SQL 數據庫中進行查找,增加了查詢速度.但是,區塊鏈數據每時每刻都在不斷地更新和變化,這就需要緩存模塊的數據也隨這不斷更新.用戶層中的數據同步模塊就會在每經過一個相同的時間段,對數據緩存模塊中的數據與區塊鏈中數據進行實時的同步和更新.在數據更新過程中,用戶層的安全檢查模塊會對新增數據進行安全檢驗,保證數據的真實性.通過安全檢測模塊的數據,才能被保存在數據緩存模塊中.而數據處理模塊則是在用戶層經過數據同步和數據安全檢測后,將區塊鏈數據處理成可以保存在SQL 數據庫中的形式.例如在比特幣交易系統中,將進行比特幣交易的買方地址、賣方地址和交易數量以表格的形式分別存入數據緩存模塊,加快下次查找速度.
4.2 查詢層
ElasticQM 的查詢層模塊接收模型用戶層發送的查詢請求,再根據查詢層中的查詢算法,在模型的存儲層快速找到相應的數據返回給用戶層.在ElasticQM 查詢層中,我們提出了基于容量可擴展區塊鏈模型的全局查詢優化算法.該算法結合了P2P 網絡中基于Super-peer 的分布式拓撲結構,將可擴展區塊鏈模型中的節點分為了查詢超級節點、查詢葉子節點和查詢驗證節點,查詢層結構如圖4 所示.
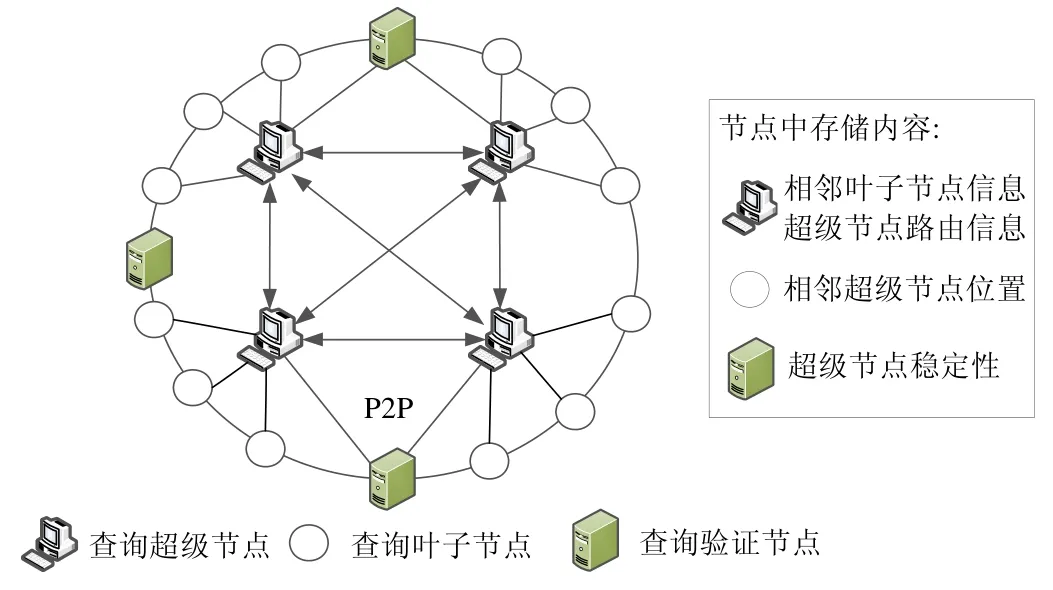
Fig.4 Architecture of query layer in ElasticQM圖4 ElasticQM 查詢層架構
模型中,查詢超級節點上存儲了系統中相鄰葉子結點的信息和超級節點間的路由信息.當進行查詢操作時,發現算法僅在查詢超級結點之間轉發,超級結點再將查詢請求轉發給適當的葉子結點.模型中,查詢葉子節點至少保存著區塊鏈每個區塊的區塊頭數據,來驗證收到的查詢數據是否被篡改,這個與比特幣錢包中的輕量級錢包相似.同時,查詢葉子節點保存著相鄰查詢超級節點位置,在查詢數據時,如果本地沒有完整的區塊鏈數據,則會優先訪問網絡中查詢超級節點.每一個新加入區塊鏈系統的節點,都會先被視為查詢葉子節點.查詢驗證節點和區塊中每個查詢超級節點和活躍的查詢葉子節點相連,實時記錄相連節點的可靠性.
查詢驗證節點會根據記錄的查詢超級節點是否出現惡意篡改區塊鏈數據來判斷超級節點的安全性,根據記錄的查詢超級節點在線時間和工作量得出超級節點的穩定性,根據記錄的查詢超級節點工作速度得到超級節點的處理能力.超級節點的工作量和工作速度通過查詢葉子節點實時向驗證節點反饋,查詢驗證節點會根據查詢超級節點的安全性、穩定性和處理能力決定其是否繼續作為查詢超級節點.同時,查詢驗證節點還會實時檢查整個區塊鏈數據,對于在區塊鏈上操作較多的活躍的查詢葉子節點,驗證節點也會記錄其節點的可靠性,作為查詢超級的候補節點.
