平面轉立體30模型智能轉換
2019-10-30 03:37:11技術宅
電腦愛好者 2019年6期
技術宅

傳統方法的不足
將現實場景轉換為電腦中的3D數據,這并不是一項新科技,比如已經在很多工作場景中出現的3D打印機,它可以通過掃描人體制作3D模型。但是這種傳統方法有著諸多不足,以3D人像采集為例,需要先通過3D掃描儀對人物進行立體式掃描,然后將掃描圖像導入3D軟件中制作成模型,再利用電腦進行3D渲染,最終才能獲得完整的人體3D數據(圖1)。
這種方式費時費力,在一些對3D數據要求較高的場景中,如VR游戲、自動導航等,需要對3D數據實時轉換,顯然傳統的3D數據捕捉是無法勝任的。
3D模型智能構建的背后
人工智能的發展,使得科學家們開始思考建立3D模型的新方法,當下較引人關注的,是對人工智能領域中計算機視覺系統及深度學習機制的應用。
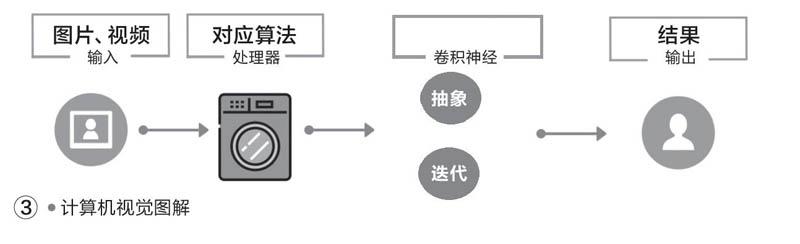
計算機視覺就是研究機器如何像人一樣“看”世界,通過攝像機和電腦來模擬人眼,對采集到的圖片或視頻進行處理以獲取相應場景的3D信息。除了會“看”之外,計算機視覺對采集到的信息還要能“識別”和“理解”,也就是在一組圖像數據中,判斷是否包含了某個特定的物體,比如一大片的紅色,到底只是一個紅色圓形圖案,還是一個飄浮的氣球。
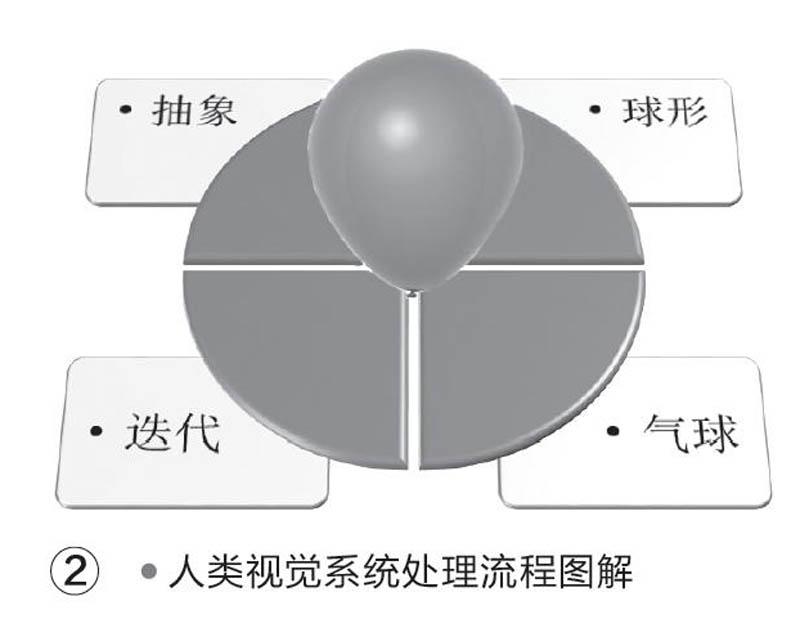
它的識別原理和人類的視覺相似,當我們通過眼睛感知一個事物(比如氣球),它首先被“平面化”成簡單的“球形”數據輸入大腦供我們進行識別,然后經過大腦一系列的“抽象”和“迭代”,最終將其理解為“氣球”(圖2、圖3)。
