基于雙耳語音分離和丟失數據技術的魯棒語音識別算法
2019-11-11 12:56:10周琳趙一良朱竑諭湯一彬
聲學技術 2019年5期
關鍵詞:信號
周琳,趙一良,朱竑諭,湯一彬
基于雙耳語音分離和丟失數據技術的魯棒語音識別算法
周琳1,趙一良1,朱竑諭1,湯一彬2
(1. 東南大學信息與工程學院水聲信號處理教育部重點實驗室,江蘇南京 210096;2. 河海大學物聯網學院,江蘇常州 213022)
魯棒語音識別技術在人機交互、智能家居、語音翻譯系統等方面有重要應用。為了提高在噪聲和語音干擾等復雜聲學環境下的語音識別性能,基于人耳聽覺系統的掩蔽效應和雞尾酒效應,利用不同聲源的空間方位,提出了基于雙耳聲源分離和丟失數據技術的魯棒語音識別算法。該算法首先根據目標語音的空間方位信息,在雙耳聲信號的等效矩形帶寬(Equivalent Rectangular Bandwidth, ERB)子帶內進行混合語音信號的分離,從而得到目標語音的數據流。針對分離后目標語音在頻域存在頻譜數據丟失的問題,利用丟失數據技術修正基于隱馬爾科夫模型的概率計算,再進行語音識別。仿真實驗表明,由于雙耳聲源分離方法得到的目標語音數據去除了噪聲和干擾的影響,所提出的算法顯著提高了復雜聲學環境下的語音識別性能。
空間聽覺;雙耳聲源分離;丟失數據技術;誤識率
0 引言
魯棒語音信號處理研究認為,實際應用環境和模型訓練環境的不匹配是造成了識別系統性能下降的主要原因,因此盡可能減小訓練環境和測試環境的失配,是當前魯棒語音信號處理系統的主要研究方向,常用的方法包括魯棒特征參數提取、特征補償和模型自適應等。
人耳聽覺系統在實際嘈雜環境下的感知能力是非常強的,BREGMAN[1]結合心理和生理聲學研究,分析人耳聽覺系統的雞尾酒效應,指出人耳聽覺感知過程可以分為兩個階段:第一,聲學信號的切分(segmentation)過程,第二,屬于同一聲源的感知成分的組合(grouping)過程,從而形成不同聲源連貫的數據流(coherent stream)。也就是說聽覺系統的感知過程,實際上是聽覺場景中不同聲源信號的重組織過程,混合聲信號中屬于同一聲源的分量組織到同一個數據流中,得到各個聲源對應的數據流,使得人耳聽覺系統可以區分不同的聲源。由此可見,包含目標聲源、噪聲和干擾的混合聲信號分離和重構是聽覺系統聲學感知和理解的基礎,也為語音信號和聲學信號的魯棒性研究提供了新的方向,因此我們從混合語音分離的角度來研究語音識別系統的魯棒性。
目前常用的語音分離方法包括:基于基函數的分離方法、基于模型的分離方法和基于計算聽覺場景分析(Computational Auditory Scene Analysis, CASA)的方法。基于模型和基于基函數的方法,在實際語音分離中的性能下降都是由于訓練環境和測試環境的不匹配導致的。而基于CASA的語音分離是根據聽覺系統對聲學事件的重組織過程實現不同聲源的分離[2],目前認為在CASA框架下,引入基于丟失、不可靠聲學信息的分類,可以規避訓練和測試環境的不匹配問題。通過對混合信號的時頻單元(Time-Frequency, TF)估計理想二進制掩蔽(Ideal Binary Mask, IBM),將其作為各個源信號的標識位,從而形成各個聲源對應的時頻單元,不僅可以解決欠定語音分離問題,還可以大幅提高噪聲環境下分離語音的信噪比、可懂度和識別率,因此基于CASA估計IBM已經成為CASA的主要目標。
