惡意代碼演化與溯源技術研究?
2019-10-28 11:21:22宋文納彭國軍傅建明張煥國陳施旅
軟件學報 2019年8期
宋文納 , 彭國軍 , 傅建明 , 張煥國 , 陳施旅
1(空天信息安全與可信計算教育部重點實驗室(武漢大學),湖北 武漢 430072)
2(武漢大學 國家網絡安全學院,湖北 武漢 430072)
惡意代碼溯源是指通過分析惡意代碼生成、傳播的規律以及惡意代碼之間衍生的關聯性,基于目標惡意代碼的特性實現對惡意代碼源頭的追蹤.隨著互聯網的蓬勃發展,惡意代碼已經成為威脅互聯網安全的關鍵因素之一.2017 年,AV-TEST 安全報告[1]指出,AV-TEST 系統檢測惡意代碼規模已經超過6.4 億,其中,Windows 和Android 平臺的惡意軟件規模極為顯著,與前一年相比,Android 設備端惡意軟件數量翻了一番,惡意軟件的數量變化如圖1[1]和圖2[1]所示.
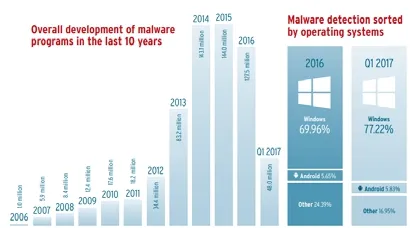
Fig.1 Over development of new malware programs in the last 10 years[1]圖1 最近10 年新惡意軟件的發展[1]
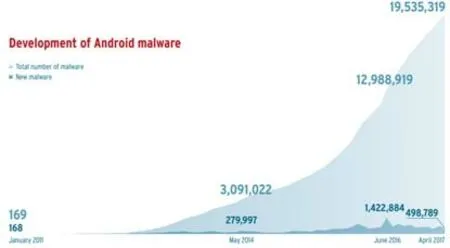
Fig.2 Development of Android malware[1]圖2 Android 惡意軟件的發展[1]
在與惡意樣本的的對抗過程中,惡意軟件分析和檢測技術也在不斷發展.基于靜態分析的檢測[2,3]、基于動態分析的檢測[4?6]以及基于機器學習的檢測[7?11]等技術不斷涌現:基于靜態分析的檢測對非混淆樣本更為準確;而基于動態分析的檢測在檢測混淆惡意軟件方面表現更為出色;基于機器學習的檢測[12?16]是通過對大規模惡意樣本進行特征提取(如API(application programming interface)、CFG(control flow graph)、關鍵字符串值等),然后采用機器學習算法(例如分類或聚類)訓練樣本,以構建模型判斷軟件的惡意特性.這為安全研究人員提供了良好的輔助功能,有效地提高了大規模惡意軟件的檢測速度.
雖然惡意軟件檢測技術的廣泛應用對惡意代碼攻擊起到了一定抵抗作用,但是震懾力依然不足.
· 一方面,惡意軟件檢測技術有限,惡意作者可利用免殺技術構建變體繞過惡意軟件檢測.例如2017 年,安天移動安全聯合獵豹移動安全實驗室捕獲一例使用MonoDroid 框架開發的移動端C#病毒,該病毒將邏輯代碼編譯成DLL 文件,進而逃避惡意代碼的常規檢測[17].2017 年5 月份爆發的WannaCry 樣本與2017 年3 月份Wcry 樣本是同源樣本,該變種利用微軟SMB 漏洞以及DOUBLEPULSAR 后門實施攻擊,繞過了包含360 在內的多個安全檢測工具,英國、法國、西班牙、韓國、俄羅斯及中國等多個國家遭受了嚴重的經濟損失[18].
· 另一方面,惡意代碼檢測技術側重于對惡意代碼的發現和防范,盡管利用該技術可以檢測到大多數惡意代碼攻擊,但是不能提供對惡意代碼來源的有效追蹤,因此不能從根源上遏制惡意代碼的泛濫.
FireEye[19]面向多個組織進行了針對網絡安全應急響應速度的調查,其報告指出,在復雜的新型惡意軟件和高級先進的持續威脅(APT)環境下,只有20%的組織認為其事件響應計劃“非常有效”,而他們最大的安全差距在于是否能夠檢測和遏制APT 類惡意軟件.這說明安全組織對威脅事件的響應計劃、人員和工具還不能跟上新的威脅.不過,現有惡意代碼檢測中的部分工作也可用于惡意代碼的溯源研究.例如,惡意代碼檢測技術中的特征分析可為溯源特征的提取提供借鑒,因為不管是惡意代碼的溯源還是檢測,在特征提取階段,均會考慮對代碼中包含其典型惡意性的關鍵代碼或數據片段進行分析.
為了進一步震懾黑客組織與網絡犯罪活動,目前學術界和產業界均展開了惡意代碼溯源分析與研究工作.其基本思路是:利用惡意樣本間的同源關系發現溯源痕跡,并根據它們出現的前后關系判定變體來源.惡意代碼同源性分析,其目的是判斷不同的惡意代碼是否源自同一套惡意代碼或是否由同一個作者、團隊編寫,其是否具有內在關聯性、相似性.從溯源目標上來看,可分為惡意代碼家族溯源及作者溯源.家族變體是已有惡意代碼在不斷的對抗或功能進化中生成的新型惡意代碼[20],針對變體的家族溯源是通過提取其特征數據及代碼片段,分析它們與已知樣本的同源關系,進而推測可疑惡意樣本的家族.例如,Kinable 等人提取惡意代碼的系統調用圖,采用圖匹配的方式比較惡意代碼的相似性,識別出同源樣本,進行家族分類[21].惡意代碼作者溯源即通過分析和提取惡意代碼的相關特征,定位出惡意代碼作者特征,揭示出樣本間的同源關系,進而溯源到已知的作者或組織.例如,文獻[22]通過分析Stuxnet 與Duqu 所用的驅動文件在編譯平臺、時間、代碼等方面的同源關系,實現了對它們作者的溯源.Kaspersky 實驗室通過深入分析Stuxnet 與Flame 這兩款惡意軟件發現,2009 版的Stuxnet 中的Resource 207 模板與Flame 中一個插件模塊mssecmgr.ocx 幾乎完全相同,得出Flame 與Stuxnet的開發人員有過早期合作等結論[23].2015 年,針對中國的某APT 攻擊采用了至少4 種不同的程序形態、不同編碼風格和不同攻擊原理的木馬程序,潛伏3 年之久,最終,360 天眼利用多維度的“大數據”分析技術進行同源性分析,進而溯源到“海蓮花”黑客組織[24].可見,發現樣本間的同源關系對于惡意代碼家族和作者的溯源,甚至對攻擊組織的溯源以及攻擊場景還原、攻擊防范等均具有重要意義.
本文主要圍繞惡意代碼的家族、作者等溯源工作進行進展研究.首先介紹惡意代碼的編碼特征和演化特性,然后從學術界和產業界兩個方面梳理現有的研究工作.歸納并基于學術界所共有的實現環節,分析各個環節面臨的關鍵問題,以及解決這些問題的研究思路;然后對產業界的溯源機理,所能解決的關鍵問題進行分析,并對學術界和產業界在溯源分析方法方面的區別和聯系進行了總結.最后,對已有的惡意代碼溯源方法中存在的挑戰進行分析,并對未來可進行的研究方向進行了展望.
1 惡意代碼的生成過程與演化特性分析
惡意代碼是指在一定環境下執行的對計算機系統或網絡系統機密性、完整性、可用性產生威脅,具有惡意企圖的代碼序列[25].惡意代碼的編寫流程通常如圖3 所示.
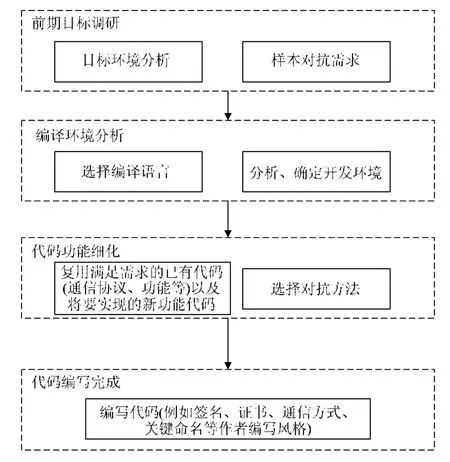
Fig.3 Malicious code writing process圖3 惡意代碼編寫流程
惡意代碼與正常應用程序的編寫流程基本相似.
(1) 前期目標調研:制定自己代碼功能需求,分析目標環境,主要獲取目標環境信息.
(2) 編譯環境選擇:根據前期目標調研階段的分析結果,確定惡意代碼的開發語言與集成開發環境(通常包括編輯器、編譯器、調試器和圖形用戶界面工具等)等,為代碼的編寫提供開發調試環境條件.
(3) 代碼細化功能分析:結合第1 階段和第2 階段的代碼功能的分析,進一步細化代碼行為功能和對抗功能.全新編寫代碼或者從已有的樣本源碼庫中選擇滿足自己需求功能的代碼片段,并作為創建新程序的復用代碼片段.選擇合適混淆和對抗環境識別分析的方法,用于編寫能夠逃避靜態和動態分析與檢測的惡意代碼.
(4) 代碼編寫:作者按照自己的代碼編寫風格與習慣進行編碼實現,并選擇合適的數字證書(APP 開發)進行簽名,完成惡意代碼的全部實現.
惡意代碼的作者編寫風格是作者在長期的編寫過程中形成的不易改變的代碼風格,利用代碼編寫風格的相似性可以實現對作者的溯源;另外,代碼開發環境(如IDE、特殊的代碼路徑、非默認編譯參數等)也可能成為作者溯源特征.
惡意代碼遵循正常軟件開發流程,但實現的功能往往是破壞計算機系統或者竊取用戶隱私等.為了使代碼中敏感操作能夠逃避檢測,惡意作者往往會采用與正常程序不一樣的編碼方式,從而表現出作為軟件與身俱來的軟件特性(如復用性、固有缺陷性等)以及作為惡意軟件所特有的多種惡意特性(如代碼敏感性、對抗性等).此外,在進行惡意代碼編寫時,功能代碼和特有對抗代碼的復用可能導致前后衍生軟件的相似性.因此,惡意代碼的編碼特性可為進行溯源分析提供有效線索.下面將具體從惡意代碼個體的編碼特性以及惡意代碼作者和家族的相似性角度進行闡述.
1.1 惡意代碼個體的編碼特性
惡意代碼個體的編碼特性指作者在編寫惡意代碼過程中所呈現出來的代碼編寫特性,為惡意代碼文件的溯源分析提供了良好理論和技術支撐,有助于溯源特征的提取.本文從代碼復用性、代碼對抗性、代碼敏感性、代碼固有缺陷性等方面分析惡意代碼的編碼特性.
1.1.1 代碼復用性
復用性是指惡意代碼作者在進行代碼復用行為后形成的一種代碼衍生特性,該特性推動了惡意代碼的快速生成.復用行為是惡意代碼作者采用的一種,將已有惡意代碼中滿足自己功能需求的代碼片段提取出來,不修改或進行稍許修改并應用于創建新的惡意代碼的行為.2014 年,Symantec 報告[26]指出,大部分惡意軟件都是已存在惡意軟件的變種而不是重新創建的新型惡意軟件.2018 年,Symantec 發布的《2017 年度回顧:移動威脅情報報告》[27]指出,2017 年移動平臺惡意軟件變種的數量增長了54%.可見,代碼復用在移動惡意軟件開發中具有普遍性,這在當前多個知名的PC 端惡意軟件中也得到充分體現.比如,CrySyS 實驗室發現Duqu 與Stuxnet 的某些DLL 文件具有多個相似的導出函數,driver 文件中也存在大量相似函數[28];Kaspersky 實驗室發現Flame 與Gauss的C&C 服務功能函數、字符串的初始化函數、字符串解密函數等相似[29].另外,惡意軟件Cloud Atlas 與RedOctober[30]的壓縮算法實現函數相似.
1.1.2 代碼固有缺陷性
固有缺陷性主要指惡意代碼的編寫缺陷.編寫缺陷是指惡意代碼作者因為個人水平或其他原因,在進行某些功能的編碼時,有時候會產生一些編寫或邏輯上的錯誤,而這種錯誤是在其編寫類似代碼時每次都會犯,這就形成了作者的固有缺陷.如果多個惡意軟件均存在類似缺陷,則可能為同一作者所為.
1.1.3 代碼對抗性
對抗性是指惡意代碼具有的可以遏制逆向分析以及繞過殺軟、穿透代理、防火墻以及對抗IDS 等防護手段.根據對抗類別的不同,惡意代碼的對抗分為基于靜態分析與檢測的對抗、基于動態分析與檢測的對抗以及基于機器學習分析與檢測的對抗等.惡意軟件的對抗性使得惡意代碼在系統設備中長期潛伏成為可能,這對系統資源和用戶數據造成了嚴重的潛在威脅.惡意代碼對抗類別及常見方法見表1.

Table 1 Confrontation category and method of Android malware表1 Android 惡意軟件的對抗類別及方法
表1 中列出的常見方法描述如下.
1) 基于靜態分析與檢測的對抗
花指令指精心設計代碼邏輯或在指令間插入定義設計的數據,干擾反匯編器給出錯誤反匯編結果;簡單加密指對病毒主體代碼采用不同密鑰加密,導致不同個體文件數據差異大,從而導致特征值提取困難[31].多態和變形是在加密基礎上,在保持代碼等價功能的前提下,對解密邏輯及原始病毒主體代碼進行變換.保持功能等價的代碼變換技術[32]包括插入無關垃圾代碼、指令擴展或收縮、改變無關指令執行順序、插入條件跳轉指令、寄存器重新分配、變量重命名等;代碼混淆指通過采用字符串混淆[33,34]、控制流混淆[35]等混淆技術對代碼自身做出變換,常見的代碼變換工具包括DexGuard[36]、ProGuard[37]、AMAD[38]、DroidChameleon[39]、代碼隱藏(惡意組件隱藏在資源文件[40?43]中、Manifest 文件欺騙)、動態加載、加殼[44,45],如UPX,ASPACK,ASPROTECT,VMProtect 等;靜態啟發式檢測主要是通過靜態啟發式掃描分析文件代碼的邏輯結構是否含有惡意程序特征[46].常見的對抗殺軟靜態啟發式檢測的技術包括多節病毒、加密宿主文件頭的前置病毒、入口點隱藏技術、在代碼中選擇隨機入口點、重新利用編譯器對齊區域、不適用API 字符串重命名已經存在的節等.