有了原理還要有實踐,為了讓計算機視覺系統能夠像人類的視覺一樣精確,科學家們還需要通過特殊的方式對該系統進行感知、識別和理解等一系列的訓練。
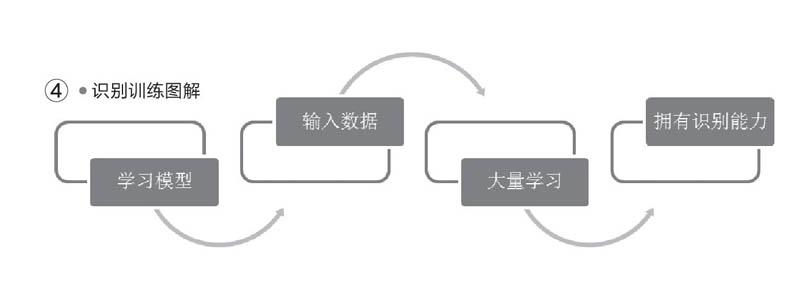
對于計算機來說,感知就是通過攝像設備進行數據的捕捉,然后轉換為數字信息讓計算機視覺系統感知到數據。識別則是對感知的數據進行甄別,比如把感知到的圓形物體識別為氣球或者籃球等物體。因為對于計算機來說,通過攝像機捕捉到的只是單純的“數據”,要想識別出這些數據代表著什么,就要進行深度學習訓練。上述氣球的例子中,科學家們準備了各種各樣的氣球圖片,讓深度學習系統進行識別訓練。通過大量的數據學習后,計算機視覺系統就可以在捕捉到氣球數據后準確地將它識別為“氣球”,而不是籃球或者足球(圖4)。
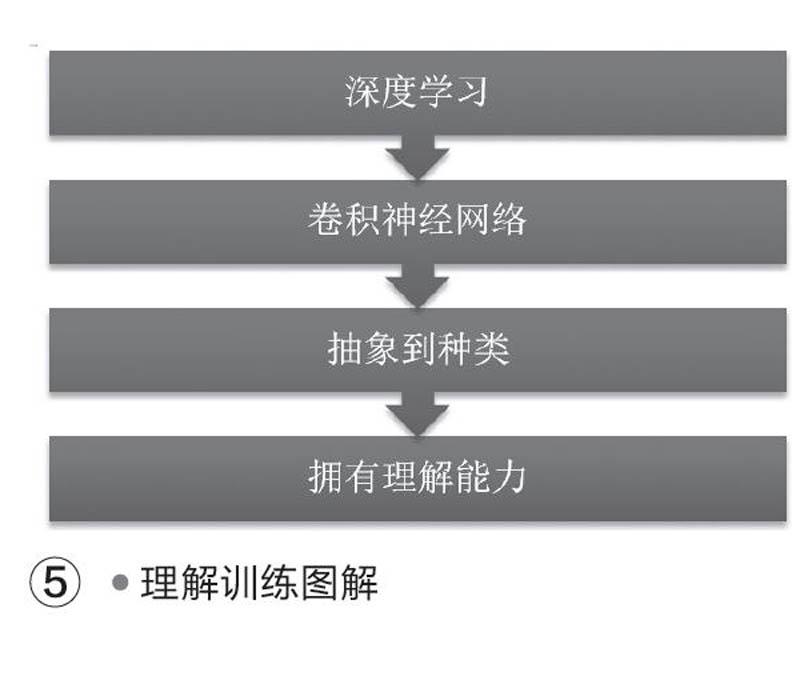
最后則是理解訓練,人類之所以能夠將看到的各種類似形狀的物體精準識別出來,依靠的是大腦的理解能力,大腦可以通過思考和知識積累,對看到的東西進行抽象化處理,從而實現對物體的理解。計算機視覺系統通過深度學習后已經可以識別出大量的物體,再結合卷積神經網絡把信息從最繁瑣的像素級別,抽象到“種類”的概念,這類似人類視覺功能的抽象和迭代,整個系統已經擁有人工智能的理解能力(圖5)。
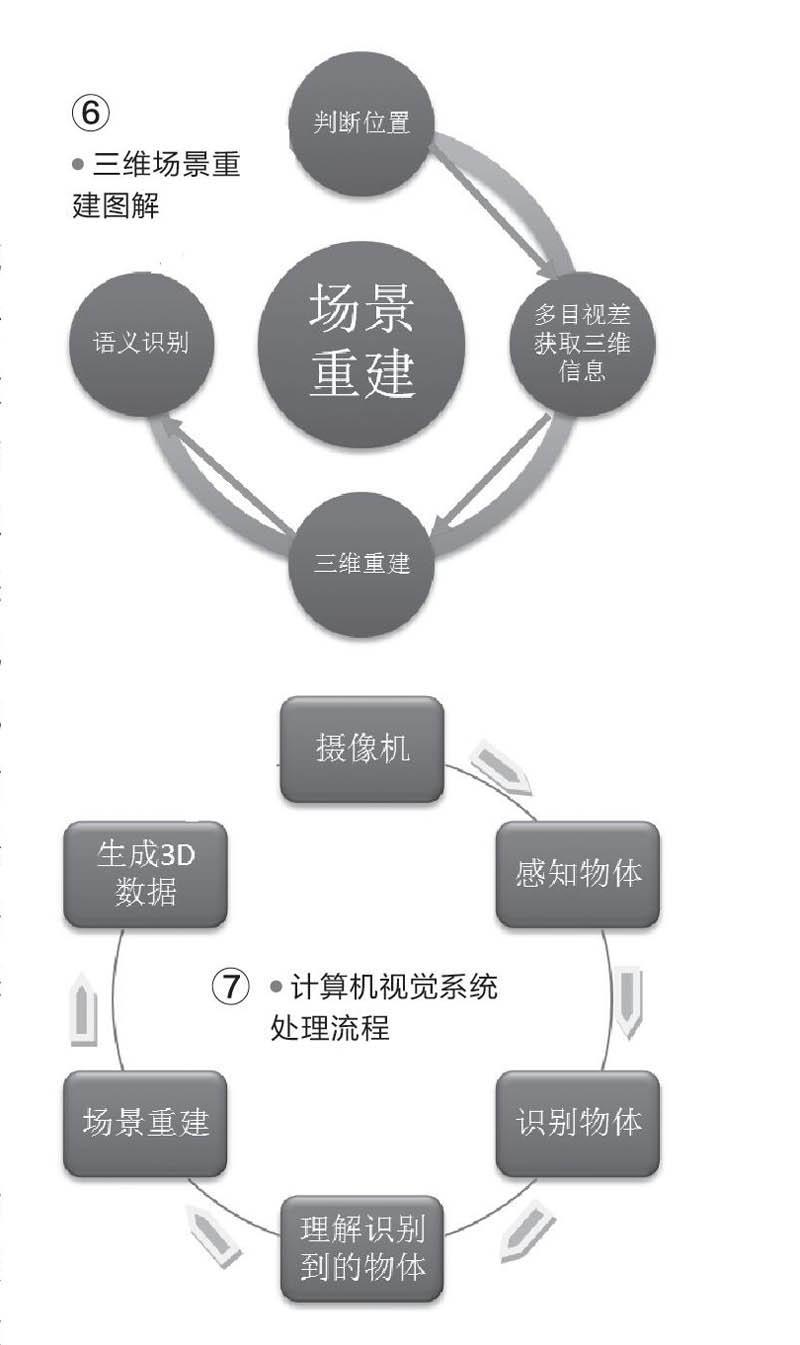
