基于TextRank和LDA的信息安全熱點感知研究
2019-12-09 02:08:12楊立寶余章馗狄曉曉
網絡空間安全 2019年5期
楊立寶 余章馗 狄曉曉
摘? ?要:文章以信息安全相關文章數據為研究對象,分析了目前信息安全研究工作中新聞動態熱點的數據處理和分析需求,結合信息安全領域特點,基于自然語言處理技術提出了基于TextRank和LDA的信息安全領域熱點感知和可視化技術,并對信息安全領域新聞動態熱點進行了關鍵詞分析、關鍵詞共現分析以及主題分析。實驗結果表明,該技術可實現信息安全研究熱點快速定位與感知,達到輔助深入研究分析的目的。
關鍵詞:信息安全;熱點分析;TextRank;LDA
中圖分類號:TP391.1? ? ? ? ? 文獻標識碼:A
Research on hotspot sensing of information security based on TextRank and LDA
Yang Libao, Yu Zhangkui, Di Xiaoxiao
(China Industrial Control Systems Cyber Emergency Response Team, Beijing 100040)
Yang Libao, Yu Zhangkui, Di Xiaoxiao
(China Industrial Control Systems Cyber Emergency Response Team, Beijing 100040)
1 引言
大數據時代下,信息呈爆炸式增長,各行業研究人員如何高效提取高價值信息,快速把握所在領域前沿動態、熱點主題和發展趨勢,為研究工作奠定良好基礎,已經成為信息技術研究的一個熱點話題。目前,在數據采集方面,網絡爬蟲技術已得到普遍應用[1],公開網絡信息的采集效率有了極大提升;在數據處理和和分析方面,使用較多的則是自然語言處理技術、機器學習等技術。本文通過關鍵詞分析和主題模型分析,深度挖掘大量信息安全新聞動態數據的深層信息,及時精準感知信息安全領域熱點,對輔助監測預警工作具有重大意義。
2? 信息安全熱點研究的需求
在全球范圍內,信息安全領域的各種新政策、新技術、新事件不斷涌現,做好信息安全熱點感知研究,一方面可以明確當前信息安全領域政策、技術、產業的現狀和趨勢,為國家信息安全相關決策提供現實依據,是提升國家信息安全保障能力的重要環節;另一方面可以更好地把握當前信息安全前沿方向和關注焦點,為信息安全防護理論、方法的學術創新提供支撐。