2) 基于動態分析與檢測的對抗
(1) 檢測調試環境:主要指在檢測到調試環境的情況下終止敏感操作,包括從文件特征、進程名、進程數據特征、加載的特定模塊、調試器窗口、調試器具有的特殊權限等方面進行檢測.例如,利用調試器一般采用DBGHELP 庫來裝載調試符號,因此根據進程是否加載了DBGHELP.DLL,來判斷是否存在調試器環境;通過FindWindow(?)等函數查看是否包含調試器標題和類名的窗口:如果存在,則很可能有調試器存在;調試器進程對其他進程調試的時候,需要擁有SeDebugPrivilege 權限,普通進程沒有該權限,因此通過打開CSRSS.EXE 進程驗證自身進程是否具備SeDebugPrivilege 權限,來確定進程是否被調試.
(2) 檢測調試行為:主要指在調試行為發生的情況下,表現出對抗調試或終止敏感操作的行為.對抗調試行為的方法包括基于調試特征檢測的調試對抗、基于調試特征隱藏關鍵代碼的調試對抗.例如,利用PEB 結構BeingDebug 標志,在程序處于調試狀態時為非0,將其作為特性進行反調試;利用異常中斷int3 指令常被設置為軟件斷點的特性,在代碼中置入int3 指令,當程序未被調試時,將進入異常處理繼續執行,但是程序處于調試階段時,int3 被當成調試器自己的斷點,而不會進入異常處理程序,通過將核心代碼寫入異常處理過程,能夠避開調試器的執行調用.
(3) 檢測沙箱環境:主要指利用硬件序列號、固件版本和其他操作系統配置作為沙箱指紋,通過檢測所處環境的沙箱系統和管理程序的每個工件來逃避沙箱系統的分析與檢測[47,48].常見方法包括:訪問特定注冊表項(例如,HKEY_LOCAL_MACHINESYSTEMControlSet001ServicesDiskEnum),然后解析子項的值,查看“vmware”“qemu”“xen”等子字符串的存在情況,以判定沙箱的存在;利用內核數量檢測沙箱環境的存在,這是因為正常環境中內核處理器是多個,但是在沙箱環境中通常是單核處理器;通過檢測設備信息,并將該信息與沙箱中已知的值進行比較檢測沙箱環境;利用模塊名稱檢測沙箱.例如,在模塊名稱上調用GetModuleHandleA(?),如果返回Null,則表示模塊已加載,沙箱在進程中注入模塊以記錄其執行活動,那么通過FreeLibrary(?)來卸載模塊,使得沙箱將不能記錄任何執行痕跡[49].
(4) 虛擬機環境檢測:基于虛擬機環境檢測的對抗分析方法主要包括3 類:語義攻擊(CPU 語義攻擊)、基于時間的攻擊和字符串攻擊[50].例如,文獻[51,52]均使用CPU 語義信息來檢測虛擬機的存在;文獻[53]利用基于時間的技術來確定管理程序自省操作的存在,來識別虛擬機的存在;Thanasis 等人提出的基于QEMU 的模擬器的不完全仿真特點識別模擬器的存在[54];此外,枚舉進程也可以識別虛擬機的存在,例如,通過使用Process32First(?)/Process32Next(?)查找與虛擬機相關的vmsrvc.exe 等進程名稱:如果存在,執行非惡意操作,逃避安全檢測.
(5) 對抗動態啟發式查殺、主動防御:常見的方法包括:調用底層的未攔截API 接口完成上層API 功能;利用受信任進程完成對目標模塊的加載,對主動防御擁有比較好的免殺效果;將多個行為在分離在多個進程中實現,將能成功繞過針對目標進程的行為進行綜合分析的啟發式查殺.例如,在進程A中完成文件釋放,進程B中完成提權,進程C完成安裝.
(6) 漏洞利用:漏洞利用[55]主要指利用程序中的某些漏洞(如緩沖區溢出漏洞[55]),得到計算機的控制權,進而逃避安全系統的分析與檢測.例如,2017 年8 月,FireEye 發布報告指出,APT28 使用EternalBlue漏洞利用工具和開源工具Responder 進行橫向傳播[56].2017 年4 月,白象組織利用Office 漏洞,該漏洞利用Office OLE 對象鏈接技術,將包含的惡意鏈接對象(HTA 文件)嵌在文檔中,通過構造響應頭中content-type 的字段信息,最后調用mshta.exe 將下載到的HTA 文件執行[57].而目前漏洞利用的高級表現形式是組合漏洞的利用,突破了單一漏洞執行過程中被安全系統分析與檢測到,而無法繼續運行的問題.例如,2017 年的FinSpy[58]利用CVE-2017-0199,CVE-2017-8759,CVE-2017-11292 等多個漏洞來投遞FinSpy,該病毒的復雜性強,對其檢測困難.
3) 對抗基于機器學習分析與檢測方法
對抗基于機器學習分析與檢測:主要是通過對抗性數據操縱惡意軟件逃避模型檢測[59].攻擊者對訓練數據進行變形,使其接近訓練數據集中良性實例,從而逃避目標分類器分類.目前,學術界的對抗研究是在攻擊者對機器學習模型內部(特征空間、分類算法等)[60]、訓練數據集、分配給輸入樣本的分類分數[61]等至少一種了解的情況下,實施的逃避方案.其中,攻擊者利用分配給輸入樣本的分類分數進行的方案,在實際的應用場景實現艱難,因為現實部署的機器學習模型只會暴漏給攻擊者最終決策(拒絕、接受等).文獻[62]在基于攻擊者僅知道機器學習模型的最終決策的情況下,提出一種使用黑盒子變形器操作惡意樣本逃避的方法EvadeHC,使PDF 惡意軟件有效地逃避了檢測器.這表明:基于機器學習模型的惡意代碼分析與檢測系統并非完全可靠,仍需兼并人工分析.
綜上,惡意代碼動態和靜態分析與檢測的對抗方法增強了代碼被解讀的困難性,加強了代碼痕跡被捕獲的難度,使得惡意代碼具備了一定的自我保護能力.然而在實際操作中,為了平衡惡意代碼的運行效率和功能,往往不會在惡意代碼中加入非常全面的對抗技術.例如文獻[63]中提出:卡巴斯基在2015 年7 月發現Duqu 的新變種Duqu2.0,利用了0day 漏洞,該漏洞無法通過靜態分析內容檢測到,但是將該惡意軟件放在沙箱環境中,利用強大的啟發式引擎進行檢測,可以攔截到行為.因此,在實際的惡意代碼分析與檢測中,動靜結合使用,往往比采用單一的方法能發現更多的惡意代碼.基于機器學習的分析與檢測方法在檢測大規模惡意代碼方面效率大大提升,但是上述分析表明,該方法的自身缺陷可能為黑客提供對抗條件.由此可見,在面對大規模惡意軟件的分析與檢測方面,人工分析與基于機器學習的分析與檢測結合使用,才能更加準確地檢測到更多惡意代碼.
1.1.4 代碼敏感性
代碼的敏感性是指惡意代碼在進行行為隱蔽觸發和敏感資源訪問的所表現出來的特性,常見的惡意代碼關鍵示例敏感點主要包括觸發條件、系統(API)調用、代碼結構、常量(關鍵字符串)等.圖4 為惡意敏感操作執行代碼片段示例,圖5 為觸發分支條件代碼片段示例.
圖4 中第1 行畫線部分表示敏感函數入口點;第5 行表示敏感函數觸發分支條件;第6 行和第7 行表示正常操作代碼片段;第9 行和第10 行表示惡意代碼操作片段;第7 行、第10 行、第15 行、第16 行畫線部分表示調用的敏感API.

Fig.4 Malicious sensitive operation execution code snippet example圖4 惡意敏感操作執行代碼片段示例
圖5 中第5 行~第7 行用于判斷殺軟是否存在;第9 行表示觸發敏感操作的分支條件;第10 行、第11 行是正常操作代碼片段;第13 行、第14 行是惡意操作代碼片段.
下面結合圖4、圖5 中代碼片段示例闡述代碼敏感性.
1) 觸發條件
觸發條件指觸發惡意敏感函數執行操作的條件,從觸發條件的代碼位置角度分為基于敏感函數入口點的觸發和基于敏感操作分支的觸發.
(1) 前者是指直接或間接觸發惡意函數調用的程序入口點[65],從用戶角度來看有兩種入口點:用戶界面和后臺調用.根據文獻[66,67]中實證研究,敏感API 操作與函數入口點之間如果沒有與UI 相關的函數調用即采用后臺回調,則所屬樣本通常具有惡意性.例如,當一個用戶交互式API 被悄悄調用時,惡意軟件便成功實施該惡意行為[68].如圖4 所示,SetTextMessage是基于回調方式將設備號發送出去.
(2) 觸發分支條件是指能夠觸發惡意敏感函數執行的代碼分支[69].該分支具有與正常程序分支不一樣的特點,文獻[64]對觸發隱藏敏感操作的分支進行了詳細的描述.該分支條件能夠使惡意活動盡可能地逃避安全軟件的檢測,如圖5 所示,為了隱藏惡意活動,作者將惡意活動隱藏在第13 行、第14 行所表示的分支路徑中,而另一分支完全執行正常活動,且隱藏活動與另一分支及分支條件之間沒有共享任何數據與資源,致使安全檢測系統在語義層面的追蹤也變得困難.
圖4 示例中,凌晨3 點~5 點時間來確定何時執行惡意活動(例如竊取私人數據),然而正常軟件卻很少使用時間作為活動執行的條件輸入.上述觸發條件的觸發形式比較多樣化,比如還包括網絡指令觸發(如遠控木馬)、環境觸發(如GPS 位置變化)等.
2) 系統(API 等)調用
系統調用[70?76]是應用程序與系統交互的接口,實現了代碼的功能,表達了關于應用程序行為的實質性語義.為了執行惡意行為,惡意軟件需要調用敏感API 函數來實現,但是僅靠單一的API 調用無法判定所屬代碼的惡意性,因為API 調用具有通用性,許多良性App 也會調用這些API(例如截屏、錄音、定位等API).然而,綜合樣本中多個API 函數構成的序列[77?79],可以看出它存在哪些惡意行為甚至意圖.例如,文獻[80]從vxheaven[81]中收集271 092 個屬于137 個惡意軟件家族的樣本,相同惡意家族的樣本因為共享相同的行為所以會調用更多相同的API 集合,發現至少90%樣本中含有15 個相同API,因此,API 集合可以作為惡意性判定的一個特征.圖4 展示的惡意性操作代碼片段中,API 序列為getDeviceId(?),sendTextMessage(“6667”,null,getIMEI(this),null,null),設備號屬于用戶隱私信息,該序列表明這是將設備號發送出去的操作,存在泄密可能,展現了代碼惡意性操作.
3) 代碼結構
代碼結構[82?84]主要指函數的邏輯結構,可以表達程序的語義信息,是一種細粒度的匹配特征.常見的代碼結構表達方式包括如函數調用圖FCG(function call graph)、控制流圖CFG、程序依賴圖PDG (program dependance graph)等.以API 為原子的代碼結構表現為FCG,該結構展現了函數的調用邏輯.在惡意代碼的家族分類中,FCG相比函數調用組成的序列集更能表達程序的原始信息,因此研究人員通常采用FCG 作為家族特征,用于惡意代碼家族的識別;CFG 是以指令為代碼單元,能夠從觸發條件、API 調用、方法調用、結果返回等方面細粒度描述惡意程序的代碼邏輯,較全面地覆蓋代碼所涉及的執行流程;PDG 是一種基于數據流依賴的代碼結構,相比前兩種語義信息更加豐富,能有效地發現惡意程序的污點傳播路徑,進一步準確定位惡意程序的執行范圍.
4) 常量
常量通過揭示關鍵參數的值和細粒度的API 語義來傳達語義信息[85],例如在圖4 中,sendTextMessage(?)函數以一個名為PremiumRate的電話號碼常量作為參數,比通過getText(?)從用戶輸入接收電話號碼的相同API的調用具有更可疑的行為.因此,惡意代碼在操作敏感數據的時候關于常量的使用至關重要.
惡意代碼在上述特征上通常具有典型敏感性,這是作者編寫惡意代碼內容的主要特點,也是安全研究人員進行溯源的主要依據之一.
1.2 惡意代碼家族和作者的編碼相似性
編碼相似性是指惡意代碼在編碼環境及特征上具有相似性,基于惡意代碼的編碼特性,同一作者或者同一家族的惡意代碼在內容和結構上往往存在相似之處[86],這為惡意代碼的溯源提供了線索.
1) 同家族惡意代碼的編碼相似性(功能相似)
惡意代碼以功能行為劃分家族,同家族惡意軟件的代碼和行為具有相似甚至相同部分[87].作者為了快速構建惡意代碼,復用已有惡意代碼生成變體,使得同家族惡意代碼中大部分代碼及資源保持不變[88].而這些特性在編譯后文件中表現為代碼片段的相似性,其相似性主要集中在執行敏感操作的代碼元素中,例如系統調用、關鍵字符串(如權限、重打包名字)和代碼結構(邏輯結構)等.
· 系統調用:同家族惡意代碼為了實施相同的功能行為,往往調用相同或相似的系統敏感函數API.
· 關鍵字符串:主要指的是硬編碼字符串,同家族惡意代碼為實現特定元素相關的行為,會在代碼中采用關鍵字符串.
· 代碼結構:同家族惡意代碼在實施相同的功能行為時,會執行相似代碼流程,因此其代碼結構相似.
利用上述特性識別惡意代碼變體,并根據已知惡意代碼家族揭示變體家族.例如,文獻[87]通過多個簽名條目(字符串、方法名、方法體等)評估不同樣本間的相似性,進而歸類同家族樣本,使得檢測變體成為可能;文獻[89]利用數據挖掘的方法分析Android 惡意軟件家族樣本的代碼結構,并運用靜態分析提取與應用程序片段關聯的代碼結構CFG,基于該代碼結構計算家族指紋,使用該指紋與待檢測的惡意軟件進行相似度計算,可以識別出同家族惡意軟件變體,驗證了代碼結構用于衡量家族變體間相似性的可行性;文獻[90]為了識別Android 惡意軟件的多態變體,采用聚類算法和社區結構方法,從家族樣本的敏感API 調用子圖中提取頻繁子圖作為惡意軟件的家族行為特征,并利用該家族特征識別未知惡意軟件,檢測率達到94.5%;錢雨村等人[91]提出采用函數調用、資源對象、控制流程圖等元素構建五元組行為,并將其作為聚類特征,所提出的方法能夠有效地對不同惡意代碼及其變種進行同源性分析及判定.綜上所述,同家族惡意代碼中存在相似性的代碼元素,這些元素可以作為家族識別的關鍵特征.