ElasticQM 查詢層采用了容量可擴展區塊鏈模型的全局查詢優化算法,如圖5 所示.當一個節點收到查詢請求時,節點首先判斷自身是否為查詢超級節點:如果該節點不為查詢超級節點,則會訪問距離最近的查詢超級節點,然后,該超級節點根據本地保存路由信息,找到接近查找目標的超級節點;如果該節點為查詢超級節點,則直接訪問本地路由信息,找到接近查找目標的超級節點.接著,由這個接近查找目標的超級節點找到與它相連的保存著需要查找的數據的葉子節點,將查詢結果同查詢結果所在的區塊和與之相連的其他區塊的區塊頭作為最終查詢結果.最后,將最終查詢結果按查找時的相同路徑返回給發送查詢請求的節點.當最初送查詢請求的節點收到了查詢數據后,首先要通過本地保存的區塊鏈的區塊頭數據與返回數據做對比,檢驗查詢結果所在的區塊鏈沒有在查詢過程中被篡改過.然后,查詢發起節點通過對查詢結果的哈希值與查詢結果所在區塊的區塊頭哈希值進行校驗,檢驗查詢結果是在其區塊中的真實數據,未被惡意篡改.查詢發起節點會將檢驗結果返回給驗證節點,使驗證節點能夠實時地監督查詢路徑上的超級節點和葉子節點的可靠性程度.如果出現某一節點惡意篡改數據的情況,驗證節點則會減少該節點的可靠性值;如果數據查詢結果正常,則增加路徑上所有節點的可靠性值.可靠值低的節點將不能繼續作為查找超級節點,而可靠性較高的葉子節點可以成為新的查詢超級節點.
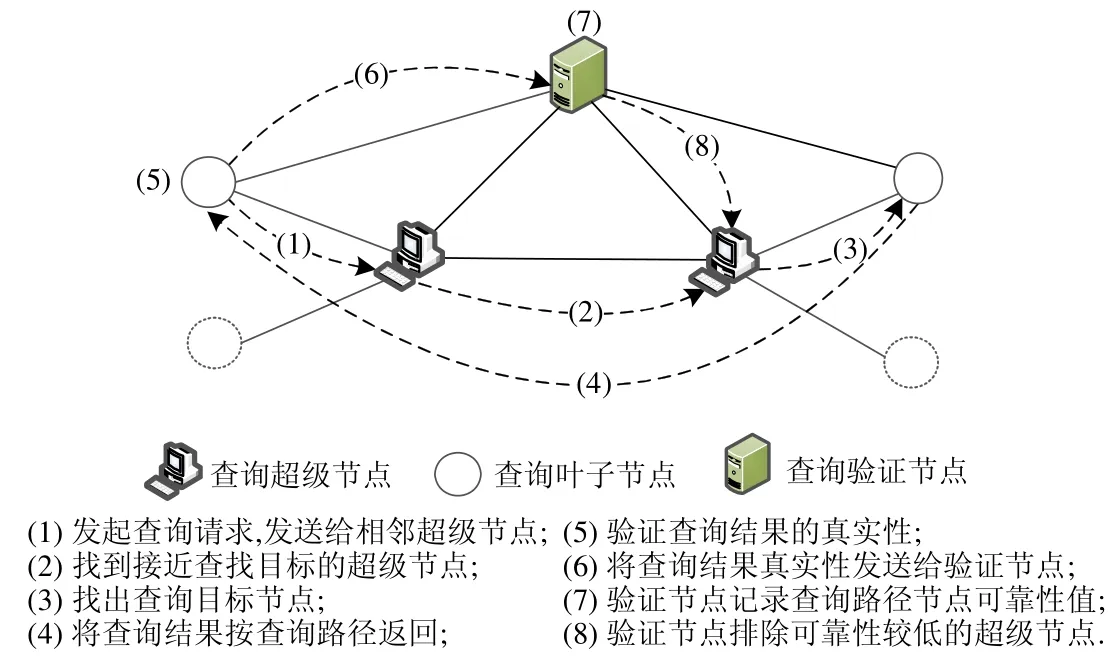
Fig.5 Global query optimization algorithm for query layer in ElasticQM圖5 ElasticQM 查詢層的全局查詢優化算法
容量可擴展區塊鏈模型的全局查詢優化算法的具體過程見算法1.
算法1.容量可擴展區塊鏈模型的全局查詢優化算法.
輸入:發起查詢節點A,查詢條件:Oi,Ni或Ri;
輸出:查詢結果,交易集合T.