2.1 現有研究概述
熱點話題是指一個話題在一段時間內頻繁出現,也就是一定時期內由多個新聞來源、多篇新聞同時報道的話題[2]。本文將信息安全熱點定義為在一段時間內出現頻次較高,被多個新聞來源廣泛關注和報道的信息安全動態新聞。國外熱點話題研究起步較早,1996年美國國防高級研究計劃局(DARPA)就倡議研究話題發現與跟蹤技術[3]。國內熱點話題研究雖起步較晚,但是目前經過學者的努力也取得了一定的研究成果。其中影響較大的包括李保利和俞士汶各種聚類算法的比較分析,賈自艷、何清和張俊海關于事件探測和追蹤算法的研究等[4]。
就目前研究而言,大致可以分為三類:其一,針對新聞、社交、論壇等網絡產品和服務的分析,此類熱點研究深度挖掘用戶行為偏好,旨在優化信息推薦機制,改進產品功能,提升用戶體驗;其二,針對新聞報道、社交網絡(微信和微博)的分析,旨在快速捕捉和精準跟蹤網絡輿情熱點,為輿情管控和相關決策提供支撐;三是,學術研究領域以一定時間范圍內的研究成果為分析對象,通過關鍵詞分析、共現分析、可視化分析等手段,明確某一領域研究現狀,追蹤前沿課題,把握研究趨勢。信息安全關乎國家安全,是信息社會的重大研究課題,本文落腳于信息安全熱點感知,兼具第二類和第三類的特點。
2.2 技術難點
海量數據爆炸性涌現,新聞數據處理分析和熱點提取都極具復雜性和特殊性。文本數據處理時,專業分詞是首要難點,專業領域詞匯切分是否正確,直接決定后續分析的準確性;關鍵詞權重計算是主要難點,僅依靠傳統的詞頻統計難以準確識別詞語在文章中的依存關系,無法準確挖掘出關鍵核心的詞匯。因此,在關鍵詞提取的基礎上,還需要對關鍵詞之間的主題概念進行聚合挖掘,更細粒度地分析數據中蘊含的研究主題以及主題本身的關鍵詞,同時借助有效的可視化工具,直觀展現這種主題分析結果。
3 熱點感知挖掘算法的設計
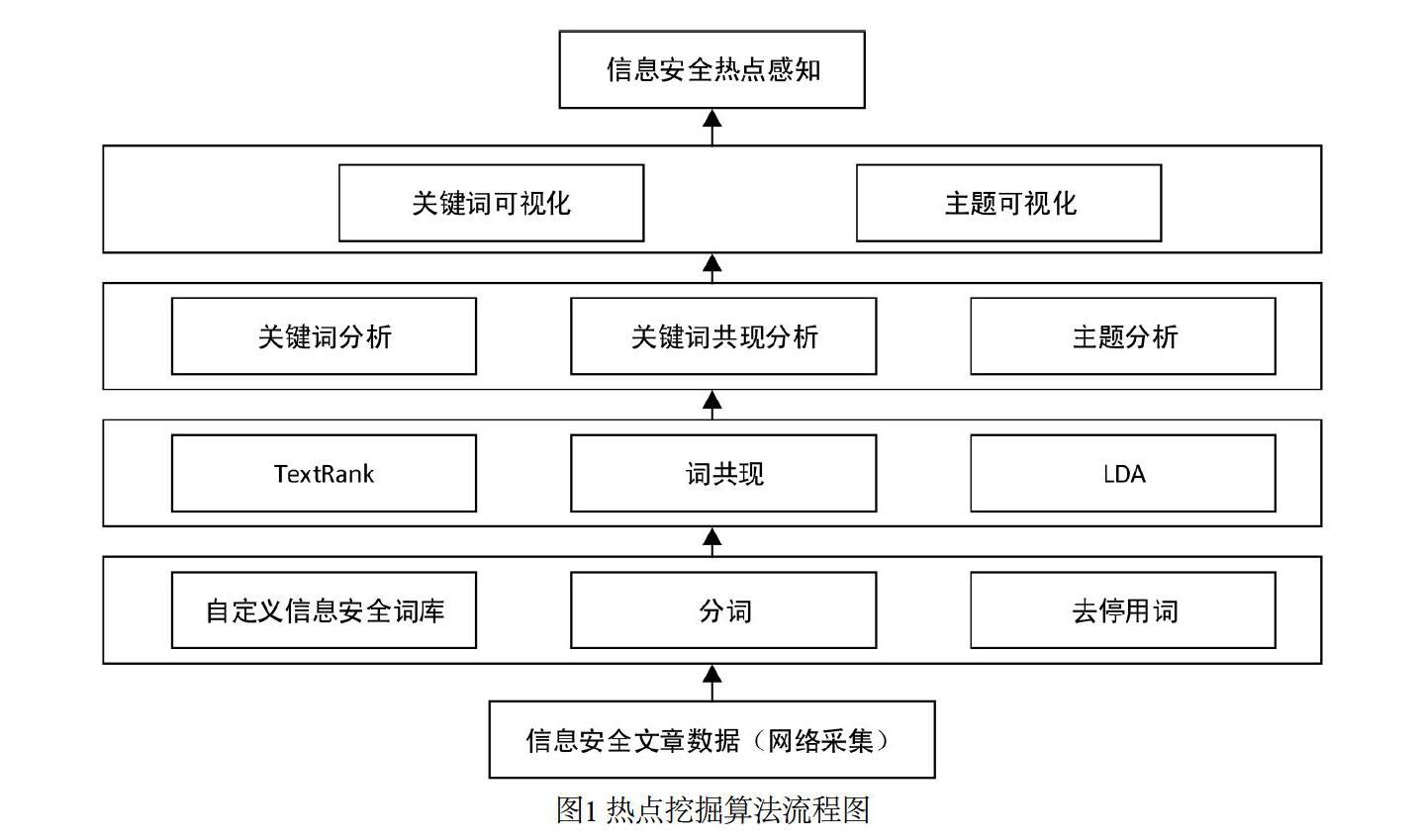
信息安全領域新聞動態熱點感知挖掘算法流程設計如圖1所示,主要包括數據源(網絡采集的信息安全相關文章數據),數據處理層(主要做分詞、去停用詞、加入自定義詞庫等處理),算法層(TextRank、詞共現、LDA等),數據分析層(關鍵詞分析、關鍵詞共現分析以及主題分析)以及可視化層(關鍵詞可視化、主題可視化等),經過整個挖掘流程,實現兩種信息安全熱點感知形式的具象化,達到信息安全領域熱點感知的目標,輔助更深層次的研究工作。
4? 熱點挖掘過程
