多特征融合的Voting-SRM情感分類研究
2019-12-04 03:33:26麥范金張興旺
小型微型計算機系統 2019年11期
趙 樂,麥范金,張興旺
1(桂林理工大學 信息科學與工程學院,機械與控制工程學院,廣西 桂林 541006)2(桂林理工大學 圖書館,廣西 桂林 541006)
1 引 言
利用機器學習對評論文本進行情感分類是目前情感分析研究的主流方法之一.如何有效地對這些評論文本進行分析處理,挖掘出有價值的信息,更好地為人們服務?近幾年,深度學習算法應用于自然語言處理,促進了文本情感分類技術的發展.何躍[1]等人基于微博情感詞、表情符號、否定詞、程度副詞等情感知識分類算法和傳統的機器學習算法,解決了機器學習算法在情感分類時樣本數據分布不均的問題.姜杰[2]等人將多樣化情感信息進行轉化,形成更有效的多特征融合模形,提高了微博情感分類的性能.
目前的機器學習算法,如支持向量機、樸素貝葉斯和神經網絡等已經在情感分類中取得了良好的分類效果,但由于文本句式的復雜性和情感特征的多樣化,因此情感分類的研究還有待進一步提高.隨機梯度下降算法在情感分類中很少應用,但實驗發現其分類性能較好.因此本文結合詞性特征和語法特征進行特征融合,然后使用軟投票機制,結合隨機梯度下降、隨機森林、神經網絡分類器等算法,提出了一種多特征融合的Voting-SRM情感分類方法.通過在IMDB電影評論數據集上進行實驗,對其進行二分類研究,實驗結果表明該方法能有效提高情感分類精度.
2 相關工作
目前,文本情感分類的方法主要有三種:基于詞典和規則的分類,基于機器學習的分類和基于深度學習的分類.
基于詞典和規則的方法,主要是根據現有情感詞典獲取文本中的情感元素,然后利用規則進行特征抽取和權重計算,隨后利用累加求和計算出句子的情感傾向值,進而計算篇章情感得分.閆曉東[3]等人通過構建極性詞典和轉折詞詞典,然后將其組合構建極性短語作為基本情感單元,重點分析了轉折詞對句子情感極性的影響.劉德喜[4]等人對比分析中英兩種語言微博中情感詞分布的差異,自動構建訓練數據、訓練分類器,最后采用投票機制確定候選詞的情感極性.唐曉波[5]等人首先對中文文本進行依存句法分析,通過構建識別規則,提取情感單元,然后對情感單元進語言翻譯轉換,最后通過與英文情感詞的匹配分析,完成了對情感評價單元的極性判定.
基于機器學習的分類方法,主要是利用機器學習的方法,抽取出文本中的情感特征,然后訓練分類器來完成情感分類任務.何躍[1]等人基于微博情感詞、表情符號、否定詞、程度副詞等情感知識分類算法和傳統的機器學習算法,解決了機器學習算法在情感分類時樣本數據分布不均的問題.姜杰[2]等人將多樣化情感信息進行轉化,形成更有效的融合特征模板,提高了微博情感分類的性能.
基于深度學習的分類方法.隨著近年來深度學習技術的快速發展,其在大規模文本數據上表現出了獨特優勢,更好地用于情感分類.現有研究工作主要是從評論文本中學習出語義詞向量,然后通過不同的語義合成方法用詞向量得到所對應句子或是文檔的特征表達[6],以此來進行學習,從而進行情感分類.李杰[7]等人以情感標簽標注評論中的產品特征詞,并利用詞向量對產品特征有效聚類,提高了特征提取和分類的準確率.楊艷[8]等人針對文本中長句和短句具有不同建模特點,提出了一種基于聯合深度學習的情感分類方法,在COAE2016測評任務中取得最高的系統準確率.
通過研究發現,隨機梯度下降算法在情感分類中很少應用,但實驗發現其分類性能較好.因此本文結合詞性特征和語法特征進行特征融合,然后使用軟投票機制,結合隨機梯度下降,隨機森林,神經網絡分類器等算法,提出了一種多特征融合的Voting-SRM情感分類方法.通過在IMDB電影評論數據集上進行實驗,對其進行二分類研究,實驗結果表明該方法能有效提高情感分類精度.
3 多特征融合的Voting-SRM情感分類研究
本文對評論文本進行詞性標注,抽取出名詞、動詞、形容詞和副詞,并結合二元語法進行特征抽取,構建向量空間模型,然后基于軟投票機制,對隨機梯度下降算法,隨機森林算法,神經網絡算法進行集成,構建情感分類模型進行情感分析.