ElasticQM 的查詢層模塊中,查詢超級節點只有在區塊鏈系統中發起查詢操作請求時,才會被優先訪問.查詢層的超級節點在區塊鏈數據存儲時沒有任何優先級,與網絡中其他節點相同.因此,查詢層中的超級節點不會影響整個可擴展區塊鏈系統的安全性和去中心化的特征.
在算法1 的步驟8 中,由于ElasticQM 模型中一些節點沒有保存著一條完整的區塊鏈數據,因此節點需要在訪問完整的區塊鏈數據后,才能驗證查詢結果的安全性.不在節點內存儲的區塊鏈數據,將由模型中其他節點(查詢超級節點、查詢葉子節點和查詢驗證節點)共同恢復并驗證.ElasticQM 的查詢層采用全局查詢優化算法后,避免了目前ElasticChain 模型查詢區塊數據時采用泛洪方法在系統中盲目查找的過程,減少了數據查找對區塊鏈網絡帶來的巨大處理壓力,并有效地減少了查詢所需時間,增加了查詢效率.
ElasticQM 在查詢層采用全局查詢優化算法后,同樣可以保證區塊鏈系統對數據的一致性要求.當模型中的超級節點將本地的路由信息惡意修改或丟失,附近的葉子節點將不能訪問這個超級節點或超級節點返回錯誤路徑.在這種情況下,葉子節點會訪問附近其他超級節點進行數據查詢.如果系統中存儲節點將本地的數據丟失或篡改,在查詢發起節點收到查詢結果后,會根據本地存儲的區塊鏈哈希頭的數據,對查詢結果的哈希值進行驗證.如果發起節點發現數據錯誤或不完整的情況,將會把驗證信息發個查詢超級節點,超級節點確認后,將惡意的存儲節點從路由表中刪除.因此,節點在ElasticQM 在查詢層中可以達到共識.
4.3 存儲層
ElasticQM 的存儲層響應查詢層的查詢請求,并發送請求到數據層進行數據查詢.在ElasticQM 存儲層中,基本采用了文獻[11]中ElasticChain 模型的數據存儲方法,實現了區塊鏈的容量可擴展存儲.ElasticQM 的存儲層主要包括了數據分片、節點驗證和分片存儲這3 個部分.在數據數據分片和分片存儲部分,ElasticQM 的存儲層采用了和ElasticChain 模型相同的算法,得到分片的方法、每個分片的大小和分片的副本數.但存儲層在節點可靠性驗證部分對ElasticChain 模型進行了改進:在ElasticQM 存儲層中的用戶節點完成每次數據分片存儲后,不再存儲P 鏈來記錄分片的存儲位置.其他節點的可靠性驗證過程都與ElasticChain 模型相同.
ElasticChain 模型中,用戶節點保存P 鏈數據是為了快速查詢數據,但是P 鏈占據了大量的存儲空間.經過ElasticQM 模型的改進,在區塊鏈上的查詢操作交給了模型查詢層完成,因此減少了區塊鏈模型的存儲空間,進一步增加了區塊鏈的存儲容量可擴展性.
4.4 數據層
目前,區塊鏈數據在每個塊中以梅克爾樹的形式存儲.梅克爾樹的特點是一個數據利用其生成的哈希值,可以快速地驗證是否存在于區塊鏈中.當用戶想要訪問區塊鏈中的一條具體數據信息時,對于一個完全節點就需要遍歷區塊內利用梅克爾樹存儲的全部數據.但是隨著區塊鏈應用的廣泛普及,區塊鏈中保存的數據量也會急劇增加,在一條完整的區塊鏈上進行數據查詢,效率隨之越來越慢.因此,本節提出了基于B-M 樹的區塊鏈存儲結構,既實現了梅克爾樹的特點(一個節點可以在不下載整個塊的情況下,驗證區塊中是否包含某筆交易),又提高了在一條完整區塊鏈上的數據查詢效率,并使區塊鏈支持數據范圍查詢.
基于B-M 樹的區塊鏈存儲結構結合了平衡二叉樹和梅克爾樹的的各自特點,其節點的數據結構如圖6 所示.一個B-M 樹的節點包括了數據序列化后的哈希值或合并后的哈希值(hash)、其包含所有葉子節點記錄發起者地址的最大值(max)和最小值(min)、該位置在平衡二叉樹映射節點地址(K)和指向葉子節點的左指針(L1)與右指針(R1).

Fig.6 Structure of B-M tree圖6 B-M 樹數據結構
在B-M 樹建立過程中,首先,系統確認在一個區塊產生的固定時間里寫入區塊的數據;然后,根據每個用戶地址數值的大小,建立起平衡二叉樹,保證樹中每個節點左右兩個子樹的高度差的絕對值不超過1;最后,從樹的底部開始,逐層地將這個平衡二叉樹的葉子節點的哈希值兩兩進行合并,組成新的哈希值,并同時保存著所有合并的記錄發起者用戶地址的最大值和最小值、該位置在平衡二叉樹映射節點地址和指向葉子節點的左指針與右指針.模型會不斷重復這個過程,直到合并成一個哈希值,并將其保存在區塊頭.在哈希值兩兩合并過程中,從平衡二叉樹的底部開始,左葉子節點和其父節點先做一次合并,然后將得到的合并哈希值與右葉子節點再次合并,得到父節點和左右兩個葉子節點的合并在一起的哈希值,直到合并成一個哈希值.這樣,B-M 樹的存儲結構就被建立起來,B-M 樹詳細的建立算法見算法2.