熱點挖掘過程分為兩部分,第一部分主要是做基于TextRank的關鍵詞提取和基于詞共現的可視化分析,實現整體數據集中的關鍵詞提取;第二部分是基于LDA主題模型分析的主題關鍵詞及相關可視化,實現主題聚合的關鍵詞挖掘。通過對兩過程的分析,實現熱點挖掘和分析過程的快速化。通過建立統計中間表、利用矩陣+樹型遍歷算法,可實現數據分析快速化的目的[4]。
4.1 數據來源
本文數據為通過網絡采集的相關動態文章,共651篇,包括文章的標題、正文、時間三個維度,時間跨度為2018-07-05至2019-04-22。文章采集的數據源均為信息安全領域的相關網站,因此省去做信息安全領域相關與否的二元判斷環節,可直接進入內容層面的熱點挖掘。
4.2 關鍵詞分析
關鍵詞分析就是從給定的文本中自動抽取出若干有意義的詞語或詞組。本節將對所有文章數據進行整合,經過數據處理以及TextRank算法計算來實現關鍵詞抽取,從而在一定程度上反映信息安全領域熱點。
TextRank算法[5]是一種用于文本的基于圖的排序算法。其基本思想來源于谷歌的PageRank算法,通過把文本分割成若干組成單元(單詞、句子)并建立圖模型,利用投票機制對文本中的重要成分進行排序。與LDA、HMM等模型不同,TextRank算法是利用局部詞匯之間關系(共現窗口)對后續關鍵詞進行排序,僅利用文檔數據集本身的信息即可實現關鍵詞提取,不需要事先對多篇文檔進行學習訓練,因其簡潔和有效而得到廣泛應用。
關鍵詞分析需要經過Python的jieba中文分詞包進行分詞,在分詞前通過jieba的load_userdict函數加入信息安全領域相關自定義詞典,比如“關鍵基礎設施”“網絡攻擊”“安全漏洞”等。同時,設置常用中英文停用詞,主要包括用來表達語氣的字詞、連接型字詞、標點符號、特殊字符等沒有實際意義的文本,比如“著”“哈”“了”等。分詞后形成一個有序的詞語集合,經過TextRank算法計算每個詞語的重要程度值并進行排序,最終得到關鍵詞和對應的權重。關鍵詞的權重越高,說明在文本中越重要。關鍵詞分析有助于分析該數據集的關鍵特征。
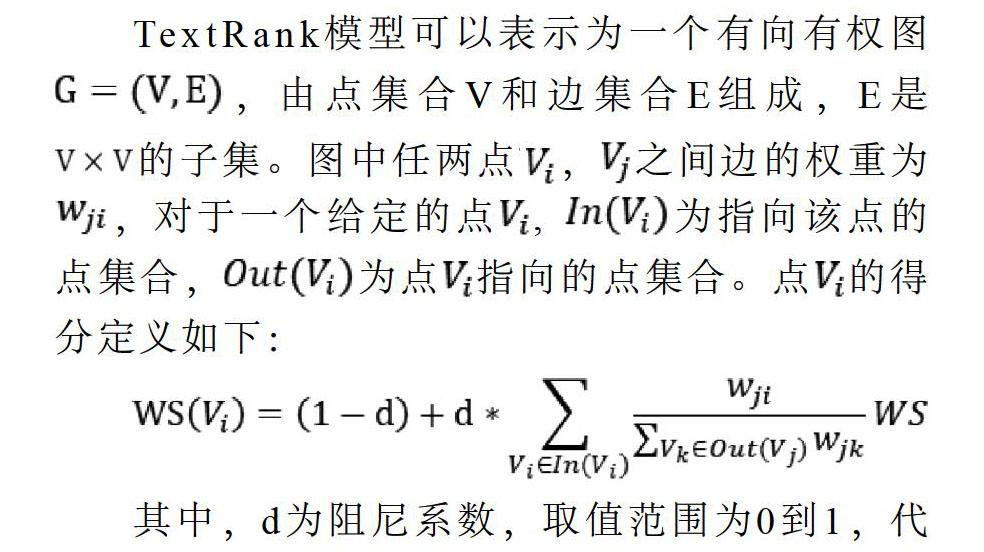
TextRank模型可以表示為一個有向有權圖,由點集合V和邊集合E組成,E是的子集。圖中任兩點,之間邊的權重為,對于一個給定的點, 為指向該點的點集合,為點指向的點集合。點的得分定義如下:
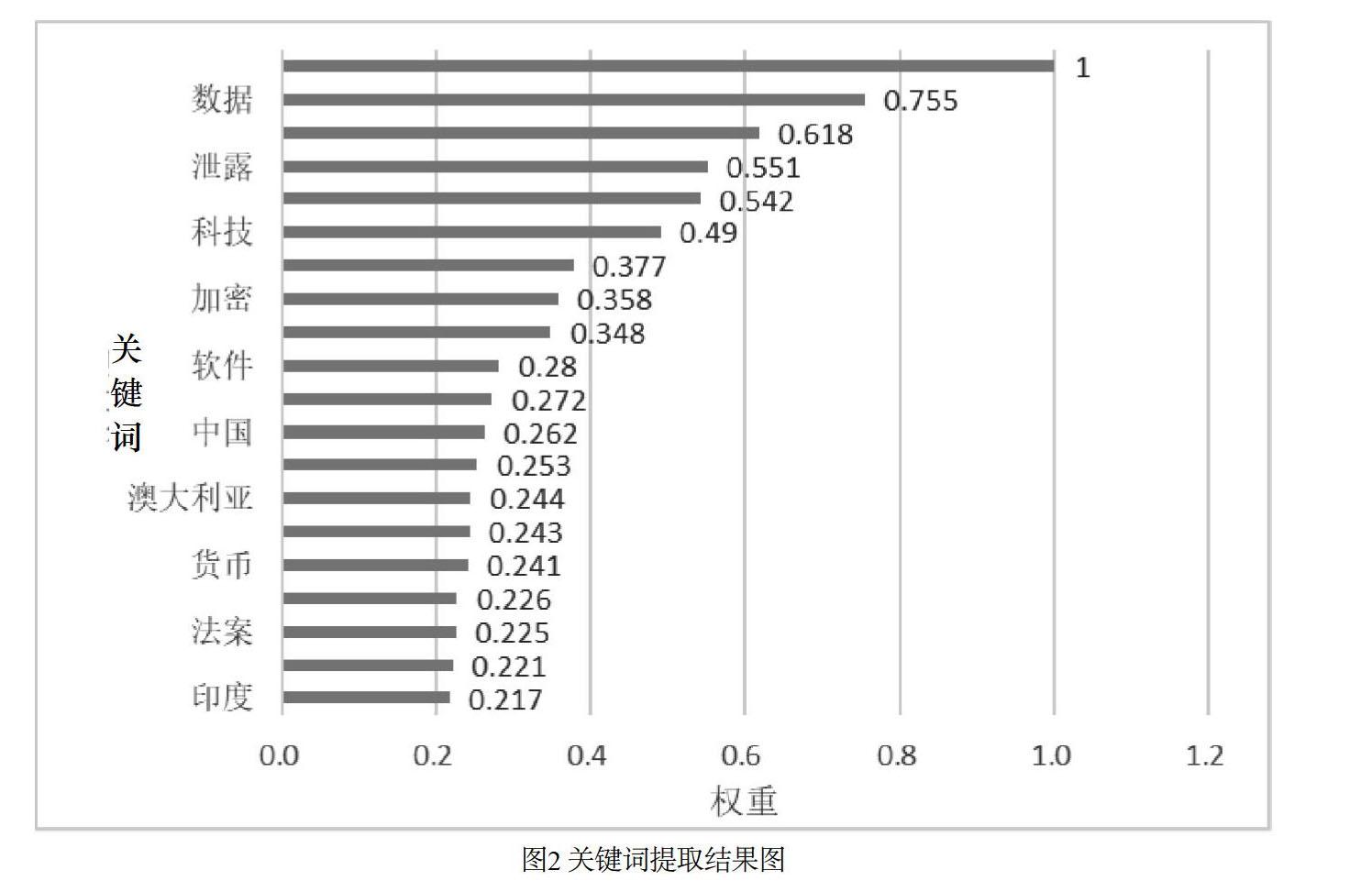