CASA的難點是提取具有感知區分性的分離特征參數用于估計IBM,常用的分離特征參數包括:基音周期、幅度調制(Amplitude Modulation, AM)、幅度調制譜(Amplitude Modulation Spectrogram, AMS)、Gammatone頻譜倒譜系數(Gammatone Frequency Cepstral Coefficients, GFCC)[3]等。但是以上分離特征參數存在明顯不足,首先在噪聲環境下,基音周期估計的準確性受到影響,同時基音周期和說話人、說話內容關系密切,因此僅僅依賴于基音、諧波分量來切分和組合感知單元,會嚴重影響分離的效果。其次,基音周期、諧波可以用于濁音段的分離,但由于語音信號中的清音成分沒有諧波結構,且能量較小,更容易受到干擾,因此目前的CASA不具備分離清音的能力。
針對當前CASA的不足,本文對基于空間方位感知的雙耳語音分離進行研究,是基于以下考慮:首先,人耳聽覺系統的雙側聽覺神經系統能夠分析和整合同側、對側聲信號,根據雙耳聲信號,人耳可以檢測最多5個聲源信號;其次聲源的空間方位信息與語音信號內容、說話人無關,即使待分離的源信號基音、諧波特征與訓練數據不同,也能依據方位信息進行有效分離。
基于方位信息的語音分離具有以上優勢,目前有不少該方向的研究工作。YAO等[4]將雙耳聲源定位和盲源分離方法相結合,用于包含語音和噪聲的混合雙耳聲信號的語音分離。ANDRESA等[5]則在線性約束最小方差框架下實現雙耳聲信號的波束成形。ZOHOURIAN等[6]則利用耳間時間差(Inter-aural Time Difference, ITD)、耳間強度差(Inter-aural Level Differences, ILD)特征參數,基于最小均方誤差(Minimum Mean Squared Error, MMSE)準則進行雙耳聲源定位,在此基礎上,利用雙耳廣義旁瓣抵消器(Generalized Sidelobe Canceller, GSC)波束形成方法用于分離目標說話人語音。基于波束形成的不足就是這些方法沒有充分利用雙耳的空間特征信息。MUROTA等[7]針對這一問題,提出了對左、右耳聲信號利用不同的統計模型進行建模,再基于最小均方誤差譜幅度估計(Minimum Mean Square Error-Short Time Spectral Amplitude, MMSE STSA)對混合語音進行分離。
除了基于波束成形的語音分離,基于模式識別的雙耳語音分離也是主要的研究方向。KIM等[8]基于ITD、ILD的方差對頻點的掩蔽值進行估計,基于頻點進行目標聲源的分離。由于基于頻點的分離方法,容易受到噪聲和混響的干擾,會導致頻點分類的錯誤。HARDING等[9]在聽覺分析濾波器Gammatone子帶內利用ITD和ILD參數,基于直方圖的概率模型實現子帶分離。但要求測試聲源的角度設置,與訓練過程保持一致,否則會造成聲源分類的誤判。KERONEN等[10]、ALINAGHI等[11]利用高斯混合模型(Gaussian Mixed Model, GMM)對混合矢量(Mixing Vector, MV)、ITD、ILD進行建模,用于解決TF單元的分類問題,但混響對該類算法性能的影響較大。