2) 同作者或團隊的編碼相似性(風格相似)
同作者或團隊編寫的惡意代碼由于受擁有的相關領域知識、經驗、編碼工具等限制,使得編寫的代碼在內容和結構上具有相似性.這種相似性抽象刻畫了作者的編碼風格,即使通過混淆技術隱藏或不留下其身份信息,但是人的編碼習慣不會因為創建非同惡意代碼而產生強大的差異.基于人的編程習慣,研究人員可挖掘和利用代碼風格追蹤到相關的作者.
目前,源代碼作者的溯源分析已經相對成熟,其主要用于軟件取證和抄襲檢測.Krsul 等人[92]將編程習慣主要分為編程布局、編程風格、編程結構這3 類,見表2.基于這些編程習慣,許多研究學者對程序的歸屬問題進行了廣泛研究,提取的特征主要集中在字節碼、n-gram 序列、結構化特征等方面.例如,MacDonell 等人[93]基于該編程習慣對惡意作者身份進行識別,識別率達到81.1%;Lange 等人[94]采用布局、詞匯以及遺傳算法指標作為特征,對20 個作者進行去匿名化,準確率達到75%;Kothari 等人[95]將詞匯標記與n-gram 結合使用,對12 個作者進行識別,準確率達到76%;Burrows 等人[96]采用字節級的N-gram 作為特征,對10 個作者的程序進行區分,準確率達到77%;Chen 等人提出通過比較程序數據流來識別作者身份的語義方法,實驗結果表明,該方法具有健壯性,即使代碼被有意修改,依然可以識別出來[97];Caliskan-Islam 等人[98]抽取抽象語法樹作為特征,從GCJ 數據集中識別出1 600 個程序員,準確率達到94%.

Table 2 Authors’ programming habits[92]表2 作者編碼習慣[92]
目前,二進制代碼作者的溯源相對源代碼的溯源工作更加困難,這是因為代碼編譯導致源碼中許多信息丟失,同時,編譯器優化可能會改變程序的結構,進一步模糊作者編碼風格.Alrabaee 等人[99]設計了OBA2 實驗,對8個不同作者創建的程序進行源碼和二進制程序的溯源分析,準確率達到77%,驗證了源碼中一些特征在編譯之后仍存在于二進制代碼形式中,可用于惡意代碼作者身份的識別.目前,常見的二進制惡意代碼的溯源作者的編碼相似性主要從代碼風格和代碼結構相似性角度進行分析.
惡意軟件的代碼風格主要依賴于作者的編碼習慣.喬延臣等人[100]通過分析惡意代碼中模塊的復用風格,構建代碼模塊的快速溯源機制,且具有較高的準確率和召回率.Rosenblumdent 等人[101]提取指令序列和控制流作為特征,去匿名化準確率達到77%.Caliskan-Islam 等人[102]改善了該方法,分別從反匯編和反編譯層面提取語義和語法特征來表示相關作者的編程風格,結合隨機森林、SVM 等機器學習算法進行訓練,針對100 個作者的900個文件進行識別,準確率達到96%.雖然該文的工作主要針對二進制文件而不是惡意文件的分析,但這依然能為二進制惡意代碼的作者溯源提供借鑒.
2018 年2 月份,趨勢科技[103]從代碼結構著手分析,指出Patchwork 和Confucius 組織的Delphi 惡意代碼存在相似之處,如圖6~圖8 所示.

Fig.6 Decompiled Form structure of Confucius’ sample[103]圖6 Confucius 示例的反編譯Form 結構[103]

Fig.7 Decompiled Form structure of Patchwork’s[103]圖7 Patchwork 示例的反編譯Form 結構[103]

Fig.8 Confucius code and Patchwork’s code[103]圖8 Confucius 代碼和Patchwork 的代碼[103]
圖6 的Confucius 示例的反編譯Form 結構和圖7 的Patchwork 示例的Delphi 反編譯Form 結構中創建了相同的TForm 對象,如圈內代碼所示.圖8 展示了兩個惡意代碼中指令結構的相似性.此外,從代碼中字符串域名的解析中發現,這兩個團體主要攻擊目標是東南亞,尤其是巴基斯坦,基于代碼結構的相似性以及攻擊方向的趨勢可以判定它們來自同一組織.
由此可知,研究作者編寫代碼風格、代碼結構相似性等對二進制惡意代碼溯源具有重要意義.
1.3 惡意代碼演化特性
惡意代碼的個體編碼特性、家族和作者的編碼相似性,表明大部分惡意代碼是對已有代碼的修改,揭示了源碼的演化趨勢.源碼的演化促使二進制惡意代碼的變化,并為其提供逆向分析思路.移動端和PC 端惡意軟件在敏感行為執行上存在差異,例如移動端經常會悄悄發送短信等,但是PC 端不會出現這樣的操作,因此下面將分平臺闡述二進制惡意代碼的演化特性.
1.3.1 傳統平臺惡意代碼的演化特性
了解惡意代碼的演化,有助于更好地把握惡意代碼的發展趨勢,為發現新的惡意軟件提供輔助信息,進而快速歸屬新惡意代碼的家族或作者.表3 從時間維度給出了惡意軟件典型功能演變歷程.

Table 3 Evolution and impact of PC malware表3 PC 端惡意軟件的演化及影響
惡意軟件的演化歷程[104]主要分為3 個階段.
· 階段1.1971 年~1999 年的惡意軟件主要以原始程序的形式出現,惡意軟件功能單一,破壞程度小,無對抗行為.
· 階段2.2000 年~2008 年,惡意軟件的破壞性增強,惡意軟件及其工具包數量急劇增長,借助網絡感染速率加快,電子郵件類蠕蟲、受損網站、SQL 注入攻擊成為主流.
· 階段3.2010 年之后,經濟利益和國家利益的驅使下的惡意軟件存在團隊協作緊密、功能日趨復雜、可持續性強及對抗性強等特點.
上述演變歷程中,一方面將惡意軟件擴展到了不同平臺,例如從早期的PC 計算機到工控行業,但更重要的是惡意代碼的功能的進化:惡意代碼在前一階段的個別特性,會在后面階段中持續增強.促進這種進化因素主要是惡意代碼功能的不斷改進以及攻防對抗技術的不斷博弈.這主要涉及惡意代碼攻擊行為和生成方式兩個過程的演化,具體演化描述如下.
1) 惡意軟件的攻擊行為演化特性
與傳統惡意軟件的攻擊行為相比,新一代惡意軟件[105?107]的攻擊行為具備高級性,如圖9 所示.
高級惡意軟件攻擊行為的定向性、持續性、隱蔽性和技術先進性的具體行為表現如下.
(1) 定向性[107]:攻擊者利用Web 服務、瀏覽器和操作系統中的漏洞,或使用社會工程技術發現目標用戶,并使用戶運行惡意代碼來散播惡意軟件.
(2) 隱蔽性:一旦進入系統,惡意代碼隱藏(加密流量等)并禁用主機保護[108],達到正常運行的目的.
(3) 持續性[108]:安裝完成后,惡意代碼會調用命令并控制服務器以獲取進一步的指令(例如竊取數據、感染其他機器并允許偵察等指令),從而持續性地控制目標機器.
(4) 技術先進性[109]:惡意軟件作者使用混淆技術,如無效的代碼插入、寄存器重新分配、子程序重新排序、指令替換、代碼轉換和代碼集成等,以逃避傳統防御措施(如防火墻、防病毒和網關等).
基于上述行為描述,說明目前的高級惡意軟件在功能和防御策略方面更為先進,其造成的影響和損失也更為嚴重.
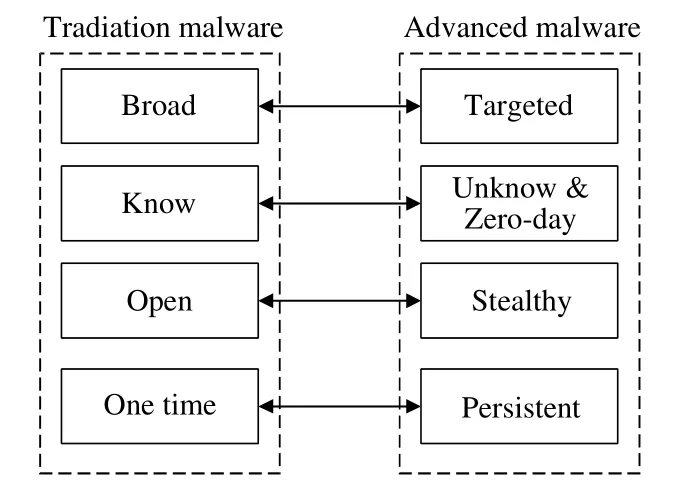
Fig.9 Attack behavior of traditional malware vs.advanced malware[107]圖9 傳統惡意軟件VS 高級惡意軟件的攻擊行為[107]
2) 惡意軟件的生成演化特性
目前,新的惡意軟件很少從頭開始創建,而是采用自動生成工具、第三方庫以及借用現有的惡意軟件代碼等[82]生成,許多惡意軟件都是已存在惡意軟件的變體[110].根據一項調查[111]指出,超過98%的新惡意軟件樣本實際上是來自現有惡意軟件家族的衍生產品(或變體).惡意代碼經過修改或者自行演化等途徑后,往往會形成數十種甚至更多的變種,使得變體數量迅速增長[112].
一個惡意代碼變種與原來惡意代碼形式上有所不同,但實現行為相似,那么這兩個惡意代碼稱為同一個家族,新生成的惡意代碼稱為家族變體[113].當前的惡意代碼變體在實現技術上大致可分為2大類:一類是共用基礎技術(核心模塊或理論),黑客通過重用基礎模塊實現惡意代碼變種[114];另一類是針對現有防范和檢測而研發的惡意代碼混淆技術.惡意代碼混淆技術按照其實現原理可分為2 類[115]:一類是干擾反逆向(反匯編)的混淆,使反逆向不能夠得到正確的分析結果,從而阻礙進一步機理分析;另一類是指令和控制流混淆,這類混淆技術通常采用加殼、垃圾代碼插入、等價指令替換、寄存器重新分配及代碼變換等方式改變惡意代碼的語法特征,隱藏其內部調用邏輯關系,使得惡意代碼逃避惡意軟件的檢測.
隨著惡意代碼家族功能和對抗策略的不斷調整,新的惡意軟件變種及其早期版本的運行時行為通常非常相似,但樣本的演化可能會帶來家族的進化,以適應新的計算機環境.例如,文獻[116]中指出,蠕蟲家族Sobig 從版本Sobig.A 到Sobig.F,該蠕蟲病毒只是增加或者減少一些特性,其行為近似相同;然而,蠕蟲家族Beagle worm從版本A 到版本C 進行了不斷的演化和升級,包括增加了后門、增加了阻礙本地安全機制的代碼、增添了更好的在已有進程中隱藏蠕蟲的機制等,其功能的復雜性提升,家族特性出現新的進化.目前,針對惡意軟件生成演化特性的研究主要從家族進化角度進行分析.例如,文獻[88]根據導出圖的路徑模式定義了一個惡意軟件演化關系的框架,該方法的局限在于對惡意代碼中源代碼的定義不包括機器生成的代碼,考慮到惡意代碼通常是從現有惡意程序中自動生成的,具有限制性;文獻[117]對惡意軟件的系統進化模型進行研究,探索不同惡意樣本數據集對演化模型分析結果的影響;研究人員[118]收集運行時執行指令、內存和寄存器修改等日志信息,構建家族演化樹,研究變化樣本的來源.
綜上所述,傳統平臺惡意軟件的行為演化描述了惡意軟件在生成之后所表現的攻擊特性.這種特性為研究惡意代碼的安全防御系統提供技術支撐,進而加強安全防范,尤其是基于軟件運行時行為的檢測系統(如沙箱、云平臺檢測系統等),使之能夠更可靠地檢測大多數惡意軟件及其變體.研究傳統平臺的惡意代碼生成演化特性能夠更加全面地把握惡意代碼的發展趨勢,進一步調整目前基于主機防御系統(如防病毒軟件)的不足.惡意代碼的攻擊行為和生成特性作為惡意軟件演化過程中的關鍵要素,對于構建惡意軟件演化史具有重要意義:有助于促進對傳統平臺惡意軟件的全面認識,明確未來惡意軟件的發展方向,是惡意軟件發展中一個需要不斷跟進的領域.
1.3.2 移動平臺惡意代碼的演化特性
第一種智能手機病毒起源于2004 年[119],被稱為Cabir,內容和功能均比較簡單,使用傳統的白名單即可以準確地對其檢測.隨著時間的推移,由于惡意作者對目標的修改以及嘗試逃避檢測,使得構造出的惡意代碼不斷改變;同時,隨著代碼復用以及現成工具的廣泛性,惡意代碼的數量不斷攀升.圖10 展現惡意家族樣本自2012 年到2017 年每個季度的數量規模,表明惡意代碼的家族數量整體呈上升趨勢[120].
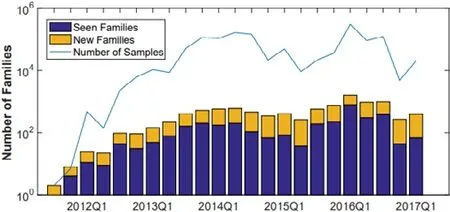
Fig.10 Quantitative scale of family samples in each quarter[120]圖10 家族樣本每個季度的數量規模[120]
下面具體分析移動平臺惡意代碼的演化特性,從行為演化和構成策略演化兩個方面展開移動平臺惡意代碼的演化特性分析.
1) 惡意代碼的行為演化
以文獻[120?125]中對Android 惡意代碼演化分析為基礎,描述移動端惡意代碼的行為演化.惡意軟件的行為主要指與特定攻擊目標相關的行為[123].惡意代碼的行為操作涉及的內容見表4.

