區塊鏈數據庫:一種可查詢且防篡改的數據庫*
2019-10-24 05:49:46申德榮聶鐵錚李曉華
軟件學報 2019年9期
關鍵詞:數據庫
焦 通,申德榮,聶鐵錚,寇 月,李曉華,于 戈
(東北大學 計算機科學與工程學院,遼寧 沈陽 110169)
通訊作者:申德榮,E-mail:shendr@mail.neu.edu.cn
隨著比特幣、以太幣等一系列加密貨幣的興起,其底層的區塊鏈技術也受到了越來越廣泛的關注[1,2].比特幣最核心的意圖是為了實現去中心化,即:在沒有第三方信任機構參與的情況下,實現兩個對等實體的數字貨幣交易.然而,現實世界中不可避免地存在很多自然中心,比如提供貸款的銀行、提供電信服務的電信運營商等.雖然我們可以把這些中心機構當作對等實體,將其與用戶的交易記錄到區塊鏈上,比如用比特幣去交話費,但是這種做法是不切實際的,因為這不利于機構管理用戶數據(包括用戶的信用等級等).實際上,現有的中心機構都是由自己管理其存儲用戶相關信息的數據庫,但是這種模式存在很多缺陷:(1)不同的數據庫可能存儲著相同的用戶基本身份信息,導致數據冗余度高;(2)不同的中心機構各自管理自己的數據,不利于機構之間的數據共享;(3)每個數據庫大都由單一機構中心化管理,使得用戶必須無條件信任該機構,存在中心化問題;(4)用戶不能夠獨立驗證數據的正確性,如果數據被惡意篡改,用戶與機構都無法察覺.不僅如此,在供應鏈以及商品溯源等領域,也對數據可信性以及數據可回溯提出了新的要求.
而區塊鏈技術具有去中心化、防篡改以及可回溯的特性,為解決上述這些問題提供了可能.為此,我們提出了區塊鏈數據庫的概念,核心思想是:通過限制中心機構對數據記錄的操作,來達到防篡改和去中心化的目的.該數據庫中有多條區塊鏈,每一條區塊鏈相當于傳統數據庫中的一張表,所有的中心機構充當數據的存儲節點,所有的存儲節點根據共識算法生成區塊鏈,所有節點(包括用戶)存儲區塊頭信息,可以由區塊頭信息檢索到記錄并驗證記錄的正確性.我們希望有高效的共識算法來提高系統的吞吐率,并有高效的查詢算法實現在區塊鏈上檢索數據.當前,在共識算法上已經有很多研究,例如POW[3,4],POS[5,6],PBFT[7].然而針對區塊鏈查詢的研究相對較少,而且現有的區塊鏈系統并不能兼顧數據回溯與數據查詢.在比特幣中可以根據每一筆交易回溯前一筆交易,但是存在的問題是交易本身不易檢索.在以太坊中是狀態樹+交易樹,狀態樹存儲的是用戶賬號信息,狀態樹支持檢索,可以根據狀態樹查詢用戶當前余額,但是狀態樹本身不記錄歷史信息,不能對狀態進行數據回溯,而且狀態樹不直接關聯交易,同樣無法有效對交易進行回溯.雖然已有一些研究利用同步技術將交易數據同步到傳統數據庫,根據各數據項建立索引,從而實現快速查詢,但是這種做法并不能保證索引的不可篡改,所以損失了區塊鏈不可篡改的特性.基于此,本文提出一種不可篡改的索引結構,兼顧數據查詢以及數據回溯.
本文首先提出了區塊鏈數據庫系統框架,將區塊鏈技術應用于數據管理;其次,提出了一種基于哈希指針的不可篡改索引,根據該索引快速檢索區塊內數據,以此實現區塊鏈的查詢;最后,通過實驗測試數據庫的讀寫性能,實驗結果表明,本文提出的不可篡改索引在保證不可篡改的同時具有較好的讀寫性能.
1 相關工作
文獻[3]中,中本聰將數字簽名技術、P2P 技術、時間戳技術、Merkle 樹技術和工作量證明機制巧妙地結合起來,解決了雙花與女巫攻擊問題,實現了擁有去中心化、防篡改和數據可回溯等特性的數字貨幣系統——比特幣系統.文獻[8]中,Buterin 等人對比特幣系統進行擴展,構建了新一代智能合約和去中心化應用平臺——以太坊.除了比特幣的功能之外,以太坊還有圖靈完備的合約語言,內置的持久化狀態存儲,具有可編程性,使開發者可以很快地在以太坊平臺上創建自己的區塊鏈應用.這兩個應用都是自下而上設計區塊鏈,有內置代幣,比特幣主要應用于貨幣,而以太坊的主要功能則是智能合約.
文獻[9]中,超級賬本則采用自上而下的設計方式,去除了內置代幣,提出了商用區塊鏈框架.它采用了松耦合的設計,將共識機制、身份驗證等組件模塊化,使之在應用過程中可以方便地根據應用場景來選擇相應的模塊,除此之外還采用了容器技術,將智能合約放在docker 中運行,從而使得智能合約可以用幾乎任意的高級語言來編寫.
比特幣、以太坊和超級賬本三大應用平臺的主要功能是針對數字貨幣與智能合約,但是數據管理性能較弱,一些機構發現了區塊鏈不可篡改、去中心化與數據可回溯特性,力圖將區塊鏈技術與傳統的數據庫技術相結合,提升數據管理的性能,同時兼顧區塊鏈去中心化、數據可回溯、防篡改的特性.