WANG等[12]將深度神經網絡(Deep Neural Networks, DNN)引入到語音分離中,將雙耳語音分離看成有監督的學習問題,并將空間特征線索從ITD、ILD擴展為雙耳互相關函數(Cross Correlation Function, CCF)和波束成形后的頻譜特征參數[13],用于訓練DNN。JIANG等[14]同時提取雙耳和單耳特征用于訓練每一個頻帶的DNN網絡,從而進行二值分類。YU等[15]則利用DNN對TF單元的雙耳特征線索進行建模,并利用雙耳房間脈沖響應(Binaural Room Impulse Responses, BRIR)與單聲源信號的卷積結果作為訓練樣本,這樣DNN對混響環境下的雙耳特征線索進行建模,但如果訓練階段使用的BRIR與測試的BRIR不匹配,會造成分離語音質量的下降。
基于GMM、DNN等模型的ITD、ILD子帶分離中,訓練和測試需要設置一致的目標聲源、干擾聲源方位,這一條件限制了算法的應用場合。針對這一不足,本文提出在Gammatone子帶內基于雙耳聲信號的相似度實現子帶的分離,在此基礎上,利用丟失數據技術實現分離后目標語音數據流的識別。本文利用Gammtone濾波器組首先對雙耳混合聲信號進行子帶分析,在子帶內通過雙耳空間特征參數ITD、ILD,基于雙耳間聲道的相似度,實現子帶目標聲源的掩蔽值計算,從而得到了目標聲源的數據流。分離后的目標聲源流在丟失數據(missing data)技術框架下進行丟失頻譜的估計和重建,用于語音識別。本文算法基于耳間聲信號的相似度進行目標聲源分離,避免了對目標聲源、干擾聲源方位角度的限制,同時本文僅利用雙耳空間特征進行目標聲源分離時,當目標聲源、干擾聲源為語音信號時,也可以實現準確的語音分離和識別。針對不同類型、不同方位的噪聲環境下的仿真實驗表明,本文算法的識別性能均有明顯提升。
1 基于空間分離和丟失數據的語音識別系統結構
本文提出的基于雙耳語音分離和丟失數據技術的語音識別算法結構如圖1所示。針對雙耳聲信號,算法包括訓練和測試兩部分。測試階段,雙耳聲信號經過Gammtone濾波后,根據目標語音的方位角,在每個子帶內計算掩蔽值,用于混合雙耳聲信號的分離,得到目標語音的數據流后,通過丟失數據技術進行目標語音識別。
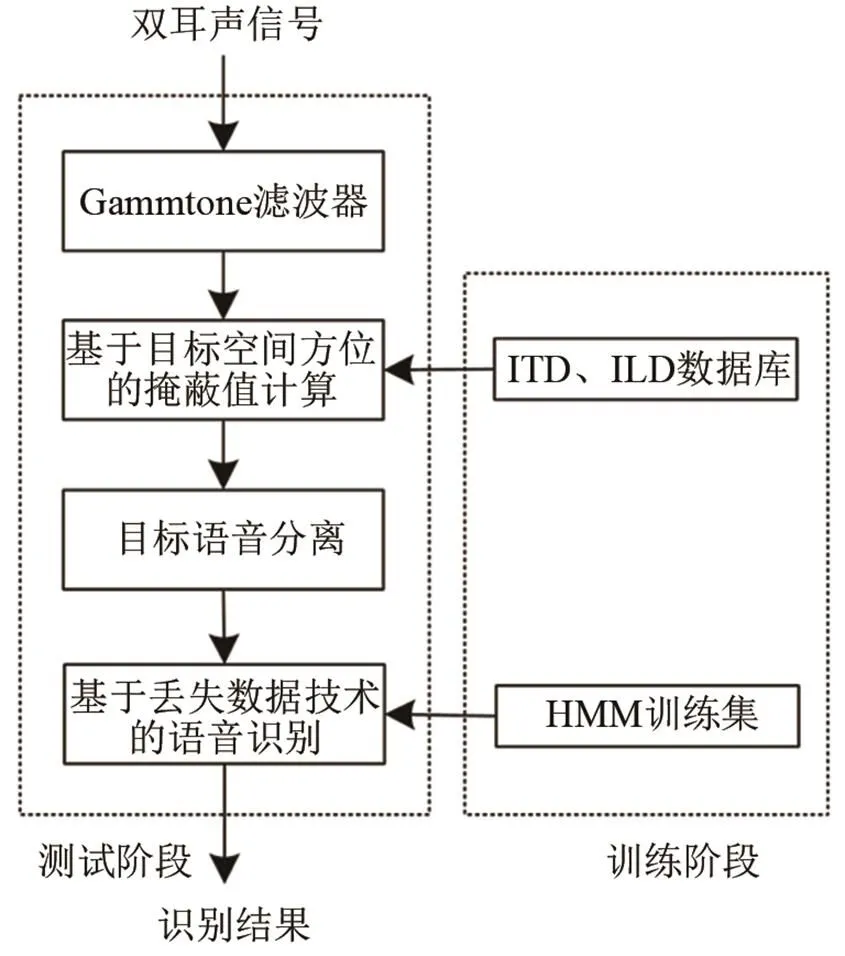
圖1 基于雙耳聲源分離和丟失數據的語音識別算法結構框圖
1.1 基于空間方位的雙耳語音分離
根據圖1的算法結構,訓練階段利用頭相關脈沖響應函數(Head Related Impulse Response, HRIR)與單聲道白噪聲信號進行卷積,得到[-90°, 90°]方位角范圍內間隔為5°的方向性雙耳聲信號,這里-90°表示正左方,0°表示正前方,90°表示正右方。訓練時采用的方向性雙耳聲信號只包含特定方位的單個聲源,用于建立每個方位角對應的ITD和ILD數據庫,其中ITD定義為雙耳聲信號互相關函數最大值對應的延遲:
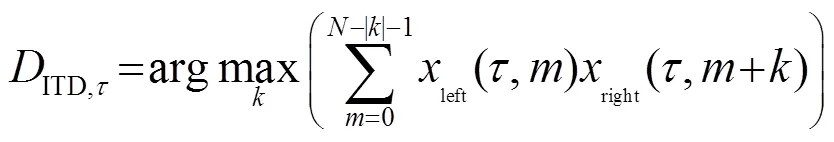
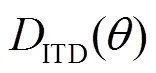


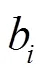
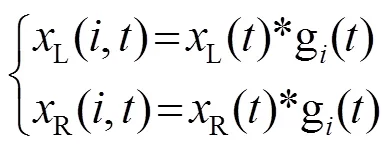