前面只是信息收集和分析的階段,真正意義上的計算機視覺系統不僅要識別和感知環境,還要將所感知到的環境在電腦中進行3D重建。3D重建首先要解決位置和角度的問題,3D場景中,身處不同的位置,看到的場景也就不同(本質就是感知的數據不同)。其次是兩眼視差的問題,不同的眼睛感知到的也是不同的數據,有視差才會有3D信息,并在此基礎上重建3D場景。最后就是語義識別,這是3D重建的終極意義,場景中所包含的不再只是無意義的像素的集合,而是有意義的獨立3D對象(圖6)。
總而言之,計算機視覺系統的整個處理流程就像是人類視覺系統,通過攝像機(眼睛)感知到周圍環境,接著通過識別系統對感知的物體進行甄別,最后通過理解能力準確識別出感知的物體,并借助場景重建生成3D數據,實現將平面物體智能轉換為3D數據(圖7)。
智能轉換3D改變你我生活
通過上述描述我們知道,利用深度學習計算機視覺系統可以快速、智能地將現實世界智能轉換為3D場景,這些應用可以給我們的生活帶來很多的便利,比如現在方興未艾的VR游戲和各種應用,借助VR攝像頭,計算機視覺系統可以將游戲者的周邊環境迅速轉換到VR場景中,讓游戲者有著更為真實的、無延遲的沉浸感(圖8)。
另一方面,該技術在包括人臉識別、指紋識別、圖像檢索、目標跟蹤等領域也有著非常廣泛的應用,在手機的人臉識別中,因為可以采集到人臉的3D數據,所以通過場景重建獲得的人臉3D模型,不僅識別率高,而且可以有效避免目前識別技術利用照片、視頻畫面來騙取識別的發生。
猜你喜歡
小學科學(學生版)(2021年7期)2021-07-28 06:44:42
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
科技傳播(2019年22期)2020-01-14 03:06:34
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