3.1 特征選擇
特征選擇是使用分類器進行情感分類的重要環節,分類結果的正確率、查準率、查全率等都取決于選擇的特征的有效性.黃發良[9]等人將微博表情符號與用戶性格情緒特征融合進圖模型中,實現了微博主題與情感的同步推導.王汝嬌[10]等人結合Twitter語言特性和詞典設計語料和詞典特征,使用卷積神經網絡得到詞向量特征,將3種特征融合,取得了較好的分類效果.何躍[1]等人將情感知識和機器學習算法組合,提出了一種組合分類算法,解決了樣本數據分布不均的問題.由于不同的評論文本在語義和語法結構上均有不同特征,本文通過分析研究,決定從詞性特征,語法特征兩個方面進行特征選擇.
3.1.1 詞性特征
詞性標注是在特定的語境中確定分詞的詞性,由于詞匯傾向性可以在一定程度上決定文本傾向性,因此情感傾向性分類需要進行詞性標注.本文分析了影評文本特性,發現名詞、動詞、形容詞、副詞在一定程度上決定了文本整體情感,所以選擇這四類特征作為詞性特征.詞性標注類別如表1所示.這里考慮到英文詞匯在進行詞干化處理的時候會出現不合理截斷或是錯誤現象,所以選取了形容詞、副詞、動詞、名詞的所有形式,以盡可能全的選擇詞性特征.
表1 詞性標注類別
Table 1 Part of speech tagging category

詞性標注形容詞JJ,JJR,JJS副詞RB,RBR,RBS,RP,WRB動詞VB,VBD,VBG,VBN,VBP,VBZ名詞NN,NNS,NNP,NNPS
3.1.2 語法特征
n元語法模型(N-gram)近似假設一個詞的概率只依賴于它前面的n-1個詞,而與其他詞無關來推斷句子的結構關系.本文在基于語料進行實驗分析后,發現二元語法模型(Bi-gram)特征在分類時性能優于一元語法(Unigram)和三元語法(Trigram).因此本文選取二元語法模型進行特征表征.
3.2 Voting-SRM分類算法
3.2.1 SGD隨機梯度下降分類器
隨機梯度下降算法(Stochastic Gradient Descent,SGD)是一種簡單、高效的方法,主要用于凸損失函數下線性分類器的判別式學習,例如線性支持向量機和Logistic回歸.SGD算法是一個基于梯度下降的改進算法,其核心思想是:首先計算出損失函數的梯度,然后根據梯度計算出函數損失值,并且按照梯度的方向使函數損失值逐漸減少,當函數損失值最小時,得到最優梯度值[11].
給定一組訓練樣本S={(xi,yi),i=1,…,n},其中xi∈Rm是一個m維輸入向量,yi∈{-1,1}是第i個訓練樣例的類標,目標是一個線性評價函數(Scoring function)f(x)=wTx+b,其中模型參數w∈Rm,截距b∈R.只需要看f(x)的符號.找到模型參數的一般選擇是通過最小化由以下式子給出的正則化訓練誤差.
(1)
其中L衡量模型擬合程度的損失函數:
L(yi,f(xi))=max{0,1-yif(xi)}
(2)
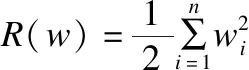
首先,將w1置為零向量,然后均勻隨機選取訓練集中一個訓練樣例(xit,yit),其中it∈{1,…,n}是通過第t次迭代選擇的訓練樣例下標.然后將公式(1)用下式近似替換:
(3)
對公式(3)求梯度得:
t+1=αwt-λtyitxit
(4)
其中,
(5)
w的公式更新為:
wt+1←wt-ηtt+1
(6)
(7)
w更新完畢后,再隨機選取一個訓練樣例用式(7)進行更新,進行T次迭代,最后得到的wT+1即為算法所求的最終解.
SGD分類器實現了一個一階SGD學習程序(first-order SGD learning routine).算法在訓練樣本上遍歷,并且對每個樣本根據以上公式給出的更新規則來更新模型參數.本文中算法選取Logisitic回歸作為算法的損失函數,L2正則化作為懲罰函數,來完成SGD分類器參數的構造.
3.2.2 Voting軟投票分類器
目前基于集成學習進行情感分類的研究很多,徐禹洪[12]等人考慮到即時性文本信息具有已標注數據規模小的特點,提出了基于優化樣本分部抽樣集成學習的半監督文本分類算法,提高了分類性能.黃偉[13]等人通過構建子分類器,每輪投票選出置信度最高的樣本使訓練集擴大一倍并更新訓練模型,提出了基于多分類器投票集成的半監督情感分類方法.本文使用加權平均概率,即為軟投票,它是結合多個不同分類器,并且為各分類器設定相應的權值,然后利用二值函數乘其權重進行匯總,并且采用平均預測概率的方式來預測分類標簽,最終得到情感分類傾向值.