由于語音信號在頻域具有良好的稀疏性,并且人耳聽覺系統具有掩蔽效應,我們將不同聲源信號的頻點離散正交性[16]擴展到子帶正交性,即用表示第個聲源、第個子帶信號的傅里葉變換,則在第個子帶內,不同聲源的聲信號滿足:
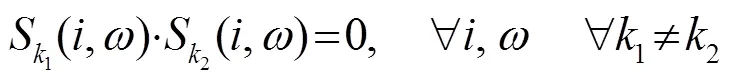
根據子帶正交性條件,在任意一個子帶內,至多只有一個聲源信號占主導。以右耳信號為例,子帶內的混合信號可做近似為
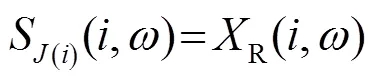
對第個聲源建立二值掩碼:
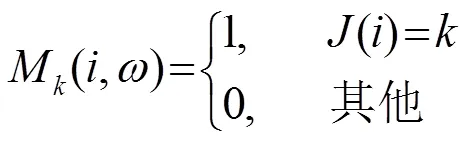
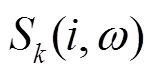
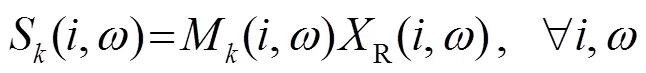
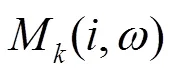
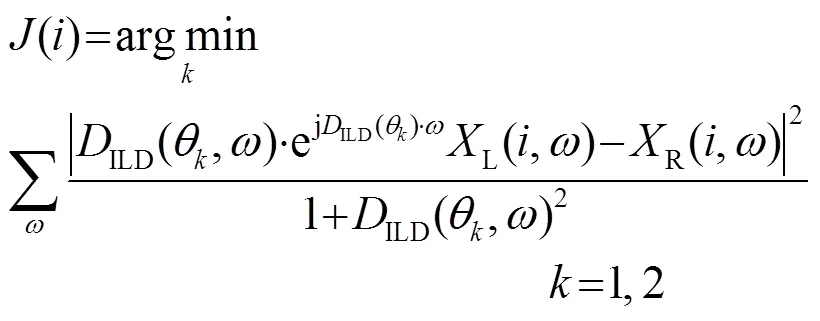
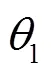
1.2 基于丟失數據的語音識別
由于本文利用Gammtone濾波組對雙耳聲信號進行子帶劃分,得到目標語音對應各個Gammtone子帶的頻域信號,因此選擇基于Gammtone子帶頻譜的RateMap參數作為HMM語音識別的特征參數,RateMap定義為每個子帶信號1(,)的均值組成的向量。
基于HMM的語音識別利用GMM模型對每個狀態的RateMap參數進行建模,假設GMM包含個高斯分量,協方差矩陣為對角陣,則某一狀態下RateMap的概率密度函數表示為
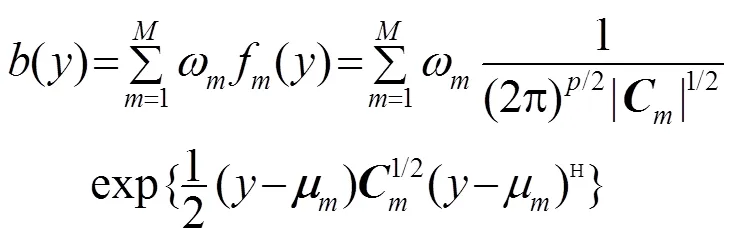
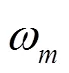
由于RateMap特征參數存在丟失的問題,直接利用丟失數據技術[17]對式(10)進行修正,其中邊緣概率方法直接忽略丟失的特征參數,則式(10)可改寫為
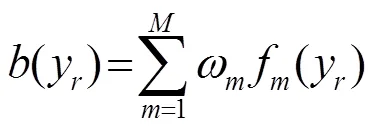
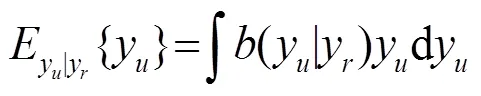
根據Bayes準則:
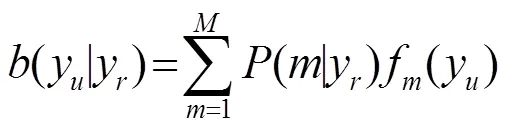
其中:
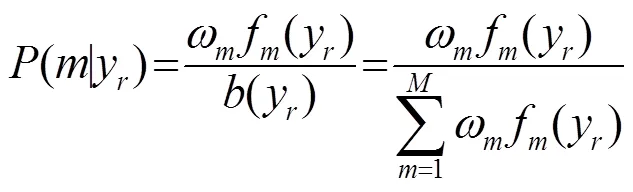
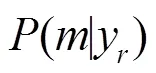
將式(13)代入到式(12),得到:
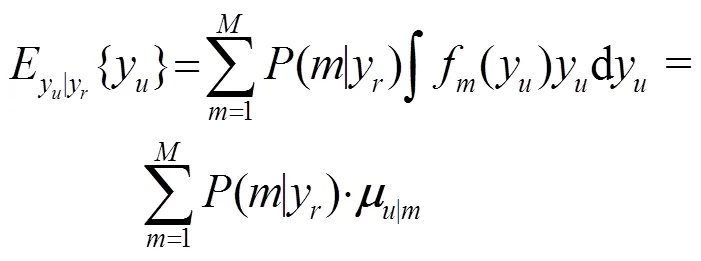
整體而言,本文算法利用Gammtone濾波器,對包含干擾信號的混合雙耳聲信號進行子帶分析,在頻域上根據目標語音的方位信息,基于式(9),獲取目標語音的子帶數據。根據目標語音的子帶信號,計算對應的RateMap參數,并針對RateMap存在特征參數丟失的情況,根據式(11)對HMM的概率計算進行修正,或者利用式(15)對丟失特征進行估計,再通過常規的HMM方法進行識別,得到最終的識別結果。
2 基于MATLAB平臺的雙耳聲源分離和丟失數據的孤立詞識別性能分析
2.1 仿真實驗參數設置