文獻[10]中,Dinh 等人受區塊鏈鏈式結構以及Git 版本控制的啟發,為每個key創建設計了一個有向無環圖,圖中每一個節點對應key的某一歷史版本,節點的前驅后繼分別對應其版本的前驅后繼,在保證高擴展性和高吞吐率的同時,實現了數據可共享與不可篡改的特性.文獻[11]中,BigchainDB 將區塊鏈技術與RethinkDB 相結合,在企業級分布式數據庫的基礎上添加區塊鏈不可篡改和去中心化等特性,提出了一種基于管程的一致性策略,提高了數據的安全性,同時解決了區塊鏈的數據存儲容量問題.文獻[12]提供了基于區塊鏈的加密存儲網絡,通過將原始數據加密并簽名后,保存到P2P 文件系統中,用戶可以對數據的完整性進行驗證.文獻[13]中,Tuan 等人提出了一種區塊鏈測試框架,包括針對區塊鏈應用的一致性算法、數據模型、執行引擎和鏈上應用的測試方法,并且分析了以太坊、超級賬本、Parity 以及UStore 的讀寫以及查詢能力,對于區塊鏈的設計以及瓶頸發現和解決帶來了極大的幫助.文獻[14]中,Tsai 等人總結了基于區塊鏈的應用開發方法,給出了開發區塊鏈應用時需要注意的關鍵問題,設計并實現了”北航鏈”.文獻[15]中,Li 等人提出了一種高效的檢索區塊鏈的方法,包括范圍查詢和Top-k查詢,有較好的靈活性.但是其解決方法是通過把區塊鏈數據以及k-v數據庫里面的數據同步到MongoDB 數據庫中,利用MongoDB 進行查詢操作,沒有從根本上解決區塊鏈的查詢問題.為了將區塊鏈技術應用于數據存儲,ChainSQL[16]將數據庫操作日志存儲于區塊鏈中,將數據存儲于附屬關系型數據庫中,在底層支持SQLite3,MySQL,PostgreSQL 等關系數據庫,可以根據區塊鏈里的日志記錄將數據庫表恢復到任意時刻點,但是其恢復粒度是以表為單位,不利于以交易為單位的數據溯源.
2 區塊鏈數據庫系統框架
通過結合區塊鏈和數據庫技術,提出一種去中心化、防篡改同時支持查詢的區塊鏈數據庫框架.如圖1 所示,分4 層,具體如下.
· 存儲層:在最底部,為k-v數據庫,負責分布式存儲數據,為每一個區塊鏈備份多個副本;
· 網絡層:是該框架的核心,負責節點間的數據傳輸以及根據共識協議確定區塊的先后順序.其中,節點由存儲節點以及用戶組成,每一機構為一個存儲節點,用于存儲本機構的數據信息,可以是一個數據庫,也可以是多個數據庫.當添加或者修改用戶相關的數據時,需要由用戶和機構共同簽名認可;簽名后的數據由機構封裝到區塊中,當區塊大小達到某一閾值時,將其打包發送給其他機構進行驗證.機構間根據共識算法驗證區塊的正確性,并決定區塊的先后順序.將驗證正確的區塊發送給存儲節點存儲,將區塊頭廣播給所有節點,包括用戶.在進行查詢操作時,用戶向存儲節點發送查詢請求,存儲節點會返回查詢到的記錄項以及查詢路徑,用戶根據查詢路徑以及區塊頭信息,可以驗證查詢結果的正確性;
· 區塊鏈層:顯示的是區塊鏈的“世界狀態”,上層應用可以據此對區塊鏈數據進行查詢操作;
· 應用層:是最上層,可以對查詢到的數據進行進一步的分析處理.
針對這一框架,本文重新定義了數據庫中的數據結構以及數據操作,并提出了Merkle RBTree 索引,基于哈希指針構建不可篡改的索引,在保證不可篡改的前提下實現高效查詢.系統中數據的操作定義如下.
· 增加記錄:數據在初次添加時,數據擁有者指定可以進行數據寫操作的公鑰,生成權限鎖定腳本,然后用自己的私鑰對該數據進行簽名;
· 修改記錄:操作者用自己的私鑰對其父記錄進行簽名,然后驗證該簽名是否能夠解鎖父記錄的鎖定腳本,當且只當在解鎖鎖定腳本的情況下,才可以添加一條相同key值的記錄,以此實現對父記錄的修改.其中,權限鎖定腳本只有數據擁有者可以修改.需要說明的是,數據修改與數據防篡改并不沖突,本文中的防篡改指的是對應版本的數據不可改且數據的更改歷史不可改,但是支持數據從較老版本更新到新的版本;
· 查找記錄:所有的參與者都可以進行查找操作,查找操作返回最新值為有效值,但是可以通過溯源操作查看該記錄的完整修改歷史;
· 刪除記錄:數據一旦添加便不可刪除,當數據已經被修改多次,處于非常古老的版本時,為了節約磁盤空間,可以刪除該數據的具體信息,但是該數據的哈希值則需要永久保存.
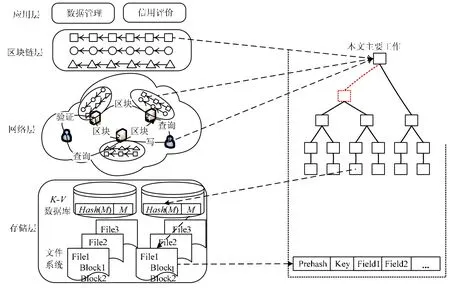
Fig.1 Blockchain database system framework圖1 區塊鏈數據庫系統框架
3 區塊鏈式數據模型
3.1 已有的區塊鏈系統模型
(1)數據結構
為了能夠較好地理解區塊鏈的結構,我們給出了哈希指針的定義.一個數據項的哈希指針是指將該數據項的內容做哈希操作后得到固定長度的哈希值,同時以該哈希值為key,該數據項的內容為value,將此k-v對存儲于k-v數據庫,則該key即為該數據項的哈希指針.