算法2.B-M 樹建立算法.
輸入:一串交易數據的數組;
輸出:B-M 樹存儲模型.


同時,我們通過舉例具體闡述B-M 樹的建立過程.當記錄發起者的用戶地址為4,7,8,10,14,20,25,30,40 時,B-M 樹的建立過程如圖7 所示.
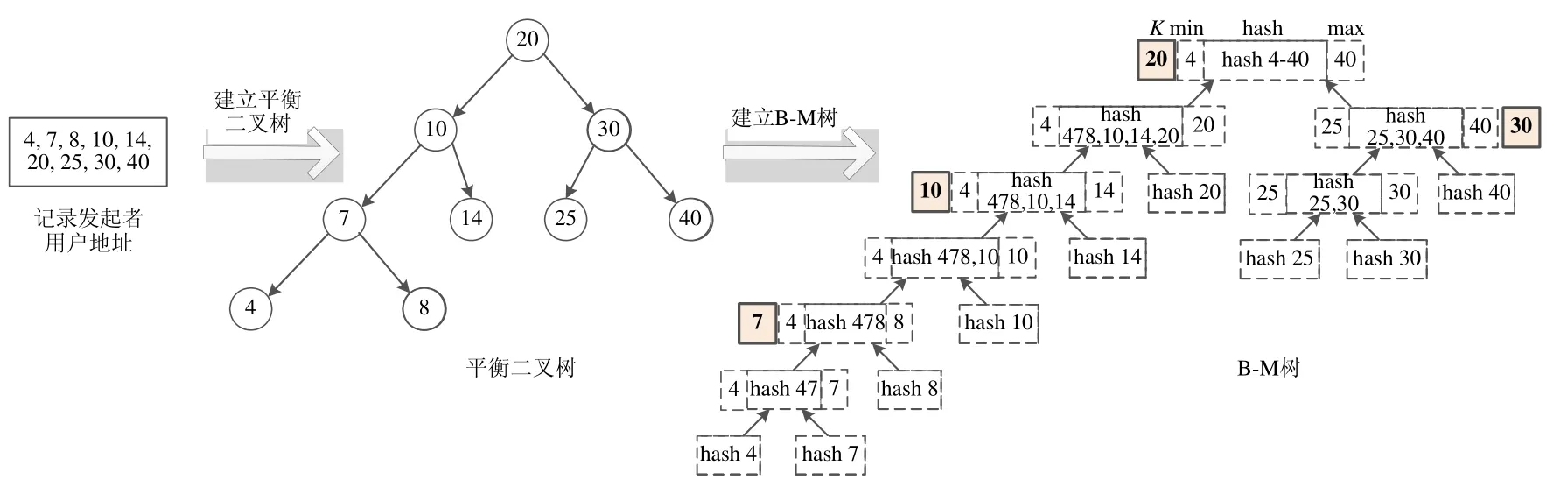
Fig.7 Establishment process of B-M tree圖7 B-M 樹建立過程
當某節點發起一個范圍查詢時,首先,如果這個節點是完全節點,則在本地查詢;如果不是完全節點,則連接一個完全節點,在這個完全節點中進行查詢.在完全節點中查詢數據時,首先從新區塊到舊區塊的順序遍歷每個區塊的區塊頭中B-M 樹的樹根,根據B-M 樹根中所有葉子節點的記錄發起者地址最大值和最小值,判斷要查詢數據是否存在于這個區塊中:如果不在樹根的最大值和最小值范圍內,則校驗下一個區塊;如果在范圍內,則根據B-M 樹中保存的平衡二叉樹映射節點地址K進行基于平衡二叉樹查找算法的搜索,直至找到相關數據,將結果返回給發起查找節點.如果搜索完整個B-M 樹還沒有找到所查找數據,則以相同方法搜索下一個區塊.B-M 樹查找算法見算法3.例如在圖7 的B-M 樹中,如果查找記錄發起者地址為8 的數據,首先從B-M 樹根節點處判斷其葉子節點包括記錄的發起者地址范圍為4~40,地址8 在其范圍內,對這個B-M 樹進行查找操作.在B-M 樹內查找時,首先訪問根節點保存的K值為20,大于8,所以向這個B-M 樹的左葉子節點進行搜索.當訪問到K值為10 的節點,地址值仍然大于8,所以繼續范圍左葉子節點,到K值為7 的節點.因為該節點K值小于所搜索地址,因此B-M 樹繼續查找該節點的右葉子節點,并訪問到了記錄發起者地址為8 的數據.最后,將查找結果返回給查找節點.當一個節點發起交易驗證時,驗證過程同目前區塊鏈系統相似.當一個節點驗證區塊鏈中是否包含某筆交易時,節點利用Merkle 樹特點,只需要一個交易哈希,一個Merkle 樹根哈希和一個Merkle 路徑,在不下載整個塊的情況下進行驗證.