基于HMM的孤立詞識別系統,本節詳細分析基于雙耳聲源分離和丟失數據技術的魯棒語音識別系統性能。本文選擇TIMIT語音庫[18]中的21個單詞作為孤立詞,將每個孤立詞的144個樣本用于訓練,71個樣本用于測試,這樣共有3 024個樣本用于訓練,1 491個樣本用于測試。樣本采樣率為16 kHz,Gammatone濾波器組通道數為64,對應的中心頻率取值范圍為50~8 000 Hz,濾波器的階數取4。每個孤立詞的RateMap參數采用對應的HMM模型,狀態數為10,每個狀態包含8個高斯分量。
由于本文算法是基于混合聲信號中不同聲源的空間方位,實現目標語音的分離,因此需要得到不同空間方位的雙耳聲信號,這里通過將單聲道的源信號和對應方位的HRIR進行卷積,得到對應方位的左、右耳雙耳聲信號,生成過程如圖2所示。
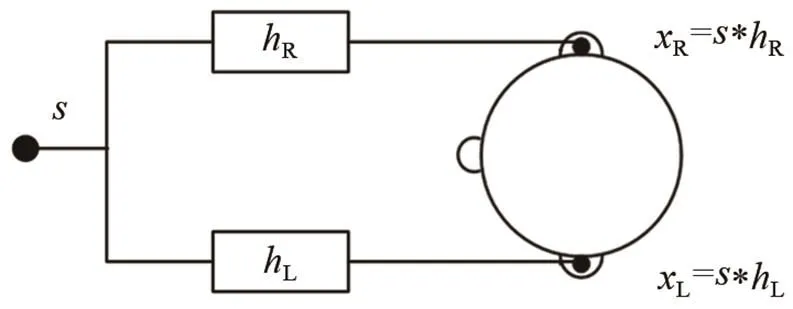
圖2 方向性雙耳聲信號生成過程
基于HMM的孤立詞識別系統對方位角為0°的目標語音進行識別,這樣測試聲信號的特征參數包含了0°方位角的空間信息。相對應的,圖1中訓練階段,HMM模型集采用的同樣是方位角為0°的訓練樣本。
本節的仿真實驗主要分為兩部分,首先分析干擾聲源為噪聲信號時,本文基于雙耳聲源分離和數據丟失的語音識別系統性能,采用NoiseX92[19]中的白噪聲、工廠噪聲和粉紅噪聲。其次分析干擾聲源為語音信號時,本文所提算法的性能,干擾語音選擇了CHAINS Speech Corpus[20]語音庫SOLO中的一段女聲語音。測試時按不同的信噪比將測試樣本集中的目標語音與干擾噪聲、干擾語音進行混合,信噪比(Signal Noise Ratio, SNR)取0、5、10、15、20 dB。兩類仿真測試過程中,目標語音的方位角均為0°,干擾噪聲、干擾語音的方位角分別設置為30°、60°、90°,目標語音和干擾信號的方位角分布如圖3所示。
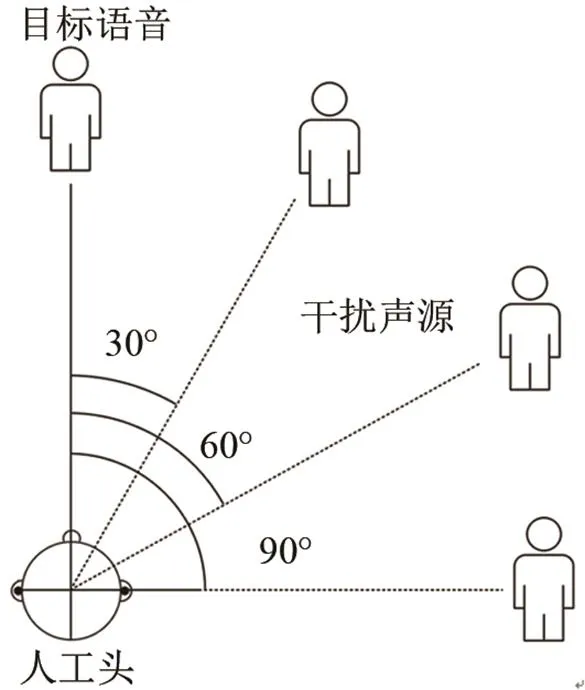
圖3 目標語音與干擾聲源的方位示意圖
由于丟失數據技術分為基于邊緣概率的方法和基于數據估計的方法,因此本文分別對基于雙耳聲源分離和邊緣概率的孤立詞識別算法、基于雙耳聲源分離和數據估計的孤立詞識別算法性能進行分析,采用誤識率(Word Error Rate, WER)作為識別系統性能指標。同時我們為了考慮系統性能的上限,給出子帶分離的理想掩蔽值(也稱為理想掩膜)。理想掩蔽值直接根據每個Gammatone子帶內的目標語音和干擾聲源的能量,計算對應的信噪比獲得局部判決值(Local Criterion, LC),通過設定LC閾值對每個子帶進行目標語音的分類:
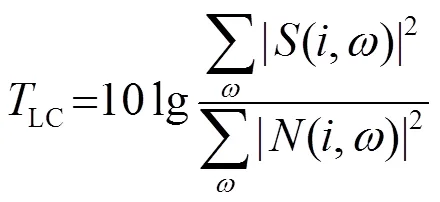
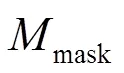
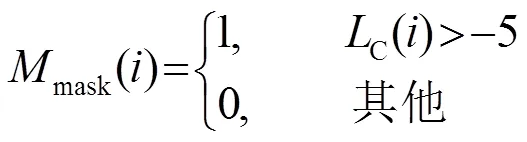
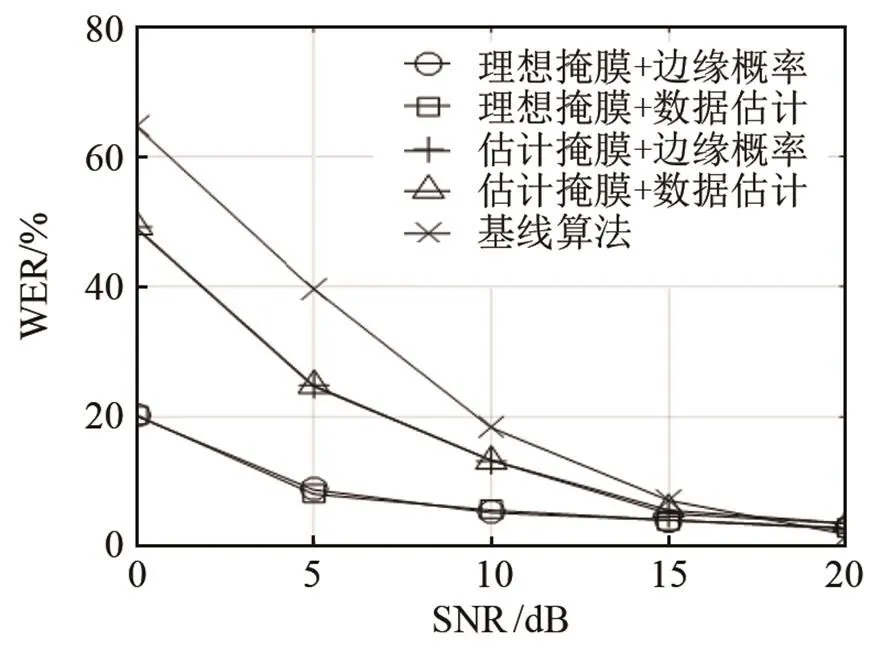
我們將基于MFCC系數和HMM模型的識別系統作為基線系統,因此本文比較三種識別算法的性能:基線系統、基于雙耳聲源分離和丟失數據技術的識別系統、基于理想掩蔽值的雙耳聲源分離和丟失數據技術的識別系統。
2.2 實驗一:干擾為噪聲的仿真結果
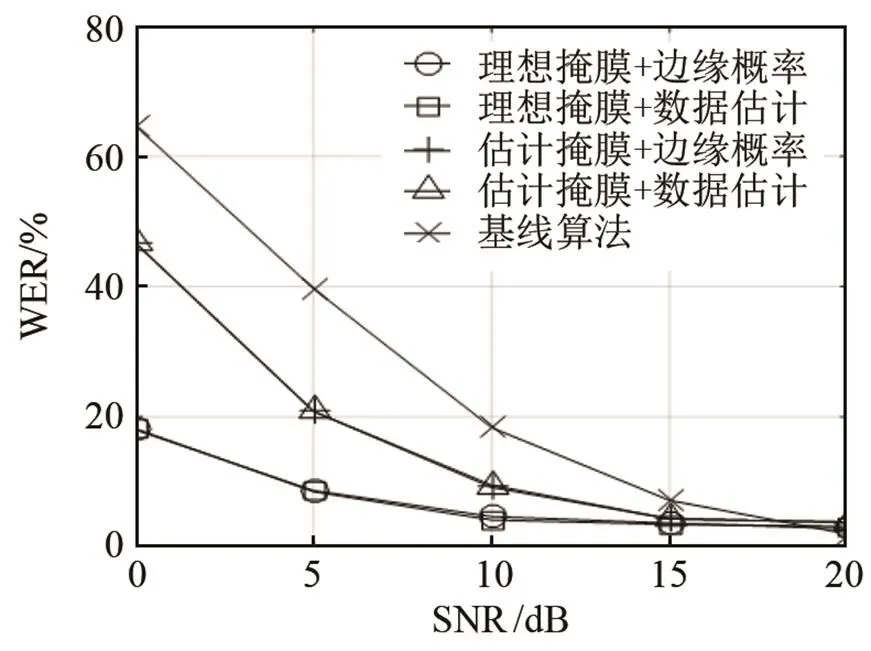