對于m個類別L=(l1,…,lm),存在n個不同的基分類器{cls1,…,clsn},其對應的權值為{w1,…,wn},則:
(8)
(9)
其中P(lj|wi)表示分類器clsi對類別lj的輸出概率,P(lj)表示類別的先驗概率,P(wi)表示分類器clsi的性能權重.Δw即為最終輸出結果.
本文算法使用三個分類器,如SGD隨機梯度下降,隨機森林,神經網絡.因此分類器性能權重可以設置為2:2:1,所以本文分類器標記為Voting-SRM.由于隨機森林算法和神經網絡模型被廣泛使用,本文不再詳細介紹其算法原理.
4 實驗設計
4.1 實驗語料及評價指標
本文選取的是IMDB電影評論數據[14],這是一個用于二分類的電影評論數據集,選取已標注的25000條評論,并隨機分為訓練集和測試集,其中80%為訓練集,20%為測試集,正面情感標注為1,負面情感標注為0.性能評價指標主要包括正確率(Accuracy)、查準率(Precision)、查全率(Recall)和F測度值(F-score).其中查準率衡量分類效果,查全率衡量分類效率,F測度值主要衡量情感分類方法性能[5].公式如下:
(10)
(11)
其中TP表示正確預測的正樣本數,TN表示正確預測的負樣本數,FP表示錯誤預測的正樣本數,FN表示錯誤預測的負樣本數[15].
4.2 特征分類
根據3.1中特征選擇的詞性特征和語法特征,設置不同的組合形式,并進行實驗驗證,分類比較其在情感分類中的作用和分類性能.其分類結果如表2所示.
表2 不同特征集合分類
Table 2 Different feature set classification

特征集合形容詞+副詞(adj+adv)形容詞+副詞+名詞(adj+adv+n)形容詞+副詞+動詞(adj+adv+v)形容詞+副詞+名詞+動詞(adj+adv+n+v)
4.3 實驗結果及分析
根據以上性能評價指標進行試驗,評測Voting-SRM方法在IMDB影評數據上情感分類性能,并觀察在不同特征集上的各評測指標的精度.其實驗結果如表3所示.
表3 不同特征集下的分類正確率
Table 3 Classification accuracy under different feature sets
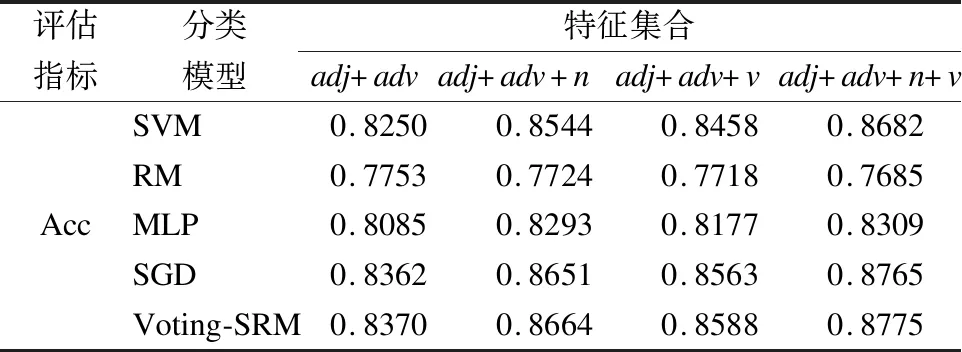
評估指標分類模型特征集合adj+advadj+adv+nadj+adv+vadj+adv+n+vAccSVM0.82500.85440.84580.8682RM0.77530.77240.77180.7685MLP0.80850.82930.81770.8309SGD0.83620.86510.85630.8765Voting-SRM0.83700.86640.85880.8775
在實驗中使用十折交叉驗證計算分類正確率,從表3可以看出,隨著特征種類的增多,五種方法的分類正確率都有所提升,其中本文提出的Voting-SRM算法分類正確率最高,由此可見該方法的有效性.從表中還可以看出形容詞+副詞+名詞的特征集比形容詞+副詞+動詞的特征集分類正確率較高,由此可見名詞在情感分類中的情感影響較大.整體來看五種分類方法的正確率,除隨機森林外,其他四種模型的的精度在不同特征集下都高于82%,因此分類效果,效率和分類方法的性能都取得了較好的成績.