其中,d為阻尼系數,取值范圍為0到1,代表從某一特定點指向其他任意點的概率,一般取值為0.85。使用TextRank算法計算圖中各點得分時,需要給圖中的點指定任意的初值,并遞歸計算直到收斂。通過使用TextRank算法對數據進行關鍵詞提取,得出了前20個關鍵詞,如圖2所示。
從圖2可以看出,排名前五的關鍵詞之中“美國”這個主題詞被識別為權重最高的關鍵詞,接下來依次為“數據”“攻擊”“泄露”“漏洞”四個詞,這些關鍵詞在一定程度上反映出信息安全領域關注和研究的一些熱點。同時,可以看到前20個關鍵詞里面出現不少國家名稱,說明這些國家在這些文章中也被高頻率地提到,在整體數據上也是很重要的關鍵詞,是應該關注的重點。本文將通過關鍵詞共現分析和主題模型來深入分析這些關鍵詞之間是否存在某種關系。
4.3 關鍵詞共現分析
這一部分是在關鍵詞分析的基礎上做關鍵詞共現分析,按關鍵詞權重從高到底排序,計算前100個關鍵詞之間的共現矩陣和共現列表,并計算每個節點的平均加權度。使用Gephi進行可視化形成共現的語義網絡圖,如圖3所示。同步出現詞模式表明在文章中最頻繁出現或與其最相關的關鍵詞之間有著語義上的緊密聯系。
關鍵詞共現次數按從大到小排序,圖3展示的是前250條共現關系的網絡,圖中節點大小表示節點加權度,連線的粗細表示節點之間共現權重。通過此圖可以更加直觀地查看關鍵詞之間的共現關系,在一定程度上反映出各個關鍵詞之間相關關系,共現頻次越高,說明二者之間的聯系緊密程度越高。如表1所示,給出前20條詞共現列表。
通過圖3與表1,可以看到“美國”與“數據”“攻擊”“信息”“系統”等關鍵詞之間存在顯著的共現關系,從一定程度上可以反映出,美國比較關注或正在研究數據安全領域,這個話題可以作為信息安全領域的一個研究熱點,研究人員可以從這個熱點著手進行深入研究,從而推進我國數據安全領域的研究工作;同樣,可以看到“攻擊”與“數據”“設備”“信息”“漏洞”“研究”等關鍵詞共現頻繁,從一定程度上可以反映出,現在攻擊者對設備的攻擊行為可能主要是利用了某些漏洞,造成相關信息和數據泄露等問題,從這些關系入手,研究者可以重點關注“哪些被漏洞容易被利用”“哪些設備容易成為攻擊目標”“攻擊容易造成哪些數據泄露”等研究方向。
4.4 主題分析
LDA 模型是由Blei等人提出的一種對自然語言進行建模的生成模型,適合挖掘大規模文檔集中潛藏的主題信息[6]。本文通過LDA模型找出數據中的主題分布。在LDA模型中,需要先假設主題數目K,這樣所有的分布將基于K個主題展開。具體LDA模型如圖4所示。