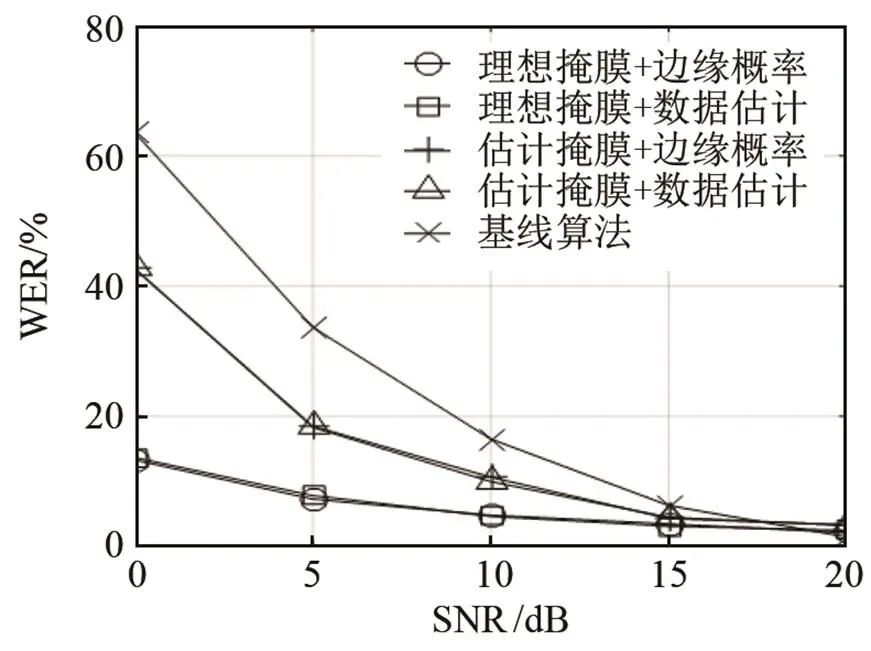
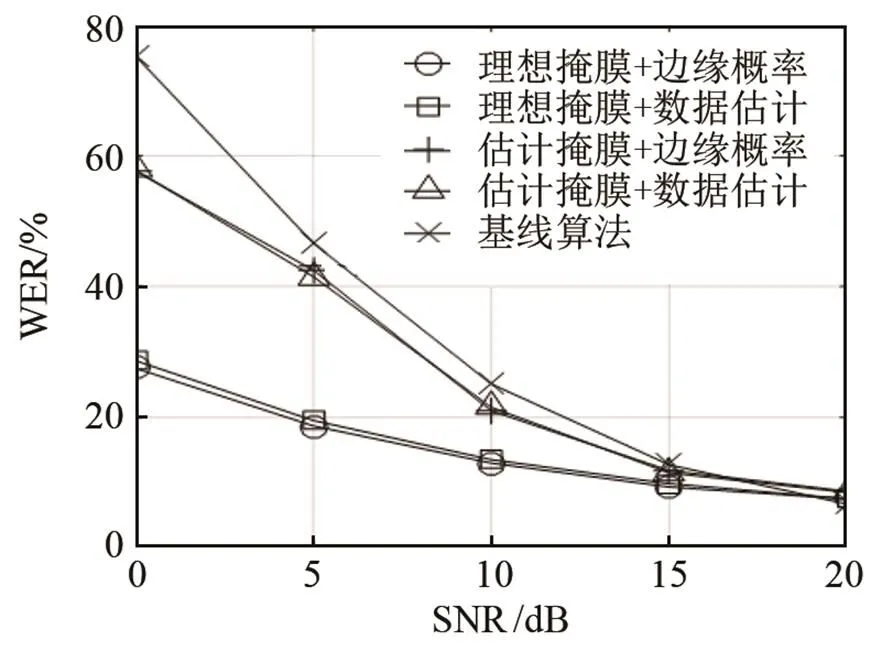
首先給出干擾分別為白噪聲、粉紅噪聲和工廠噪聲時,不同信噪比(Signal Noise Ratio, SNR)時,不同識別算法的誤識率結果,如圖4~6所示。針對每一類噪聲,圖示自上而下分別表示噪聲在30°、60°、90°的誤識率WER比較結果。
首先根據圖4~6的仿真結果,不同類型噪聲條件下,本文算法的WER均低于基線系統。同時,信噪比越低,本文算法的性能改善越明顯,這是由于信噪比越低,基線系統的語音特征參數受到的噪聲干擾越嚴重,而本文算法利用方位信息分離出的目標語音數據,受到噪聲的干擾明顯減少。
(a) 干擾噪聲位于30°
(b) 干擾噪聲位于60°
(c) 干擾噪聲位于90°
其次,對于同一類型的噪聲,目標語音與干擾噪聲的空間方位相隔越大,即干擾噪聲的方位從30°變化到60°、90°時,本文算法的性能改善越明顯。這是由于目標語音和干擾噪聲的空間方位間隔越大,各個子帶內,不同方位聲源的雙耳聲信號ITD、ILD的差異性逐步增加,從而提高了子帶分類的正確率,進而改善了目標語音數據流的識別率。
再者,不管是基于理想的掩蔽值,還是基于估計的掩蔽值,掩蔽值分離后的目標語音采用邊緣化概率方法和采用數據估計方法,進行孤立詞識別時的誤識率基本一致。相比較而言,邊緣化算法略優于數據估計算法的識別性能,這是由于邊緣概率算法避免利用單一估計值來表示不可靠分量,相反,它只考慮丟失特征參數的分布,而數據估計技術更依賴于特征參數的統計概率分布而不是數據的可靠性,其優勢在于可以得到完整的語音特征向量,從而可以采用常規的識別算法。
在干擾為噪聲時,基于理想掩蔽值的孤立詞識別性能要優于基于估計掩蔽值的識別性能。這是由于理想掩蔽值對目標語音子帶的判決更加準確,分離后的目標語音數據流基本只包含目標語音成分,因此理想掩蔽值對應的識別系統性能可以作為基于空間分離的識別系統上限。根據圖4~6,本文算法的識別性能和基于理想掩蔽值的識別系統性能存在一定的差距,根據我們目前的研究發現,當混合雙耳聲信號中包含了兩個以上的聲源時,ITD、ILD的聯合分布與單聲源的ITD、ILD分布有較大的差異,混合雙耳聲信號僅僅利用歐式距離進行分離,其子帶分類的準確性受到限制。因此提高混合雙耳聲信號中子帶分類的正確率,可以顯著提高后端識別系統的性能,即基于雙耳聲源分離和丟失數據的孤立詞識別系統性能還有較大的提升空間。

(a) 干擾噪聲位于30°
(b) 干擾噪聲位于60°
(c) 干擾噪聲位于90°
(a) 干擾噪聲位于30°
(b) 干擾噪聲位于60°

(c) 干擾噪聲位于90°
2.3 仿真實驗二:干擾為語音的仿真結果
目前常用的魯棒語音識別算法如特征補償、模型自適應等,對提取的純凈語音特征參數采用HMM、GMM等進行建模,測試環境中的噪聲影響了HMM、GMM等模型參數分布,例如概率模型的均值向量和協方差矩陣,通常采用線性方法對噪聲干擾后的模型參數分布進行預測。但當干擾為語音信號時,例如有兩個或者多個說話人時,由于干擾語音的特征參數與目標語音的特征參數分布相似度高,那么干擾語音對目標語音特征參數模型的影響就不能簡單地利用線性模型來模擬,因此常規的魯棒語音識別算法對干擾語音的魯棒性較弱。本文所提算法從空間分離的角度,在空間域進行混合雙耳聲信號的分離,不同聲源的區分特征更為明顯,因此本文進一步分析在干擾為語音時,不同算法的識別性能差異。