Table 4 Android malware behavior and goals表4 Android 惡意軟件的行為及目標
(1) 隱私侵犯:據文獻[120]統計,2014 年之后,與隱私侵犯相關的API 調用增加.例如HttpURLConnection.connect(?)等,該調用結合ContentResolver.query(?)可用于查詢用戶的隱私信息[124].這反映了移動平臺惡意軟件具備向隱私侵犯行為演化的趨勢.
(2) 數據竊取:據文獻[120]統計,在2012 年到2014 年,基于短信方式竊取數據的行為較多;而在2014 年之后,主要以網絡通道來竊取數據.竊取數據方式的改變表明:互聯網技術的發展在為人們帶來方便的同時,也給攻擊者帶來了更多的機會.由此表明:智能化時代的來臨,數據保護愈發重要,這也為APP 開發者提出了更高的安全需求.
(3) 欺詐:據McAfee 指出,傳統的基于高級短信的收費欺詐形式已經演變為僵尸網絡廣告欺詐、按次付費下載的分發詐騙以及勒索軟件欺詐.目前的詐騙方式偽裝手段更高級、迷惑性更強、可持續時間更久.2017 年,McAfee[122]發現目前絕大多數惡意軟件都是ad clicker Trojans,它在后臺以欺詐手段操作移動廣告,創建利潤.
(4) 逃避:文獻[120]指出,作用于更新攻擊以及查詢沙箱中某些硬件的相關API 調用在2017 年增加.此外,文獻[121]統計指出,自2014 年之后,重命名、字符串加密是使用量增長最快的技術,動態加載、逃避動態分析等技術增加次之,而在Native 中隱藏有效載荷關鍵代碼的方法幾乎處于平穩狀態.由此可以得出,惡意軟件行為具有向逃避動態分析發展的趨勢.
(5) 漏洞利用:文獻[120]中指出,Process.killProcess(?)、File.Pid(?)、File.mkdir(?)等與漏洞利用相關的API調用增加,表明該行為目前比較流行.文獻[121]指出,目前,利用漏洞獲取root 權限已經不再流行;與此同時,利用漏洞獲取device-admin-privilege 權限成為主流.McAfee[122]指出,2017 年手機銀行類木馬軟件(比如Marcher malware)增加趨勢明顯,作為虛假更新或通過針對性的電子郵件或短信網絡釣魚提供.
結合上述演化行為,表明Android 惡意代碼向更復雜、更具有針對性、逃避性發展,這也對移動安全防御系統提出了更高的挑戰.研究移動平臺惡意代碼的演化行為,可以幫助安全研究人員更好地研究移動可疑惡意軟件,理解惡意代碼的操作和意圖,進而歸屬出家族變體,促進移動平臺安全體系的穩固.
2) 惡意代碼構成策略的演化
據賽門鐵克統計:2012 年,每個移動惡意軟件家族平均有38 個變種;而在2013 年,每個家族變種數量達到58 個[125],展現了移動平臺惡意軟件變種規模逐年增加的趨勢.與此同時,為了逃避移動平臺防御系統的檢測,自Android 惡意軟件出現以來,使用混淆技術構建惡意軟件的數量也逐年增加.文獻[126]指出,Google Play 中不足25%合法應用程序被混淆[127],90%的惡意代碼都使用了混淆技術.惡意軟件在演化過程中繼承了靜態分析的局限性,根據衡量惡意軟件行為演化過程中混淆API 的演化趨勢,發現加密、反射、動態加載、代碼隱藏等混淆技術,在惡意樣本的生成過程中被越來越多地采用[41].此外,在分析基于代碼隱藏構建的惡意軟件Incognito 中,發現其APK 和Dex 的資源文件中,惡意代碼所包含的常見方法并不多,這意味著在Incognito 應用程序中隱藏的惡意代碼要么不流行、要么被高度混淆而使代碼看起來不明顯,從而逃避自動化系統動態檢測[40].
基于上述對移動平臺惡意軟件行為演化和對抗技術演化的分析,重建惡意軟件系統演化史,將有助于為移動平臺中當前惡意軟件與之前惡意軟件的相關性提供線索,同時明確目前移動平臺惡意軟件以及未來可能的發展趨勢,達到更全面地分析及了解移動平臺惡意軟件的目的.目前已經提出了基于靜態[128]和動態[129]的分析模型,用于識別惡意軟件的進化關系.例如,文獻[130]提出了基于模型檢查的方法來構建Android 惡意軟件家族之間的進化關系.因為惡意軟件作者通常會采用代碼變換技術[131]隱藏派生關系,使得靜態分析無效,文中采用動態分析[132]提取系統調用蹤跡生成形式化模型,用于驗證惡意軟件行為的屬性,具體為使用通信系統的微積(calculus of communicating systems,簡稱CCS)來制定模型,結合選擇性的mu 演算邏輯表達行為屬性,驗證結果確定了惡意軟件樣本共有的常見惡意軟件行為.基于該結果推斷它們的祖先與后代之間的關系,從而獲取家族進化樹.建立惡意軟件的進化模型有助于把握目前惡意代碼的特性、快速地溯源同源樣本,發現更多地未知移動平臺惡意軟件,進一步促進移動平臺安全體系的完善.
2 惡意代碼溯源機理
學術界和產業界的惡意代碼溯源機理存在差異:在學術界,常見的惡意代碼溯源依賴于代碼的相似性分析,進而揭示惡意代碼間的同源關系,且其溯源的目是定位變體家族或作者;而產業界,惡意代碼溯源更傾向于惡意代碼結構及其攻擊鏈的關聯性分析,且其溯源目的是為了挖掘攻擊者或攻擊背后的真正意圖.基于這種差異性,本文將從學術界和產業界分別分析惡意代碼的溯源機理.
2.1 學術界惡意代碼溯源
學術界惡意代碼溯源的基本思想是:采用靜態或動態的方式獲取惡意代碼的特征信息,通過對惡意代碼的特征學習,建立不同類別惡意代碼的特征模型,通過計算待檢測惡意代碼針對不同特征類別的相似性度量,指導惡意代碼的同源性判定[133].常見的惡意代碼溯源主要包括4 個階段:特征提取、特征預處理、相似性計算、同源判定,各階段間的流程關系如圖11 所示.
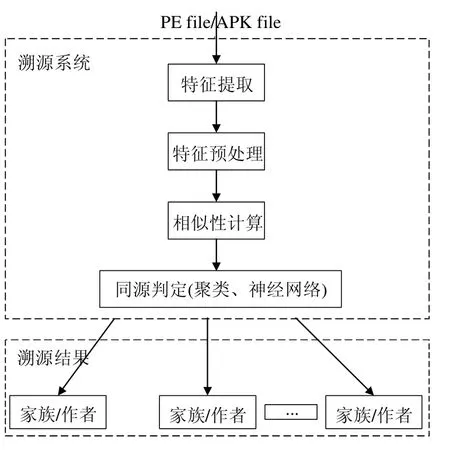
Fig.11 Malicious code traceability system model圖11 惡意代碼溯源系統模型
圖11 所示的溯源對象是Windows 平臺的PE 文件/Android 平臺的APK 文件.將惡意文件輸入溯源系統,經過同源分析,獲取溯源結果.溯源系統模型的4 個階段中:實線框包圍的特征提取和同源判定是溯源系統中不可缺少的階段;虛線框包圍的特征預處理則根據初始特征是否適合于下一階段的輸入來決定是否執行;虛線框包圍的相似性計算是基于聚類的同源性分析中必須執行階段,相似性計算值作為聚類度量值使用,然而該階段在基于神經網絡的同源分析中省去,這是因為基于神經網絡的同源算法旨在通過調整神經網絡參數,構建同源性分析模型,在調整好的模型中對樣本進行同源處理,無需額外執行樣本間相似性計算.本文將詳細闡述4 個階段的實現機理,并評估其優勢及缺陷.
2.1.1 特征提取
特征提取是溯源分析過程的基礎,具有同源性的惡意代碼是通過它們的共有特征與其他代碼區分開來的.因此,所提取的特征既要反映出惡意代碼的本質和具有同源性惡意代碼之間的相似性,又要滿足提取的有效性[134].依據溯源目的,溯源特征提取包括溯源家族的特征提取和溯源作者的特征提取.由于編譯器的編譯、優化以及惡意作者的混淆處理等,編譯后的惡意代碼中大部分源碼信息丟失,特征提取的有效信息量變小.因此,有效地提取惡意代碼特征需要做以下兩點.
(1) 克服惡意代碼的對抗手段.知道變體為避免檢測而使用的技術,以便識別在其逃避策略下保持不變的變體的一部分[67].例如在代碼級別的變體上,調用間接尋址、代碼重排序、垃圾代碼插入技術等,逃避使用字符串匹配與偏移或API 調用匹配的簡單簽名方法.針對該問題已經提出對抗逃避策略的動態或靜態分析技術,例如污點分析、代碼語義分析、動態分析等.文獻[87]提出采用統計性方法獲取常見的多個字符串作為簽名,這些簽名對于重排序和硬編碼都是健壯的,因此可以在一定程度上克服惡意代碼的對抗手段.
(2) 相似性代碼的片段提取.根據惡意代碼家族和作者的編碼相似性,惡意代碼的家族溯源中,以相似性行為代碼片段為導向,在編譯后的代碼中,提取同家族變體的相似性特征來識別同源樣本;惡意代碼的作者溯源分析中,在編譯后的代碼及其結構中,提取作者遺留的編碼習慣作為特征,來識別同源樣本.學術界常見的特征提取類型包括序列特征和代碼結構特征,見表5,在惡意代碼家族溯源或作者溯源中均效果明顯.然而因其溯源目標存在差異,所以兩種類型的特征在不同的溯源應用中表現不同.此外,權限特征和資源使用特征在移動平臺中廣泛采用.下面將揭示序列特征、代碼結構特征,權限特征和資源使用特征在溯源家族、溯源作者中的應用情況.

Table 5 Malicious code feature type表5 惡意代碼特征類型
1) 序列特征
常見的序列包括指令序列、字節碼序列、API 調用序列、n-gram 序列等.序列提取是一種語法分析方法,通過分析語法上不容易被混淆的序列作為特征.文獻[135]通過熵值評估和實證研究,提取統計性強的字節碼序列作為特征,這種特征在同家族惡意代碼中廣泛存在,即使該樣本被混淆,被混淆部分因發生變化很少出現在較多樣本中.然而,如果文件被嚴重混淆,則無法通過靜態分析方式獲取特征.動態分析可以克服靜態分析的此種缺點,文獻[136?139]利用動態分析,從系統調用序列中提取n-gram 序列作為特征.n-gram 序列相對于整個的API調用序列,在數據集中出現的次數更多,穩定性更強,因此該特征相較于API 調用序列具有較好的統計特性,可以用于檢測一般性混淆的變體.這些文獻均是針對家族變體的分析,API 調用序列、統計性強的字節碼序列反映了同家族的行為特征,可以在家族變體分析中使用.然而在基于作者的溯源分析中,不能單純依據代碼功能相似性提取特征,因為即使同一個作者或團隊也會編寫出不同家族的惡意代碼,但是特定類型的編碼習慣在編譯過程后保留在了二進制文件里,利用該類信息,可以執行二進制作者的溯源.文獻[102,140]均提取到了溯源到作者的特征,文獻[140]提取了7 類WinAPI 調用模式作為作者的編碼習慣特征,有效地溯源到了惡意代碼的作者.然而該特征是依據作者已有的樣本進行提取,依賴于已有的樣本數量.Caliskan-Islam 等人[102]使用Hex-Rays 反編譯二進制文件為類似于C 的偽代碼,基于該代碼構建模糊抽象語法樹,然后從語法樹中獲取可以表示作者編碼風格的語法特征,從而實現對惡意代碼作者的溯源.在惡意代碼的家族溯源和作者溯源中,由于惡意代碼的特征大多反映功能、結構信息,反映作者與作者關系的特征較少,因此在溯源作者的特征提取中能夠提取到的信息較少,且在學術界,針對作者的溯源文獻低于針對家族的溯源文獻.在序列特征提取中,統計性強的序列特征可以檢測到密切相似的數據對象,但檢測惡意軟件變體的能力要低得多,因此在同源性分析中,序列特征并不用于準確性匹配.
2) 代碼結構特征
代碼結構提取是一種從代碼邏輯結構提取特征的方法,該特征包含了程序的語義信息,屬于細粒度特征.常見的代碼結構主要包括API 調用圖結構、CFG 圖結構、PDG 圖結構等.代碼結構包含程序的行為語義信息,即使樣本的語法被混淆處理,只要語義相同,還是可以追蹤到.例如,文獻[146]采用PDG 作為代碼特征,通過計算兩個樣本間的相似性,可以有效地檢測復用或克隆惡意代碼,同時能夠抵抗多種類型的檢測逃避技術,例如語句重排序、插入以及刪除代碼等.雖然惡意代碼的代碼結構特征使得惡意代碼對抗性在檢測系統中作用變小甚至無效,但在基于代碼結構特征的同源分析中,常用的子圖同構算法是NP 問題,該問題使得系統計算復雜度變大.例如,文獻[142]提出加權的敏感API 調用子圖集,作為惡意代碼的聚類特征,并對該圖進行加權處理,對加權后的敏感API 調用圖執行同構計算,加大了系統分析的復雜度.為了消除該問題,文獻[133]提出利用卷積神經網絡對惡意代碼API 調用圖進行處理的方法,選擇關鍵節點鄰域構建感知野,使圖結構數據轉換為卷積神經網絡能夠處理的結構,消除了子圖同構帶來的問題.
相比代碼結構信息,序列信息會丟失惡意代碼執行過程中的某些空間特征.但是基于代碼結構的相似性分析由于要分析程序執行流程,因此復雜度比較高,效率得不到保證;同時,序列信息比圖結構信息更容易獲得,因此大多數研究者仍然采用基于指令序列或API 序列的特征進行研究[133].
3) 權限特征
權限是Android 系統的三大保護機制之一,在Manifest 文件中,聲明的權限很容易捕獲應用程序的數據使用意圖,可用于識別應用程序的惡意行為[152].權限特征提取屬于輕量級方法,避免了高成本的時間和計算,但是它只能捕獲應用程序的粗粒度功能,通常需要結合序列特征、代碼結構特征等使用,方能深刻地展示應用程序的行為信息.文獻[148]提出采用AXMLPrinter2 工具解析AndroidManifest.xml 文件獲取權限,并集合API 調用作為特征集合,用于Android 惡意軟件的靜態檢測,使用權限與API 結合的特征優于僅使用權限作為特征的分類結果,說明權限信息粒度較粗,API 信息有助于惡意軟件的分類.文獻[149]使用Android 惡意軟件的共同權限和描述文本的組合來估計權限的意圖,該方法克服了良性應用有意、無意采用類似的權限所引起的錯誤檢測問題,但是由于描述文本中的正面詞語并非強制性的,可以偽造且不會丟失任何惡意功能,因此它仍然存在對錯誤檢測和穩健性的挑戰.