算法3.B-M 樹查找算法.
輸入:基于B-M 樹的區塊鏈數據,查詢條件:Oi;
輸出:查詢結果,交易集合T.


基于B-M 樹存儲結構的區塊鏈模型,既保證了數據在區塊中可快速驗證,又充分利用二叉樹特點保證了查詢的高效性.基于B-M 樹模型與使用B+樹建立區塊內數據索引的方法相比,省略了根據索引再查找數據的過程,因此具有更快的查詢速度.
4.5 理論分析與討論
本節總結ElasticQM 查詢模型中查詢層所提出的容量可擴展區塊鏈模型的全局查詢優化算法、數據層所提出的B-M 樹建立算法和B-M 樹查找算法的時間代價和空間代價.對于區塊鏈容量可擴展模型ElasticChain,進行查詢操作時,最壞的情況是不能根據P 鏈中信息找到存儲分片數據的節點(節點故障),這樣,模型需要采用泛洪搜索算法,在區塊鏈網絡中進行搜索,這樣,搜索的時間復雜度為O(np),np為系統中的節點數.而在ElasticQM 容量可擴展區塊鏈模型的全局查詢優化算法中,查詢葉子節點通過向查詢超級節點請求,再由超級節點間進行查詢,這樣,在查詢層ElasticQM 模型的查詢時間復雜度為O(nsp),nsp為系統中的查詢超級節點數.在ElasticQM 數據層,基于B-M 樹的查找算法時間復雜度接近于平衡二叉樹為O(lognt),nt為一個區塊中的交易總數.而在 ElasticChain 模型中,在區塊內進行查詢需要遍歷區塊完整數據,查詢時間復雜度為O(nt).因此,ElasticQM 查詢模型整體查詢時間復雜度為O(nsp×lognt),ElasticChain 模型整體查詢時間復雜度為O(np×nt).在空間代價方面,ElasticQM 模型在查詢層的全局優化算法與ElasticChain 模型相同,都是基于副本分片策略進行存儲.而在ElasticQM 模型數據層,與區塊鏈和ElasticChain 模型相比增加了指針和葉子節點范圍等數據,但在一個區塊中.兩個模型空間復雜度同為O(nt),nt為一個區塊中的交易總數.
5 實驗與分析
5.1 實驗環境
實驗的開發環境為Intel Core i5-6500 3.20GHz CPU 和16GB 內存的PC 機上.利用VMware Workstation 12.5.2建立了4,8,12 和16 個節點.每個節點為內存1GB 硬盤大小為60GB 的ubuntu16.04 系統.借助IBM 開發的開源的Hyperledge fabric v0.6 版本,構建起ElasticChain 區塊鏈的容量可擴展模型.
在實驗中,我們在ElasticQM 模型、基于ElasticChain 容量可擴展區塊鏈模型和基于fabric 的區塊鏈系統上分別進行查詢操作.實驗循環運行調用chaincode_example02.go 交易代碼,每完成一次交易,會生成大小為5.39KB 的廣播消息和具有唯一標識的哈希值.在查詢一條交易或驗證交易安全性時,都可以根據生成的唯一的哈希值進行查詢驗證操作.當3 個模型分別產生127MB,635MB 和1270MB 數據時,停止調用交易代碼.
在基于ElasticChain 區塊鏈模型中,我們將數據進行基于副本分配策略分片處理,在分片時,我們設置了每64MB 數據作為一個分片,每個分片保存的副本數根據分配策略計算得出,每個分片的最小副本數為2 份.并且在ElasticQM 的存儲層,也采用相同的副本分配方法.同時,實驗分析了3 種區塊鏈模型在不同節點數下(當在網絡中共有4 個節點、8 個節點、12 個節點和16 個節點時)查詢速度的快慢.當網絡中節點數為4,8,12 和16 時,在ElasticQM 查詢層實驗設置的查詢超級節點數分別為1 個~4 個,其余節點為查詢葉子節點,每個查詢超級節點分別鏈接著3 個不重復的葉子節點,并且實驗在查詢葉子節點中隨機選取了2 個作為查詢驗證節點.
5.2 評估與結果分析
首先,實驗分析在可擴展模型上,基于ElasticQM 查詢方法的查詢效率.