區塊鏈就是一個個的區塊根據哈希指針首尾相連,每一個區塊一旦形成便不可改變.如圖2 所示,區塊分為區塊頭和區塊體兩部分:區塊頭包括版本號、前一區塊哈希指針(由前一區塊頭數據哈希得到)、區塊形成時的時間戳、區塊體中交易自下而上哈希得到的Merkle 根以及用于工作量證明的隨機數和目標哈希;區塊體中保存著區塊中的所有交易記錄.
如圖3 所示,交易(transaction)包含版本號(nVersion)、交易輸入(TxIn)、交易輸出(Txout)以及交易時間(nLockTime).其中:交易輸入包含其要花費的交易輸出(preout)以及鎖定腳本(ScriptSig),并且當且僅當SicriptSig是上一個輸出中ScriptPubk 對應的私鑰簽名時才被認為是有效的;交易輸出指定該筆交易的輸出金額(nValue),以及收款人的公鑰(ScripPubk).數字簽名技術[17]保證每筆交易被支付到一個公鑰里,然后只有擁有私鑰的人才能花費掉這筆交易.
(2)數據讀寫流程
對于數據的存儲管理,在寫入數據時,每個區塊的數據操作流程如下.
1)收集交易.將未寫入到區塊內的交易數據進行正確性檢查(包括格式檢查以及雙花檢查),并將有效的交易數據收集在集合(MapTransaction)中,其中,MapTransaction 只存放在內存中,其內存放了從交易哈希到交易的map 映射;
2)創建區塊.將MapTransaction 中的數據添加到區塊體中;之后運行PoW 機制,搜索合適的隨機數值,使得區塊頭的哈希值小于目標哈希,從而證明該區塊有效,即挖礦成功并獲得獎勵;
3)存儲區塊.在網絡上將該區塊廣播,在本地將該區塊順序存儲在本地磁盤文件(blk000x.bat)中;
4)更新區塊索引(CblockIndex).在k-v數據庫中更新CblockIndex,CblockIndex 記錄著區塊的磁盤存儲位置以及該區塊的前驅和后繼區塊,根據區塊索引,能夠得到區塊鏈的世界狀態;
5)更新交易索引(TxIndex).TxIndex 存儲在k-v數據庫中,包含每一筆交易的磁盤存儲位置以及交易的后繼交易(以該交易作為輸入的交易).后繼交易初始為空,標識該交易是未花費的,當該交易被花費后更新其后繼交易,也是根據該標識位判斷交易是否被雙花;
6)將寫入到磁盤的交易數據從MapTransaction 中移除.
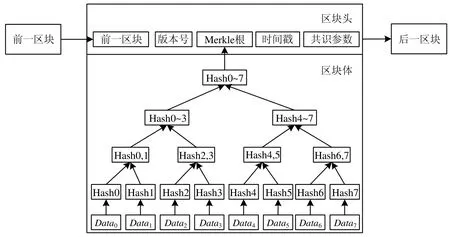
Fig.2 Block structure diagram圖2 區塊結構示意圖
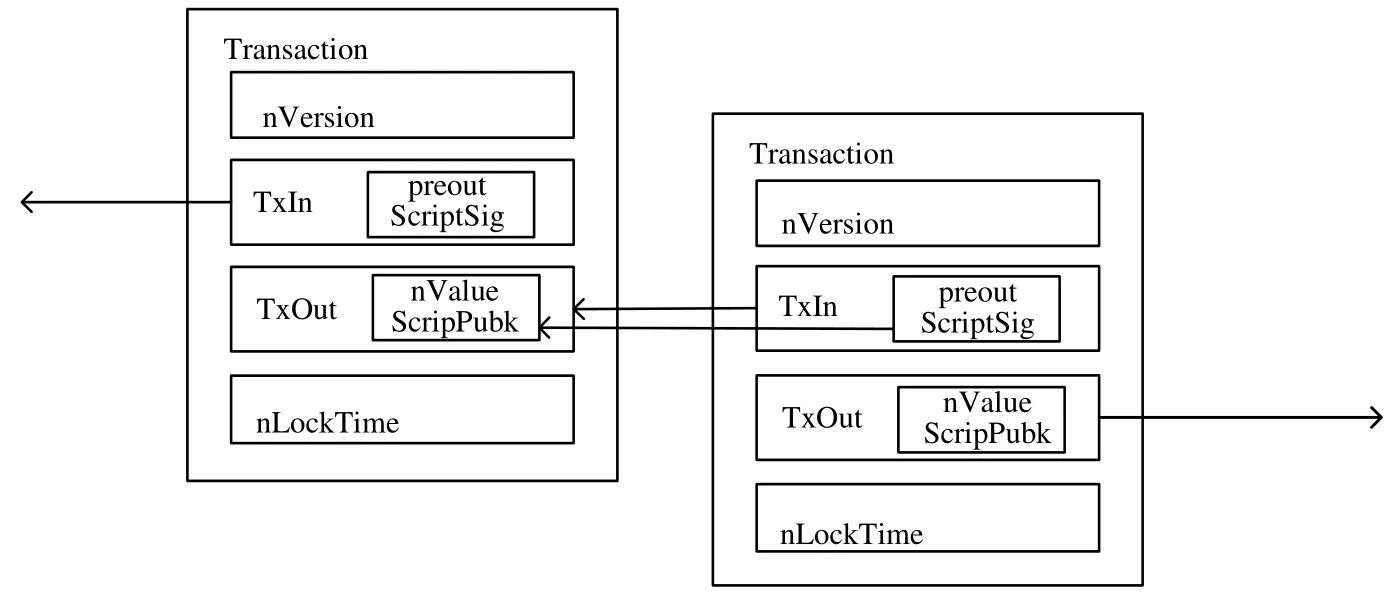
Fig.3 Transaction structure diagram圖3 交易結構示意圖
在讀取數據的時候,必須要提供要讀取數據的hash值,根據hash值,先在內存中的MapTransaction 中查找;如果沒有查找到,則根據hash值到k-v數據庫中查找對應索引信息TxIndex;最后,根據TxIndex 在磁盤文件blk000x.bat 中讀取到數據.