4) 資源使用特征
資源文件的使用特征在移動平臺中應用廣泛,該特征主要是從APK 解壓后的resources.arsc 文件以及res文件中提取的信息.文獻[150]提出在重打包的APK 中,資源文件幾乎相同,資源文件的使用可以作為檢測惡意代碼變體的特征之一,在采用統計性強的字節碼熵作為特征的過程中,發現直接提取APK 文件的字節碼的檢測率,高于僅使用dex 字節碼的檢測.這主要是因為APK 文件中包含有大量的資源信息,而惡意代碼變種往往僅對原始惡意軟件中dex 中的代碼進行修改,對資源改變很少甚至無改變,因此采用包含資源文件的字節碼特征,更能夠有效地檢測到家族變體.文獻[151]提出傳感器類型和生成傳感器數據傳播路徑作為特征,以提供傳感器使用模式的概述,然后使用傳感器使用模式識別應用程序是否具有危害性.文獻[41]提出了結構不一致(structural inconsistencies)和邏輯不一致(logical inconsistencies)的資源特征,從而用于識別Android 惡意軟件的家族變體.但是文中的資源特征提取使用簡單的啟發式方法派生,沒有涉及程序/資源分析,因此效率較高;但是針對混淆而一般樣本的檢測問題,該文提出的資源特征不足以分析.
2.1.2 特征預處理
特征預處理在溯源分析技術中起到承上啟下作用:承上即對初始特征進行預處理;啟下則是為相似性計算提供基礎數據.提取的原始特征存在不具有代表性、不能量化等問題,特征預處理針對這一問題進行解決,以提取出適用于相似性計算的代表性特征.根據第2.1.1 節所述,常見的特征類型包括序列特征和代碼結構特征,其中,針對移動平臺的權限特征和資源使用特征,在具體的表現形式上也以序列特征和代碼結構特征為主,下面分析每類特征形式的預處理機理.
1) 序列特征預處理
常見的序列特征預處理方法包括信息熵評估、正則表達式轉換、N-grams 序列、序列向量化、權重量化法等.序列特征預處理使得初始特征中冗余特征消除、特征語義表達增強、特征量化等以便于進行相似性計算,具體描述如下.
· 信息熵評估
熵是包含在數據中的信息量的非常廣泛的量度,是提取穩定性特征的有用工具[153].根據熵值對特征的信息量進行評估,進而選擇出穩定性的特征序列.2016 年,Cheng Wang 等人[154]為了優化操作碼序列特征的精度和性能,提出了基于信息熵的特征提取方法來提取數量少但非常有用的信息,來表示惡意軟件實例.關鍵步驟如下.
(1) 在匯編代碼中選擇2-元組操作碼序列,見表6.
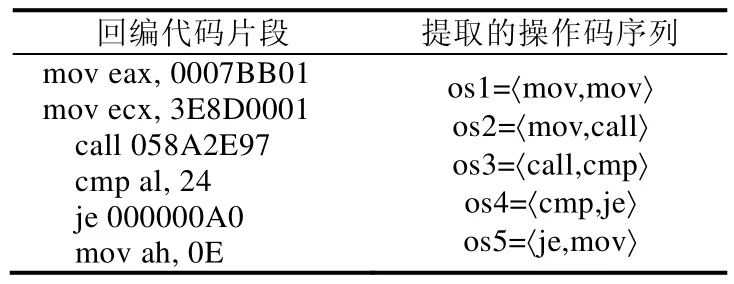
Table 6 Assembly code fragment example表6 匯編代碼片段舉例
(2) 利用變形信息熵計算操作碼序列信息熵,信息熵公式如(1)所示.
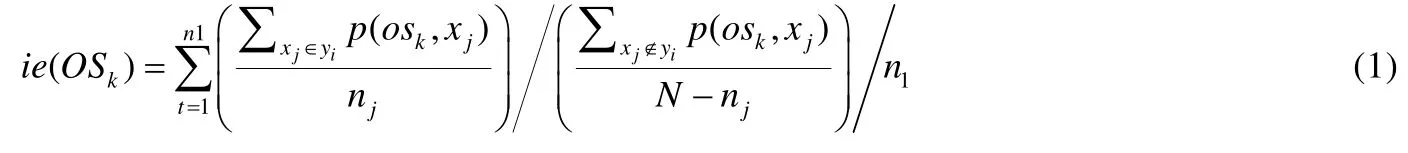
其中,p(osk,xj)表示惡意代碼xj中osk操作碼序列出現的概率,yi表示惡意軟件家族的數目,N為惡意代碼總數.設置閾值α,并將ie(OSk)>α的操作碼序列提取出來用于相似性比較中的特征數據.選擇具有高信息熵的操作碼序列作為惡意軟件實例的表示,結果表明:較少數量的具有高信息熵的操作碼序列,比大量的操作碼序列提供更好的準確性和性能,緩解了因操作碼多樣性導致惡意代碼的特征維度大的問題.
· 正則表達式轉換
正則表達式是由字符元素以及元素之間的組合組成規則序列,以用來表達對字符串的過濾.在序列的分析中,將序列轉換為基于序列元素和序列間關系的正則表達式,從而實現對符合正則表達式的惡意軟件識別.該特征是一種啟發式特征,可以識別事前未出現的惡意軟件.例如,L.Wu[155]通過分析惡意軟件敏感API 操作以及事件等,將API 序列特征轉換為正則表達式,并在發生類似的正則表達式模式時檢測惡意代碼,在最終的實驗結果中,證明基于正則表達式的方法可以檢測出部分新惡意軟件.
·N-gram 序列
N-gram 指由較大字符串分割出的固定長度的子字符串[156],例如字符串序列MALWARE,那么被分割出的4-grams 是MALW,ALWA,LWAR,WARE 等.IBM 研究小組最先將N-gram 方法應用于惡意軟件分析中[157],使用N-gram 的統計屬性可以預測給定序列中下個子序列.從惡意代碼提取n-gram 序列,一方面便于進行相似性計算;另一方面,基于n-gram 序列相比原始序列統計性更強,有利于對未知惡意代碼序列識別.文獻[158]提出對API 調用序列進行n-gram 處理獲取子序列,如果采用API 序列作為特征,此時序列相對較長,其他代碼(如附加功能)會添加到該部分;然而基于N-gram 的序列子集比整個API 序列的更穩定.采用n-gram 方法將API 調用序列轉換為n-gram 序列,具體過程如圖12 所示.
S1,S2表示初始特征API 序列,為了方便表示,將API 名稱用單個大寫英文字符表示,并基于該字符序列提取對應的n-gram 序列,該特征相比API 序列特征更短,且序列種類多樣化,在表達相似性上更具有代表性.但是n-gram 很難同時捕獲不同長度的序列,存在一個有意義的序列被拆開的可能,影響結果的準確性判定.
· 序列向量化
序列向量化是一種量化序列的方法,將具體的序列轉換為可進行計算的數學模型.通過量化分析,有利于進行重要特征的分析,提取出具有代表性特征.此外,量化的特征便于進行相似性計算.例如,文獻[158]以API 調用序列作為神經網絡分析的目標,經過分析,將一個惡意樣本歸屬到某個惡意軟件家族.API 調用序列是由具體名稱序列組成的序列,不能進行數學計算,因此在將提取的API 調用序列特征輸入到神經網絡之前會進行預處理,如果某個API 調用序列中出現2 次或2 次以上相同的API 調用子序列,則消除掉重復的子序列.然后采用one-hot編碼對序列中每一個API 構建唯一的二級制向量,該向量的長度等于不同API 調用的總數,將API 調用名稱構成的序列轉換為二進制向量序列.由于字典中一共包含60 個不同的系統調用,因此不會遇到任何特征向量大小的挑戰,實現了特征的量化表示,可以輸入到神經網絡進行運算.此外,基于神經網絡的訓練向量往往面臨維度高問題,文獻[159]初始產生基于字符串、3 元-API 調用組合、API-參數調用組合等3 種類型的特征0.5 億個,為了降低維度,作者提出采用隨機映射將輸入的特征維度降低了45 倍,進而使得高緯度的特征數據能夠高效地在神經網絡模型中訓練.序列向量化使得基于特征的數學計算變得可能,進而用于同源性分析的后續處理.

Fig.12 Conversion of API sequences to n-gram sequences圖12 API 序列轉化為n-gram 序列
· 權重
權重是一種統計分析方法,權重定義了特征重要性.文獻[160]提出計算API 調用、返回值、模塊名稱等動態特征向量的權重,以選擇重要的特征.由于權重特征本身的限制,該文構建了一種新的基于TF-IDF 的權重計算方法,如公式(2)所示.

其中,a表示惡意軟件變體;t表示惡意軟件特征向量;ω(t,a)表示樣本a中特征t的權重;TF(t,a)表示變體a中包含該特征t的數目占該變體中所有特征數目的比例;E[P(c|t)]表示特征t在不同家族中出現的差異.ω值越大,說明該特征越能表達樣本a的關鍵信息.根據該權重值可以選擇具有強分辨力的特征,即,具有高權重值的靠前特征被選擇,并采用Min-Max 對選出的特征向量進行歸一化處理.將該特征應用于集成學習算法的分類訓練中,并與現有的惡意軟件分析類方法,如卡方檢驗(chi-square test)[161]和主成分分析(principal component analysis,簡稱PCA)[162]進行比較,發現惡意軟件的分類工作比之前更加準確.
2) 代碼結構特征預處理
一方面,基于代碼結構的特征在相似度比較時存在邊、節點等匹配問題即子圖同構算法復雜性;另一方面,代碼結構特征中存在冗余結構,因此除去冗余、保留與惡意操作相關的代碼結構是預處理的主要目的.常見的結構圖包括API 調用圖、CFG 調用圖、PDG 圖等.本文將代碼結構特征中預處理機理闡述如下.
· API 調用圖預處理
API 調用圖是由圖中敏感API,根據前后調用關系建立的網絡結構圖.
為了消除圖相似性計算的復雜性問題,文獻[133]對調用圖特征進行預處理,以選擇API 調用圖中重要節點,具體為采用PageRank 算法計算API 調用節點的重要程度,但是在API 調用圖中,某個節點不需要用戶隨機訪問,因此使用PageRank 算法的時,需要考慮每個API 對惡意代碼行為的貢獻程度,結合PageRank 算法和貢獻程度實現對API 重要程度的計算;同時對API 進行分類,為不同API 設置不同的等級;然后計算各節點在圖中重要程度,從而選擇關鍵節點,構建出適合于神經網絡算法的輸入值.
2016 年,文獻[90]為了對抗重打包中正常代碼部分對惡意代碼部分的影響,以提取出更能代表家族惡意代碼部分的特征,在基于家族惡意代碼API 調用圖的基礎上,利用社區結構算法進一步提取API 調用圖的敏感頻繁子圖,并將其作為家族惡意代碼特征,特征的進一步細化使得系統對應用程序的識別速率提升,識別一個軟件的時間減少到了4.4s.
· CFG 圖預處理
CFG 圖以單個代碼語句為原子單位,細粒度地表示了程序的執行流程[163].面對其在圖同構方面的復雜性問題,文獻[124]采用Hyperion[164]二進制靜態分析工具,將惡意軟件的CFG 結構以正則表達式字符串的形式生成,正則表達式中包含匯編指令信息和程序的控制結構信息,使得基于圖的相似性匹配轉換為基于字符串的相似性匹配,解決了圖匹配帶來的復雜度.此外,文獻[165]提出采用Poulik 等人[166]設計的方法將CFG 轉化為基于一定語法的字符串,該方法抽象地表示了應用程序的信息,在抵抗代碼變換方面,比基于n-gram 特征表達的方法具有更好的抵抗性.文獻[167]提出CFG 與DFG 結合,轉化為矩陣形式用于CNN 模型訓練,在準確率方面取得了良好的效果,針對Marvin 數據集的檢測達到了99.649%,但是在召回率方面低于文獻[165].這可能是因為前者包含了數據流分析,匹配更加精準,使得漏報情況相對較重.
· PDG 圖預處理
PDG 圖是一種結合數據流和控制流分析的代碼結構,展現了敏感操作的依賴性,包含程序語義信息.但是該特征結構在匹配時是一種準確性匹配,因此計算復雜度比較高.文獻[168]對基于單個方法的PDG 進行預處理,將PDG 轉換為一組特征向量,并根據特征向量找到相似性引用程序集群.該方法對應用程序中所有方法進行處理以提取一組特征向量,當一組新的應用程序加入時,它需要與以前的大量特征向量再次進行比較,因此效率低下.但是需要檢測沒有任何先驗知識的未知惡意代碼時,該方法有效.
基于上述描述表明:在圖特征的預處理過程中,評估圖中的關鍵節點、非圖形化處理、排除圖中非相關子圖[169]均是對圖進行預處理,以消除圖相似性計算復雜度的有效方法,基于神經網絡模型的應用使得消除圖結構間的計算成為可能.在實際同源判定中,需要結合所構建的特征以及實際應用場景及目的,來選擇合適的特征預處理方案.
2.1.3 相似性計算
溯源的目是通過分析樣本的同源性定位到家族或作者,樣本的同源性可以通過分析代碼相似性來獲取.相似性計算旨在衡量惡意代碼間相似度,具體為采用一種相似性模型對惡意代碼的特征進行運算.根據預處理特征類型的不同以及溯源需求(效率、準確性等)的差異,采用不同的相似性運算方法.目前比較流行的相似性計算方法主要集中在對集合、序列、向量、圖等特征表現形式的處理.
1) 基于集合的相似性計算
集合是多個元素的組合,這是一種簡單的特征形式,常見的相似性計算方法為Jaccard 系數等.Qiao 等人[80]在不同惡意樣本API 集合的相似性比較中采用了Jaccard 系數方法,將為A,B兩個集合的交集在并集中所占的比例作為相似度,比例值越大,證明越相似,如公式(3)所示.