實驗的查詢目標是在容量大小為127MB,635MB 和1270MB 的區塊鏈數據中,隨機抽取90 條交易記錄和10 條惡意編造的交易記錄;然后,在基于ElasticQM 和基于ElasticChain 區塊鏈模型中,對這100 條記錄進行查找操作.兩種模型在4 個、8 個、12 個和16 個節點時在總容量為127MB 區塊鏈數據中,平均查找一條交易記錄所需時間如圖8(a)所示.基于ElasticQM 和基于ElasticChain 模型在總容量為635MB 和1270MB 區塊鏈數據中,平均查找一條交易記錄所需時間如圖8(b)和圖8(c)所示.
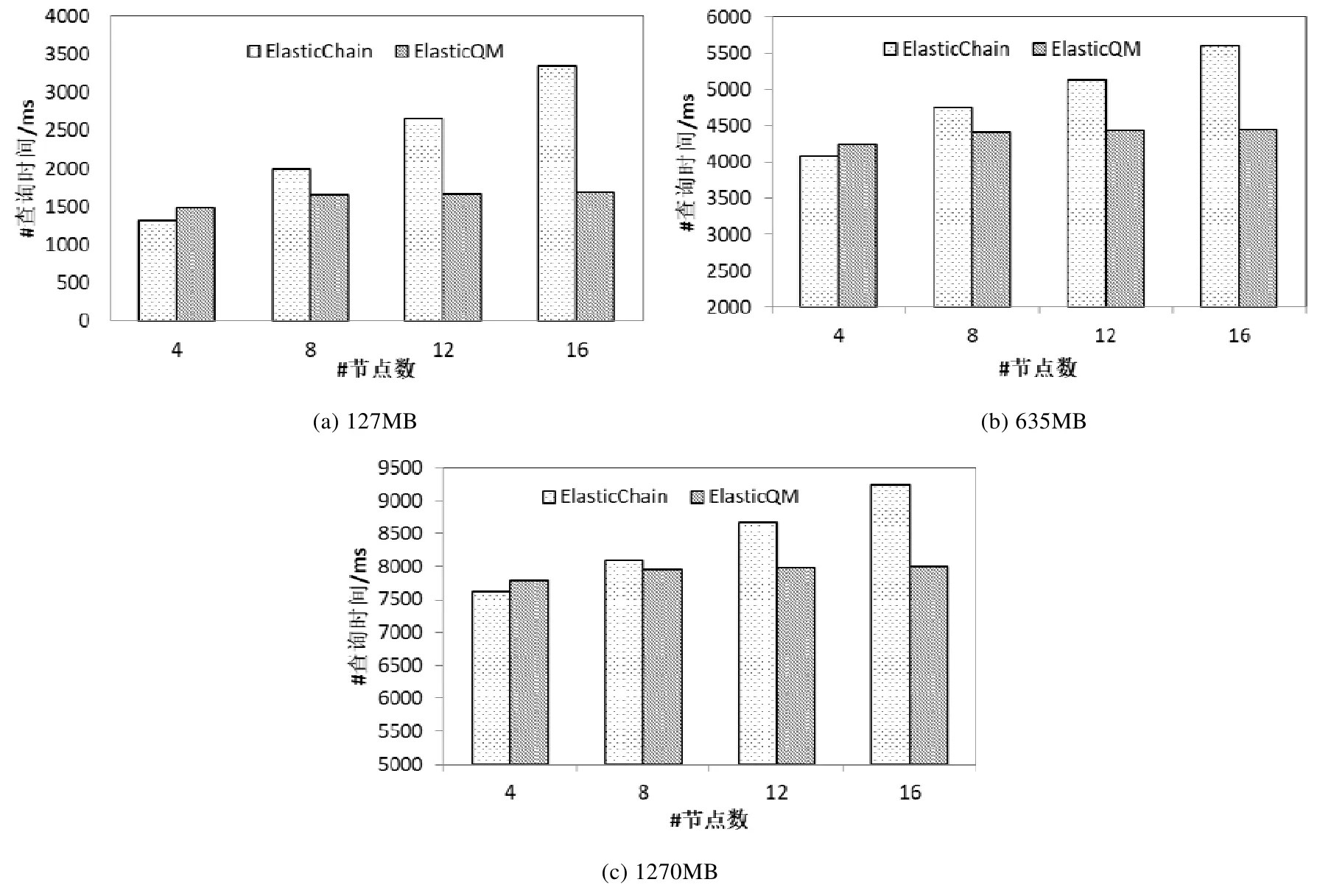
Fig.8 Queries speed for ElasticQM and ElasticChain model圖8 ElasticQM 和ElasticChain 模型的查詢速度
通過分析圖8 的實驗結果,可以得到以下結論.