(3)已有模型存在的不足
已有的模型利用數字簽名技術以及MerkleRoot 來保證數據不可篡改和數據安全,但是其交易數據結構固定,只能處理固定結構的交易數據,不能處理一般數據,不適合傳統數據庫中的數據處理,缺少一般性;在進行數據讀寫操作時,只能夠根據數據的hash值進行處理,在不知道數據hash值的情況下,無法進行數據查詢操作.
3.2 面向數據庫的區塊鏈系統模型
針對已有模型中的不足,本文提出一種面向數據庫的區塊鏈系統模型,將交易結構擴展到任意記錄格式,為每一個區塊創建一個不可篡改的索引,在保證不可篡改的同時實現高效查詢,為數據的所有者賦予新的語義,并重新定義數據操作.
(1)數據結構
為了能夠操作更一般的數據,本文將交易結構進行了擴展,如圖4 所示,交易分為交易頭(transaction)和數據(data)兩部分:交易頭包含版本號(version)、父交易哈希(PreHash)、交易時間(nTime)、交易下一擁有者公鑰(ScriptPubk)、證明本交易有效的簽名(ScriptSig);數據部分類似于傳統數據庫中的表結構,包含關鍵字key以及各個字段(field).根據交易頭部分實現數據的權限管理以及不可篡改和可回溯,根據數據部分記錄各種類型的數據.其中,PreHash 指向相同Key 的前一交易.在進行寫入數據的時候,首先查詢是否存在關鍵字為key的交易:如果存在,則檢驗當前交易的SicriptSig 是否與前一交易的ScriptPubk 相匹配,只有在匹配的情況下,才認為交易有效;如果該key是第1 次出現,則將PreHash 置為0.在進行數據讀取的時候,根據key進行檢索,返回最近的查詢結果,但是可以根據交易中的PreHash 進行溯源.數據的修改通過寫入新交易實現,所有的記錄都不可刪除.
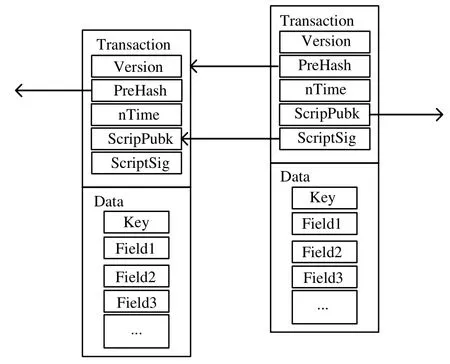
Fig.4 Database-oriented transaction structure圖4 面向數據庫的交易結構示意圖
區塊結構與已有的大體類似,特別之處是在區塊的MerkleTree 中添加了關于交易key值的索引信息,使得可以從MerkleRoot 根據key值直接檢索到對應交易,實現了交易的可查詢性;同時,索引是經由Hash 運算保存在Merkle 樹中,保證了索引的不可篡改.
(2)數據讀寫流程
為了實現針對于key的查詢,寫入數據時,在每一個區塊中創建一個關于key的不可篡改索引,并將該索引記錄保存在k-v數據庫中;在讀取數據時,根據key從區塊頭的MerkleRoot 開始索引,在O(logN)時間內索引到交易的hash值,然后根據該hash值到k-v數據庫中查詢到對應的TxIndex,最后,在磁盤文件blk000x.dat 中讀取交易信息.
4 數據操作算法
4.1 Merkle RBTree索引構建
區塊鏈數據庫要求其數據滿足不可篡改性,則對于數據的索引自然也應該是不可篡改的.我們定義區塊一旦形成便不可修改,因此,我們對于每一個區塊構造一個二叉查找樹,然后將數據與二叉查找樹一起做哈希運算,從而實現數據與索引的不可篡改.
我們選擇紅黑樹和Merkle 樹結合,選擇紅黑樹有以下幾個原因.
1)紅黑樹是二叉查找樹,同時也是平衡二叉樹,雖然不是完美平衡,但是能夠保證查詢復雜度為O(logN);
2)和Merkle 樹一樣,紅黑樹是由下往上生長的,從而能夠保證父節點是由子節點哈希得到的,在插入新節點時,父節點信息可以得到相應更新.
然而,傳統索引中的記錄值并不是全部存儲在葉子節點,其內部節點也都存儲著記錄值.然而這會在兩個方面影響Merkle 樹的性能.
1)不利于輕量級存在性證明.