通過以上計算,將查詢點與待比較空間中的集合點進行比較,返回滿足條件的結果.該算法思想簡單,操作方面,在基于集合形式的特征中廣泛采用.
2) 序列形式特征的相似性計算
序列特征的相似性計算既要考慮序列元素的匹配,又要考慮序列的次序關系.2013 年,Faruki 等人[135]提出采用SDhash 相似性散列技術構建樣本的簽名序列,并采用漢明距離法對序列進行相似性計算,從而識別同源性樣本.惡意軟件通常會將其惡意負載隱藏在DEX 或托管為主應用APK 的資源文件中,文獻[163]從DEX 或APK類型的應用程序中提取所有可用資源中的片段構建特征序列,結合模糊Hash 和特征Hash 的方法[164]計算樣本之間的相似度.此外,也有研究者采用數據挖掘的方法進行相似性計算,例如,喬等人[140]利用頻繁模式離群因子計算基于 WinAPI 調用序列的相似性;文獻[143]將兩個字符串形式的簽名中公共的 LCS(largest common substring)長度占較大簽名長度的比值作為相似性值,此種方法是一種簡單的數學算法,計算復雜度低.
3) 基于向量形式特征的相似性計算
向量是一種基于維度的幾何表示方法,在相似性比較中,需要明確各維度的特征類別,使得不同樣本的特征向量中各維度具備一致性.文獻[170]提出基于指紋的特征,但該指紋是位特征向量,因此不能直接采用Jaccard相似度進行計算.為了計算兩個指紋之間的相似性,文中采用了位Jaccard 相似度計算代表相同內容的位特征向量之間的相似性.具體過程為:1) 計算兩個向量并集的基數,假設A和B是兩個位特征向量,那么兩個向量并集的基數是A+B,按位求并的結果向量中“1”的數目;2) 計算兩個向量交集中基數,仍然基于上述假設,兩個向量交集的基數是兩個向量按位交集結果中“1”的數目;3) 將交集的基數除以并集的基數即為位向量間的相似度值.Suarez-Tangil 等人[89]用數據挖掘算法中向量空間模型,展示家族的惡意代碼特征形式,將同家族提取出來的具有代表性的CFG 元素作為特征中維度,采用余弦算法對不同家族的向量空間模型進行相似度計算,根據余弦值來判斷它們的相似性,從而識別出相似性樣本,進而歸屬到對應的家族.用于比較向量的余弦相似度反映了惡意代碼間的相似性,其具體公式如公式(4)所示.
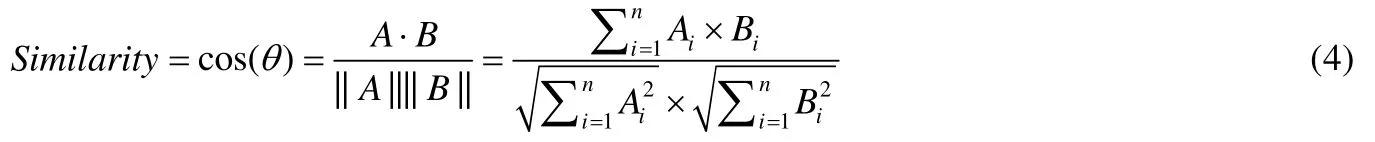
公式(4)中計算的相似性值在0 和1 之間,并且基于閾值確定相似性變體.該閾值與相似性分析結果的準確性密切相關,因此在現實世界中,如果要尋找惡意軟件變體,則需要嚴格制定閾值.
4) 圖特征的相似性計算
圖特征的相似性計算涉及到圖中邊和節點的匹配,復雜性比較高.文獻[171]提出采用的是最小距離匹配度量法,比較不同樣本的CFG 圖特征的相似性.Kinable 等人通過靜態分析惡意代碼的系統調用圖,采用圖匹配的方式計算圖相似性得分,該得分近似于圖的編輯距離.利用該得分比較樣本的相似性,采用聚類算法將樣本進行聚類,實現家族分類[82].Fan 等人[90]將API 調用圖的敏感子圖集作為特征,為了計算圖之間的相似度,文中自定義加權敏感API 子圖匹配方法來計算同源惡意行為的圖形之間的相似度,同時容忍較小的實現差異.文獻[105]采用兩個匹配——“Initial matching”,“second matching”和統計模型來計算樣本特征的相似性.在“Initial matching”中,匹配具有完全相同4 元組值的方法;在“second matching”中,遞歸地比較先前匹配方法的Parent/Child 方法的4 個元組值.Parent 方法是調用上一個匹配方法的方法,而Child 方法是由以前匹配的方法調用的方法.
基于上述描述表明:針對不同的特征形式可以采用同一種算法,例如,Jaccard 系數既可以用于集合形式的相似性計算,也可以用于向量等其他特征.此外,在實際的特征相似性分析中,往往由于特征形式的多樣性,會采用多種相似性計算方法結合使用.上述相似性比較方法中:基于集合的比較方法實現簡單,但沒有考慮變量間的相關性;而基于向量的相似性比較考慮了變量的位置關系,但是向量方法容易引起維度膨脹問題;基于序列的相似性比較考慮了變量的次序關系,但缺乏元素間的相關性分析;基于圖特征的相似性比較則考慮了變量間的語義相關性,但計算復雜度大,該特征往往用于需要精確匹配的場景中.上述相似性比較的粒度依次變細,在實際溯源分析中,需要結合應用需求,選擇合適的相似性計算方法.
2.1.4 同源判定
目前,學術界常見的同源判定方法主要包括基于聚類算法的同源判定、基于神經網絡的同源判定等.利用聚類算法操作相似性值獲取待測樣本同源度,同源度越高,溯源結果越準確.
1) 目前,在惡意代碼的聚類中,應用廣泛的聚類算法是基于密度的聚類算法、劃分聚類算法、層次聚類算法、近鄰聚類算法,具體見表7.
這里以DBSCAN 聚類算法[172]來闡述其聚類原理.DBSCAN 聚類搜索數據空間中密集區域,并與低密度區域分隔,低密度區域樣本被認為是“噪音”,因此被丟棄.DBSCAN 聚類一共包括4 個階段,步驟如下.
(1) 對于待測集合中尚未檢查過的對象p,如p未被處理過(歸為某個簇或者標記為噪聲),則檢查其鄰域:若包含的對象數大于閾值,則建立新簇C,將其中的所有點加入候選集N.
(2) 對候選集N中所有尚未被處理的對象q,檢查其鄰域:若至少包含閾值個對象,則將這些對象加入N;如果q未歸入任何一個簇,則將q加入C.
(3) 重復步驟2),繼續檢查N中未處理的對象,直至當前候選集N為空.
(4) 重復步驟1)~步驟3),直到所有對象都歸入了某個簇或標記為噪聲.

Table 7 Application of clustering algorithm in homology judgment表7 聚類算法在同源判定中的應用
圖13 描述了在訓練時間內子簇及其代表性樣本和對應的家族之間的關聯.實線方形框表示聚出來的家族,橢圓形框表示簇,橢圓形里面的刺邊圓圈表示簇中的代表樣本即簇中心.新樣本輸入時,將新樣本分別與已分類家族中的代表樣本即橢圓中的刺邊圓圈進行相似性計算,選擇相似性值排名靠前的樣本,通過同源決策(選擇相似性樣本的平均值,以最接近樣本的家族作為歸屬家族或者將選出的靠前幾個候選樣本交給人工分析等決策方法),歸屬到對應的家族.
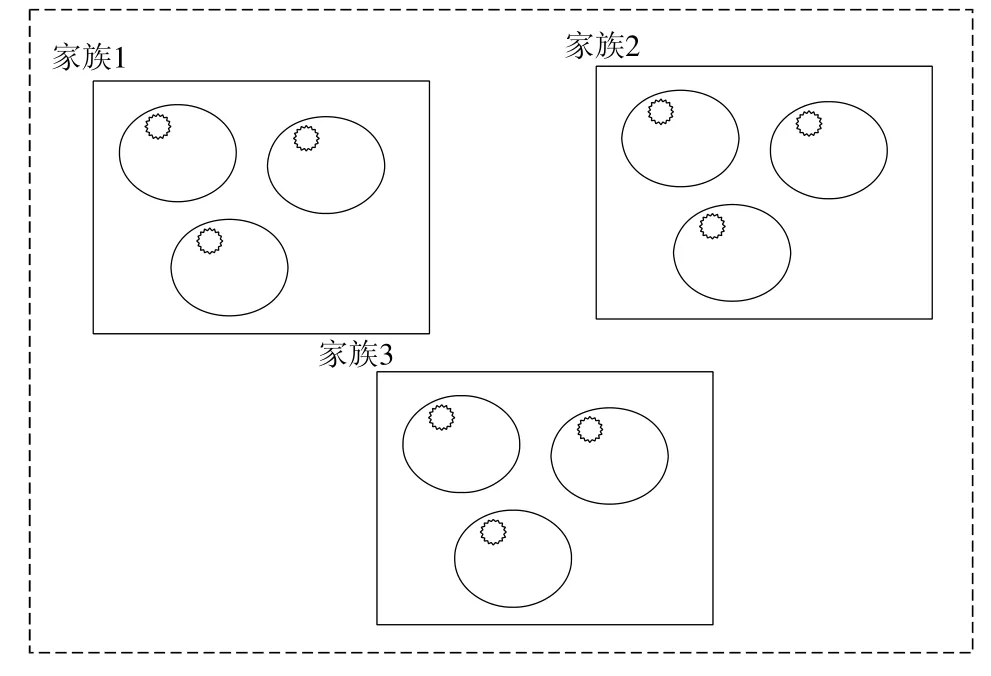
Fig.13 Abstracted cluster model圖13 抽象聚類模型
DBSCAN 聚類算法的優勢在于聚類時不需要事先指定聚類的簇數,可根據樣本之間的差異性將相似樣本聚為一類.此外,在該算法中,高密度區域可以是任意形狀,樣本不一定要圍繞單個中心,這符合惡意代碼演化、衍生的特點,適用于同源性惡意代碼的聚類.
基于聚類算法的同源判定一般步驟如下.
· 設置聚類閾值.
· 利用聚類算法進行聚簇運算,使得同一簇內的數據對象的相似性盡可能大;同時,不在同一簇中的數據對象的差異性也盡可能地大.
· 同源判定,如果同簇中屬于同一家族或同一作者的多;而同一家族或同一作者的樣本幾乎很少出現的不同簇中,則表明聚類出的模型同源性判定效果強.
2) 基于神經網絡的同源判定.
神經網絡是一種多層網絡的機器學習算法,可以處理多特征以及復雜特征的同源判定.基本思想為:將樣本特征作為輸入層數據,然后不斷調整神經網絡參數,直到輸出的樣本與該樣本是一種同源關系未為止.在測試過程中,將惡意代碼特征送輸入層,即可判斷惡意代碼的同源性.
趙炳麟等人[133]提出了基于神經網絡的同源判定方法,其整體實現框架如圖14 所示.
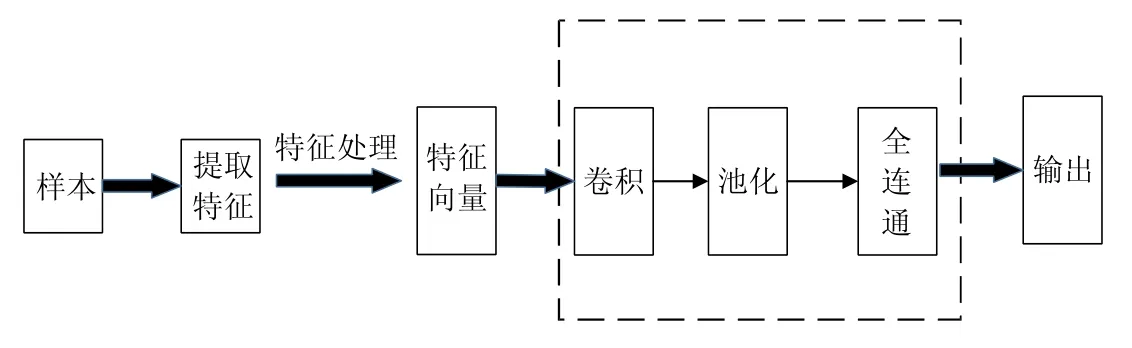
Fig.14 CNN-based homologous analysis model of malicious code圖14 基于CNN 的惡意代碼同源分析模型
下面描述具體實現過程.
· 采用靜態分析方法分析惡意代碼,提取其API 調用圖作為惡意代碼樣本的特征,該階段操作為圖14 中的“提取特征”.
· 選擇調用圖中的關鍵節點,使其能夠與卷積神經網絡的輸入匹配,該階段為圖14 中的“特征處理”.以關鍵節點鄰域構建感知野,使圖結構數據轉換為卷積神經網絡能夠處理的結構,設置一個統一的規則,使圖的鄰域到感知野是一條單射函數,從而保證具有相似結構特征和屬性的節點能夠映射到感知野的相似區域.這個過程是對關鍵節點及其鄰近節點的一個規范化的過程,至此,特征向量構建完畢.
· 將特征向量輸入CNN 模型進行訓練,直到模型處于穩定狀態.至此,基于CNN 的惡意代碼同源判定模型建立完畢.
· 對8 個家族的惡意樣本進行測試,實驗結果表明,惡意代碼同源性分析的準確率達到93%,并且針對惡意代碼檢測的準確率達到96%.
根據上述研究發現,基于聚類算法的同源判定過程為不斷調整聚類閾值、測試其同源性強度的過程.在該過程中存在以下問題:1) 圖特征的相似性計算是個NP 問題,計算復雜度大;2) 當出現多類型特征共存時,需要考慮不同類型特征帶來的影響,導致相似性判定模型變得復雜,影響同源判定結果.而基于神經網絡的聚類算法主要的運算是對其調參過程,只要特征滿足該神經網絡模型的輸入標準,即使包含多類型特征,依然可執行同源判定.
2.2 產業界惡意代碼溯源
產業界除了采用與學術界類似的同源判定方法之外,還會通過關聯的方法對惡意代碼進行溯源.
2.2.1 溯源意圖
產業界的溯源意圖除了溯源出編寫惡意代碼作者、惡意代碼家族之外,還要挖掘出攻擊者及攻擊者背后的真正意圖,從而遏制攻擊者的進一步行動.