(1)在相同的區塊鏈數據中進行查詢操作時,ElasticQM 模型與ElasticChain 模型相比,當網絡中節點數較少時,ElasticChain 模型的平均查詢一條記錄的速度比ElasticQM 模型略快;而當網絡中節點數較增加時,ElasticChain 模型的平均查詢一條記錄的所需時間明顯增加,而ElasticQM 模型所用的查詢時間增量較小;并且當節點數量越多時,ElasticQM 的查詢速度優于 ElasticChain 模型越明顯.這是由于ElasticChain 模型將區塊鏈數據分片存儲后,數據查詢算法會首先遍歷P 鏈數據,而當P 鏈中存儲的節點存在故障,模型就會采用基于P2P 網路中的泛洪算法,因此查詢效率較低.而ElasticQM 模型在查詢層采用了基于超級節點的查詢算法,網絡中當節點數增加后,ElasticQM 在查詢時仍然可以通過超級節點中保存的路由信息快速找到相應的數據;
(2)通過對圖8(a)~圖8(c)進行對比可以看出:如果網絡中節點數相同,當區塊鏈數據增加后,ElasticQM 模型和ElasticChain 模型在區塊鏈上數據查詢時間隨著查找范圍的擴大成比例地增加.但由于兩種模型采用副本分配策略將數據分片處理后再存儲,查詢時間開銷主要包括了在區塊鏈中查找時間和訪問存儲節點和驗證節點的時間.隨著區塊鏈數據增加,ElasticQM 模型和ElasticChain 模型節點間的通訊次數增加緩慢.因此,兩個模型與基于fabric 的區塊鏈模型相比,查詢時間增速較慢;
(3)隨著區塊鏈數據的增加,網絡中相同節點數時,ElasticQM 模型在區塊鏈數據上進行查找的時間增長的速率比ElasticChain 模型的查找時間增長較慢.因為在ElasticQM 模型的每個區塊中,數據以B-M樹的結構進行存儲,其在塊內的查詢效率接近平和二叉樹查找效率.
然后,實驗分析ElasticQM 模型所占用存儲空間的大小.
在實驗中,在ElasticQM 模型、基于ElasticChain 容量可擴展區塊鏈模型和基于fabric 的區塊鏈系統上分別存儲比特幣錢包中前一個、五個和十個區塊數據(數據大小分別為127MB,635MB 和1270MB).ElasticQM 模型的存儲層和ElasticChain 模型的副本分片策略與查詢實驗相同.當網絡中節點數為4,8,12 和16 時(ElasticQM查詢層查詢超級節點、查詢葉子節點和查詢驗證節點的設置也與上述查詢實驗相同),ElasticQM 模型、ElasticChain 模型和基于fabric 的區塊鏈系統中所有節點存儲數據的總量如圖9 所示.
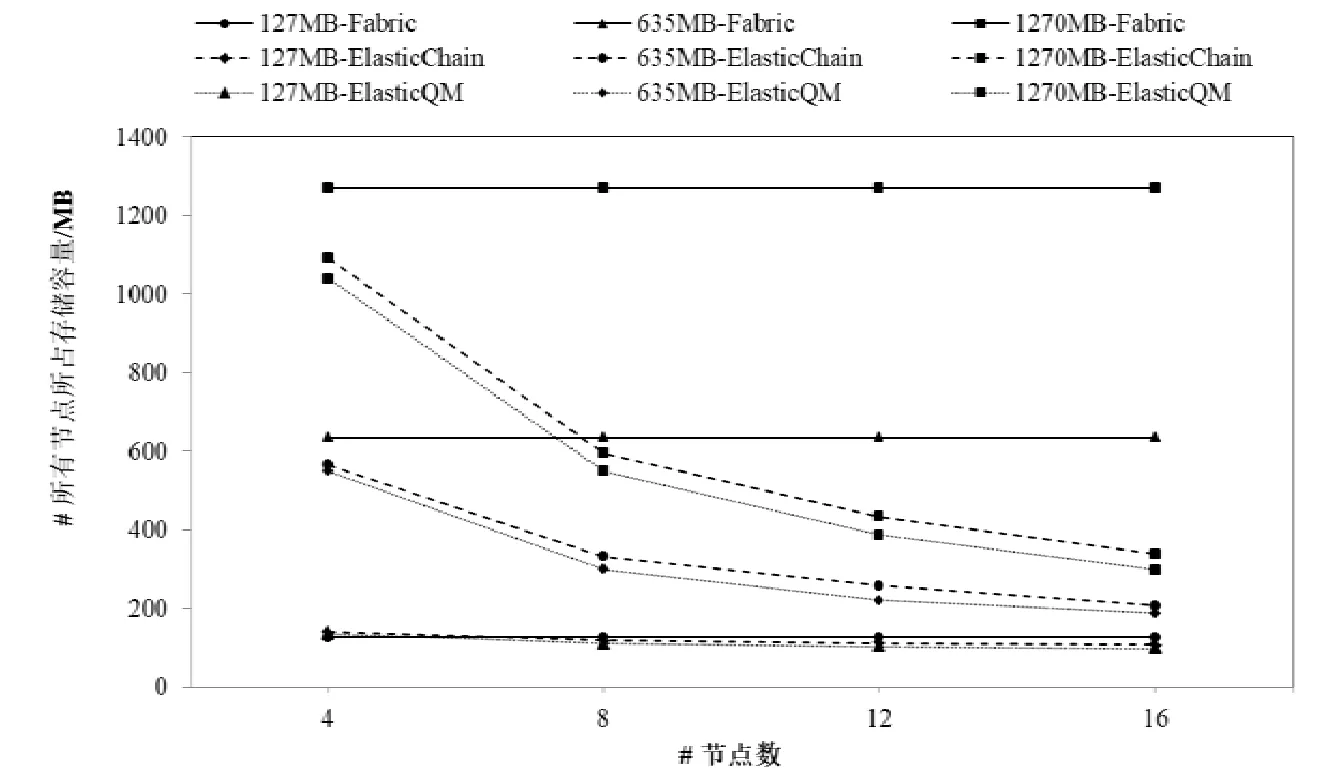
Fig.9 Storage space occupied by ElasticQM,ElasticChain and fabric-based blockchain model圖9 ElasticQM,ElasticChain 和基于fabric 區塊鏈模型占用的存儲空間總量
通過分析圖9 的實驗結果,可以得到以下結論.