如圖5 所示:如果輕量級節點持有MerkleRoot 即H11以及記錄信息Data4,我們想證明Data4是否存在于這棵樹中.我們直接將序列{H3,H7,H9}發送給該節點,該節點計算Hash(Hash(H7,Hash(H3,Hash(Data4))),H9),如果得到的值等于H11,則證明Data4存在于這棵樹中;否則不存在.其實,存在性證明就是通過將孩子節點兩兩哈希得到父親節點,通過判斷父親節點是否相同來驗證孩子節點的正確性.這就要求我們可以由孩子節點哈希得到父親節點,但是如果父親節點存放了與孩子節點無關的記錄,我們便無法根據孩子節點哈希得到父親節點,也便無法進行存在性證明;
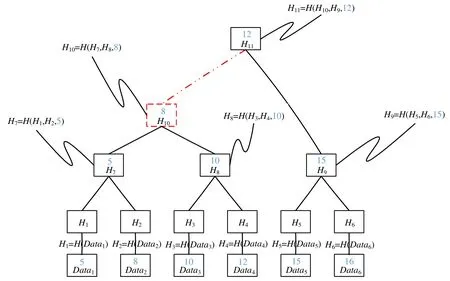
Fig.5 MerkleRBTree logical structure圖5 MerkleRBTree 邏輯結構圖
2)不利于分支刪減,不能節省磁盤空間.
考慮到這樣一種情景:Data1,Data2,Data3,Data4已經被修改過多次,而Data5,Data6則很少被修改,根據第2節對于修改記錄的描述可知:前面4 個數據項已經有了很多后繼,相當于非常久遠的版本;而后兩個數據項還是屬于較新的版本.我們希望可以刪除Data1~Data4但是不影響后續對于Data5,Data6的查詢驗證等操作.如果數據項都存在葉子節點,我們可以通過刪除Data1~Data4只保留H10來節省磁盤空間而不影響樹的功能;但是如果有數據記錄存放在分支節點,我們便無法刪除分支節點來節省磁盤空間,因為那樣會影響樹的功能(無法對剩余分支進行存在性證明).
因此,我們將索引內部節點的記錄值往左下方移動,直到葉子節點為止,從而使得記錄值只存放在葉子節點.在實現上,就是將小于等于節點關鍵字的記錄存儲在左子樹,大于關鍵字的記錄存放在右子樹,中間節點只存放關鍵字和子節點hash值.
如圖5 所示,共有6 條記錄項:Data1,Data2,…,Data6,每個記錄項都有一個關鍵值分別為5,8,10,12,15,16.按照關鍵值順序將記錄項存儲到葉子節點中.分支節點中存放著左右子樹的哈希值以及關鍵字,同時保證該節點的左子樹中的關鍵值都小于等于該節點的關鍵值,右子樹中的關鍵值都大于該節點關鍵值.
4.2 基于索引的數據操作算法
(1)數據插入算法
根據數據結構定義,節點結構如下.

葉子節點包含交易信息,中間分支節點存儲索引信息.如果節點是分支節點,其lefthash和righthash分別為左右孩子節點哈希,key值等于左子樹最大關鍵值.如果節點是葉子節點,其左右子樹為空,為了區別于分支節點,其lefthash為0,righthash等于交易哈希值,value為交易記錄.節點的哈希值定義為
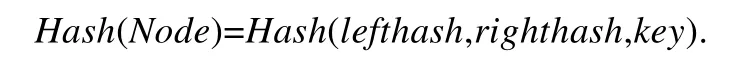
我們從根節點開始插入數據,如果關鍵值小于等于根節點,則插入到其左子樹;如果大于,則插入到右子樹,直到最后一層分支節點h,根據如下所述4 種情況分別在該節點處插入新值.
· 情況1:如果該分支節點為空(只在MerkleRoot 為空時出現),先新建一個葉子節點存放(key,value)數據,然后新建一個分支節點,并定義其左孩子為葉子節點,關鍵值為key,左哈希為葉子節點哈希值.插入結果如圖6(a)所示.這也說明了一棵樹只要不為空,則其分支節點一定不為空,而且最后一層分支節點的key值一定與其左孩子key值相同;
· 情況2:如果待插入數據key值小于該節點key值,我們應該將該數據插入到該節點左側,但是由情況1可知:該節點左孩子一定不為空,而且是葉子節點.為此,我們新建一個葉子節點存放待插入的(key,value)數據,然后新建一個分支節點,其關鍵字為待插入節點key,左孩子為新建的葉子節點,右孩子為原來分支節點的左孩子,父節點為原分支節點,插入結果如圖6(b)所示,其中,連接和分支節點用虛線表示;
· 情況3:如果待插入數據key值大于該節點,而且該節點右孩子為空,則直接新建葉子節點存儲數據,并將其定義為分支節點右孩子,插入結果如圖6(c)所示;
· 情況4:如果待插入數據key值大于該節點,而且該節點右孩子不為空,我們先新建葉子節點存儲數據,然后新建分支節點,分支節點關鍵值為待插入數據key值與原分支節點右孩子key值中的較小者,左孩子為待插入數據與原分支節點右孩子中key值較小者,右孩子為較大者,父節點為原分支節點,插入后結果如圖6(d)所示.
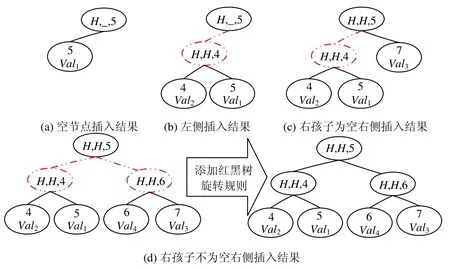
Fig.6 Example of last layer branch node insertion圖6 最后一層分支節點插入示例
算法1.數據插入算法.