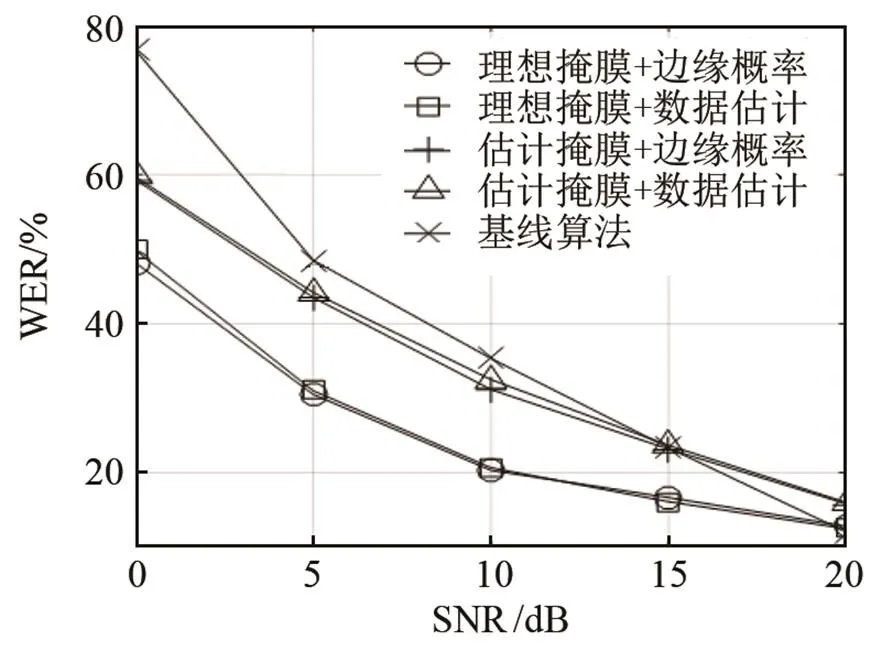
同樣,目標說話人的方位固定在方位0°,另一說話人的方位為30°、60°和90°,語音干擾的信干比取值范圍與噪聲的信噪比取值方位相同,不同算法的誤識率結果如圖7所示。
根據圖7結果,相對于圖4~6的識別結果,在干擾語音條件下,基線系統的誤識率要遠遠高于在噪聲環境下的誤識率,這是由于在相同的信噪比下,由于語音干擾和目標語音特征參數的相似度較高,從而無法從混合語音信號中提取有效的目標語音信號特征參數。而本文算法利用不同聲源的空間方位,在空間域實現不同說話人語音信號的分離,因此本文算法相對于基線系統的性能提高,在語音干擾環境下,要比噪聲環境下的性能改善明顯。同時根據圖7,語音干擾和目標語音的角度分隔越大,則本文算法的性能提高越明顯。
(a) 干擾噪聲位于30°
(b) 干擾噪聲位于60°
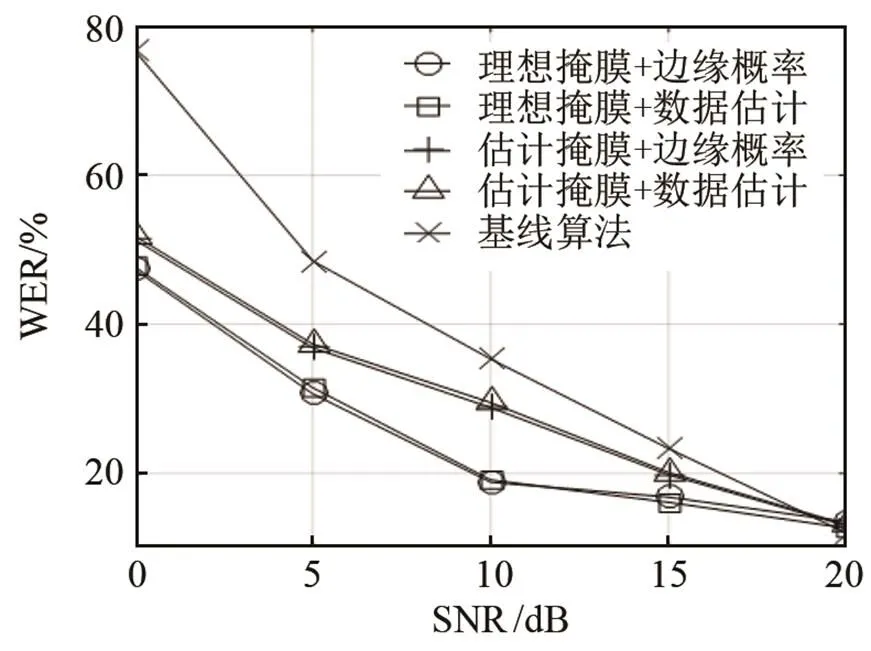
(c) 干擾噪聲位于90°
同時,在相同的信噪比下,語音干擾條件下的本文算法識別性能不如在噪聲環境下的性能。特別的,理想掩蔽值對應的識別系統性能在低信噪比下的性能不如圖4~6在噪聲干擾下的識別性能,這并不是由于理想掩蔽值不能實現正確的目標聲源分離,而是由于式(16)、(17)在進行子帶分類時,是基于式(3)給出的兩個聲源信號在子帶內的正交性,根據子帶內目標語音和干擾語音的能量比實現分類的,這實際上是從聽覺系統的感知機制得到的結論,即在一個臨界頻帶內,人耳聽覺系統由于掩蔽效應,只能感知一個聲源信號,但該子帶內實際包含兩個或者兩個以上聲源信號。這樣子帶分類后,雖然某一子帶歸為目標語音,但該子帶內實際上也包含了干擾語音成分,并且干擾語音對該子帶內占主導的目標語音的影響,比噪聲對目標語音的影響大。因此如果要進一步提高基于空間分離的識別系統在干擾語音下的識別性能,不能簡單的利用式(5)計算二進制掩蔽值,用于目標聲源、干擾聲源的分離,而是可以采用軟判決值的方法用于子帶內目標語音的分離,這也是我們下一步研究的方向。
3 結論
本文基于人耳聽覺系統的掩蔽效應和雞尾酒效應,利用不同聲源信號的空間方位進行語音信號的分離,實現目標語音的數據重構,再基于丟失數據技術,進行語音識別,從而提高了語音識別系統的魯棒性。在不同噪聲環境、不同空間方位條件下的仿真實驗結果表明,本文算法顯著提高了識別系統的性能。
同時本文研究表明,基于空間分離和丟失數據的識別算法性能取決于子帶分類的準確性,如果要提高目標語音分離的正確率,需要從兩個方面入手,其一是子帶分類的方法,目前課題組正在進行基于深度神經網絡的子帶分離算法研究,初步的仿真結果表明了該方法的有效性;其二需要對式(3)的感知正交性進行建模,不使用二進制進行子帶的硬判決方法,而是利用軟判決的方法實現子帶的分類,從而能夠準確地重構目標語音的數據流,這也是我們目前正在開展的研究工作。
[1] BREGMAN S. Auditory scene analysis: The perceptual organization of sound[M]. Cambridge, MA,US: The MIT Press, 1994.