2.2.2 溯源機理
產業界與學術界溯源方法的差異主要表現在特征提取和同源判定兩個方面:在特征提取上,產業界更傾向于從代碼結構、攻擊鏈中提取相似性特征;在同源判定上,除了采用與已有的歷史樣本進行相似度聚類分析之外,產業界還會采用一些關聯性分析方法.目前,產業界常見的溯源特征見表8.
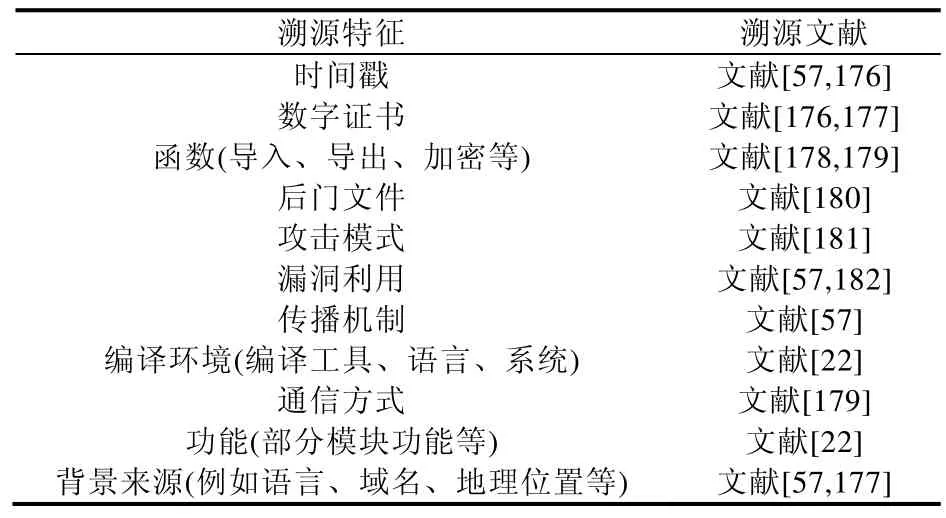
Table 8 Traceability characteristics of industry表8 產業界溯源特征
表8 展示了產業界溯源特征類別多,對溯源樣本的描述全面詳細,下面舉例闡述這些特征.
FireEye[176]實驗室于2013 年對APT 高級可持續攻擊進行分析,在攻擊所用的惡意代碼中發現了相同的代碼段、時間戳、數字證書等,收集惡意代碼中這些信息作為特征,基于這些特征進行關聯分析,認為攻擊均是由同一個組織操縱.
文獻[177]指出,將所有收集到的可執行文件的時區、時間戳作為溯源特征,根據特定標準分組統計,將統計出來的工作時間映射到攻擊者的時區,再根據世界時區分布圖,就可以定推斷攻擊者所在的區域或國家.
Mandiant 的研究人員通過文件的導入函數信息生成哈希作為特征,用于追蹤APT 攻擊的惡意代碼[178].
2017 年,McAfee 報告[180]指出,Appears 惡意軟件與Lazarus Cybercrime Group 有關,發現Appears 中包含一個ELF 格式的后門文件,該ELF 文件與已報告屬于Lazarus 網絡犯罪組織的多個可執行文件類似,因此判定該惡意軟件的作者是Lazarus Cybercrime Group.
攻擊模式主要指某些攻擊團隊特有的攻擊套路,并且長期專注于一個領域的攻擊.例如2016 年10 月爆發的Mirai 僵尸網絡[181]主要利用物聯網設備默認口令的問題感染大量設備,通過對其攻擊模式進行相似性匹配,溯源到對應的作者.
在“白象”組織最新的攻擊行動中[57],安天工程師對“白象組織”進行了追蹤分析,通過分析樣本中的系統賬號、開發編譯工具、樣本編譯時間等對黑客組織成員進行畫像分析;繼而對用戶ID 進行追蹤,并將ID 為“cr01nk zer0”的黑客關聯到了www.null.co.in 網站的一個發帖人,捕獲其郵箱等個人信息;同時,在多個論壇進行關聯,深入挖掘相關信息,最終確定其來源區域為東南亞某國.
啟明星辰[182]揭露海德薇(Hedwig)組織在利用文件漏洞攻擊的樣本中,樣本所利用的漏洞和內嵌的Shellcode 高度同源.例如,2012 年至2014 年攔截到的CVE-2010-3333 漏洞的shellcode 和2015 年攔截到的CVE-2012-0158 漏洞部分樣本的shellcode 功能、代碼完全一致.這些可以作為關聯分析的特征,進而溯源到黑客組織.
Gostev[22]花費2 個月分析Duqu 木馬,發現Stuxnet 與Duqu 所用的驅動文件在編譯平臺、時間、代碼等方面具有相似性,并通過關聯分析得出 Duqu 是 Stuxnet 先驅的結論.文獻[103]從代碼模塊著手分析,指出Patchwork 和Confucius 組織的Delphi 惡意代碼存在相似之處.
安天[57]對“女神”行動的溯源包括對C&C 的分析,發現“女神”攻擊樣本涉及到3 個域名,通過whois 查詢溯源到注冊人均來自同一個人,且注冊地為東南亞;此外,進行時間戳的分析關聯當時活躍的黑客組織,最終確定該攻擊來自于東南亞某國.此外,安天對“苦酒(BITTER)”行動進行C&C 分析,獲取攻擊郵件域名、偽裝樣本App、郵件和數據中“非常好的”英文等,并對這些信息進行關聯分析,推斷攻擊者的區域及特點.
2013 年曝光的“阿克斯(Arx)”組織利用0day 漏洞(CVE-2013-3906 等傳播Trojan[Spy]/Win32.Zbot 和Trojan/Win32.Dapato 惡意軟件.安天對從攻擊者樣本的時間節點、攻擊目標、傳播細節、相關的C&C 基礎設施的注冊信息等提取特征進行關聯分分析,發現“阿克斯”組織與“白象”組織并不存在明顯聯系,但是也來自東南亞某國[57],且攻擊大部分目標均為中國,這些組織具有相似的背景線索和特點,推測它們可能來自某國的不同組織.
安天對“白象二代”組織[57]的一名開發人員ID 為“Kanishk”進行關聯分析,發現中文翻譯為“迦膩色迦”,迦膩色伽是貴霜帝國(Kushan Empire)的君主,貴霜帝國主要控制范圍在印度河流域,此背景信息提供攻擊者潛在的來源信息.
上述案例主要從樣本、C&C 信息、背景來源等作為溯源特征關聯到攻擊者.相比學術界溯源特征,產業界溯源特征更加詳細全面,信息復雜度大.因此,學術界的同源判定方法并不能完全用于產業界各類特征的相似性分析中.通過對360 安全威脅中心[183,184]、火眼[185]、安天CERT[57]、綠盟[181]等公開的溯源素材進行分析,將產業界溯源方法分類見表9.

Table 9 Common malicious code traceability method in industry表9 產業界常見惡意代碼溯源方法
溯源方法已經在產業界廣泛使用,在實際溯源分析中,一般會結合關聯分析技術、畫像分析等溯源到攻擊者及真實意圖.例如,文獻[183]獲取C&C 服務器域名后,查詢其whois 信息,然后與貼吧信息關聯定位到攻擊者.文獻[184]中在獲得下載惡意代碼的域名信息后,利用360 威脅情報中心分析平臺擴展樣本信息,獲取歷史樣本信息以及與其相關的溯源報告,通過信息關聯定位出APT 攻擊者.綠盟[181]指出,2015 年,烏克蘭電廠遭受攻擊之后,攻擊者利用killdisk 組件銷毀了全部數據,在主機上沒有留下任何操作痕跡,最終通過全流量分析找到了溯源線索.FireEye 通過多重調查、針對端點和網絡偵測持續監控,并對APT28 組織的攻擊活動進行追蹤和畫像,最終確定APT28 是俄羅斯政府幕后支持的黑客組織[185].綠盟[181]在溯源關于攻擊者使用加密的SMTP 服務器竊取敏感信息的案例中,分析入侵日志,獲取到郵箱的用戶名與密碼,登陸攻擊者郵箱,在登陸郵箱后發現攻擊者真實郵箱,通過進一步的關聯分析,定位到了攻擊者.文獻[181]對樣本進行分析獲取時間戳,統計出相應的時區,推斷出攻擊者所在的國家,最后,基于互聯網上公開的信息進行關聯分析和畫像分析,確定攻擊組織.這些案例均是通過手動分析關聯惡意代碼攻擊者,雖然定位結果信息全面,但是效率較低,無法做到完全自動化地溯源.此外,從“白象”系列的攻擊中發現,中國大量基礎的信息安全環節和產品能力還不到位.“白象一代”以免殺PE 輔助有限的社會工程技巧,成功實施了攻擊,這是一種輕量級APT 攻擊;而“白象二代”雖然采用高級的對抗方法,但也未見其使用0day 漏洞,且所使用的漏洞是已經被修補過的,其中2 個漏洞也未經過免殺處理,但依然成功實施了攻擊.由此可見,當前,補丁、系統加固等基礎安全環節不到位、產品能力仍然不足.
3 惡意代碼溯源對抗
自從“GhostNet”幽靈網、APT1 等事件之后,近年來,全球范圍內各類網絡攻擊事件不斷被曝光,惡意代碼溯源手段和技術也在不斷發展,“白象”“海蓮花(APT32)”“摩訶草”等各類溯源分析報告陸續被公布.2017 年,美國有24 個研究機構[186]展開了APT 的相關溯源研究,發布相關研究報告多達47 篇;我國有4 個機構發布了8 篇報告,居全球第二.
惡意樣本、攻擊行為(攻擊者)、攻擊手段和渠道(攻擊者與攻擊事件的關聯)是溯源分析的關鍵要素,黑客組織為了盡可能消除溯源線索,目前從代碼、攻擊行為等多個層面采取了對抗措施.
(1) 代碼角度的溯源對抗:惡意開發者盡可能在代碼編寫生成階段消除(或偽造)溯源痕跡,或采用技術手段混淆甚至隱藏自身關鍵特征信息,避免特征信息的暴漏.
(2) 攻擊行為的溯源對抗:黑客組織采用精準定位、偽裝、隱藏(持續免殺或無文件運行)、自毀等方式,使得攻擊行為不被發現;在攻擊渠道方面,黑客組織采用代理、匿名網絡技術阻止對實際攻擊來源、渠道的追蹤.
3.1 代碼角度的溯源對抗
代碼的溯源對抗主要指攻擊者在惡意代碼發布之前,對代碼文件進行痕跡(如生成時間、時區、特殊字符串、語言、C&C 域名、團隊代碼特征、開發壞境等)消除、偽造或混淆處理,使得安全研究人員從中無法或者盡可能少地提取到有效信息.例如2017 年,安天移動安全分析團隊對Dvmap 病毒分析報告[187]顯示:該黑客組織故意隱匿APK 文件生成時間,在生成APK 時修改系統本地時間,導致解包APK 文件獲取到的生成時間為1979年.同樣在2017 年,維基解密公布Vault7 系列數百份文件中泄露,CIA 在惡意程序源碼Marble 中插入外語,嫁禍中國、俄羅斯等國.比如,將惡意程序中使用的語言偽裝為漢語而非美式英語,然后假裝掩飾使用漢語的痕跡,用于阻礙取證調查人員和反病毒公司將病毒、木馬和黑客攻擊行為溯源到CIA 身上.另外,大量使用加殼和代碼加固方案,也提升了代碼痕跡被提取分析的難度.
第1.1.3 節描述了編寫惡意軟件的對抗性方法,這些方法同樣使得從惡意代碼中提取同源特征信息變得困難.
以上這些措施不僅會妨礙產業界對單個樣本的人工溯源進度以及與其他樣本的關聯難度,同時也將給需要大量標注樣本的學術領域溯源研究帶來障礙.
然而,隨著主機行為監控[188]、惡意代碼API[91]、棧異常的shellcode 檢測[189]、敏感信息測量[190]、內核虛擬機防護[191]、解析殼[192]等各種安全防護機制的不斷出現,惡意開發者也開始對代碼進行了自我保護處理,使得代碼的解讀變得更加困難.
3.2 攻擊行為的溯源對抗
惡意軟件攻擊行為的溯源對抗主要指軟件運行后,攻擊團隊或惡意軟件自身進行的對抗行為,主要包括自身偽裝、持續免殺策略、攻擊定向性提升、控守網絡隱匿、攻擊載體隱匿等.
(1) 增強自身偽裝,提高人工分析溯源難度.
目前常見的偽裝程序分為重打包程序和區域性偽裝.重打包程序偽裝將惡意程序邏輯隱藏在合法程序的有用功能之后,且惡意程序只占重打包程序的小部分,致使系統調用[193]和敏感路徑[194]等特征在合法組件和惡意組件中無法區分,因此在惡意代碼檢測及惡意代碼家族變體識別時容易逃離.陳凱等人[195]為了識別出重打包惡意軟件,構建基于UI 界面結構和代碼方法層結構的MassVet,該方法在識別重打包惡意代碼方面取得效果,但仍然有限,特別是識別具有防御策略的惡意軟件.
區域性偽裝則往往與特定區域相關,主要是通過將特定區域的語言、域名、時區、組織等嵌入到偽裝程序中,從而逃離區域溯源.例如,2017 年6 月8 日,卡巴斯基[196]發布報告《Dvmap:The first Android malware with code injection》指出,該惡意軟件所包含的“.root_sh”腳本文件中存在中文注釋,推測其開發人員可能是中國人,但通過對其惡意樣本載荷向位于亞馬遜云的頁面接口回傳的數據進行分析,發現該頁面域名中包含“d3pritf0m3bku5”字樣,經分析為印度尼西亞方言;同時,對惡意樣本colourblock 的Google Play 市場緩存及全球其他分發來源的頁面留存信息關聯分析,得到Retgumhoap Kanumep 為該惡意樣本聲明的作者姓名,其姓“Kanumep”各字母從右至左逆序排列則為Pemunak,即印度尼西亞語“軟件”之意,融合多方證據證明,該黑客來源于印度尼西亞.
(2) 增強免殺手段,提高抗分析能力,提高安全軟件檢測難度.