輸入:根節點h,插入記錄關鍵值key,插入數據值value;
輸出:根節點.

· 算法1 的第2 行、第3 行是區塊為空時的初始插入操作;
· 第4 行~第6 行是當插入key值小于節點key值時,如果該節點左孩子是最后一層分支節點,則按照之前所述情況2 插入數據;否則,以左孩子節點為當前節點遞歸插入數據;
· 第7 行~第10 行是當插入key值大于節點key值時:
? 如果右孩子為空,則該節點是最后一層分支節點,按照情況3 插入數據;
? 如果右孩子不為空,且是最后一層分支節點,則按照情況4 插入數據;否則,以右孩子為當前節點,遞歸插入數據;
· 第11 行~第13 行添加紅黑樹旋轉規則,保證該樹黑色平衡;
· 第14 行、第15 行更新節點哈希值.
數據插入之后,我們得到從根節點開始的二叉搜索樹,而每個節點的哈希值即Hash(lefthash,righthash,key)又完全映射成一個基于哈希的不可篡改索引.數據是先寫入到內存區塊當中,當內存區塊大小到達一定的閾值,則將該區塊順序寫入到磁盤中,將其對應的MerkleRBIndex 存儲到k-v數據庫中.數據庫中存儲格式:
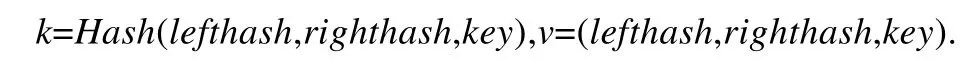
為了便于理解,可以認為MerkleRBIndex 對應一個map 集合mapMerkleIndex.
(2)數據查找算法
根據之前創建的索引,我們可以提供一種針對關鍵字key的查詢方法,并且根據Merkle 樹的特性,提供對應該查詢結果的驗證路徑,使得輕量級客戶端可以根據極少量信息去自我驗證查詢結果的正確性.
當輸入關鍵值key時,首先在內存區塊中檢索,如果檢索不到,就加載k-v數據庫中上一區塊的MerkleRBIndex 索引,直到檢索到該數據項或者不存在該記錄.當在特定區塊中檢索的時候,首先從MerkleRoot節點開始檢索,如果目標關鍵字小于等于根節點關鍵字,則在mapMerkleIndex 中查找k為root.lefthash的目錄,其對應的v則為下次要比對的對象;否則,查找root.righthash.最后,查詢鎖定在葉子節點,如果葉子節點的關鍵值等于目標關鍵值則查詢成功;否則,記錄不存在該區塊中.
算法2.數據查找算法.
輸入:關鍵值key,索引map〈Hash(lefthash,righthash,key),〈lefthash,righthash,key〉〉mmap;
輸出:節點哈希值以及驗證路徑Vector〈〈hash,key〉〉path.

· 算法2 的第2 行初始化當前查找hash值為merkleroot;
· 第3 行~第9 行向下檢索直到葉子節點,其中:第4 行~第6 行是如果目標key值小于等于當前索引項key值,則更新索引項為當前索引項的左哈希對應的索引項,并將其右哈希和索引key值保存在驗證路徑中;第7 行~第9 行對應目標key值大于當前索引key值的情況;
· 第10 行~第14 行是檢驗葉子節點是否包含目標key值:如果不在,則清空驗證路徑;如果在,則更新交易哈希值,并且將該項對應的驗證值添加到驗證路徑中.
在圖5 所示的MerkleRBTree 中,對于關鍵字key=10 的查詢,從節點H11開始,依次查詢H10,H8和H3,驗證路徑為path={(H9,12),(H7,8),(H4,10),(0,10)}.
本文提出的索引結構能夠讓索引自我檢測索引的正確性和完整性.在區塊內檢索數據的過程,就是對mapMerkleIndex進行map 映射的過程.由于該map 最初是根據交易數據和索引信息自下往上兩兩哈希得到的,每一個條目都是確定且不可缺少的,當從最頂端開始向下檢索的時候,能且只能檢索到構建索引時存在的節點,直到葉子節點.如果在檢索過程中指向一個map 中不存在的條目,則可以確定該索引數據缺失或者數據被篡改.
(3)數據驗證算法
不僅存儲節點可以在查詢的時候檢測到索引的正確性和完整性,而且用戶節點可以在接收到查詢結果之后對查詢進行驗證.如第2 節所述:用戶節點存有區塊頭信息,而區塊頭當中有MerkleRoot 值,用戶根據查詢結果和驗證路徑,對路徑上的值兩兩哈希生成查詢結果對應的MerkleRoot 值,用戶通過比較該值是否與自己保存的區塊頭中的MerkleRoot 值相同,從而驗證查詢的正確性.而且查詢路徑的長度對應交易在二叉查找樹中的深度,對于含有N個交易的區塊,任意交易的查詢路徑長度為logN,而且查詢路徑中的值為256 位的哈希值,驗證的存儲代價極小而且高效.
算法3.數據驗證算法.
輸入:交易信息tx,驗證路徑path,根哈希merkleroot;
輸出:true or false.

算法3 的第2 行計算交易哈希值;第3 行~第5 行根據驗證路徑,從該交易開始向上重新生成父節點,最后生成根節點;第6 行~第8 行比對根據驗證路徑生成的根節點值與本地保存的根節點值,如果相同,則查詢有效.