[2] WANG D L, BROWN G. Computational auditory scene analysis: Principles, algorithms, and applications[M]. New York: Hoboken NJ: Wiley & IEEE Press, 2006.
[3] WANG Y, HAN K, WANG D L. Exploring monaural features for classification-based speech segregation[J]. IEEE Transactions on Audio, Speech and Language Processing, 2013, 21(2): 270-279.
[4] YAO J, XIANG Y, QIAN S, et al. Noise source separation of diesel engine by combining binaural sound localization method and blind source separation method[J]. Mechanical Systems & Signal Processing, 2017, 96: 303-320.
[5] KOUTROUVELIS A I, HENDRIKS R C, HEUSDENS R, et al. Relaxed Binaural LCMV Beamforming[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2017, 25(1): 137-152.
[6] ZOHOURIAN M, MARTIN R. Binaural speaker localization and separation based on a joint ITD/ILD model and head movement tracking[C]//IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 2016: 430-434.
[7] MUROTA Y, KITAMURA D, KOYAMA S, et al. Statistical modeling of binaural signal and its application to binaural source separation[C]//IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Queensland, Australia, 2015: 494-498.
[8] KIM Y I, AN S J, KIL R M. Zero-crossing based binaural mask estimation for missing data speech recognition[C]//IEEE International Conference on Acoustics, Speech and Signal Processing, Toulouse, France, 2006: 89-92.
[9] HARDING S, BARKER J, BROWN G J. Mask estimation for missing data speech recognition based on statistics of binaural interaction[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(1): 58-67.
[10] KERONEN S, KALLASJOKI H, REMES U. Mask estimation and imputation methods for missing data speech recognition in a multisource reverberant environment[J]. Computer Speech & Language, 2013, 27(3): 798-819.
[11] ALINAGHI A, JACKSON P J B, LIU Q, et al. Joint mixing vector and binaural model based stereo source separation[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2014, 22(9): 1434-1448.
[12] WANG Y, WANG D L. Towards scaling up classification-based speech separation[J]. IEEE Trans. Audio, Speech, Lang. Process. 2013, 21(7): 1381-1390.
[13] ZHANG X, WANG D L. Deep Learning Based Binaural Speech Separation in Reverberant Environments[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2017, 25(5): 1075-1084.
[14] JIANG Y, WANG D, LIU R, et al. Binaural classification for reverberant speech segregation using deep neural networks[J]. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2014, 22(12): 2112-2121.
[15] YU Y, WANG W, HAN P. Localization based stereo speech source separation using probabilistic time-frequency masking and deep neural networks[J]. EURASIP J. Audio Speech Music Proc. 2016(1): 1-18.
[16] JOURJINE A, RICKARD S, YILMAZ O. Blind separation of disjoint orthogonal signals: Demixing n sources from 2 mixtures[C]//IEEE International Conference on Acoustics, Speech and Signal Processing, Istanbul Turkey, 2000: 2985-2988.
[17] COOKE M, GREEN P, JOSIFOVSKI L, et al. Robust automatic speech recognition with missing and unreliable acoustic data[J]. Speech Communication, 2001, 34(3): 267-285.
[18] FISHER W, DODDINGTON G, and GOUDIE-MARSHALL K. The DARPA speech recognition research database: Specifications and status[C]//DARPA Speech Recognition Workshop, Palo Alto, CA, 1986: 93-99.
[19] VARGA A, STEENEKEN H, TOMLINSON M, et al. The NOISEX-92 study on the effect of additive noise on automatic speech recognition[R]. Speech Research Unit, Defense Research Agency, Malvern, UK, 1992.
[20] CUMMINS F, GRIMALDI M, LEONARD T, et al. The chains speech corpus: Characterizing individual speakers[C]//11thInternational Conference Speech and Computer, St. Petersburg, Russia, 2006: 1-6.
Robust speech recognition algorithm based on binaural speech separation and missing data technique
ZHOU Lin1, ZHAO Yi-liang1, ZHU Hong-yu1, TANG Yi-bin2
(1. Key Laboratory of Underwater Acoustic Signal Processing of Ministry of Education, School of Information Science and Engineering, Southeast University, Nanjing 210096, Jiangsu, China; 2. College of Internet of Things Engineering, Hohai University, Changzhou 213022, Jiangsu, China)
Robust speech recognition has an important application in human-computer interaction, smart home, voice translation system and so on. In order to improve the speech recognition performance in complex acoustic environment with noise and speech interference, a robust speech recognition algorithm based on binaural speech separation and missing data technique is proposed in this paper. First, according to the azimuth of the target sound source, the algorithm separates the mixed data in the sub-bands of equivalent rectangular bandwidth (ERB), and obtains the data flow of the target sound source. Then, in order to solve the problem that the target source loses spectral data in some ERB sub-bands, the probability calculation based on hidden Markov model is modified by using the missing data technique, and finally the reconstructed spectrum data is utilized for speech recognition. The simulation results show that the proposed algorithm can improve the performance of speech recognition in complex acoustic environment, because the influence of noise and interference on the target sound source data is neglected after binaural speech separation.
spatial hearing; binaural speech separation; missing data technique.; speech recognition; word error rate (WER)
H107
A
1000-3630(2019)-05-0545-09
10.16300/j.cnki.1000-3630.2019.05.011
2018-09-14;
2018-10-19
國家自然科學基金(61571106、61501169、61201345)、中央高校基本科研業務費專項資金(2242013K30010)
周琳(1978-), 女, 江蘇鎮江人, 副教授, 研究方向為語音、聲學信號處理。
周琳,E-mail: Linzhou@seu.edu.cn
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