表4 不同特征集下的查準率
Table 4 Precision rate under different feature sets
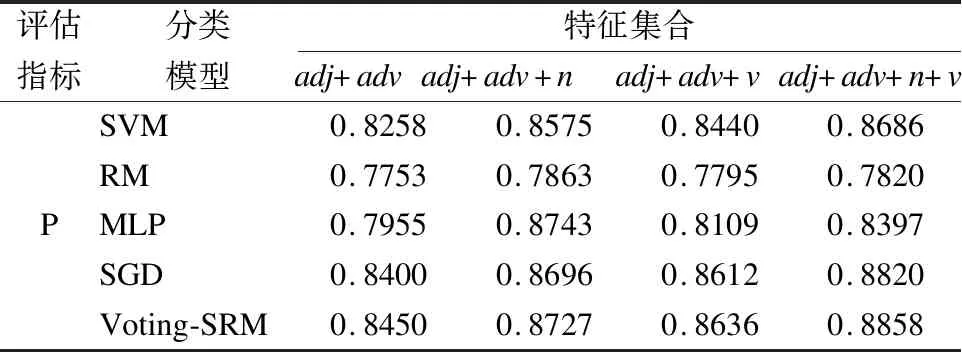
評估指標分類模型特征集合adj+advadj+adv+nadj+adv+vadj+adv+n+vPSVMRMMLPSGDVoting-SRM0.82580.77530.79550.84000.84500.85750.78630.87430.86960.87270.84400.77950.81090.86120.86360.86860.78200.83970.88200.8858
從表4、表5、表6中可以看出,隨著特征種類的增加,五種方法的總體查全率、查準率和F-測度值都得到提高.本文提出得到Voting-SRM算法分類模型具有最高的分類精度,由此可見該方法是有效的.從表中還可以看出,形容詞+副詞+名詞的特征集各種分類性能均高于形容詞+副詞+動詞的特征集,表示名詞在情感分類中具有更大的影響.因此在以后的研究中應該更加深入的研究不同詞性組合對情感分類的影響.
表5 不同特征集下的查全率
Table 5 Recall rate under different feature sets
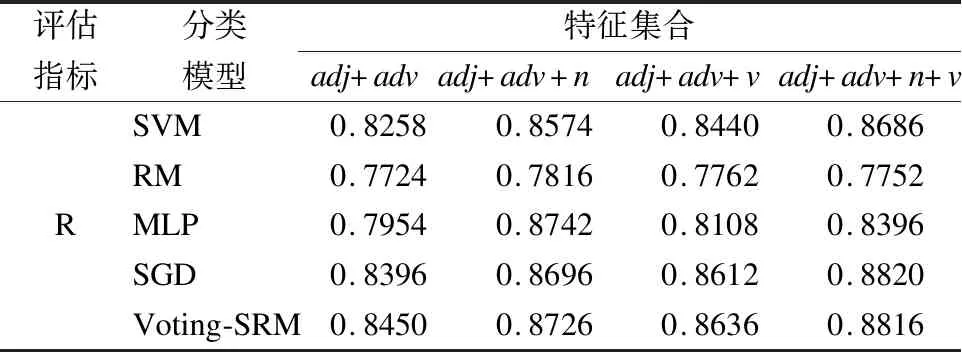
評估指標分類模型特征集合adj+advadj+adv+nadj+adv+vadj+adv+n+vRSVMRMMLPSGDVoting-SRM0.82580.77240.79540.83960.84500.85740.78160.87420.86960.87260.84400.77620.81080.86120.86360.86860.77520.83960.88200.8816
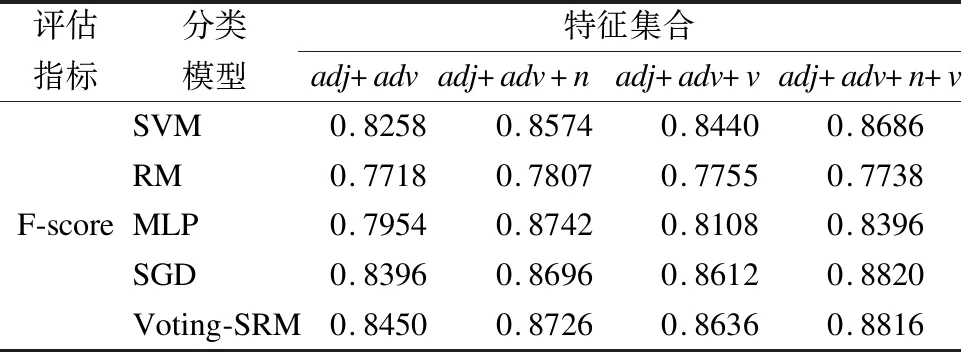
表6 不同特征集下的F-測度值Table 6 F-score values under different feature sets
為了更直觀的觀察和分析各種評測指標,使用折線圖來展示比較五種方法在不同特征集上的分類結果. 從圖1- 圖4