(1)ElasticQM 和ElasticChain 模型的所有節點儲存總量與fabric 區塊鏈相比,在節點數較少的情況下相差不大;但當節點數增多時,ElasticQM 和ElasticChain 模型所占用的存儲空間與fabric 區塊鏈系統相比明顯減少.這是由于在實驗中fabric 區塊鏈系統節點都是完全節點,隨節點數的增加,系統存儲開銷也正比例地增加;而ElasticQM 和ElasticChain 模型采用了副本分片策略,在保證安全的情況下將數據進行了分片處理并保存,實現了區塊鏈數據的存儲容量的可擴展性;
(2)當網絡中的區塊鏈數據量較小時,ElasticQM 和ElasticChain 模型儲存總量與fabric 區塊鏈相比相差不大.這是由于ElasticChain 模型在存儲交易數據的同時,在P 鏈中保存了存儲節點位置信息,在POR 鏈中保存了儲存節點的可靠性評價信息.而ElasticQM 模型在查詢層查詢超級節點中保存了超級節點間的路由信息,查詢驗證節點存儲了各個節點的查詢穩定性,在數據層每個區塊中數據以B-M 樹的結構進行存儲,B-M 樹中記錄著發起者地址的最大值和最小值、該位置在平衡二叉樹映射節點地址和指向葉子節點的左指針與右指針,并且在用戶層增加了數據緩存模塊.這些ElasticQM 和ElasticChain 模型比目前區塊鏈系統增加的數據占據著一定比例的存儲空間.但隨著區塊鏈中區塊的不斷增加,基于實驗中的副本分配策略就會大量減少ElasticQM 和ElasticChain 模型中的存儲總量.
(3)ElasticQM 模型占用的存儲空間略少于ElasticChain 模型,但兩個模型占用的存儲空間的差距不大;并且當網絡中的區塊鏈數據不斷增加時,ElasticQM 和ElasticChain 模型儲存總量的增量趨于平緩.
6 總結與展望
區塊鏈技術是目前計算機領域的研究熱點,隨著其廣泛應用,對于區塊鏈存儲容量的可擴展有著越來越高的要求.基于ElasticChain 區塊鏈存儲容量可擴展模型,將一條完整的區塊鏈副本進行分片處理,并將分片數據保存在一定比例的節點中,提升了區塊鏈的存儲容量.本文提出一種區塊鏈容量可擴展模型的高效查詢方法——ElasticQM,將數據保存在用戶層、查詢層、存儲層和數據層模塊中:在用戶層,模型將查詢結果緩存,加快再次查詢相同數據時的查詢速度;模型在查詢層采用容量可擴展區塊鏈模型的全局查詢優化算法,增加了查詢超級節點、查詢驗證節點和查詢葉子節點這 3 種模型中的角色,提高了查詢效率;在存儲層,模型基于ElasticChain 區塊鏈存儲方法實現了區塊鏈的容量可擴展存儲;在數據層,ElasticQM 采用基于B-M 樹的區塊鏈存儲結構,并給出了B-M 樹的建立算法和基于B-M 樹的查找算法.通過在多節點不同數據量的區塊鏈中查詢的實驗表明,ElasticQM 所有節點占用存儲空間略小于ElasticChain 模型,但明顯小于目前區塊鏈模型,并且ElasticQM 的查詢效率明顯優于ElasticChain 模型.
在未來區塊鏈技術的應用中,多鏈共存將是一個普遍現象.為了解決不同體系的區塊鏈中的代幣互轉的問題,就產生了對跨鏈操作的需求.目前,主流的跨鏈技術包括公證人機制、側鏈技術和中繼技術等.但在本文的模型中,尚未對可跨鏈的區塊鏈模型的高效查詢方法進行研究.因此,在可以實現跨鏈操作的區塊鏈系統中進行高效的數據查詢,將是未來區塊鏈技術的重要研究方向之一.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