5 實 驗
實驗的硬件環境是Intel(R)Core(TM)i5-6500 CPU(3.2GHz),RAM 為8Gb 的PC 機,操作系統為Windows10.借助Bitcoin 的開源代碼v0.1.0 版本構建了一個區塊鏈數據庫,實驗中主要修改了Bitcoin 的底層數據結構,包括交易格式以及在區塊中交易的組織形式,其中:交易格式擴展為支持更一般的數據格式,交易的組織形式由Merkle 樹改為MerkleRBTree;保留了非對稱加密技術以及UTXO 的思想,類比Bitcoin 中的公鑰與私鑰腳本結合形成價值傳遞軌跡,本實驗中利用公鑰私鑰腳本結合形成數據的修改軌跡,并且利用該軌跡進行數據溯源.需要說明的是,本文的主要研究點是對于區塊鏈數據的索引方法,不涉及網絡以及共識協議,故在實驗時利用單機進行測試,并將共識替換為檢查交易的合法性,將有效交易存入到區塊中,當區塊大小達到閾值,則將整個區塊存入磁盤.在本節中,我們設計多組實驗來測試本文所提出的不可篡改索引的性能,實驗中的主要指標為算法的運行時間,并將算法獨立運行30 次的平均值定義為算法的運行時間.
· 實驗1:MerkleRBTree 的性能測試
在比特幣中生成區塊時,需要對交易兩兩哈希得到 MerkleRoot.本文的模型中將 MerkleTree 替換成MerkleRBTree,在得到MerkleRoot 的同時生成對應的索引.我們設計實驗測試了在區塊交易數為26,27,…,216時對應的索引構建的時間代價.如圖7 所示:MerkleTree 和MerkleRBTree 的構建代價隨著交易數的增加而線性增加,有著相近的性能.說明在可接受的代價內實現了索引的構建,增加了查詢功能.這里,MerkleRBTree 的時間代價多于MerkleTree 的時間代價,主要是因為在進行哈希操作時,MerkleTree 每次哈希輸入為兩個值,分別為左右子哈希;在MerkleRBTree 中,每次哈希操作為3 個值,分別為左右子哈希和對應的key值.
· 實驗2:區塊大小對于交易平均寫入時間以及內存消耗的影響
交易到內存之后,需要等到形成一個完整區塊才能存入到磁盤,這就使得第1 個進入到區塊的交易和最后一個進入區塊的交易有時間差,故在此取多個交易的平均時間.在這里,用交易數來度量區塊大小,分別設置區塊中最大交易數量為64,128,256,512,1024,2048,4096,8192,設置交易的字段數為3.如圖8 所示,交易的平均寫入時間隨著區塊最大交易數的增加而減小.這是因為區塊中交易數越多,寫入磁盤的時間代價均分到每一個交易上的代價就會越小.同時發現:當最大交易數為1024 以后,平均寫入代價趨于穩定.另一方面,區塊越大交易數越大,對應的內存消耗越大,且在區塊交易數超過1024 以后,內存消耗增加明顯.綜合考慮兩者因素,確定區塊大小為1024 個交易.
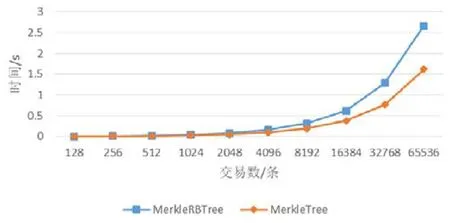
Fig.7 MerkleRBTree and MerkleTree build cost comparison圖7 MerkleRBTree 和MerkleTree 構建代價對比
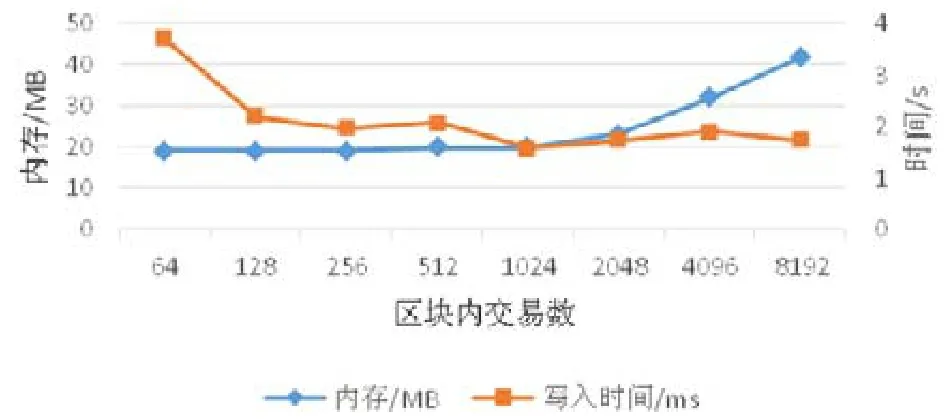
Fig.8 Impact of block size on memory and write time圖8 區塊大小對內存和寫入時間的影響
· 實驗3:key值查詢與hash值查詢性能對比
現有的區塊鏈系統只能根據交易哈希值進行查詢,哈希值形如“1ef4c1a9c62aa236766d2864c4c0f2d609aa83 d4f256dc35962a603a6832a476”抽象且與數據沒有直接關聯.本文實現了針對數據關鍵字key進行查詢,我們設計的實驗測試了針對key值與hash值的查詢性能比較.如圖9 所示,本文提出的針對key值的查詢和比特幣中針對哈希值的查詢有相當的性能,表明在可接受的時間代價內,實現了交易的可查詢性.