LDA模型假設文檔中主題和主題中詞的先驗分布都是Dirichlet分布,即對于任意一篇文檔d, 其主題分布為,對于任意一個主題k, 其詞分布為,α和η分別為對應分布的超參數。對于數據的任意一篇文檔d中的第n個詞,可以從主題分布中得到它的主題編號的分布為,而對于該主題編號,得到我們得到的詞的概率分布為。
這個模型里,有M個文檔與主題的Dirichlet分布,而對應的數據有M個主題編號的多項分布,這樣就組成了Dirichlet-multi共軛,可以使用貝葉斯推斷的方法得到基于Dirichlet分布的文檔主題后驗分布。同理,對于主題與詞的分布,有K個主題與詞的Dirichlet分布,而對應的數據有K個主題編號的多項分布,這樣就組成了Dirichlet-multi共軛,可以使用貝葉斯推斷的方法得到基于Dirichlet分布的主題詞的后驗分布。由于主題產生詞不依賴具體某一個文檔,因此文檔主題分布和主題詞分布是獨立的。
主題分析通過使用LDA主題模型算法,計算所有文章中出現的主要詞匯簇,這些詞匯集合構成了一個主題,同時給出每個詞匯的權重,以及每篇文章所屬主題的主題系數及類別。本文基于Python的Sklearn編寫程序,分別對K等于1-20的主題參數進行了實驗。通過pyLDAvis實現對主題模型結果的可視化,如圖5所示,在K=5的時候,主題分布相對平衡,主題之間交疊較少,主題聚合效果較好。
圖5展示了5個不同主題之間的距離關系,交疊關系,可以看到5個主題分布相對平衡,可以很好地區分各個主題。圖中左側為聚合的主題,點擊每個主題,右側即可呈現對應的前25個主題詞及其對應的權重,這樣的主題分析結果可視化形式,很容易幫助研究人員從這5個主題中辨析出信息安全研究的熱點主題。右側為點擊主題3后的結果,主要展示了主題TOP25關鍵詞以及權重,從這些關鍵詞可以看到該主題主要講述的網絡攻擊,攻擊的目標主要是關鍵基礎設施,其中OT(操作技術)、ICS(工業控制系統)等工控網絡系統是重要目標。這也提示研究人員需要把關鍵基礎設施領域的工控網絡和控制系統安全作為重點研究,同時作為國家、社會和企業重點保護的目標。此外,通過分析其他幾個主題,可以看到目前工控安全已成為全球關注的熱點。主題分析結果對工控系統遭受的攻擊進行了比較全面的展示,對研究人員及時關注工控領域相關攻擊途徑、攻擊目標、攻擊方法以及防范措施都起到一定的啟示作用。
5 結束語