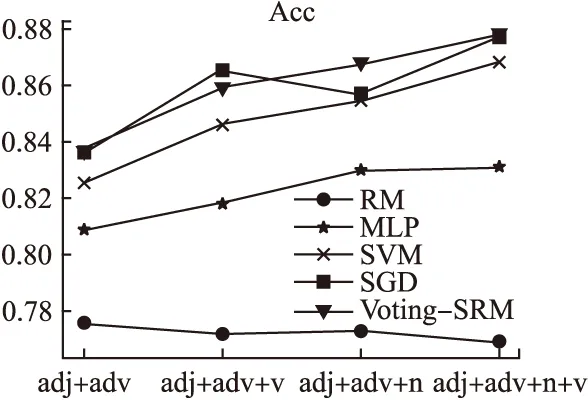
圖1 不同特征集下的正確率Fig.1 Accuary rate under different feature sets
可以看出本文提出的方法,在各種評測指標上均優于SVM算法.從圖中可以看出,神經網絡模型在查全率,查準率和F-測度值上均存在較大波動,顯示為不穩定狀態.當提取少量特征時,本文算法在各種性能上和SGD方法相當,但在提取了多種特征時,本文提出的方法能有效提高分類效果,分類效率和分類性能,這四種評測指標均優于SGD算法.因此本文提出的方法在文本情感分類中是可行的,且分類性能較好.
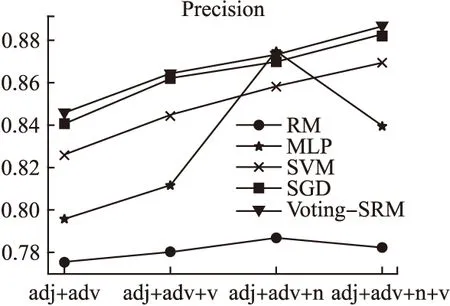
圖2 不同特征集下的平均查準率評價結果Fig.2 Average precision under different feature sets
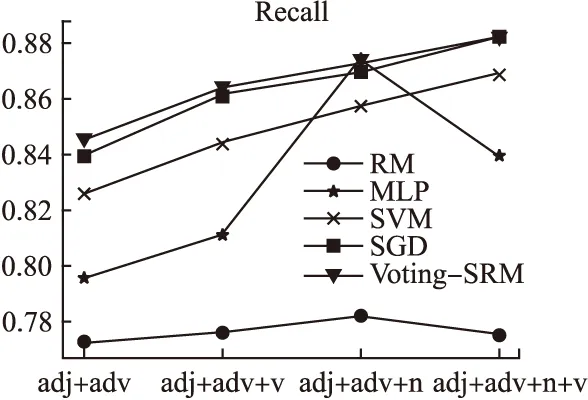
圖3 不同特征集下的平均查全率評價結果Fig.3 Average recall rate under different feature sets
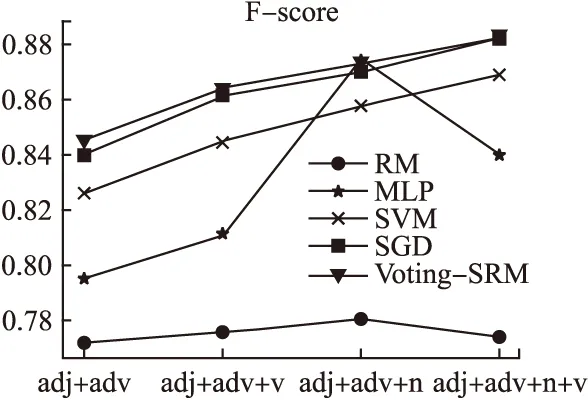
圖4 不同特征集下的F-測度值評價結果Fig.4 F-score values under different feature sets
5 結 語
本文研究使用軟投票機制集成SGD隨機梯度下降,隨機森林算法和神經網絡算法,并提取不同特征集在IMDB影評數據集上進行對比實驗,結果表明該方法有效提高了文本情感分類性能.情感分類精度的提高在于在情感特征中引入了詞性特征和語法特征,并使用詞頻逆文檔頻率進行特征抽取,構建向量空間模型,在同等條件下,實驗結果表明該方法優于支持向量機算法.但本文在抽取特征時只考慮了詞性和語法特征,并未考慮加入情感詞典、句法特征和依存語法特征,因此在以后的工作中會進一步擴展特征抽取過程,考慮更多影響文本情感傾向的因素,進一步提高文本情感分類性能.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