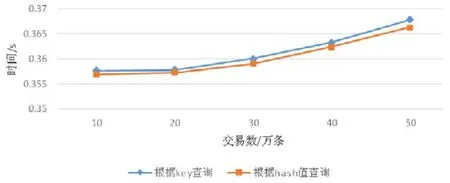
Fig.9 Comparison of key value query and hash value query圖9 key 值查詢與hash 值查詢對比
· 實驗4:區塊深度對于查詢時間的影響
數據在存儲時是按照寫入順序依次添加到區塊中,區塊順序寫入磁盤.我們設計的實驗測試了數據寫入先后順序對于查詢的影響.實驗中順序寫入50 萬條key升序數據,每一個區塊大小為1 000 條數據,一共500 區塊,測試不同深度的數據查詢時間.如圖10 所示:數據查詢操作并不受區塊深度影響,對于先后寫入的數據具有相近的查詢時間,查詢時間均勻分布在0.36s 左右.圖中的異常點主要是因為在進行數據查詢時,需要訪問k-v數據庫讀取元數據信息,而k值為256 位的哈希值,k-v數據庫的不穩定性導致了異常點的出現.
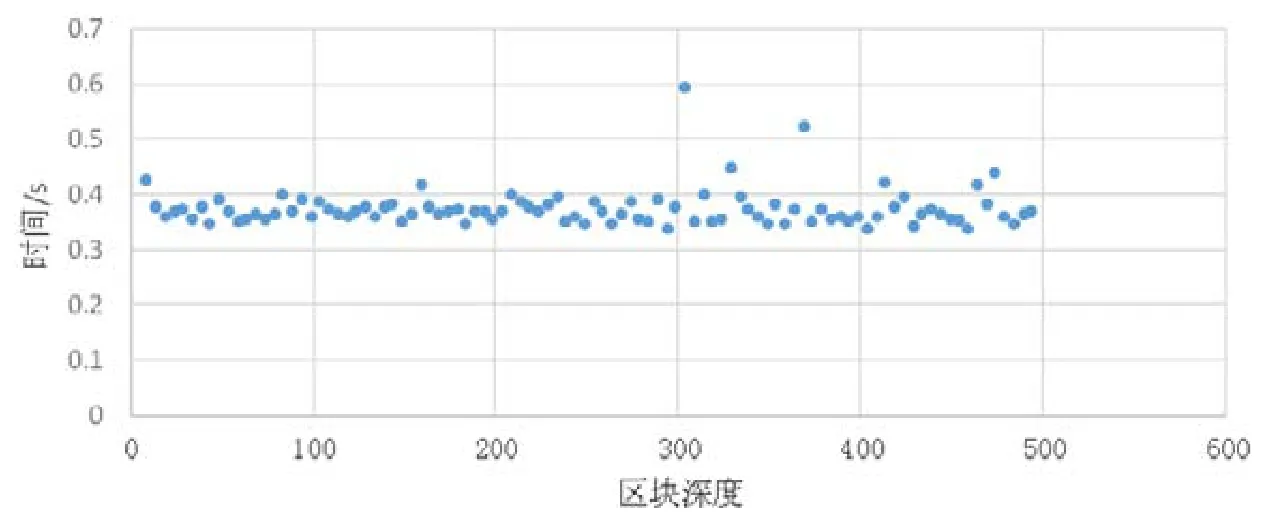
Fig.10 Block depth influence on query time圖10 區塊深度對于查詢時間的影響
· 實驗5:數據溯源性能測試
區塊鏈的特性之一就是數據可回溯,即返回任意數據的完整修改歷史.我們設計實驗測試了數據版本數對于溯源時間的影響,分別設置7 條區塊鏈,每條鏈的區塊個數依次為10,20,30,40,50,60,70,區塊中交易個數固定為1 024,交易的字段數固定為3,字段值為value+區塊號,每個區塊中key為0~1023,以此模擬數據的版本更新.分別在7 條鏈上針對同一關鍵字key進行數據溯源,記錄查詢到最初版本所需要的時間.如圖11 所示,數據溯源的查詢代價接近于單次數據查詢的時間代價.這說明數據溯源的查詢代價集中于最新版本的查詢時間,歷史數據的溯源時間相對于單次查詢時間微乎其微,具有很好的溯源效率.
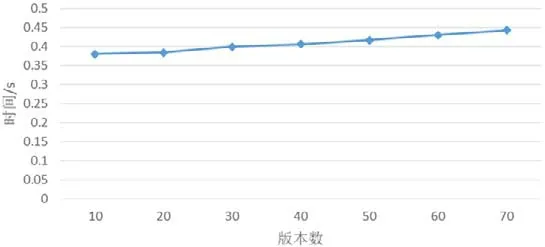
Fig.11 Impact of version number on query time圖11 版本數對于查詢時間的影響
6 總結
本文首先提出了一種區塊鏈數據庫模型,將區塊鏈技術應用于數據管理;其次提出了一種基于哈希指針的樹型索引結構,用于管理區塊內的記錄項,并由此實現查詢;最后,通過實驗測試數據庫的讀寫性能.實驗結果表明:本文提出的不可篡改索引在保證不可篡改的同時,具有較好的讀寫性能.同時,本文提出的針對key值的查詢方法,是對于區塊鏈數據庫進行多值查詢以及范圍查詢的基礎,之后還會在此基礎上進一步研究區塊鏈的復雜查詢.
當下人們對于數據安全的要求越來越高,區塊鏈憑借著安全不可篡改的特性,必然會有出色的表現.然而要構建一個成熟的區塊鏈數據庫還需要一些后續工作.
(1)利用高效的共識算法提升系統的吞吐率;
(2)利用智能合約管理每一個數據項的讀寫權限,保證只有擁有者授權的公鑰可以訪問和修改數據.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