本文在網絡數據采集的基礎上,使用自然語言處理技術,設計了一套信息安全領域高價值信息提取感知策略。首先,加入信息安全領域自定義詞庫,對數據進行分詞、去停用詞等預處理過程,利用TextRank算法進行關鍵詞提取,得到高敏價值熱點詞。其次,在關鍵詞基礎上使用詞共現技術,計算前100個關鍵詞在數據中的共現矩陣,獲取關鍵詞的語義關系共現網絡,分析得到重要共現熱點。最后,通過構建LDA主題模型,挖掘數據中蘊含的各種主題及主題相關的關鍵詞,并通過可視化技術將主題具象化,實現信息安全熱點的精準識別與感知,達到輔助研究的目的。
參考文獻
[1] 周德懋, 李舟軍. 高性能網絡爬蟲:研究綜述[J]. 計算機科學, 2009, 36(8):26-29.
[2] 羅亞平. 基于用戶瀏覽行為的網絡熱點話題發現模型研究[D]. 北京郵電大學, 2008.
[3] 劉旭. 基于互聯網數據的話題發現及追蹤技術研究與實現[D]. 復旦大學, 2010.
[4] 孫明溪, 劉春琦. 基于DBSCAN算法與句間關系的熱點話題發現研究[J]. 圖書情報工作, 2017(12).
[5] 夏天. 詞語位置加權TextRank的關鍵詞抽取研究[J]. 數據分析與知識發現, 2013, 29(9):30-34.
[6] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022.
作者簡介:
楊立寶(1990-),男,漢族,河北唐山人,北京理工大學,碩士,國家工業信息安全發展研究中心,助理工程師;主要研究方向和關注領域:大數據與信息安全、工業信息安全。
余章馗(1992-),男,漢族,云南騰沖人,中國人民大學,碩士,國家工業信息安全發展研究中心,助理工程師;主要研究方向和關注領域:工業信息安全、工控安全、工業大數據安全。
狄曉曉(1993-),女,漢族,山東萊蕪人,北京航空航天大學,碩士,國家工業信息安全發展研究中心,助理工程師;主要研究方向和關注領域:工業信息安全、工業大數據安全。
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
云南化工(2021年8期)2021-12-21 06:37:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
科技傳播(2019年22期)2020-01-14 03:06:54
傳媒評論(2019年4期)2019-07-13 05:49:14
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