惡意代碼的復雜度顯著增強,主要指惡意代碼開發的復雜性提升,以逃避查殺.2017 年,在高級攻擊領域[58],FinSpy 的代碼經過多層虛擬機保護,并且還有反調試和反虛擬機等功能;在2017 年4 月,Seduploader 的新版本增加了一些新功能,例如截圖功能或從C2 服務器直接加載到內存中執行,從而逃避惡意軟件的檢測.安天在《白象的舞步——HangOver 攻擊事件回顧及部分樣本分析》中指出,“白象一代”使用了超過500 個C&C 域名樣本,同時采用多種環境開發編譯,例如VC,VB,.net,Autoit 等,結合PE 免殺處理等手段,且在該次攻擊后,具有相關基因特點的攻擊載荷變少,說明黑客組織已經開始著手對抗檢測方法,并已經擁有對抗溯源的意識.而在2015 年的“白象二代”中,黑客組織使用了具有極高社工構造技巧的魚叉釣魚郵件進行定向投放、在傳播方式上不再單純采用附件而轉為下載鏈接、部分漏洞利用采用了反檢測技術對抗手段,初步具備了更為清晰的遠程控制的指令體系.“白象二代”相比“白象一代”的技術手段更為高級,其攻擊行動在整體性和技術能力上的提升,可能帶來攻擊成功率上的提升.
(3) 提升目標定位精度,增強攻擊定向性,降低樣本被捕獲幾率.
傳統的惡意代碼攻擊未分析目標特點,實行隨機性的最大傳播策略,這種機制容易暴漏自己.因此,為了避免被發現,攻擊者會盡可能地多了解攻擊目標,實施小范圍的攻擊活動,這樣可有效降低樣本被捕獲分析的幾率.例如海蓮花團伙的攻擊活動中,魚叉郵件的社工特性突出,體現為對攻擊目標的深度了解,例如樣本中的附件名:invitation letter-zhejiang ***** working group.doc,星號是非常具體的目標所在組織的簡稱,意味著這是完全對目標定制的攻擊木馬.2018 年,Confucius 黑客組織執行客戶端和服務器端的IP 過濾,僅對指定IP 地址進行破壞,如果受害者來自攻擊目標以外的國家,該程序將自行刪除并退出.這與2017 年底,來自該組織的C&C 不僅可以從任何IP 地址訪問,而且可以在不進行身份驗證的情況下,瀏覽服務器目錄樹,形成鮮明對比[58].
(4) 提升通信控制方式的隱匿性,提高攻擊者被溯源難度.
目前,惡意代碼通信方式更加隱蔽,體現在域名隱藏、IP 地址動態變化等.例如,海蓮花組織為了抵抗溯源開啟Whois 域名隱藏和并且不斷更換服務器的IP 地址,并使用DGA 算法生成動態域名,增加了安全分析人員定位有效服務器難度.海蓮花組織在最新攻擊中,攻擊者對采用的網絡基礎設施也做了更徹底的隔離,使之更不容易做關聯溯源分析[58].
(5) 通過無痕跡運行技術,隱匿攻擊代碼,提升攻擊代碼被定位難度.
近年來,無文件惡意代碼攻擊又開始逐漸引起注意.無文件惡意代碼沒有文件載體僅在內存中運行,該類軟件運行后不會在磁盤上留下痕跡,溯源檢測困難.比如,安天分析“女神”(Shakti)行動發現,其樣本運行時會在內存中解密一個dll 模塊并注入到瀏覽器進程中,這些dll 模塊都被直接注入到內存中運行,在磁盤中并無實體文件[58].趨勢科技[197]發現,木馬軟件JS-POWMET.DE 通過完全無文件的感染,完成整個攻擊過程,這種極其隱蔽的操作使得沙箱難以分析,甚至專門的安全分析師也難以察覺.
這種惡意軟件的出現已經表明,網絡犯罪分子將會使用一切手段來躲避安全軟件的檢測和分析.這在一定程度上說明那些不常見的無文件惡意軟件的感染方法也在不斷發展,即使安全研究人員能夠從內存中獲取代碼,調查工作仍然很難開展.
4 惡意代碼溯源面臨的挑戰和發展趨勢
嚴峻的網絡安全對抗和博弈形勢,使得對惡意代碼的演化與溯源技術的研究價值凸顯,學術界、產業界近年來分別從攻擊和防護[198,199]兩個方面展開了深入的研究.前文基于已有的研究總結了惡意代碼的生成過程和編碼特征,并對來自產業界、學術界惡意代碼的溯源機理和溯源對抗方法進行了詳細描述.目前,學術界和產業界在惡意代碼溯源技術方面取得了較大的進步,在追蹤惡意代碼組織、黑客組織(攻擊者)、發現未知惡意代碼方面取得了部分研究成果,例如海蓮花、白象、方程式組織等典型APT 攻擊計劃和黑客團隊的不斷曝光.但依然存在不足和挑戰.具體描述如下:
(1) 產業界惡意代碼溯源特征提取與分析的自動化程度嚴重不足.
目前,產業界的溯源分析過程主要基于人工分析手段,例如,Sasser 與Netsky、Duqu 與Stuxnet、Flame 與Gauss 等的識別工作均由相關安全專家人工分析完成,雖然分析結果詳細全面、可信度高,但受專家經驗影響較大,其效率較低.
這主要是因為溯源特征碎片化,特征提取位置不穩定,與此同時,惡意代碼作者采用大量的對抗技術應對自動化檢測與分析,使得特征自動化提取困難.這些困難都是目前自動化溯源分析面臨的重要挑戰.
(2) 編譯器及開源代碼復用給溯源工作帶來干擾.
一方面,大量攻擊程序源代碼被公開,開源項目及第三方庫如雨后春筍,這也導致目前很多惡意代碼在編碼階段開始進行大量的代碼復用;另外一方面,即便處理不同的復用代碼,編譯器也將自動插入大量相似代碼,這給基于代碼相似性的溯源分析帶來很大干擾.比如,文獻[200]使用VC6.0 和GCC-4.7.2 編譯了一個只包含用c語言編寫的主函數的源代碼文件,使用IDA pro 逆向二進制可執行文件,發現VC6.0 插入了103 個函數.而GCC-4.7.2 插入了18 個函數,不同編譯器插入的函數與函數插入的位置均不同,需要大量的經驗和技巧才能識別這些函數,這類函數對惡意代碼分析與同源判定工作造成干擾.如何有效排除公共復用代碼干擾,是后續需要解決的一個問題.
除此之外,即便是對于相同的病毒代碼,當攻擊者采用不同的編譯器、不同的編譯參數進行編譯時,最終生成的代碼特征也可能發生較大變化,從而導致原本同源的代碼被漏判.
(3) 溯源對抗和偽造手段將對溯源工作帶來嚴重挑戰.
目前,有效的惡意代碼溯源案例中,大多都依賴了類似特殊字符串、語言、控守地址、作者編碼心理、代碼風格、時間戳等極具個性化且易被偽造的低維特征.為了防止被溯源追蹤,目前部分惡意軟件作者和團隊已經具備溯源對抗意識并開始采用溯源對抗甚至偽造手段,這將對惡意軟件的溯源工作帶來極大挑戰.
(4) 惡意代碼溯源基礎庫缺乏,溯源分析效率低下.
提升溯源效率的第一要素,需要構建惡意代碼、代碼編寫者、攻擊團隊的代碼或行為基礎庫,否則,即便獲得以往攻擊樣本的變種,也很難快速獲得溯源數據支撐.
目前,在溯源基礎庫的構建方面還存在較多問題.
· 首先,在惡意代碼溯源特征庫構建方面,目前已有的惡意性判定特征和積累難以直接適用.目前,惡意代碼捕獲樣本數量多,但以往主要是以“惡意性判定”為目標來構建特征庫,但惡意性判定特征與惡意代碼家族聚類特征存在很大差異.
· 其次,在惡意代碼編寫者和攻擊者基礎庫方面,由于之前被定位的惡意代碼編寫者與攻擊者基礎數據少,這一工作還難以有效開展.
(5) 溯源攻擊者(代碼使用者)困難.
目前,針對攻擊者的追蹤主要發生在產業界,惡意代碼攻擊者的追蹤需要對攻擊者手段、攻擊者行為進行刻畫,同時需要結合攻擊意圖等關聯到攻擊者.攻擊意圖的分析需要結合多個攻擊樣本集分析其功能,同時了解黑客背景,例如黑客的活躍區域、擅長的攻擊手段等,構建攻擊行為演化趨勢,揭示出攻擊背后的真正意圖.然而在實際的攻擊中,黑客活動異常隱蔽,所暴露的活動只是很少部分,此外,嫁禍類攻擊日益增多,因此識別真正來自于某個組織的攻擊特點是溯源攻擊者的另一挑戰.
除此之外,攻擊者信息還依賴于跨境、跨國第三方平臺(論壇、Github、網盤資源)信息等,但是第三方平臺人員信息復雜、數量龐大,同時存在偽造信息的可能,因此,即使能夠追溯到攻擊者的部分信息,準確定位到個人還是需要進一步針對個人進行審查.
(6) 新型APT 攻擊溯源難度大.
目前,學術界和產業界在惡意代碼家族聚類[91]及溯源分析[189]方面主要依賴已知的惡意代碼,已知樣本量越大,溯源結果越準確.已有的惡意樣本為溯源變體提供了先驗知識,但如果僅根據已有的樣本來識別變體,將可能導致溯源工作低效甚至無效,特別是在應對APT 環境下的零日惡意樣本時.隨著APT 功能的復雜以及逃避技術的增強,已有的歷史數據無法檢測出高級的APT 攻擊.
(7) 產學研合作需要增強.
目前,學術界惡意代碼溯源分析方法主要采用學術界已有算法和相關理論成果,并輔以產業界公開的安全分析網站及報告等信息,樣本提取與標注數據嚴重不足,難以構建滿足現實溯源需求、切實有效的溯源分析方法.而產業界獲取的特征信息雖然詳細全面,但是缺乏良好的自動化特征提取模式與溯源關聯分析機制,更多的是借助于人工分析平臺輔以有限的信息自動化關聯,效率低下.產業界與學術界如何進一步加強合作,構建更加有效的溯源技術與體系,是今后發展的一個必然選擇.
在應對相關挑戰的同時,惡意軟件溯源研究與分析工作將得到系統化推動,溯源對抗技術也將在對抗博弈中得到不斷發展.對于后續發展,相關展望如下.
(1) 政府部門將在溯源基礎信息庫的建設工作起到主導作用,多方協同建設機制將被構建.
惡意代碼的演化衍生特性涉及軟件靜態特征、行為規律、家族衍生特性、作者編碼習慣、惡意軟件團隊特性等,這些是做好惡意代碼溯源分析工作的基礎與重要依據.
選擇合適的特征及特征粒度構建基礎庫特征模板,充分利用現有的惡意軟件信息庫以及程序自動化分析技術,構建融合惡意軟件靜態特征、行為規律、家族衍生特性、作者及團隊風格等的強大溯源基礎信息庫,是今后不可回避的一個研究和建設重點.
在溯源基礎信息庫的建設過程中,基于惡意代碼溯源工作的重要性與特殊性,政府部門必將起到主導作用,各大安全廠商、重要互聯網企業、各類重要信息系統所在單位等將作為重要支撐單位進行協同建設.比如,當前的各大反病毒廠商的樣本以及歸屬判定知識,將為基礎信息庫奠定重要基礎,同時由于其強大的樣本捕獲與分析體系,反病毒廠商也必將成為溯源基礎信息庫后續不斷完善的重要渠道.
(2) 網絡威脅情報庫建設與共享將進一步增強.
準確、及時的網絡威脅情報庫,是惡意軟件發現和溯源的另外一個重要基礎.目前,多個安全公司都構建了自己的網絡威脅情報分析平臺,如何有效地加強合作建設與資源共享,將成為國家網絡威脅溯源的重要基礎.
從建設內容上說,除了目前已有的威脅數據之外,來自暗網和攻擊第一現場的最新威脅情報、最新惡意軟件樣本、最新漏洞攻擊樣本以及代碼靜態和行為特征,都將成為網絡威脅情報庫建設的重要內容;與此同時,開源軟件平臺、典型網絡攻擊平臺和框架的公開資源也將成為網絡威脅情報庫構建時的重要來源.
(3) 溯源對抗措施將日益成熟和體系化,溯源質量和可信度將受到影響
目前,逃避溯源已經成為惡意軟件攻擊的一個重要考量因素.與此同時,產業界中基于低維經驗特征的溯源取證分析工作還將持續,人工分析在相當一段時間內依然是溯源分析的主要手段.
在此背景下,惡意軟件作者和團隊將投入更多精力在溯源對抗技術研發中,基于現有溯源機制的溯源對抗方法、框架和體系將會得到不斷成熟,相應的溯源偽造、干擾工具和體系將被構建.這不僅可以去除、混淆甚至能夠偽造溯源特征,這將對今后惡意軟件溯源分析報告的質量與可信度形成極大影響.
(4) 溯源痕跡偽造識別技術將成為惡意代碼溯源工作的重要需求.
隨著溯源痕跡偽造技術的不斷應用,現有的基于低維簡單溯源特征的溯源分析手段將難以發揮應有的作用.如何有效識別溯源偽造樣本,排除溯源偽造樣本形成的干擾,成為產業界溯源工作不可回避的重要任務,這也將成為學術界溯源分析研究的重要需求之一.
(5) 難以偽造的基于高層語義的溯源特征將被提出和構建.
細粒度的惡意軟件行為刻畫、代表攻擊本質的惡意軟件攻擊意圖重塑等,將可能成為對抗偽造溯源痕跡的重要依據與突破點.
(6) 多維度的溯源特征智能化解析機制將被構建.
隨著樣本特征庫信息量以及樣本分析粒度的不斷豐富,對惡意代碼的家族和來源認識將更加全面,在樣本細粒度分析與提取技術的不斷提升下,家族惡意代碼特征智能化解析將成為發展趨勢,各類惡意軟件溯源特征自動化分析平臺將被構建,進而可脫離對人工分析的過度依賴.而自動化解析機制的形成,也將進一步推動溯源基礎信息庫的構建.
(7) 基于智能化的惡意軟件自動化溯源定位機制將逐漸構建.
隨著惡意軟件家族聚類研究和溯源分析技術的不斷推進,以及惡意樣本的溯源知識庫的不斷完善,惡意代碼、團隊、作者溯源基因庫將逐步構建和細化,產業界與學術界將合作日益緊密.結合網絡態勢感知、數字畫像技術、大數據分析、機器學習、深度學習等技術實現的攻擊者自動化溯源定位機制將被構建和不斷推動.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22
海峽科技與產業(2016年3期)2016-05-17 04:32:12
